
1. Введение
Функции генеративного искусственного интеллекта BigQuery позволяют использовать SQL для анализа данных с помощью больших языковых моделей (LLM). Вы можете анализировать тональность, создавать сводки и подписи к изображениям, обрабатывая миллионы строк, без перемещения данных.
Но что, если для получения точных и достоверных результатов вашему запросу требуется огромный объем контекстной информации (например, правила, руководства или видео)?
Кэширование контекста Gemini решает эту проблему, сохраняя большой объем контекста в кэше. Последующие запросы обращаются к кэшу, а не обрабатывают все содержимое каждый раз, что обеспечивает меньшую задержку и до 90% скидки на входные токены.
В этом практическом задании вы создадите средство проверки политики возврата товаров, использующее явное контекстное кэширование для анализа запросов клиентов на возврат на основе огромного статического документа с политикой возврата товаров в BigQuery.

Что вы будете делать
- Создайте набор данных BigQuery и заполните его примерами запросов на возврат товара от клиентов.
- Создайте контекстный кэш в Gemini Enterprise Agent Platform (ранее известной как Vertex AI), указывающий на документ с политикой возврата, хранящийся в облачном хранилище.
- Выполните запрос с помощью
AI.GENERATE, который обращается к кэшу, чтобы эффективно обрабатывать запросы построчно.
Что вам понадобится
- Веб-браузер, например Chrome.
- Проект Google Cloud с включенной функцией выставления счетов.
- Доступ к Google Cloud Shell
Этот практический семинар предназначен для разработчиков всех уровней, включая начинающих.
Стоимость ресурсов, созданных в рамках этого практического занятия, должна составлять менее 2 долларов.
Ориентировочная продолжительность: выполнение этого практического задания займет приблизительно 30 минут.
2. Прежде чем начать
Создайте проект в Google Cloud.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Запустить Cloud Shell
Cloud Shell — это среда командной строки, работающая в Google Cloud и поставляемая с предустановленными необходимыми инструментами.
- В верхней части консоли Google Cloud нажмите кнопку «Активировать Cloud Shell» .

- После подключения к Cloud Shell подтвердите свою аутентификацию:
gcloud auth list - Убедитесь, что ваш проект настроен:
gcloud config get project - Если параметры вашего проекта заданы не так, как ожидалось, настройте их следующим образом:
gcloud config set project <YOUR_PROJECT_ID>
Укажите идентификатор проекта и его местоположение.
Выполните следующую команду, чтобы получить идентификатор вашего активного проекта Google Cloud и установить местоположение по умолчанию в качестве переменных среды для использования на протяжении всего этого практического занятия:
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
Включить API
Выполните эту команду, чтобы включить необходимые API :
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
3. Подготовка данных BigQuery
Прежде чем тестировать контекстное кэширование, нам потребуется набор данных и таблица, заполненная примерами запросов на возврат товаров от клиентов, чтобы затем выполнить наши запросы.
1. Создайте набор данных.
Выполните следующую команду в Cloud Shell, чтобы создать набор данных BigQuery с именем caching_demo :
bq mk --dataset $PROJECT_ID:caching_demo
2. Создайте и заполните таблицу.
Выполните следующую команду, чтобы создать таблицу с именем return_requests и вставить в нее примеры запросов на возврат от клиентов :
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
Вы должны увидеть сообщение об успешном завершении:
Created your-project-id.caching_demo.return_requests
Теперь мы готовы создать наш тайник!
4. Создайте контекстный кэш.
Вы создадите кэш, используя REST-запрос к конечной точке модели Gemini Enterprise Agent Platform (ранее известной как Vertex AI) с помощью curl .
Выполните следующую команду в Cloud Shell, чтобы создать новый сегмент хранилища . Он будет использоваться для хранения файлов, которые мы хотим кэшировать:
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
Далее скопируйте образец документа с политикой в созданный вами контейнер:
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
Теперь выполните следующую команду, чтобы создать кэш, ссылающийся на ваш недавно подготовленный документ политики (это может занять около минуты):
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
Обратите внимание на name , возвращаемое в JSON-ответе, которое будет выглядеть примерно так: projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID . Этот CACHE_ID понадобится вам на следующем шаге.
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
Сохраните значение CACHE_ID в качестве переменной среды в Cloud Shell:
export CACHE_ID="<YOUR_CACHE_ID>"
5. Запустите AI.GENERATE с кэшированным содержимым.
