
1. نظرة عامة
في هذا المختبر، ستستخدم BigQuery DataFrames من دفتر ملاحظات Python في BigQuery Studio لتنظيف مجموعة البيانات العامة الخاصة بمبيعات المشروبات الكحولية في ولاية آيوا وتحليلها. استفِد من إمكانات BigQuery ML والدوال عن بُعد لاكتشاف الإحصاءات.
ستنشئ ورقة ملاحظات Python لمقارنة المبيعات في مختلف المناطق الجغرافية. يمكن تكييف هذه الطريقة للعمل على أي بيانات منظَّمة.
الأهداف
في هذه الميزة الاختبارية، ستتعرّف على كيفية تنفيذ المهام التالية:
- تفعيل واستخدام دفاتر ملاحظات Python في BigQuery Studio
- الربط بخدمة BigQuery باستخدام حزمة BigQuery DataFrames
- إنشاء انحدار خطّي باستخدام BigQuery ML
- إجراء عمليات تجميع وربط معقّدة باستخدام بنية مألوفة تشبه بنية pandas
2. المتطلبات
قبل البدء
لإكمال التعليمات الواردة في هذا الدرس التطبيقي حول الترميز، يجب أن يكون لديك مشروع على Google Cloud تم تفعيل BigQuery Studio فيه، بالإضافة إلى حساب فوترة مرتبط.
- في Google Cloud Console، ضِمن صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على Google Cloud. كيفية التحقّق من تفعيل الفوترة في مشروع
- اتّبِع التعليمات لتفعيل BigQuery Studio لإدارة مواد العرض.
إعداد BigQuery Studio
أنشئ دفتر ملاحظات فارغًا واربطه بوقت تشغيل.
- انتقِل إلى BigQuery Studio في Google Cloud Console.
- انقر على ▼ بجانب الزر +.
- انقر على ورقة ملاحظات Python.
- أغلِق أداة اختيار النموذج.
- انقر على + رمز لإنشاء خلية رمز جديدة.
- ثبِّت أحدث إصدار من حزمة BigQuery DataFrames من خلية الرمز البرمجي.اكتب الأمر التالي.
%pip install --upgrade bigframes --quiet
3- قراءة مجموعة بيانات عامة
ابدأ حزمة BigQuery DataFrames بتنفيذ ما يلي في خلية رمز جديدة:
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
ملاحظة: في هذا البرنامج التعليمي، نستخدم "وضع الترتيب الجزئي" التجريبي الذي يتيح إجراء طلبات بحث أكثر فعالية عند استخدامه مع الفلترة المشابهة لفلترة pandas. قد لا تعمل بعض ميزات pandas التي تتطلّب ترتيبًا أو فهرسًا صارمًا.
التحقّق من إصدار حزمة bigframes باستخدام
bpd.__version__
يتطلّب هذا البرنامج التعليمي الإصدار 1.27.0 أو إصدارًا أحدث.
مبيعات التجزئة للمشروبات الكحولية في ولاية آيوا
يتم توفير مجموعة بيانات مبيعات التجزئة للمشروبات الكحولية في ولاية آيوا على BigQuery من خلال برنامج مجموعات البيانات العامة في Google Cloud. تحتوي مجموعة البيانات هذه على كل عمليات شراء المشروبات الكحولية بالجملة في ولاية آيوا من قِبل تجار التجزئة لبيعها للأفراد منذ 1 كانون الثاني (يناير) 2012. يتم جمع البيانات من قِبل "قسم المشروبات الكحولية" في "وزارة التجارة في ولاية آيوا".
في BigQuery، أرسِل طلب بحث إلى bigquery-public-data.iowa_liquor_sales.sales لتحليل مبيعات الكحول بالتجزئة في ولاية آيوا. استخدِم طريقة bigframes.pandas.read_gbq() لإنشاء DataFrame من سلسلة طلب بحث أو رقم تعريف جدول.
نفِّذ ما يلي في خلية رمز جديدة لإنشاء DataFrame باسم "df":
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
التعرّف على المعلومات الأساسية حول DataFrame
استخدِم طريقة DataFrame.peek() لتنزيل عيّنة صغيرة من البيانات.
