
1. Introducción
Las funciones de IA generativa de BigQuery te permiten usar SQL para razonar sobre tus datos con modelos grandes de lenguaje (LLMs). Puedes analizar el sentimiento, generar resúmenes y subtitular imágenes en millones de filas sin mover tus datos.
Pero, ¿qué sucede si tu instrucción necesita una gran cantidad de contexto (como políticas, manuales o un video) para obtener resultados precisos y confiables?
El almacenamiento en caché de contexto de Gemini resuelve este problema almacenando ese contexto grande en una caché. Las instrucciones posteriores hacen referencia a la caché en lugar de procesar el contenido completo cada vez, lo que ofrece una latencia más baja y hasta un 90% de descuento en los tokens de entrada.
En este codelab, compilarás un verificador de política de devoluciones de "letra pequeña" que usa el almacenamiento en caché de contexto explícito para analizar las solicitudes de devolución de los clientes en comparación con un documento de política de devoluciones estático y masivo en BigQuery.

Actividades
- Crea un conjunto de datos de BigQuery y complétalo con solicitudes de devolución de clientes de muestra.
- Crea una caché de contexto en Agent Platform de Gemini Enterprise (anteriormente conocida como Vertex AI) que apunte a un documento de política de devoluciones almacenado en Cloud Storage.
- Ejecuta una consulta con
AI.GENERATEque haga referencia a la caché para evaluar las solicitudes de manera eficiente fila por fila.
Requisitos
- Un navegador web, como Chrome
- Un proyecto de Google Cloud con la facturación habilitada.
- Acceso a Google Cloud Shell
Este codelab está dirigido a desarrolladores de todos los niveles, incluidos principiantes.
Los recursos creados en este codelab deberían costar menos de $2.
Duración estimada: Se estima que finalizar este codelab tomará 30 minutos.
2. Antes de comenzar
Cómo crear un proyecto de Google Cloud
- En la consola de Google Cloud, en la página del selector de proyectos, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información sobre cómo verificar si la facturación está habilitada en un proyecto.
Inicie Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con las herramientas necesarias.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica tu autenticación:
gcloud auth list - Confirma que tu proyecto esté configurado:
gcloud config get project - Si tu proyecto no está configurado como se espera, configúralo:
gcloud config set project <YOUR_PROJECT_ID>
Configura el ID y la ubicación del proyecto
Ejecuta el siguiente comando para recuperar tu ID del proyecto de Google Cloud activo y establecer la ubicación predeterminada como variables de entorno para usar en este codelab:
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
Habilita las APIs
Ejecuta este comando para habilitar las APIs requeridas:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. Prepara los datos de BigQuery
Antes de que podamos probar el almacenamiento en caché de contexto, necesitamos un conjunto de datos y una tabla completados con solicitudes de devolución de clientes de muestra para ejecutar nuestras consultas.
1. Crea un conjunto de datos
Ejecuta el siguiente comando en Cloud Shell para crear un conjunto de datos de BigQuery llamado caching_demo:
bq mk --dataset $PROJECT_ID:caching_demo
2. Crea y completa la tabla
Ejecuta el siguiente comando para crear una tabla llamada return_requests y insertar solicitudes de devolución de clientes de muestra:
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
Deberías ver un mensaje de éxito:
Created your-project-id.caching_demo.return_requests
Ahora estamos listos para crear nuestra caché.
4. Crea la caché de contexto
Crearás la caché con una llamada REST al extremo del modelo de Agent Platform de Gemini Enterprise (anteriormente conocida como Vertex AI) con curl.
Ejecuta el siguiente comando en Cloud Shell para crear un bucket de almacenamiento nuevo. Se usará para almacenar los archivos que queremos almacenar en caché:
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
A continuación, copia el documento de política de muestra en el bucket que creaste recientemente:
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
Ahora, ejecuta el siguiente comando para crear la caché que hace referencia al documento de política que acabas de preparar (esto puede tardar un minuto en completarse):
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
Toma nota del name que se muestra en la respuesta JSON, que se verá de la siguiente manera: projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID. Necesitarás ese CACHE_ID para el siguiente paso.
