
1. Übersicht
In diesem Lab verwenden Sie BigQuery DataFrames aus einem Python-Notebook in BigQuery Studio, um das öffentliche Dataset „Iowa Liquor Sales“ zu bereinigen und zu analysieren. BigQuery ML- und Remote-Funktionsfunktionen nutzen, um Erkenntnisse zu gewinnen.
Sie erstellen ein Python-Notebook, um die Verkäufe in verschiedenen geografischen Einheiten zu vergleichen. Das kann an beliebige strukturierte Daten angepasst werden.
Ziele
Aufgaben in diesem Lab:
- Python-Notebooks in BigQuery Studio aktivieren und verwenden
- Verbindung zu BigQuery mit dem BigQuery DataFrames-Paket herstellen
- Lineare Regression mit BigQuery ML erstellen
- Komplexe Aggregationen und Joins mit einer vertrauten pandas-ähnlichen Syntax ausführen
2. Voraussetzungen
Hinweis
Wenn Sie der Anleitung in diesem Codelab folgen möchten, benötigen Sie ein Google Cloud-Projekt mit aktiviertem BigQuery Studio und einem verknüpften Abrechnungskonto.
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist
- Folgen Sie der Anleitung unter BigQuery Studio für die Asset-Verwaltung aktivieren.
BigQuery Studio vorbereiten
Leeres Notebook erstellen und mit einer Laufzeit verbinden
- Rufen Sie BigQuery Studio in der Google Cloud Console auf.
- Klicken Sie neben der Schaltfläche + auf das ▼.
- Wählen Sie Python-Notebook aus.
- Schließen Sie die Vorlagenauswahl.
- Wählen Sie + Code aus, um eine neue Codezelle zu erstellen.
- Installieren Sie die neueste Version des BigQuery DataFrames-Pakets über die Codezelle.Geben Sie den folgenden Befehl ein.
%pip install --upgrade bigframes --quiet
3. Öffentliches Dataset lesen
Initialisieren Sie das BigQuery DataFrames-Paket, indem Sie Folgendes in einer neuen Codezelle ausführen:
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
Hinweis: In diesem Tutorial verwenden wir den experimentellen „Modus für partielle Sortierung“, der in Verbindung mit pandas-ähnlicher Filterung effizientere Abfragen ermöglicht. Einige pandas-Funktionen, für die eine strikte Reihenfolge oder ein Index erforderlich ist, funktionieren möglicherweise nicht.
Prüfen Sie die Version Ihres bigframes-Pakets mit
bpd.__version__
Für diese Anleitung ist Version 1.27.0 oder höher erforderlich.
Einzelhandelsumsätze mit Spirituosen in Iowa
Das Dataset zu Einzelhandelsumsätzen mit Spirituosen in Iowa wird in BigQuery über das Programm für öffentliche Datasets in Google Cloud bereitgestellt. Dieses Dataset enthält alle Großhandelskäufe von Spirituosen im Bundesstaat Iowa durch Einzelhändler zum Verkauf an Privatpersonen seit dem 1. Januar 2012. Die Daten werden von der Abteilung für alkoholische Getränke im Handelsministerium von Iowa erhoben.
Fragen Sie in BigQuery das Dataset bigquery-public-data.iowa_liquor_sales.sales ab, um die Einzelhandelsumsätze mit Spirituosen in Iowa zu analysieren. Mit der Methode bigframes.pandas.read_gbq() können Sie einen DataFrame aus einem Abfragestring oder einer Tabellen-ID erstellen.
Führen Sie den folgenden Code in einer neuen Codezelle aus, um einen DataFrame mit dem Namen „df“ zu erstellen:
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
Grundlegende Informationen zu einem DataFrame abrufen
Mit der Methode DataFrame.peek() können Sie eine kleine Stichprobe der Daten herunterladen.
Führen Sie diese Zelle aus:
df.peek()
Erwartete Ausgabe:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
Hinweis: Für head() ist eine Sortierung erforderlich und es ist im Allgemeinen weniger effizient als peek(), wenn Sie eine Stichprobe von Daten visualisieren möchten.
