
1. Introduzione
Le funzioni di AI generativa di BigQuery consentono di utilizzare SQL per ragionare sui dati utilizzando modelli linguistici di grandi dimensioni (LLM). Puoi analizzare il sentiment, generare riepiloghi e aggiungere didascalie alle immagini in milioni di righe senza spostare i dati.
Ma cosa succede se il prompt ha bisogno di una grande quantità di contesto (come norme, manuali o un video) per ottenere risultati accurati e affidabili?
La memorizzazione nella cache del contesto di Gemini risolve questo problema memorizzando il contesto di grandi dimensioni in una cache. I prompt successivi fanno riferimento alla cache anziché elaborare ogni volta l'intero contenuto, offrendo una latenza inferiore e uno sconto fino al 90% sui token di input.
In questo codelab creerai un controllo delle norme sui resi "Scritta in piccolo" che utilizza la memorizzazione nella cache del contesto esplicito per analizzare le richieste di reso dei clienti rispetto a un documento statico e di grandi dimensioni delle norme sui resi in BigQuery.

In questo lab proverai a:
- Crea un set di dati BigQuery e compilalo con richieste di reso dei clienti di esempio.
- Crea una cache contestuale in Gemini Enterprise Agent Platform (precedentemente nota come Vertex AI) che rimandi a un documento di norme sui resi archiviato in Cloud Storage.
- Esegui una query utilizzando
AI.GENERATEche fa riferimento alla cache per valutare in modo efficiente le richieste riga per riga.
Che cosa ti serve
- Un browser web come Chrome
- Un progetto cloud Google Cloud con la fatturazione abilitata
- Accesso a Google Cloud Shell
Questo codelab è rivolto a sviluppatori di tutti i livelli, inclusi i principianti.
Le risorse create in questo codelab dovrebbero costare meno di 2 $.
Durata stimata:il completamento di questo codelab richiede circa 30 minuti.
2. Prima di iniziare
Crea un progetto Google Cloud
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Avvia Cloud Shell
Cloud Shell è un ambiente a riga di comando in esecuzione in Google Cloud che viene precaricato con gli strumenti necessari.
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta connesso a Cloud Shell, verifica l'autenticazione:
gcloud auth list - Verifica che il progetto sia configurato:
gcloud config get project - Se il progetto non è impostato come previsto, impostalo:
gcloud config set project <YOUR_PROJECT_ID>
Imposta l'ID progetto e la località
Esegui questo comando per recuperare l'ID progetto Google Cloud attivo e impostare la località predefinita come variabili di ambiente da utilizzare in questo codelab:
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
Abilita API
Esegui questo comando per abilitare le API richieste:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. Prepara i dati BigQuery
Prima di poter testare la memorizzazione nella cache del contesto, abbiamo bisogno di un set di dati e di una tabella compilata con richieste di reso dei clienti di esempio su cui eseguire le query.
1. Crea un set di dati
Esegui il comando seguente in Cloud Shell per creare un set di dati BigQuery denominato caching_demo:
bq mk --dataset $PROJECT_ID:caching_demo
2. Creare e compilare la tabella
Esegui questo comando per creare una tabella denominata return_requests e inserire richieste di reso dei clienti di esempio:
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
Dovresti visualizzare un messaggio che conferma la riuscita dell'operazione:
Created your-project-id.caching_demo.return_requests
Ora siamo pronti per creare la cache.
4. Crea la cache del contesto
Creerai la cache utilizzando una chiamata REST all'endpoint del modello Gemini Enterprise Agent Platform (in precedenza Vertex AI) utilizzando curl.
Esegui questo comando in Cloud Shell per creare un nuovo bucket di archiviazione. Verrà utilizzato per archiviare i file che vogliamo memorizzare nella cache:
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
Successivamente, copia il documento di policy di esempio nel bucket appena creato:
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
Ora esegui questo comando per creare la cache che fa riferimento al documento della policy appena preparato (il completamento dell'operazione potrebbe richiedere circa un minuto):
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
Prendi nota di name restituito nella risposta JSON, che avrà questo aspetto: projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID. Ti servirà CACHE_ID per il passaggio successivo.
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
Salva CACHE_ID come variabile di ambiente in Cloud Shell:
export CACHE_ID="<YOUR_CACHE_ID>"
5. Esegui AI.GENERATE con i contenuti memorizzati nella cache
Innanzitutto, verifichiamo che i dati di esempio siano stati generati correttamente. Vai alla console BigQuery, individua il set di dati caching_demo e fai clic sulla tabella return_requests.
