
1. Introduction
Les fonctions d'IA générative de BigQuery vous permettent d'utiliser SQL pour raisonner sur vos données à l'aide de grands modèles de langage (LLM). Vous pouvez analyser les sentiments, générer des résumés et ajouter des légendes aux images sur des millions de lignes sans déplacer vos données.
Mais que faire si votre requête nécessite une quantité massive de contexte (comme des règles, des manuels ou une vidéo) pour obtenir des résultats précis et fiables ?
La mise en cache du contexte Gemini résout ce problème en stockant ce grand contexte dans un cache. Les requêtes suivantes font référence au cache au lieu de traiter l'intégralité du contenu à chaque fois. La latence est donc réduite et vous bénéficiez d'une remise pouvant atteindre 90% sur les jetons d'entrée.
Dans cet atelier de programmation, vous allez créer un vérificateur des conditions générales de retour qui utilise la mise en cache de contexte explicite pour analyser les demandes de retour des clients par rapport à un énorme document statique sur les conditions de retour dans BigQuery.

Objectifs de l'atelier
- Créez un ensemble de données BigQuery et remplissez-le avec des exemples de demandes de retour de clients.
- Créez un cache de contexte dans Gemini Enterprise Agent Platform (anciennement Vertex AI) pointant vers un document de conditions de retour stocké dans Cloud Storage.
- Exécutez une requête à l'aide de
AI.GENERATEqui fait référence au cache pour évaluer efficacement les requêtes ligne par ligne.
Prérequis
- Un navigateur Web (par exemple, Chrome)
- Un projet Google Cloud avec facturation activée
- Accès à Google Cloud Shell
Cet atelier de programmation s'adresse aux développeurs de tous niveaux, y compris aux débutants.
Les ressources créées dans cet atelier de programmation devraient coûter moins de 2 $.
Durée estimée : cet atelier de programmation prendra environ 30 minutes.
2. Avant de commencer
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Démarrer Cloud Shell
Cloud Shell est un environnement de ligne de commande exécuté dans Google Cloud et fourni avec les outils nécessaires.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez votre authentification :
gcloud auth list - Vérifiez que votre projet est configuré :
gcloud config get project - Si votre projet n'est pas défini comme prévu, définissez-le :
gcloud config set project <YOUR_PROJECT_ID>
Définir l'ID et l'emplacement de votre projet
Exécutez la commande suivante pour récupérer l'ID de votre projet Google Cloud actif et définir l'emplacement par défaut en tant que variables d'environnement à utiliser tout au long de cet atelier de programmation :
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
Activer les API
Exécutez cette commande pour activer les API requises :
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. Préparer les données BigQuery
Avant de pouvoir tester la mise en cache du contexte, nous avons besoin d'un ensemble de données et d'un tableau contenant des exemples de demandes de retour client pour exécuter nos requêtes.
1. Créer un ensemble de données
Exécutez la commande suivante dans Cloud Shell pour créer un ensemble de données BigQuery nommé caching_demo :
bq mk --dataset $PROJECT_ID:caching_demo
2. Créer et remplir la table
Exécutez la commande suivante pour créer une table nomméereturn_requests et insérer des exemples de demandes de retour client :
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
Un message confirmant le succès de l'opération doit s'afficher :
Created your-project-id.caching_demo.return_requests
Nous sommes maintenant prêts à créer notre cache.
4. Créer le cache de contexte
Vous allez créer le cache à l'aide d'un appel REST au point de terminaison du modèle Gemini Enterprise Agent Platform (anciennement Vertex AI) à l'aide de curl.
Exécutez la commande suivante dans Cloud Shell pour créer un bucket de stockage. Il servira à stocker les fichiers que nous souhaitons mettre en cache :
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
Ensuite, copiez l'exemple de document de règle dans le bucket que vous venez de créer :
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
Exécutez à présent la commande suivante pour créer le cache faisant référence au document de stratégie que vous venez de préparer (cette opération peut prendre une minute ou deux) :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
Notez le name renvoyé dans la réponse JSON, qui ressemblera à ceci : projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID. Vous aurez besoin de ce CACHE_ID pour l'étape suivante.
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
Enregistrez CACHE_ID en tant que variable d'environnement dans Cloud Shell :
export CACHE_ID="<YOUR_CACHE_ID>"
5. Exécuter AI.GENERATE avec du contenu mis en cache
Commençons par vérifier que nos exemples de données ont été générés correctement. Accédez à la console BigQuery, localisez l'ensemble de données caching_demo, puis cliquez sur la table return_requests.
