
1. はじめに
BigQuery の生成 AI 関数を使用すると、SQL を使用して大規模言語モデル(LLM)でデータを推論できます。データを移動することなく、数百万行の感情分析、要約の生成、画像のキャプション作成を行うことができます。
ただし、正確で信頼性の高い結果を得るために、プロンプトに大量のコンテキスト(ポリシー、マニュアル、動画など)が必要な場合はどうすればよいでしょうか?
Gemini コンテキスト キャッシュは、この問題を解決するために、大きなコンテキストをキャッシュに保存します。後続のプロンプトは、毎回コンテンツ全体を処理するのではなく、キャッシュを参照するため、レイテンシが短縮され、入力トークンの費用が最大 90% 削減されます。
この Codelab では、明示的なコンテキスト キャッシュを使用して、BigQuery の大規模な静的返品に関するポリシー ドキュメントに対して顧客の返品リクエストを分析する「Fine Print」返品に関するポリシー チェッカーを構築します。

演習内容
- BigQuery データセットを作成し、顧客返品リクエストのサンプルを入力します。
- Gemini Enterprise Agent Platform(旧称 Vertex AI)で、Cloud Storage に保存されている返品に関するポリシー ドキュメントを指すコンテキスト キャッシュを作成します。
AI.GENERATEを使用してクエリを実行し、キャッシュを参照してリクエストを効率的に行単位で評価します。
必要なもの
- ウェブブラウザ(Chrome など)
- 課金を有効にした Google Cloud プロジェクト
- Google Cloud Shell へのアクセス
この Codelab は、初心者を含むあらゆるレベルのデベロッパーを対象としています。
この Codelab で作成するリソースの費用は 2 ドル未満です。
所要時間: この Codelab の所要時間はおよそ 30 分です。
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト セレクタ ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] アイコンをクリックします。

- Cloud Shell に接続したら、認証を確認します。
gcloud auth list - プロジェクトが構成されていることを確認します。
gcloud config get project - プロジェクトが想定どおりに設定されていない場合は、設定します。
gcloud config set project <YOUR_PROJECT_ID>
プロジェクト ID とロケーションを設定する
