
1. Pengantar
Fungsi AI generatif BigQuery memungkinkan Anda menggunakan SQL untuk melakukan penalaran pada data menggunakan Model Bahasa Besar (LLM). Anda dapat menganalisis sentimen, membuat ringkasan, dan memberi teks pada gambar di jutaan baris tanpa memindahkan data.
Namun, bagaimana jika perintah Anda memerlukan konteks yang sangat besar (seperti kebijakan, panduan, atau video) untuk mendapatkan hasil yang akurat dan andal?
Caching konteks Gemini mengatasi hal ini dengan menyimpan konteks besar tersebut dalam cache. Perintah berikutnya akan mereferensikan cache, bukan memproses seluruh konten setiap kali, sehingga menawarkan latensi yang lebih rendah dan diskon hingga 90% untuk token input.
Dalam codelab ini, Anda akan membuat Pemeriksa Kebijakan Pengembalian "Ketentuan Kecil" yang menggunakan caching konteks eksplisit untuk menganalisis permintaan pengembalian pelanggan terhadap dokumen kebijakan pengembalian statis yang besar di BigQuery.

Yang akan Anda lakukan
- Membuat set data BigQuery dan mengisinya dengan contoh permintaan pengembalian pelanggan.
- Membuat Cache Konteks di Platform Agen Gemini Enterprise (sebelumnya dikenal sebagai Vertex AI), yang mengarah ke dokumen kebijakan pengembalian yang disimpan di Cloud Storage.
- Menjalankan kueri menggunakan
AI.GENERATEyang mereferensikan cache untuk mengevaluasi permintaan berdasarkan baris per baris secara efisien.
Yang akan Anda butuhkan
- Browser web seperti Chrome
- Project Google Cloud yang mengaktifkan penagihan
- Akses ke Google Cloud Shell
Codelab ini ditujukan untuk developer dari semua level, termasuk pemula.
Resource yang dibuat dalam codelab ini akan dikenai biaya kurang dari $2.
Perkiraan durasi: Codelab ini memerlukan waktu sekitar 30 menit untuk diselesaikan.
2. Sebelum memulai
Membuat Project Google Cloud
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
Mulai Cloud Shell
Cloud Shell adalah lingkungan command line yang berjalan di Google Cloud dan sudah dilengkapi dengan alat yang diperlukan.
- Klik Activate Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, verifikasi autentikasi Anda:
gcloud auth list - Pastikan project Anda dikonfigurasi:
gcloud config get project - Jika project Anda tidak ditetapkan seperti yang diharapkan, tetapkan project:
gcloud config set project <YOUR_PROJECT_ID>
Menetapkan Project ID dan Lokasi
Jalankan perintah berikut untuk mengambil Project ID Google Cloud aktif dan menetapkan lokasi default sebagai variabel lingkungan yang akan digunakan di seluruh codelab ini:
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
Mengaktifkan API
Jalankan perintah ini untuk mengaktifkan API yang diperlukan:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. Menyiapkan Data BigQuery
Sebelum dapat menguji caching konteks, kita memerlukan set data dan tabel yang diisi dengan contoh permintaan pengembalian pelanggan untuk menjalankan kueri.
1. Membuat set data
Jalankan perintah berikut di Cloud Shell untuk membuat set data BigQuery bernama caching_demo:
bq mk --dataset $PROJECT_ID:caching_demo
2. Membuat dan mengisi tabel
Jalankan perintah berikut untuk membuat tabel bernama return_requests dan menyisipkan contoh permintaan pengembalian pelanggan:
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
Anda akan melihat pesan keberhasilan:
Created your-project-id.caching_demo.return_requests
Sekarang kita siap membuat cache.
4. Membuat Cache Konteks
Anda akan membuat cache menggunakan panggilan REST ke endpoint model Platform Agen Gemini Enterprise (sebelumnya dikenal sebagai Vertex AI) menggunakan curl.
Jalankan perintah berikut di Cloud Shell untuk membuat bucket penyimpanan baru. Bucket ini akan digunakan untuk menyimpan file yang ingin kita cache:
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
Selanjutnya, salin dokumen kebijakan contoh ke dalam bucket yang baru dibuat:
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
Sekarang, jalankan perintah berikut untuk membuat cache yang mereferensikan dokumen kebijakan yang baru di-staging (proses ini mungkin memerlukan waktu satu menit atau lebih untuk diselesaikan):
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
Perhatikan name yang ditampilkan dalam JSON respons, yang akan terlihat seperti ini: projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID. Anda akan memerlukan CACHE_ID tersebut untuk langkah berikutnya.
