
۱. مرور کلی
در این آزمایش، شما از BigQuery DataFrames از یک نوتبوک پایتون در BigQuery Studio برای پاکسازی و تجزیه و تحلیل مجموعه دادههای عمومی فروش مشروبات الکلی آیووا استفاده خواهید کرد. از BigQuery ML و قابلیتهای توابع از راه دور برای کشف بینشها استفاده خواهید کرد.
شما یک دفترچه یادداشت پایتون برای مقایسه فروش در مناطق جغرافیایی مختلف ایجاد خواهید کرد. این دفترچه میتواند برای کار با هر داده ساختاریافتهای سازگار باشد.
اهداف
در این آزمایشگاه، شما یاد میگیرید که چگونه وظایف زیر را انجام دهید:
- فعالسازی و استفاده از نوتبوکهای پایتون در BigQuery Studio
- با استفاده از بسته BigQuery DataFrames به BigQuery متصل شوید
- ایجاد رگرسیون خطی با استفاده از BigQuery ML
- انجام عملیات تجمیع و پیوند پیچیده با استفاده از سینتکس آشنای پانداس
۲. الزامات
قبل از اینکه شروع کنی
برای دنبال کردن دستورالعملهای این آزمایشگاه کد، به یک پروژه گوگل کلود با BigQuery Studio فعال و یک حساب پرداخت متصل نیاز دارید.
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید
- مطمئن شوید که صورتحساب برای پروژه Google Cloud شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر
- دستورالعملها را برای فعال کردن BigQuery Studio برای مدیریت دارایی دنبال کنید.
آمادهسازی استودیوی BigQuery
یک دفترچه یادداشت خالی ایجاد کنید و آن را به یک محیط اجرا متصل کنید.
- در کنسول گوگل کلود به BigQuery Studio بروید.
- روی علامت ▼ کنار دکمه + کلیک کنید.
- دفترچه یادداشت پایتون را انتخاب کنید.
- انتخابگر قالب را ببندید.
- برای ایجاد یک سلول کد جدید ، + Code را انتخاب کنید.
- آخرین نسخه از بسته BigQuery DataFrames را از طریق کد نصب کنید. دستور زیر را تایپ کنید.
%pip install --upgrade bigframes --quiet
۳. خواندن یک مجموعه داده عمومی
با اجرای دستور زیر در یک سلول کد جدید، بسته BigQuery DataFrames را مقداردهی اولیه کنید:
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
توجه: در این آموزش، ما از حالت آزمایشی «مرتبسازی جزئی» استفاده میکنیم که امکان پرسوجوهای کارآمدتری را در هنگام استفاده با فیلترینگ مشابه پانداس فراهم میکند. برخی از ویژگیهای پانداس که نیاز به مرتبسازی دقیق یا اندیسگذاری دارند، ممکن است کار نکنند.
نسخه بسته bigframes خود را با این دستور بررسی کنید
bpd.__version__
این آموزش به نسخه ۱.۲۷.۰ یا بالاتر نیاز دارد.
خرده فروشی مشروبات الکلی آیووا
مجموعه دادههای فروش خردهفروشی مشروبات الکلی آیووا از طریق برنامه مجموعه دادههای عمومی Google Cloud در BigQuery ارائه شده است. این مجموعه دادهها شامل هر خرید عمده مشروبات الکلی در ایالت آیووا توسط خردهفروشان برای فروش به افراد از اول ژانویه ۲۰۱۲ است. دادهها توسط بخش نوشیدنیهای الکلی در وزارت بازرگانی آیووا جمعآوری میشوند.
در BigQuery، برای تحلیل فروش خردهفروشی مشروبات الکلی آیووا، از bigquery-public-data.iowa_liquor_sales.sales کوئری بگیرید. از متد bigframes.pandas.read_gbq() برای ایجاد یک DataFrame از یک رشته کوئری یا شناسه جدول استفاده کنید.
برای ایجاد یک DataFrame با نام "df" ، کد زیر را در یک سلول کد جدید اجرا کنید:
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
اطلاعات اولیه در مورد یک DataFrame را کشف کنید
از متد DataFrame.peek() برای دانلود نمونه کوچکی از دادهها استفاده کنید.
