
1. Einführung
Stellen Sie sich vor, Sie könnten Ihre Daten schneller und effizienter für die Analyse vorbereiten, ohne ein Programmierexperte sein zu müssen. Mit BigQuery Data Preparation ist das möglich. Diese leistungsstarke Funktion vereinfacht die Datenaufnahme, ‑transformation und ‑bereinigung und ermöglicht es allen Datenexperten in Ihrer Organisation, Daten vorzubereiten.
Möchten Sie die Geheimnisse Ihrer Produktdaten lüften?
Voraussetzungen
- Grundlegende Kenntnisse der Google Cloud Console
- Grundkenntnisse in SQL
Lerninhalte
- Wie Sie mit der BigQuery-Datenaufbereitung Ihre Rohdaten bereinigen und in umsetzbare Business Intelligence umwandeln können – mit einem realistischen Beispiel aus der Mode- und Kosmetikbranche.
- Datenvorbereitung für bereinigte Daten ausführen und planen
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome
2. Grundlegende Einrichtung und Anforderungen
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes Projekt. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

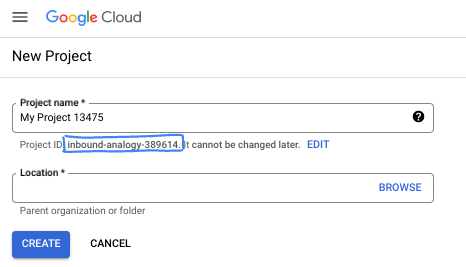
- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Es handelt sich um einen String, der nicht von Google APIs verwendet wird. Sie können sie jederzeit aktualisieren.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich (kann nach dem Festlegen nicht mehr geändert werden). In der Cloud Console wird automatisch ein eindeutiger String generiert. Normalerweise ist es nicht wichtig, wie dieser String aussieht. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie es mit einem eigenen Namen versuchen und sehen, ob er verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten finden Sie in der Dokumentation.
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/-APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um Kosten zu vermeiden, die über diese Anleitung hinausgehen, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können am Programm Kostenloser Testzeitraum mit einem Guthaben von 300$ teilnehmen.
3. Hinweis
API aktivieren
Damit Sie Gemini in BigQuery verwenden können, müssen Sie die Gemini for Google Cloud API aktivieren. Dieser Schritt wird in der Regel von einem Dienstadministrator oder Projektinhaber mit der IAM-Berechtigung serviceusage.services.enable ausgeführt.
- Wenn Sie die Gemini for Google Cloud API aktivieren möchten, rufen Sie im Google Cloud Marketplace die Seite Gemini for Google Cloud auf. Zu Gemini für Google Cloud
- Wählen Sie in der Projektauswahl ein Projekt aus.
- Klicken Sie auf Aktivieren. Die Seite wird aktualisiert und zeigt den Status Aktiviert an. Gemini in BigQuery ist jetzt im ausgewählten Google Cloud-Projekt für alle Nutzer mit den erforderlichen IAM-Berechtigungen verfügbar.
Rollen und Berechtigungen zum Entwickeln von Datenaufbereitungen einrichten
- Wählen Sie unter „IAM und Verwaltung“ die Option „IAM“ aus.
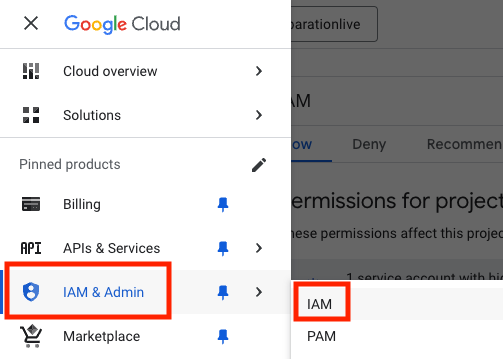
- Wählen Sie Ihren Nutzer aus und klicken Sie auf das Stiftsymbol, um den Hauptnutzer zu bearbeiten.
Für die Verwendung der BigQuery-Datenvorbereitung benötigen Sie die folgenden Rollen und Berechtigungen:
- BigQuery-Datenbearbeiter (roles/bigquery.dataEditor)
- Service Usage-Nutzer (roles/serviceusage.serviceUsageConsumer)
4. Eintrag „bq data preparation demo“ in BigQuery Analytics Hub suchen und abonnieren
In dieser Anleitung verwenden wir das Dataset bq data preparation demo. Es handelt sich um ein verknüpftes Dataset in BigQuery Analytics Hub, aus dem wir Daten lesen.
Bei der Datenvorbereitung werden keine Daten in die Quelle zurückgeschrieben. Sie werden aufgefordert, eine Zieltabelle zu definieren, in die geschrieben werden soll. Die Tabelle, mit der wir in dieser Übung arbeiten, hat nur 1.000 Zeilen, um die Kosten gering zu halten. Die Datenaufbereitung wird jedoch in BigQuery ausgeführt und skaliert entsprechend.
So finden Sie das verknüpfte Dataset und abonnieren es:
- Analytics Hub aufrufen: Rufen Sie in der Google Cloud Console BigQuery auf.
- Wählen Sie im BigQuery-Navigationsmenü unter „Governance“ die Option „Analytics Hub“ aus.
- Eintrag suchen: Klicken Sie in der Analytics Hub-Benutzeroberfläche auf Einträge suchen.
- Geben Sie
bq data preparation demoin die Suchleiste ein und drücken Sie die Eingabetaste.

- Abonnieren Sie das Unternehmensprofil: Wählen Sie das
bq data preparation demo-Unternehmensprofil in den Suchergebnissen aus. - Klicken Sie auf der Seite mit den Angebotsdetails auf die Schaltfläche Abonnieren.
- Prüfen Sie alle Bestätigungsdialogfelder und aktualisieren Sie das Projekt bzw. den Datensatz bei Bedarf. Die Standardeinstellungen sollten korrekt sein.
