
1. 概要
このラボでは、BigQuery Studio の Python ノートブックから BigQuery DataFrames を使用して、アイオワ州の酒類販売に関する一般公開データセットをクリーンアップして分析します。BigQuery ML とリモート関数の機能を利用して分析情報を取得します。
Python ノートブックを作成して、地域間の売上を比較します。これは、任意の構造化データで動作するように適応できます。
目標
このラボでは、次のタスクの実行方法について学びます。
- BigQuery Studio で Python ノートブックを有効にして使用する
- BigQuery DataFrames パッケージを使用して BigQuery に接続する
- BigQuery ML を使用して線形回帰を作成する
- 使い慣れた pandas のような構文を使用して、複雑な集計と結合を実行する
2. 必要なもの
始める前に
この Codelab の手順に沿って操作するには、BigQuery Studio が有効になっていて、請求先アカウントが接続されている Google Cloud プロジェクトが必要です。
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Google Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- アセット管理に関する BigQuery Studio を有効にするの手順に沿って操作します。
BigQuery Studio を準備する
空のノートブックを作成して、ランタイムに接続します。
- Google Cloud コンソールで BigQuery Studio に移動します。
- [+] ボタンの横にある ▼ をクリックします。
- [Python ノートブック] を選択します。
- テンプレート セレクタを閉じます。
- [+ コード] を選択して、新しいコードセルを作成します。
- コードセルから BigQuery DataFrames パッケージの最新バージョンをインストールします。次のコマンドを入力します。
%pip install --upgrade bigframes --quiet
3. 一般公開データセットを読み取る
新しいコードセルで次のコードを実行して、BigQuery DataFrames パッケージを初期化します。
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
注: このチュートリアルでは、試験運用版の「部分順序モード」を使用します。このモードでは、pandas のようなフィルタリングと組み合わせて使用すると、クエリの効率が向上します。厳密な順序付けまたはインデックスを必要とする一部の pandas 機能は動作しない可能性があります。
次のコマンドを使用して bigframes パッケージのバージョンを確認します。
bpd.__version__
このチュートリアルでは、バージョン 1.27.0 以降が必要です。
アイオワ州の酒類小売販売
アイオワ州の酒類小売販売データセットは、Google Cloud の一般公開データセット プログラムを通じて BigQuery で提供されています。このデータセットには、2012 年 1 月 1 日以降にアイオワ州の小売業者が個人に販売するために行った酒類の卸売購入がすべて含まれています。データは、アイオワ州商務局内のアルコール飲料部門によって収集されます。
BigQuery で bigquery-public-data.iowa_liquor_sales.sales をクエリして、アイオワ州の酒類小売販売を分析します。bigframes.pandas.read_gbq() メソッドを使用して、クエリ文字列またはテーブル ID から DataFrame を作成します。
