
۱. مقدمه
توابع هوش مصنوعی مولد BigQuery به شما امکان میدهند از SQL برای استدلال در مورد دادههای خود با استفاده از مدلهای زبان بزرگ (LLM) استفاده کنید. میتوانید احساسات را تجزیه و تحلیل کنید، خلاصهها را تولید کنید و تصاویر را در میلیونها ردیف بدون جابجایی دادههای خود شرح دهید.
اما اگر درخواست شما برای دریافت نتایج دقیق و قابل اعتماد به حجم زیادی از متن (مانند سیاستها، دستورالعملها یا ویدیو) نیاز داشته باشد، چه باید کرد؟
ذخیرهسازی زمینه Gemini این مشکل را با ذخیره آن زمینه بزرگ در یک حافظه پنهان حل میکند. درخواستهای بعدی به جای پردازش کل محتوا در هر بار، به حافظه پنهان ارجاع میدهند و تأخیر کمتری را ارائه میدهند و تا ۹۰٪ تخفیف در توکنهای ورودی ارائه میدهند.
در این آزمایشگاه کد، شما یک بررسیکنندهی سیاست بازگشت کالا با جزئیات دقیق (Fine Print) خواهید ساخت که از ذخیرهسازی صریح متن برای تجزیه و تحلیل درخواستهای بازگشت مشتری در برابر یک سند سیاست بازگشت کالا با حجم زیاد و استاتیک در BigQuery استفاده میکند.

کاری که انجام خواهید داد
- یک مجموعه داده BigQuery ایجاد کنید و آن را با درخواستهای بازگشت نمونه مشتری پر کنید.
- یک Context Cache در Gemini Enterprise Agent Platform (که قبلاً با نام Vertex AI شناخته میشد) ایجاد کنید که به یک سند سیاست بازگشت کالا که در Cloud Storage ذخیره شده است، اشاره میکند.
- با استفاده از
AI.GENERATEیک کوئری اجرا کنید که به حافظه پنهان (cache) ارجاع میدهد تا درخواستها را به صورت ردیف به ردیف و به طور کارآمد ارزیابی کند.
آنچه نیاز دارید
- یک مرورگر وب مانند کروم
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
- دسترسی به پوسته ابری گوگل
این آزمایشگاه کد برای توسعهدهندگان در تمام سطوح، از جمله مبتدیان، مناسب است.
منابع ایجاد شده در این آزمایشگاه کد باید کمتر از ۲ دلار هزینه داشته باشند.
مدت زمان تخمینی: تکمیل این آزمایشگاه کد تقریباً 30 دقیقه طول خواهد کشید.
۲. قبل از شروع
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
شروع پوسته ابری
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و ابزارهای لازم از قبل روی آن بارگذاری شدهاند.
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، احراز هویت خود را تأیید کنید:
gcloud auth list - تأیید کنید که پروژه شما پیکربندی شده است:
gcloud config get project - اگر پروژه شما مطابق انتظار تنظیم نشده است، آن را تنظیم کنید:
gcloud config set project <YOUR_PROJECT_ID>
شناسه و مکان پروژه خود را تنظیم کنید
دستور زیر را اجرا کنید تا شناسه فعال پروژه گوگل کلود خود را بازیابی کنید و مکان پیشفرض را به عنوان متغیرهای محیطی برای استفاده در سراسر این آزمایشگاه کد تنظیم کنید :
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
فعال کردن APIها
برای فعال کردن API های مورد نیاز، این دستور را اجرا کنید:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
۳. آمادهسازی دادههای BigQuery
قبل از اینکه بتوانیم ذخیرهسازی زمینه (context caching) را آزمایش کنیم، به یک مجموعه داده و یک جدول پر از درخواستهای بازگشت نمونه مشتری نیاز داریم تا کوئریهای خود را روی آنها اجرا کنیم.
