
১. সংক্ষিপ্ত বিবরণ
এই ল্যাবে, আপনি BigQuery Studio-তে একটি পাইথন নোটবুক থেকে BigQuery DataFrames ব্যবহার করে Iowa liquor sales public ডেটাসেটটি পরিষ্করণ ও বিশ্লেষণ করবেন। ইনসাইট আবিষ্কার করতে BigQuery ML এবং remote function-এর সক্ষমতা কাজে লাগান।
আপনি বিভিন্ন ভৌগোলিক অঞ্চলের বিক্রয় তুলনা করার জন্য একটি পাইথন নোটবুক তৈরি করবেন। এটি যেকোনো স্ট্রাকচার্ড ডেটার ওপর কাজ করার জন্য অভিযোজিত করা যেতে পারে।
উদ্দেশ্য
এই ল্যাবে, আপনি নিম্নলিখিত কাজগুলো কীভাবে সম্পাদন করতে হয় তা শিখবেন:
- BigQuery Studio-তে পাইথন নোটবুক সক্রিয় করুন এবং ব্যবহার করুন।
- BigQuery DataFrames প্যাকেজ ব্যবহার করে BigQuery-এর সাথে সংযোগ করুন
- BigQuery ML ব্যবহার করে একটি লিনিয়ার রিগ্রেশন তৈরি করুন।
- পরিচিত পান্ডাস-সদৃশ সিনট্যাক্স ব্যবহার করে জটিল অ্যাগ্রিগেশন এবং জয়েন সম্পাদন করুন।
২. প্রয়োজনীয়তা
- ক্রোম বা ফায়ারফক্সের মতো একটি ব্রাউজার
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট
শুরু করার আগে
এই কোডল্যাবের নির্দেশাবলী অনুসরণ করার জন্য, আপনার BigQuery Studio সক্রিয় করা একটি Google Cloud Project এবং একটি সংযুক্ত বিলিং অ্যাকাউন্ট প্রয়োজন হবে।
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার গুগল ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন তা জানুন।
- অ্যাসেট ম্যানেজমেন্টের জন্য BigQuery Studio সক্রিয় করতে নির্দেশাবলী অনুসরণ করুন।
BigQuery Studio প্রস্তুত করুন
একটি খালি নোটবুক তৈরি করুন এবং এটিকে রানটাইমের সাথে সংযুক্ত করুন।
- গুগল ক্লাউড কনসোলে BigQuery Studio- তে যান।
- + বাটনের পাশে থাকা ▼ চিহ্নটিতে ক্লিক করুন।
- পাইথন নোটবুক নির্বাচন করুন।
- টেমপ্লেট নির্বাচকটি বন্ধ করুন।
- নতুন কোড সেল তৈরি করতে + কোড নির্বাচন করুন।
- কোড সেল থেকে BigQuery DataFrames প্যাকেজের সর্বশেষ সংস্করণটি ইনস্টল করতে নিম্নলিখিত কমান্ডটি টাইপ করুন।
%pip install --upgrade bigframes --quiet
৩. একটি পাবলিক ডেটাসেট পড়ুন
একটি নতুন কোড সেলে নিম্নলিখিতটি চালিয়ে BigQuery DataFrames প্যাকেজটি ইনিশিয়ালাইজ করুন:
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
দ্রষ্টব্য: এই টিউটোরিয়ালে আমরা পরীক্ষামূলক 'পার্শিয়াল অর্ডারিং মোড' ব্যবহার করছি, যা পান্ডাস-সদৃশ ফিল্টারিংয়ের সাথে ব্যবহার করলে আরও কার্যকর কোয়েরি করতে সাহায্য করে। পান্ডাসের কিছু ফিচার, যেগুলোর জন্য কঠোর অর্ডারিং বা ইনডেক্স প্রয়োজন, সেগুলো কাজ নাও করতে পারে।
আপনার bigframes প্যাকেজ সংস্করণটি যাচাই করুন
bpd.__version__
এই টিউটোরিয়ালটির জন্য ভার্সন ১.২৭.০ বা তার পরবর্তী সংস্করণ প্রয়োজন।
আইওয়া মদের খুচরা বিক্রয়
