
1. 소개
BigQuery의 생성형 AI 함수를 사용하면 SQL을 사용하여 대규모 언어 모델 (LLM)을 통해 데이터에 대해 추론할 수 있습니다. 데이터를 이동하지 않고도 수백만 개의 행에 걸쳐 감정을 분석하고, 요약을 생성하고, 이미지에 캡션을 추가할 수 있습니다.
하지만 정확하고 신뢰할 수 있는 결과를 얻기 위해 프롬프트에 정책, 매뉴얼, 동영상과 같은 방대한 양의 컨텍스트가 필요한 경우에는 어떻게 해야 할까요?
Gemini 컨텍스트 캐싱은 이러한 대규모 컨텍스트를 캐시에 저장하여 이 문제를 해결합니다. 후속 프롬프트는 매번 전체 콘텐츠를 처리하는 대신 캐시를 참조하여 지연 시간을 줄이고 입력 토큰에 최대 90% 할인을 제공합니다.
이 Codelab에서는 명시적 컨텍스트 캐싱을 사용하여 BigQuery의 대규모 정적 반품 정책 문서에 대해 고객 반품 요청을 분석하는 '세부사항' 반품 정책 검사기를 빌드합니다.

실습할 내용
- BigQuery 데이터 세트를 만들고 샘플 고객 반품 요청으로 채웁니다.
- Cloud Storage에 저장된 반품 정책 문서를 가리키는 Gemini Enterprise Agent Platform (이전 명칭: Vertex AI)에서 컨텍스트 캐시를 만듭니다.
- 캐시를 참조하는
AI.GENERATE를 사용하여 쿼리를 실행하여 행별로 요청을 효율적으로 평가합니다.
필요한 항목
- 웹브라우저(예: Chrome)
- 결제가 사용 설정된 Google Cloud 프로젝트
- Google Cloud Shell 액세스
이 Codelab은 초보자를 포함한 모든 수준의 개발자를 대상으로 합니다.
이 Codelab에서 만든 리소스의 비용은 2달러 미만이어야 합니다.
예상 소요 시간: 이 Codelab을 완료하는 데 약 30분이 소요됩니다.
2. 시작하기 전에
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell 시작
Cloud Shell은 Google Cloud에서 실행되는 명령줄 환경으로, 필요한 도구가 미리 로드되어 제공됩니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 인증을 확인합니다.
gcloud auth list - 프로젝트가 구성되어 있는지 확인합니다.
gcloud config get project - 프로젝트가 예상대로 설정되지 않은 경우 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
프로젝트 ID 및 위치 설정
다음 명령어를 실행하여 활성 Google Cloud 프로젝트 ID를 가져오고 기본 위치를 설정하여 이 Codelab 전체에서 사용할 환경 변수로 설정합니다.
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
API 사용 설정
이 명령어를 실행하여 필요한 API를 사용 설정합니다.
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. BigQuery 데이터 준비
컨텍스트 캐싱을 테스트하려면 쿼리를 실행할 데이터 세트와 샘플 고객 반품 요청으로 채워진 테이블이 필요합니다.
1. 데이터 세트 만들기
Cloud Shell에서 다음 명령어를 실행하여 caching_demo라는 BigQuery 데이터 세트를 만듭니다.
bq mk --dataset $PROJECT_ID:caching_demo
2. 테이블 만들기 및 채우기
다음 명령어를 실행하여 return_requests라는 이름의 테이블을 만들고 샘플 고객 반품 요청을 삽입합니다.
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
다음과 같은 성공 메시지가 표시됩니다.
Created your-project-id.caching_demo.return_requests
이제 캐시를 만들 준비가 되었습니다.
4. 컨텍스트 캐시 만들기
curl를 사용하여 Gemini Enterprise 에이전트 플랫폼 (이전 명칭: Vertex AI) 모델 엔드포인트에 대한 REST 호출을 사용하여 캐시를 만듭니다.
Cloud Shell에서 다음 명령어를 실행하여 새 스토리지 버킷을 만듭니다. 이는 캐시할 파일을 저장하는 데 사용됩니다.
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
다음으로 새로 만든 버킷에 샘플 정책 문서를 복사합니다.
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
이제 다음 명령어를 실행하여 새로 스테이징된 정책 문서를 참조하는 캐시를 만듭니다 (완료하는 데 1분 정도 걸릴 수 있음).
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
응답 JSON에 반환된 name를 확인합니다. projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID와 비슷합니다. 다음 단계에서 이 CACHE_ID이 필요합니다.