新しいコードセルで次のコードを実行して、「df」という名前の DataFrame を作成します。
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
DataFrame に関する基本情報を確認する
DataFrame.peek() メソッドを使用して、データの小さなサンプルをダウンロードします。
このセルを実行します。
df.peek()
想定される出力:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
注: head() には順序付けが必要であり、データのサンプルを可視化する場合は、通常 peek() よりも効率が低下します。
pandas と同様に、DataFrame.dtypes プロパティを使用して、使用可能なすべての列とそれに対応するデータ型を確認します。これらは pandas 互換の方法で公開されます。
このセルを実行します。
df.dtypes
想定される出力:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
DataFrame.describe() メソッドは、DataFrame からいくつかの基本的な統計情報をクエリします。DataFrame.to_pandas() を実行して、これらの要約統計量を pandas DataFrame としてダウンロードします。
このセルを実行します。
df.describe("all").to_pandas()
想定される出力:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
4. データを可視化してクリーンアップする
アイオワ州の酒類小売販売データセットには、小売店の所在地など、詳細な地理情報が含まれています。これらのデータを使用して、地域間の傾向と差異を特定します。
郵便番号別の売上を可視化する
DataFrame.plot.hist() などの組み込みの可視化メソッドがいくつかあります。このメソッドを使用して、郵便番号別の酒類の販売額を比較します。
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
想定される出力:
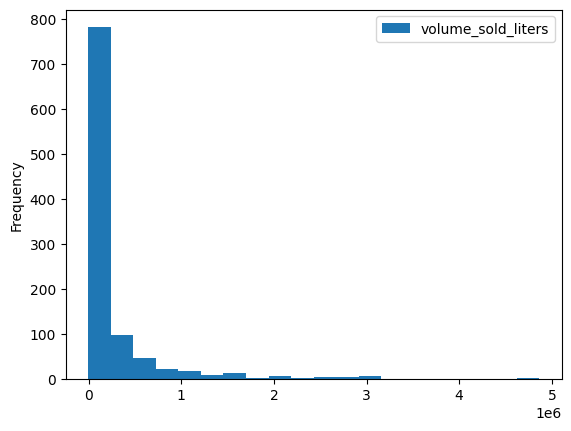
棒グラフを使用して、どの郵便番号で最も多くアルコールが販売されたかを確認します。
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
想定される出力:
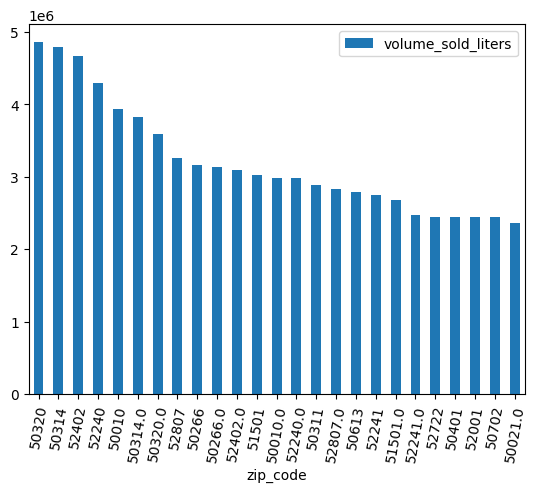
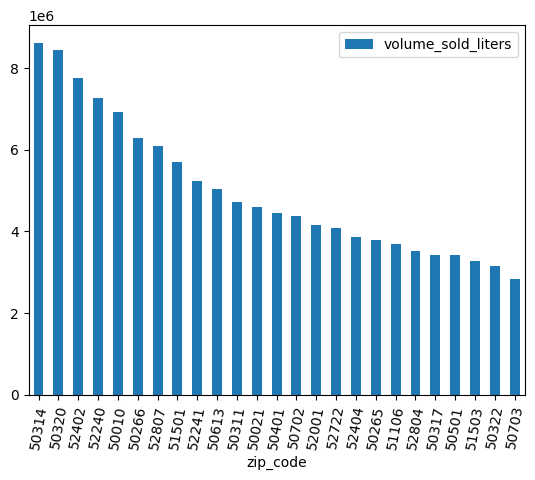
データをクリーニングする
一部の郵便番号には末尾に .0 が付いています。データ収集のどこかで、郵便番号が誤って浮動小数点値に変換された可能性があります。正規表現を使用して郵便番号をクリーンアップし、分析を繰り返します。
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
想定される出力:
5. 売上の相関関係を検出する
一部の郵便番号で販売数が多いのはなぜですか?1 つの仮説は、母集団のサイズの違いによるものです。人口が多い郵便番号では、酒類の販売量が多くなる可能性があります。
この仮説を検証するには、人口と酒類の販売量の相関関係を計算します。
他のデータセットと結合する
米国国勢調査局の米国コミュニティ調査の郵便番号集計エリア調査などの人口データセットと結合します。
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