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
Simpan CACHE_ID sebagai variabel lingkungan di Cloud Shell:
export CACHE_ID="<YOUR_CACHE_ID>"
5. Menjalankan AI.GENERATE dengan Konten yang Di-cache
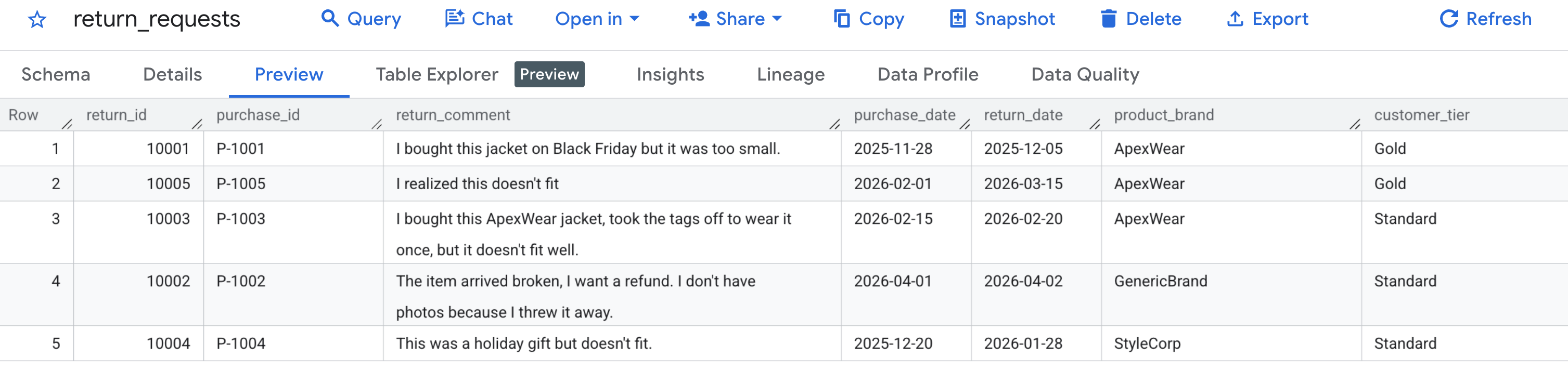
Pertama, mari kita verifikasi bahwa data contoh kita dibuat dengan benar. Buka konsol BigQuery, temukan set data caching_demo, lalu klik tabel return_requests.
Di tab Pratinjau, Anda akan melihat permintaan pengembalian pelanggan yang kita buat sebelumnya:
Setelah cache dibuat dan diisi, Anda dapat membuat kueri menggunakan AI.GENERATE untuk mengevaluasi permintaan pengembalian dana dengan hanya mereferensikan Cache ID tersebut.
Untuk menghindari pencarian dan penggantian variabel secara manual, jalankan perintah berikut di Cloud Shell. Tindakan ini akan membuat kueri SQL secara dinamis menggunakan variabel lingkungan yang ada dan mencetaknya ke layar sehingga Anda dapat dengan mudah menyalinnya.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
