
1. Présentation
Dans cet atelier, vous allez utiliser BigQuery DataFrames à partir d'un notebook Python dans BigQuery Studio pour nettoyer et analyser l'ensemble de données public sur les ventes de boissons alcoolisées dans l'Iowa. Utilisez les fonctionnalités BigQuery ML et de fonction distante pour découvrir des insights.
Vous allez créer un notebook Python pour comparer les ventes dans différentes zones géographiques. Il peut être adapté pour fonctionner sur n'importe quelles données structurées.
Objectifs
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Activer et utiliser des notebooks Python dans BigQuery Studio
- Se connecter à BigQuery à l'aide du package BigQuery DataFrames
- Créer une régression linéaire à l'aide de BigQuery ML
- Effectuez des agrégations et des jointures complexes à l'aide d'une syntaxe semblable à celle de pandas.
2. Conditions requises
Avant de commencer
Pour suivre les instructions de cet atelier de programmation, vous aurez besoin d'un projet Google Cloud avec BigQuery Studio activé et un compte de facturation associé.
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Google Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Suivez les instructions pour activer BigQuery Studio pour la gestion des éléments.
Préparer BigQuery Studio
Créez un notebook vide et connectez-le à un environnement d'exécution.
- Accédez à BigQuery Studio dans la console Google Cloud.
- Cliquez sur ▼ à côté du bouton +.
- Sélectionnez Notebook Python.
- Fermez le sélecteur de modèle.
- Sélectionnez + Code pour créer une cellule de code.
- Installez la dernière version du package BigQuery DataFrames à partir de la cellule de code.Saisissez la commande suivante.
%pip install --upgrade bigframes --quiet
3. Lire un ensemble de données public
Initialisez le package BigQuery DataFrames en exécutant la commande suivante dans une nouvelle cellule de code :
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
Remarque : Dans ce tutoriel, nous utilisons le "mode de tri partiel" expérimental, qui permet d'effectuer des requêtes plus efficaces lorsqu'il est utilisé avec un filtrage de type pandas. Il est possible que certaines fonctionnalités pandas nécessitant un ordre ou un index stricts ne fonctionnent pas.
Vérifiez la version du package bigframes avec
bpd.__version__
Ce tutoriel nécessite la version 1.27.0 ou ultérieure.
Ventes d'alcools au détail dans l'Iowa
L'ensemble de données sur les ventes de boissons alcoolisées au détail dans l'Iowa est fourni sur BigQuery via le programme d'ensembles de données publics de Google Cloud. Cet ensemble de données contient tous les achats de boissons alcoolisées en gros effectués par les détaillants dans l'État de l'Iowa depuis le 1er janvier 2012. Les données sont collectées par la division des boissons alcoolisées du département du commerce de l'Iowa.
Dans BigQuery, interrogez bigquery-public-data.iowa_liquor_sales.sales pour analyser les ventes de boissons alcoolisées au détail dans l'Iowa. Utilisez la méthode bigframes.pandas.read_gbq() pour créer un DataFrame à partir d'une chaîne de requête ou d'un ID de table.
Exécutez le code suivant dans une nouvelle cellule de code pour créer un DataFrame nommé "df" :
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
Découvrir des informations de base sur un DataFrame
Utilisez la méthode DataFrame.peek() pour télécharger un petit échantillon des données.
Exécutez cette cellule :
df.peek()
Résultat attendu :
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
Remarque : head() nécessite un tri et est généralement moins efficace que peek() si vous souhaitez visualiser un échantillon de données.
Comme avec pandas, utilisez la propriété DataFrame.dtypes pour afficher toutes les colonnes disponibles et leurs types de données correspondants. Elles sont exposées de manière compatible avec pandas.
Exécutez cette cellule :
df.dtypes
Résultat attendu :
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
La méthode DataFrame.describe() interroge des statistiques de base à partir du DataFrame. Exécutez DataFrame.to_pandas() pour télécharger ces statistiques récapitulatives sous forme de DataFrame pandas.
Exécutez cette cellule :
df.describe("all").to_pandas()
Résultat attendu :
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
4. Visualiser et nettoyer les données
L'ensemble de données sur les ventes de boissons alcoolisées dans l'Iowa fournit des informations géographiques précises, y compris l'emplacement des magasins. Utilisez ces données pour identifier les tendances et les différences entre les zones géographiques.
Visualiser les ventes par code postal
Il existe plusieurs méthodes de visualisation intégrées, telles que DataFrame.plot.hist(). Utilisez cette méthode pour comparer les ventes d'alcool par code postal.
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
Résultat attendu :