۱. ایجاد یک مجموعه داده
دستور زیر را در Cloud Shell اجرا کنید تا یک مجموعه داده BigQuery با نام caching_demo ایجاد شود:
bq mk --dataset $PROJECT_ID:caching_demo
۲. ایجاد و پر کردن جدول
دستور زیر را برای ایجاد جدولی با نام return_requests و درج درخواستهای بازگشت مشتری نمونه اجرا کنید:
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
شما باید یک پیام موفقیتآمیز ببینید:
Created your-project-id.caching_demo.return_requests
اکنون آمادهایم تا حافظه پنهان خود را ایجاد کنیم!
۴. ایجاد حافظه پنهان زمینه
شما با استفاده از curl ، با استفاده از یک فراخوانی REST به نقطه پایانی مدل Gemini Enterprise Agent Platform (که قبلاً با نام Vertex AI شناخته میشد) حافظه پنهان (cache) را ایجاد خواهید کرد.
دستور زیر را در Cloud Shell اجرا کنید تا یک مخزن ذخیرهسازی جدید ایجاد شود . این مخزن برای ذخیره فایلهایی که میخواهیم کش کنیم، استفاده خواهد شد:
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
در مرحله بعد، سند سیاست نمونه را در سطل تازه ایجاد شده خود کپی کنید :
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
اکنون، دستور زیر را برای ایجاد حافظه پنهان (cache) که به سند سیاست تازه مرحلهبندی شده شما ارجاع میدهد، اجرا کنید (تکمیل این مرحله ممکن است حدود یک دقیقه طول بکشد):
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
به name که در JSON پاسخ برگردانده میشود توجه کنید، که به این شکل خواهد بود: projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID . برای مرحله بعدی به آن CACHE_ID نیاز خواهید داشت.
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
ذخیره CACHE_ID به عنوان یک متغیر محیطی در Cloud Shell:
export CACHE_ID="<YOUR_CACHE_ID>"
۵. اجرای AI.GENERATE با محتوای ذخیرهشده
ابتدا، بیایید تأیید کنیم که دادههای نمونه ما به درستی تولید شدهاند . به کنسول BigQuery بروید، مجموعه داده caching_demo را پیدا کنید و روی جدول return_requests کلیک کنید.
در زیر برگه پیشنمایش ، باید درخواستهای بازگشت مشتری که قبلاً ایجاد کردهایم را ببینید:
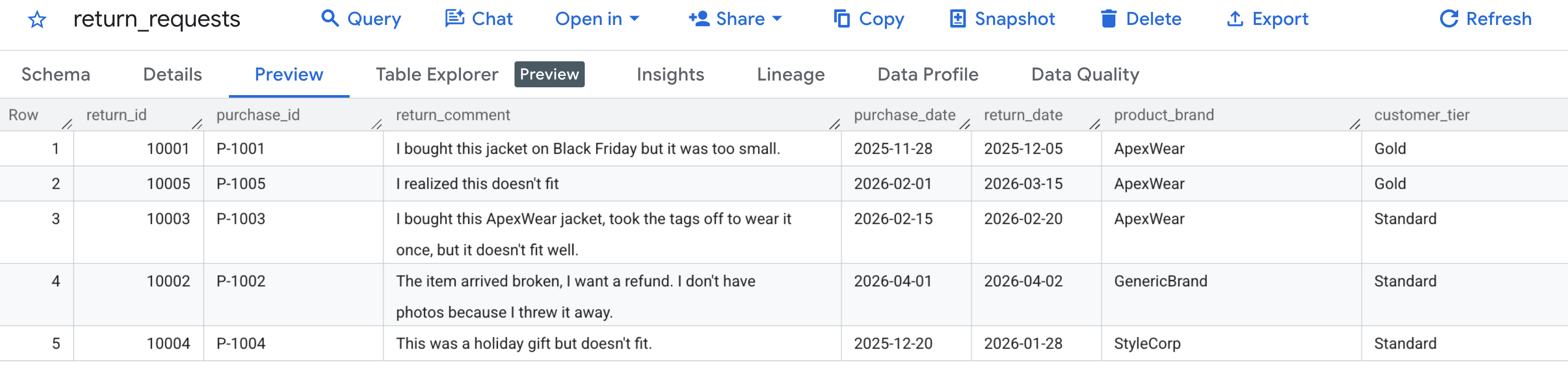
اکنون که حافظه پنهان ایجاد و پر شده است، میتوانید با استفاده از AI.GENERATE و با ارجاع به شناسه حافظه پنهان، درخواست بازپرداخت را ارزیابی کنید.
