
1. סקירה כללית
בשיעור Lab הזה תשתמשו ב-BigQuery DataFrames מתוך מחברת Python ב-BigQuery Studio כדי לנקות ולנתח את מערך הנתונים הציבורי של מכירות משקאות חריפים באיווה. להשתמש ביכולות של BigQuery ML ושל פונקציות מרוחקות כדי להפיק תובנות.
תצרו קובץ notebook של Python כדי להשוות מכירות באזורים גיאוגרפיים שונים. אפשר להתאים את התהליך הזה כך שיפעל על כל נתון מובנה.
מטרות
בשיעור ה-Lab הזה תלמדו איך לבצע את המשימות הבאות:
- הפעלה ושימוש ב-notebooks של Python ב-BigQuery Studio
- התחברות ל-BigQuery באמצעות חבילת BigQuery DataFrames
- יצירת רגרסיה ליניארית באמצעות BigQuery ML
- ביצוע צבירות וצירופים מורכבים באמצעות תחביר מוכר שדומה ל-pandas
2. דרישות
לפני שמתחילים
כדי לפעול לפי ההוראות ב-codelab הזה, תצטרכו פרויקט ב-Google Cloud שבו מופעל BigQuery Studio ומקושר אליו חשבון לחיוב.
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט בענן שלכם ב-Google Cloud. כך בודקים אם החיוב מופעל בפרויקט
- פועלים לפי ההוראות להפעלת BigQuery Studio לניהול נכסים.
הכנה של BigQuery Studio
יוצרים מחברת ריקה ומקשרים אותה לסביבת זמן ריצה.
- עוברים אל BigQuery Studio במסוף Google Cloud.
- לוחצים על ▼ לצד הלחצן +.
- בוחרים באפשרות Python notebook.
- סוגרים את בורר התבניות.
- לוחצים על + Code (קוד) כדי ליצור תא קוד חדש.
- מתקינים את הגרסה העדכנית של חבילת BigQuery DataFrames מתא הקוד.מקלידים את הפקודה הבאה.
%pip install --upgrade bigframes --quiet
3. קריאה של מערך נתונים ציבורי
מאתחלים את חבילת BigQuery DataFrames על ידי הפעלת הפקודה הבאה בתא קוד חדש:
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
הערה: במדריך הזה אנחנו משתמשים ב'מצב סדר חלקי' הניסיוני, שמאפשר לבצע שאילתות יעילות יותר כשמשתמשים בו עם סינון כמו ב-pandas. יכול להיות שחלק מהתכונות של pandas שדורשות סדר או אינדקס מדויקים לא יפעלו.
בודקים את גרסת החבילה של bigframes באמצעות
bpd.__version__
כדי לבצע את ההדרכה הזו, צריך להשתמש בגרסה 1.27.0 ואילך.
Iowa liquor retail sales
מערך הנתונים של מכירות קמעונאיות של משקאות חריפים באיווה מסופק ב-BigQuery דרך התוכנית של Google Cloud למערכי נתונים ציבוריים. מערך הנתונים הזה מכיל כל רכישה סיטונאית של משקאות חריפים במדינת איווה על ידי קמעונאים למכירה לאנשים פרטיים מאז 1 בינואר 2012. הנתונים נאספים על ידי המחלקה למשקאות אלכוהוליים במשרד המסחר של איווה.
ב-BigQuery, מריצים שאילתה בטבלה bigquery-public-data.iowa_liquor_sales.sales כדי לנתח את נתוני המכירות הקמעונאיות של משקאות חריפים באיווה. משתמשים ב-method bigframes.pandas.read_gbq() כדי ליצור DataFrame ממחרוזת שאילתה או ממזהה טבלה.
מריצים את הקוד הבא בתא קוד חדש כדי ליצור DataFrame בשם df:
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
קבלת מידע בסיסי על DataFrame
כדי להוריד מדגם קטן של הנתונים, משתמשים בשיטה DataFrame.peek().