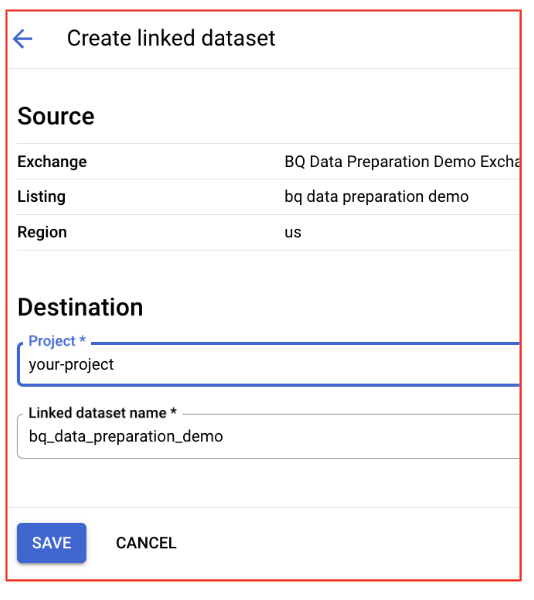
- Auf das Dataset in BigQuery zugreifen: Nachdem Sie das Abo abgeschlossen haben, werden die Datasets im Eintrag mit Ihrem BigQuery-Projekt verknüpft.
Kehren Sie zu BigQuery Studio zurück.
5. Daten untersuchen und Datenvorbereitung starten
- Dataset und Tabelle suchen: Wählen Sie im Bereich „Explorer“ Ihr Projekt aus und suchen Sie dann nach dem Dataset, das in der Liste
bq data preparation demoenthalten war. Wählen Sie die Tabellestg_productaus. - In Data Preparation öffnen: Klicken Sie auf das Dreipunkt-Menü neben dem Tabellennamen und wählen Sie
Open in Data Preparationaus.
Die Tabelle wird in der Benutzeroberfläche für die Datenvorbereitung geöffnet. Sie können nun mit der Transformation Ihrer Daten beginnen.

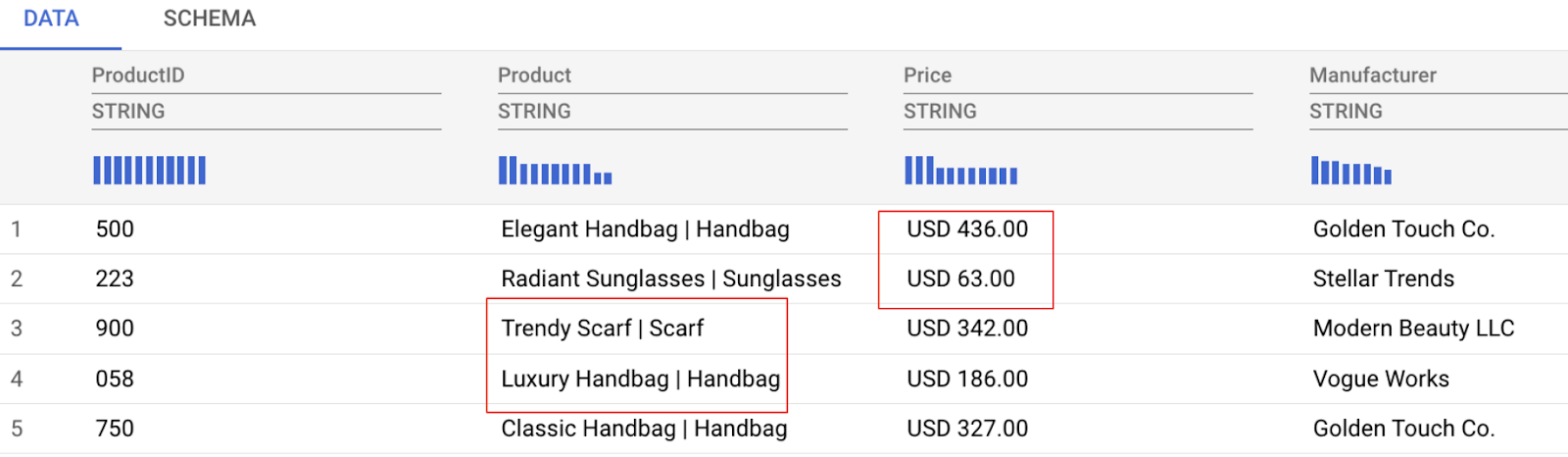
Wie Sie in der Datenvorschau unten sehen können, gibt es einige Datenherausforderungen, die wir angehen müssen. Dazu gehören:
- Die Spalte „Preis“ enthält sowohl den Betrag als auch die Währung, was die Analyse erschwert.
- In der Spalte „Produkt“ werden Produktname und ‑kategorie kombiniert (durch einen senkrechten Strich | getrennt).