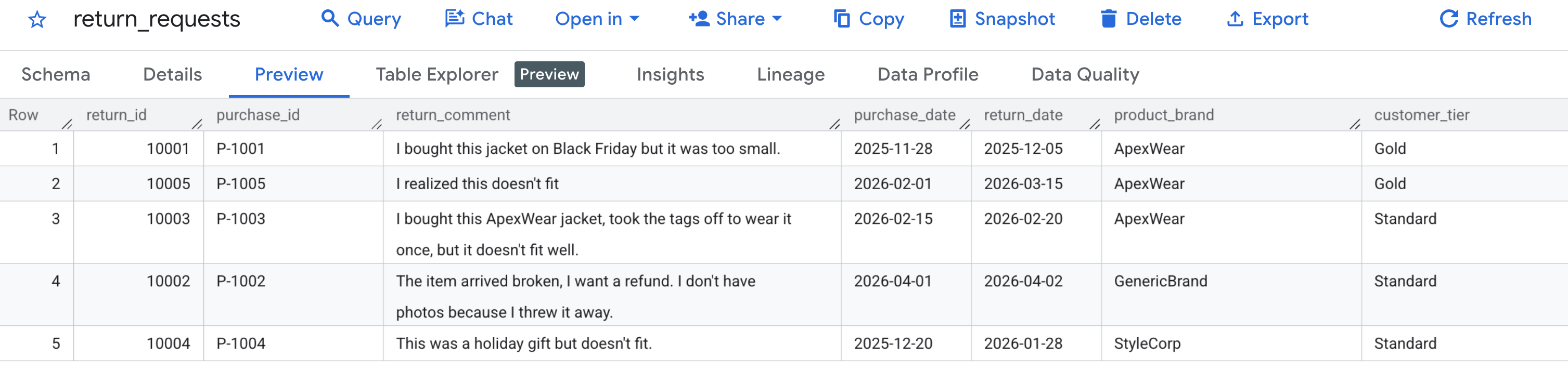
Для начала давайте убедимся, что наши тестовые данные были сгенерированы правильно . Перейдите в консоль BigQuery , найдите набор данных caching_demo и щелкните таблицу return_requests .
На вкладке «Предварительный просмотр » вы должны увидеть запросы на возврат товара, которые мы сгенерировали ранее:
Теперь, когда кэш создан и заполнен, вы можете использовать AI.GENERATE для оценки запроса на возврат средств, просто указав идентификатор этого кэша.
Чтобы избежать ручного поиска и замены переменных, выполните следующую команду в Cloud Shell . Это динамически сформирует SQL-запрос, используя существующие переменные среды, и выведет его на экран, чтобы вы могли легко его скопировать.
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