Nella scheda Anteprima, dovresti visualizzare le richieste di reso dei clienti che abbiamo generato in precedenza:
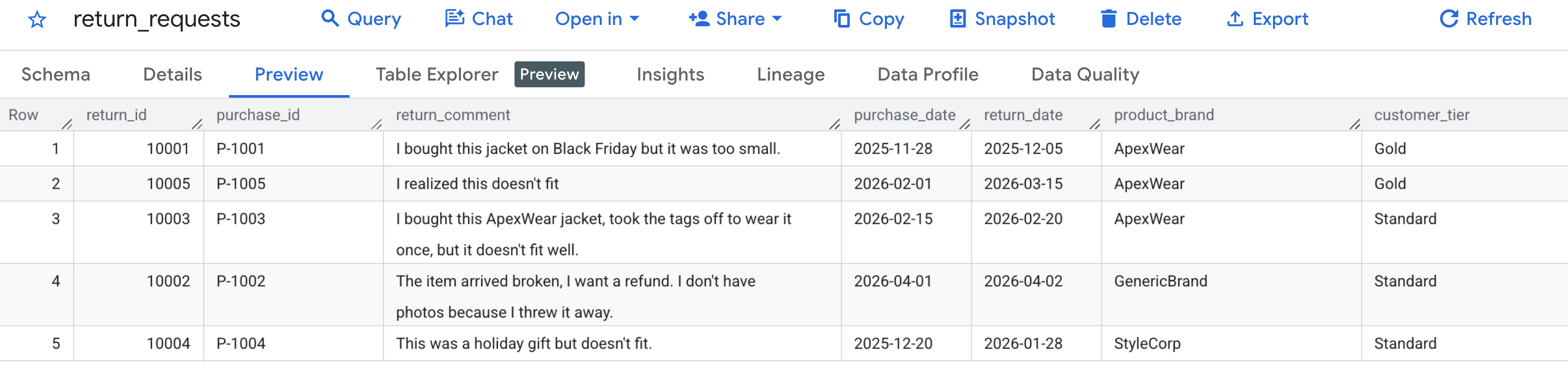
Ora che la cache è stata creata e compilata, puoi eseguire query utilizzando AI.GENERATE per valutare la richiesta di rimborso semplicemente facendo riferimento all'ID cache.
Per evitare di trovare e sostituire manualmente le variabili, esegui questo comando in Cloud Shell. In questo modo, la query SQL verrà creata dinamicamente utilizzando le variabili di ambiente esistenti e verrà stampata sullo schermo in modo che tu possa copiarla facilmente.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
Ora, copia l'SQL nel terminale, vai alla console BigQuery nel browser ed esegui la query nella scheda dell'editor di query.