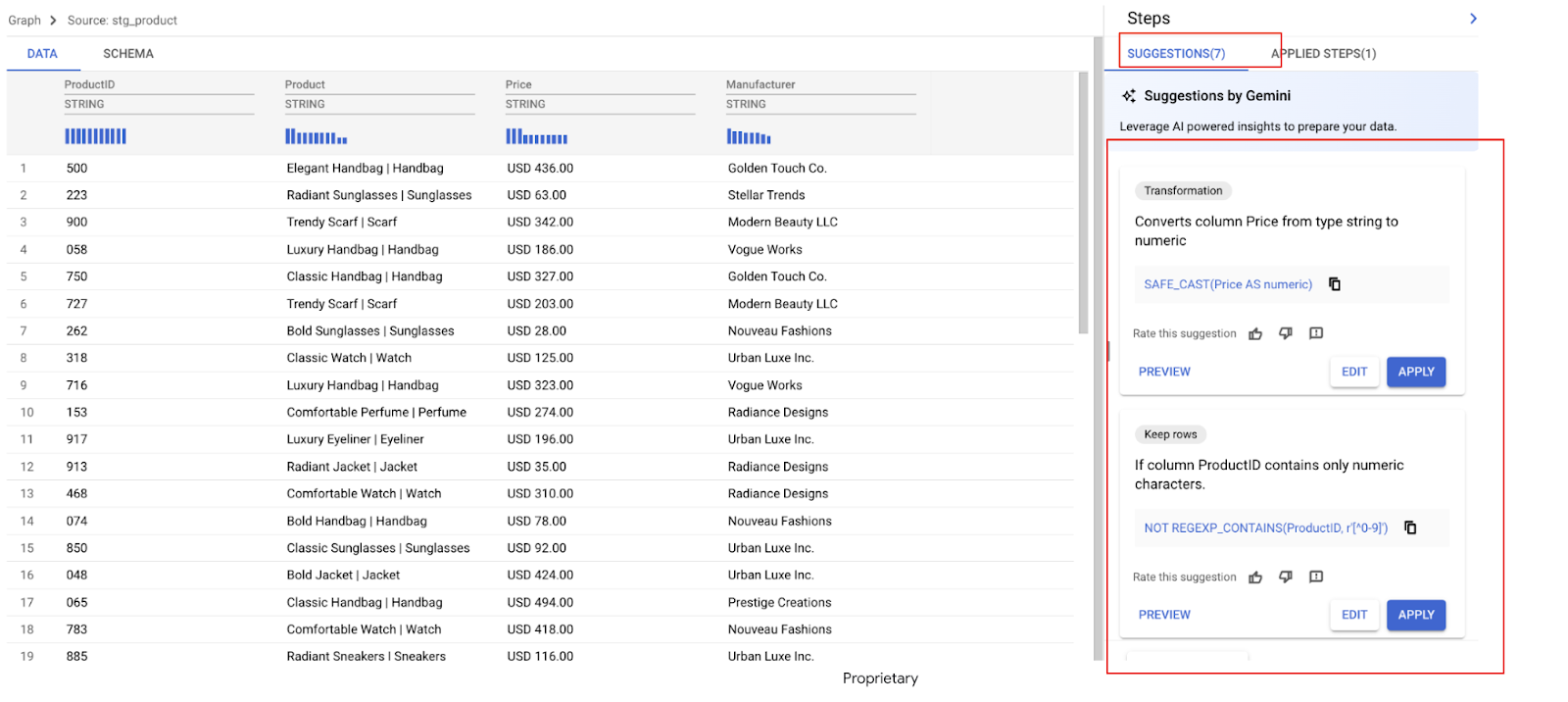
Gemini analysiert Ihre Daten sofort und schlägt mehrere Transformationen vor. In diesem Beispiel sehen wir eine Reihe von Empfehlungen. In den nächsten Schritten wenden wir die benötigten an.
6. Umgang mit der Spalte „Preis“
Sehen wir uns die Spalte Preis an. Wie wir gesehen haben, enthält er sowohl die Währung als auch den Betrag. Unser Ziel ist es, diese in zwei separate Spalten aufzuteilen: „Währung“ und „Betrag“.
Gemini hat mehrere Empfehlungen für die Spalte „Preis“ ermittelt.
- Suchen Sie nach einer Empfehlung, die in etwa so lautet:
Beschreibung: „Mit diesem Ausdruck wird das führende ‚USD ‘ aus dem angegebenen Feld entfernt.“
REGEXP_REPLACE(Price,` `r'^USD\s',` `r'')
- „Vorschau“ auswählen

- „Übernehmen“ auswählen
Als Nächstes konvertieren wir den Datentyp der Spalte „Price“ von STRING in NUMERIC.
- Suchen Sie nach einer Empfehlung, die in etwa so lautet:
Beschreibung: „Konvertiert die Spalte ‚Preis‘ vom Typ ‚string‘ in ‚float64‘“
SAFE_CAST(Price AS float64)
- Klicken Sie auf „Übernehmen“.
In der Schrittliste sollten jetzt drei angewendete Schritte angezeigt werden.

7. Produktspalte
Die Produktspalte enthält sowohl den Produktnamen als auch die Kategorie, getrennt durch einen senkrechten Strich (|).
Wir könnten zwar wieder natürliche Sprache verwenden, aber sehen wir uns eine weitere leistungsstarke Funktion von Gemini an.
Produktnamen bereinigen
- Wählen Sie den Kategorieabschnitt eines Produkteintrags einschließlich des Zeichens
|aus und löschen Sie ihn.
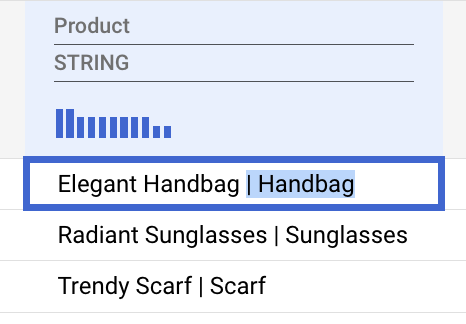
Gemini erkennt dieses Muster automatisch und schlägt eine Transformation vor, die auf die gesamte Spalte angewendet werden kann.
- Wählen Sie „Bearbeiten“ aus.
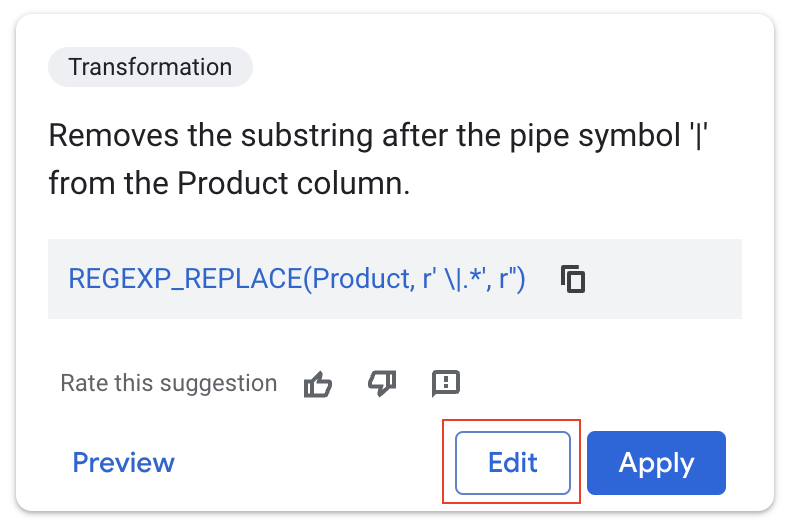
Die Empfehlung von Gemini ist genau richtig: Alles nach dem Zeichen „|“ wird entfernt, sodass nur der Produktname übrig bleibt.
