
1. Panoramica
In questo lab utilizzerai BigQuery DataFrames da un blocco note Python in BigQuery Studio per pulire e analizzare il set di dati pubblico sulle vendite di liquori in Iowa. Utilizza le funzionalità di BigQuery ML e delle funzioni remote per scoprire approfondimenti.
Creerai un notebook Python per confrontare le vendite nelle diverse aree geografiche. Può essere adattato per funzionare con qualsiasi dato strutturato.
Obiettivi
In questo lab imparerai a:
- Attivare e utilizzare i notebook Python in BigQuery Studio
- Connettiti a BigQuery utilizzando il pacchetto BigQuery DataFrames
- Creare una regressione lineare utilizzando BigQuery ML
- Esegui aggregazioni e unioni complesse utilizzando una sintassi simile a pandas
2. Requisiti
Prima di iniziare
Per seguire le istruzioni di questo codelab, avrai bisogno di un progetto Google Cloud con BigQuery Studio abilitato e un account di fatturazione collegato.
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Segui le istruzioni per attivare BigQuery Studio per la gestione degli asset.
Prepara BigQuery Studio
Crea un notebook vuoto e connettilo a un runtime.
- Vai a BigQuery Studio nella console Google Cloud.
- Fai clic su ▼ accanto al pulsante +.
- Seleziona Notebook Python.
- Chiudi il selettore dei modelli.
- Seleziona + Codice per creare una nuova cella di codice.
- Installa l'ultima versione del pacchetto BigQuery DataFrames dalla cella di codice.Digita il seguente comando.
%pip install --upgrade bigframes --quiet
3. Leggere un set di dati pubblico
Inizializza il pacchetto BigQuery DataFrames eseguendo il seguente comando in una nuova cella di codice:
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
Nota: in questo tutorial utilizziamo la "modalità di ordinamento parziale" sperimentale, che consente query più efficienti se utilizzata con filtri simili a quelli di pandas. Alcune funzionalità di pandas che richiedono un ordinamento o un indice rigoroso potrebbero non funzionare.
Controlla la versione del pacchetto bigframes con
bpd.__version__
Questo tutorial richiede la versione 1.27.0 o successive.
Vendite al dettaglio di liquori in Iowa
Il set di dati sulle vendite al dettaglio di liquori in Iowa viene fornito su BigQuery tramite il programma per i set di dati pubblici di Google Cloud. Questo set di dati contiene tutti gli acquisti all'ingrosso di alcolici nello stato dell'Iowa da parte dei rivenditori per la vendita a privati a partire dal 1° gennaio 2012. I dati vengono raccolti dalla divisione per le bevande alcoliche del Dipartimento del Commercio dell'Iowa.
In BigQuery, esegui una query su bigquery-public-data.iowa_liquor_sales.sales per analizzare le vendite al dettaglio di liquori in Iowa. Utilizza il metodo bigframes.pandas.read_gbq() per creare un DataFrame da una stringa di query o da un ID tabella.
Esegui il seguente codice in una nuova cella di codice per creare un DataFrame denominato "df":
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
Scopri le informazioni di base su un DataFrame
Utilizza il metodo DataFrame.peek() per scaricare un piccolo campione dei dati.
Esegui questa cella:
df.peek()
Output previsto:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
Nota: head() richiede l'ordinamento ed è generalmente meno efficiente di peek() se vuoi visualizzare un campione di dati.
Come con pandas, utilizza la proprietà DataFrame.dtypes per visualizzare tutte le colonne disponibili e i relativi tipi di dati. Questi vengono esposti in modo compatibile con pandas.
Esegui questa cella:
df.dtypes
Output previsto:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
Il metodo DataFrame.describe() esegue query su alcune statistiche di base del DataFrame. Esegui DataFrame.to_pandas() per scaricare queste statistiche riepilogative come DataFrame Pandas.
Esegui questa cella:
df.describe("all").to_pandas()
Output previsto:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
4. Visualizzare e pulire i dati
Il set di dati sulle vendite al dettaglio di alcolici nell'Iowa fornisce informazioni geografiche granulari, inclusa la posizione dei negozi al dettaglio. Utilizza questi dati per identificare tendenze e differenze tra le aree geografiche.
Visualizzare le vendite per codice postale
Esistono diversi metodi di visualizzazione integrati, ad esempio DataFrame.plot.hist(). Utilizza questo metodo per confrontare le vendite di alcolici per codice postale.