Utilisez un graphique à barres pour identifier les codes postaux où le plus d'alcool a été vendu.
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Résultat attendu :
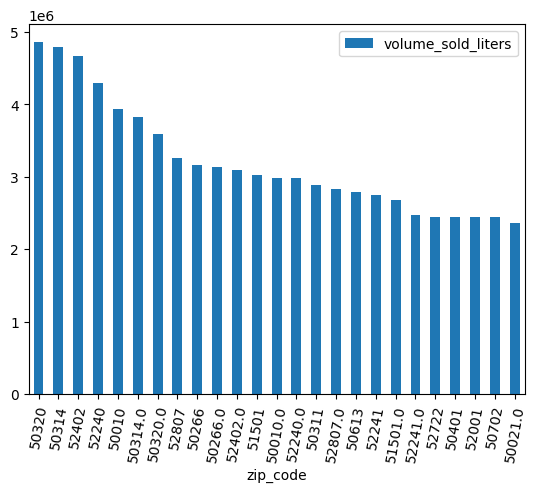
Nettoyer les données
Certains codes postaux sont suivis d'un .0. Il est possible que les codes postaux aient été accidentellement convertis en valeurs à virgule flottante lors de la collecte des données. Utilisez des expressions régulières pour nettoyer les codes postaux et répétez l'analyse.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Résultat attendu :

5. Découvrir les corrélations dans les ventes
Pourquoi certains codes postaux génèrent-ils plus de ventes que d'autres ? Une hypothèse est que cela est dû à des différences de taille de population. Un code postal avec une population plus importante vendra probablement plus d'alcool.
Testez cette hypothèse en calculant la corrélation entre la population et le volume des ventes d'alcool.
Effectuer une jointure avec d'autres ensembles de données
Associez-le à un ensemble de données sur la population, comme l'enquête sur les zones de tabulation des codes postaux de l'American Community Survey du Bureau du recensement des États-Unis.
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
L'American Community Survey identifie les États par GEOID. Dans le cas des zones de tabulation de codes postaux, le GEOID est égal au code postal.
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
Crée un graphique en nuage de points pour comparer les populations des zones de tabulation des codes postaux avec les litres d'alcool vendus.
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
Résultat attendu :

Calculer les corrélations
La tendance semble à peu près linéaire. Ajustez un modèle de régression linéaire à ces données pour vérifier dans quelle mesure la population peut prédire les ventes d'alcool.
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
Vérifiez la qualité de l'ajustement à l'aide de la méthode score.
model.score(feature_columns, label_columns).to_pandas()
Exemple de résultat :
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
Tracez la ligne de régression en appelant la fonction predict sur une plage de valeurs de population.
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
Résultat attendu :

Gérer l'hétéroscédasticité
Les données du graphique précédent semblent hétéroscédastiques. La variance autour de la ligne de régression augmente avec la population.
Peut-être que la quantité d'alcool achetée par personne est relativement constante.
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
Résultat attendu :

Calculez la moyenne des litres d'alcool achetés de deux manières différentes :
- Quelle est la quantité moyenne d'alcool achetée par personne dans l'Iowa ?
- Moyenne, pour tous les codes postaux, de la quantité d'alcool achetée par personne.
Dans (1), il reflète la quantité d'alcool achetée dans l'ensemble de l'État. Dans (2), il reflète le code postal moyen, qui ne sera pas nécessairement le même que (1), car les populations des différents codes postaux sont différentes.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
Résultat attendu : 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
Résultat attendu : 67.139
Représentez ces moyennes sous forme de graphique, comme ci-dessus.
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
Résultat attendu :
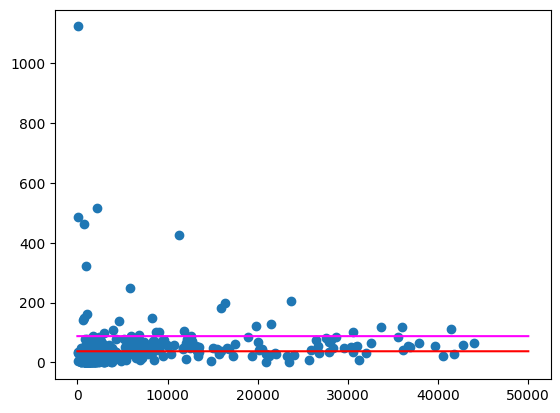
Il existe encore des codes postaux qui sont des valeurs aberrantes assez importantes, en particulier dans les zones moins peuplées. Nous vous laissons le soin de formuler des hypothèses pour expliquer ce phénomène. Par exemple, il se peut que certains codes postaux aient une faible population, mais une forte consommation, car ils contiennent le seul magasin d'alcool de la région. Si tel est le cas, le calcul basé sur la population des codes postaux environnants peut permettre de lisser ces valeurs aberrantes.
6. Comparer les types d'alcool vendus
En plus des données géographiques, la base de données des ventes d'alcool au détail de l'Iowa contient également des informations détaillées sur les articles vendus. En les analysant, nous pourrons peut-être révéler des différences de goûts entre les zones géographiques.
Parcourir les catégories
Les éléments sont classés dans la base de données. Combien de catégories y a-t-il ?
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
Résultat attendu : 103
Quelles sont les catégories les plus populaires en termes de volume ?
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)