アメリカン コミュニティ サーベイでは、州は GEOID で識別されます。郵便番号集計エリアの場合、GEOID は郵便番号と同じです。
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
郵便番号別集計地域の人口と販売されたアルコールのリットル数を比較する散布図を作成します。
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
想定される出力:
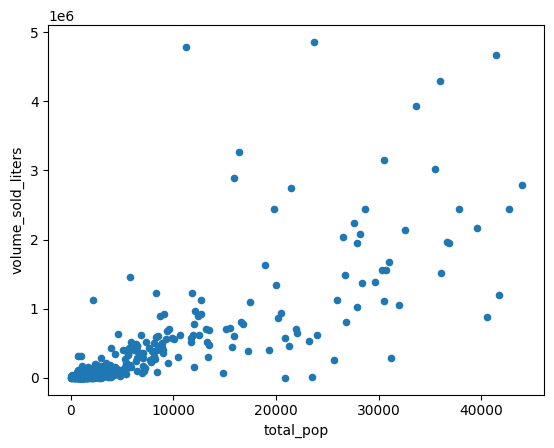
相関関係を計算する
傾向はほぼ線形に見えます。これに線形回帰モデルを適合させて、人口が酒類の売上をどの程度予測できるかを確認します。
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
score メソッドを使用して、適合度を確認します。
model.score(feature_columns, label_columns).to_pandas()
出力例:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
母集団値の範囲で predict 関数を呼び出して、最適な適合線を引きます。
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
想定される出力:
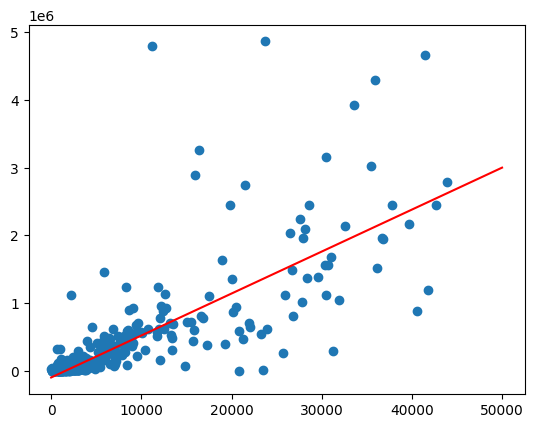
不均一分散に対処する
前のグラフのデータは、不均一分散であるように見えます。最適な適合線の分散は、母集団とともに増加します。
1 人あたりのアルコール購入量は比較的一定である可能性があります。
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
想定される出力:
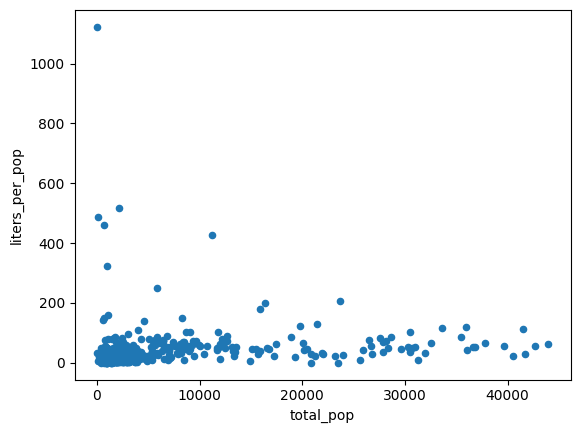
購入されたアルコールの平均量を次の 2 つの方法で計算します。
- アイオワ州の 1 人あたりの平均アルコール購入量はどのくらいですか?
- 1 人あたりのアルコール購入量のすべての郵便番号の平均値。
(1)は、州全体で購入されたアルコール飲料の量を反映しています。(2)は平均郵便番号を反映していますが、郵便番号ごとに人口が異なるため、(1)と同じになるとは限りません。
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
想定される出力: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
想定される出力: 67.139
上記と同様に、これらの平均値をプロットします。
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
想定される出力:
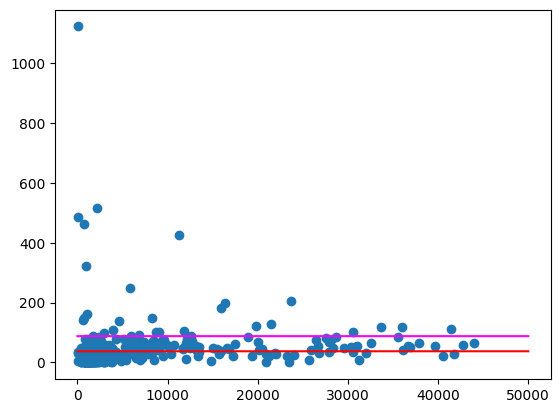
特に人口の少ない地域では、外れ値がかなり大きい郵便番号がまだいくつかあります。この理由を仮説立てることは、演習として残されています。たとえば、一部の郵便番号は人口が少ないものの、その地域で唯一の酒屋があるため消費量が多い可能性があります。その場合、周辺の郵便番号の人口に基づいて計算すると、これらの外れ値が平準化される可能性があります。
6. 販売された酒類の種類の比較
アイオワ州の酒類小売販売データベースには、地理データに加えて、販売された商品に関する詳細情報も含まれています。これらのデータを分析することで、地域ごとの好みの違いを明らかにできるかもしれません。
カテゴリを探索
アイテムはデータベースで分類されます。カテゴリの数はいくつですか?