این سلول را اجرا کنید:
df.peek()
خروجی مورد انتظار:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
نکته: head() نیاز به مرتبسازی دارد و اگر بخواهید نمونهای از دادهها را مصورسازی کنید، عموماً نسبت به peek() کارایی کمتری دارد.
درست مانند پانداس، از ویژگی DataFrame.dtypes برای مشاهده تمام ستونهای موجود و انواع دادههای مربوط به آنها استفاده کنید. این موارد به روشی سازگار با پانداس نمایش داده میشوند.
این سلول را اجرا کنید:
df.dtypes
خروجی مورد انتظار:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
متد DataFrame.describe() برخی از آمارهای اولیه را از DataFrame پرسوجو میکند. برای دانلود این آمارهای خلاصه به عنوان یک DataFrame از pandas، DataFrame.to_pandas() را اجرا کنید.
این سلول را اجرا کنید:
df.describe("all").to_pandas()
خروجی مورد انتظار:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
۴. دادهها را مصورسازی و پالایش کنید
مجموعه دادههای خردهفروشی مشروبات الکلی آیووا، اطلاعات جغرافیایی دقیقی از جمله محل قرارگیری فروشگاههای خردهفروشی را ارائه میدهد. از این دادهها برای شناسایی روندها و تفاوتها در مناطق جغرافیایی مختلف استفاده کنید.
فروش بر اساس کد پستی را تجسم کنید
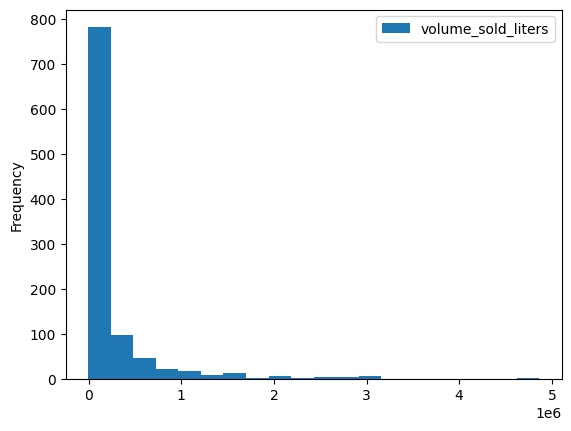
چندین متد تجسم داخلی مانند DataFrame.plot.hist() وجود دارد. از این متد برای مقایسه فروش مشروبات الکلی بر اساس کد پستی استفاده کنید.
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
خروجی مورد انتظار:
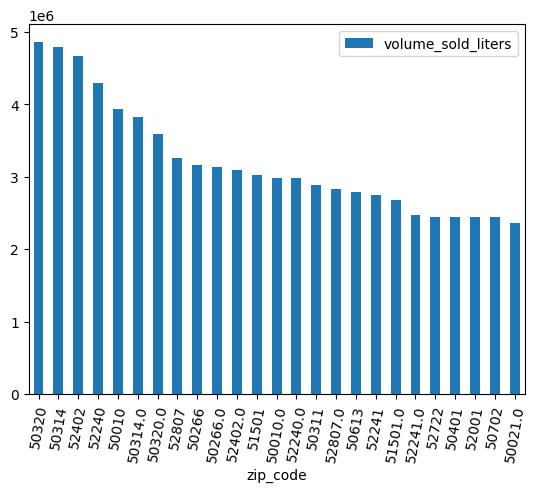
از یک نمودار میلهای استفاده کنید تا ببینید کدام فروشگاههای زنجیرهای بیشترین الکل را فروختهاند.