הרצת התא הזה:
df.peek()
הפלט הצפוי:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
הערה: כדי להשתמש ב-head() צריך להזמין אותה, ובדרך כלל היא פחות יעילה מ-peek() אם רוצים להציג מדגם של נתונים.
בדומה ל-pandas, משתמשים במאפיין DataFrame.dtypes כדי לראות את כל העמודות הזמינות ואת סוגי הנתונים התואמים שלהן. הם מוצגים באופן שתואם ל-pandas.
הרצת התא הזה:
df.dtypes
הפלט הצפוי:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
השיטה DataFrame.describe() מפעילה שאילתות על נתונים סטטיסטיים בסיסיים מ-DataFrame. מריצים את הפקודה DataFrame.to_pandas() כדי להוריד את הנתונים הסטטיסטיים האלה של הסיכום כ-pandas DataFrame.
הרצת התא הזה:
df.describe("all").to_pandas()
הפלט הצפוי:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
4. המחשה וניקוי של הנתונים
מערך הנתונים של מכירות קמעונאיות של משקאות חריפים באיווה מספק מידע גיאוגרפי מפורט, כולל המיקום של החנויות הקמעונאיות. אפשר להשתמש בנתונים האלה כדי לזהות מגמות והבדלים באזורים גיאוגרפיים שונים.
הדמיה של נתוני המכירות לפי מיקוד
יש כמה שיטות מובנות להצגת נתונים, כמו DataFrame.plot.hist(). אפשר להשתמש בשיטה הזו כדי להשוות את מכירות המשקאות החריפים לפי מיקוד.
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
הפלט הצפוי:
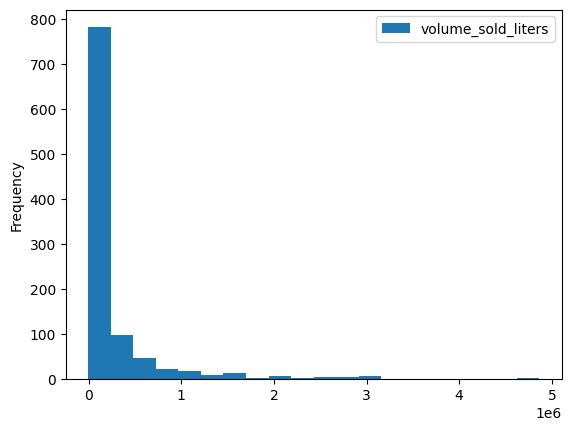
אפשר להשתמש בתרשים עמודות כדי לראות באילו מיקודים נמכרו הכי הרבה משקאות אלכוהוליים.
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
הפלט הצפוי:
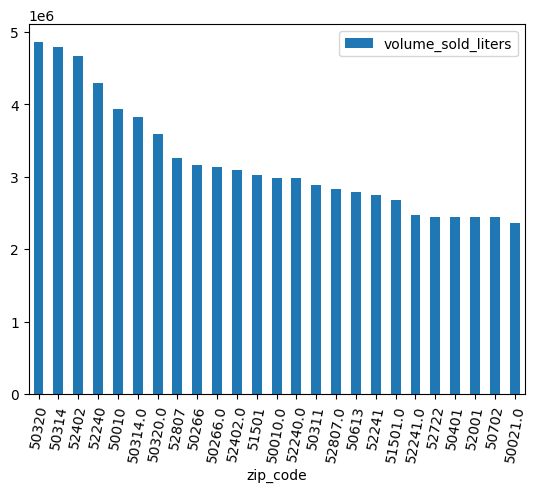
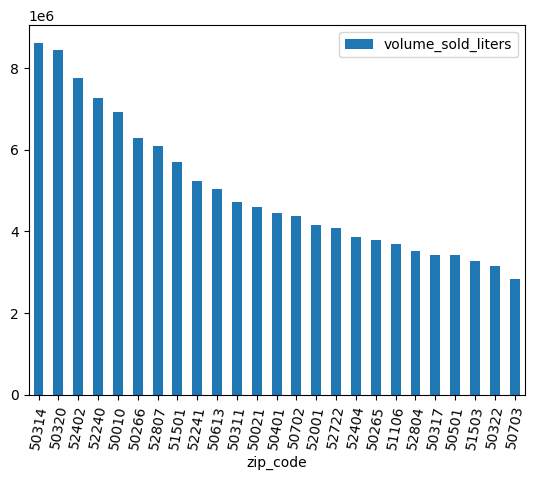
ניקוי הנתונים
לחלק מהמיקודים יש סיומת .0. יכול להיות שבמהלך איסוף הנתונים, מיקודים הומרו בטעות לערכים של נקודה צפה. משתמשים בביטויים רגולריים כדי לנקות את המיקודים וחוזרים על הניתוח.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
הפלט הצפוי:
5. גילוי קורלציות במכירות
למה יש אזורי מיקוד שבהם נפח המכירות גבוה יותר מאשר באזורי מיקוד אחרים? השערה אחת היא שההבדל נובע מהבדלים בגודל האוכלוסייה. בדרך כלל, באזור מיקוד עם יותר תושבים יימכרו יותר משקאות חריפים.