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
想定される出力: 103
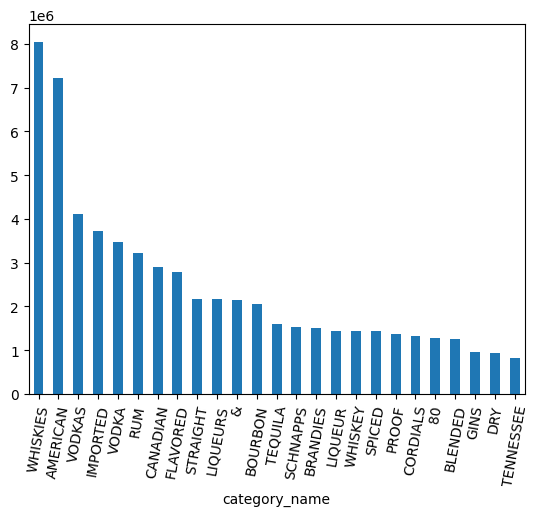
ボリュームが最も多いカテゴリはどれですか?
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
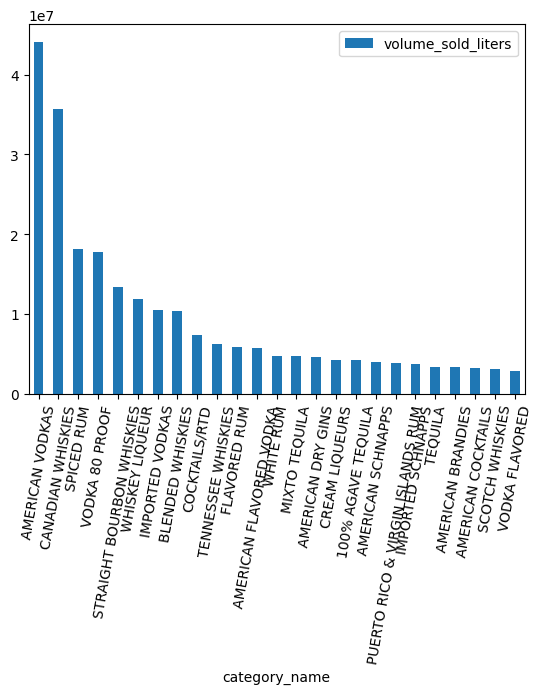
ARRAY データ型の操作
ウイスキー、ラム、ウォッカなど、それぞれに複数のカテゴリがあります。これらを何らかの方法でグループ化したいのですが。
まず、Series.str.split() メソッドを使用して、カテゴリ名を個別の単語に分割します。explode() メソッドを使用して、作成された配列のネストを解除します。
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
category_parts.nunique()
想定される出力: 113
上のグラフを見ると、データには VODKA と VODKAS が別々に含まれています。カテゴリをより小さなセットに折りたたむには、さらにグループ化が必要です。
7. BigQuery DataFrames で NLTK を使用する
カテゴリが 100 程度であれば、ヒューリスティックを記述したり、カテゴリからより広範な酒類へのマッピングを手動で作成したりすることも可能です。または、Gemini などの大規模言語モデルを使用して、このようなマッピングを作成することもできます。Codelab の BigQuery DataFrames を使用して非構造化データから分析情報を取得するを試して、Gemini で BigQuery DataFrames を使用してください。
代わりに、より従来の自然言語処理パッケージである NLTK を使用して、これらのデータを処理します。たとえば、「ステマー」と呼ばれるテクノロジーを使用すると、複数形と単数形の名詞を同じ値に統合できます。
NLTK を使用して単語を語幹に変換する
NLTK パッケージは、Python からアクセスできる自然言語処理メソッドを提供します。パッケージをインストールして試してみましょう。
%pip install nltk
次に、パッケージをインポートします。バージョンを検査します。これはチュートリアルの後半で使用します。
import nltk
nltk.__version__
単語を標準化する方法の一つに、単語の「語幹」化があります。これにより、複数形の末尾の「s」などの接尾辞が削除されます。
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
いくつかの単語で試してみましょう。
stem("WHISKEY")
想定される出力: whiskey
stem("WHISKIES")
想定される出力: whiski
残念ながら、この方法ではウイスキーとウイスキーを同じものとしてマッピングできませんでした。ステマーは不規則な複数形にはうまく機能しません。より高度な手法を使用して基本語(レンマ)を特定するレンマタイザーを試してください。
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
いくつかの単語で試してみましょう。
lemmatize("WHISKIES")
想定される出力: whisky
lemmatize("WHISKY")
想定される出力: whisky
lemmatize("WHISKEY")
想定される出力: whiskey
残念ながら、このレンマタイザーは「whiskey」を「whiskies」と同じレンマにマッピングしません。この単語はアイオワ州の小売酒類販売データベースで特に重要であるため、辞書を使用してアメリカ英語のスペルに手動でマッピングします。
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
いくつかの単語で試してみましょう。
lemmatize("WHISKIES")
想定される出力: whiskey
lemmatize("WHISKEY")
想定される出力: whiskey
おめでとうございます。このレンマ化ツールは、カテゴリを絞り込むのに適しています。BigQuery で使用するには、クラウドにデプロイする必要があります。
関数をデプロイするようにプロジェクトを設定する
BigQuery がこの関数にアクセスできるようにクラウドにデプロイする前に、1 回限りの設定を行う必要があります。