Sekarang, salin sql di terminal, buka konsol BigQuery di browser Anda, lalu jalankan kueri di tab editor kueri.
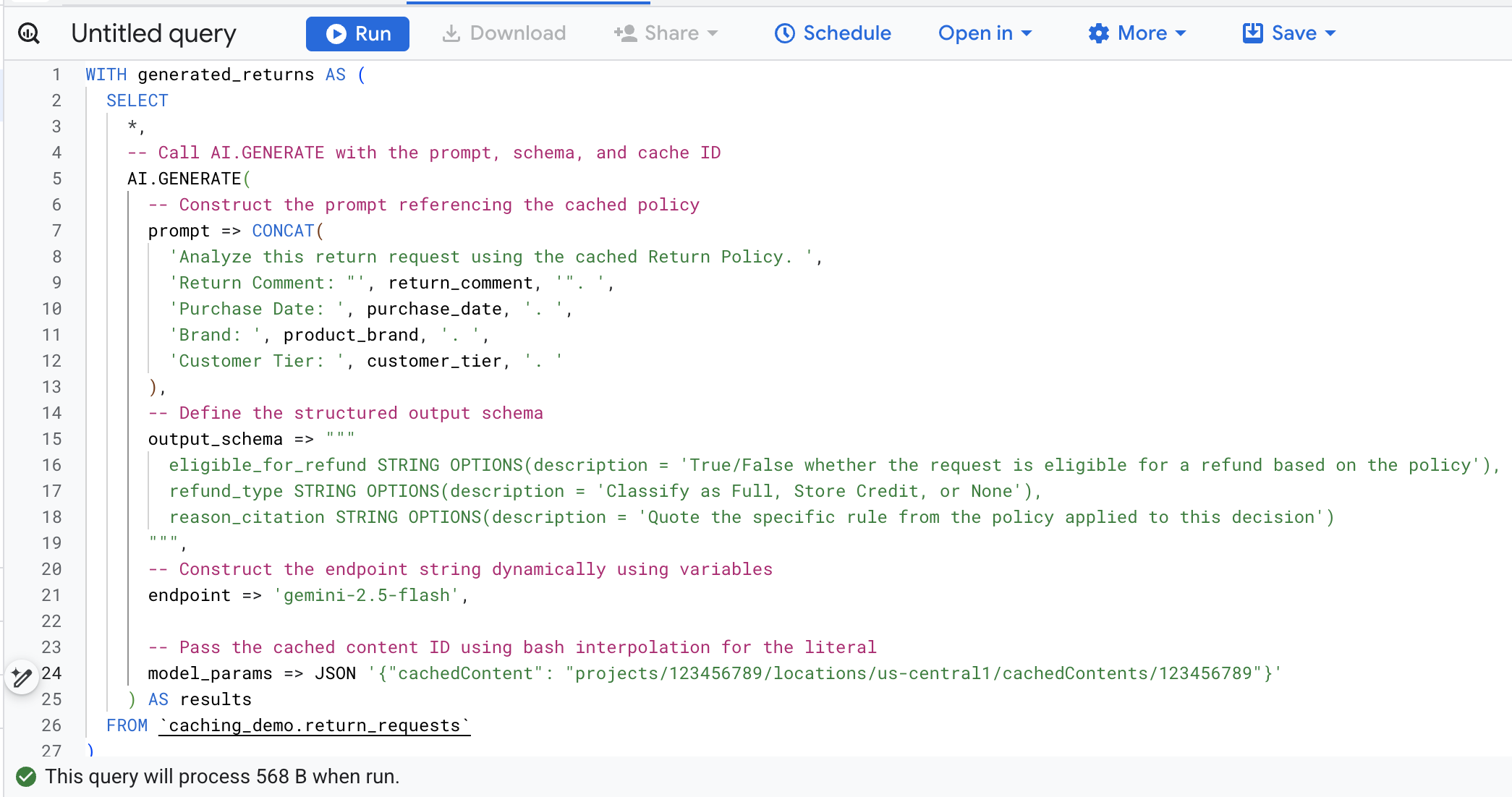
Berikut perincian argumen utama dalam panggilan fungsi ini:
prompt: Berisi informasi spesifik untuk setiap baris pelanggan. Teks ini secara efektif ditambahkan ke dokumen Kebijakan Pengembalian yang besar dan sudah ada dalam cache.output_schema: Menentukan struktur JSON yang diharapkan dari respons model.endpoint: Menentukan endpoint model AI Platform Agen (Gemini 2.5 Flash dalam kasus ini) yang digunakan untuk pembuatan.model_params: Parameter penting yang meneruskan Cache ID yang dibuat menggunakan kolomcachedContent.
Anda akan melihat hasil yang dibuat untuk menganalisis setiap permintaan pengembalian dana sesuai dengan kebijakan yang disimpan. Scroll ke kanan untuk melihat metrik token yang diekstrak.