Dieses Mal möchten wir unsere Originaldaten jedoch nicht überschreiben.
- Wählen Sie im Drop-down-Menü für die Zielspalte die Option „Neue Spalte erstellen“ aus.
- Legen Sie ProductName als Name fest.

- Sehen Sie sich die Änderungen in der Vorschau an, um sicherzugehen, dass alles richtig aussieht.
- Wenden Sie die Transformation an.
Produktkategorie extrahieren
Wir verwenden natürliche Sprache, um Gemini anzuweisen, das Wort nach dem senkrechten Strich (|) in der Spalte „Produkt“ zu extrahieren. Der extrahierte Wert wird in die vorhandene Spalte „Produkt“ geschrieben und überschreibt den bisherigen Wert.
- Klicken Sie auf
Add Step, um einen neuen Transformationsschritt hinzuzufügen.
- Wählen Sie im Drop-down-Menü
Transformationaus. - Geben Sie im Feld für den Natural Language Prompt "extract the word after the pipe (|) in the Product column." ein und drücken Sie dann die Eingabetaste, um den SQL-Code zu generieren.
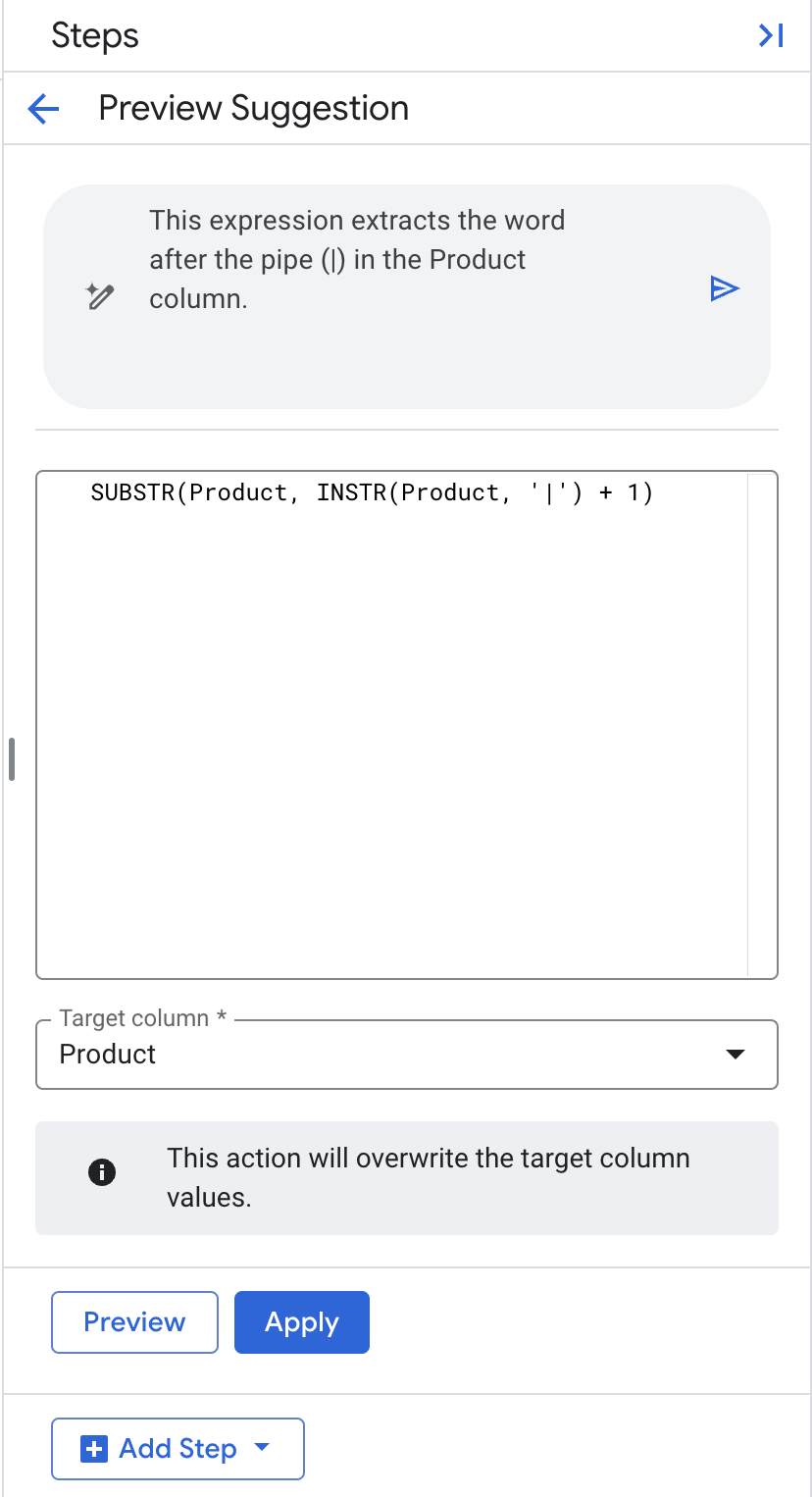
- Lassen Sie die Zielspalte auf „Produkt“ eingestellt.
- Klicken Sie auf Anwenden.
Die Transformation sollte die folgenden Ergebnisse liefern.