新しいコードセルを作成し、your-project-id をこのチュートリアルで使用する Google Cloud プロジェクト ID に置き換えます。
project_id = "your-project-id"
この関数はクラウドリソースにアクセスする必要がないため、権限のないサービス アカウントを作成します。
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
想定される出力: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
関数を保持する BigQuery データセットを作成します。
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
リモート関数のデプロイ
Cloud Functions API がまだ有効になっていない場合は有効にします。
!gcloud services enable cloudfunctions.googleapis.com
次に、作成したデータセットに関数をデプロイします。前の手順で作成した関数に @bpd.remote_function デコレータを追加します。
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
デプロイには約 2 分かかります。
リモート関数を使用する
デプロイが完了したら、この関数をテストできます。
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
想定される出力:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
8. 郡別のアルコール消費量を比較する
lemmatize 関数が使用可能になったので、これを使用してカテゴリを結合します。
カテゴリを最もよく表す単語を見つける
まず、データベース内のすべてのカテゴリの DataFrame を作成します。
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
想定される出力:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
次に、句読点や「item」などのフィラーワードを除き、カテゴリ内のすべての単語の DataFrame を作成します。
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
想定される出力:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
グループ化後にレンマ化することで、Cloud Functions の負荷を軽減できます。データベース内の数百万行のそれぞれにレンマ化関数を適用することは可能ですが、グループ化後に適用するよりもコストがかかり、割り当ての増加が必要になる場合があります。
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
想定される出力:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
単語がレンマ化されたら、カテゴリを最もよく表すレンマを選択する必要があります。カテゴリには機能語が少ないため、単語が他の複数のカテゴリに現れる場合は、要約語として適している可能性が高いというヒューリスティックを使用します(例: ウイスキー)。
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
想定される出力:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
各カテゴリを要約する単一のレンマができたので、これを元の DataFrame にマージします。
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
想定される出力:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
郡を比較する
各郡の販売数を比較して、違いを確認します。
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
各郡で最も売れている商品(レンマ)を見つけます。
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
想定される出力:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
郡間の違いはどの程度ですか?
