
1. Wprowadzenie
Funkcje generatywnej AI w BigQuery umożliwiają używanie SQL do analizowania danych za pomocą dużych modeli językowych (LLM). Możesz analizować nastrój, generować podsumowania i dodawać podpisy do obrazów w milionach wierszy bez przenoszenia danych.
Co jednak zrobić, jeśli prompt wymaga ogromnej ilości kontekstu (np. zasad, instrukcji lub filmu), aby uzyskać dokładne i wiarygodne wyniki?
Pamięć podręczna kontekstu Gemini rozwiązuje ten problem, przechowując duży kontekst w pamięci podręcznej. Kolejne prompty odwołują się do pamięci podręcznej zamiast za każdym razem przetwarzać całą treść, co zapewnia mniejsze opóźnienia i 90% rabatu na tokeny wejściowe.
W tym module dowiesz się, jak utworzyć narzędzie do sprawdzania zasad zwrotów „Fine Print”, które wykorzystuje jawne buforowanie kontekstu do analizowania próśb klientów o zwrot w odniesieniu do obszernego, statycznego dokumentu zasad zwrotów w BigQuery.

Jakie zadania wykonasz
- Utwórz zbiór danych BigQuery i wypełnij go przykładowymi żądaniami zwrotu produktów przez klientów.
- Utwórz pamięć podręczną kontekstu na platformie Gemini Enterprise Agent Platform (wcześniej Vertex AI), która będzie wskazywać dokument zasad zwrotów przechowywany w Cloud Storage.
- Uruchom zapytanie z użyciem funkcji
AI.GENERATE, która odwołuje się do pamięci podręcznej, aby skutecznie oceniać żądania wiersz po wierszu.
Czego potrzebujesz
- przeglądarka, np. Chrome;
- projekt Google Cloud z włączonymi płatnościami;
- Dostęp do Google Cloud Shell
To ćwiczenie jest przeznaczone dla deweloperów na wszystkich poziomach zaawansowania, w tym dla początkujących.
Zasoby utworzone w tym module powinny kosztować mniej niż 2 PLN.
Szacowany czas trwania: ukończenie tego codelabu zajmie około 30 minut.
2. Zanim zaczniesz
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchamianie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera niezbędne narzędzia.
- U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź uwierzytelnianie:
gcloud auth list - Sprawdź, czy projekt jest skonfigurowany:
gcloud config get project - Jeśli projekt nie jest ustawiony zgodnie z oczekiwaniami, ustaw go:
gcloud config set project <YOUR_PROJECT_ID>
Ustawianie identyfikatora projektu i lokalizacji
Uruchom to polecenie, aby pobrać aktywny identyfikator projektu Google Cloud i ustawić domyślną lokalizację jako zmienne środowiskowe, których będziesz używać podczas naszych ćwiczeń z programowania:
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
Włącz interfejsy API
Aby włączyć wymagane interfejsy API, uruchom to polecenie:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. Przygotowywanie danych BigQuery
Zanim będziemy mogli przetestować buforowanie kontekstu, potrzebujemy zbioru danych i tabeli wypełnionej przykładowymi żądaniami zwrotu od klientów, na których będziemy uruchamiać zapytania.
1. Tworzenie zbioru danych
Aby utworzyć zbiór danych BigQuery o nazwie caching_demo, uruchom w Cloud Shell to polecenie:
bq mk --dataset $PROJECT_ID:caching_demo
2. Tworzenie i wypełnianie tabeli
Uruchom to polecenie, aby utworzyć tabelę o nazwiereturn_requests i wstawić przykładowe prośby o zwrot produktów:
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
Powinien wyświetlić się komunikat o powodzeniu:
Created your-project-id.caching_demo.return_requests
Możemy teraz utworzyć pamięć podręczną.
4. Tworzenie pamięci podręcznej kontekstu
Pamięć podręczną utworzysz za pomocą wywołania REST do punktu końcowego modelu Gemini Enterprise Agent Platform (wcześniej Vertex AI) przy użyciu curl.