شغِّل هذه الخلية:
df.peek()
الناتج المتوقّع:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
ملاحظة: يتطلّب head() الترتيب وهو أقل كفاءة بشكل عام من peek() إذا كنت تريد عرض عيّنة من البيانات.
كما هو الحال مع مكتبة pandas، استخدِم السمة DataFrame.dtypes لعرض جميع الأعمدة المتاحة وأنواع البيانات المقابلة لها. يتم عرضها بطريقة متوافقة مع مكتبة pandas.
شغِّل هذه الخلية:
df.dtypes
الناتج المتوقّع:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
تستعلم طريقة DataFrame.describe() عن بعض الإحصاءات الأساسية من DataFrame. نفِّذ DataFrame.to_pandas() لتنزيل هذه الإحصاءات الموجزة كـ pandas DataFrame.
شغِّل هذه الخلية:
df.describe("all").to_pandas()
الناتج المتوقّع:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
4. تصوُّر البيانات وتنظيفها
تقدّم مجموعة بيانات مبيعات المشروبات الكحولية بالتجزئة في ولاية آيوا معلومات جغرافية دقيقة، بما في ذلك مواقع متاجر البيع بالتجزئة. استخدِم هذه البيانات لتحديد المؤشرات والاختلافات في المناطق الجغرافية.
عرض المبيعات حسب الرمز البريدي
تتوفّر عدة طرق مضمّنة للتمثيل المرئي، مثل DataFrame.plot.hist(). استخدِم هذه الطريقة لمقارنة مبيعات المشروبات الكحولية حسب الرمز البريدي.
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
الناتج المتوقّع:
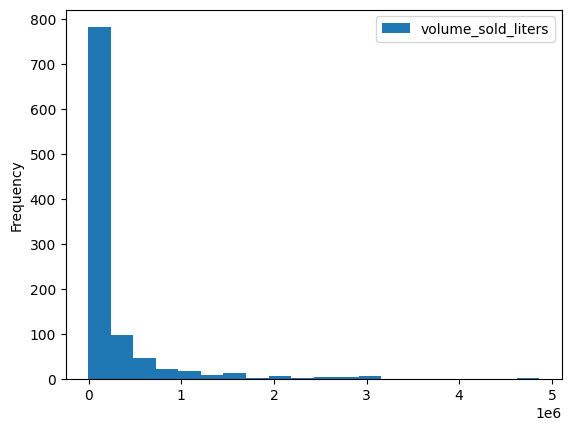
استخدِم رسمًا بيانيًا شريطيًا لمعرفة الرموز البريدية التي حقّقت أكبر مبيعات من المشروبات الكحولية.
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
الناتج المتوقّع:
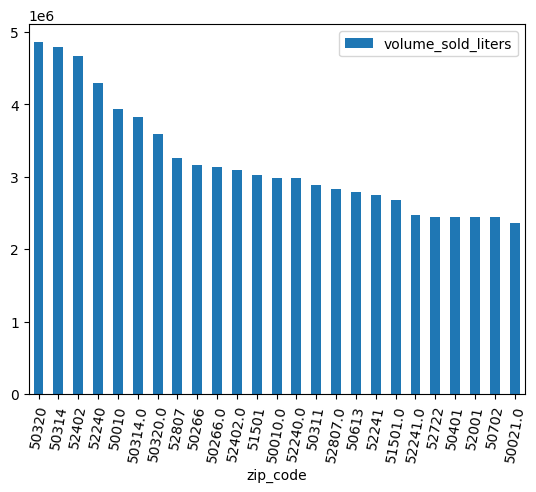
تنظيف البيانات
تحتوي بعض الرموز البريدية على .0 في نهايتها. من المحتمل أنّه تم تحويل الرموز البريدية عن طريق الخطأ إلى قيم نقطة عائمة في مكان ما أثناء عملية جمع البيانات. استخدِم التعبيرات العادية لتنظيف الرموز البريدية وكرِّر التحليل.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
الناتج المتوقّع:
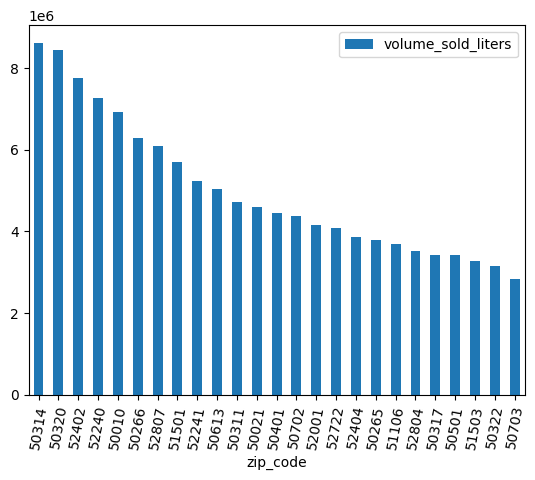
5- اكتشاف الارتباطات في المبيعات
لماذا تبيع بعض الرموز البريدية أكثر من غيرها؟ إحدى الفرضيات هي أنّ السبب يعود إلى الاختلافات في حجم السكان. من المرجّح أن يحقّق الرمز البريدي الذي يضم عددًا أكبر من السكان مبيعات أعلى من المشروبات الكحولية.