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
Guarda el CACHE_ID como una variable de entorno en Cloud Shell:
export CACHE_ID="<YOUR_CACHE_ID>"
5. Ejecuta AI.GENERATE con contenido almacenado en caché
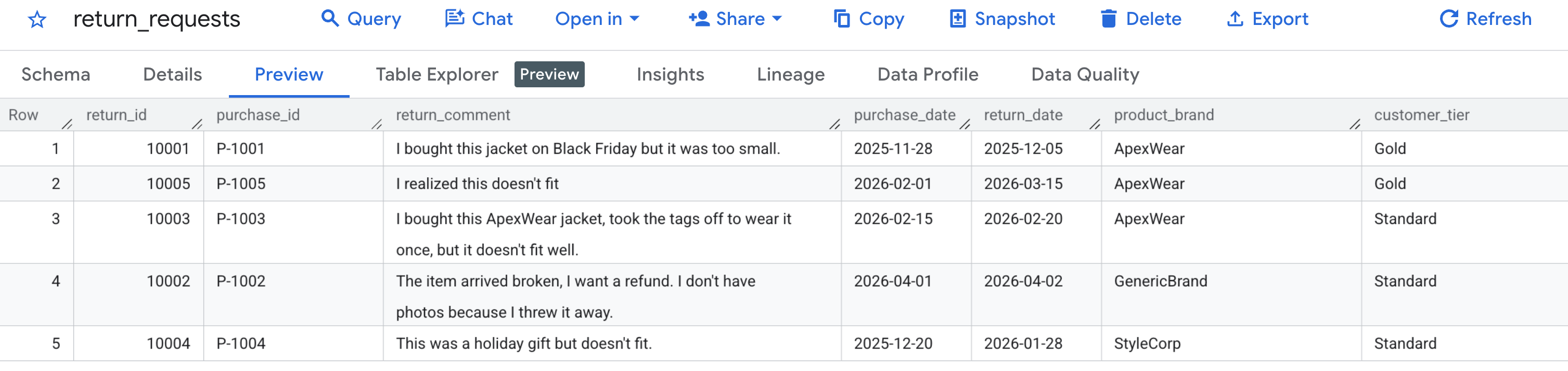
Primero, verifiquemos que nuestros datos de muestra se hayan generado correctamente. Navega a la consola de BigQuery, ubica el conjunto de datos caching_demo y haz clic en la tabla return_requests.
En la pestaña Vista previa, deberías ver las solicitudes de devolución de clientes que generamos antes:
Ahora que se creó y completó la caché, puedes realizar consultas con AI.GENERATE para evaluar la solicitud de reembolso con solo hacer referencia a ese ID de caché.
Para evitar buscar y reemplazar variables de forma manual, ejecuta el siguiente comando en Cloud Shell. Esto compilará de forma dinámica la consulta en SQL con tus variables de entorno existentes y la imprimirá en la pantalla para que puedas copiarla con facilidad.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