כדי לבדוק את ההשערה הזו, מחשבים את המתאם בין האוכלוסייה לבין נפח המכירות של משקאות חריפים.
שילוב עם מערכי נתונים אחרים
אפשר לשלב עם מערך נתונים של אוכלוסייה, כמו סקר אזורי המיקוד של US Census Bureau's American Community Survey.
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
בסקר American Community Survey, המדינות מזוהות באמצעות GEOID. במקרה של אזורי טבלה של מיקודים, ה-GEOID שווה למיקוד.
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
יוצרים תרשים פיזור כדי להשוות בין אוכלוסיות באזורים שמוגדרים לפי מיקוד לבין ליטרים של אלכוהול שנמכרו.
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
הפלט הצפוי:
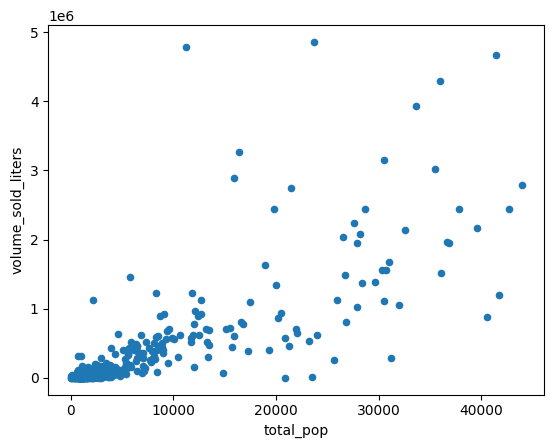
חישוב מתאמים
המגמה נראית לינארית בערך. כדי לבדוק עד כמה אפשר לחזות את מכירות המשקאות החריפים על סמך גודל האוכלוסייה, אפשר להתאים למודל הזה מודל רגרסיה לינארית.
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
כדי לבדוק את מידת ההתאמה, משתמשים בשיטה score.
model.score(feature_columns, label_columns).to_pandas()
פלט לדוגמה:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
משרטטים את קו ההתאמה הטוב ביותר על ידי הפעלת הפונקציה predict על טווח של ערכי אוכלוסייה.
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
הפלט הצפוי:
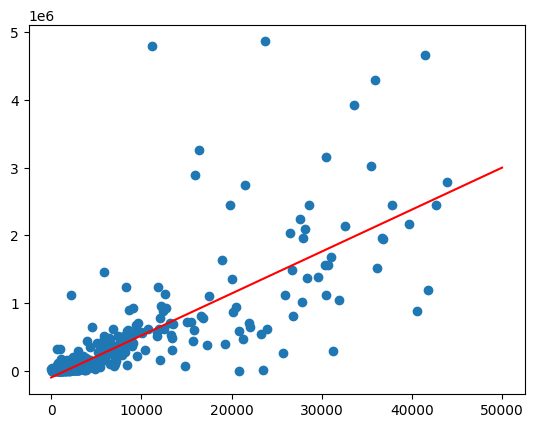
טיפול בהטרוסקדסטיות
הנתונים בתרשים הקודם נראים הטרוסקדסטיים. השונות סביב הקו בעל ההתאמה הטובה ביותר גדלה עם האוכלוסייה.