اختبِر هذه الفرضية من خلال احتساب الارتباط بين عدد السكان وحجم مبيعات المشروبات الكحولية.
الربط بمجموعات بيانات أخرى
يمكنك الربط بمجموعة بيانات سكانية، مثل مسح مكتب الإحصاء الأمريكي التابع لمكتب تعداد الولايات المتحدة لمناطق التبويب الخاصة بالرموز البريدية.
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
تحدّد هيئة American Community Survey الولايات حسب GEOID. في حالة مناطق التبويب حسب الرمز البريدي، يكون GEOID مساويًا للرمز البريدي.
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
أنشئ رسمًا بيانيًا بالنقاط المبعثرة لمقارنة عدد سكان منطقة التجميع حسب الرمز البريدي بكمية الكحول المباعة باللتر.
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
الناتج المتوقّع:
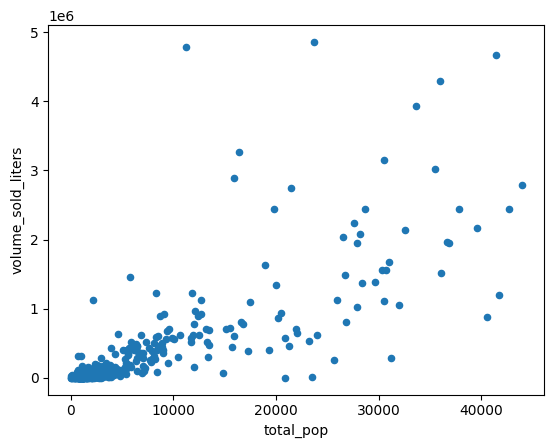
حساب الارتباطات
يبدو المؤشر خطيًا إلى حدّ كبير. يمكنك إنشاء نموذج انحدار خطي لهذا الغرض لمعرفة مدى قدرة عدد السكان على توقّع مبيعات المشروبات الكحولية.
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
يمكنك التحقّق من مدى تطابقها باستخدام طريقة score.
model.score(feature_columns, label_columns).to_pandas()
نموذج الناتج:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
ارسم خط أفضل تطابق من خلال استدعاء الدالة predict على مجموعة من قيم المحتوى (الجمهرة).
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
الناتج المتوقّع:
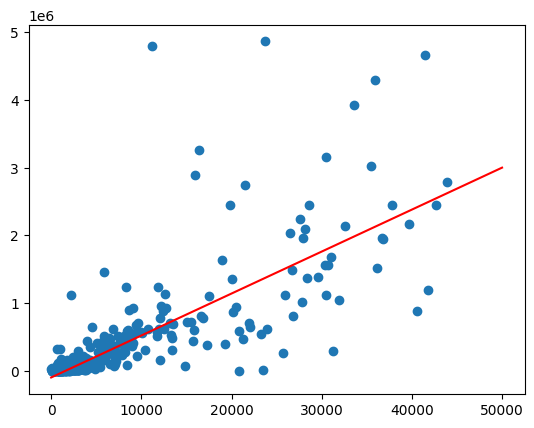
معالجة التباين غير المتساوي
يبدو أنّ البيانات في الرسم البياني السابق غير متجانسة التباين. يزداد التباين حول خط أفضل تطابق مع عدد السكان.