Dans l'onglet Aperçu, vous devriez voir les demandes de retour client que nous avons générées précédemment :
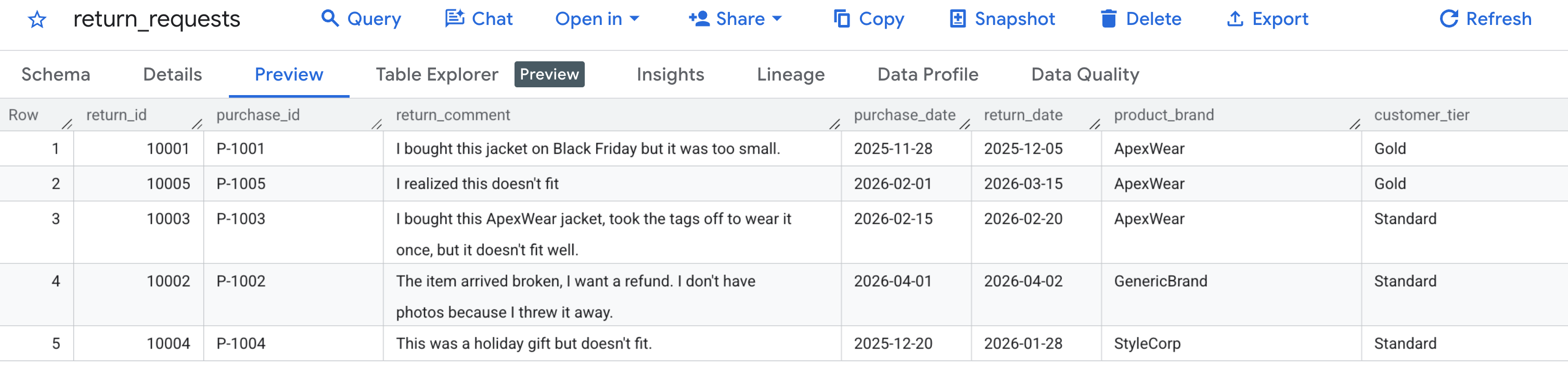
Maintenant que le cache a été créé et rempli, vous pouvez effectuer une requête à l'aide de AI.GENERATE pour évaluer la demande de remboursement en référençant simplement cet ID de cache.
Pour éviter de rechercher et de remplacer manuellement les variables, exécutez la commande suivante dans Cloud Shell. Cela créera dynamiquement la requête SQL à l'aide de vos variables d'environnement existantes et l'affichera à l'écran pour que vous puissiez la copier facilement.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
Maintenant, copiez le code SQL dans le terminal, accédez à la console BigQuery dans votre navigateur, puis exécutez la requête dans l'onglet de l'éditeur de requête.