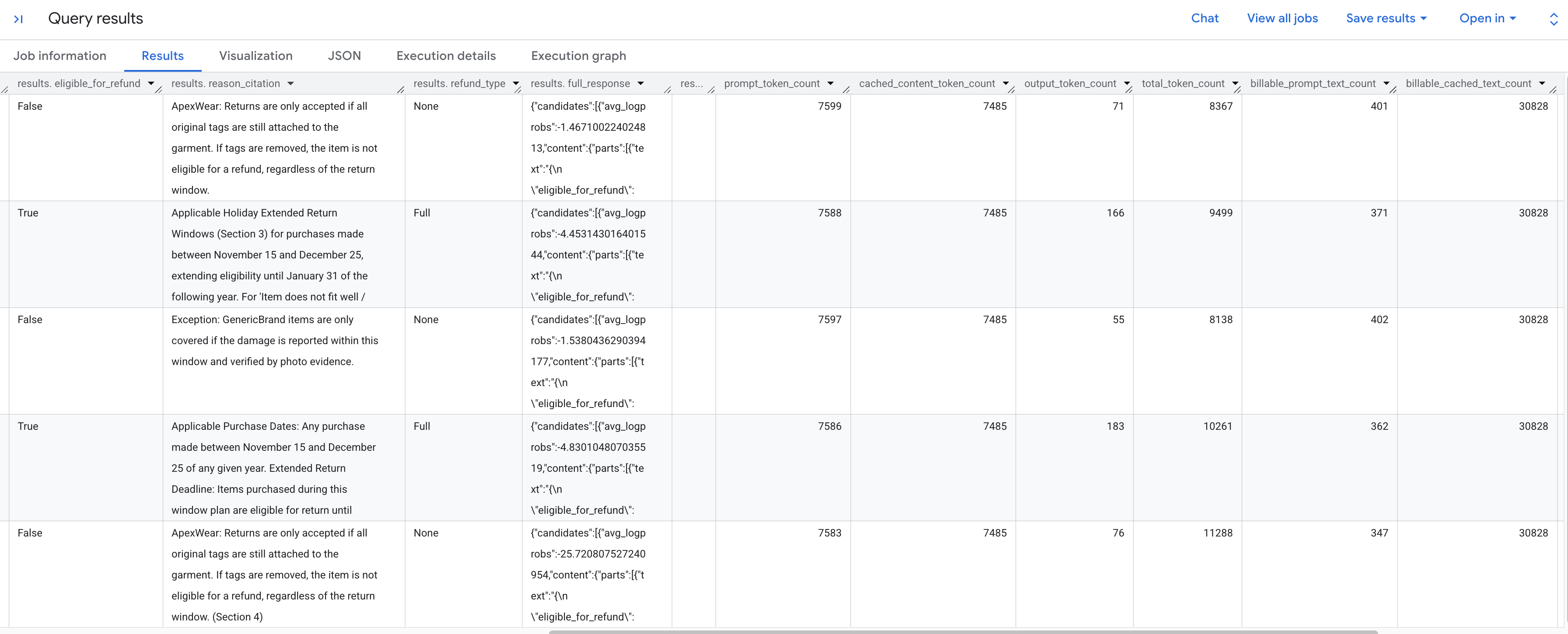
Berikut perincian metrik token yang Anda lihat:
prompt_token_count: Jumlah total token yang diproses dalam perintah input (termasuk konten yang di-cache).cached_content_token_count: Jumlah token yang ditayangkan dari cache (yang mewakili dokumen Kebijakan Pengembalian statis).output_token_count: Jumlah token yang dihasilkan oleh model dalam respons.total_token_count: Jumlah token perintah dan output.billable_prompt_text_count: Jumlah karakter yang dapat ditagih di bagian perintah yang tidak di-cache.billable_cached_text_count: Jumlah karakter yang dapat ditagih dalam konten yang di-cache.
Lihat kolom billable_prompt_text_count —kolom ini hanya menampilkan beberapa ratus karakter per baris, yang hanya merupakan permintaan spesifik pelanggan. Bandingkan dengan billable_cached_text_count yang berisi lebih dari 30.000 karakter untuk Kebijakan Pengembalian lengkap. Tanpa caching konteks, Anda akan membayar untuk memproses dokumen kebijakan lengkap tersebut untuk setiap baris. Dengan melakukan caching, Anda hanya membayar untuk dokumen besar tersebut satu kali, dan baris berikutnya hanya akan menagih Anda untuk teks perintah kecil yang berubah.
Hal ini akan menghasilkan penghematan besar untuk tugas batch.
6. Pembersihan
Untuk menghindari biaya berkelanjutan ke akun Google Cloud Anda, hapus resource yang dibuat selama codelab ini.
Jalankan perintah berikut di Cloud Shell untuk menghapus set data BigQuery dan tabelnya:
bq rm -r -f -d caching_demo
Hapus bucket staging yang dibuat untuk dokumen kebijakan:
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
Terakhir, hapus cache konteks untuk menghindari biaya penyimpanan berkelanjutan menggunakan variabel yang Anda simpan sebelumnya:
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. Selamat
Selamat! Anda telah berhasil membuat cache konteks di Platform Agen dan mereferensikannya dalam fungsi AI BigQuery untuk mempercepat analisis sekaligus mengurangi biaya pemrosesan token input.
Yang telah Anda pelajari
- Cara menyiapkan tabel lingkungan untuk analisis permintaan pengembalian dana.
- Cara memanggil Agent Platform (Vertex AI) API menggunakan
curluntuk membuat cache konteks dokumen statis secara eksplisit. - Cara menggunakan Cache ID yang dibuat dalam kueri SQL
AI.GENERATEuntuk menghilangkan token input yang berlebihan di seluruh perintah aktif.