
1. परिचय
BigQuery के जनरेटिव एआई फ़ंक्शन की मदद से, लार्ज लैंग्वेज मॉडल (एलएलएम) का इस्तेमाल करके, SQL की मदद से अपने डेटा का विश्लेषण किया जा सकता है. अपने डेटा को कहीं और ले जाए बिना, लाखों पंक्तियों में मौजूद डेटा के लिए, लोगों की राय का विश्लेषण किया जा सकता है, खास जानकारी जनरेट की जा सकती है, और इमेज के लिए कैप्शन जनरेट किए जा सकते हैं.
हालांकि, अगर सटीक और भरोसेमंद नतीजे पाने के लिए, आपके प्रॉम्प्ट को ज़्यादा कॉन्टेक्स्ट (जैसे कि नीतियां, मैन्युअल या कोई वीडियो) की ज़रूरत हो, तो क्या होगा?
Gemini के कॉन्टेक्स्ट को कैश में सेव करने की सुविधा इस समस्या को हल करती है. इसके लिए, वह बड़े कॉन्टेक्स्ट को कैश में सेव करती है. इसके बाद के प्रॉम्प्ट, हर बार पूरा कॉन्टेंट प्रोसेस करने के बजाय, कैश में सेव किए गए कॉन्टेक्स्ट का रेफ़रंस देते हैं. इससे, इंतज़ार का समय कम हो जाता है और इनपुट टोकन पर 90% तक की छूट मिलती है.
इस कोडलैब में, "बारीक अक्षरों में लिखी गई जानकारी" के लिए, सामान लौटाने की नीति की जांच करने वाला एक टूल बनाया जाएगा. यह टूल, BigQuery में मौजूद, सामान लौटाने की नीति के बड़े और स्टैटिक दस्तावेज़ के ख़िलाफ़, ग्राहक के सामान लौटाने के अनुरोधों का विश्लेषण करने के लिए, साफ़ तौर पर कॉन्टेक्स्ट को कैश में सेव करने की सुविधा का इस्तेमाल करता है.

आप क्या करेंगे
- एक BigQuery डेटासेट बनाएं और उसमें, ग्राहक के सामान लौटाने के अनुरोधों के सैंपल जोड़ें.
- Gemini Enterprise Agent Platform (जिसे पहले Vertex AI के नाम से जाना जाता था) में, कॉन्टेक्स्ट कैश बनाएं. यह कैश, Cloud Storage में सेव किए गए, सामान लौटाने की नीति के दस्तावेज़ की ओर इशारा करेगा.
AI.GENERATEका इस्तेमाल करके एक क्वेरी चलाएं. यह क्वेरी, हर पंक्ति के हिसाब से अनुरोधों का आकलन करने के लिए, कैश का रेफ़रंस देगी.
आपको किन चीज़ों की ज़रूरत होगी
- कोई वेब ब्राउज़र, जैसे कि Chrome
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
- Google Cloud Shell का ऐक्सेस
यह कोडलैब, सभी लेवल के डेवलपर के लिए है. इसमें शुरुआती डेवलपर भी शामिल हैं.
इस कोडलैब में बनाए गए संसाधनों की लागत, दो डॉलर से कम होनी चाहिए.
अनुमानित समय: इस कोडलैब को पूरा करने में करीब 30 मिनट लगेंगे.
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट बनाएं
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, कोई Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग की सुविधा चालू हो. किसी प्रोजेक्ट के लिए बिलिंग की सुविधा चालू है या नहीं, यह देखने का तरीका जानें.
Cloud Shell शुरू करें
Cloud Shell , Google Cloud में चलने वाला एक कमांड-लाइन एनवायरमेंट है. इसमें ज़रूरी टूल पहले से लोड होते हैं.
- Google Cloud Console में सबसे ऊपर, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, अपनी पुष्टि करें:
gcloud auth list - पुष्टि करें कि आपका प्रोजेक्ट कॉन्फ़िगर किया गया है या नहीं:
gcloud config get project - अगर आपका प्रोजेक्ट, उम्मीद के मुताबिक सेट नहीं है, तो उसे सेट करें:
gcloud config set project <YOUR_PROJECT_ID>
अपना प्रोजेक्ट आईडी और जगह की जानकारी सेट करें
अपने चालू Google Cloud प्रोजेक्ट का आईडी वापस पाने और इस कोडलैब में इस्तेमाल करने के लिए, डिफ़ॉल्ट जगह की जानकारी को एनवायरमेंट वैरिएबल के तौर पर सेट करने के लिए, यह कमांड चलाएं:
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
एपीआई चालू करें
**ज़रूरी एपीआई चालू करने** के लिए, यह कमांड चलाएं:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. BigQuery डेटा तैयार करना
कॉन्टेक्स्ट को कैश में सेव करने की सुविधा की जांच करने से पहले, हमें एक डेटासेट और एक टेबल की ज़रूरत होगी. इसमें, ग्राहक के सामान लौटाने के अनुरोधों के सैंपल मौजूद हों, ताकि हम उनके ख़िलाफ़ अपनी क्वेरी चला सकें.