יכול להיות שכמות האלכוהול שנרכשת לכל אדם היא קבועה יחסית.
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
הפלט הצפוי:
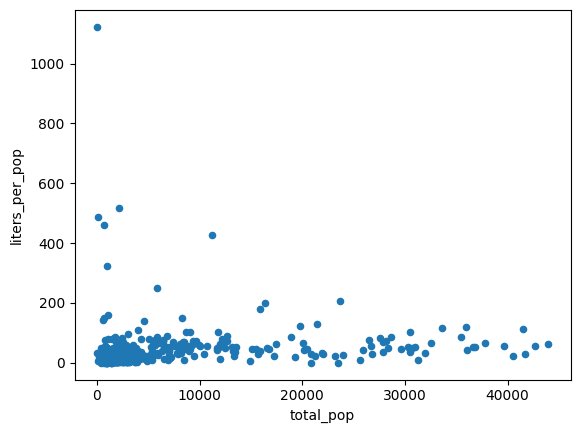
חשב את כמות האלכוהול הממוצעת (בליטרים) שנרכשה בשתי דרכים שונות:
- מהו הסכום הממוצע של אלכוהול שנרכש לכל אדם באיווה?
- מהו הממוצע של כמות האלכוהול שנרכשה לכל אדם בכל המיקודים.
ב-(1), הוא משקף את כמות האלכוהול שנרכשה בכל המדינה. ב-(2) מוצג המיקוד הממוצע, שלא בהכרח יהיה זהה ל-(1) כי יש הבדלים בין אוכלוסיות שגרות במיקודים שונים.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
הפלט הצפוי: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
הפלט הצפוי: 67.139
משרטטים את הממוצעים האלה, כמו בדוגמה שלמעלה.
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
הפלט הצפוי:
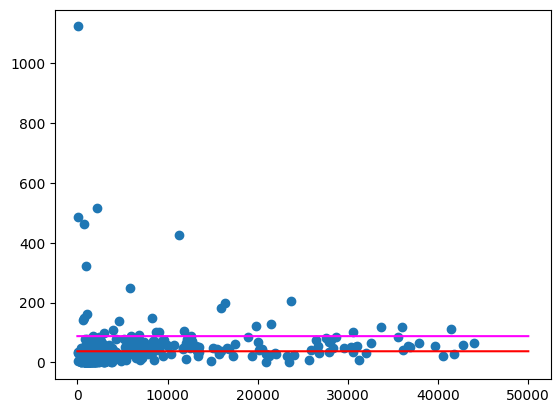
עדיין יש כמה מיקודים שהם חריגים גדולים למדי, במיוחד באזורים עם אוכלוסייה קטנה יותר. מומלץ להעלות השערות לגבי הסיבה לכך. לדוגמה, יכול להיות שבאזורים מסוימים יש אוכלוסייה קטנה אבל צריכה גבוהה כי יש בהם את חנות המשקאות היחידה באזור. אם כן, חישוב על סמך אוכלוסיית המיקודים הסמוכים עשוי לאזן את הערכים החריגים האלה.
6. השוואה בין סוגים של משקאות אלכוהוליים שנמכרים
בנוסף לנתונים גיאוגרפיים, מסד הנתונים של מכירות קמעונאיות של משקאות חריפים באיווה מכיל גם מידע מפורט על הפריט שנמכר. אולי באמצעות ניתוח הנתונים האלה נוכל לגלות הבדלים בטעמים באזורים גיאוגרפיים שונים.
עוד קטגוריות
הפריטים מסווגים במסד הנתונים. כמה קטגוריות יש?