ربما يكون مقدار الكحول الذي يتم شراؤه لكل شخص ثابتًا نسبيًا.
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
الناتج المتوقّع:
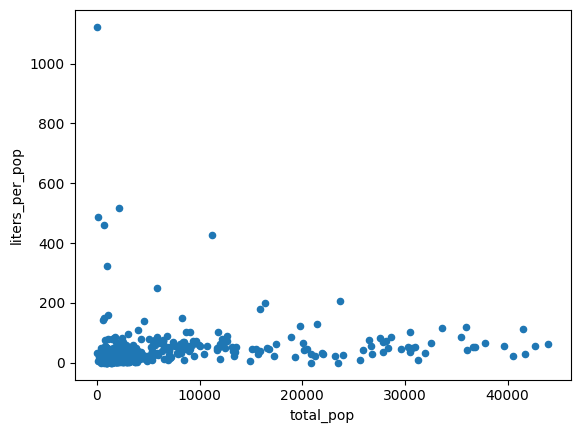
احتسِب متوسط لترات الكحول التي تم شراؤها بطريقتَين مختلفتَين:
- ما هو متوسط كمية الكحول التي يتم شراؤها لكل شخص في ولاية آيوا؟
- ما هو متوسط كمية الكحول التي تم شراؤها لكل شخص في جميع الرموز البريدية؟
في (1)، يعكس هذا الرقم مقدار الكحول الذي يتم شراؤه في الولاية بأكملها. في (2)، يعكس هذا المقياس متوسط الرمز البريدي، والذي لن يكون بالضرورة هو نفسه (1) لأنّ الرموز البريدية المختلفة تضم أعدادًا مختلفة من السكان.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
الناتج المتوقّع: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
الناتج المتوقّع: 67.139
ارسم هذه المتوسطات، كما هو موضح أعلاه.
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
الناتج المتوقّع:
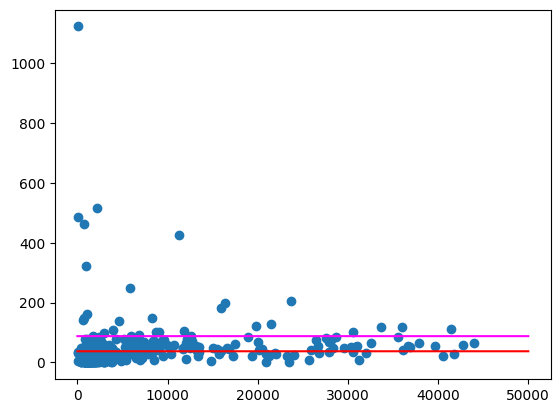
لا تزال هناك بعض الرموز البريدية التي تشكّل قيمًا متطرفة كبيرة جدًا، خاصةً في المناطق التي يقل فيها عدد السكان. نترك لك مهمة وضع فرضية لتفسير ذلك، مثلاً قد يكون بعض الرموز البريدية ذات عدد سكان منخفض ولكن معدل استهلاك مرتفع لأنّها تحتوي على متجر المشروبات الكحولية الوحيد في المنطقة. في هذه الحالة، قد يؤدي احتساب متوسط عدد السكان استنادًا إلى الرموز البريدية المحيطة إلى تسوية هذه القيم الشاذة.
6. مقارنة أنواع المشروبات الكحولية المباعة
بالإضافة إلى البيانات الجغرافية، تحتوي قاعدة بيانات مبيعات المشروبات الكحولية بالتجزئة في ولاية آيوا أيضًا على معلومات مفصّلة حول السلعة المباعة. ومن خلال تحليل هذه البيانات، يمكننا الكشف عن الاختلافات في الأذواق بين المناطق الجغرافية المختلفة.