Wie bei pandas können Sie mit der Property DataFrame.dtypes alle verfügbaren Spalten und die entsprechenden Datentypen aufrufen. Sie werden auf pandas-kompatible Weise bereitgestellt.
Führen Sie diese Zelle aus:
df.dtypes
Erwartete Ausgabe:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
Mit der Methode DataFrame.describe() werden einige grundlegende Statistiken aus dem DataFrame abgefragt. Führen Sie DataFrame.to_pandas() aus, um diese zusammenfassenden Statistiken als Pandas DataFrame herunterzuladen.
Führen Sie diese Zelle aus:
df.describe("all").to_pandas()
Erwartete Ausgabe:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
4. Daten visualisieren und bereinigen
Das Dataset „Iowa Liquor Retail Sales“ (Einzelhandelsverkauf von Spirituosen in Iowa) enthält detaillierte geografische Informationen, einschließlich des Standorts der Einzelhandelsgeschäfte. Anhand dieser Daten können Sie Trends und Unterschiede zwischen geografischen Einheiten ermitteln.
Umsatz nach Postleitzahl visualisieren
Es gibt mehrere integrierte Visualisierungsmethoden wie DataFrame.plot.hist(). Mit dieser Methode können Sie die Spirituosenverkäufe nach Postleitzahl vergleichen.
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
Erwartete Ausgabe:
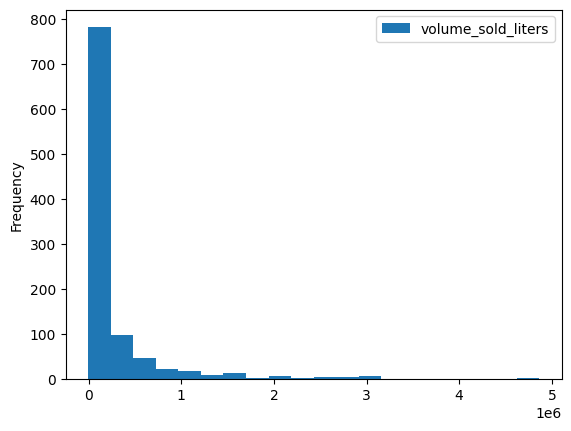
Mit einem Balkendiagramm können Sie sehen, in welchen Postleitzahlen die meisten alkoholischen Getränke verkauft wurden.
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Erwartete Ausgabe:
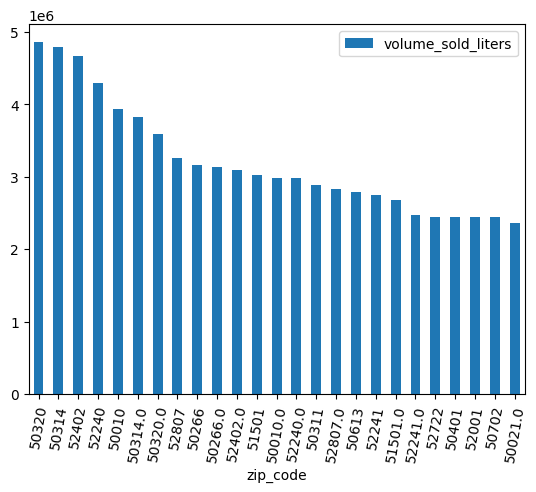
Daten bereinigen
Einige Postleitzahlen haben ein nachgestelltes .0. Möglicherweise wurden die Postleitzahlen bei der Datenerhebung versehentlich in Gleitkommawerte umgewandelt. Verwenden Sie reguläre Ausdrücke, um die Postleitzahlen zu bereinigen, und wiederholen Sie die Analyse.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Erwartete Ausgabe:
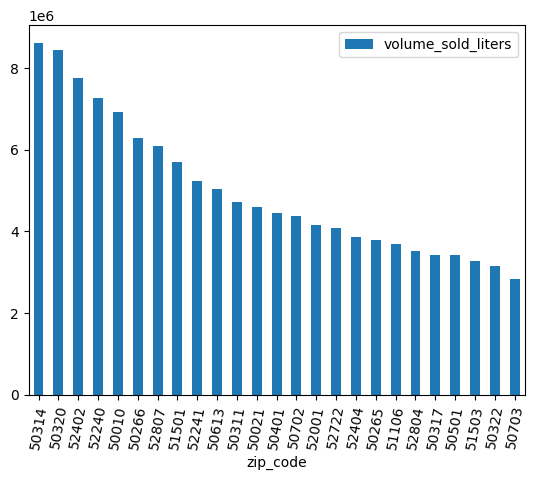
5. Korrelationen im Umsatz erkennen
Warum werden in einigen Postleitzahlen mehr Produkte verkauft als in anderen? Eine Hypothese ist, dass dies auf Unterschiede in der Bevölkerungsgröße zurückzuführen ist. In einer Postleitzahl mit mehr Einwohnern wird wahrscheinlich mehr Alkohol verkauft.