Utiliser le type de données ARRAY
Il existe plusieurs catégories de whisky, de rhum, de vodka, etc. J'aimerais les regrouper d'une manière ou d'une autre.
Commencez par diviser les noms de catégories en mots distincts à l'aide de la méthode Series.str.split(). Désimbriquez le tableau ainsi créé à l'aide de la méthode explode().
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)

category_parts.nunique()
Résultat attendu : 113
Si vous regardez le graphique ci-dessus, les données indiquent toujours que VODKA est distinct de VODKAS. Un regroupement supplémentaire est nécessaire pour réduire le nombre de catégories.
7. Utiliser NLTK avec BigQuery DataFrames
Avec seulement une centaine de catégories, il serait possible d'écrire des heuristiques ou même de créer manuellement un mappage entre les catégories et le type de boisson alcoolisée plus large. Il est également possible d'utiliser un grand modèle de langage tel que Gemini pour créer un tel mappage. Essayez l'atelier de programmation Obtenir des insights à partir de données non structurées à l'aide de BigQuery DataFrames pour utiliser BigQuery DataFrames avec Gemini.
Utilisez plutôt un package de traitement du langage naturel plus traditionnel, NLTK, pour traiter ces données. Par exemple, une technologie appelée "stemmer" peut fusionner les noms au pluriel et au singulier dans la même valeur.
Utiliser NLTK pour extraire la racine des mots
Le package NLTK fournit des méthodes de traitement du langage naturel accessibles depuis Python. Installez le package pour l'essayer.
%pip install nltk
Importez ensuite le package. Inspectez la version. Vous en aurez besoin dans la suite de ce tutoriel.
import nltk
nltk.__version__
Une façon de standardiser les mots consiste à les "raciniser". Cela supprime tous les suffixes, comme le "s" à la fin des mots au pluriel.
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
Essayez sur quelques mots.
stem("WHISKEY")
Résultat attendu : whiskey
stem("WHISKIES")
Résultat attendu : whiski
Malheureusement, cela n'a pas permis de mapper "whiskies" sur "whisky". Les stemmers ne fonctionnent pas bien avec les pluriels irréguliers. Essayez un lemmatiseur, qui utilise des techniques plus sophistiquées pour identifier le mot de base, appelé "lemme".
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
Essayez sur quelques mots.
lemmatize("WHISKIES")
Résultat attendu : whisky
lemmatize("WHISKY")
Résultat attendu : whisky
lemmatize("WHISKEY")
Résultat attendu : whiskey
Malheureusement, ce lemmatiseur ne mappe pas "whiskey" au même lemme que "whiskies". Comme ce mot est particulièrement important pour la base de données des ventes de boissons alcoolisées dans l'Iowa, mappez-le manuellement à l'orthographe américaine à l'aide d'un dictionnaire.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Essayez sur quelques mots.
lemmatize("WHISKIES")
Résultat attendu : whiskey
lemmatize("WHISKEY")
Résultat attendu : whiskey
Félicitations ! Ce lemmatiseur devrait permettre de réduire le nombre de catégories. Pour l'utiliser avec BigQuery, vous devez le déployer dans le cloud.
Configurer votre projet pour le déploiement de fonctions
Avant de déployer cette fonction dans le cloud pour que BigQuery puisse y accéder, vous devez effectuer une configuration ponctuelle.
Créez une cellule de code et remplacez your-project-id par l'ID du projet Google Cloud que vous utilisez pour ce tutoriel.
project_id = "your-project-id"
Créez un compte de service sans aucune autorisation, car cette fonction n'a pas besoin d'accéder à des ressources cloud.
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
Résultat attendu : bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
Créez un ensemble de données BigQuery pour contenir la fonction.
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
Déployer une fonction distante
Activez l'API Cloud Functions si ce n'est pas déjà fait.
!gcloud services enable cloudfunctions.googleapis.com
Déployez maintenant votre fonction dans l'ensemble de données que vous venez de créer. Ajoutez un décorateur @bpd.remote_function à la fonction que vous avez créée lors des étapes précédentes.
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Le déploiement devrait prendre environ deux minutes.
Utiliser les fonctions à distance
Une fois le déploiement terminé, vous pouvez tester cette fonction.
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
Résultat attendu :
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
8. Comparer la consommation d'alcool par comté
Maintenant que la fonction lemmatize est disponible, utilisez-la pour combiner des catégories.
Trouver le mot qui résume le mieux la catégorie
Commencez par créer un DataFrame de toutes les catégories de la base de données.
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
Résultat attendu :
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
Ensuite, créez un DataFrame de tous les mots des catégories, à l'exception de quelques mots de remplissage comme la ponctuation et "article".
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
Résultat attendu :
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