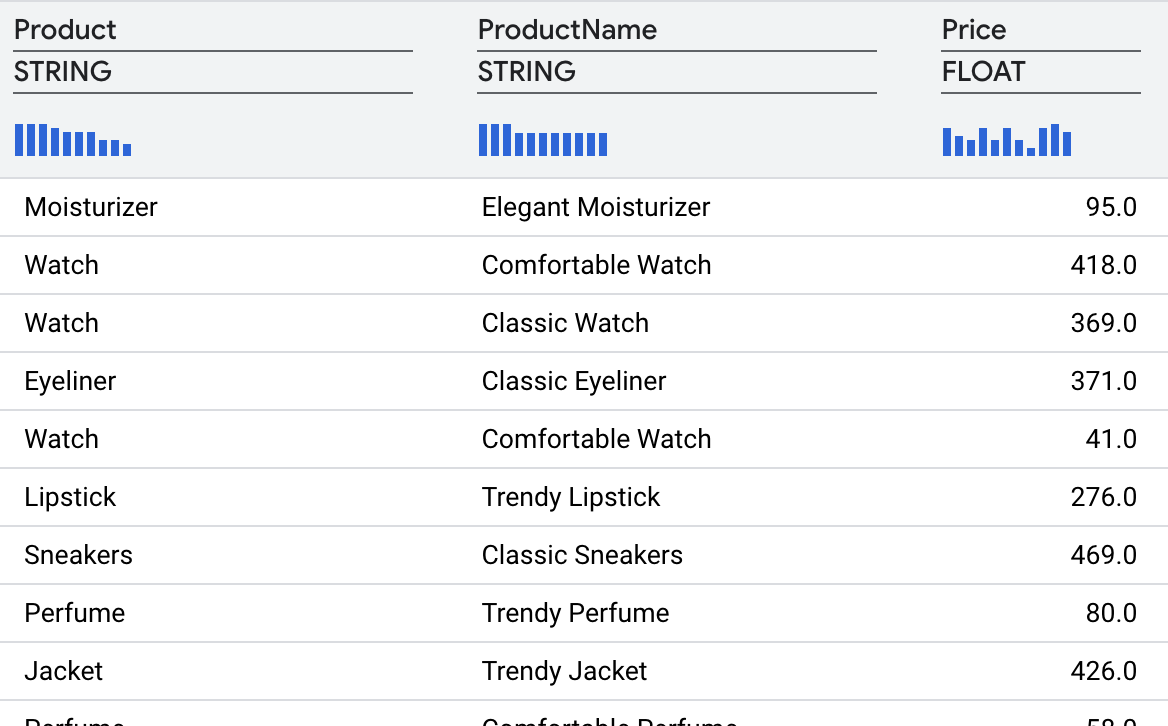
8. Daten durch Joins anreichern
Häufig möchten Sie Ihre Daten mit Informationen aus anderen Quellen anreichern. In unserem Beispiel verknüpfen wir unsere Produktdaten mit erweiterten Produktattributen, stg_extended_product, aus einer Drittanbietertabelle. Diese Tabelle enthält Details wie Marke und Einführungsdatum.
- Klicken Sie auf
Add Step. - „
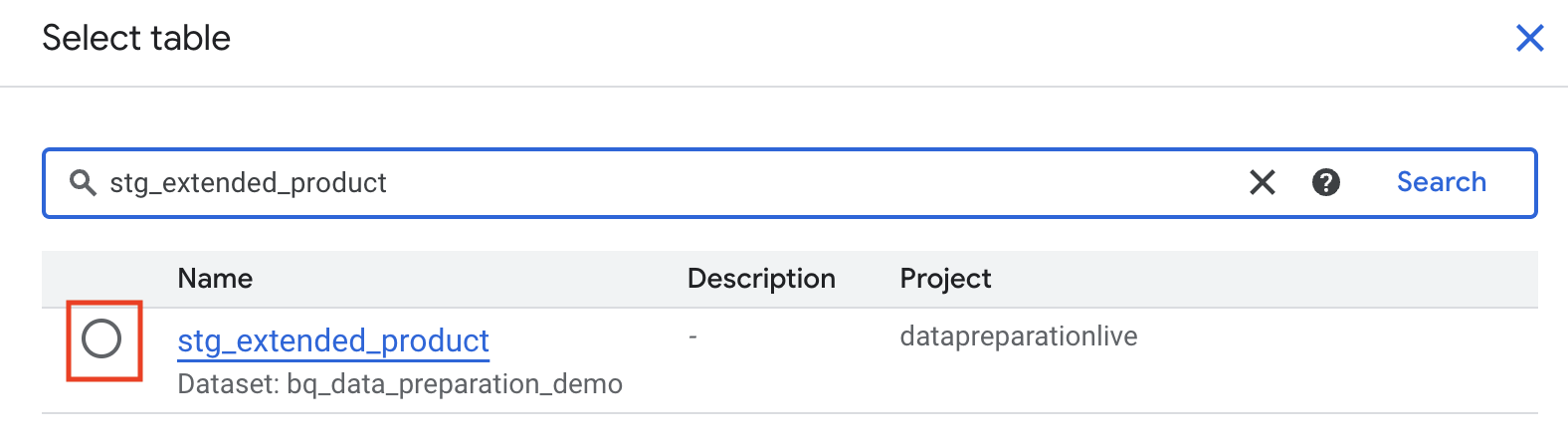
Join“ auswählen - Rufen Sie die Tabelle
stg_extended_productauf.
Gemini in BigQuery hat den Join-Schlüssel „productid“ automatisch für uns ausgewählt und die linke und rechte Seite qualifiziert, da der Schlüsselname identisch ist.