Теперь скопируйте SQL-запрос из терминала , перейдите в консоль BigQuery в браузере и выполните запрос на вкладке редактора запросов.
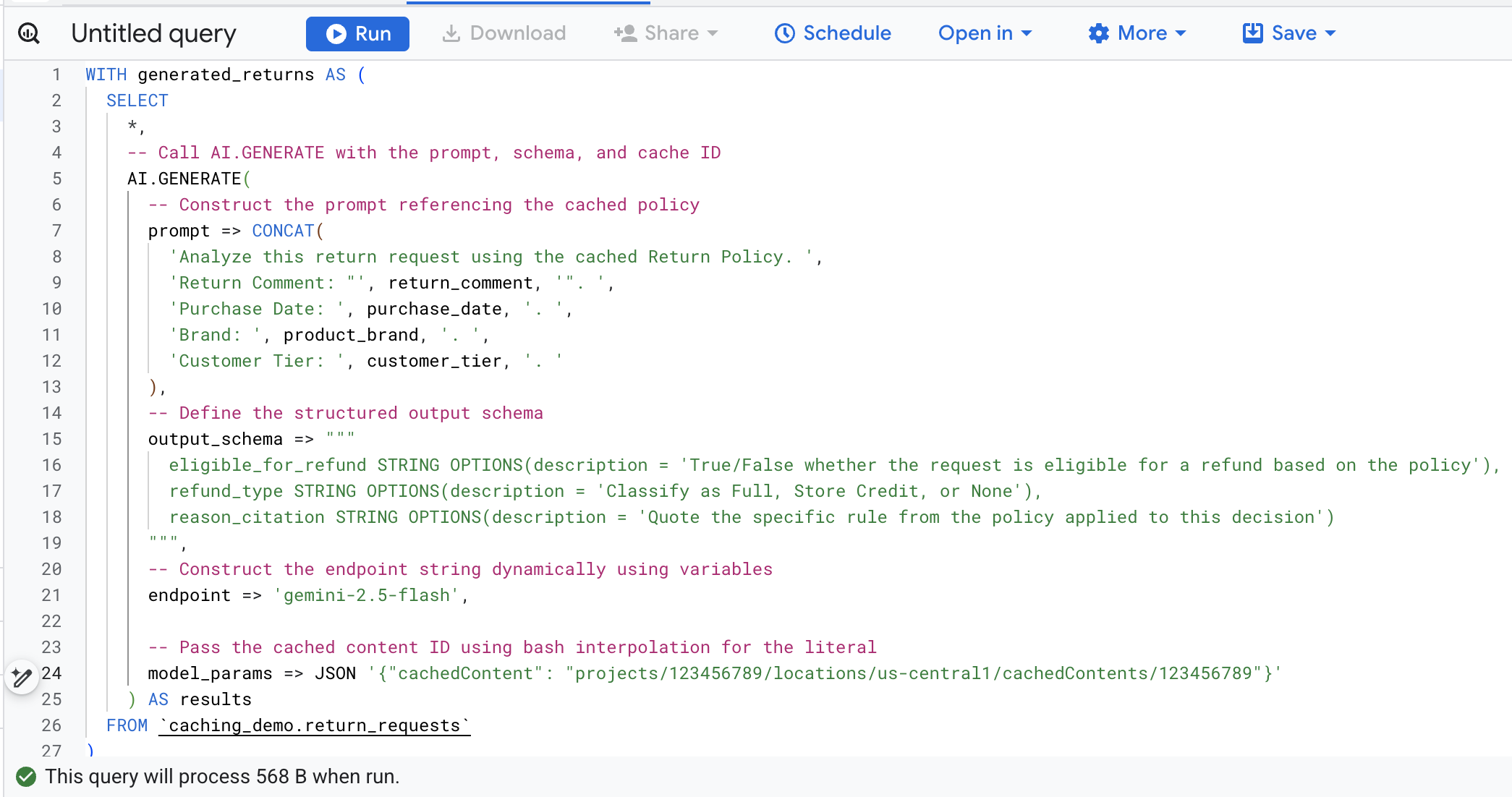
Вот подробное описание основных аргументов в этом вызове функции:
-
prompt: Содержит подробную информацию по каждой строке с данными о клиенте. Этот текст фактически добавляется к большому документу «Политика возврата», уже находящемуся в кэше. -
output_schema: Определяет ожидаемую структуру JSON-ответа модели. -
endpoint: Указывает конечную точку модели Agent Platform AI (в нашем случае Gemini 2.5 Flash), используемую для генерации. -
model_params: Важный параметр, передающий сгенерированный идентификатор кэша с помощью поляcachedContent.
Вы должны увидеть результаты анализа каждого запроса в соответствии с сохраненной политикой. Прокрутите вправо, чтобы увидеть извлеченные метрики токенов.