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
خروجی مورد انتظار:
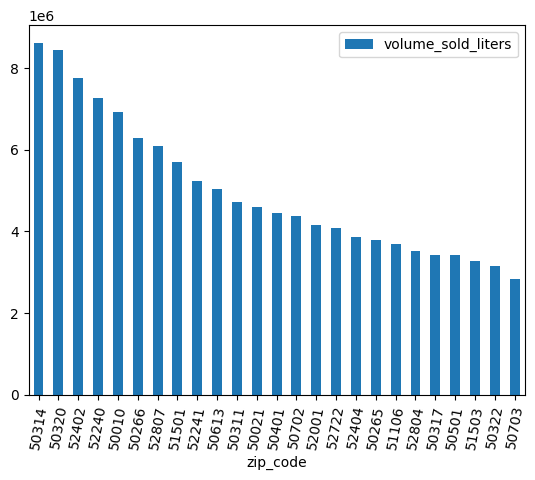
دادهها را تمیز کنید
برخی از کدهای پستی دارای عدد .0 هستند. احتمالاً در جایی از مجموعه دادهها، کدهای پستی بهطور تصادفی به مقادیر ممیز شناور تبدیل شدهاند. از عبارات منظم برای پاک کردن کدهای پستی و تکرار تحلیل استفاده کنید.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
خروجی مورد انتظار:
۵. همبستگیها را در فروش کشف کنید
چرا برخی از کدهای پستی بیشتر از بقیه میفروشند؟ یک فرضیه این است که این به دلیل تفاوت در اندازه جمعیت است. یک کد پستی با جمعیت بیشتر احتمالاً مشروبات الکلی بیشتری میفروشد.
این فرضیه را با محاسبه همبستگی بین جمعیت و حجم فروش مشروبات الکلی آزمایش کنید.
با مجموعه دادههای دیگر ادغام کنید
با یک مجموعه داده جمعیتی مانند «نظرسنجی جامعه آمریکایی» از اداره سرشماری ایالات متحده، «جدولبندی منطقه بر اساس کد پستی» به آن بپیوندید.
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
بررسی جامعه آمریکا، ایالتها را بر اساس GEOID مشخص میکند. در مورد مناطق جدولبندی کد پستی، GEOID برابر با کد پستی است.
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
یک نمودار پراکندگی برای مقایسه جمعیت مناطق جدولبندی شده بر اساس کد پستی با لیترهای الکل فروخته شده ایجاد کنید.
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
خروجی مورد انتظار:
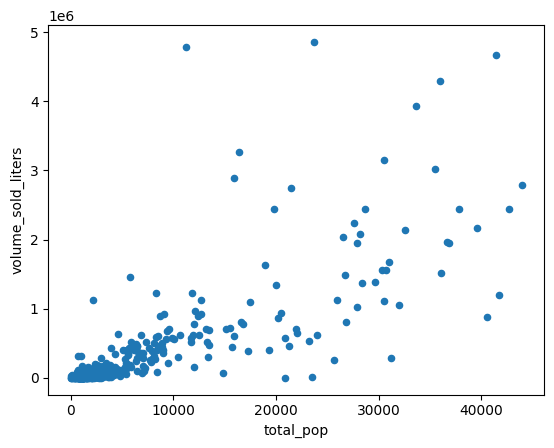
محاسبه همبستگیها
این روند تقریباً خطی به نظر میرسد. یک مدل رگرسیون خطی بر آن برازش دهید تا بررسی کنید که جمعیت چقدر میتواند فروش مشروبات الکلی را پیشبینی کند.
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
با استفاده از روش score میزان برازش را بررسی کنید.
model.score(feature_columns, label_columns).to_pandas()
خروجی نمونه:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
بهترین خط برازش را رسم کنید اما تابع predict را روی طیفی از مقادیر جمعیت فراخوانی کنید.
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
خروجی مورد انتظار:
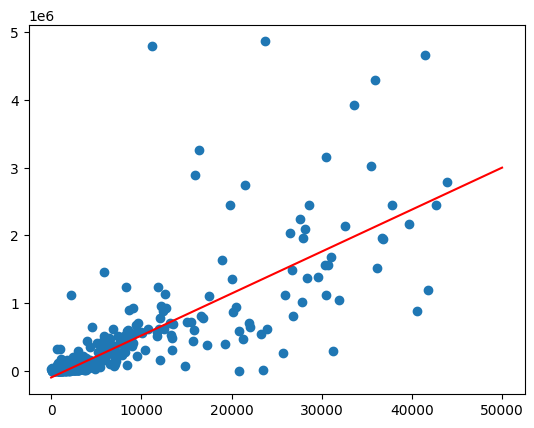
پرداختن به ناهمسانی واریانس
به نظر میرسد دادههای نمودار قبلی ناهمسانی واریانس دارند. واریانس حول بهترین خط برازش با افزایش جمعیت افزایش مییابد.