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
הפלט הצפוי: 103
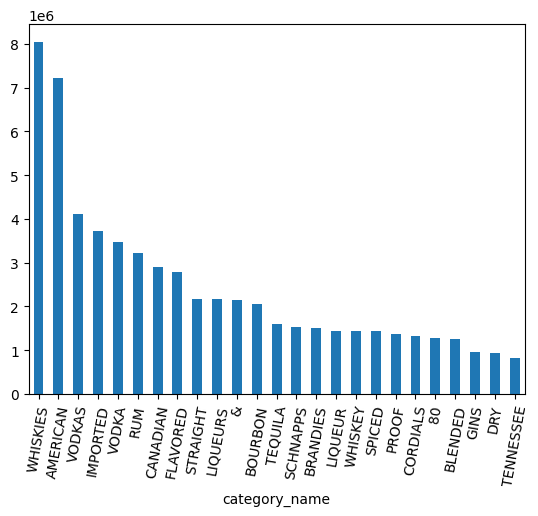
מהן הקטגוריות הכי פופולריות לפי נפח?
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
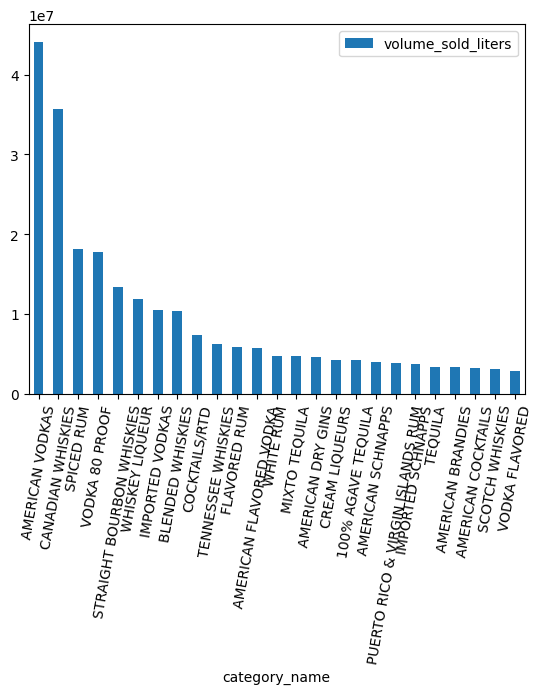
עבודה עם סוג הנתונים ARRAY
יש כמה קטגוריות של ויסקי, רום, וודקה ועוד. הייתי רוצה לקבץ אותם יחד בצורה כלשהי.
מתחילים בפיצול שמות הקטגוריות למילים נפרדות באמצעות השיטה Series.str.split(). כדי לבטל את הקינון של המערך שנוצר, משתמשים ב-method explode().
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
category_parts.nunique()
הפלט הצפוי: 113
אם בוחנים את התרשים שלמעלה, אפשר לראות שהנתונים עדיין מציגים את VODKA בנפרד מ-VODKAS. כדי לכווץ את הקטגוריות לקבוצה קטנה יותר, צריך להוסיף עוד קיבוץ.
7. שימוש ב-NLTK עם BigQuery DataFrames
עם כ-100 קטגוריות בלבד, אפשר לכתוב היוריסטיקות או אפילו ליצור מיפוי ידני מקטגוריה לסוג המשקאות הרחב יותר. אפשר גם להשתמש במודל שפה גדול כמו Gemini כדי ליצור מיפוי כזה. כדאי לנסות את ה-codelab קבלת תובנות מנתונים לא מובנים באמצעות BigQuery DataFrames כדי להשתמש ב-BigQuery DataFrames עם Gemini.
במקום זאת, אפשר להשתמש בחבילת עיבוד שפה טבעית (NLP) מסורתית יותר, NLTK, כדי לעבד את הנתונים האלה. לדוגמה, טכנולוגיה שנקראת 'stemmer' יכולה למזג שמות עצם ברבים וביחיד לאותו ערך.