عرض الفئات
يتم تصنيف العناصر في قاعدة البيانات. كم عدد الفئات؟
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
الناتج المتوقّع: 103
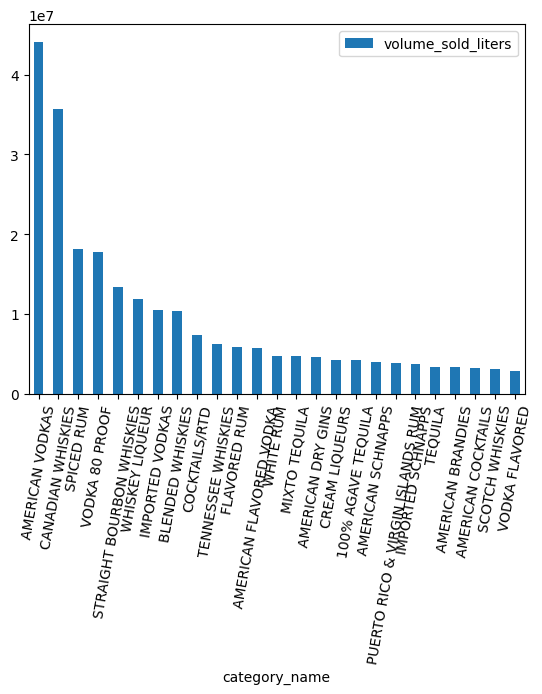
ما هي الفئات الأكثر رواجًا حسب الحجم؟
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
العمل باستخدام نوع البيانات ARRAY
تتوفّر عدة فئات من كل من الويسكي والروم والفودكا وغيرها. أريد تجميع هذه الصور معًا بطريقة ما.
ابدأ بتقسيم أسماء الفئات إلى كلمات منفصلة باستخدام طريقة Series.str.split(). يمكنك إلغاء تداخل الصفيفة التي يتم إنشاؤها باستخدام الطريقة explode().
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
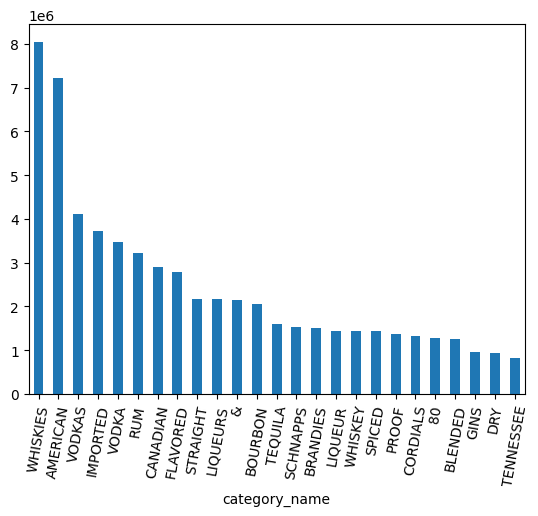
category_parts.nunique()
الناتج المتوقّع: 113
بالنظر إلى الرسم البياني أعلاه، لا تزال البيانات تتضمّن VODKA منفصلة عن VODKAS. يجب إجراء المزيد من التجميع لتصغير عدد الفئات.
7. استخدام NLTK مع إطارات بيانات BigQuery
مع توفّر 100 فئة فقط، سيكون من الممكن كتابة بعض الإرشادات أو حتى إنشاء عملية ربط يدويًا من الفئة إلى نوع المشروبات الكحولية الأوسع. بدلاً من ذلك، يمكن استخدام نموذج لغوي كبير، مثل Gemini، لإنشاء عملية الربط هذه. جرِّب برنامج التدريب العملي الحصول على إحصاءات من بيانات غير منظَّمة باستخدام BigQuery DataFrames لاستخدام BigQuery DataFrames مع Gemini.
بدلاً من ذلك، استخدِم حزمة معالجة لغة طبيعية أكثر تقليدية، وهي NLTK، لمعالجة هذه البيانات. يمكن لتقنية تُعرف باسم "التقطيع" دمج الأسماء الجمع والمفرد في القيمة نفسها، على سبيل المثال.
استخدام NLTK لتحديد جذور الكلمات
توفّر حزمة NLTK طرقًا لمعالجة اللغات الطبيعية يمكن الوصول إليها من Python. ثبِّت الحزمة لتجربتها.