شاید میزان الکل خریداری شده به ازای هر نفر نسبتاً ثابت باشد.
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
خروجی مورد انتظار:
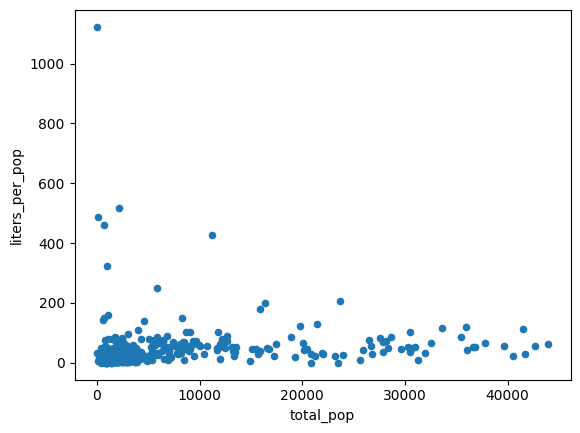
میانگین لیتر الکل خریداری شده را به دو روش مختلف محاسبه کنید:
- میانگین میزان الکل خریداری شده برای هر نفر در آیووا چقدر است؟
- میانگین میزان الکل خریداری شده به ازای هر نفر در کل کدهای پستی چقدر است؟
در (1)، این مقدار نشان دهنده میزان خرید الکل در کل ایالت است. در (2)، میانگین کد پستی را نشان میدهد که لزوماً با (1) یکسان نخواهد بود زیرا کدهای پستی مختلف، جمعیتهای متفاوتی دارند.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
خروجی مورد انتظار: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
خروجی مورد انتظار: 67.139
این میانگینها را مشابه بالا رسم کنید.
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
خروجی مورد انتظار:
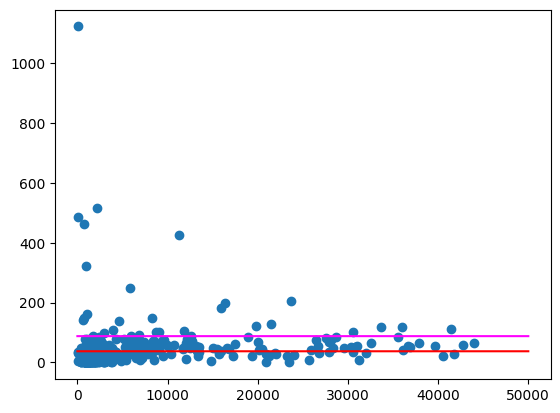
هنوز برخی از کدهای پستی وجود دارند که به خصوص در مناطقی با جمعیت کمتر، دادههای پرت بسیار بزرگی هستند. این به عنوان یک تمرین برای فرضیهسازی در مورد دلیل این امر باقی مانده است. به عنوان مثال، ممکن است برخی از کدهای پستی جمعیت کمی دارند اما مصرف بالایی دارند زیرا تنها فروشگاه مشروبات الکلی در منطقه در آنها قرار دارد. در این صورت، محاسبه بر اساس جمعیت کدهای پستی اطراف ممکن است حتی این دادههای پرت را نیز از بین ببرد.
۶. مقایسه انواع مشروبات الکلی فروخته شده
علاوه بر دادههای جغرافیایی، پایگاه داده خردهفروشی مشروبات الکلی آیووا همچنین شامل اطلاعات دقیقی در مورد کالای فروخته شده است. شاید با تجزیه و تحلیل این موارد، بتوانیم تفاوتهای سلیقهای را در مناطق جغرافیایی مختلف آشکار کنیم.