שימוש ב-NLTK כדי להסיר את התחיליות והסיומות של מילים
חבילת NLTK מספקת שיטות לעיבוד שפה טבעית שאפשר לגשת אליהן מ-Python. כדי לנסות את התכונה, מתקינים את החבילה.
%pip install nltk
בשלב הבא, מייבאים את החבילה. בודקים את הגרסה. נשתמש בו בהמשך המדריך.
import nltk
nltk.__version__
אחת הדרכים לתקנן מילים היא להשתמש בשיטת ה-stemming. הפעולה הזו מסירה את כל הסיומות, כמו 's' בסוף מילים ברבים.
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
נסו את זה על כמה מילים.
stem("WHISKEY")
הפלט הצפוי: whiskey
stem("WHISKIES")
הפלט הצפוי: whiski
לצערנו, המיפוי הזה לא התאים את המילה whiskies לאותו מיפוי של המילה whiskey. השימוש ב-Stemmers לא יעיל עם מילים ברבים לא סדיר. אפשר לנסות להשתמש בכלי לניתוח מורפולוגי, שמשתמש בטכניקות מתוחכמות יותר כדי לזהות את מילת הבסיס, שנקראת 'למה'.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
נסו את זה על כמה מילים.
lemmatize("WHISKIES")
הפלט הצפוי: whisky
lemmatize("WHISKY")
הפלט הצפוי: whisky
lemmatize("WHISKEY")
הפלט הצפוי: whiskey
לצערנו, הכלי הזה לא ממפה את המילה whiskey לאותו בסיס כמו המילה whiskies. המילה הזו חשובה במיוחד למסד הנתונים של מכירות משקאות חריפים קמעונאיים באיווה, ולכן צריך למפות אותה ידנית לאיות האמריקאי באמצעות מילון.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
נסו את זה על כמה מילים.
lemmatize("WHISKIES")
הפלט הצפוי: whiskey
lemmatize("WHISKEY")
הפלט הצפוי: whiskey
מזל טוב! הלמטיזטור הזה אמור לעזור לצמצם את הקטגוריות. כדי להשתמש בו עם BigQuery, צריך לפרוס אותו בענן.
הגדרת הפרויקט לפריסת פונקציות
לפני שמפעילים את הפונקציה הזו בענן כדי ש-BigQuery יוכל לגשת אליה, צריך לבצע הגדרה חד-פעמית.
יוצרים תא קוד חדש ומחליפים את your-project-id במזהה הפרויקט ב-Google Cloud שבו אתם משתמשים במדריך הזה.
project_id = "your-project-id"
יוצרים חשבון שירות ללא הרשאות, כי הפונקציה הזו לא צריכה גישה למשאבי ענן.
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
הפלט הצפוי: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
יוצרים מערך נתונים ב-BigQuery שיכיל את הפונקציה.
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
פריסת פונקציה מרחוק
מפעילים את Cloud Functions API אם הוא עדיין לא מופעל.
!gcloud services enable cloudfunctions.googleapis.com
עכשיו, פורסים את הפונקציה למערך הנתונים שיצרתם. מוסיפים את העיטור @bpd.remote_function לפונקציה שיצרתם בשלבים הקודמים.
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
הפריסה אמורה להימשך כשתי דקות.
שימוש בפונקציות של השלט הרחוק
אחרי שהפריסה מסתיימת, אפשר לבדוק את הפונקציה הזו.
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
הפלט הצפוי:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
8. השוואה של צריכת אלכוהול לפי מחוז
עכשיו, כשהפונקציה lemmatize זמינה, אפשר להשתמש בה כדי לשלב קטגוריות.
חיפוש המילה שהכי מתאימה לסיכום הקטגוריה
קודם כל, יוצרים DataFrame של כל הקטגוריות במסד הנתונים.
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
הפלט הצפוי:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
לאחר מכן, יוצרים DataFrame של כל המילים בקטגוריות, למעט כמה מילות מילוי כמו סימני פיסוק והמילה item.