次のコマンドを実行して、アクティブな Google Cloud プロジェクト ID を取得し、この Codelab 全体で使用する環境変数としてデフォルトの場所を設定します。
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
API を有効にする
次のコマンドを実行して、必要な API を有効にします。
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. BigQuery データを準備する
コンテキスト キャッシュをテストする前に、クエリの実行対象となるサンプル顧客返品リクエストが入力されたデータセットとテーブルが必要です。
1. データセットを作成する
Cloud Shell で次のコマンドを実行して、caching_demo という名前の BigQuery データセットを作成します。
bq mk --dataset $PROJECT_ID:caching_demo
2. テーブルを作成してデータを入力する
次のコマンドを実行して、return_requests という名前のテーブルを作成し、顧客返品リクエストのサンプルを挿入します。
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
成功メッセージが表示されます。
Created your-project-id.caching_demo.return_requests
これで、キャッシュを作成する準備が整いました。
4. コンテキスト キャッシュを作成する
curl を使用して Gemini Enterprise Agent Platform(旧称 Vertex AI)モデル エンドポイントに REST 呼び出しを行い、キャッシュを作成します。
Cloud Shell で次のコマンドを実行して、新しいストレージ バケットを作成します。これは、キャッシュに保存するファイルを保存するために使用されます。
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
次に、新しく作成したバケットにサンプル ポリシー ドキュメントをコピーします。
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
次のコマンドを実行して、新しくステージングしたポリシー ドキュメントを参照するキャッシュを作成します(完了するまでに 1 分ほどかかることがあります)。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
レスポンスの JSON で返された name(projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID のような形式)をメモします。この CACHE_ID は次のステップで必要になります。