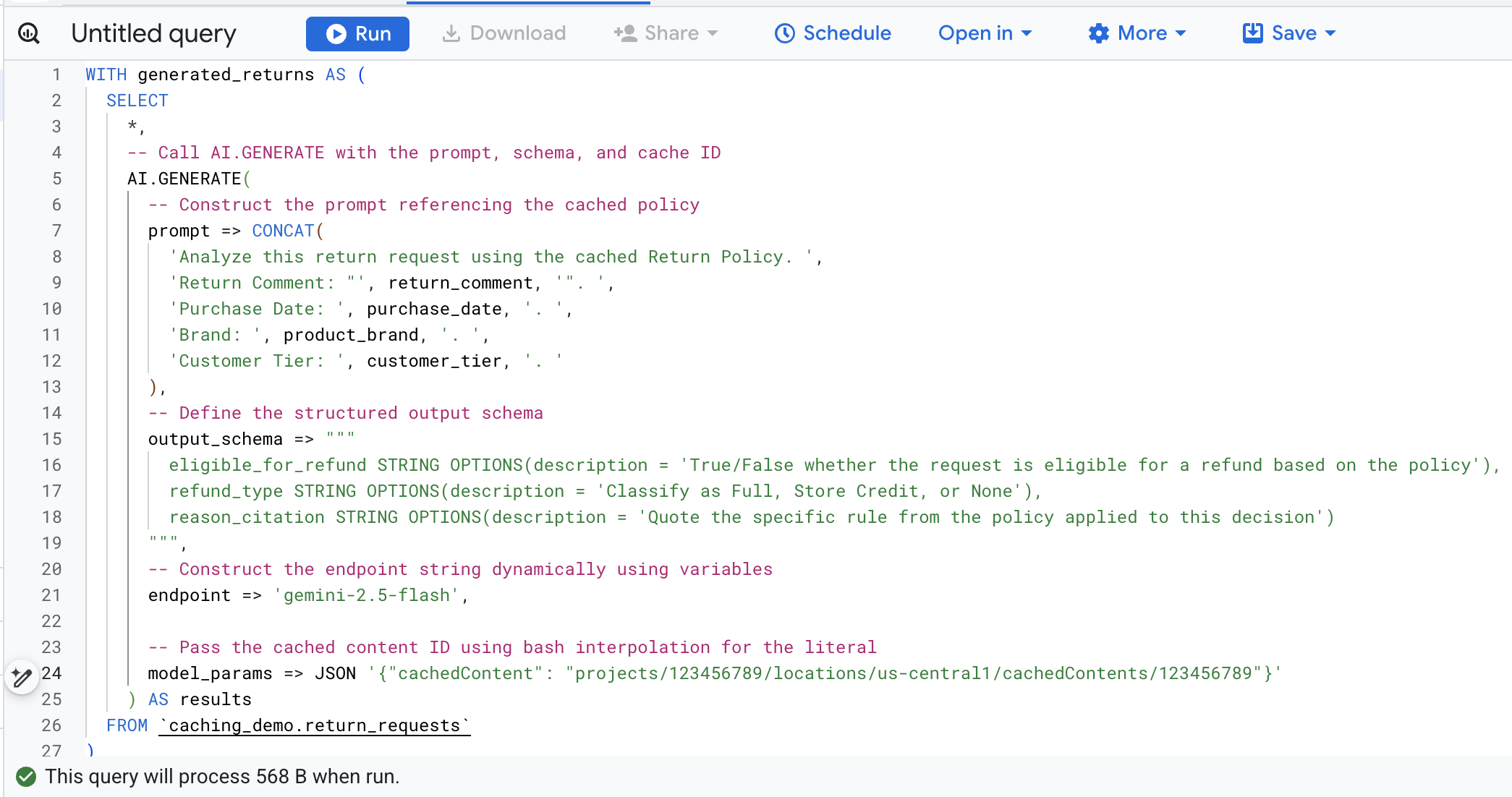
Ecco una suddivisione degli argomenti principali in questa chiamata di funzione:
prompt: contiene le informazioni specifiche per ogni riga del cliente. Questo testo viene effettivamente aggiunto al documento di grandi dimensioni Norme sui resi già presente nella cache.output_schema: definisce la struttura JSON prevista della risposta del modello.endpoint: specifica l'endpoint del modello di AI della piattaforma dell'agente (Gemini 2.5 Flash nel nostro caso) utilizzato per la generazione.model_params: parametro fondamentale che trasmette l'ID cache generato utilizzando il campocachedContent.
Dovresti visualizzare i risultati generati che analizzano ogni richiesta di reso in base alle norme memorizzate. Scorri verso destra per visualizzare le metriche dei token estratti.
