
1. Introdução
As funções de IA generativa do BigQuery permitem usar o SQL para raciocinar sobre os dados usando modelos de linguagem grandes (LLMs). É possível analisar sentimentos, gerar resumos e legendas de imagens em milhões de linhas sem mover os dados.
Mas e se o prompt precisar de uma grande quantidade de contexto (como políticas, manuais ou um vídeo) para gerar resultados precisos e confiáveis?
O armazenamento em cache de contexto do Gemini resolve esse problema armazenando esse contexto grande em um cache. Os prompts subsequentes referenciam o cache em vez de processar o conteúdo completo todas as vezes, oferecendo menor latência e até 90% de desconto nos tokens de entrada.
Neste codelab, você vai criar um verificador de política de devolução de "letras miúdas" que usa o armazenamento em cache de contexto explícito para analisar solicitações de devolução de clientes em relação a um documento de política de devolução estático e enorme no BigQuery.

Atividades deste laboratório
- Criar um conjunto de dados do BigQuery e preenchê-lo com exemplos de solicitações de devolução de clientes.
- Criar um cache de contexto na plataforma de agentes do Gemini Enterprise (antiga Vertex AI), apontando para um documento de política de devolução armazenado no Cloud Storage.
- Executar uma consulta usando
AI.GENERATEque referencia o cache para avaliar as solicitações linha por linha de maneira eficiente.
O que é necessário
- Um navegador da web, como o Chrome
- Tenha um projeto na nuvem do Google Cloud com o faturamento ativado.
- Acesso ao Google Cloud Shell
Este codelab é destinado a desenvolvedores de todos os níveis, incluindo iniciantes.
Os recursos criados neste codelab custam menos de US $2.
Duração estimada:este codelab leva aproximadamente 30 minutos para ser concluído.
2. Antes de começar
Criar um projeto do Google Cloud
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto na nuvem. Saiba como verificar se o faturamento está ativado em um projeto.
Iniciar o Cloud Shell
O Cloud Shell é um ambiente de linha de comando em execução no Google Cloud que vem pré-carregado com as ferramentas necessárias.
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique sua autenticação:
gcloud auth list - Confirme se o projeto está configurado:
gcloud config get project - Se o projeto não estiver definido como esperado, defina-o:
gcloud config set project <YOUR_PROJECT_ID>
Definir o ID e o local do projeto
Execute o comando a seguir para recuperar o ID do projeto ativo do Google Cloud e definir o local padrão como variáveis de ambiente a serem usadas neste codelab:
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
Ativar APIs
Execute este comando para ativar as APIs necessárias:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. Preparar dados do BigQuery
Antes de testar o armazenamento em cache de contexto, precisamos de um conjunto de dados e uma tabela preenchida com exemplos de solicitações de devolução de clientes para executar nossas consultas.
1. Criar um conjunto de dados
Execute o comando a seguir no Cloud Shell para criar um conjunto de dados do BigQuery chamado caching_demo:
bq mk --dataset $PROJECT_ID:caching_demo
2. Criar e preencher a tabela
Execute o comando a seguir para criar uma tabela chamada return_requests e inserir exemplos de solicitações de devolução de clientes:
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
Você vai receber uma mensagem de confirmação:
Created your-project-id.caching_demo.return_requests
Agora estamos prontos para criar nosso cache.
4. Criar o cache de contexto
Você vai criar o cache usando uma chamada REST para o endpoint do modelo da plataforma de agentes do Gemini Enterprise (antiga Vertex AI) usando curl.
Execute o comando a seguir no Cloud Shell para criar um novo bucket de armazenamento. Ele será usado para armazenar arquivos que queremos armazenar em cache:
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
Em seguida, copie o documento de política de amostra para o bucket recém-criado:
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
Agora, execute o comando a seguir para criar o cache que referencia o documento de política recém-preparado (isso pode levar um minuto ou mais para ser concluído):
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
Anote o name retornado na resposta JSON, que será semelhante a esta: projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID. Você vai precisar desse CACHE_ID para a próxima etapa.