Uruchom w Cloud Shell to polecenie, aby utworzyć nowy zasobnik pamięci. Będzie on używany do przechowywania plików, które chcemy zapisać w pamięci podręcznej:
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
Następnie skopiuj przykładowy dokument z zasadami do nowo utworzonego zasobnika:
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
Teraz uruchom to polecenie, aby utworzyć pamięć podręczną odwołującą się do nowo przygotowanego dokumentu zasad (może to potrwać około minuty):
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
Zwróć uwagę na wartość name zwróconą w odpowiedzi JSON, która będzie wyglądać tak: projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID. Będzie on potrzebny w następnym kroku.CACHE_ID
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
Zapisz identyfikator CACHE_ID jako zmienną środowiskową w Cloud Shell:
export CACHE_ID="<YOUR_CACHE_ID>"
5. Uruchamianie funkcji AI.GENERATE z treścią w pamięci podręcznej
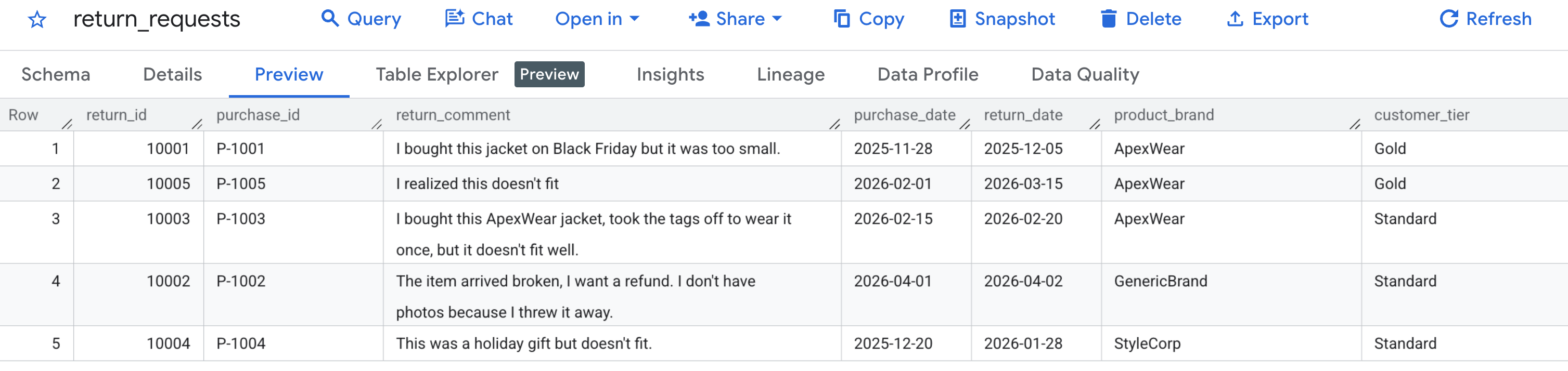
Najpierw sprawdźmy, czy dane przykładowe zostały wygenerowane prawidłowo. Otwórz konsolę BigQuery, znajdź caching_demo zbiór danych i kliknij tabelę return_requests.
Na karcie Podgląd powinny być widoczne wygenerowane wcześniej żądania zwrotu produktów przez klientów:
Po utworzeniu i wypełnieniu pamięci podręcznej możesz wysyłać zapytania za pomocą funkcji AI.GENERATE, aby ocenić prośbę o zwrot środków, po prostu odwołując się do identyfikatora pamięci podręcznej.
Aby uniknąć ręcznego wyszukiwania i zastępowania zmiennych, uruchom w Cloud Shell to polecenie. Spowoduje to dynamiczne utworzenie zapytania SQL przy użyciu istniejących zmiennych środowiskowych i wyświetlenie go na ekranie, aby można było je łatwo skopiować.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
Teraz skopiuj kod SQL w terminalu, otwórz konsolę BigQuery w przeglądarce i wykonaj zapytanie na karcie edytora zapytań.