আইওয়া মদের খুচরা বিক্রয় ডেটাসেটটি গুগল ক্লাউডের পাবলিক ডেটাসেট প্রোগ্রামের মাধ্যমে বিগকোয়েরিতে সরবরাহ করা হয়েছে। এই ডেটাসেটটিতে ১ জানুয়ারী, ২০১২ থেকে আইওয়া রাজ্যে খুচরা বিক্রেতাদের দ্বারা ব্যক্তিদের কাছে বিক্রয়ের জন্য মদের প্রতিটি পাইকারি ক্রয়ের তথ্য রয়েছে। আইওয়া বাণিজ্য বিভাগের অধীনস্থ অ্যালকোহলিক বেভারেজেস ডিভিশন এই ডেটা সংগ্রহ করে।
BigQuery-তে, আইওয়ার মদের খুচরা বিক্রয় বিশ্লেষণ করতে bigquery-public-data.iowa_liquor_sales.sales কোয়েরিটি চালান। কোয়েরি স্ট্রিং বা টেবিল আইডি থেকে একটি ডেটাফ্রেম তৈরি করতে bigframes.pandas.read_gbq() মেথডটি ব্যবহার করুন।
'df' নামের একটি ডেটাফ্রেম তৈরি করতে একটি নতুন কোড সেলে নিম্নলিখিত কোডটি চালান:
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
একটি ডেটাফ্রেম সম্পর্কে প্রাথমিক তথ্য জানুন
ডেটার একটি ছোট নমুনা ডাউনলোড করতে DataFrame.peek() মেথডটি ব্যবহার করুন।
এই সেলটি চালান:
df.peek()
প্রত্যাশিত আউটপুট:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
দ্রষ্টব্য: head() ফাংশনে ডেটা সাজানোর প্রয়োজন হয় এবং ডেটার একটি নমুনা ভিজ্যুয়ালাইজ করতে চাইলে এটি সাধারণত peek() চেয়ে কম কার্যকর।
পান্ডাসের মতোই, সমস্ত উপলব্ধ কলাম এবং তাদের সংশ্লিষ্ট ডেটা টাইপ দেখতে DataFrame.dtypes প্রপার্টিটি ব্যবহার করুন। এগুলো পান্ডাস-সামঞ্জস্যপূর্ণ উপায়ে প্রদর্শিত হয়।
এই সেলটি চালান:
df.dtypes
প্রত্যাশিত আউটপুট:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
DataFrame.describe() মেথডটি DataFrame থেকে কিছু প্রাথমিক পরিসংখ্যান কোয়েরি করে। এই সারসংক্ষেপ পরিসংখ্যানগুলো একটি pandas DataFrame হিসেবে ডাউনলোড করতে DataFrame.to_pandas() রান করুন।
এই সেলটি চালান:
df.describe("all").to_pandas()
প্রত্যাশিত আউটপুট:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
৪. ডেটা দৃশ্যায়ন ও পরিষ্করণ করুন
আইওয়া মদের খুচরা বিক্রয় ডেটাসেটটি খুচরা দোকানগুলোর অবস্থান সহ সূক্ষ্ম ভৌগোলিক তথ্য প্রদান করে। বিভিন্ন ভৌগোলিক অঞ্চলের মধ্যে প্রবণতা এবং পার্থক্য শনাক্ত করতে এই ডেটা ব্যবহার করুন।
জিপ কোড অনুযায়ী বিক্রয়ের চিত্রায়ন করুন
DataFrame.plot.hist() -এর মতো বেশ কিছু বিল্ট-ইন ভিজ্যুয়ালাইজেশন মেথড রয়েছে। জিপ কোড অনুযায়ী মদের বিক্রয় তুলনা করতে এই মেথডটি ব্যবহার করুন।
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
প্রত্যাশিত আউটপুট:
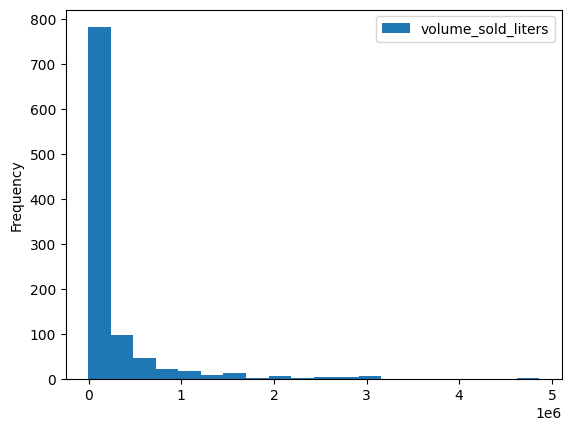
কোন জিপ কোড সবচেয়ে বেশি অ্যালকোহল বিক্রি করেছে তা দেখতে একটি বার চার্ট ব্যবহার করুন।
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
প্রত্যাশিত আউটপুট:
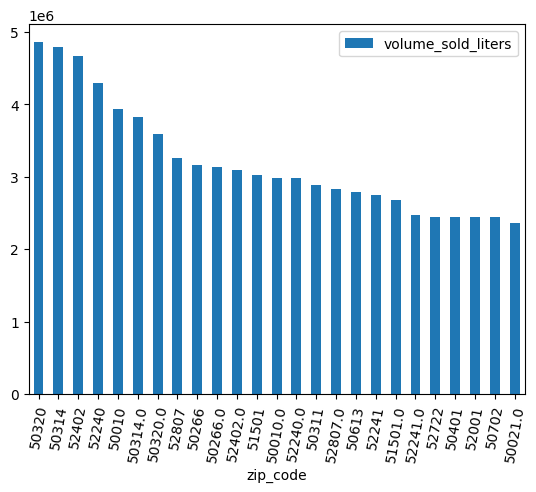
ডেটা পরিষ্কার করুন
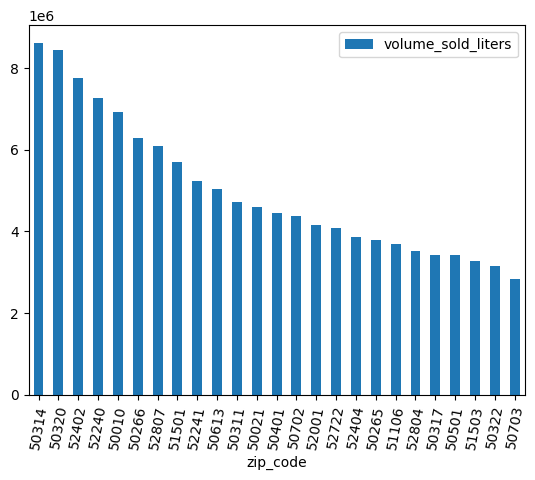