Testen Sie diese Hypothese, indem Sie die Korrelation zwischen der Bevölkerung und dem Umsatzvolumen von Spirituosen berechnen.
Mit anderen Datasets verknüpfen
Führen Sie die Daten mit einem Bevölkerungs-Dataset zusammen, z. B. mit der American Community Survey des US Census Bureau.
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
Bei der American Community Survey werden Bundesstaaten anhand der GEOID identifiziert. Bei ZIP Code Tabulation Areas entspricht der GEOID der Postleitzahl.
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
Erstellen Sie ein Streudiagramm, um die Bevölkerungszahlen der ZCTA mit der Menge des verkauften Alkohols zu vergleichen.
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
Erwartete Ausgabe:
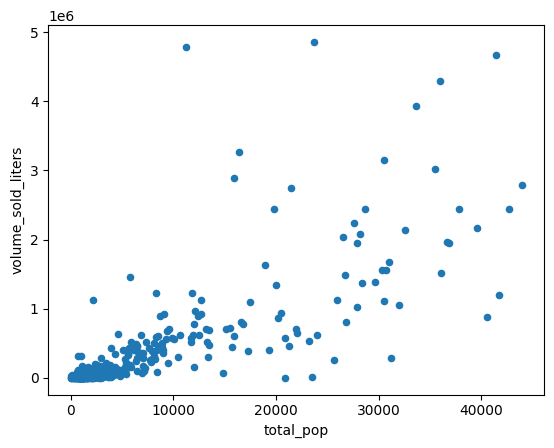
Korrelationen berechnen
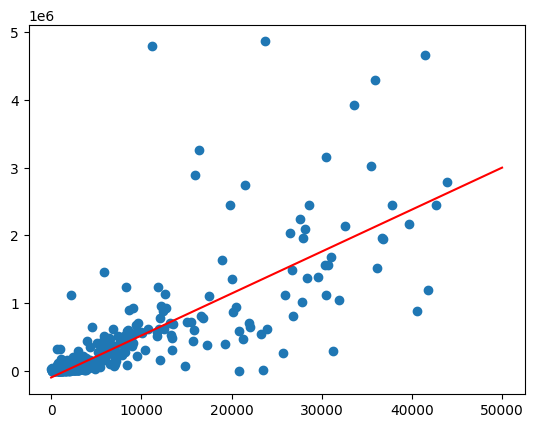
Der Trend ist in etwa linear. Passen Sie ein lineares Regressionsmodell an diese Daten an, um zu prüfen, wie gut sich der Umsatz mit Spirituosen anhand der Bevölkerungszahl vorhersagen lässt.
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
Prüfen Sie mit der Methode score, wie gut die Anpassung ist.
model.score(feature_columns, label_columns).to_pandas()
Beispielausgabe:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
Zeichnen Sie die Linie für die beste Anpassung, indem Sie die Funktion predict für einen Bereich von Populationswerten aufrufen.