دستهها را کاوش کنید
اقلام در پایگاه داده دستهبندی شدهاند. چند دسته وجود دارد؟
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
خروجی مورد انتظار: 103
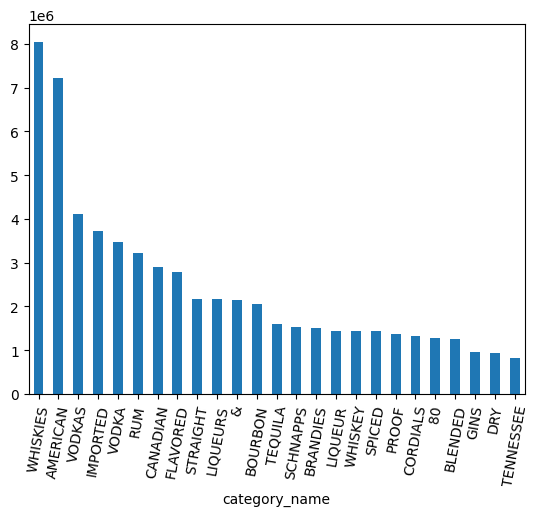
محبوبترین دستهبندیها از نظر حجم کدامند؟
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
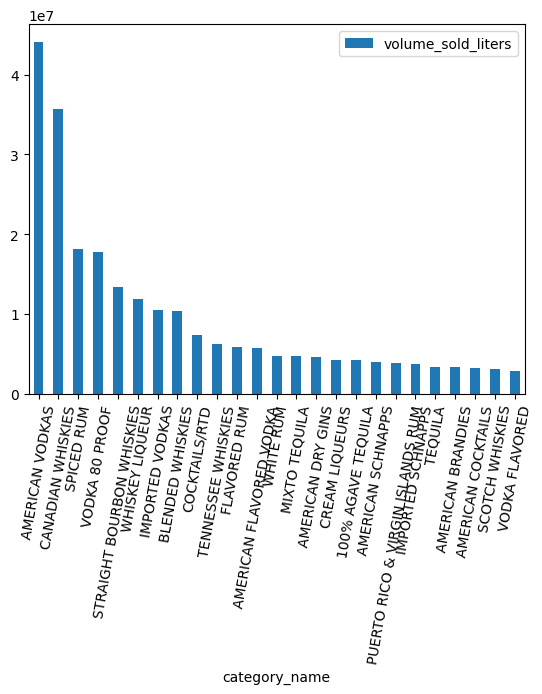
کار با نوع داده ARRAY
ویسکی، رم، ودکا و غیره چندین دسته بندی دارند. من دوست دارم به نحوی اینها را در یک گروه قرار دهم.
با استفاده از متد ()Series.str.split نام دستهها را به کلمات جداگانه تقسیم کنید. آرایهای که این کار ایجاد میکند را با استفاده از متد explode() از حالت تودرتو خارج کنید.
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
category_parts.nunique()
خروجی مورد انتظار: 113
با نگاهی به نمودار بالا، دادهها هنوز VODKA را از VODKAS جدا کردهاند. برای تقسیمبندی دستهها به مجموعهای کوچکتر، به گروهبندی بیشتری نیاز است.
۷. استفاده از NLTK با BigQuery DataFrames
با تنها حدود ۱۰۰ دسته، نوشتن برخی روشهای اکتشافی یا حتی ایجاد دستی نگاشت از دسته به نوع گستردهتر مشروبات الکلی امکانپذیر است. از طرف دیگر، میتوان از یک مدل زبانی بزرگ مانند Gemini برای ایجاد چنین نگاشتی استفاده کرد. codelab را امتحان کنید . با استفاده از BigQuery DataFrames از دادههای بدون ساختار بینش کسب کنید تا از BigQuery DataFrames با Gemini استفاده کنید.
در عوض، از یک بسته پردازش زبان طبیعی سنتیتر، NLTK، برای پردازش این دادهها استفاده کنید. برای مثال، فناوریای به نام "stemmer" میتواند اسمهای جمع و مفرد را در یک مقدار واحد ادغام کند.
استفاده از NLTK برای ریشهیابی کلمات
بسته NLTK روشهای پردازش زبان طبیعی را ارائه میدهد که از طریق پایتون قابل دسترسی هستند. برای امتحان کردن، این بسته را نصب کنید.