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
Output previsto:
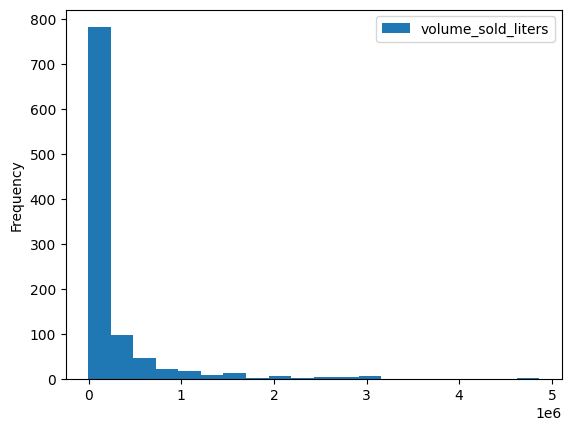
Utilizza un grafico a barre per vedere quali codici postali hanno venduto più alcolici.
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Output previsto:
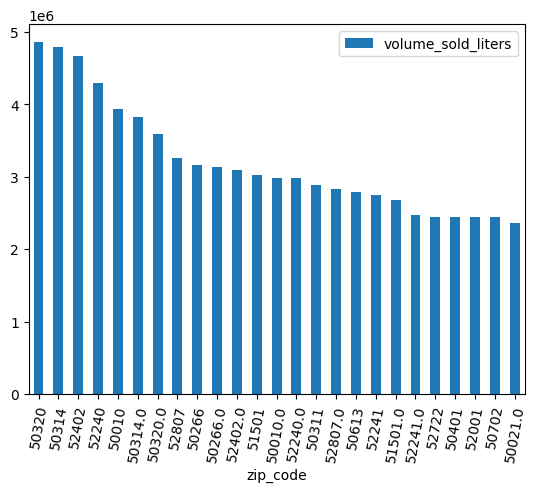
pulisci i dati
Alcuni codici postali hanno un .0 finale. È possibile che in qualche punto della raccolta dei dati i codici postali siano stati convertiti accidentalmente in valori in virgola mobile. Utilizza le espressioni regolari per ripulire i codici postali e ripeti l'analisi.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Output previsto:

5. Scopri le correlazioni nelle vendite
Perché alcuni codici postali vendono di più rispetto ad altri? Un'ipotesi è che ciò sia dovuto alle differenze nelle dimensioni della popolazione. Un codice postale con una popolazione più numerosa probabilmente venderà più liquori.
Verifica questa ipotesi calcolando la correlazione tra la popolazione e il volume delle vendite di liquori.
Unire ad altri set di dati
Unisciti a un set di dati sulla popolazione, ad esempio l'indagine sull'area di tabulazione dei codici postali dell'American Community Survey del Census Bureau degli Stati Uniti.
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
L'American Community Survey identifica gli stati in base al GEOID. Nel caso delle aree di tabulazione dei codici postali, il GEOID è uguale al codice postale.
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
Crea un grafico a dispersione per confrontare le popolazioni delle aree di tabulazione dei codici postali con i litri di alcol venduti.
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
Output previsto:

Calcolare le correlazioni
La tendenza sembra più o meno lineare. Adatta un modello di regressione lineare per verificare in che misura la popolazione può prevedere le vendite di liquori.
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
Controlla la qualità dell'adattamento utilizzando il metodo score.
model.score(feature_columns, label_columns).to_pandas()
Esempio di output:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
Traccia la linea di migliore adattamento chiamando la funzione predict su un intervallo di valori della popolazione.
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
Output previsto:
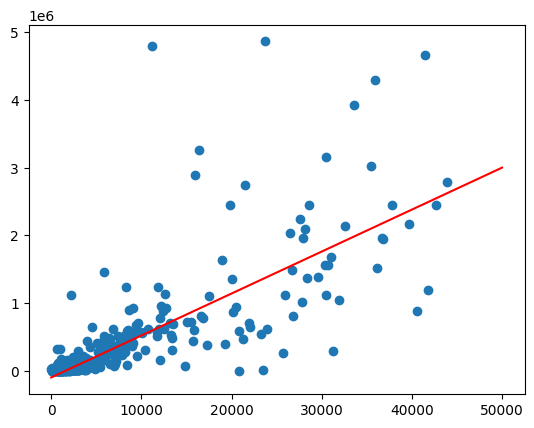
Gestione dell'eteroschedasticità
I dati nel grafico precedente sembrano eteroschedastici. La varianza intorno alla linea di miglior adattamento aumenta con la popolazione.