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
Erwartete Ausgabe:
Heteroskedastizität beheben
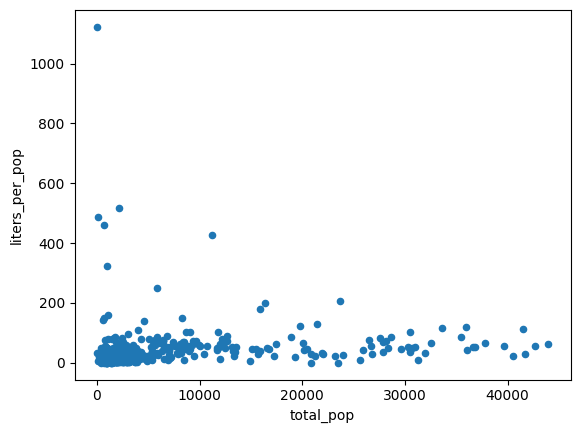
Die Daten im vorherigen Diagramm scheinen heteroskedastisch zu sein. Die Varianz um die Linie der besten Anpassung nimmt mit der Bevölkerung zu.
Vielleicht ist die Menge an Alkohol, die pro Person gekauft wird, relativ konstant.
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
Erwartete Ausgabe:
Berechnen Sie die durchschnittliche Menge an gekauftem Alkohol auf zwei verschiedene Arten:
- Wie viel Alkohol wird in Iowa durchschnittlich pro Person gekauft?
- Wie hoch ist der Durchschnitt aller Postleitzahlen für die Menge an Alkohol, die pro Person gekauft wurde?
In (1) wird angegeben, wie viel Alkohol im gesamten Bundesstaat gekauft wird. In (2) wird der durchschnittliche Postleitzahlbereich angegeben, der nicht unbedingt mit (1) übereinstimmt, da die Bevölkerung in den einzelnen Postleitzahlbereichen unterschiedlich ist.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
Erwartete Ausgabe: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
Erwartete Ausgabe: 67.139
Stellen Sie diese Durchschnittswerte wie oben grafisch dar.
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
Erwartete Ausgabe:
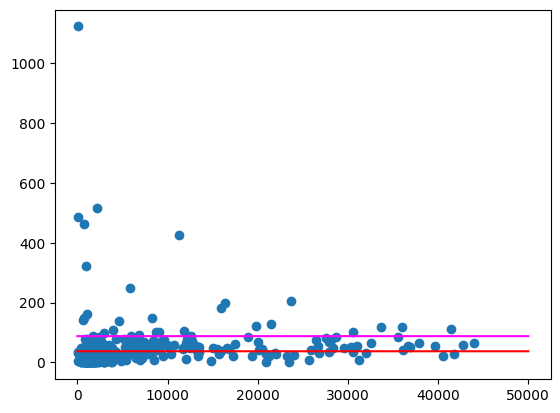
Es gibt immer noch einige Postleitzahlen, die Ausreißer sind, insbesondere in Gebieten mit weniger Einwohnern. Es bleibt Ihnen überlassen, Hypothesen aufzustellen, warum das so ist. Es könnte beispielsweise sein, dass einige Postleitzahlen eine geringe Bevölkerungszahl, aber einen hohen Verbrauch aufweisen, weil sich dort das einzige Spirituosengeschäft in der Gegend befindet. In diesem Fall können Sie die Berechnung auf der Grundlage der Bevölkerung der umliegenden Postleitzahlen durchführen, um diese Ausreißer auszugleichen.
6. Vergleich der verkauften Spirituosenarten
Neben geografischen Daten enthält die Datenbank für Einzelhandelsverkäufe von Spirituosen in Iowa auch detaillierte Informationen zum verkauften Artikel. Vielleicht lassen sich dadurch Unterschiede im Geschmack in verschiedenen geografischen Gebieten aufdecken.
Kategorien entdecken
Artikel werden in der Datenbank kategorisiert. Wie viele Kategorien gibt es?
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
Erwartete Ausgabe: 103
Welche Kategorien sind nach Volumen am beliebtesten?