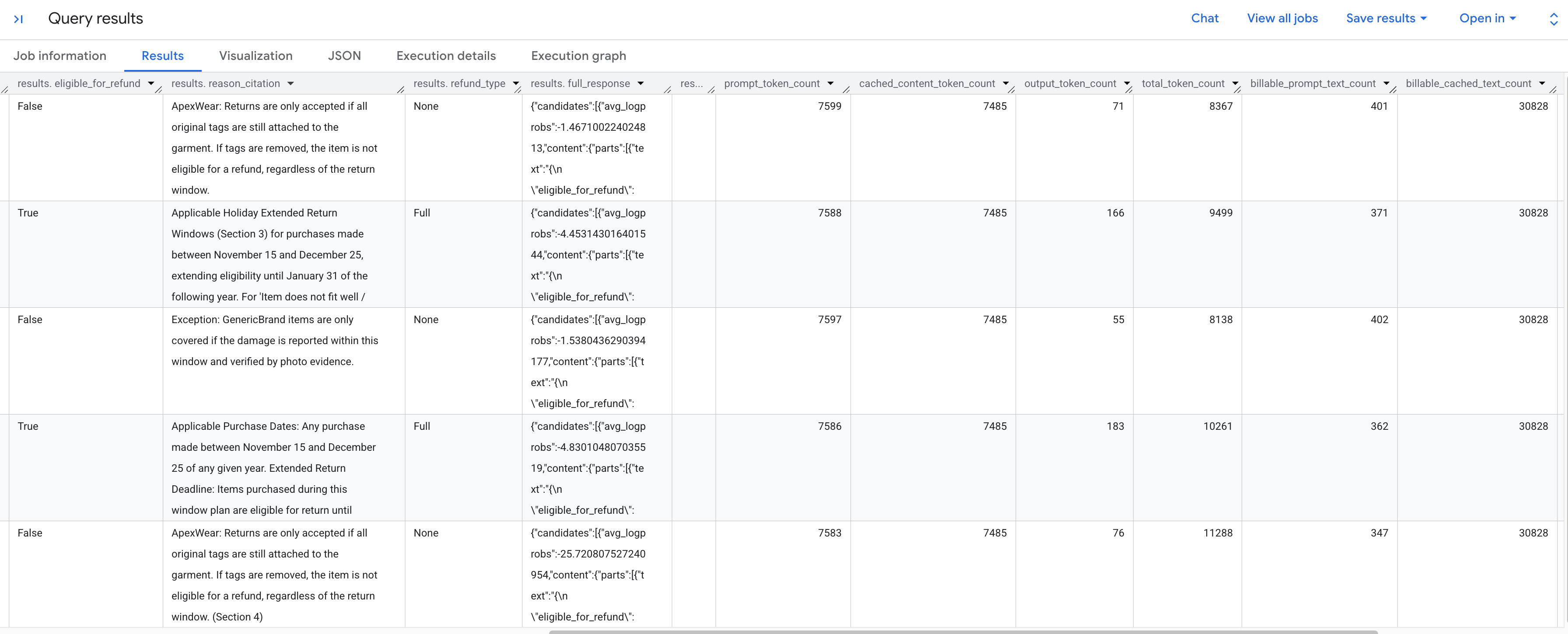
Вот подробная информация о показателях токена, которые вы видите:
-
prompt_token_count: Общее количество токенов, обработанных во входном запросе (включая кэшированное содержимое). -
cached_content_token_count: Количество токенов, предоставленных из кэша (представляющих статический документ «Политика возврата»). -
output_token_count: Количество токенов, сгенерированных моделью в ответе. -
total_token_count: Сумма токенов подсказки и вывода. -
billable_prompt_text_count: Количество платных символов в некэшируемой части запроса. -
billable_cached_text_count: Количество платных символов в кэшированном контенте.
Посмотрите на столбец billable_prompt_text_count — в каждой строке отображается всего несколько сотен символов, что соответствует конкретному запросу клиента. Сравните это с показателем billable_cached_text_count , превышающим 30 000 символов для всего текста политики возврата. Без контекстного кэширования вы бы платили за обработку всего документа политики для каждой отдельной строки . При кэшировании вы платите за большой документ один раз, а за последующие строки взимается плата только за небольшой, изменяющийся текст запроса.
Это позволяет значительно сэкономить на пакетных заданиях!
6. Уборка
Чтобы избежать дальнейших списаний средств с вашего аккаунта Google Cloud, удалите ресурсы, созданные в ходе этого практического занятия.
Выполните следующую команду в Cloud Shell , чтобы удалить набор данных BigQuery и его таблицы:
bq rm -r -f -d caching_demo
Удалите временный контейнер, созданный для документа политики:
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
Наконец, удалите контекстный кэш , чтобы избежать дальнейших расходов на хранение данных, используя ранее сохраненные переменные:
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
7. Поздравляем!
Поздравляем! Вы успешно создали контекстный кэш в Agent Platform и сослались на него в функции BigQuery AI, что ускорило анализ и снизило затраты на обработку входных токенов.
Что вы узнали
- Как настроить таблицы окружения для анализа запросов на возврат.
- Как вызвать API платформы агентов (Vertex AI) с помощью
curlдля явного создания статического кэша контекста документа. - Как использовать сгенерированный идентификатор кэша в SQL-запросе
AI.GENERATEдля устранения избыточных входных токенов в активных запросах.