%pip install nltk
سپس، بسته را وارد کنید. نسخه را بررسی کنید. بعداً در این آموزش از آن استفاده خواهیم کرد.
import nltk
nltk.__version__
یکی از راههای استانداردسازی کلمات، ریشهیابی کلمه است. این روش هرگونه پسوندی را حذف میکند، مانند یک «s» انتهایی برای جمعها.
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
این را روی چند کلمه امتحان کنید.
stem("WHISKEY")
خروجی مورد انتظار: whiskey
stem("WHISKIES")
خروجی مورد انتظار: whiski
متأسفانه، این روش ویسکیها را به همان ویسکی مرتبط نکرد. ریشهیابها با جمعهای نامنظم خوب کار نمیکنند. از یک ریشهیاب استفاده کنید که از تکنیکهای پیچیدهتری برای شناسایی کلمهی پایه به نام «لِما» استفاده میکند.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
این را روی چند کلمه امتحان کنید.
lemmatize("WHISKIES")
خروجی مورد انتظار: whisky
lemmatize("WHISKY")
خروجی مورد انتظار: whisky
lemmatize("WHISKEY")
خروجی مورد انتظار: whiskey
متأسفانه، این ریشهیاب، کلمهی «whiskey» را به ریشهی کلمهی «whiskies» مرتبط نمیکند. از آنجایی که این کلمه برای پایگاه دادهی فروش خردهفروشی مشروبات الکلی در آیووا بسیار مهم است، میتوانید آن را به صورت دستی و با استفاده از یک فرهنگ لغت به املای آمریکایی آن مرتبط کنید.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
این را روی چند کلمه امتحان کنید.
lemmatize("WHISKIES")
خروجی مورد انتظار: whiskey
lemmatize("WHISKEY")
خروجی مورد انتظار: whiskey
تبریک! این ابزار ریشهیابی کلمات باید برای محدود کردن دستهبندیها به خوبی کار کند. برای استفاده از آن با BigQuery، باید آن را در فضای ابری مستقر کنید.
پروژه خود را برای استقرار تابع تنظیم کنید
قبل از اینکه این را در فضای ابری مستقر کنید تا BigQuery بتواند به این عملکرد دسترسی داشته باشد، باید تنظیماتی را یکباره انجام دهید.
یک سلول کد جدید ایجاد کنید و your-project-id را با شناسه پروژه Google Cloud که برای این آموزش استفاده میکنید، جایگزین کنید.
project_id = "your-project-id"
یک حساب کاربری سرویس بدون هیچ مجوزی ایجاد کنید، زیرا این عملکرد نیازی به دسترسی به هیچ منبع ابری ندارد.
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
خروجی مورد انتظار: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
یک مجموعه داده BigQuery برای نگهداری تابع ایجاد کنید.
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
استقرار یک عملکرد از راه دور
اگر هنوز API توابع ابری را فعال نکردهاید، آن را فعال کنید.
!gcloud services enable cloudfunctions.googleapis.com
حالا، تابع خود را روی مجموعه دادهای که ایجاد کردهاید، مستقر کنید. یک دکوراتور @bpd.remote_function به تابعی که در مراحل قبلی ایجاد کردهاید، اضافه کنید.
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
استقرار باید حدود دو دقیقه طول بکشد.
استفاده از عملکردهای راه دور
پس از اتمام استقرار، میتوانید این عملکرد را آزمایش کنید.
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
خروجی مورد انتظار:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
۸. مقایسه مصرف الکل بر اساس شهرستان
اکنون که تابع lemmatize در دسترس است، از آن برای ترکیب دستهها استفاده کنید.
پیدا کردن کلمهای که به بهترین شکل دسته بندی را خلاصه کند
ابتدا، یک DataFrame از تمام دستههای موجود در پایگاه داده ایجاد کنید.
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
خروجی مورد انتظار:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
در مرحله بعد، یک DataFrame از تمام کلمات موجود در دستهها ایجاد کنید، به جز چند کلمه پرکننده مانند علائم نگارشی و "item".