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
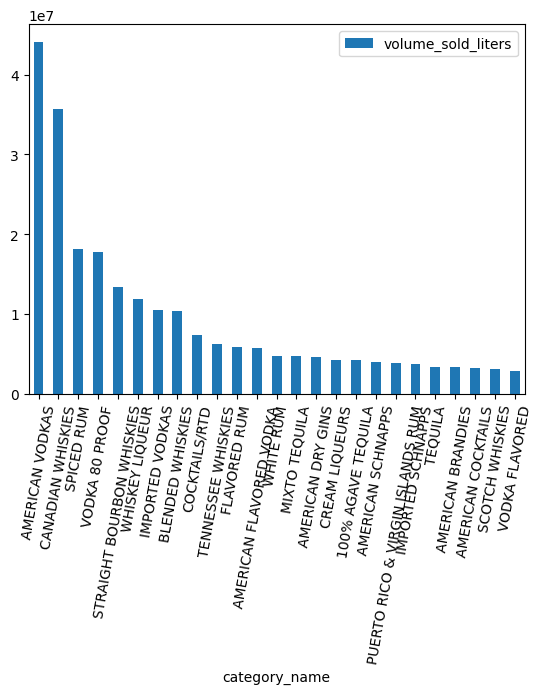
Mit dem ARRAY-Datentyp arbeiten
Es gibt mehrere Kategorien für Whisky, Rum, Wodka und mehr. Ich möchte diese irgendwie gruppieren.
Teilen Sie zuerst die Kategorienamen mit der Methode Series.str.split() in einzelne Wörter auf. Heben Sie die Verschachtelung des so erstellten Arrays mit der Methode explode() auf.
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
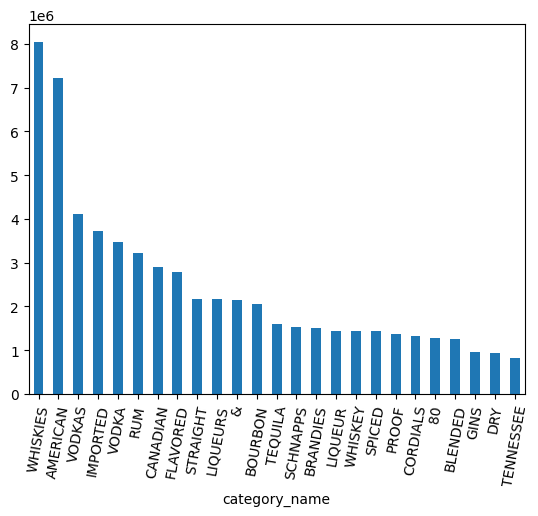
category_parts.nunique()
Erwartete Ausgabe: 113
Im obigen Diagramm sind die Daten für VODKA und VODKAS weiterhin getrennt. Es ist eine weitere Gruppierung erforderlich, um Kategorien in einem kleineren Set zusammenzufassen.
7. NLTK mit BigQuery DataFrames verwenden
Bei nur etwa 100 Kategorien wäre es möglich, einige Heuristiken zu schreiben oder sogar manuell eine Zuordnung von Kategorie zu Spirituosentyp zu erstellen. Alternativ kann ein Large Language Model wie Gemini verwendet werden, um eine solche Zuordnung zu erstellen. Im Codelab Get insights from unstructured data using BigQuery DataFrames (Informationen aus unstrukturierten Daten mit BigQuery DataFrames gewinnen) erfahren Sie, wie Sie BigQuery DataFrames mit Gemini verwenden.
Verwenden Sie stattdessen ein herkömmlicheres Natural Language Processing-Paket wie NLTK, um diese Daten zu verarbeiten. Mit einer Technologie namens „Stemmer“ können beispielsweise Plural- und Singularformen von Nomen in denselben Wert zusammengeführt werden.
NLTK zum Stemming von Wörtern verwenden
Das NLTK-Paket bietet Methoden für die Verarbeitung natürlicher Sprache, auf die über Python zugegriffen werden kann. Installieren Sie das Paket, um es auszuprobieren.
