
1. Einführung
Mit den Funktionen für generative KI von BigQuery können Sie Large Language Models (LLMs) verwenden, um Ihre Daten mit SQL zu analysieren. Sie können die Stimmung analysieren, Zusammenfassungen erstellen und Bilder in Millionen von Zeilen mit Untertiteln versehen, ohne Ihre Daten zu verschieben.
Was aber, wenn für Ihren Prompt eine große Menge an Kontext (z. B. Richtlinien, Handbücher oder ein Video) erforderlich ist, um genaue und zuverlässige Ergebnisse zu erhalten?
Gemini-Kontext-Caching löst dieses Problem, indem der große Kontext in einem Cache gespeichert wird. Bei nachfolgenden Prompts wird auf den Cache verwiesen, anstatt den gesamten Inhalt jedes Mal zu verarbeiten. Das führt zu einer geringeren Latenz und zu einer Rabattierung von bis zu 90% bei Eingabetokens.
In diesem Codelab erstellen Sie einen „Kleingedrucktes“-Rückgabebedingungen-Checker, der explizites Kontext-Caching verwendet, um Kundenretourenanfragen anhand eines umfangreichen, statischen Rückgabebedingungendokuments in BigQuery zu analysieren.

Aufgaben
- Erstellen Sie ein BigQuery-Dataset und füllen Sie es mit Beispielanfragen für Kundenrückgaben.
- Erstellen Sie einen Kontext-Cache in der Gemini Enterprise Agent Platform (früher Vertex AI), der auf ein in Cloud Storage gespeichertes Dokument mit Rückgabebedingungen verweist.
- Führen Sie eine Abfrage mit
AI.GENERATEaus, die auf den Cache verweist, um die Anfragen effizient zeilenweise auszuwerten.
Voraussetzungen
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Zugriff auf Google Cloud Shell
Dieses Codelab richtet sich an Entwickler aller Erfahrungsstufen, auch an Anfänger.
Die in diesem Codelab erstellten Ressourcen sollten weniger als 2 $ kosten.
Voraussichtliche Dauer:Dieses Codelab dauert etwa 30 Minuten.
2. Hinweis
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und mit den erforderlichen Tools vorinstalliert ist.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.

- Prüfen Sie nach der Verbindung mit Cloud Shell Ihre Authentifizierung:
gcloud auth list - Prüfen Sie, ob Ihr Projekt konfiguriert ist:
gcloud config get project - Wenn Ihr Projekt nicht wie erwartet festgelegt ist, legen Sie es fest:
gcloud config set project <YOUR_PROJECT_ID>
Projekt-ID und Standort festlegen
Führen Sie den folgenden Befehl aus, um Ihre aktive Google Cloud-Projekt-ID abzurufen und den standardmäßigen Standort als Umgebungsvariable festzulegen, die in diesem Codelab verwendet werden soll:
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
APIs aktivieren
Führen Sie diesen Befehl aus, um die erforderlichen APIs zu aktivieren:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. BigQuery-Daten vorbereiten
Bevor wir das Zwischenspeichern von Kontext testen können, benötigen wir ein Dataset und eine Tabelle mit Beispielanfragen zur Rückgabe von Kundenartikeln, gegen die wir unsere Abfragen ausführen können.
1. Dataset erstellen
Führen Sie den folgenden Befehl in Cloud Shell aus, um ein BigQuery-Dataset mit dem Namen caching_demo zu erstellen:
bq mk --dataset $PROJECT_ID:caching_demo
2. Tabelle erstellen und befüllen
Führen Sie den folgenden Befehl aus, um eine Tabelle mit dem Namen return_requests zu erstellen und Beispielanfragen für Kundenrückgaben einzufügen:
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
Es sollte eine Erfolgsmeldung angezeigt werden:
Created your-project-id.caching_demo.return_requests
Jetzt können wir den Cache erstellen.
4. Kontext-Cache erstellen
Sie erstellen den Cache mit einem REST-Aufruf an den Modellendpunkt der Gemini Enterprise Agent Platform (früher Vertex AI) mit curl.
Führen Sie in Cloud Shell den folgenden Befehl aus, um einen neuen Speicher-Bucket zu erstellen. Hier werden Dateien gespeichert, die wir im Cache speichern möchten:
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
Kopieren Sie als Nächstes das Beispielrichtliniendokument in den neu erstellten Bucket:
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
Führen Sie nun den folgenden Befehl aus, um den Cache zu erstellen, der auf das neu bereitgestellte Richtliniendokument verweist. Dies kann etwa eine Minute dauern.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
Notieren Sie sich die name, die in der JSON-Antwort zurückgegeben wird. Sie sieht so aus: projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID. Sie benötigen CACHE_ID für den nächsten Schritt.