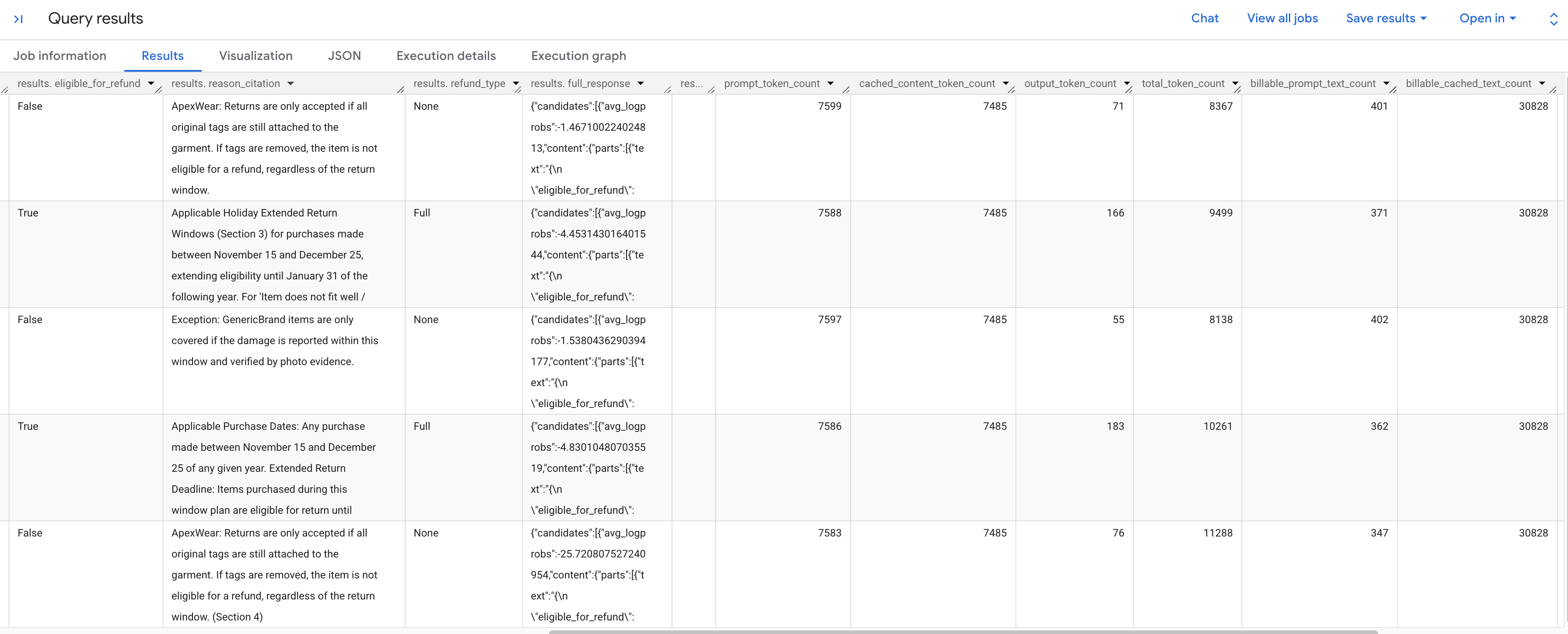
Ecco una suddivisione delle metriche dei token che visualizzi:
prompt_token_count: il numero totale di token elaborati nel prompt di input (incluso il contenuto memorizzato nella cache).cached_content_token_count: il numero di token pubblicati dalla cache (che rappresenta il documento statico Norme sui resi).output_token_count: il numero di token generati dal modello nella risposta.total_token_count: la somma dei token di prompt e di output.billable_prompt_text_count: il numero di caratteri fatturabili nella parte non memorizzata nella cache del prompt.billable_cached_text_count: il numero di caratteri fatturabili nel contenuto memorizzato nella cache.
Guarda la colonna billable_prompt_text_count: mostra solo poche centinaia di caratteri per riga, ovvero solo la richiesta specifica del cliente. Il billable_cached_text_count di oltre 30.000 caratteri per le Norme sui resi complete è un altro discorso. Senza la memorizzazione nella cache del contesto, pagheresti l'elaborazione dell'intero documento delle norme per ogni singola riga. Memorizzando nella cache, paghi il documento di grandi dimensioni una sola volta e le righe successive ti addebitano solo il testo del prompt piccolo e variabile.
Ciò si traduce in un enorme risparmio per i job batch.
6. Esegui la pulizia
Per evitare addebiti continui al tuo account Google Cloud, elimina le risorse create durante questo codelab.
Esegui il seguente comando in Cloud Shell per eliminare il set di dati BigQuery e le relative tabelle:
bq rm -r -f -d caching_demo
Elimina il bucket di staging creato per il documento della policy:
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
Infine, elimina la cache del contesto per evitare addebiti continui per lo spazio di archiviazione utilizzando le variabili che hai memorizzato in precedenza:
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. Complimenti
Complimenti! Hai creato correttamente una cache contestuale in Agent Platform e l'hai utilizzata come riferimento in una funzione AI di BigQuery per velocizzare l'analisi e ridurre i costi di elaborazione dei token di input.
Cosa hai imparato
- Come configurare le tabelle dell'ambiente per l'analisi delle richieste di reso.
- Come chiamare l'API Agent Platform (Vertex AI) utilizzando
curlper creare esplicitamente una cache del contesto del documento statico. - Come utilizzare l'ID cache generato in una query SQL
AI.GENERATEper eliminare i token di input ridondanti nei prompt attivi.