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
Cloud Shell에서 CACHE_ID를 환경 변수로 저장합니다.
export CACHE_ID="<YOUR_CACHE_ID>"
5. 캐시된 콘텐츠로 AI.GENERATE 실행
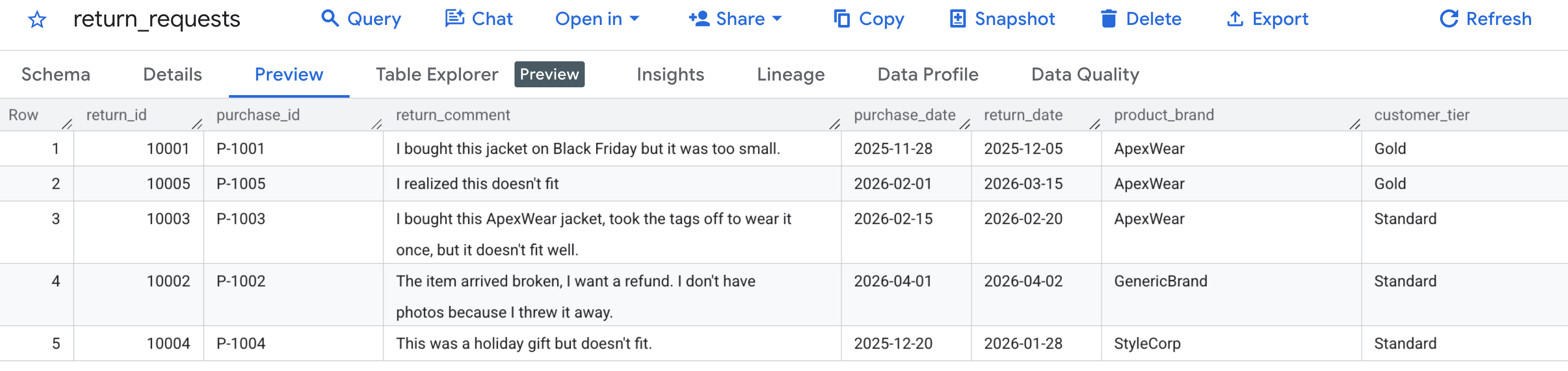
먼저 샘플 데이터가 올바르게 생성되었는지 확인해 보겠습니다. BigQuery 콘솔로 이동하여 caching_demo 데이터 세트를 찾고 return_requests 테이블을 클릭합니다.
미리보기 탭에 이전에 생성한 고객 반품 요청이 표시됩니다.
이제 캐시가 생성되고 채워졌으므로 AI.GENERATE를 사용하여 해당 캐시 ID를 참조하는 것만으로 환불 요청을 평가할 수 있습니다.
변수를 수동으로 찾아 바꾸지 않으려면 Cloud Shell에서 다음 명령어를 실행하세요. 그러면 기존 환경 변수를 사용하여 SQL 쿼리가 동적으로 빌드되고 화면에 출력되므로 쉽게 복사할 수 있습니다.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