%pip install nltk
بعد ذلك، استورِد الحزمة. فحص الإصدار سيتم استخدامها لاحقًا في البرنامج التعليمي.
import nltk
nltk.__version__
إحدى طرق توحيد الكلمات هي "تجزئة" الكلمة. يزيل هذا الإجراء أي لاحقات، مثل حرف "s" في نهاية الكلمات الدالة على الجمع.
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
جرِّب هذه الميزة على بضع كلمات.
stem("WHISKEY")
الناتج المتوقّع: whiskey
stem("WHISKIES")
الناتج المتوقّع: whiski
لسوء الحظ، لم يتم ربط الويسكي بالويسكي نفسه. لا تعمل أدوات التقطيع بشكل جيد مع صيغ الجمع غير المنتظمة. جرِّب استخدام أداة تحليل صرفي، وهي تستخدم تقنيات أكثر تطورًا لتحديد الكلمة الأساسية، والتي تُعرف باسم "الصيغة الأصلية".
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
جرِّب هذه الميزة على بضع كلمات.
lemmatize("WHISKIES")
الناتج المتوقّع: whisky
lemmatize("WHISKY")
الناتج المتوقّع: whisky
lemmatize("WHISKEY")
الناتج المتوقّع: whiskey
لسوء الحظ، لا يربط هذا المحلّل الصرفي بين الكلمة الأساسية "whiskey" والكلمة الأساسية نفسها "whiskies". بما أنّ هذه الكلمة مهمة بشكل خاص لقاعدة بيانات مبيعات المشروبات الكحولية بالتجزئة في ولاية آيوا، يمكنك ربطها يدويًا بالتهجئة الأمريكية باستخدام قاموس.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
جرِّب هذه الميزة على بضع كلمات.
lemmatize("WHISKIES")
الناتج المتوقّع: whiskey
lemmatize("WHISKEY")
الناتج المتوقّع: whiskey
تهانينا! من المفترض أن يعمل هذا المحلّل اللغوي بشكلٍ جيد لتضييق نطاق الفئات. لاستخدامها مع BigQuery، يجب نشرها على السحابة الإلكترونية.
إعداد مشروعك لنشر الدوال
قبل نشر هذا الإجراء على السحابة الإلكترونية ليتمكّن BigQuery من الوصول إليه، عليك إجراء بعض عمليات الإعداد لمرة واحدة.
أنشئ خلية رمز جديدة واستبدِل your-project-id برقم تعريف مشروع Google Cloud الذي تستخدمه في هذا البرنامج التعليمي.
project_id = "your-project-id"
أنشئ حساب خدمة بدون أي أذونات، لأنّ هذه الدالة لا تحتاج إلى الوصول إلى أي موارد على السحابة الإلكترونية.
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
الناتج المتوقّع: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
أنشئ مجموعة بيانات في BigQuery لتضمين الدالة.
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
نشر دالة عن بُعد
فعِّل واجهة برمجة التطبيقات Cloud Functions API إذا لم يسبق لك تفعيلها.
!gcloud services enable cloudfunctions.googleapis.com
الآن، يمكنك نشر الدالة في مجموعة البيانات التي أنشأتها للتو. أضِف أداة تزيين @bpd.remote_function إلى الدالة التي أنشأتها في الخطوات السابقة.
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
من المفترض أن تستغرق عملية النشر حوالي دقيقتَين.
استخدام وظائف جهاز التحكّم عن بُعد
بعد اكتمال عملية النشر، يمكنك اختبار هذه الدالة.
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
الناتج المتوقّع:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
8. مقارنة استهلاك الكحول حسب المقاطعة
بعد أن أصبحت الدالة lemmatize متاحة، استخدِمها لدمج الفئات.
العثور على الكلمة التي تلخّص الفئة على أفضل نحو
أولاً، أنشئ DataFrame لجميع الفئات في قاعدة البيانات.
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
الناتج المتوقّع:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
بعد ذلك، أنشئ DataFrame يتضمّن جميع الكلمات في الفئات، باستثناء بعض الكلمات الحشو، مثل علامات الترقيم و "السلعة".