برای جلوگیری از پیدا کردن و جایگزینی دستی متغیرها، دستور زیر را در Cloud Shell اجرا کنید . این دستور به صورت پویا با استفاده از متغیرهای محیطی موجود شما، کوئری SQL را میسازد و آن را روی صفحه نمایش چاپ میکند تا بتوانید به راحتی آن را کپی کنید.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
حالا، sql را در ترمینال کپی کنید ، به کنسول BigQuery در مرورگر خود بروید و کوئری را در تب ویرایشگر کوئری اجرا کنید .
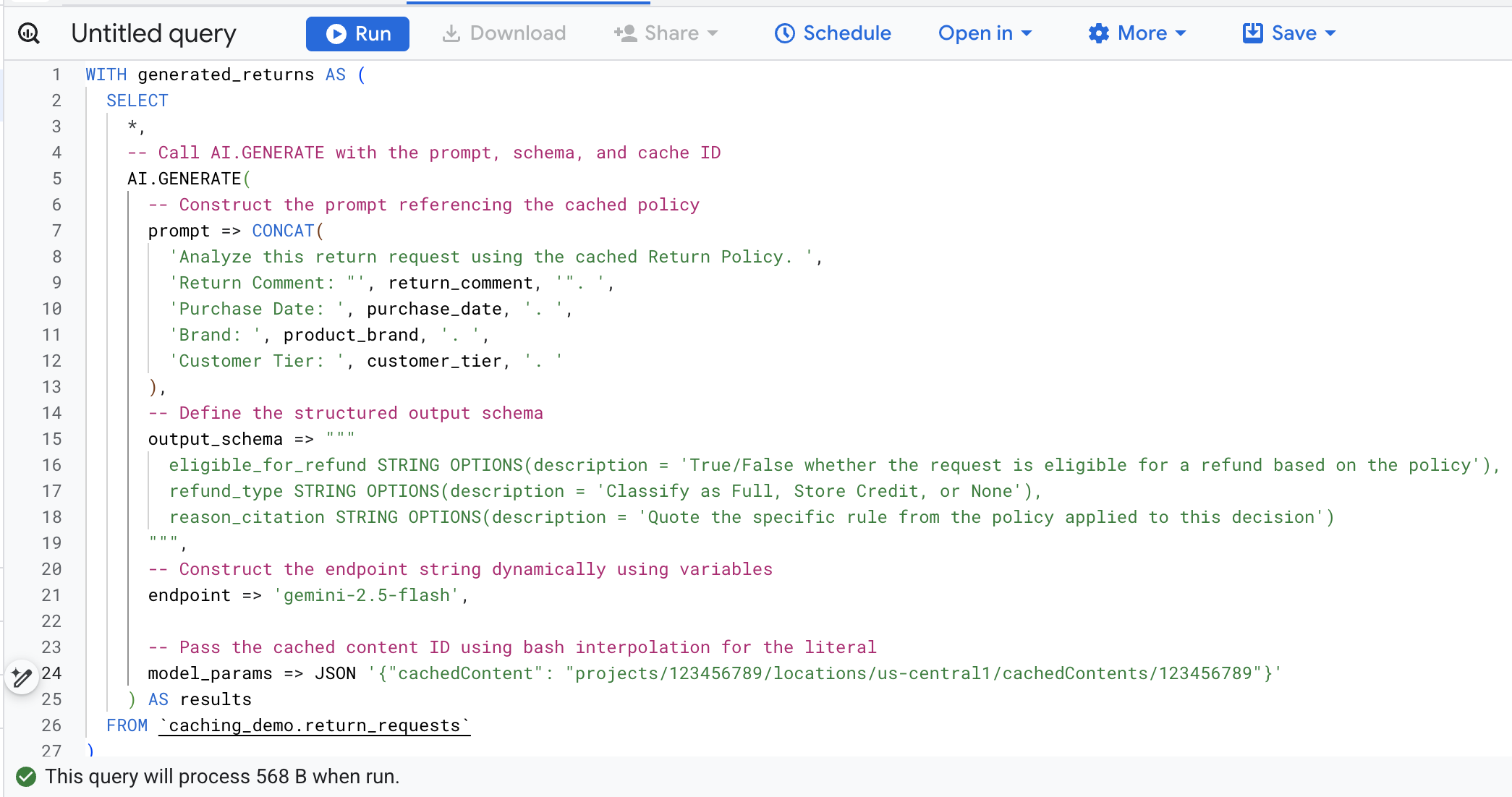
در اینجا خلاصهای از آرگومانهای کلیدی در این فراخوانی تابع آمده است:
-
prompt: شامل اطلاعات خاص برای هر ردیف مشتری است. این متن به طور مؤثر به سند بزرگ «سیاست بازگشت کالا» که از قبل در حافظه پنهان (cache) قرار دارد، اضافه میشود. -
output_schema: ساختار JSON مورد انتظار از پاسخ مدل را تعریف میکند. -
endpoint: نقطه پایانی مدل هوش مصنوعی پلتفرم عامل (در مورد ما Gemini 2.5 Flash) مورد استفاده برای تولید را مشخص میکند. -
model_params: پارامتر بسیار مهمی که شناسه کش تولید شده را با استفاده از فیلدcachedContentارسال میکند.
شما باید نتایج تولید شده را که هر درخواست بازگشت را طبق سیاست ذخیره شده تجزیه و تحلیل میکند، ببینید. برای دیدن معیارهای توکن استخراج شده، به سمت راست اسکرول کنید.