কিছু জিপ কোডের শেষে .0 রয়েছে। সম্ভবত ডেটা সংগ্রহের কোনো পর্যায়ে জিপ কোডগুলো ভুলবশত ফ্লোটিং পয়েন্ট মানে রূপান্তরিত হয়ে গেছে। রেগুলার এক্সপ্রেশন ব্যবহার করে জিপ কোডগুলো পরিমার্জন করুন এবং বিশ্লেষণটি পুনরায় করুন।
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
প্রত্যাশিত আউটপুট:
৫. বিক্রয়ের মধ্যে পারস্পরিক সম্পর্ক খুঁজে বের করুন
কেন কিছু জিপ কোডে অন্যগুলোর চেয়ে বেশি বিক্রি হয়? একটি অনুমান হলো, এর কারণ জনসংখ্যার আকারের পার্থক্য। যে জিপ কোডের জনসংখ্যা বেশি, সেখানে সম্ভবত বেশি মদ বিক্রি হবে।
জনসংখ্যা এবং মদের বিক্রির পরিমাণের মধ্যে পারস্পরিক সম্পর্ক গণনা করে এই অনুমানটি পরীক্ষা করুন।
অন্যান্য ডেটাসেটের সাথে যুক্ত করুন
ইউএস সেন্সাস ব্যুরোর আমেরিকান কমিউনিটি সার্ভে জিপ কোড ট্যাবুলেশন এরিয়া সার্ভের মতো একটি জনসংখ্যা ডেটাসেটের সাথে যুক্ত হন।
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
আমেরিকান কমিউনিটি সার্ভে জিওআইডি (GEOID) দ্বারা রাজ্যগুলোকে চিহ্নিত করে। জিপ কোড গণনা এলাকার ক্ষেত্রে, জিওআইডি-ই জিপ কোডের সমান হয়।
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
জিপ কোড গণনা এলাকার জনসংখ্যার সাথে বিক্রি হওয়া অ্যালকোহলের পরিমাণ (লিটারে) তুলনা করার জন্য একটি স্ক্যাটার প্লট তৈরি করুন।
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
প্রত্যাশিত আউটপুট:
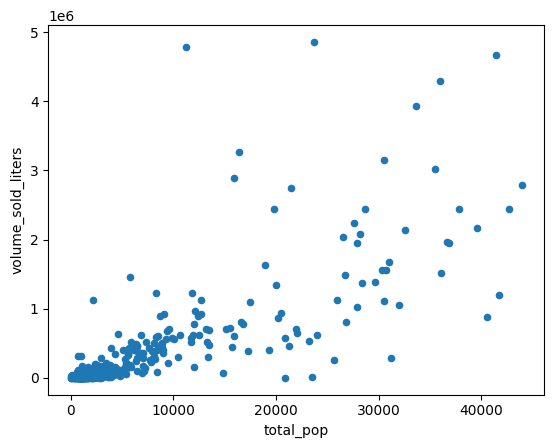
পারস্পরিক সম্পর্ক গণনা করুন
প্রবণতাটি মোটামুটি রৈখিক বলে মনে হচ্ছে। জনসংখ্যা মদের বিক্রি কতটা ভালোভাবে পূর্বাভাস দিতে পারে তা যাচাই করার জন্য এর উপর একটি রৈখিক রিগ্রেশন মডেল প্রয়োগ করুন।
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
score পদ্ধতি ব্যবহার করে ফিটটি কতটা ভালো তা যাচাই করুন।
model.score(feature_columns, label_columns).to_pandas()
নমুনা আউটপুট:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
জনসংখ্যার মানগুলির একটি পরিসরের উপর predict ফাংশনটি প্রয়োগ করে সর্বোত্তম ফিট রেখাটি অঙ্কন করুন।
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
প্রত্যাশিত আউটপুট:
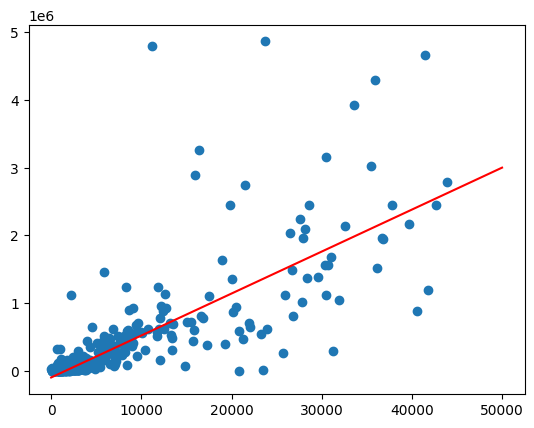
হেটেরোসেডাস্টিসিটি মোকাবেলা করা
পূর্ববর্তী চার্টের ডেটা হেটেরোস্কেডাস্টিক বলে মনে হচ্ছে। বেস্ট ফিট লাইনের চারপাশের ভ্যারিয়েন্স পপুলেশনের সাথে বৃদ্ধি পায়।
সম্ভবত মাথাপিছু কেনা মদের পরিমাণ তুলনামূলকভাবে স্থির।
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
প্রত্যাশিত আউটপুট:
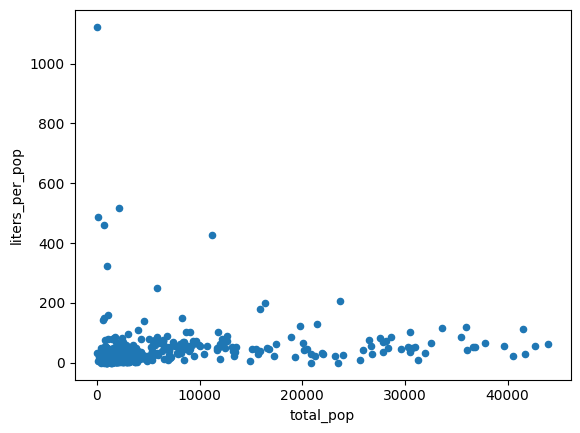
দুটি ভিন্ন উপায়ে ক্রয়কৃত অ্যালকোহলের গড় পরিমাণ লিটারে গণনা করুন:
- আইওয়াতে মাথাপিছু গড়ে কী পরিমাণ অ্যালকোহল কেনা হয়?