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
الناتج المتوقّع:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
يُرجى العِلم أنّه من خلال إجراء عملية التقطيع بعد التجميع، يمكنك تقليل الحمل على Cloud Function. من الممكن تطبيق دالة التقطيع على كل صف من الصفوف العديدة في قاعدة البيانات، ولكن سيكلّف ذلك أكثر من تطبيقها بعد التجميع وقد يتطلّب زيادة الحصة.
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
الناتج المتوقّع:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
بعد أن تمّت عملية التقطيع، عليك اختيار الكلمة الأساسية التي تلخّص الفئة على أفضل نحو. بما أنّه لا توجد العديد من الكلمات الوظيفية في الفئات، استخدِم قاعدة الاستدلال التي تنص على أنّه إذا ظهرت كلمة في عدة فئات أخرى، من المرجّح أن تكون أفضل ككلمة تلخيصية (مثل الويسكي).
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
الناتج المتوقّع:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
بعد أن أصبح هناك كلمة أساسية واحدة تلخّص كل فئة، ادمجها مع إطار البيانات الأصلي.
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
الناتج المتوقّع:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
مقارنة المقاطعات
قارِن المبيعات في كل مقاطعة لمعرفة الاختلافات.
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
ابحث عن المنتج الأكثر مبيعًا (الكلمة الأساسية) في كل مقاطعة.
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
الناتج المتوقّع:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
ما مدى اختلاف المقاطعات عن بعضها البعض؟
county_max_lemma.groupby("lemma").size().to_pandas()
الناتج المتوقّع:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
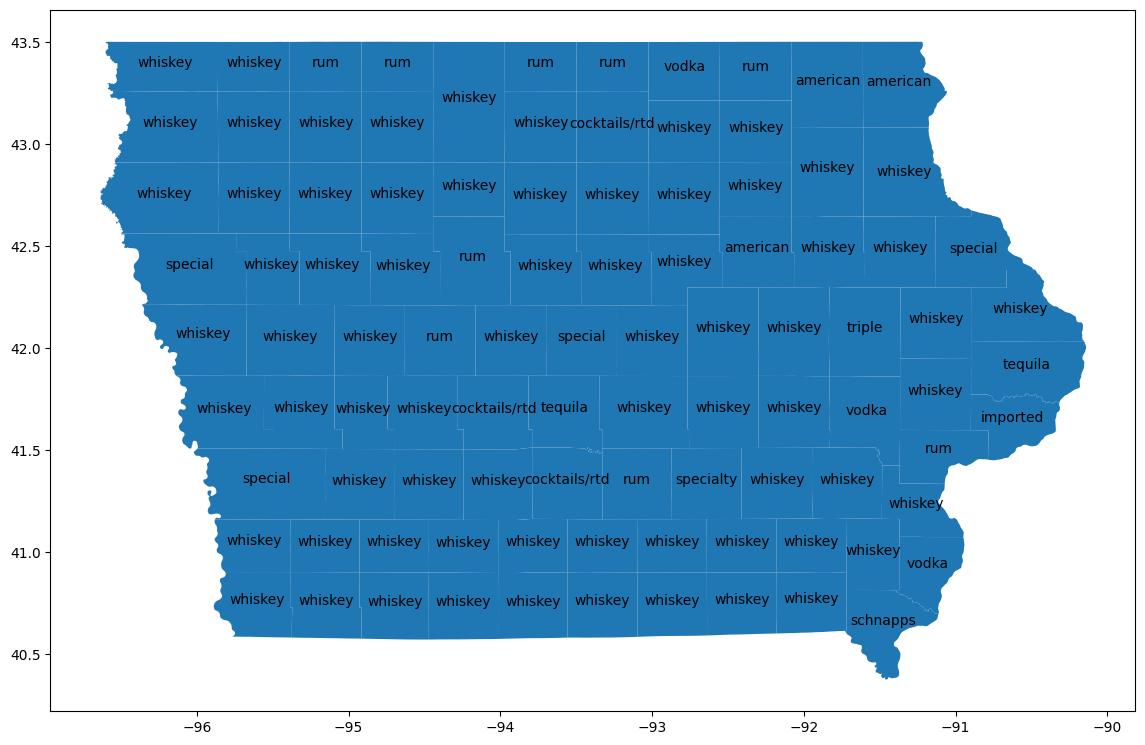
في معظم المقاطعات، يكون الويسكي هو المنتج الأكثر رواجًا من حيث الحجم، بينما يكون الفودكا هو الأكثر رواجًا في 15 مقاطعة. قارِن ذلك بأنواع المشروبات الكحولية الأكثر رواجًا على مستوى الولاية.