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
Cloud Shell で CACHE_ID を環境変数として保存します。
export CACHE_ID="<YOUR_CACHE_ID>"
5. キャッシュに保存されたコンテンツで AI.GENERATE を実行する
まず、サンプルデータが正しく生成されたことを確認します。BigQuery コンソールに移動し、caching_demo データセットを見つけて、return_requests テーブルをクリックします。
[プレビュー] タブに、先ほど生成したお客様の返品リクエストが表示されます。
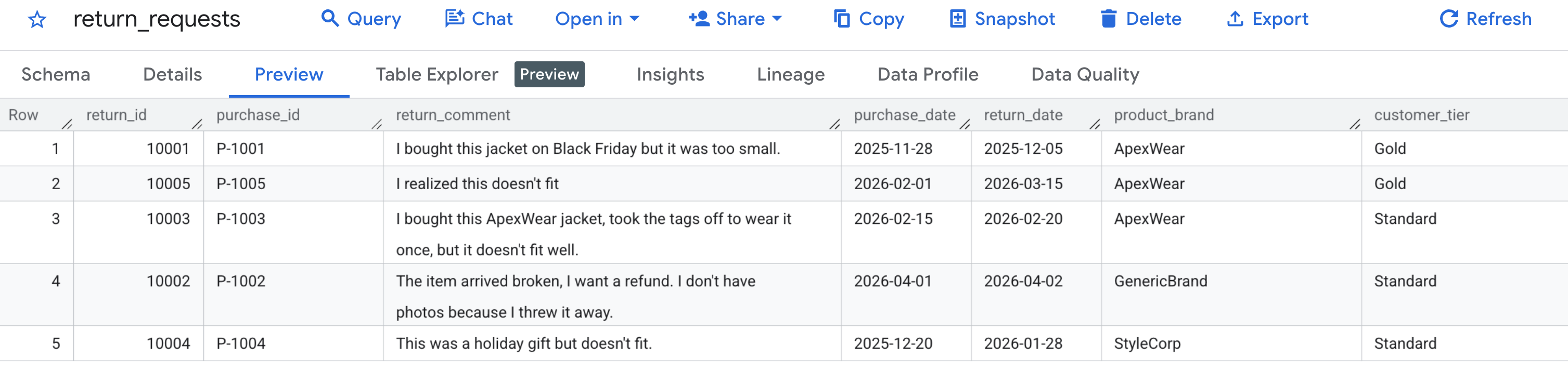
キャッシュが作成され、データが入力されたので、AI.GENERATE を使用してクエリを実行し、キャッシュ ID を参照するだけで払い戻しリクエストを評価できます。
変数を手動で検索して置き換えることを避けるため、Cloud Shell で次のコマンドを実行します。これにより、既存の環境変数を使用して SQL クエリが動的に構築され、画面に出力されるため、簡単にコピーできます。
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
次に、ターミナルの SQL をコピーし、ブラウザで BigQuery コンソールに移動して、クエリエディタ タブでクエリを実行します。
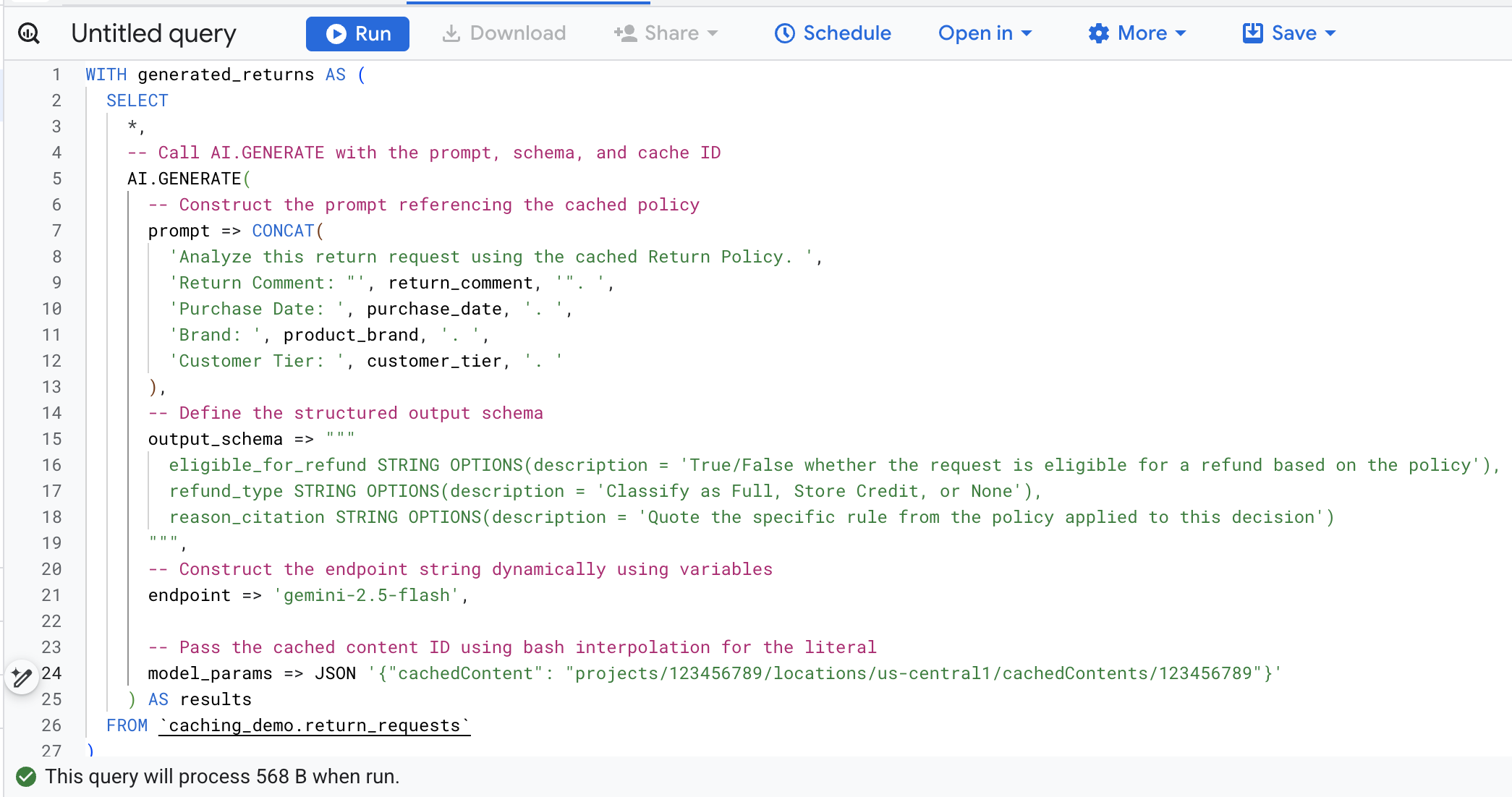
この関数呼び出しの主な引数は次のとおりです。
prompt: 各顧客行の固有の情報が含まれます。このテキストは、キャッシュにすでに存在する大きな返品ポリシーのドキュメントに効果的に追加されます。output_schema: モデルのレスポンスの想定される JSON 構造を定義します。endpoint: 生成に使用される Agent Platform AI モデル エンドポイント(この場合は Gemini 2.5 Flash)を指定します。model_params:cachedContentフィールドを使用して生成されたキャッシュ ID を渡す重要なパラメータ。
保存されたポリシーに従って各返品リクエストを分析した結果が表示されます。右にスクロールして、抽出されたトークン指標を表示します。
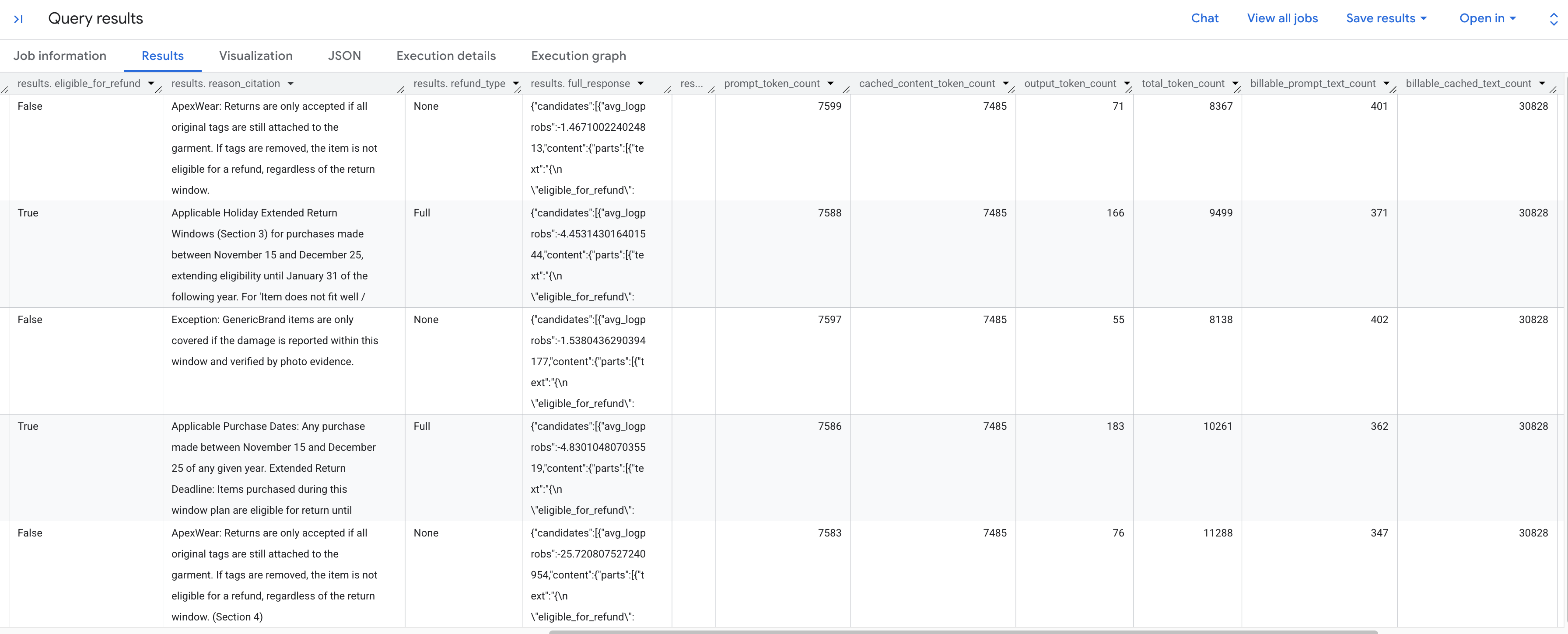
表示されるトークン指標の内訳は次のとおりです。