이제 터미널에서 SQL을 복사하고 브라우저에서 BigQuery 콘솔로 이동하여 쿼리 편집기 탭에서 쿼리를 실행합니다.
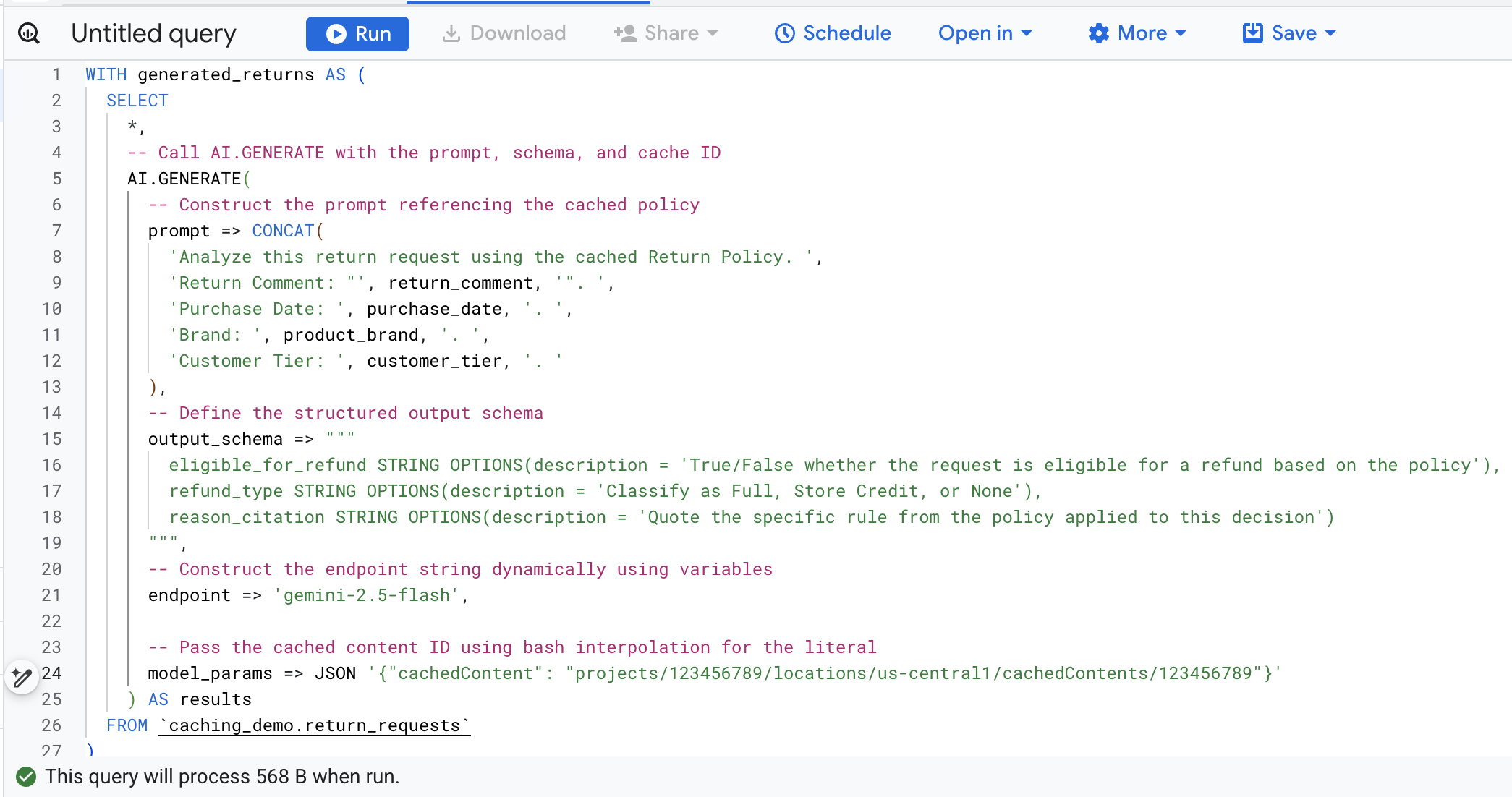
이 함수 호출의 주요 인수는 다음과 같습니다.
prompt: 각 고객 행의 구체적인 정보를 포함합니다. 이 텍스트는 캐시에 이미 있는 대규모 반품 정책 문서에 효과적으로 추가됩니다.output_schema: 모델의 응답에 예상되는 JSON 구조를 정의합니다.endpoint: 생성에 사용되는 에이전트 플랫폼 AI 모델 엔드포인트 (이 경우 Gemini 2.5 Flash)를 지정합니다.model_params:cachedContent필드를 사용하여 생성된 캐시 ID를 전달하는 중요한 매개변수입니다.
저장된 정책에 따라 각 반품 요청을 분석한 결과가 표시됩니다. 오른쪽으로 스크롤하여 추출된 토큰 측정항목을 확인합니다.