1. डेटासेट बनाना
caching_demo नाम का BigQuery डेटासेट बनाने के लिए, Cloud Shell में यह कमांड चलाएं:
bq mk --dataset $PROJECT_ID:caching_demo
2. टेबल बनाना और उसमें डेटा जोड़ना
`return_requests` नाम की टेबल बनानेreturn_requests और ग्राहक के सामान लौटाने के अनुरोधों के सैंपल जोड़ने के लिए, यह कमांड चलाएं:
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
आपको सफलता का मैसेज दिखेगा:
Created your-project-id.caching_demo.return_requests
अब हम अपना कैश बनाने के लिए तैयार हैं!
4. कॉन्टेक्स्ट कैश बनाना
कैश बनाने के लिए, Gemini Enterprise Agent Platform (जिसे पहले Vertex AI के नाम से जाना जाता था) के मॉडल एंडपॉइंट पर, curl का इस्तेमाल करके REST कॉल किया जाएगा.
नया स्टोरेज बकेट बनाने के लिए, Cloud Shell में यह कमांड चलाएं. इसका इस्तेमाल, उन फ़ाइलों को सेव करने के लिए किया जाएगा जिन्हें हमें कैश में सेव करना है:
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
इसके बाद, नीति के सैंपल वाले दस्तावेज़ की कॉपी , नए बनाए गए बकेट में करें:
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
अब, कैश बनाने के लिए यह कमांड चलाएं. यह कैश, नीति के उस दस्तावेज़ का रेफ़रंस देगा जिसे आपने अभी-अभी स्टेज किया है. इसमें एक मिनट या उससे ज़्यादा समय लग सकता है:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
रिस्पॉन्स JSON में दिखाए गए name को नोट करें. यह इस तरह दिखेगा: projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID. अगले चरण के लिए, आपको इस CACHE_ID की ज़रूरत होगी.
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
Cloud Shell में, CACHE_ID को एनवायरमेंट वैरिएबल के तौर पर सेव करें:
export CACHE_ID="<YOUR_CACHE_ID>"
5. कैश में सेव किए गए कॉन्टेंट के साथ, AI.GENERATE का इस्तेमाल करना
सबसे पहले, पक्का करें कि हमारा सैंपल डेटा सही तरीके से जनरेट हुआ हो. BigQuery कंसोल पर जाएं, caching_demo डेटासेट ढूंढें, और return_requests टेबल पर क्लिक करें.
झलक टैब में, आपको ग्राहक के सामान लौटाने के वे अनुरोध दिखने चाहिए जिन्हें हमने पहले जनरेट किया था:
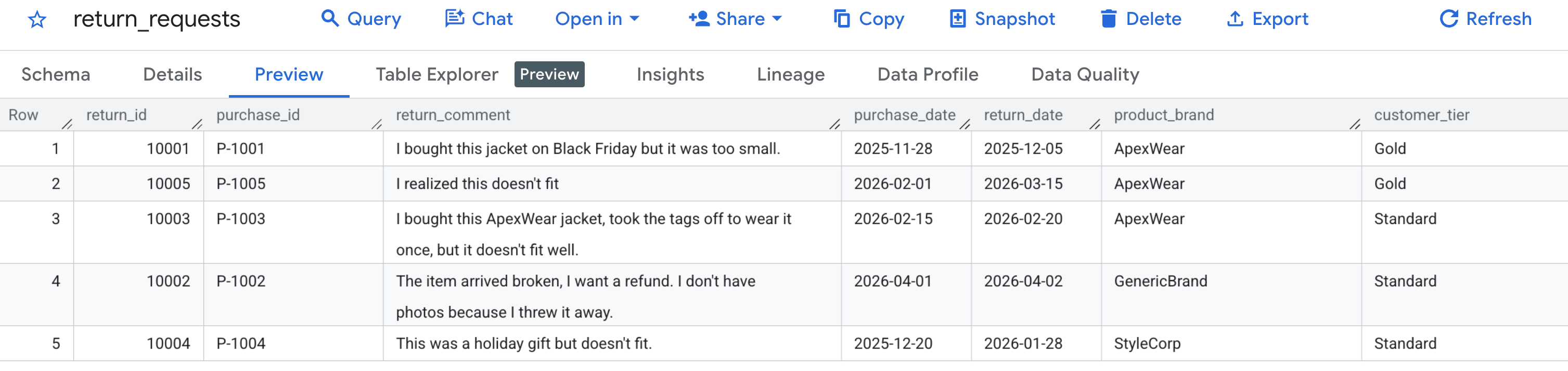
कैश बन जाने और उसमें डेटा जुड़ जाने के बाद, रिफ़ंड के अनुरोध का आकलन करने के लिए, AI.GENERATE का इस्तेमाल करके क्वेरी की जा सकती है. इसके लिए, सिर्फ़ उस कैश आईडी का रेफ़रंस देना होगा.