- সমস্ত জিপ কোড জুড়ে মাথাপিছু অ্যালকোহল ক্রয়ের গড় কত?
(1)-এ, এটি সমগ্র রাজ্যে কী পরিমাণ অ্যালকোহল কেনা হয় তা প্রতিফলিত করে। (2)-এ, এটি গড় জিপ কোড প্রতিফলিত করে, যা অগত্যা (1)-এর সমান হবে না কারণ বিভিন্ন জিপ কোডের জনসংখ্যা ভিন্ন ভিন্ন হয়।
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
প্রত্যাশিত আউটপুট: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
প্রত্যাশিত আউটপুট: 67.139
উপরেরটির অনুরূপভাবে এই গড়গুলো লেখচিত্রে অঙ্কন করুন।
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
প্রত্যাশিত আউটপুট:
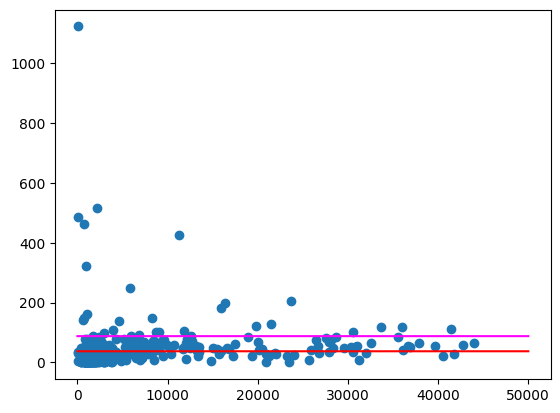
এখনও কিছু জিপ কোড রয়েছে যা বেশ বড় ধরনের ব্যতিক্রম, বিশেষ করে কম জনসংখ্যার এলাকাগুলোতে। এর কারণ কী, তা অনুমান করার জন্য এটিকে একটি অনুশীলন হিসেবে রেখে দেওয়া হলো। উদাহরণস্বরূপ, এমন হতে পারে যে কিছু জিপ কোডের জনসংখ্যা কম কিন্তু সেখানে খরচ বেশি, কারণ এলাকার একমাত্র মদের দোকানটি সেখানেই অবস্থিত। যদি তাই হয়, তাহলে আশেপাশের জিপ কোডগুলোর জনসংখ্যার ভিত্তিতে গণনা করলে এই ব্যতিক্রমগুলো হয়তো সমান হয়ে যেতে পারে।
৬. বিক্রি হওয়া মদের প্রকারভেদের তুলনা
ভৌগোলিক তথ্যের পাশাপাশি, আইওয়ার মদের খুচরা বিক্রয় ডেটাবেসে বিক্রি হওয়া পণ্য সম্পর্কেও বিস্তারিত তথ্য রয়েছে। সম্ভবত এগুলো বিশ্লেষণ করে আমরা বিভিন্ন ভৌগোলিক অঞ্চলের রুচির পার্থক্যগুলো উন্মোচন করতে পারব।
বিভাগগুলি অন্বেষণ করুন
ডাটাবেসে আইটেমগুলো শ্রেণীবদ্ধ করা আছে। এখানে কয়টি বিভাগ আছে?