Hinweis: Das Feld „Beschreibung“ muss „Join by productid“ enthalten. Wenn sie zusätzliche Join-Schlüssel enthält, überschreiben Sie das Beschreibungsfeld mit „Join by productid“ und wählen Sie die Schaltfläche „Generieren“ im Beschreibungsfeld aus, um den Join-Ausdruck mit der folgenden Bedingung L. neu zu generieren.
productid
= R.
productid. 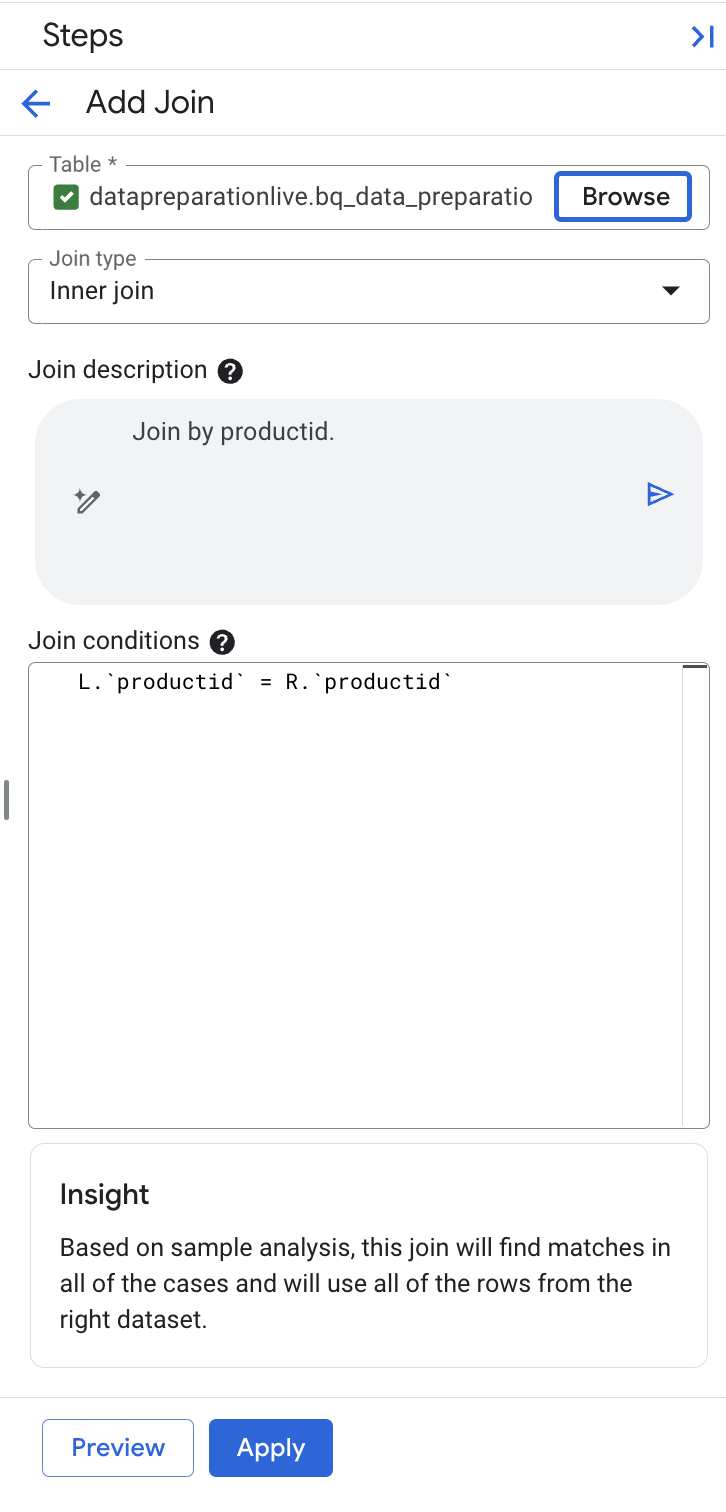
- Optional: Wählen Sie „Vorschau“ aus, um eine Vorschau der Ergebnisse zu sehen.
- Klicken Sie auf
Apply.
Erweiterte Attribute bereinigen
Der Join war zwar erfolgreich, die Daten der erweiterten Attribute müssen aber bereinigt werden. Die Spalte LaunchDate enthält inkonsistente Datumsformate und in der Spalte Brand fehlen einige Werte.
Wir beginnen mit der Spalte LaunchDate.

Sehen Sie sich die Empfehlungen von Gemini an, bevor Sie Transformationen erstellen.
- Klicken Sie auf den Spaltennamen
LaunchDate. Es sollten Empfehlungen ähnlich denen im Bild unten generiert werden.
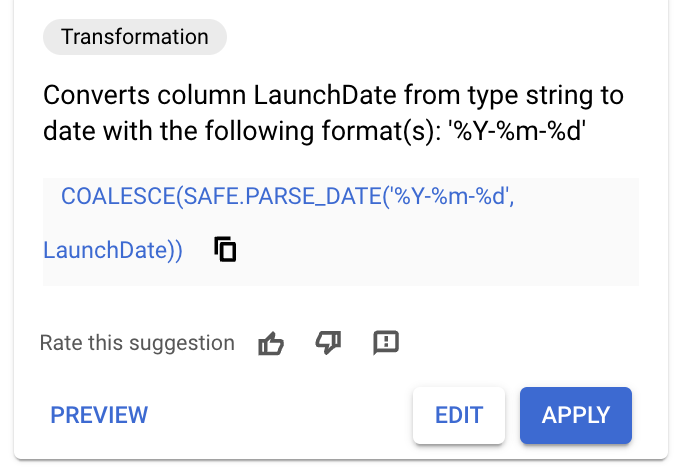
- Wenn Sie eine Empfehlung mit dem folgenden SQL-Code sehen, wenden Sie die Empfehlung an und überspringen Sie die nächsten Schritte.
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- Wenn Sie keine Empfehlung sehen, die dem oben genannten SQL-Code entspricht, klicken Sie auf
Add Step. - Wählen Sie
Transformationaus. - Geben Sie im SQL-Feld Folgendes ein:
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- Setzen Sie den Wert
Target ColumnsaufLaunchDate. - Klicken Sie auf
Apply.
Die Spalte „LaunchDate“ hat jetzt ein einheitliches Datumsformat.

9. Zieltabelle hinzufügen
Unser Dataset ist jetzt bereinigt und kann in eine Dimensionstabelle in unserem Data Warehouse geladen werden.
- Klicken Sie auf
ADD STEP. - Wählen Sie
Destinationaus. - Geben Sie die erforderlichen Parameter ein: „Dataset“:
bq_data_preparation_demo„Tabelle“:DimProduct - Klicken Sie auf
Save.