वैरिएबल को मैन्युअल तरीके से ढूंढने और बदलने से बचने के लिए, Cloud Shell में यह कमांड चलाएं. इससे, आपके मौजूदा एनवायरमेंट वैरिएबल का इस्तेमाल करके, SQL क्वेरी डाइनैमिक तरीके से बनेगी और स्क्रीन पर दिखेगी, ताकि इसे आसानी से कॉपी किया जा सके.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
अब, टर्मिनल में मौजूद SQL को कॉपी करें, अपने ब्राउज़र में BigQuery कंसोल पर जाएं, और क्वेरी एडिटर टैब में क्वेरी को एक्ज़ीक्यूट करें.
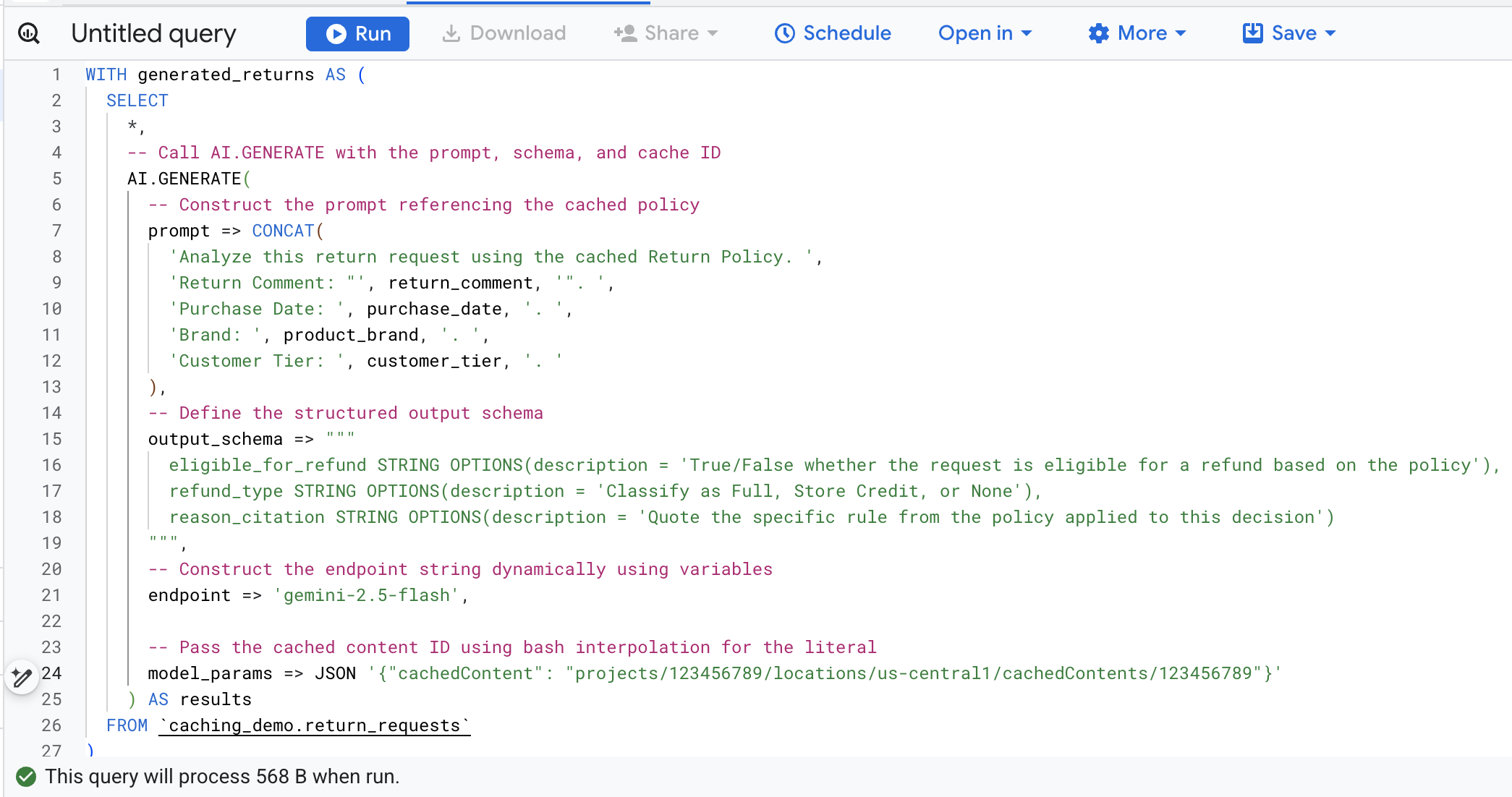
इस फ़ंक्शन कॉल में मौजूद मुख्य आर्ग्युमेंट की जानकारी यहां दी गई है:
prompt: इसमें, ग्राहक की हर पंक्ति के लिए खास जानकारी होती है. यह टेक्स्ट, कैश में पहले से मौजूद, सामान लौटाने की नीति के बड़े दस्तावेज़ में जोड़ा जाता है.output_schema: यह मॉडल के रिस्पॉन्स के लिए, JSON के अनुमानित स्ट्रक्चर को तय करता है.endpoint: यह जनरेशन के लिए इस्तेमाल किए गए, Agent Platform के एआई मॉडल एंडपॉइंट (हमारे मामले में Gemini 2.5 Flash) के बारे में बताता है.model_params: यह अहम पैरामीटर है. यहcachedContentफ़ील्ड का इस्तेमाल करके, जनरेट किए गए कैश आईडी को पास करता है.
आपको जनरेट किए गए नतीजे दिखेंगे. इनमें, सेव की गई नीति के मुताबिक, सामान लौटाने के हर अनुरोध का विश्लेषण किया गया होगा. एक्सट्रैक्ट की गई टोकन मेट्रिक देखने के लिए, दाईं ओर स्क्रोल करें.