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
প্রত্যাশিত আউটপুট: 103
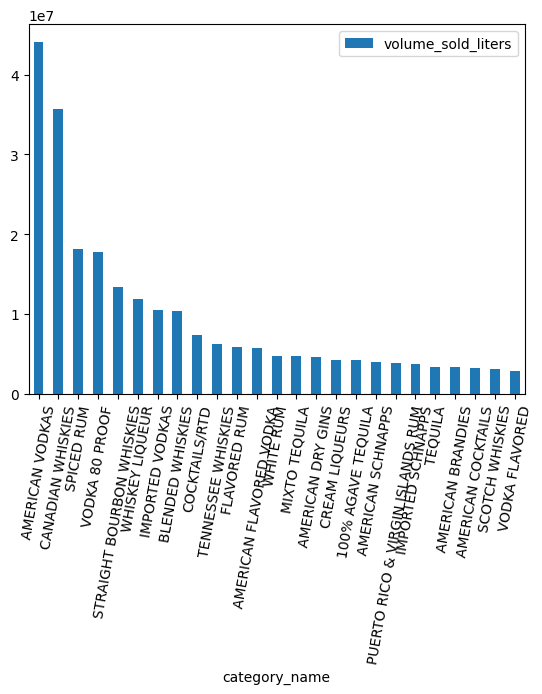
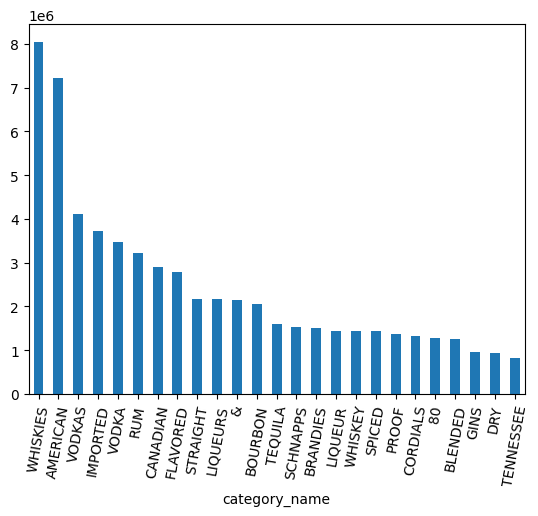
পরিমাণের দিক থেকে সবচেয়ে জনপ্রিয় বিভাগগুলো কোনগুলো?
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
অ্যারে ডেটা টাইপ নিয়ে কাজ করা
হুইস্কি, রাম, ভদকা এবং আরও অনেক কিছুরই বিভিন্ন বিভাগ রয়েছে। আমি এগুলোকে কোনোভাবে একত্রিত করতে চাই।
প্রথমে Series.str.split() মেথড ব্যবহার করে ক্যাটাগরির নামগুলোকে আলাদা আলাদা শব্দে ভাগ করুন। এরপর explode() মেথড ব্যবহার করে এর ফলে তৈরি হওয়া অ্যারেটিকে আননেস্ট করুন।
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
category_parts.nunique()
প্রত্যাশিত আউটপুট: 113
উপরের চার্টটি দেখলে বোঝা যায়, ডেটাতে এখনও VODKA এবং VODKAS আলাদা রয়েছে। বিভাগগুলোকে আরও ছোট একটি সেটে সংকুচিত করার জন্য আরও গ্রুপিং প্রয়োজন।
৭. BigQuery ডেটাফ্রেমের সাথে NLTK ব্যবহার
মাত্র প্রায় ১০০টি ক্যাটাগরি থাকায়, কিছু হিউরিস্টিকস লেখা বা এমনকি ম্যানুয়ালি এক ক্যাটাগরি থেকে অন্য ক্যাটাগরির মদের ধরনের সাথে একটি ম্যাপিং তৈরি করা সম্ভব। বিকল্পভাবে, এই ধরনের ম্যাপিং তৈরি করার জন্য জেমিনির মতো একটি বৃহৎ ল্যাঙ্গুয়েজ মডেল ব্যবহার করা যেতে পারে। জেমিনির সাথে বিগকোয়েরি ডেটাফ্রেম ব্যবহার করতে, 'Get insights from unstructured data using BigQuery DataFrames' কোডল্যাবটি চেষ্টা করুন।
এর পরিবর্তে, এই ডেটাগুলো প্রসেস করার জন্য NLTK-এর মতো একটি প্রচলিত ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং প্যাকেজ ব্যবহার করুন। উদাহরণস্বরূপ, 'স্টেমার' নামক একটি প্রযুক্তি বহুবচন ও একবচন বিশেষ্যকে একই মানে একীভূত করতে পারে।
NLTK ব্যবহার করে শব্দ তৈরি করা
NLTK প্যাকেজটি ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং মেথড সরবরাহ করে যা পাইথন থেকে ব্যবহার করা যায়। এটি ব্যবহার করে দেখার জন্য প্যাকেজটি ইনস্টল করুন।
%pip install nltk
এরপর, প্যাকেজটি ইম্পোর্ট করুন। ভার্সনটি পরীক্ষা করে দেখুন। টিউটোরিয়ালের পরবর্তী অংশে এটি কাজে লাগবে।
import nltk
nltk.__version__
শব্দকে প্রমিত করার একটি উপায় হলো শব্দটির মূল রূপ তৈরি করা। এতে যেকোনো প্রত্যয় বাদ দেওয়া হয়, যেমন বহুবচনের জন্য শব্দের শেষে থাকা 's'।
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
কয়েকটি শব্দের উপর এটি চেষ্টা করে দেখুন।
stem("WHISKEY")
প্রত্যাশিত আউটপুট: whiskey
stem("WHISKIES")
প্রত্যাশিত আউটপুট: whiski
দুর্ভাগ্যবশত, এটি 'whiskies' এবং 'whiskey'-কে একই অর্থে চিহ্নিত করতে পারেনি। স্টেমারগুলো অনিয়মিত বহুবচনের ক্ষেত্রে ভালোভাবে কাজ করে না। একটি লেমাটাইজার ব্যবহার করে দেখুন, যা 'লেমা' নামক মূল শব্দটি শনাক্ত করার জন্য আরও উন্নত কৌশল ব্যবহার করে।
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