Wir haben jetzt mit den Tabs „Daten“ und „Schema“ gearbeitet. Zusätzlich dazu bietet die BigQuery-Datenvorbereitung eine „Diagramm“-Ansicht, in der die Reihenfolge der Transformationsschritte in Ihrer Pipeline visuell dargestellt wird.
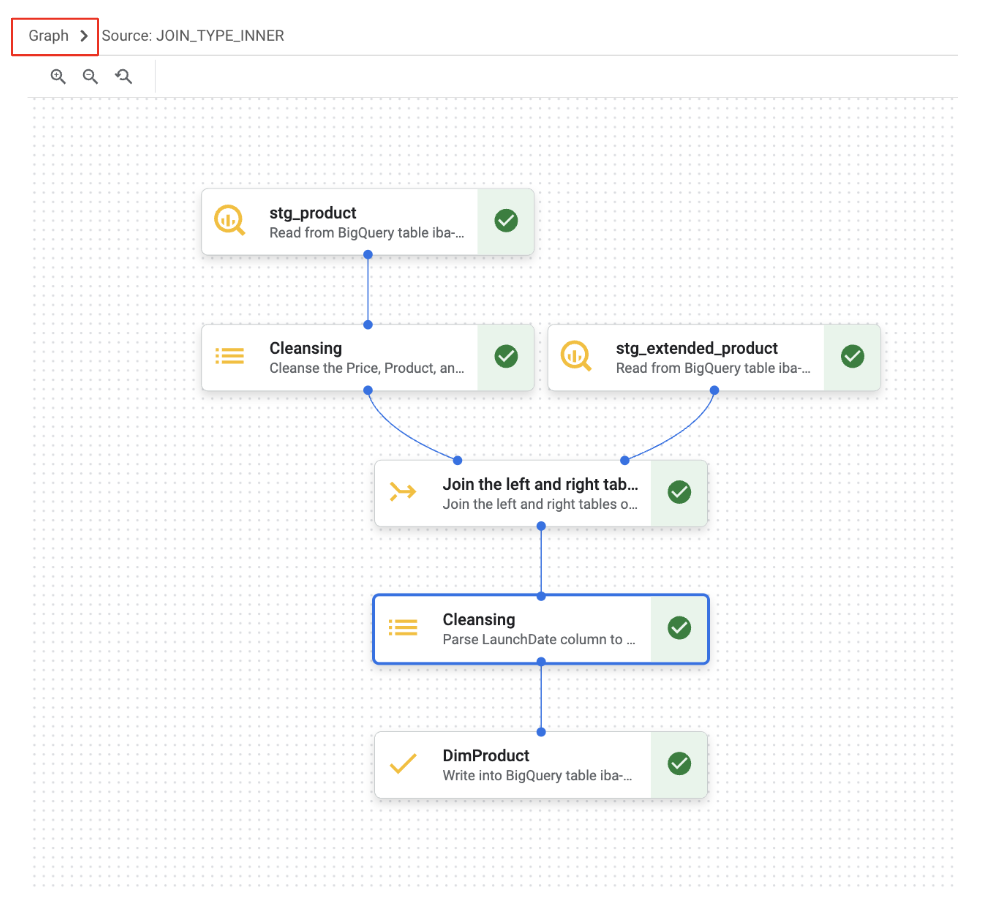
10. Bonus A: Spalte „Hersteller“ verarbeiten und Fehlertabelle erstellen
Außerdem haben wir leere Werte in der Spalte Manufacturer gefunden. Für diese Datensätze möchten wir eine Datenqualitätsprüfung implementieren und sie zur weiteren Überprüfung in eine Fehlertabelle verschieben.
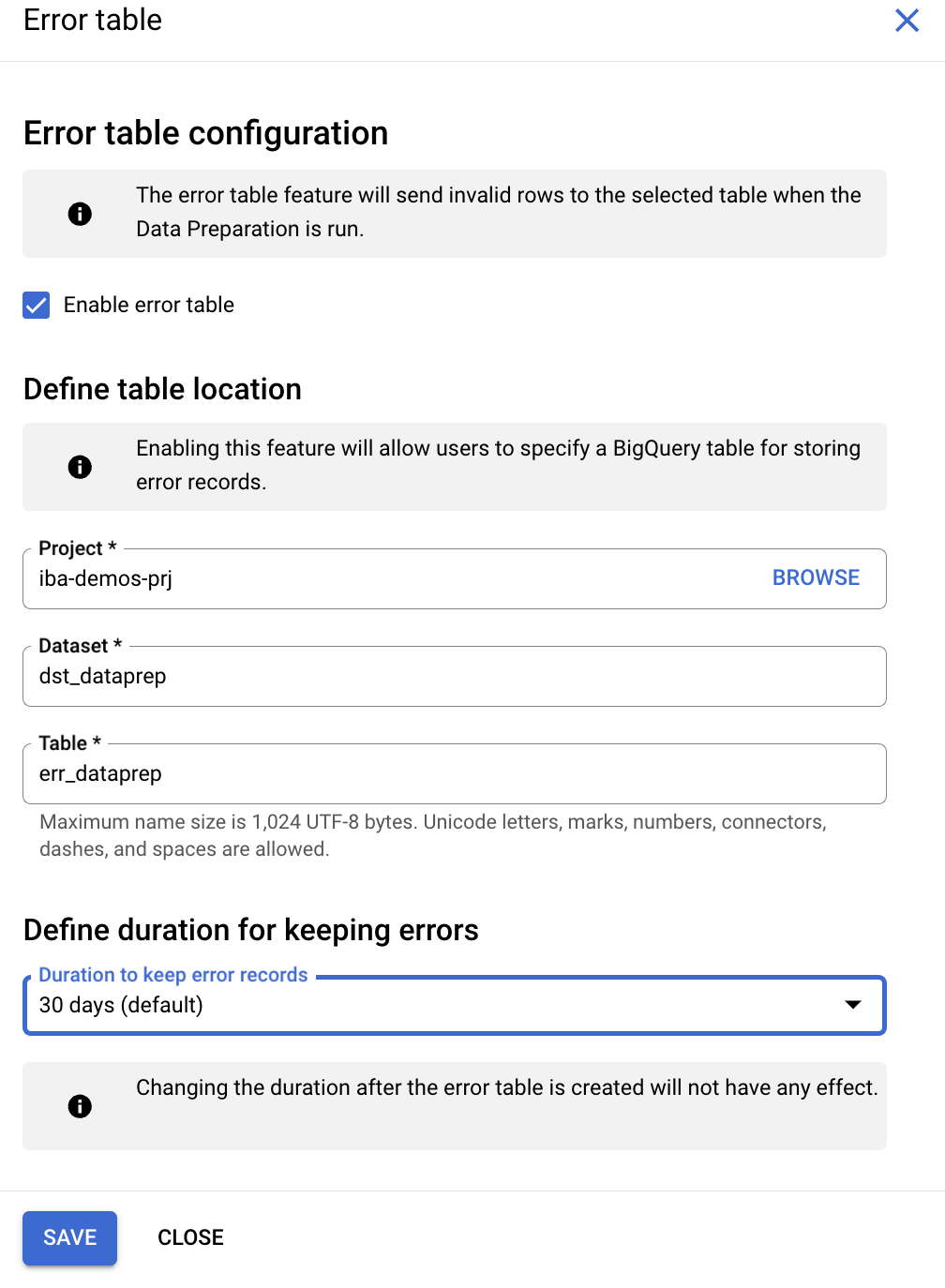
Fehlertabelle erstellen
- Klicken Sie neben dem Titel
stg_product data preparationauf die SchaltflächeMore. - Wählen Sie im Bereich
Settingdie OptionError Tableaus. - Setzen Sie ein Häkchen in das Kästchen
Enable error tableund konfigurieren Sie die Einstellungen so:
- Dataset: Wählen Sie
bq_data_preparation_demoaus. - Tabelle: Geben Sie
err_dataprepein. - Wählen Sie unter
Define duration for keeping errorsdie Option30 days (default)aus.
- Klicken Sie auf
Save.
Validierung für die Spalte „Hersteller“ einrichten
- Wählen Sie die Spalte „Hersteller“ aus.
- Gemini hat wahrscheinlich eine relevante Transformation erkannt. Suchen Sie die Empfehlung, bei der nur Zeilen mit einem nicht leeren Feld „Hersteller“ beibehalten werden. Der SQL-Code sieht in etwa so aus:
Manufacturer IS NOT NULL
2.Klicken Sie bei dieser Empfehlung auf die Schaltfläche „Bearbeiten“, um sie zu prüfen.