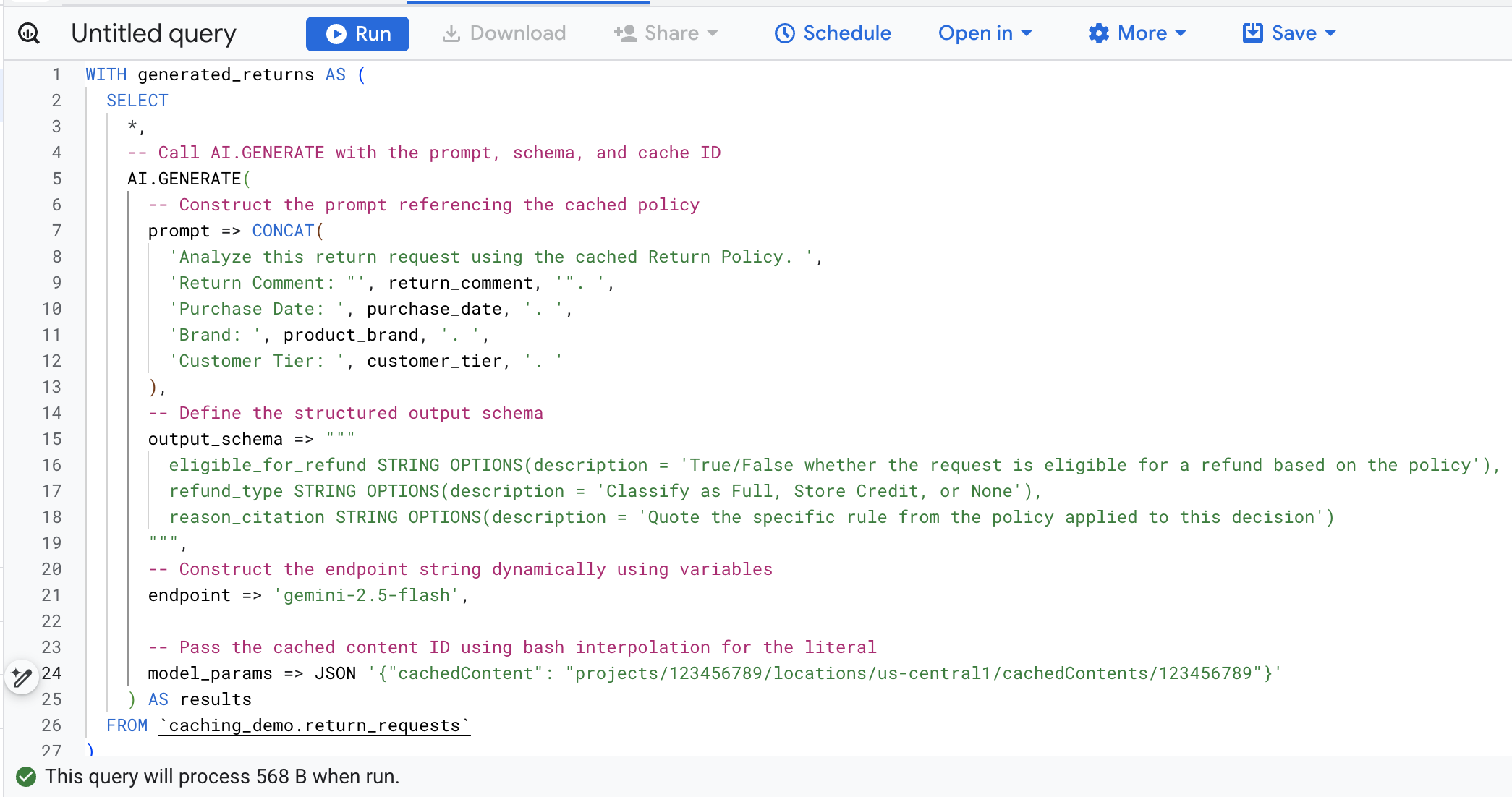
Voici les principaux arguments de cet appel de fonction :
prompt: contient les informations spécifiques à chaque ligne client. Ce texte est effectivement ajouté au grand document sur les conditions de retour déjà présent dans le cache.output_schema: définit la structure JSON attendue de la réponse du modèle.endpoint: spécifie le point de terminaison du modèle d'IA de la plate-forme d'agent (Gemini 2.5 Flash dans notre cas) utilisé pour la génération.model_params: paramètre essentiel qui transmet l'ID de cache généré à l'aide du champcachedContent.
Les résultats générés devraient analyser chaque demande de retour en fonction du règlement stocké. Faites défiler l'écran vers la droite pour afficher les métriques des jetons extraits.