কয়েকটি শব্দের উপর এটি চেষ্টা করে দেখুন।
lemmatize("WHISKIES")
প্রত্যাশিত আউটপুট: whisky
lemmatize("WHISKY")
প্রত্যাশিত আউটপুট: whisky
lemmatize("WHISKEY")
প্রত্যাশিত আউটপুট: whiskey
দুর্ভাগ্যবশত, এই লেমাটাইজারটি 'whiskey' শব্দটিকে 'whiskies' শব্দের মতো একই লেমাতে ম্যাপ করে না। যেহেতু এই শব্দটি আইওয়ার খুচরা মদের বিক্রয় ডেটাবেসের জন্য বিশেষভাবে গুরুত্বপূর্ণ, তাই একটি অভিধান ব্যবহার করে এটিকে ম্যানুয়ালি আমেরিকান বানানে ম্যাপ করুন।
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
কয়েকটি শব্দের উপর এটি চেষ্টা করে দেখুন।
lemmatize("WHISKIES")
প্রত্যাশিত আউটপুট: whiskey
lemmatize("WHISKEY")
প্রত্যাশিত আউটপুট: whiskey
অভিনন্দন! এই লেম্যাটাইজারটি ক্যাটাগরিগুলো সংকুচিত করার জন্য ভালোভাবে কাজ করবে। BigQuery-এর সাথে এটি ব্যবহার করতে হলে, আপনাকে এটি ক্লাউডে ডেপ্লয় করতে হবে।
ফাংশন ডেপ্লয়মেন্টের জন্য আপনার প্রজেক্ট সেটআপ করুন।
এটি ক্লাউডে স্থাপন করার আগে, যাতে BigQuery এই ফাংশনটি অ্যাক্সেস করতে পারে, আপনাকে একবারের জন্য কিছু সেটআপ করতে হবে।
একটি নতুন কোড সেল তৈরি করুন এবং your-project-id জায়গায় এই টিউটোরিয়ালের জন্য ব্যবহৃত গুগল ক্লাউড প্রজেক্ট আইডিটি বসান।
project_id = "your-project-id"
কোনো অনুমতি ছাড়াই একটি সার্ভিস অ্যাকাউন্ট তৈরি করুন, কারণ এই ফাংশনটির কোনো ক্লাউড রিসোর্সে অ্যাক্সেসের প্রয়োজন নেই।
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
প্রত্যাশিত আউটপুট: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
ফাংশনটি ধারণ করার জন্য একটি BigQuery ডেটাসেট তৈরি করুন।
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
একটি রিমোট ফাংশন স্থাপন করা
ক্লাউড ফাংশনস এপিআই যদি আগে থেকে সক্রিয় করা না থাকে, তবে তা সক্রিয় করুন।
!gcloud services enable cloudfunctions.googleapis.com
এখন, আপনার তৈরি করা ডেটাসেটে ফাংশনটি ডিপ্লয় করুন। পূর্ববর্তী ধাপে তৈরি করা ফাংশনটিতে একটি @bpd.remote_function ডেকোরেটর যোগ করুন।
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
স্থাপন করতে প্রায় দুই মিনিট সময় লাগা উচিত।
রিমোট ফাংশন ব্যবহার করা
ডেপ্লয়মেন্ট সম্পন্ন হলে, আপনি এই ফাংশনটি পরীক্ষা করতে পারবেন।
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
প্রত্যাশিত আউটপুট:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
৮. কাউন্টি অনুসারে অ্যালকোহল সেবনের তুলনা
এখন যেহেতু lemmatize ফাংশনটি উপলব্ধ, ক্যাটাগরিগুলোকে একত্রিত করতে এটি ব্যবহার করুন।
বিভাগটিকে সবচেয়ে ভালোভাবে সংক্ষেপে বর্ণনা করার মতো শব্দ খুঁজে বের করা।
প্রথমে, ডাটাবেসে থাকা সমস্ত ক্যাটাগরি নিয়ে একটি ডেটাফ্রেম তৈরি করুন।
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