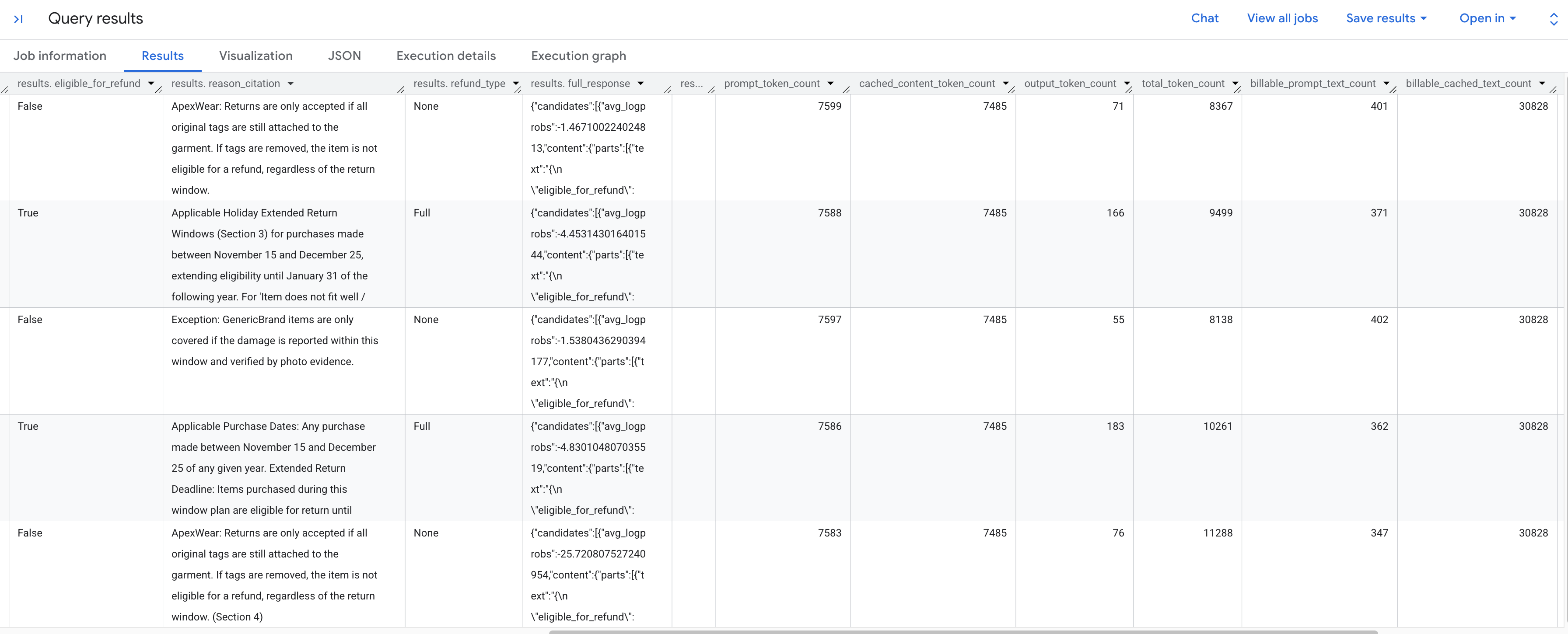
표시되는 토큰 측정항목은 다음과 같습니다.
prompt_token_count: 입력 프롬프트에서 처리된 총 토큰 수 (캐시된 콘텐츠 포함)입니다.cached_content_token_count: 캐시에서 제공된 토큰 수 (정적 반품 정책 문서를 나타냄)output_token_count: 모델에서 응답에 생성한 토큰 수입니다.total_token_count: 프롬프트 및 출력 토큰의 합계입니다.billable_prompt_text_count: 캐시되지 않은 프롬프트 부분의 청구 가능한 문자 수입니다.billable_cached_text_count: 캐시된 콘텐츠의 청구 가능한 문자 수입니다.
billable_prompt_text_count 열을 살펴보세요. 행당 수백 자만 표시되며 이는 고객의 구체적인 요청일 뿐입니다. 전체 반품 정책의 billable_cached_text_count은 30,000자를 초과합니다. 컨텍스트 캐싱이 없으면 모든 단일 행에 대해 전체 정책 문서를 처리하는 비용을 지불해야 합니다. 캐싱하면 대규모 문서에 대해 한 번만 비용을 지불하고 이후 행에서는 변경되는 작은 프롬프트 텍스트에 대해서만 비용이 청구됩니다.
따라서 일괄 작업의 비용을 대폭 절감할 수 있습니다.
6. 삭제
Google Cloud 계정에 지속적으로 비용이 청구되지 않도록 하려면 이 Codelab 중에 만든 리소스를 삭제하세요.
Cloud Shell에서 다음 명령어를 실행하여 BigQuery 데이터 세트와 테이블을 삭제합니다.
bq rm -r -f -d caching_demo
정책 문서용으로 생성된 스테이징 버킷을 삭제합니다.
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
마지막으로 이전에 저장한 변수를 사용하여 지속적인 스토리지 요금이 청구되지 않도록 컨텍스트 캐시를 삭제합니다.
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. 축하합니다
축하합니다. Agent Platform에서 컨텍스트 캐시를 만들고 BigQuery AI 함수에서 이를 참조하여 분석 속도를 높이는 동시에 입력 토큰 처리 비용을 절감했습니다.
학습한 내용
- 반품 요청 분석을 위한 환경 테이블을 설정하는 방법
curl를 사용하여 에이전트 플랫폼 (Vertex AI) API를 호출하여 정적 문서 컨텍스트 캐시를 명시적으로 만드는 방법- 생성된 캐시 ID를
AI.GENERATESQL 쿼리에서 사용하여 활성 프롬프트 전반에서 중복 입력 토큰을 삭제하는 방법