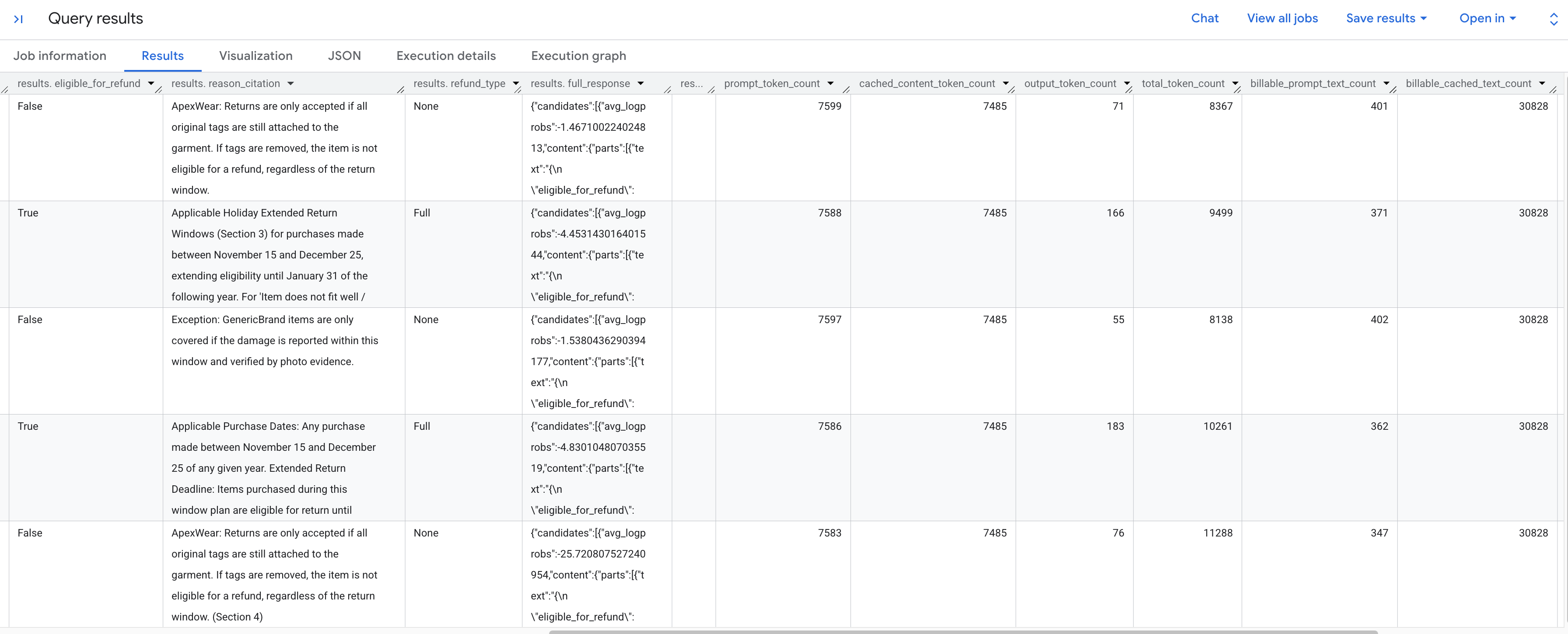
Voici le détail des métriques de jetons que vous voyez :
prompt_token_count: nombre total de jetons traités dans la requête d'entrée (y compris le contenu mis en cache).cached_content_token_count: nombre de jetons diffusés à partir du cache (représentant le document statique sur les conditions de retour).output_token_count: nombre de jetons générés par le modèle dans la réponse.total_token_count: somme des jetons d'invite et de sortie.billable_prompt_text_count: nombre de caractères facturables dans la partie non mise en cache du prompt.billable_cached_text_count: nombre de caractères facturables dans le contenu mis en cache.
Examinez la colonne billable_prompt_text_count. Elle n'affiche que quelques centaines de caractères par ligne, ce qui correspond à la demande spécifique du client. À titre de comparaison,la billable_cached_text_count de l'intégralité des conditions de retour dépasse les 30 000 caractères. Sans la mise en cache du contexte, vous paieriez le traitement de l'intégralité du document de règles pour chaque ligne. En le mettant en cache, vous ne payez le grand document qu'une seule fois. Les lignes suivantes ne vous facturent que le petit texte d'invite qui change.
Cela permet de réaliser des économies considérables pour les jobs par lot.
6. Effectuer un nettoyage
Pour éviter que les ressources créées lors de cet atelier de programmation ne soient facturées en permanence sur votre compte Google Cloud, supprimez-les.
Exécutez la commande suivante dans Cloud Shell pour supprimer l'ensemble de données BigQuery et ses tables :
bq rm -r -f -d caching_demo
Supprimez le bucket intermédiaire créé pour le document de règles :
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
Enfin, supprimez le cache de contexte pour éviter des frais de stockage continus à l'aide des variables que vous avez stockées précédemment :
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. Félicitations
Félicitations ! Vous avez créé un cache de contexte dans Agent Platform et l'avez référencé dans une fonction AI BigQuery pour accélérer l'analyse tout en réduisant les coûts de traitement des jetons d'entrée.
Connaissances acquises
- Configurer des tables d'environnement pour l'analyse des demandes de retour
- Comment appeler l'API Agent Platform (Vertex AI) à l'aide de
curlpour créer explicitement un cache de contexte de document statique. - Comment utiliser l'ID de cache généré dans une requête SQL
AI.GENERATEpour éliminer les jetons d'entrée redondants dans les requêtes actives.