প্রত্যাশিত আউটপুট:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
এরপরে, বিরামচিহ্ন এবং 'আইটেম'-এর মতো কয়েকটি অপ্রয়োজনীয় শব্দ ছাড়া, ক্যাটাগরিগুলোর সমস্ত শব্দ নিয়ে একটি ডেটাফ্রেম তৈরি করুন।
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
প্রত্যাশিত আউটপুট:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
মনে রাখবেন যে, গ্রুপিং করার পরে লেমাটাইজ করার মাধ্যমে আপনি আপনার ক্লাউড ফাংশনের উপর চাপ কমাচ্ছেন। ডাটাবেসের কয়েক মিলিয়ন সারির প্রতিটিতে লেমাটাইজ ফাংশনটি প্রয়োগ করা সম্ভব, কিন্তু গ্রুপিং করার পরে এটি প্রয়োগ করার চেয়ে এতে খরচ বেশি হবে এবং কোটা বাড়ানোর প্রয়োজন হতে পারে।
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
প্রত্যাশিত আউটপুট:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
এখন যেহেতু শব্দগুলোকে লেমায় রূপান্তর করা হয়েছে, আপনাকে এমন একটি লেমা নির্বাচন করতে হবে যা বিভাগটিকে সবচেয়ে ভালোভাবে সংক্ষিপ্ত করে। যেহেতু বিভাগগুলোতে ক্রিয়াপদ-নির্ভর শব্দ খুব বেশি নেই, তাই এই সাধারণ নিয়মটি ব্যবহার করুন যে, যদি কোনো শব্দ একাধিক অন্য বিভাগে উপস্থিত থাকে, তবে সম্ভবত এটি একটি সংক্ষিপ্তকারী শব্দ হিসেবেই বেশি ভালো (যেমন হুইস্কি)।
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
প্রত্যাশিত আউটপুট:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
এখন যেহেতু প্রতিটি বিভাগের সারসংক্ষেপকারী একটিমাত্র লেমা রয়েছে, এটিকে মূল ডেটাফ্রেমের সাথে মার্জ করুন।
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
প্রত্যাশিত আউটপুট:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
কাউন্টিগুলির তুলনা
প্রতিটি কাউন্টির বিক্রয় তুলনা করে দেখুন কী কী পার্থক্য রয়েছে।
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
প্রতিটি কাউন্টিতে সর্বাধিক বিক্রিত পণ্যটি (লেমা) খুঁজুন।
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
প্রত্যাশিত আউটপুট:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
কাউন্টিগুলো একে অপরের থেকে কতটা আলাদা?
county_max_lemma.groupby("lemma").size().to_pandas()
প্রত্যাশিত আউটপুট:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
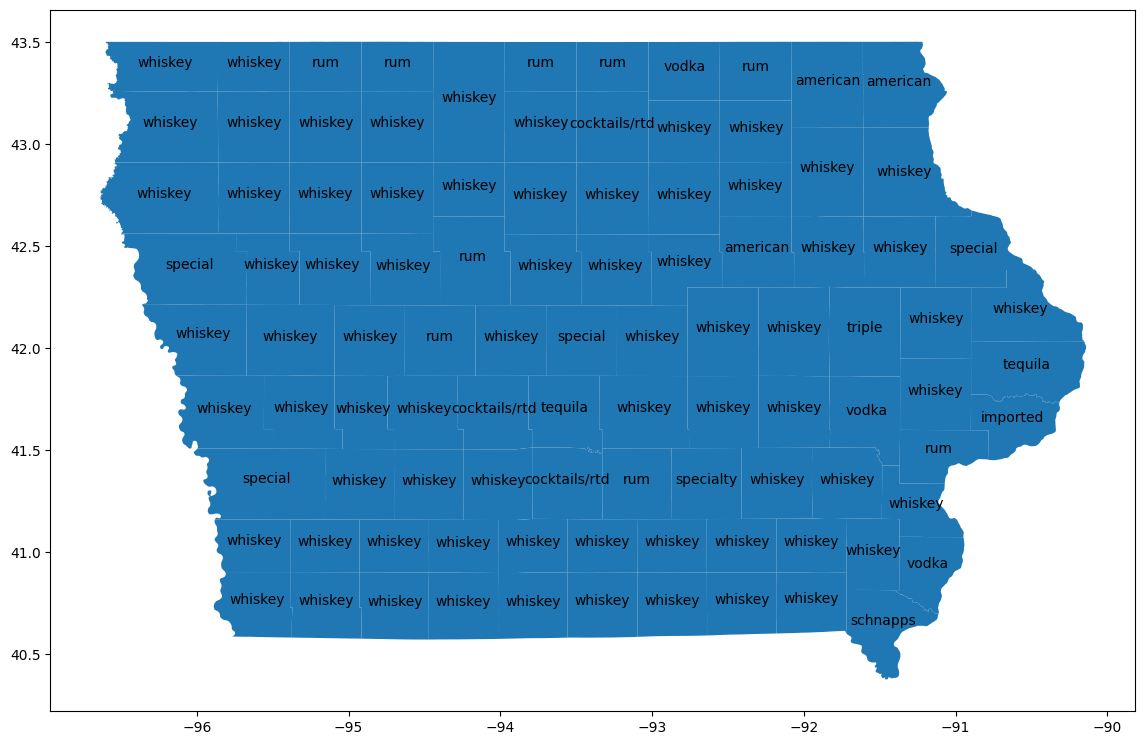
বেশিরভাগ কাউন্টিতে, পরিমাণের দিক থেকে হুইস্কি সবচেয়ে জনপ্রিয় পণ্য, এবং ১৫টি কাউন্টিতে ভদকা সবচেয়ে জনপ্রিয়। রাজ্যব্যাপী সবচেয়ে জনপ্রিয় মদের প্রকারগুলোর সাথে এর তুলনা করুন।
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
প্রত্যাশিত আউটপুট:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
রাজ্যজুড়ে হুইস্কি ও ভদকার পরিমাণ প্রায় একই, তবে ভদকার পরিমাণ হুইস্কির চেয়ে কিছুটা বেশি।
অনুপাত তুলনা করা
প্রতিটি কাউন্টির বিক্রয়ের বিশেষত্ব কী? কোন বিষয়টি একটি কাউন্টিকে রাজ্যের বাকি অংশ থেকে আলাদা করে তোলে?