Forse la quantità di alcol acquistata per persona è relativamente costante.
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
Output previsto:

Calcola la media dei litri di alcolici acquistati in due modi diversi:
- Qual è la quantità media di alcolici acquistati per persona in Iowa?
- Qual è la media in tutti i codici postali della quantità di alcol acquistata per persona.
In (1), riflette la quantità di alcolici acquistati in tutto lo stato. In (2) viene visualizzato il codice postale medio, che non corrisponde necessariamente a (1) perché i diversi codici postali hanno popolazioni diverse.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
Output previsto: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
Output previsto: 67.139
Traccia queste medie, in modo simile a quanto sopra.
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
Output previsto:

Esistono ancora alcuni codici postali che sono valori anomali piuttosto grandi, soprattutto nelle aree con meno popolazione. Lasciamo a te il compito di ipotizzare il motivo. Ad esempio, potrebbe essere che alcuni codici postali abbiano una popolazione bassa ma un consumo elevato perché contengono l'unico negozio di liquori della zona. In questo caso, il calcolo basato sulla popolazione dei codici postali circostanti potrebbe compensare questi valori anomali.
6. Confronto tra i tipi di liquori venduti
Oltre ai dati geografici, il database delle vendite al dettaglio di alcolici dell'Iowa contiene anche informazioni dettagliate sull'articolo venduto. Forse analizzandoli possiamo rivelare differenze nei gusti tra le varie aree geografiche.
Consultare le categorie
Gli elementi sono classificati nel database. Quante categorie ci sono?
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
Output previsto: 103
Quali sono le categorie più popolari in base al volume?
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)

Utilizzo del tipo di dati ARRAY
Esistono diverse categorie di whisky, rum, vodka e altro ancora. Vorrei raggrupparli in qualche modo.
Inizia dividendo i nomi delle categorie in parole separate utilizzando il metodo Series.str.split(). Separa l'array creato utilizzando il metodo explode().
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)

category_parts.nunique()
Output previsto: 113
Se osservi il grafico sopra, i dati mostrano ancora VODKA separato da VODKAS. È necessario un ulteriore raggruppamento per comprimere le categorie in un insieme più piccolo.
7. Utilizzo di NLTK con BigQuery DataFrames
Con solo circa 100 categorie, sarebbe fattibile scrivere alcune euristiche o persino creare manualmente una mappatura dalla categoria al tipo di liquore più ampio. In alternativa, si potrebbe utilizzare un modello linguistico di grandi dimensioni come Gemini per creare una mappatura di questo tipo. Prova il codelab Ottieni insight dai dati non strutturati utilizzando BigQuery DataFrames per utilizzare BigQuery DataFrames con Gemini.
Utilizza invece un pacchetto di elaborazione del linguaggio naturale più tradizionale, NLTK, per elaborare questi dati. Ad esempio, una tecnologia chiamata "stemmer" può unire nomi plurali e singolari nello stesso valore.
Utilizzo di NLTK per estrarre il tema delle parole
Il pacchetto NLTK fornisce metodi di elaborazione del linguaggio naturale accessibili da Python. Installa il pacchetto per provarlo.
%pip install nltk
Poi importa il pacchetto. Controlla la versione. Verrà utilizzato più avanti nel tutorial.
import nltk
nltk.__version__
Un modo per standardizzare le parole è quello di "troncarle". In questo modo vengono rimossi tutti i suffissi, ad esempio la "s" finale per i plurali.
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
Prova a farlo con qualche parola.
stem("WHISKEY")
Output previsto: whiskey
stem("WHISKIES")
Output previsto: whiski
Purtroppo, non è stato possibile mappare i whisky allo stesso modo del whiskey. Gli stemmer non funzionano bene con i plurali irregolari. Prova un lemmatizzatore, che utilizza tecniche più sofisticate per identificare la parola base, chiamata "lemma".
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
Prova a farlo con qualche parola.
lemmatize("WHISKIES")
Output previsto: whisky
lemmatize("WHISKY")
Output previsto: whisky
lemmatize("WHISKEY")
Output previsto: whiskey
Purtroppo, questo lemmatizzatore non associa "whiskey" allo stesso lemma di "whiskies". Poiché questa parola è particolarmente importante per il database delle vendite al dettaglio di alcolici in Iowa, mappala manualmente con l'ortografia americana utilizzando un dizionario.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Prova a farlo con qualche parola.
lemmatize("WHISKIES")
Output previsto: whiskey
lemmatize("WHISKEY")
Output previsto: whiskey
Complimenti! Questo lemmatizzatore dovrebbe funzionare bene per restringere le categorie. Per utilizzarlo con BigQuery, devi eseguirne il deployment nel cloud.