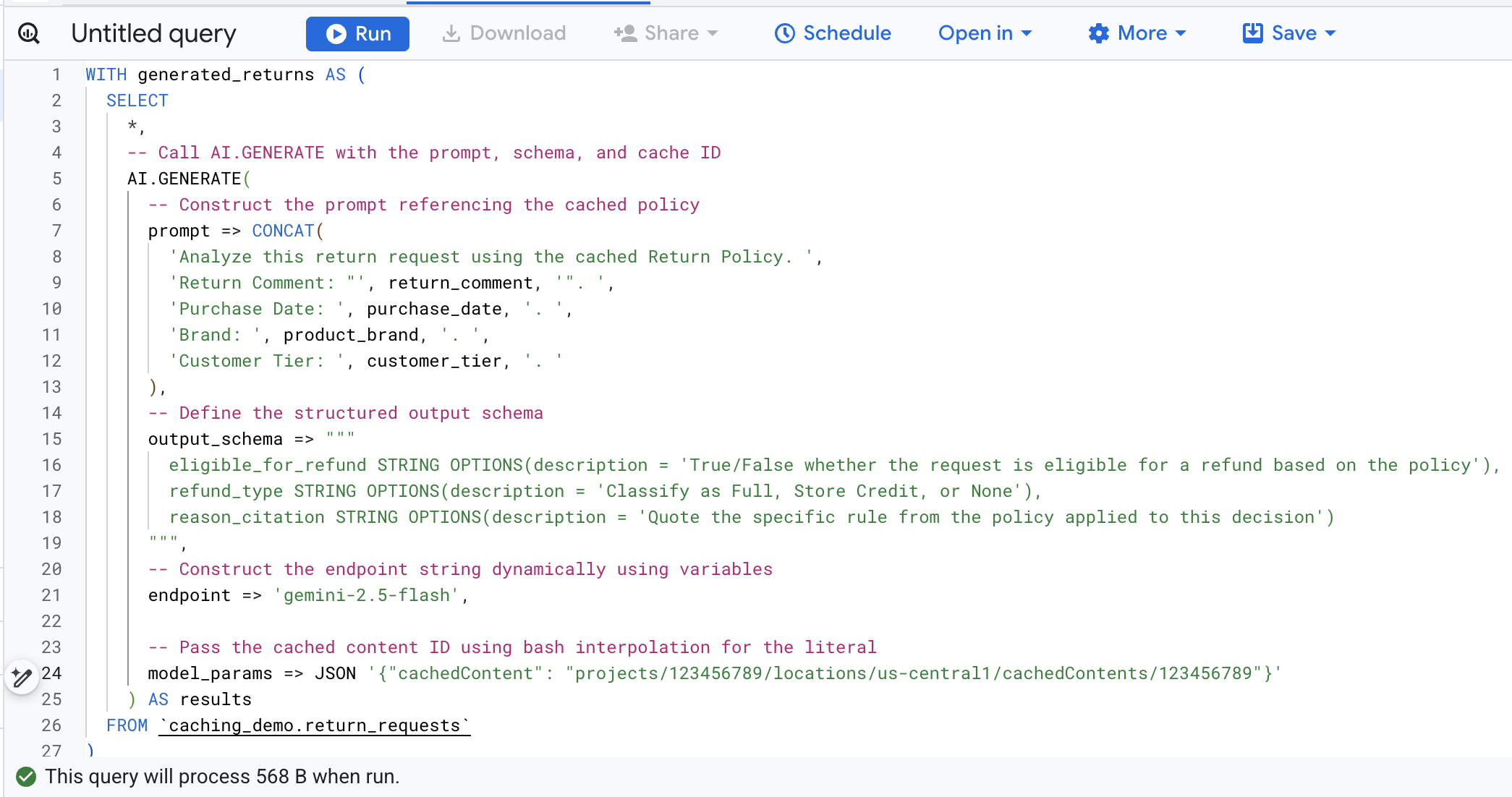
Oto zestawienie najważniejszych argumentów w tym wywołaniu funkcji:
prompt: zawiera szczegółowe informacje o każdym wierszu klienta. Ten tekst jest dołączany do dużego dokumentu Zasady zwrotów, który jest już w pamięci podręcznej.output_schema: określa oczekiwaną strukturę JSON odpowiedzi modelu.endpoint: określa punkt końcowy modelu AI platformy agentów (w naszym przypadku Gemini 2.5 Flash) używany do generowania.model_params: kluczowy parametr, który przekazuje wygenerowany identyfikator pamięci podręcznej za pomocą polacachedContent.
Powinny pojawić się wygenerowane wyniki analizy każdej prośby o zwrot zgodnie z zapisanymi zasadami. Przewiń w prawo, aby zobaczyć wyodrębnione dane tokena.