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
خروجی مورد انتظار:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
توجه داشته باشید که با lemmatize کردن پس از گروهبندی، بار روی تابع ابری خود را کاهش میدهید. میتوان تابع lemmatize را روی هر یک از چندین میلیون ردیف در پایگاه داده اعمال کرد، اما هزینه آن بیشتر از اعمال آن پس از گروهبندی است و ممکن است نیاز به افزایش سهمیه داشته باشد.
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
خروجی مورد انتظار:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
حالا که کلمات بنواژهبندی شدهاند، باید بنواژهای را انتخاب کنید که به بهترین شکل آن دسته را خلاصه کند. از آنجایی که کلمات تابعی زیادی در دستهها وجود ندارد، از این روش اکتشافی استفاده کنید که اگر یک کلمه در چندین دسته دیگر ظاهر شود، احتمالاً بهتر است به عنوان یک کلمه خلاصهکننده باشد (مثلاً ویسکی).
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
خروجی مورد انتظار:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
حالا که یک لم واحد وجود دارد که هر دسته را خلاصه میکند، آن را با DataFrame اصلی ادغام کنید.
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
خروجی مورد انتظار:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
مقایسه شهرستانها
فروش در هر شهرستان را مقایسه کنید تا ببینید چه تفاوتهایی وجود دارد.
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
پرفروشترین محصول (لِما) را در هر شهرستان پیدا کنید.
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
خروجی مورد انتظار:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
استانها چقدر با هم فرق دارند؟
county_max_lemma.groupby("lemma").size().to_pandas()
خروجی مورد انتظار:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
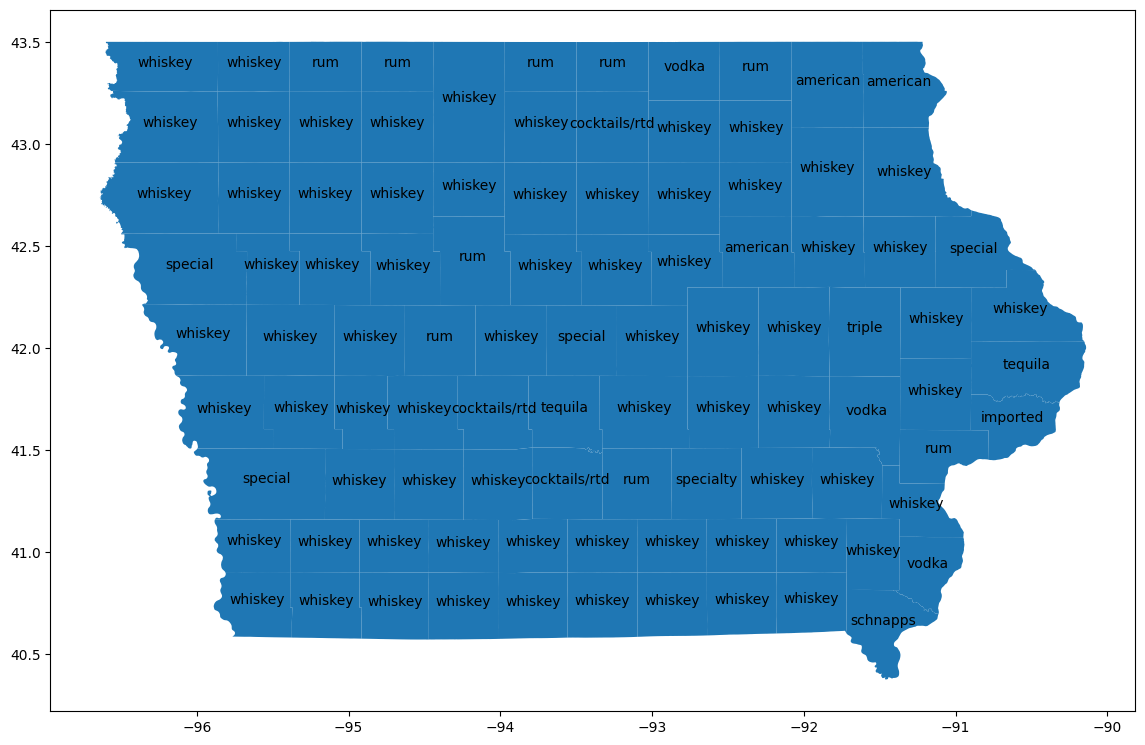
در بیشتر شهرستانها، ویسکی محبوبترین محصول از نظر حجم است و ودکا در ۱۵ شهرستان محبوبترین است. این را با محبوبترین انواع مشروبات الکلی در سراسر ایالت مقایسه کنید.