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
CACHE_ID als Umgebungsvariable in Cloud Shell speichern:
export CACHE_ID="<YOUR_CACHE_ID>"
5. AI.GENERATE mit im Cache gespeicherten Inhalten ausführen
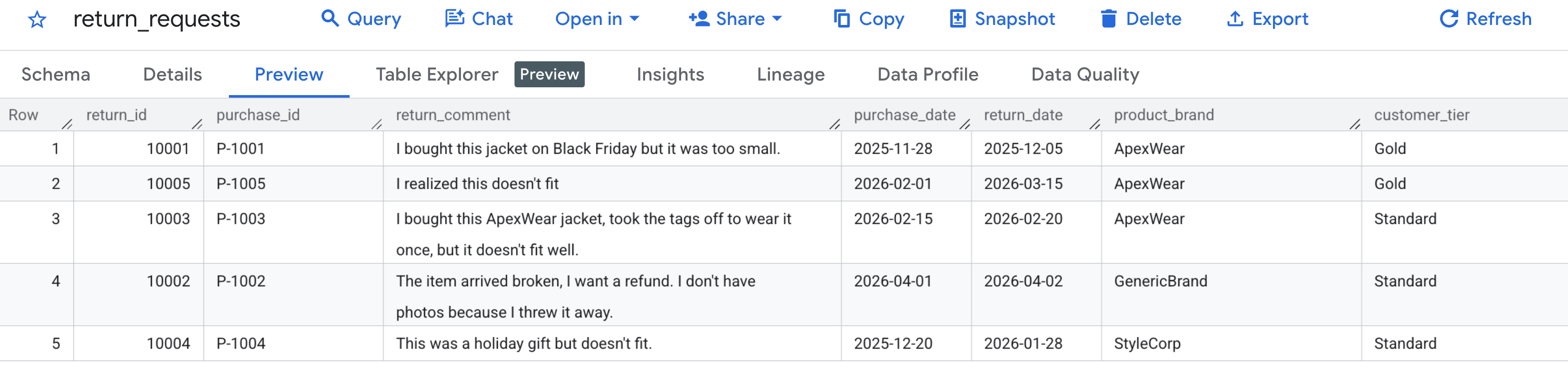
Prüfen wir zuerst, ob unsere Beispieldaten richtig generiert wurden. Rufen Sie die BigQuery-Konsole auf, suchen Sie das Dataset caching_demo und klicken Sie auf die Tabelle return_requests.
Auf dem Tab Vorschau sollten die zuvor generierten Anträge auf Kundenrückgabe angezeigt werden:
Nachdem der Cache erstellt und befüllt wurde, können Sie ihn mit AI.GENERATE abfragen, um den Erstattungsantrag zu prüfen. Dazu müssen Sie nur auf die Cache-ID verweisen.
Damit Sie Variablen nicht manuell suchen und ersetzen müssen, führen Sie den folgenden Befehl in Cloud Shell aus. Dadurch wird die SQL-Abfrage dynamisch erstellt. Dabei werden Ihre vorhandenen Umgebungsvariablen verwendet und die Abfrage wird auf dem Bildschirm ausgegeben, damit Sie sie einfach kopieren können.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
Kopieren Sie nun das SQL im Terminal, rufen Sie die BigQuery-Konsole in Ihrem Browser auf und führen Sie die Abfrage auf dem Tab „Abfrageeditor“ aus.