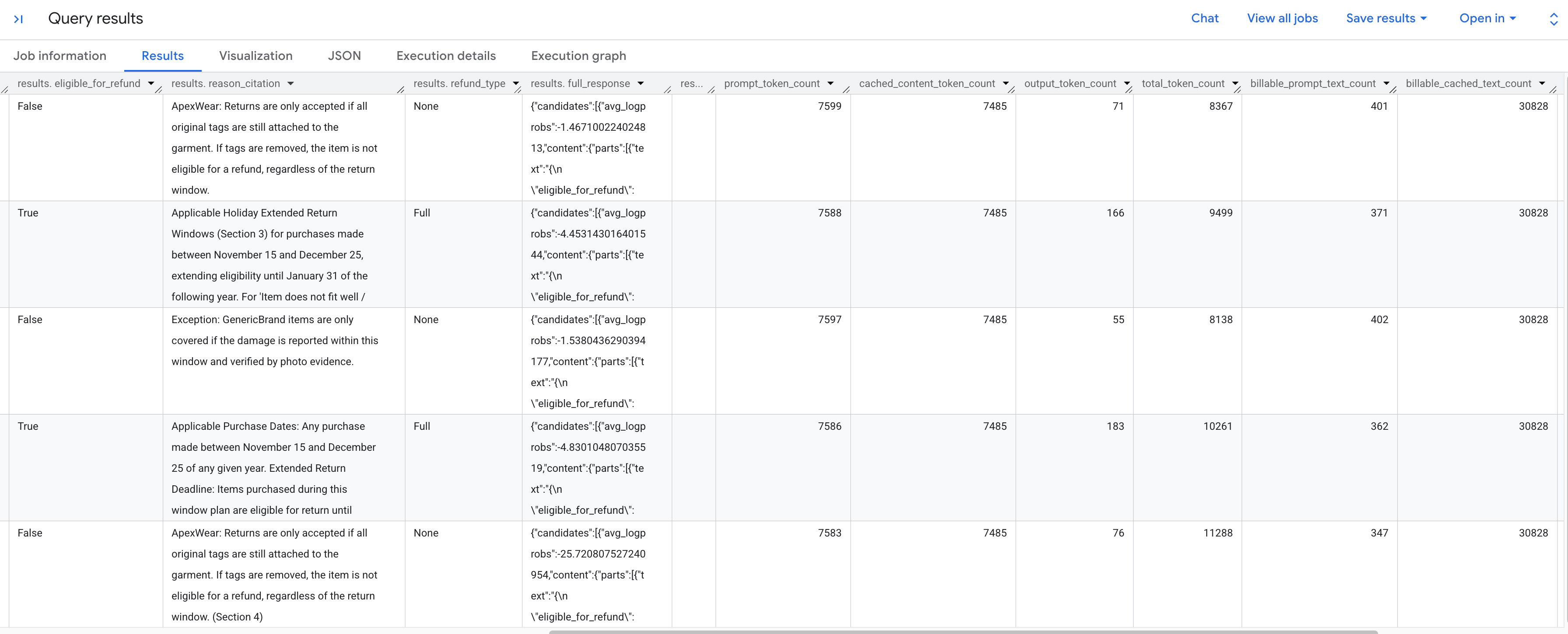
در اینجا خلاصهای از معیارهای توکن که مشاهده میکنید، آورده شده است:
-
prompt_token_count: تعداد کل توکنهای پردازششده در اعلان ورودی (شامل محتوای ذخیرهشده). -
cached_content_token_count: تعداد توکنهای ارائه شده از حافظه پنهان (که نشاندهنده سند استاتیک سیاست بازگشت کالا است). -
output_token_count: تعداد توکنهای تولید شده توسط مدل در پاسخ. -
total_token_count: مجموع توکنهای اعلان و خروجی. -
billable_prompt_text_count: تعداد کاراکترهای قابل پرداخت در بخش غیر ذخیره شدهی اعلان. -
billable_cached_text_count: تعداد کاراکترهای قابل پرداخت در محتوای ذخیره شده.
به ستون billable_prompt_text_count نگاه کنید - فقط چند صد کاراکتر در هر ردیف نشان میدهد که فقط درخواست خاص مشتری است. این را با billable_cached_text_count که بیش از 30،000 کاراکتر برای کل سیاست بازگشت کالا دارد، مقایسه کنید. بدون ذخیرهسازی زمینه، شما برای پردازش آن سند کامل سیاست برای هر سطر هزینه پرداخت میکنید. با ذخیرهسازی آن، شما یک بار برای سند بزرگ هزینه پرداخت میکنید و سطرهای بعدی فقط برای متن کوچک و متغیر اعلان هزینه دریافت میکنند.