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
خروجی مورد انتظار:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
ویسکی و ودکا تقریباً حجم یکسانی دارند، و ودکا کمی بیشتر از ویسکی در سطح ایالت است.
مقایسه نسبتها
چه چیزی در مورد فروش در هر شهرستان منحصر به فرد است؟ چه چیزی این شهرستان را از بقیه ایالت متفاوت میکند؟
با استفاده از معیار h کوهن، مشخص کنید کدام حجم فروش مشروبات الکلی بیشترین تفاوت را با آنچه بر اساس نسبت فروش در سطح ایالت انتظار میرود، دارد.
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
اکنون که h کوهن برای هر لم اندازهگیری شده است، بزرگترین اختلاف را از نسبت سراسری ایالت در هر شهرستان بیابید.
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
خروجی مورد انتظار:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
هرچه مقدار h کوهن بزرگتر باشد، احتمال وجود تفاوت آماری معنادار در میزان مصرف آن نوع الکل در مقایسه با میانگینهای ایالتی بیشتر است. برای مقادیر مثبت کوچکتر، تفاوت در مصرف با میانگین کل ایالت متفاوت است، اما ممکن است به دلیل تفاوتهای تصادفی باشد.
نکتهی فرعی: به نظر نمیرسد شهرستان ال پاسو جزو شهرستانهای آیووا باشد، این موضوع ممکن است نشاندهندهی نیاز دیگری به پاکسازی دادهها قبل از اتکای کامل به این نتایج باشد.
تجسم شهرستانها
برای دریافت منطقه جغرافیایی هر شهرستان، به جدول bigquery-public-data.geo_us_boundaries.counties بپیوندید. نام شهرستانها در سراسر ایالات متحده منحصر به فرد نیست، بنابراین فیلتر کنید تا فقط شهرستانهای آیووا را شامل شود. کد FIPS برای آیووا '19' است.
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
خروجی مورد انتظار:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
از GeoPandas برای نمایش این تفاوتها روی نقشه استفاده کنید.
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)
۹. تمیز کردن
اگر برای این آموزش یک پروژه جدید Google Cloud ایجاد کردهاید، میتوانید آن را حذف کنید تا از هزینههای اضافی برای جداول یا سایر منابع ایجاد شده جلوگیری شود.
روش دیگر، حذف توابع ابری، حسابهای سرویس و مجموعه دادههای ایجاد شده برای این آموزش است.
۱۰. تبریک میگویم!
شما دادههای ساختاریافته را با استفاده از BigQuery DataFrames پاکسازی و تجزیه و تحلیل کردهاید. در طول مسیر، مجموعه دادههای عمومی Google Cloud، دفترچههای پایتون در BigQuery Studio، BigQuery ML، توابع از راه دور BigQuery و قدرت BigQuery DataFrames را بررسی کردهاید. کارت فوقالعاده بود!
مراحل بعدی
- این مراحل را برای دادههای دیگر، مانند پایگاه داده نامهای ایالات متحده ، اعمال کنید.
- سعی کنید کد پایتون را در دفترچه یادداشت خود تولید کنید . دفترچههای یادداشت پایتون در BigQuery Studio توسط Colab Enterprise پشتیبانی میشوند. نکته: من درخواست کمک برای تولید دادههای آزمایشی را بسیار مفید میدانم.
- نمونه دفترچههای مربوط به BigQuery DataFrames را در گیتهاب بررسی کنید.
- برای اجرای یک دفترچه یادداشت در BigQuery Studio، یک برنامه زمانی ایجاد کنید.
- برای ادغام بستههای پایتون شخص ثالث با BigQuery، یک تابع از راه دور با BigQuery مستقر کنید.