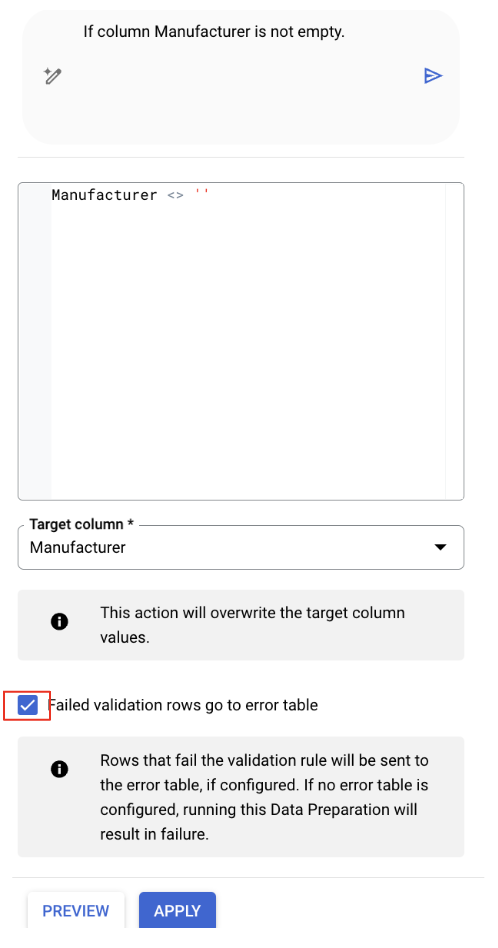
- Aktivieren Sie die Option Zeilen mit fehlgeschlagener Validierung werden an die Fehlertabelle gesendet, falls sie nicht aktiviert ist.
- Klicken Sie auf
Apply.
Sie können die angewendeten Transformationen jederzeit überprüfen, ändern oder löschen, indem Sie auf die Schaltfläche „Angewendete Schritte“ klicken.

Redundante Spalte „ProductID_1“ bereinigen
Die Spalte „ProductID_1“, in der die „ProductID“ aus der zusammengeführten Tabelle dupliziert wird, kann jetzt gelöscht werden.
- Wechseln Sie zum Tab
Schema. - Klicken Sie neben der Spalte
ProductID_1auf das Dreipunkt-Menü. - Klicken Sie auf
Drop.
Jetzt können wir den Job zur Datenvorbereitung ausführen und unsere gesamte Pipeline validieren. Wenn wir mit den Ergebnissen zufrieden sind, können wir den Job so planen, dass er automatisch ausgeführt wird.
- Speichern Sie Ihre Vorbereitungen, bevor Sie die Ansicht zur Datenvorbereitung verlassen. Neben dem Titel
stg_product data preparationsollte die SchaltflächeSaveangezeigt werden. Klicken Sie auf die Schaltfläche, um zu speichern.
11. Umgebung bereinigen
stg_product data preparationlöschen- Dataset
bq data preparation demolöschen
12. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs.
Behandelte Themen
- Datenvorbereitung einrichten
- Tabellen öffnen und Datenvorbereitung durchführen
- Spalten mit numerischen Daten und Einheitenbeschreibung aufteilen
- Datumsformate standardisieren
- Datenvorbereitungen ausführen