Ahora, copia el SQL en la terminal, navega a la consola de BigQuery en tu navegador y ejecuta la consulta en la pestaña del editor de consultas.
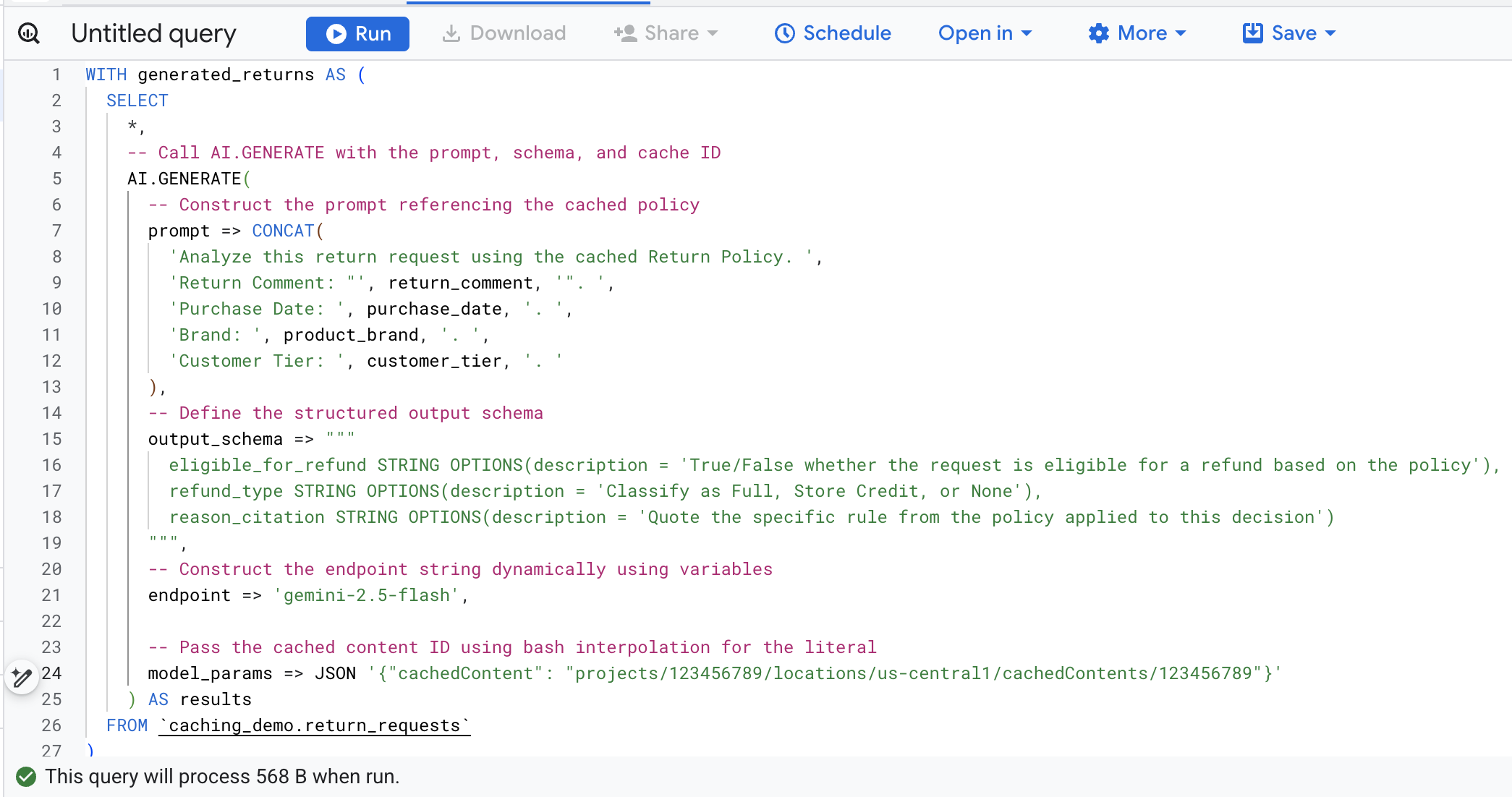
Este es un desglose de los argumentos clave en esta llamada a función:
prompt: Contiene la información específica de cada fila de clientes. Este texto se agrega de manera efectiva al documento grande de la política de devoluciones que ya está en la caché.output_schema: Define la estructura JSON esperada de la respuesta del modelo.endpoint: Especifica el extremo del modelo de IA de Agent Platform (Gemini 2.5 Flash en nuestro caso) que se usa para la generación.model_params: Es un parámetro fundamental que pasa el ID de caché generado con el campocachedContent.
Deberías ver los resultados generados que analizan cada solicitud de devolución según la política almacenada. Desplázate hacia la derecha para ver las métricas de tokens extraídas.