Configura il progetto per il deployment delle funzioni
Prima di eseguire il deployment nel cloud in modo che BigQuery possa accedere a questa funzione, devi eseguire una configurazione una tantum.
Crea una nuova cella di codice e sostituisci your-project-id con l'ID progetto Google Cloud che utilizzi per questo tutorial.
project_id = "your-project-id"
Crea un service account senza autorizzazioni, poiché questa funzione non richiede l'accesso a risorse cloud.
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
Output previsto: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
Crea un set di dati BigQuery per contenere la funzione.
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
Deployment di una funzione remota
Abilita l'API Cloud Functions se non è ancora abilitata.
!gcloud services enable cloudfunctions.googleapis.com
Ora esegui il deployment della funzione nel set di dati che hai appena creato. Aggiungi un decoratore @bpd.remote_function alla funzione che hai creato nei passaggi precedenti.
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Il deployment dovrebbe richiedere circa due minuti.
Utilizzare le funzioni del telecomando
Al termine del deployment, puoi testare questa funzione.
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
Output previsto:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
8. Confronto del consumo di alcol per contea
Ora che la funzione lemmatize è disponibile, utilizzala per combinare le categorie.
Trovare la parola che riassume meglio la categoria
Innanzitutto, crea un DataFrame di tutte le categorie nel database.
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
Output previsto:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
Successivamente, crea un DataFrame di tutte le parole nelle categorie, ad eccezione di alcune parole di riempimento come la punteggiatura e "articolo".
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
Output previsto:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
Tieni presente che, se esegui la lemmatizzazione dopo il raggruppamento, riduci il carico sulla tua funzione cloud. È possibile applicare la funzione di lemmatizzazione a ciascuna delle diverse milioni di righe del database, ma costerebbe di più rispetto all'applicazione dopo il raggruppamento e potrebbe richiedere aumenti della quota.
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
Output previsto:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
Ora che le parole sono state lemmatizzate, devi selezionare il lemma che riassume meglio la categoria. Poiché nelle categorie non sono presenti molte parole funzionali, utilizza l'euristica secondo cui se una parola compare in più categorie, è probabilmente più adatta come parola riassuntiva (ad es. whisky).
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
Output previsto:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
Ora che esiste un unico lemma che riassume ogni categoria, uniscilo al DataFrame originale.
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
Output previsto:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
Confronto tra contee
Confronta le vendite in ogni contea per vedere quali differenze ci sono.
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
Trova il prodotto (lemma) più venduto in ogni contea.
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
Output previsto:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
Quanto sono diverse le contee tra loro?
county_max_lemma.groupby("lemma").size().to_pandas()
Output previsto:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
Nella maggior parte delle contee, il whisky è il prodotto più popolare in termini di volume, mentre la vodka è la più popolare in 15 contee. Confronta questo dato con i tipi di liquori più popolari a livello statale.
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
Output previsto:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
Il whisky e la vodka hanno quasi lo stesso volume, con la vodka leggermente superiore al whisky a livello statale.
Confronto delle proporzioni
Qual è l'unicità delle vendite in ogni contea? Che cosa rende la contea diversa dal resto dello stato?
Utilizza la misura h di Cohen per scoprire quali volumi di vendita di liquori differiscono maggiormente in proporzione da quanto ci si aspetterebbe in base alla proporzione delle vendite a livello statale.
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
Ora che l'h di Cohen è stata misurata per ogni lemma, trova la differenza più grande rispetto alla proporzione a livello statale in ogni contea.
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
Output previsto:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
Maggiore è il valore h di Cohen, maggiore è la probabilità che esista una differenza statisticamente significativa nella quantità di quel tipo di alcol consumato rispetto alle medie statali. Per i valori positivi più piccoli, la differenza di consumo è diversa dalla media statale, ma potrebbe essere dovuta a differenze casuali.
Un'osservazione: la contea di EL PASO non sembra essere una contea dell'Iowa. Ciò potrebbe indicare la necessità di un'altra pulizia dei dati prima di fare affidamento completamente su questi risultati.