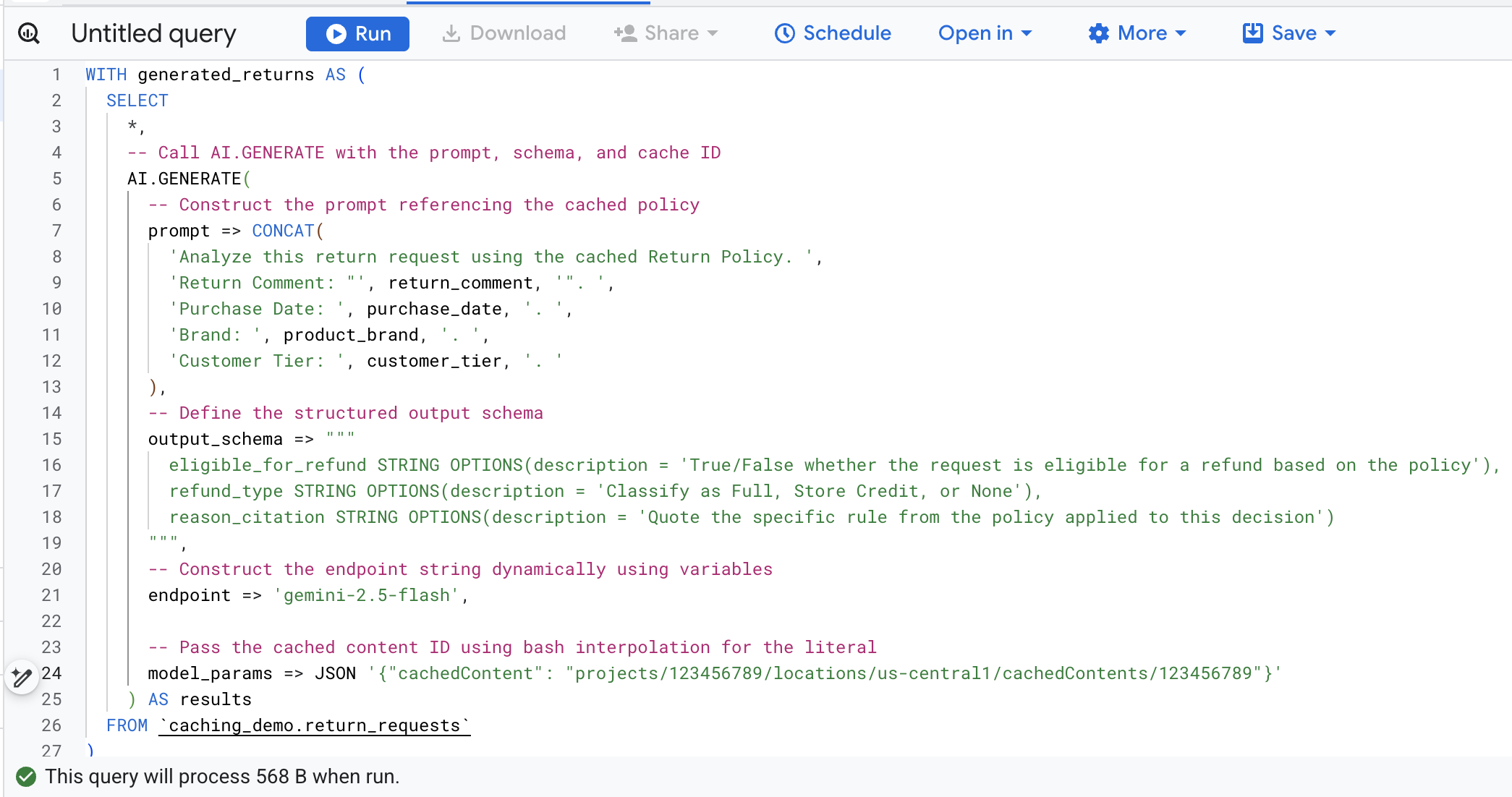
Hier eine Aufschlüsselung der wichtigsten Argumente in diesem Funktionsaufruf:
prompt: Enthält die spezifischen Informationen für jede Kundenzeile. Dieser Text wird effektiv an das große Dokument mit den Rückgabebedingungen angehängt, das sich bereits im Cache befindet.output_schema: Definiert die erwartete JSON-Struktur der Antwort des Modells.endpoint: Gibt den KI-Modellendpunkt der Agent-Plattform (in unserem Fall Gemini 2.5 Flash) an, der für die Generierung verwendet wird.model_params: Wichtiger Parameter, der die generierte Cache-ID über das FeldcachedContentübergibt.
Sie sollten die generierten Ergebnisse sehen, in denen jede Retourenanfrage gemäß der gespeicherten Richtlinie analysiert wird. Scrollen Sie nach rechts, um die extrahierten Token-Messwerte zu sehen.