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
הפלט הצפוי:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
שימו לב: ביצוע למטיזציה אחרי הקיבוץ מקטין את העומס על פונקציה של Cloud Functions. אפשר להחיל את הפונקציה lemmatize על כל אחת מכמה מיליוני השורות במסד הנתונים, אבל זה יעלה יותר מאשר להחיל אותה אחרי הקיבוץ, ויכול להיות שיהיה צורך להגדיל את המכסה.
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
הפלט הצפוי:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
אחרי שהמילים עברו למיזציה, צריך לבחור את הלמה שמסכמת בצורה הטובה ביותר את הקטגוריה. מכיוון שאין הרבה מילות תפקוד בקטגוריות, אפשר להשתמש בהיוריסטיקה הבאה: אם מילה מופיעה בכמה קטגוריות אחרות, סביר להניח שעדיף להשתמש בה כמילה מסכמת (למשל, ויסקי).
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
הפלט הצפוי:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
עכשיו, אחרי שיש למה אחת שמסכמת כל קטגוריה, צריך למזג אותה עם ה-DataFrame המקורי.
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
הפלט הצפוי:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
השוואה בין מחוזות
כדאי להשוות את נתוני המכירות בכל מחוז כדי לראות את ההבדלים.
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
למצוא את המוצר (הלמה) שנמכר הכי הרבה בכל מחוז.
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
הפלט הצפוי:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
מה ההבדל בין המחוזות?
county_max_lemma.groupby("lemma").size().to_pandas()
הפלט הצפוי:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
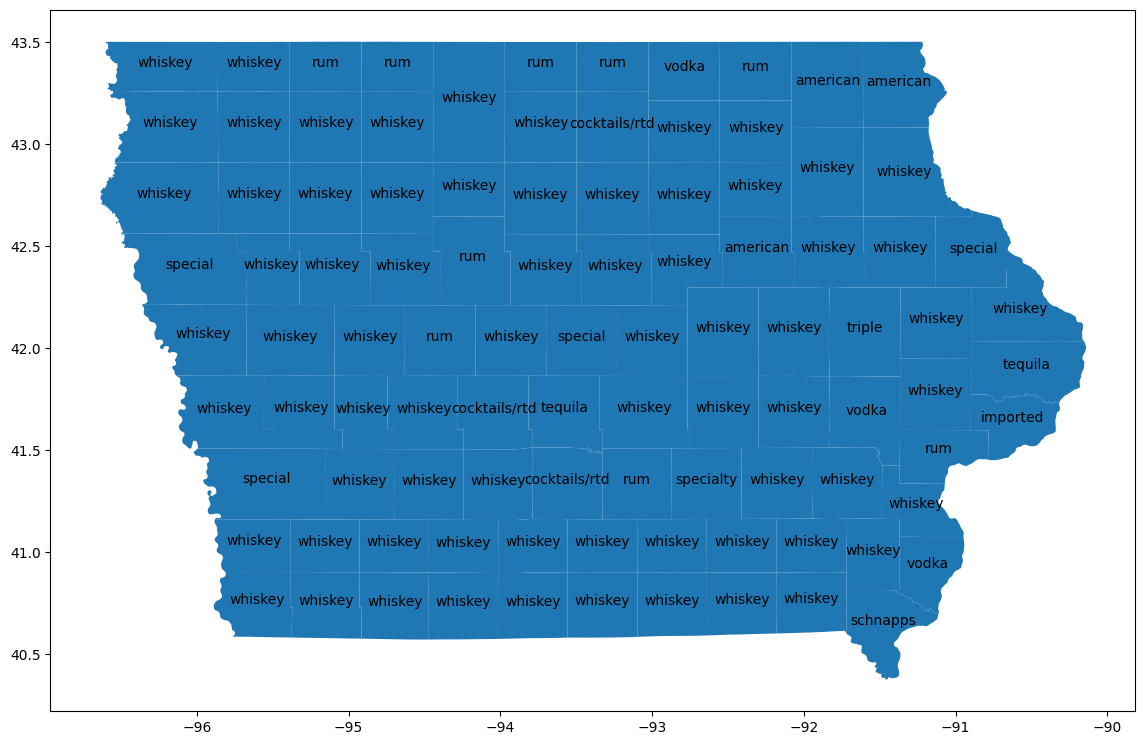
ברוב המחוזות, ויסקי הוא המוצר הפופולרי ביותר לפי נפח, וודקה היא המוצר הפופולרי ביותר ב-15 מחוזות. השוואה בין הנתון הזה לבין סוגי המשקאות החריפים הכי פופולריים ברמת המדינה.