Visualizzare le contee
Unisciti alla tabella bigquery-public-data.geo_us_boundaries.counties per ottenere l'area geografica di ogni contea. I nomi delle contee non sono univoci negli Stati Uniti, quindi filtra per includere solo le contee dell'Iowa. Il codice FIPS per l'Iowa è "19".
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
Output previsto:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
Utilizza GeoPandas per visualizzare queste differenze su una mappa.
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)
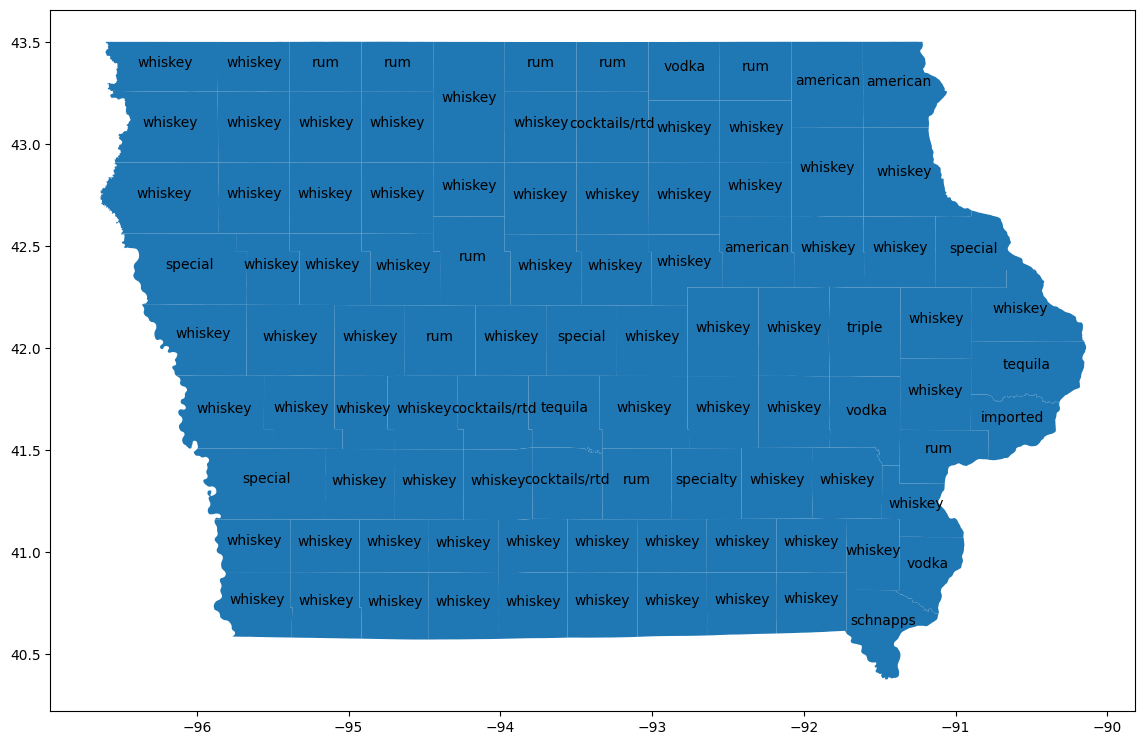
9. Esegui la pulizia
Se hai creato un nuovo progetto Google Cloud per questo tutorial, puoi eliminarlo per evitare addebiti aggiuntivi per tabelle o altre risorse create.
In alternativa, elimina le Funzioni Cloud, i service account e i set di dati creati per questo tutorial.
10. Complimenti!
Hai pulito e analizzato i dati strutturati utilizzando BigQuery DataFrames. Durante il percorso, hai esplorato i set di dati pubblici di Google Cloud, i notebook Python in BigQuery Studio, BigQuery ML, le funzioni remote di BigQuery e la potenza di BigQuery DataFrames. Ottimo lavoro.
Passaggi successivi
- Applica questi passaggi ad altri dati, ad esempio al database dei nomi degli Stati Uniti.
- Prova a generare codice Python nel tuo notebook. I notebook Python in BigQuery Studio sono basati su Colab Enterprise. Suggerimento: trovo molto utile chiedere aiuto per generare dati di test.
- Esplora i notebook di esempio per BigQuery DataFrames su GitHub.
- Crea una pianificazione per eseguire un notebook in BigQuery Studio.
- Esegui il deployment di una funzione remota con BigQuery DataFrames per integrare pacchetti Python di terze parti con BigQuery.