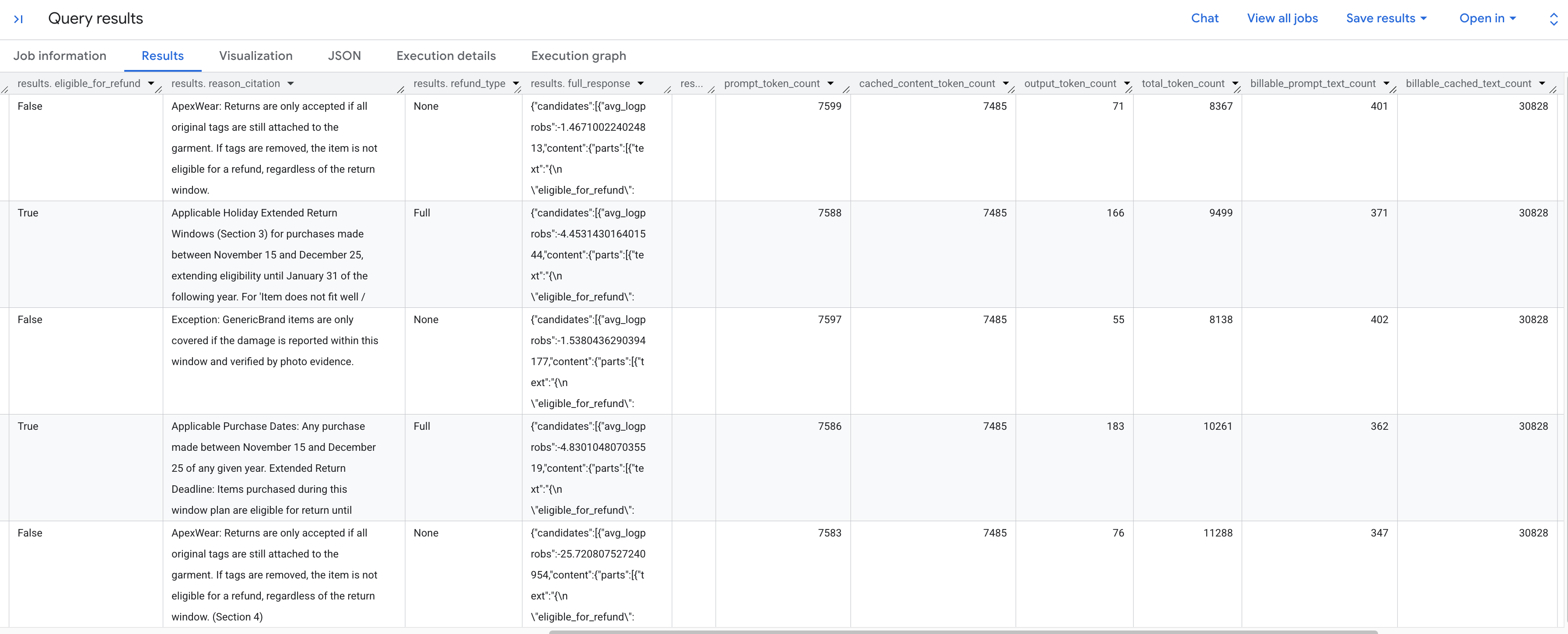
Hier finden Sie eine Aufschlüsselung der Token-Messwerte, die angezeigt werden:
prompt_token_count: Die Gesamtzahl der im Eingabe-Prompt verarbeiteten Tokens (einschließlich der im Cache gespeicherten Inhalte).cached_content_token_count: Die Anzahl der aus dem Cache bereitgestellten Tokens (entspricht dem statischen Dokument zur Rückgaberichtlinie).output_token_count: Die Anzahl der Tokens, die vom Modell in der Antwort generiert wurden.total_token_count: Die Summe der Prompt- und Ausgabetokens.billable_prompt_text_count: Die Anzahl der abrechenbaren Zeichen im nicht gecachten Teil des Prompts.billable_cached_text_count: Die Anzahl der abrechenbaren Zeichen im Cache-Inhalt.
In der Spalte billable_prompt_text_count werden nur wenige Hundert Zeichen pro Zeile angezeigt. Das ist die spezifische Anfrage des Kunden. Im Gegensatz dazu umfasst die vollständige Rückgaberichtlinie billable_cached_text_count über 30.000 Zeichen. Ohne Kontext-Caching müssten Sie für die Verarbeitung des gesamten Richtliniendokuments für jede einzelne Zeile bezahlen. Durch das Caching zahlen Sie nur einmal für das große Dokument. Bei nachfolgenden Zeilen werden Ihnen nur die kleinen, sich ändernden Prompt-Texte in Rechnung gestellt.
Das führt zu enormen Einsparungen bei Batchjobs.
6. Bereinigen
Löschen Sie die in diesem Codelab erstellten Ressourcen, um laufende Gebühren für Ihr Google Cloud-Konto zu vermeiden.
Führen Sie den folgenden Befehl in Cloud Shell aus, um das BigQuery-Dataset und seine Tabellen zu löschen:
bq rm -r -f -d caching_demo
Löschen Sie den Staging-Bucket, der für das Richtliniendokument erstellt wurde:
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
Löschen Sie den Kontextcache, um laufende Speicherkosten zu vermeiden. Verwenden Sie dazu die zuvor gespeicherten Variablen:
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. Glückwunsch
Glückwunsch! Sie haben erfolgreich einen Kontext-Cache auf der Agent Platform erstellt und in einer BigQuery KI-Funktion darauf verwiesen, um die Analyse zu beschleunigen und gleichzeitig die Kosten für die Verarbeitung von Eingabetokens zu senken.
Das haben Sie gelernt
- Umgebungstabellen für die Analyse von Retourenanfragen einrichten
- So rufen Sie die Agent Platform (Vertex AI) API mit
curlauf, um explizit einen statischen Dokumentkontext-Cache zu erstellen. - So verwenden Sie die generierte Cache-ID in einer
AI.GENERATE-SQL-Abfrage, um redundante Eingabetokens in aktiven Prompts zu entfernen.