Notez qu'en lemmatisant après le regroupement, vous réduisez la charge sur votre fonction Cloud. Il est possible d'appliquer la fonction de lemmatisation à chacune des plusieurs millions de lignes de la base de données, mais cela coûterait plus cher que de l'appliquer après le regroupement et pourrait nécessiter une augmentation du quota.
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
Résultat attendu :
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
Maintenant que les mots ont été lemmatisés, vous devez sélectionner le lemme qui résume le mieux la catégorie. Étant donné qu'il n'y a pas beaucoup de mots fonctionnels dans les catégories, utilisez l'heuristique selon laquelle, si un mot apparaît dans plusieurs autres catégories, il est probablement préférable de l'utiliser comme mot récapitulatif (par exemple, "whisky").
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
Résultat attendu :
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
Maintenant qu'il existe un seul lemme résumant chaque catégorie, fusionnez-le avec le DataFrame d'origine.
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
Résultat attendu :
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
Comparer des comtés
Comparez les ventes dans chaque comté pour identifier les différences.
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
Trouvez le produit (lemme) le plus vendu dans chaque comté.
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
Résultat attendu :
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
Quelles sont les différences entre les comtés ?
county_max_lemma.groupby("lemma").size().to_pandas()
Résultat attendu :
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
Dans la plupart des comtés, le whisky est le produit le plus populaire en volume, tandis que la vodka est la plus populaire dans 15 comtés. Comparez cela aux types d'alcool les plus populaires dans l'État.
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
Résultat attendu :
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
Le volume de whisky et de vodka est presque identique, celui de la vodka étant légèrement supérieur à celui du whisky dans l'ensemble de l'État.
Comparer des proportions
Qu'est-ce qui rend les ventes uniques dans chaque comté ? Qu'est-ce qui différencie le comté du reste de l'État ?
Utilisez la mesure h de Cohen pour identifier les volumes de vente d'alcool qui diffèrent le plus proportionnellement de ce qui serait attendu en fonction de la proportion des ventes à l'échelle de l'État.
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
Maintenant que le h de Cohen a été mesuré pour chaque lemme, trouvez la plus grande différence par rapport à la proportion à l'échelle de l'État dans chaque comté.
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
Résultat attendu :
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
Plus la valeur h de Cohen est élevée, plus il est probable qu'il existe une différence statistiquement significative dans la quantité de ce type d'alcool consommée par rapport aux moyennes de l'État. Pour les valeurs positives plus petites, la différence de consommation est différente de la moyenne de l'État, mais cela peut être dû à des différences aléatoires.
Remarque : Le comté d'EL PASO ne semble pas être un comté de l'Iowa. Cela peut indiquer qu'il est nécessaire de nettoyer les données avant de se fier entièrement à ces résultats.
Visualiser les comtés
Effectuez une jointure avec la table bigquery-public-data.geo_us_boundaries.counties pour obtenir la zone géographique de chaque comté. Les noms de comtés ne sont pas uniques aux États-Unis. Filtrez donc les données pour n'inclure que les comtés de l'Iowa. Le code FIPS de l'Iowa est "19".
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
Résultat attendu :
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
Utilisez GeoPandas pour visualiser ces différences sur une carte.
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)

9. Effectuer un nettoyage
Si vous avez créé un projet Google Cloud pour ce tutoriel, vous pouvez le supprimer pour éviter des frais supplémentaires pour les tables ou autres ressources créées.
Vous pouvez également supprimer les fonctions Cloud, les comptes de service et les ensembles de données créés pour ce tutoriel.
10. Félicitations !
Vous avez nettoyé et analysé des données structurées à l'aide de DataFrames BigQuery. Vous avez exploré les ensembles de données publics de Google Cloud, les notebooks Python dans BigQuery Studio, BigQuery ML, les fonctions distantes BigQuery et la puissance de BigQuery DataFrames. Bravo !
Étapes suivantes
- Appliquez ces étapes à d'autres données, comme la base de données des noms aux États-Unis.
- Essayez de générer du code Python dans votre notebook. Les notebooks Python dans BigQuery Studio sont fournis par Colab Enterprise. Conseil : Je trouve très utile de demander de l'aide pour générer des données de test.
- Explorez les exemples de notebooks pour BigQuery DataFrames sur GitHub.
- Créez une programmation pour exécuter un notebook dans BigQuery Studio.
- Déployez une fonction distante avec BigQuery DataFrames pour intégrer des packages Python tiers à BigQuery.