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
Salve o CACHE_ID como uma variável de ambiente no Cloud Shell:
export CACHE_ID="<YOUR_CACHE_ID>"
5. Executar AI.GENERATE com conteúdo armazenado em cache
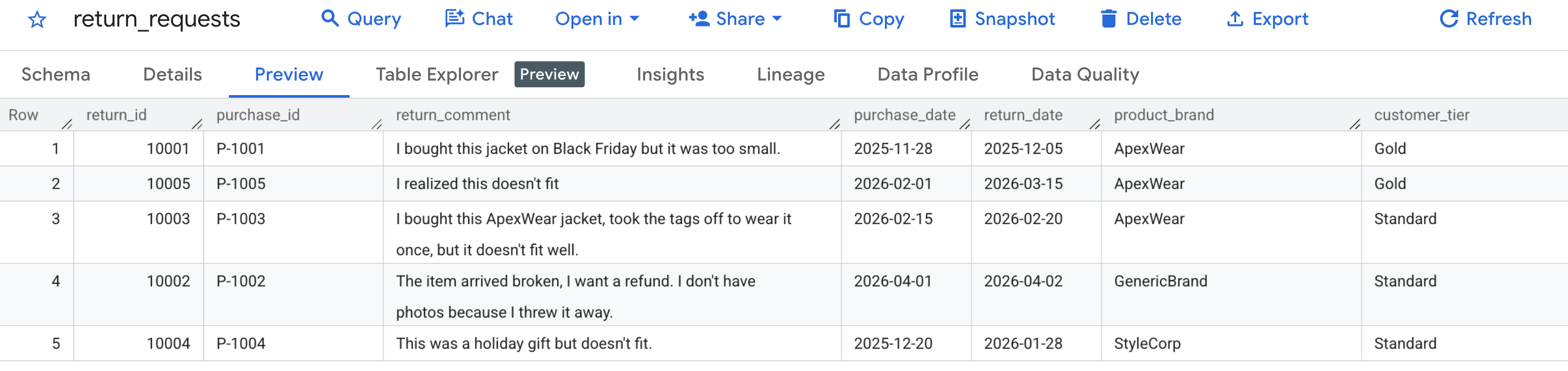
Primeiro, vamos verificar se os dados de amostra foram gerados corretamente. Navegue até o console do BigQuery, localize o conjunto de dados caching_demo e clique na tabela return_requests.
Na guia Visualização, você vai encontrar as solicitações de devolução de clientes que geramos anteriormente:
Agora que o cache foi criado e preenchido, você pode consultar usando AI.GENERATE para avaliar a solicitação de reembolso simplesmente referenciando o ID do cache.
Para evitar encontrar e substituir variáveis manualmente, execute o comando a seguir no Cloud Shell. Isso vai criar dinamicamente a consulta SQL usando as variáveis de ambiente atuais e imprimi-la na tela para que você possa copiá-la facilmente.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