%pip install nltk
Importieren Sie als Nächstes das Paket. Prüfen Sie die Version. Sie benötigen sie später in der Anleitung.
import nltk
nltk.__version__
Eine Möglichkeit, Wörter zu standardisieren, besteht darin, sie zu „stämmen“. Dadurch werden alle Suffixe entfernt, z. B. ein „s“ am Ende für Plurale.
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
Probieren Sie es mit einigen Wörtern aus.
stem("WHISKEY")
Erwartete Ausgabe: whiskey
stem("WHISKIES")
Erwartete Ausgabe: whiski
Leider wurde „whiskies“ nicht als Synonym für „whiskey“ erkannt. Stemmer funktionieren nicht gut mit unregelmäßigen Pluralformen. Verwenden Sie einen Lemmatizer, der anspruchsvollere Techniken verwendet, um das Grundwort, das sogenannte „Lemma“, zu identifizieren.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
Probieren Sie es mit einigen Wörtern aus.
lemmatize("WHISKIES")
Erwartete Ausgabe: whisky
lemmatize("WHISKY")
Erwartete Ausgabe: whisky
lemmatize("WHISKEY")
Erwartete Ausgabe: whiskey
Leider wird „whiskey“ von diesem Lemmatisierer nicht demselben Lemma wie „whiskies“ zugeordnet. Da dieses Wort für die Datenbank zum Einzelhandelsverkauf von Spirituosen in Iowa besonders wichtig ist, wird es manuell mithilfe eines Wörterbuchs der amerikanischen Schreibweise zugeordnet.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Probieren Sie es mit einigen Wörtern aus.
lemmatize("WHISKIES")
Erwartete Ausgabe: whiskey
lemmatize("WHISKEY")
Erwartete Ausgabe: whiskey
Glückwunsch! Dieser Lemmatisierer sollte sich gut eignen, um die Kategorien einzugrenzen. Wenn Sie es mit BigQuery verwenden möchten, müssen Sie es in der Cloud bereitstellen.
Projekt für die Bereitstellung von Funktionen einrichten
Bevor Sie die Funktion in der Cloud bereitstellen, damit BigQuery darauf zugreifen kann, müssen Sie einige einmalige Einrichtungsschritte ausführen.
Erstellen Sie eine neue Codezelle und ersetzen Sie your-project-id durch die Google Cloud-Projekt-ID, die Sie für diese Anleitung verwenden.
project_id = "your-project-id"
Erstellen Sie ein Dienstkonto ohne Berechtigungen, da für diese Funktion kein Zugriff auf Cloud-Ressourcen erforderlich ist.
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
Erwartete Ausgabe: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
Erstellen Sie ein BigQuery-Dataset, in dem die Funktion gespeichert werden soll.
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
Remote-Funktion bereitstellen
Aktivieren Sie die Cloud Functions API, falls sie noch nicht aktiviert ist.
!gcloud services enable cloudfunctions.googleapis.com
Stellen Sie die Funktion nun für das Dataset bereit, das Sie gerade erstellt haben. Fügen Sie der Funktion, die Sie in den vorherigen Schritten erstellt haben, den Decorator @bpd.remote_function hinzu.
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Die Bereitstellung sollte etwa zwei Minuten dauern.
Remote-Funktionen verwenden
Sobald die Bereitstellung abgeschlossen ist, können Sie diese Funktion testen.
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
Erwartete Ausgabe:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
8. Alkoholkonsum nach County vergleichen
Da die Funktion lemmatize jetzt verfügbar ist, können Sie sie verwenden, um Kategorien zu kombinieren.
Das Wort finden, das die Kategorie am besten zusammenfasst
Erstellen Sie zuerst einen DataFrame mit allen Kategorien in der Datenbank.
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
Erwartete Ausgabe:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
Erstellen Sie als Nächstes einen DataFrame mit allen Wörtern in den Kategorien, mit Ausnahme einiger Füllwörter wie Satzzeichen und „Artikel“.