prompt_token_count: 入力プロンプトで処理されたトークンの合計数(キャッシュに保存されたコンテンツを含む)。cached_content_token_count: キャッシュから提供されたトークンの数(静的な返品ポリシー ドキュメントを表します)。output_token_count: レスポンスでモデルによって生成されたトークンの数。total_token_count: プロンプト トークンと出力トークンの合計。billable_prompt_text_count: プロンプトのキャッシュに保存されていない部分の課金対象文字数。billable_cached_text_count: キャッシュに保存されたコンテンツの課金対象文字数。
billable_prompt_text_count 列を見ると、各行に数百文字しか表示されていません。これは、お客様の具体的なリクエストのみです。返品ポリシー全体の 30,000 文字を超える billable_cached_text_count と比較してください。コンテキスト キャッシュがない場合、すべての行に対してポリシー ドキュメント全体を処理する費用が発生します。キャッシュに保存することで、大きなドキュメントの料金は 1 回のみで、後続の行では小さな変更されたプロンプト テキストの料金のみが請求されます。
これにより、バッチジョブの費用を大幅に削減できます。
6. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、この Codelab で作成したリソースを削除します。
Cloud Shell で次のコマンドを実行して、BigQuery データセットとそのテーブルを削除します。
bq rm -r -f -d caching_demo
ポリシー ドキュメント用に作成したステージング バケットを削除します。
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
最後に、以前に保存した変数を使用して、継続的なストレージ料金が発生しないようにコンテキスト キャッシュを削除します。
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. 完了
おめでとうございます!Agent Platform でコンテキスト キャッシュを作成し、BigQuery AI 関数で参照して、入力トークンの処理コストを削減しながら分析を高速化しました。
学習した内容
- 返品リクエストの分析用に環境テーブルを設定する方法。
curlを使用して Agent Platform(Vertex AI)API を呼び出し、静的ドキュメント コンテキスト キャッシュを明示的に作成する方法。- 生成されたキャッシュ ID を
AI.GENERATESQL クエリで使用して、アクティブなプロンプト間で冗長な入力トークンを排除する方法。