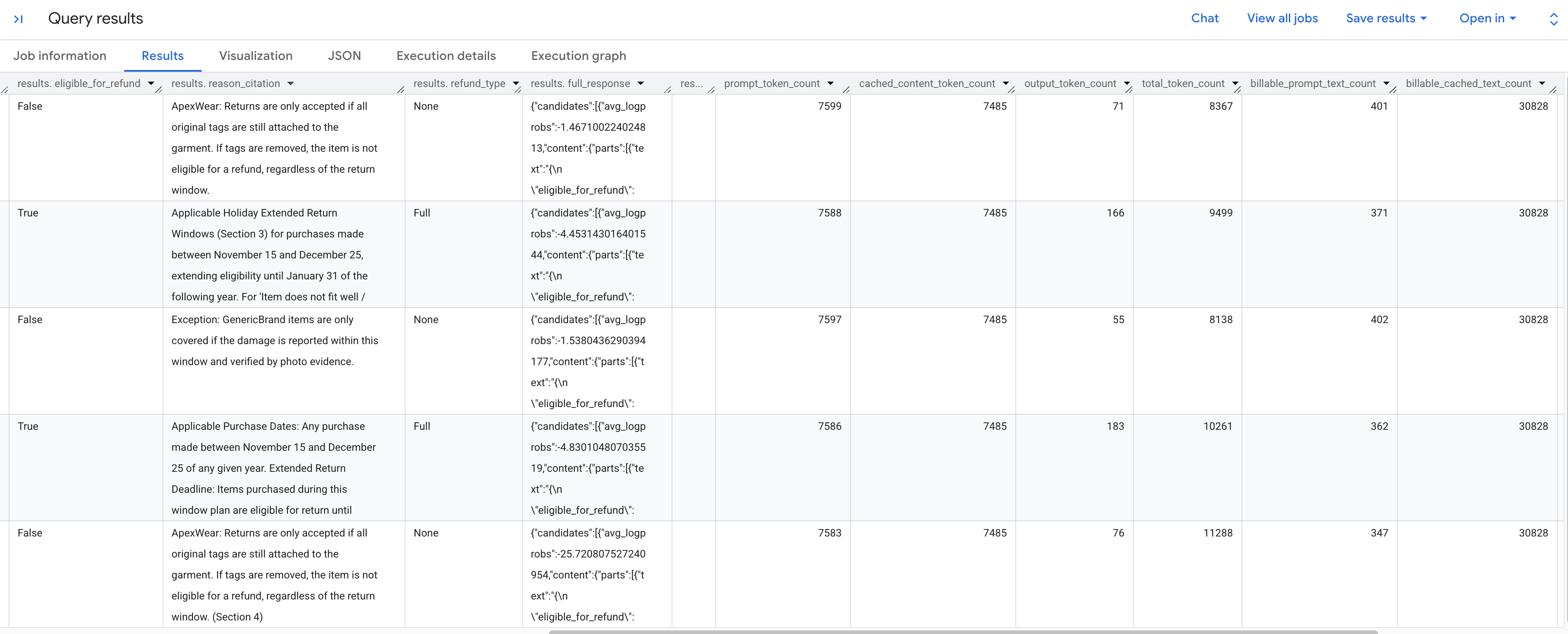
यहां, आपको दिखने वाली टोकन मेट्रिक की जानकारी दी गई है:
prompt_token_count: इनपुट प्रॉम्प्ट में प्रोसेस किए गए टोकन की कुल संख्या. इसमें कैश में सेव किया गया कॉन्टेंट भी शामिल है.cached_content_token_count: कैश से दिखाए गए टोकन की संख्या. यह, सामान लौटाने की स्टैटिक नीति के दस्तावेज़ को दिखाता है.output_token_count: रिस्पॉन्स में मॉडल से जनरेट किए गए टोकन की संख्या.total_token_count: प्रॉम्प्ट और आउटपुट टोकन का योग.billable_prompt_text_count: प्रॉम्प्ट के उस हिस्से में बिल किए जा सकने वाले वर्णों की संख्या जो कैश में सेव नहीं है.billable_cached_text_count: कैश में सेव किए गए कॉन्टेंट में बिल किए जा सकने वाले वर्णों की संख्या.
billable_prompt_text_count कॉलम देखें. इसमें हर पंक्ति के लिए, सिर्फ़ कुछ सौ वर्ण दिखते हैं. यह सिर्फ़ ग्राहक का खास अनुरोध है. इसकी तुलना, billable_cached_text_count से करें. इसमें, सामान लौटाने की पूरी नीति के लिए 30,000 से ज़्यादा वर्ण हैं. कॉन्टेक्स्ट को कैश में सेव करने की सुविधा के बिना, आपको हर पंक्ति के लिए, नीति के पूरे दस्तावेज़ को प्रोसेस करने के लिए पैसे चुकाने पड़ते. इसे कैश में सेव करने पर, आपको बड़े दस्तावेज़ के लिए एक बार पैसे चुकाने पड़ते हैं. इसके बाद की पंक्तियों के लिए, आपसे सिर्फ़ प्रॉम्प्ट के उस छोटे टेक्स्ट के लिए पैसे लिए जाते हैं जो बदलता रहता है.