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
Erwartete Ausgabe:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
Durch die Lemmatisierung nach der Gruppierung wird die Last für Ihre Cloud-Funktion reduziert. Es ist möglich, die Funktion „Lemmatisieren“ auf jede der mehreren Millionen Zeilen in der Datenbank anzuwenden. Das wäre jedoch teurer als die Anwendung nach der Gruppierung und erfordert möglicherweise eine Kontingenterhöhung.
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
Erwartete Ausgabe:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
Nachdem die Wörter lemmatisiert wurden, müssen Sie das Lemma auswählen, das die Kategorie am besten zusammenfasst. Da es in den Kategorien nicht viele Funktionswörter gibt, können Sie die Heuristik verwenden, dass ein Wort wahrscheinlich besser als zusammenfassendes Wort geeignet ist, wenn es in mehreren anderen Kategorien vorkommt (z.B. Whiskey).
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
Erwartete Ausgabe:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
Da es jetzt ein einzelnes Lemma gibt, das jede Kategorie zusammenfasst, führen Sie es mit dem ursprünglichen DataFrame zusammen.
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
Erwartete Ausgabe:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
Landkreise vergleichen
Vergleichen Sie die Umsätze in den einzelnen Landkreisen, um Unterschiede zu erkennen.
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
Ermitteln Sie das meistverkaufte Produkt (Lemma) in jedem Landkreis.
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
Erwartete Ausgabe:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
Wie unterschiedlich sind die Landkreise?
county_max_lemma.groupby("lemma").size().to_pandas()
Erwartete Ausgabe:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
In den meisten Countys ist Whiskey das beliebteste Produkt nach Volumen, in 15 Countys ist Wodka am beliebtesten. Vergleichen Sie dies mit den beliebtesten Spirituosenarten im gesamten Bundesstaat.
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
Erwartete Ausgabe:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
Whiskey und Wodka haben fast das gleiche Volumen, wobei Wodka bundesweit etwas höher liegt als Whiskey.
Anteile vergleichen
Was ist das Besondere an den Verkäufen in den einzelnen Ländern? Was unterscheidet den Bezirk vom Rest des Bundesstaats?
Mit dem Cohen-h-Maß können Sie herausfinden, welche Verkaufszahlen für Spirituosen sich proportional am stärksten von den erwarteten Werten auf Grundlage des landesweiten Verkaufsanteils unterscheiden.
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
Nachdem der Cohen-h-Wert für jedes Lemma gemessen wurde, suchen Sie in jedem County nach der größten Abweichung vom bundesweiten Anteil.
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
Erwartete Ausgabe:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
Je größer der Cohen-h-Wert ist, desto wahrscheinlicher ist es, dass es einen statistisch signifikanten Unterschied bei der Menge des konsumierten Alkohols im Vergleich zu den Durchschnittswerten des Bundesstaats gibt. Bei den kleineren positiven Werten weicht der Verbrauch vom bundesweiten Durchschnitt ab, was jedoch auf zufällige Unterschiede zurückzuführen sein kann.
Nebenbei bemerkt: EL PASO County ist anscheinend kein County in Iowa. Das kann darauf hindeuten, dass die Daten bereinigt werden müssen, bevor Sie sich vollständig auf diese Ergebnisse verlassen.
Countys visualisieren
Verknüpfen Sie die Daten mit der Tabelle bigquery-public-data.geo_us_boundaries.counties, um das geografische Gebiet für jeden Bezirk zu erhalten. Namen von Countys sind in den USA nicht eindeutig. Filtern Sie daher so, dass nur Countys aus Iowa berücksichtigt werden. Der FIPS-Code für Iowa ist „19“.
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
Erwartete Ausgabe:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
Mit GeoPandas können Sie diese Unterschiede auf einer Karte visualisieren.