county_max_lemma.groupby("lemma").size().to_pandas()
想定される出力:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
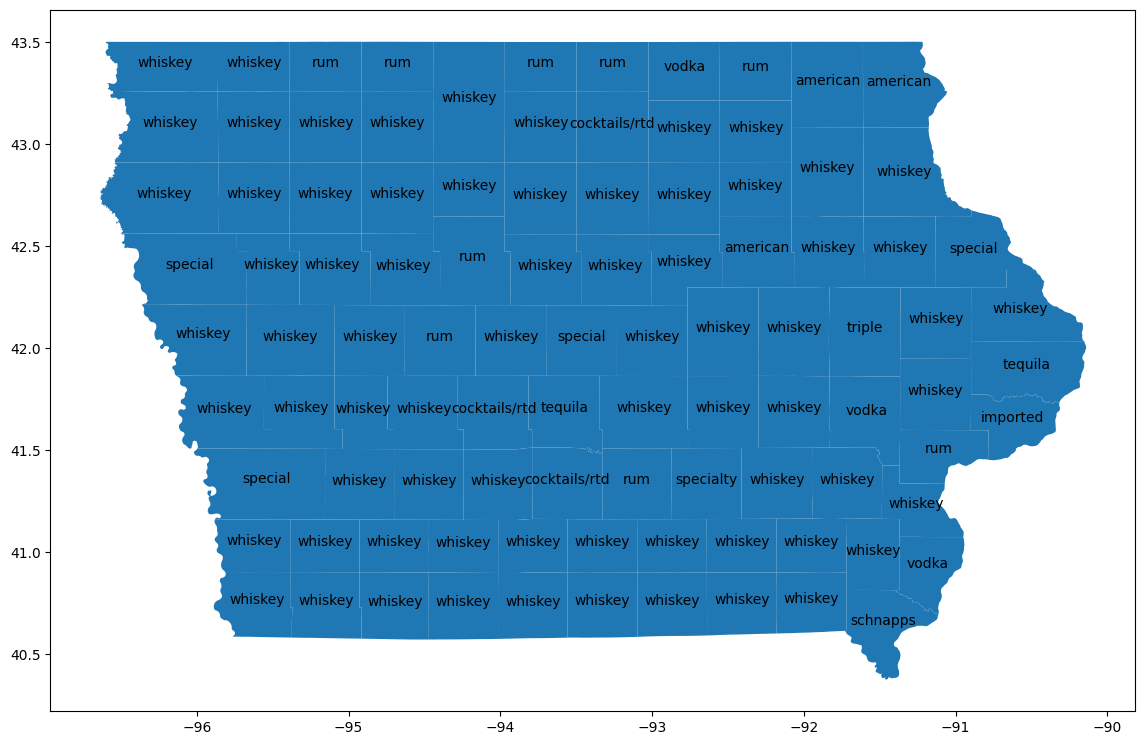
ほとんどの郡で、ウイスキーが数量ベースで最も人気のある商品であり、15 の郡ではウォッカが最も人気のある商品です。州全体で最も人気のある酒類と比較します。
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
想定される出力:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
ウィスキーとウォッカの販売量はほぼ同じで、州全体ではウォッカがウィスキーをわずかに上回っています。
比率の比較
各郡の販売の独自性は何ですか?この郡が州の他の地域と異なる点は何ですか?
コーエンの h 測定を使用して、州全体の販売割合に基づいて予想される販売量と、比例して最も異なる酒類の販売量を見つけます。
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
各レンマの Cohen の h が測定されたので、各郡で州全体の割合との差が最も大きいものを探します。
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
想定される出力:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
コーエンの h 値が大きいほど、その種類のアルコールの消費量が州の平均値と比べて統計的に有意な差がある可能性が高くなります。正の値が小さい場合は、消費量の差が州全体の平均と異なりますが、ランダムな差による可能性があります。
補足: EL PASO 郡は アイオワ州の郡ではないようです。これは、これらの結果に完全に依存する前に、データのクリーンアップがさらに必要であることを示している可能性があります。
郡を可視化する
bigquery-public-data.geo_us_boundaries.counties テーブルと結合して、各郡の地理的エリアを取得します。米国の郡名は一意ではないため、アイオワ州の郡のみを含めるようにフィルタします。アイオワ州の FIPS コードは「19」です。
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
想定される出力:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
GeoPandas を使用して、これらの違いを地図上に可視化します。
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)
9. クリーンアップ
このチュートリアル用に新しい Google Cloud プロジェクトを作成した場合は、削除して、作成したテーブルやその他のリソースに追加料金が発生しないようにします。
または、このチュートリアルで作成した Cloud Functions、サービス アカウント、データセットを削除します。
10. 完了
BigQuery DataFrames を使用して構造化データをクリーンアップして分析しました。このコースでは、Google Cloud の公開データセット、BigQuery Studio の Python ノートブック、BigQuery ML、BigQuery リモート関数、BigQuery DataFrames の機能について学習しました。お疲れさまでした。
次のステップ
- これらの手順は、USA names database などの他のデータにも適用できます。
- ノートブックで Python コードを生成してみてください。BigQuery Studio の Python ノートブックは、Colab Enterprise を基盤としています。ヒント: テストデータの生成を依頼すると、非常に便利です。
- GitHub で BigQuery DataFrames のサンプル ノートブックを確認する。
- BigQuery Studio でノートブックを実行するスケジュールを作成します。
- BigQuery DataFrames を使用してリモート関数をデプロイし、サードパーティの Python パッケージを BigQuery と統合します。