Agora, copie o SQL no terminal, navegue até o console do BigQuery no navegador e execute a consulta na guia do editor de consultas.
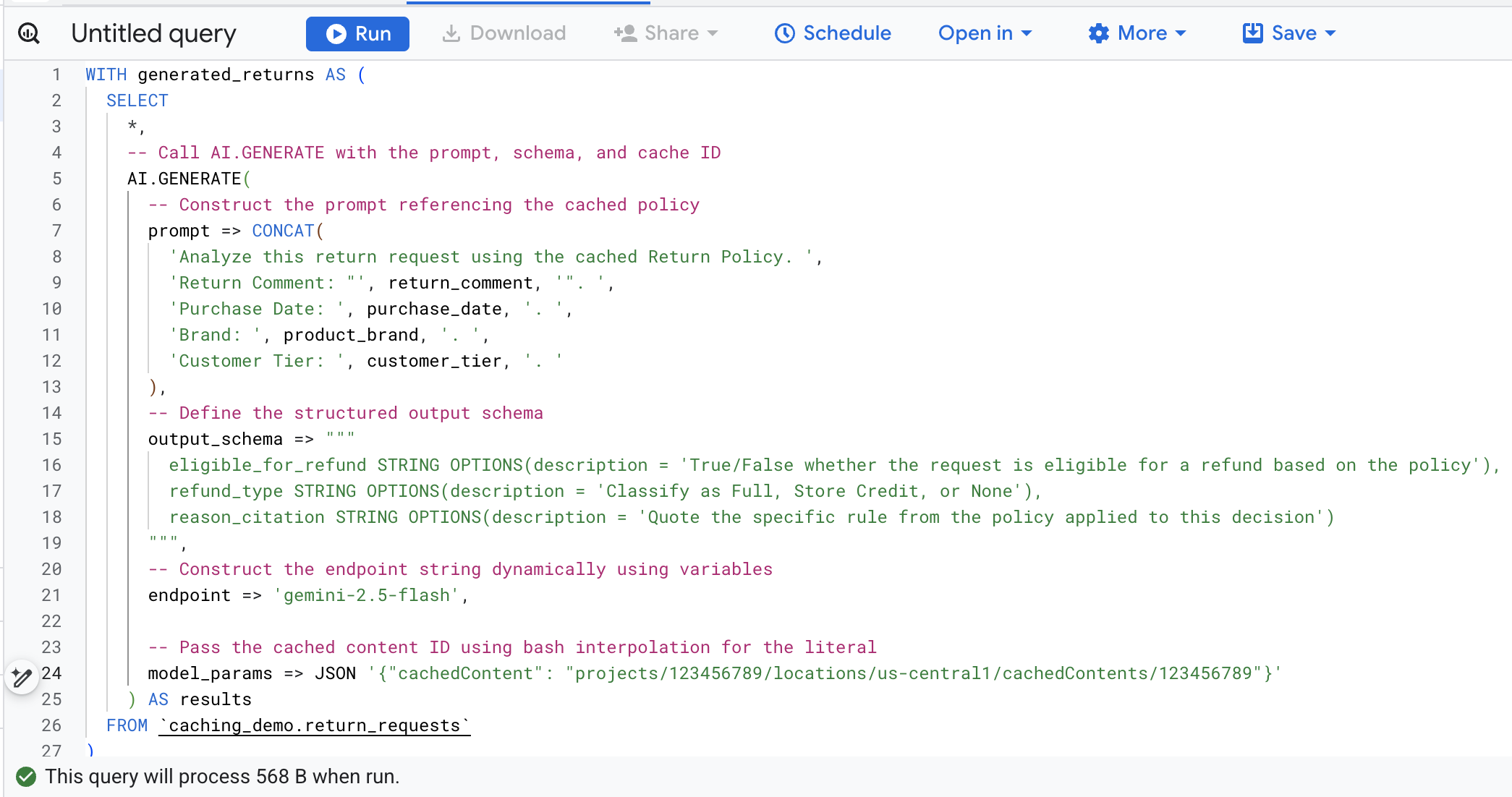
Confira a seguir um detalhamento dos principais argumentos nessa chamada de função:
prompt: contém as informações específicas de cada linha do cliente. Esse texto é anexado ao documento de política de devolução grande que já está no cache.output_schema: define a estrutura JSON esperada da resposta do modelo.endpoint: especifica o endpoint do modelo de IA da plataforma de agentes (Gemini 2.5 Flash no nosso caso) usado para geração.model_params: parâmetro essencial que transmite o ID do cache gerado usando o campocachedContent.
Você deve ver os resultados gerados analisando cada pedido de devolução de acordo com a política armazenada. Role para a direita para ver as métricas de token extraídas.