রাজ্যব্যাপী বিক্রয়ের অনুপাতের ভিত্তিতে যা প্রত্যাশিত, তার থেকে কোন মদের বিক্রয়ের পরিমাণগুলো আনুপাতিকভাবে সবচেয়ে বেশি ভিন্ন, তা খুঁজে বের করতে কোহেনের h পরিমাপটি ব্যবহার করুন।
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
এখন যেহেতু প্রতিটি লেমার জন্য কোহেনের h পরিমাপ করা হয়েছে, প্রতিটি কাউন্টিতে রাজ্যব্যাপী অনুপাত থেকে বৃহত্তম পার্থক্যটি নির্ণয় করুন।
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
প্রত্যাশিত আউটপুট:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
কোহেনের h-এর মান যত বড় হবে, রাজ্যের গড়ের তুলনায় সেই নির্দিষ্ট ধরণের অ্যালকোহল সেবনের পরিমাণে পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ পার্থক্য থাকার সম্ভাবনা তত বেশি। ক্ষুদ্রতর ধনাত্মক মানগুলোর ক্ষেত্রে, সেবনের পার্থক্যটি রাজ্যব্যাপী গড়ের চেয়ে ভিন্ন হয়, কিন্তু এটি দৈবচয়নের কারণেও হতে পারে।
প্রসঙ্গক্রমে উল্লেখ্য: এল পাসো কাউন্টি আইওয়ার কোনো কাউন্টি বলে মনে হচ্ছে না; এই বিষয়টি ইঙ্গিত দেয় যে, এই ফলাফলগুলোর ওপর পুরোপুরি নির্ভর করার আগে ডেটা পরিমার্জনের আরও একটি প্রয়োজন রয়েছে।
কাউন্টিগুলির কল্পনা
প্রতিটি কাউন্টির ভৌগোলিক এলাকা পেতে bigquery-public-data.geo_us_boundaries.counties টেবিলের সাথে জয়েন করুন। মার্কিন যুক্তরাষ্ট্র জুড়ে কাউন্টির নামগুলো অনন্য নয়, তাই শুধুমাত্র আইওয়ার কাউন্টিগুলো অন্তর্ভুক্ত করার জন্য ফিল্টার করুন। আইওয়ার FIPS কোড হলো '19'।
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
প্রত্যাশিত আউটপুট:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
মানচিত্রে এই পার্থক্যগুলো দৃশ্যমান করতে GeoPandas ব্যবহার করুন।
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)
৯. পরিষ্কার করুন
আপনি যদি এই টিউটোরিয়ালের জন্য একটি নতুন গুগল ক্লাউড প্রজেক্ট তৈরি করে থাকেন, তবে তৈরি করা টেবিল বা অন্যান্য রিসোর্সের জন্য অতিরিক্ত চার্জ এড়াতে আপনি সেটি ডিলিট করে দিতে পারেন।
বিকল্পভাবে, এই টিউটোরিয়ালের জন্য তৈরি করা ক্লাউড ফাংশন, সার্ভিস অ্যাকাউন্ট এবং ডেটাসেটগুলো মুছে ফেলুন।
১০. অভিনন্দন!
আপনি BigQuery DataFrames ব্যবহার করে স্ট্রাকচার্ড ডেটা পরিষ্কার ও বিশ্লেষণ করেছেন। এই প্রক্রিয়ায় আপনি Google Cloud-এর পাবলিক ডেটাসেট, BigQuery Studio-এর পাইথন নোটবুক, BigQuery ML, BigQuery রিমোট ফাংশন এবং BigQuery DataFrames-এর কার্যকারিতা সম্পর্কে জেনেছেন। চমৎকার কাজ!
পরবর্তী পদক্ষেপ
- এই ধাপগুলো অন্যান্য ডেটার ক্ষেত্রেও প্রয়োগ করুন, যেমন ইউএসএ নামের ডেটাবেস ।
- আপনার নোটবুকে পাইথন কোড তৈরি করার চেষ্টা করুন। BigQuery Studio-এর পাইথন নোটবুকগুলো Colab Enterprise দ্বারা চালিত। একটি পরামর্শ: টেস্ট ডেটা তৈরি করার জন্য সাহায্য চাওয়াটা আমার কাছে বেশ উপকারী বলে মনে হয়।
- গিটহাবে BigQuery DataFrames-এর নমুনা নোটবুকগুলো দেখুন।
- BigQuery Studio-তে একটি নোটবুক চালানোর জন্য একটি শিডিউল তৈরি করুন।
- BigQuery-এর সাথে থার্ড-পার্টি পাইথন প্যাকেজ ইন্টিগ্রেট করতে BigQuery ডেটাফ্রেমসহ একটি রিমোট ফাংশন ডিপ্লয় করুন।