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
الناتج المتوقّع:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
يبلغ حجم استهلاك الويسكي والفودكا المستوى نفسه تقريبًا، مع ارتفاع حجم استهلاك الفودكا قليلاً عن الويسكي على مستوى الولاية.
مقارنة النسب
ما هي الميزة الفريدة للمبيعات في كل مقاطعة؟ ما الذي يميّز المقاطعة عن بقية الولاية؟
استخدِم مقياس Cohen's h لمعرفة أحجام مبيعات المشروبات الكحولية التي تختلف بشكل كبير عن المتوقّع استنادًا إلى نسبة المبيعات على مستوى الولاية.
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
بعد قياس إحصاءة Cohen's h لكل كلمة أساسية، ابحث عن أكبر فرق عن النسبة على مستوى الولاية في كل مقاطعة.
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
الناتج المتوقّع:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
كلّما زادت قيمة h لكوهين، زاد احتمال وجود فرق ذي دلالة إحصائية في كمية هذا النوع من الكحول المستهلك مقارنةً بمتوسطات الولاية. بالنسبة إلى القيم الموجبة الأصغر، يختلف استهلاك الطاقة عن المتوسط على مستوى الولاية، ولكن قد يرجع ذلك إلى اختلافات عشوائية.
ملاحظة جانبية: لا يبدو أنّ مقاطعة EL PASO هي مقاطعة في ولاية آيوا، وقد يشير ذلك إلى ضرورة أخرى لتنظيف البيانات قبل الاعتماد بشكل كامل على هذه النتائج.
عرض المقاطعات
انضم إلى جدول bigquery-public-data.geo_us_boundaries.counties للحصول على المنطقة الجغرافية لكل مقاطعة. أسماء المقاطعات ليست فريدة في جميع أنحاء الولايات المتحدة، لذا عليك الفلترة لتضمين المقاطعات من ولاية آيوا فقط. رمز FIPS لولاية آيوا هو "19".
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
الناتج المتوقّع:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
استخدِم GeoPandas لعرض هذه الاختلافات على خريطة.
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)
9- تَنظيم
إذا أنشأت مشروعًا جديدًا على السحابة الإلكترونية لهذا البرنامج التعليمي، يمكنك حذفه لمنع تحصيل رسوم إضافية مقابل الجداول أو الموارد الأخرى التي تم إنشاؤها.
بدلاً من ذلك، احذف وظائف Cloud Functions وحسابات الخدمة ومجموعات البيانات التي تم إنشاؤها لهذا البرنامج التعليمي.
10. تهانينا!
لقد نظّفت البيانات المنظَّمة وحلّلتها باستخدام BigQuery DataFrames. خلال هذه الرحلة، استكشفت مجموعات البيانات العامة في Google Cloud، ودفاتر ملاحظات Python في BigQuery Studio، وBigQuery ML، وBigQuery Remote Functions، وقوة BigQuery DataFrames. أحسنت!
الخطوات التالية
- طبِّق هذه الخطوات على بيانات أخرى، مثل قاعدة بيانات الأسماء في الولايات المتحدة.
- جرِّب إنشاء رمز Python في دفتر ملاحظاتك. تستند أوراق ملاحظات Python في BigQuery Studio إلى Colab Enterprise. ملاحظة: أجد أنّ طلب المساعدة في إنشاء بيانات اختبار مفيد جدًا.
- استكشِف دفاتر الملاحظات النموذجية لإطارات بيانات BigQuery على GitHub.
- أنشئ جدولاً زمنيًا لتشغيل دفتر ملاحظات في BigQuery Studio.
- يمكنك نشر دالة عن بُعد باستخدام BigQuery DataFrames لدمج حِزم Python التابعة لجهات خارجية مع BigQuery.