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)
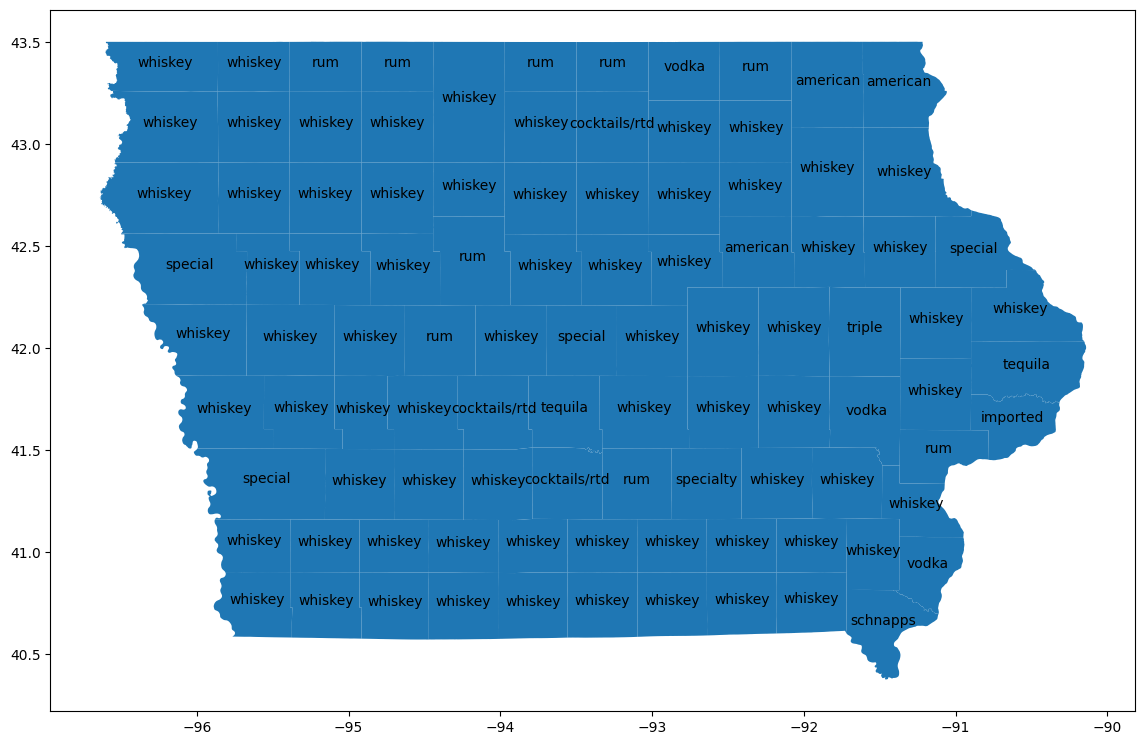
9. Bereinigen
Wenn Sie für diese Anleitung ein neues Google Cloud-Projekt erstellt haben, können Sie es löschen, um zusätzliche Gebühren für erstellte Tabellen oder andere Ressourcen zu vermeiden.
Alternativ können Sie die Cloud Functions, Dienstkonten und Datasets löschen, die für diese Anleitung erstellt wurden.
10. Glückwunsch!
Sie haben strukturierte Daten mit BigQuery DataFrames bereinigt und analysiert. Dabei haben Sie die öffentlichen Datasets von Google Cloud, Python-Notebooks in BigQuery Studio, BigQuery ML, BigQuery-Remote-Funktionen und die Leistungsfähigkeit von BigQuery DataFrames kennengelernt. Fantastisch!
Nächste Schritte
- Sie können diese Schritte auch für andere Daten anwenden, z. B. für die USA names database.
- Python-Code in Ihrem Notebook generieren Python-Notebooks in BigQuery Studio basieren auf Colab Enterprise. Tipp: Ich finde es sehr hilfreich, um Unterstützung beim Generieren von Testdaten zu bitten.
- Beispiel-Notebooks für BigQuery DataFrames auf GitHub
- Planen Sie die Ausführung eines Notebooks in BigQuery Studio.
- Stellen Sie eine Remote-Funktion mit BigQuery DataFrames bereit, um Python-Drittanbieterpakete in BigQuery einzubinden.