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
הפלט הצפוי:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
לוויסקי ולודקה יש נפח כמעט זהה, כאשר נפח הוודקה מעט גבוה יותר מנפח הוויסקי ברמת המדינה.
השוואת שיעורים
מה מייחד את המכירות בכל מחוז? מה מייחד את המחוז משאר המדינה?
כדי לגלות אילו נפחי מכירות של משקאות חריפים שונים באופן יחסי הכי הרבה ממה שהיה צפוי על סמך שיעור המכירות ברמת המדינה, אפשר להשתמש במדד h של כהן.
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
אחרי שמודדים את h של כהן לכל למה, צריך למצוא את ההבדל הגדול ביותר מהשיעור ברמת המדינה בכל מחוז.
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
הפלט הצפוי:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
ככל שערך h של כהן גבוה יותר, כך גדל הסיכוי שיש הבדל בעל מובהקות סטטיסטית בכמות האלכוהול מהסוג הזה שנצרכה בהשוואה לממוצעים במדינה. במקרה של ערכים חיוביים קטנים יותר, ההבדל בצריכה שונה מהממוצע ברמת המדינה, אבל יכול להיות שההבדל נובע משינויים אקראיים.
הערה: נראה שמחוז אל פאסו הוא לא מחוז באיווה. יכול להיות שצריך לנקות את הנתונים לפני שמסתמכים באופן מלא על התוצאות האלה.
הצגה חזותית של מחוזות
מצטרפים לטבלה bigquery-public-data.geo_us_boundaries.counties כדי לקבל את האזור הגיאוגרפי של כל מחוז. שמות המחוזות לא ייחודיים בארצות הברית, לכן צריך לסנן כדי לכלול רק מחוזות מאיווה. קוד ה-FIPS של איווה הוא '19'.
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
הפלט הצפוי:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
אפשר להשתמש ב-GeoPandas כדי להציג את ההבדלים האלה במפה.
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)
9. הסרת המשאבים
אם יצרתם פרויקט חדש ב-Google Cloud לצורך המדריך הזה, תוכלו למחוק אותו כדי למנוע חיובים נוספים על טבלאות או משאבים אחרים שנוצרו.
אפשרות אחרת היא למחוק את Cloud Functions, חשבונות השירות ומערכי הנתונים שנוצרו לצורך המדריך הזה.
10. מעולה!
ניקיתם וניתחתם נתונים מובנים באמצעות BigQuery DataFrames. במהלך הקורס התנסיתם במערכי נתונים ציבוריים של Google Cloud, במחברות Python ב-BigQuery Studio, ב-BigQuery ML, בפונקציות מרוחקות של BigQuery וביכולות של BigQuery DataFrames. עבודה נהדרת!
השלבים הבאים
- אפשר להשתמש בשלבים האלה כדי להוסיף נתונים אחרים, כמו מסד הנתונים של שמות בארה"ב.
- אפשר לנסות ליצור קוד Python ב-notebook. קובצי Python Notebook ב-BigQuery Studio מופעלים על ידי Colab Enterprise. טיפ: לדעתי, מאוד שימושי לבקש עזרה ביצירת נתוני בדיקה.
- אפשר לעיין במחברות לדוגמה של BigQuery DataFrames ב-GitHub.
- יוצרים תזמון להרצת מחברת ב-BigQuery Studio.
- אפשר לפרוס פונקציה מרוחקת עם BigQuery DataFrames כדי לשלב חבילות Python של צד שלישי עם BigQuery.