این منجر به صرفهجویی عظیمی برای کارهای دستهای میشود!
۶. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، منابع ایجاد شده در طول این codelab را حذف کنید.
دستور زیر را در Cloud Shell اجرا کنید تا مجموعه داده BigQuery و جداول آن حذف شود:
bq rm -r -f -d caching_demo
سطل مرحلهبندی ایجاد شده برای سند سیاست را حذف کنید :
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
در نهایت، برای جلوگیری از هزینههای ذخیرهسازی مداوم با استفاده از متغیرهایی که قبلاً ذخیره کردهاید، حافظه پنهان زمینه را حذف کنید :
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
۷. تبریک
تبریک! شما با موفقیت یک حافظه پنهان زمینه در Agent Platform ایجاد کردید و آن را در یک تابع هوش مصنوعی BigQuery ارجاع دادید تا سرعت تجزیه و تحلیل افزایش یابد و در عین حال هزینههای پردازش توکن ورودی کاهش یابد.
آنچه آموختهاید
- نحوه تنظیم جداول محیطی برای تجزیه و تحلیل درخواست بازگشت.
- نحوه فراخوانی API پلتفرم عامل (Vertex AI) با استفاده از
curlبرای ایجاد صریح یک حافظه پنهان زمینه سند استاتیک. - نحوه استفاده از Cache ID تولید شده در یک کوئری
AI.GENERATESQL برای حذف توکنهای ورودی اضافی در اعلانهای فعال.