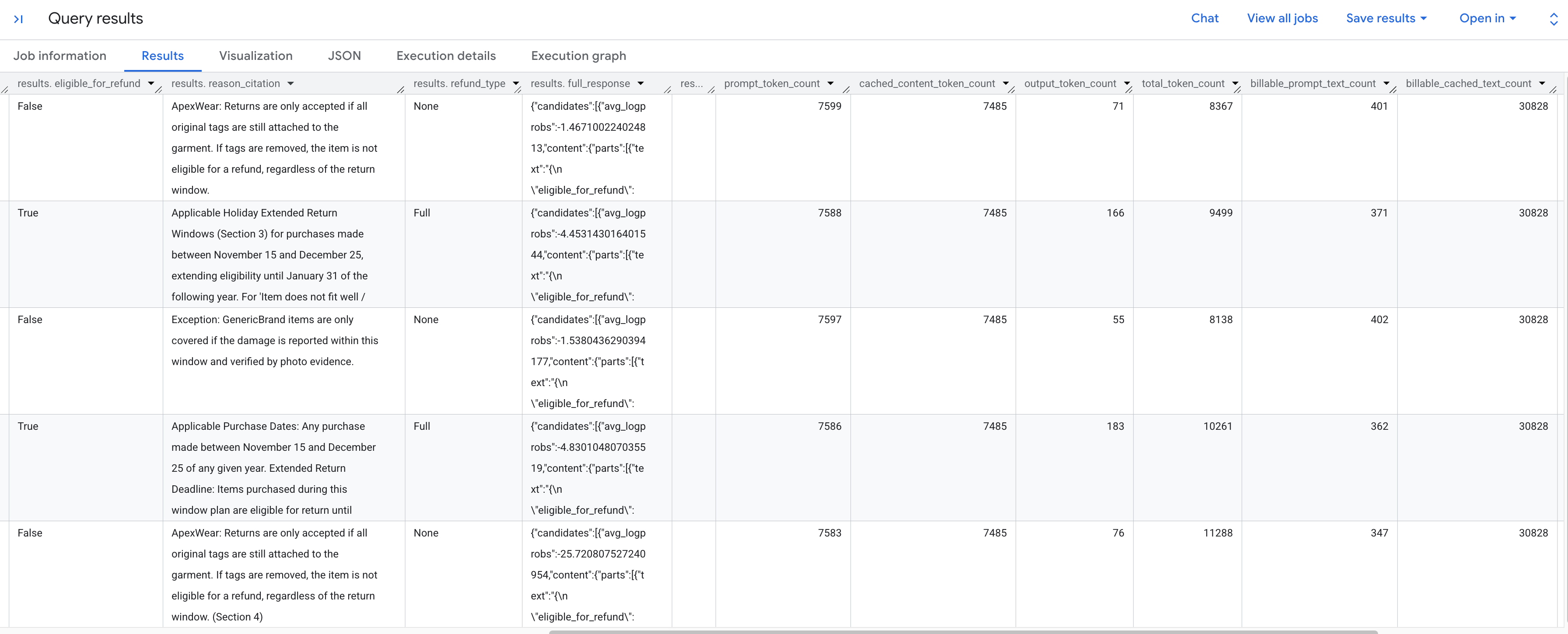
Este es un desglose de las métricas de tokens que ves:
prompt_token_count: Es la cantidad total de tokens procesados en la instrucción de entrada (incluido el contenido almacenado en caché).cached_content_token_count: Es la cantidad de tokens que se publicaron desde la caché (que representa el documento de política de devoluciones estático).output_token_count: Es la cantidad de tokens que genera el modelo en la respuesta.total_token_count: Es la suma de los tokens de instrucción y de salida.billable_prompt_text_count: Es la cantidad de caracteres facturables en la parte no almacenada en caché de la instrucción.billable_cached_text_count: Es la cantidad de caracteres facturables en el contenido almacenado en caché.
Observa la columna billable_prompt_text_count : Muestra solo unos cientos de caracteres por fila, que es solo la solicitud específica del cliente. Compara eso con el billable_cached_text_count de más de 30,000 caracteres para la política de devoluciones completa. Sin el almacenamiento en caché de contexto, pagarías para procesar ese documento de política completo para cada fila. Si lo almacenas en caché, pagas el documento grande una vez y las filas posteriores solo te cobran por el texto de instrucción pequeño y cambiante.
Esto genera ahorros masivos para los trabajos por lotes.
6. Limpia
Para evitar cargos continuos en tu cuenta de Google Cloud, borra los recursos creados durante este codelab.
Ejecuta el siguiente comando en Cloud Shell para borrar el conjunto de datos de BigQuery y sus tablas:
bq rm -r -f -d caching_demo
Borra el bucket de etapa intermedia creado para el documento de política:
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
Por último, borra la caché de contexto para evitar cargos de almacenamiento continuos con las variables que almacenaste antes:
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. Felicitaciones
¡Felicitaciones! Creaste correctamente una caché de contexto en Agent Platform y la consultaste en una función IA de BigQuery para acelerar el análisis y reducir los costos de procesamiento de tokens de entrada.
Qué aprendiste
- Cómo configurar tablas de entorno para el análisis de solicitudes de devolución
- Cómo llamar a la API de Agent Platform (Vertex AI) con
curlpara crear de forma explícita una caché de contexto de documento estático - Cómo usar el ID de caché generado en una consulta en SQL
AI.GENERATEpara eliminar tokens de entrada redundantes en las instrucciones activas