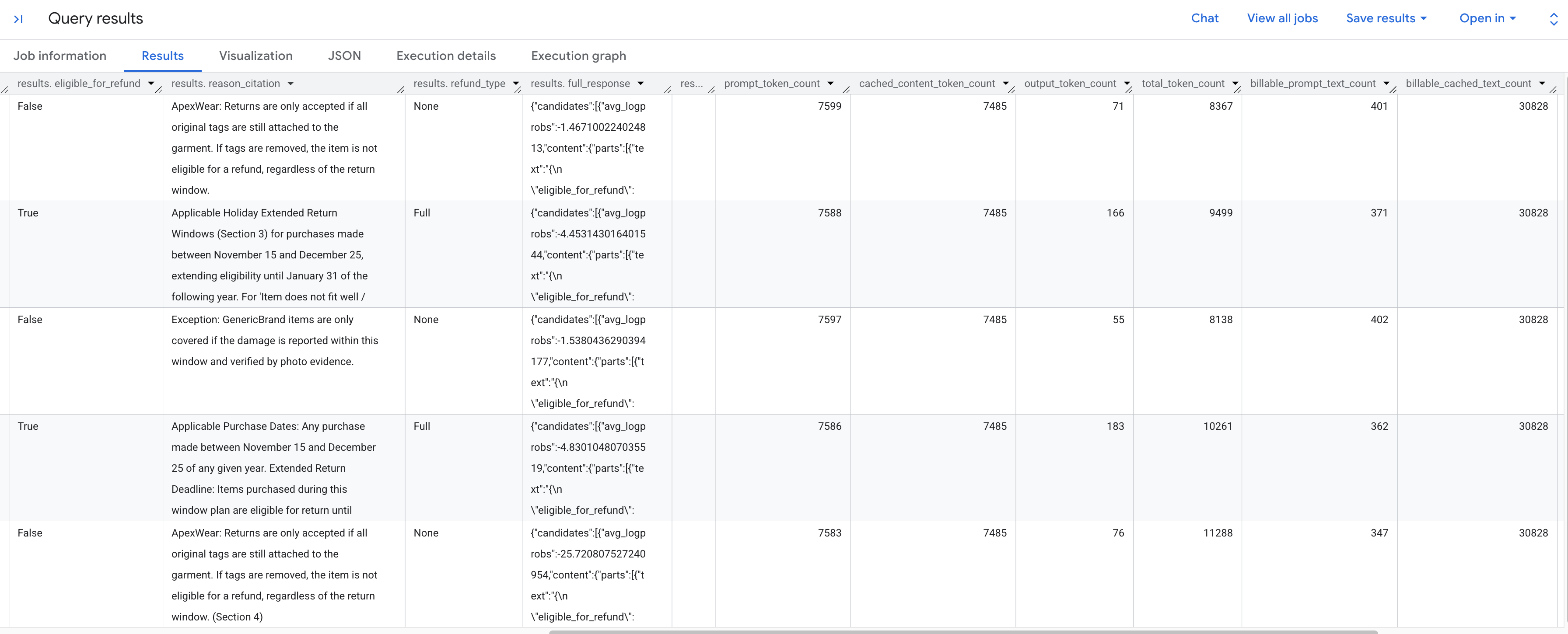
Oto zestawienie wyświetlanych danych o tokenach:
prompt_token_count: łączna liczba tokenów przetworzonych w prompcie wejściowym (w tym treści z pamięci podręcznej).cached_content_token_count: liczba tokenów wyświetlonych z pamięci podręcznej (reprezentujących statyczny dokument zasad zwrotów).output_token_count: liczba tokenów wygenerowanych przez model w odpowiedzi.total_token_count: suma tokenów promptu i tokenów wyjściowych.billable_prompt_text_count: liczba płatnych znaków w niebuforowanej części promptu.billable_cached_text_count: liczba znaków podlegających opłacie w treściach w pamięci podręcznej.
Spójrz na kolumnę billable_prompt_text_count – w każdym wierszu jest tylko kilkaset znaków, co stanowi konkretne żądanie klienta. Porównaj to z billable_cached_text_count ponad 30 000 znaków w pełnych zasadach zwrotów. Bez buforowania kontekstu musisz zapłacić za przetworzenie całego dokumentu zasad dla każdego wiersza. Dzięki temu zapłacisz za duży dokument tylko raz, a w przypadku kolejnych wierszy opłata będzie naliczana tylko za mały, zmieniający się tekst prompta.
Dzięki temu możesz znacznie zaoszczędzić na zadaniach wsadowych.
6. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone podczas tego ćwiczenia.
Uruchom w Cloud Shell to polecenie, aby usunąć zbiór danych BigQuery i jego tabele:
bq rm -r -f -d caching_demo
Usuń zasobnik tymczasowy utworzony na potrzeby dokumentu zasad:
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
Na koniec usuń pamięć podręczną kontekstu, aby uniknąć dalszych opłat za przechowywanie danych, używając zmiennych zapisanych wcześniej:
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. Gratulacje
Gratulacje! Udało Ci się utworzyć pamięć podręczną kontekstu na platformie Agent Platform i odwołać się do niej w funkcji AI BigQuery, aby przyspieszyć analizę przy jednoczesnym zmniejszeniu kosztów przetwarzania tokenów wejściowych.
Czego się dowiedziałeś(-aś)
- Jak skonfigurować tabele środowisk na potrzeby analizy próśb o zwrot.
- Jak wywołać interfejs API platformy agentów (Vertex AI) za pomocą
curl, aby jawnie utworzyć statyczną pamięć podręczną kontekstu dokumentu. - Jak używać wygenerowanego identyfikatora pamięci podręcznej w zapytaniu SQL
AI.GENERATE, aby wyeliminować nadmiarowe tokeny wejściowe w aktywnych promptach.