इससे बैच जॉब के लिए, काफ़ी बचत होती है!
6. व्यवस्थित करें
अपने Google Cloud खाते पर लगातार लगने वाले शुल्क से बचने के लिए, इस कोडलैब के दौरान बनाए गए संसाधन मिटाएं.
BigQuery डेटासेट और उसकी टेबल मिटाने के लिए, Cloud Shell में यह कमांड चलाएं:
bq rm -r -f -d caching_demo
नीति के दस्तावेज़ के लिए बनाया गया स्टेजिंग बकेट मिटाएं:
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
आखिर में, कॉन्टेक्स्ट कैश मिटाएं , ताकि पहले सेव किए गए वैरिएबल का इस्तेमाल करके, स्टोरेज के लगातार लगने वाले शुल्क से बचा जा सके:
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. बधाई हो
बधाई हो! आपने Agent Platform में, कॉन्टेक्स्ट कैश बना लिया है. साथ ही, इनपुट टोकन को प्रोसेस करने की लागत कम करते हुए, विश्लेषण की प्रोसेस को तेज़ करने के लिए, इसे BigQuery के एआई फ़ंक्शन में रेफ़रंस किया है.
आपने क्या सीखा
- सामान लौटाने के अनुरोधों के विश्लेषण के लिए, एनवायरमेंट टेबल सेट अप करने का तरीका.
- स्टैटिक दस्तावेज़ के कॉन्टेक्स्ट कैश को साफ़ तौर पर बनाने के लिए,
curlका इस्तेमाल करके, Agent Platform (Vertex AI) API को कॉल करने का तरीका. - चालू प्रॉम्प्ट में मौजूद, एक जैसे इनपुट टोकन को हटाने के लिए,
AI.GENERATESQL क्वेरी में, जनरेट किए गए कैश आईडी का इस्तेमाल करने का तरीका.