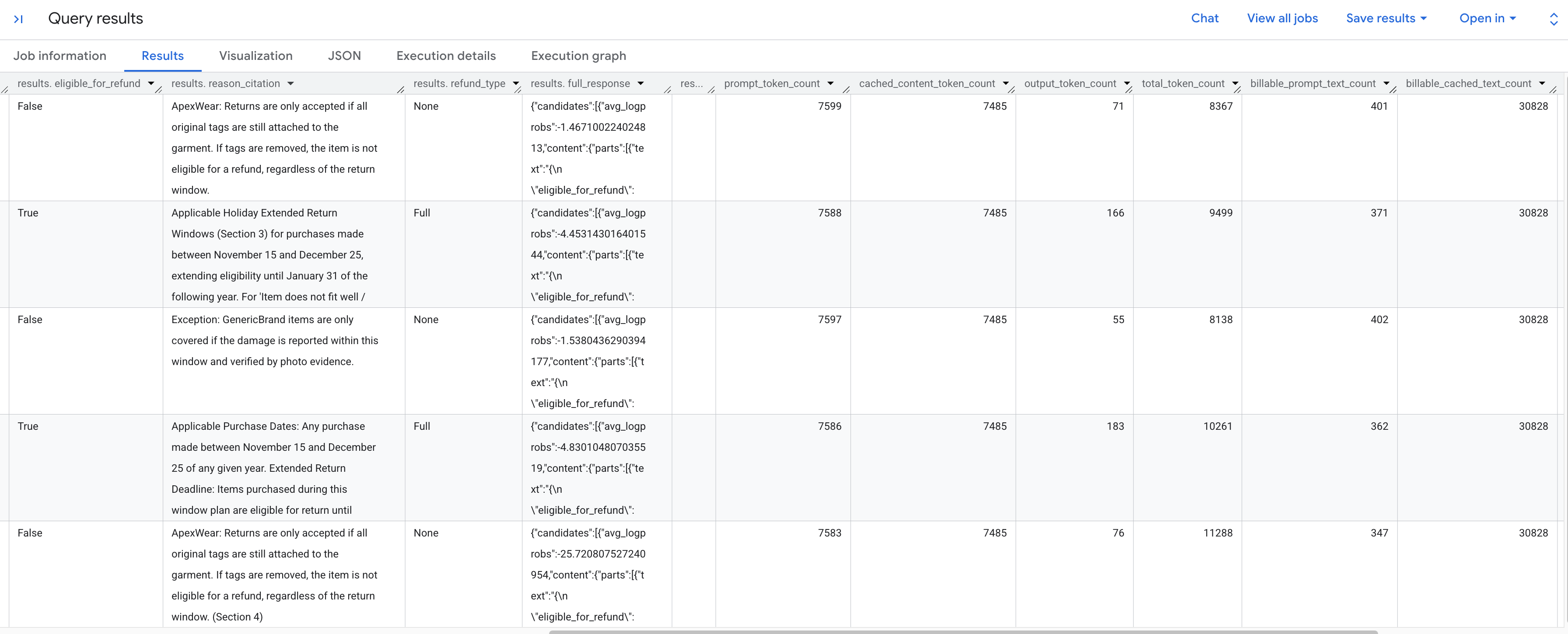
Confira a seguir um detalhamento das métricas de token que você encontra:
prompt_token_count: o número total de tokens processados no prompt de entrada (incluindo o conteúdo armazenado em cache).cached_content_token_count: o número de tokens veiculados do cache (que representa o documento de política de devolução estático).output_token_count: o número de tokens gerados pelo modelo na resposta.total_token_count: a soma dos tokens de prompt e de saída.billable_prompt_text_count: o número de caracteres faturáveis na parte não armazenada em cache do prompt.billable_cached_text_count: o número de caracteres faturáveis no conteúdo armazenado em cache.
Observe a coluna billable_prompt_text_count : ela mostra apenas algumas centenas de caracteres por linha, que é apenas a solicitação específica do cliente. Compare isso com o billable_cached_text_count de mais de 30.000 caracteres para a política de devolução completa. Sem o armazenamento em cache de contexto, você pagaria para processar o documento de política completo para cada linha. Ao armazená-lo em cache, você paga pelo documento grande uma vez, e as linhas subsequentes só cobram pelo texto do prompt pequeno e em mudança.
Isso resulta em economias enormes para jobs em lote.
6. Limpar
Para evitar cobranças contínuas na sua conta do Google Cloud, exclua os recursos criados durante este codelab.
Execute o comando a seguir no Cloud Shell para excluir o conjunto de dados do BigQuery e as tabelas dele:
bq rm -r -f -d caching_demo
Exclua o bucket de preparação criado para o documento de política:
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
Por fim, exclua o cache de contexto para evitar cobranças de armazenamento contínuas usando as variáveis armazenadas anteriormente:
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. Parabéns
Parabéns! Você criou um cache de contexto na plataforma de agentes e o referenciou em uma função de IA do BigQuery para acelerar a análise e reduzir os custos de processamento de tokens de entrada.
O que você aprendeu
- Como configurar tabelas de ambiente para análise de dados de pedidos de devolução.
- Como chamar a API da plataforma de agentes (Vertex AI) usando
curlpara criar explicitamente um cache de contexto de documento estático. - Como usar o ID do cache gerado em uma consulta SQL
AI.GENERATEpara eliminar tokens de entrada redundantes em prompts ativos.