
1. Обзор
В этой лабораторной работе вы будете использовать DataFrames из блокнота Python в BigQuery Studio для очистки и анализа общедоступного набора данных о продажах алкогольных напитков в Айове. Воспользуйтесь возможностями BigQuery ML и удаленных функций для получения ценных аналитических данных.
Вам предстоит создать блокнот на Python для сравнения продаж по географическим регионам. Его можно адаптировать для работы с любыми структурированными данными.
Цели
В этой лабораторной работе вы научитесь выполнять следующие задачи:
- Активируйте и используйте блокноты Python в BigQuery Studio.
- Подключитесь к BigQuery, используя пакет BigQuery DataFrames.
- Создайте линейную регрессию с помощью BigQuery ML.
- Выполняйте сложные агрегации и объединения, используя привычный синтаксис, аналогичный pandas.
2. Требования
Прежде чем начать
Для выполнения инструкций в этом практическом задании вам потребуется проект Google Cloud с включенной функцией BigQuery Studio и подключенный платежный аккаунт.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего проекта Google Cloud включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта.
- Следуйте инструкциям, чтобы включить BigQuery Studio для управления ресурсами .
Подготовка BigQuery Studio
Создайте пустой блокнот и подключите его к среде выполнения.
- Перейдите в BigQuery Studio в консоли Google Cloud.
- Нажмите на значок ▼ рядом с кнопкой + .
- Выберите блокнот Python .
- Закройте окно выбора шаблона.
- Выберите + Код , чтобы создать новую ячейку с кодом.
- Установите последнюю версию пакета BigQuery DataFrames из ячейки кода. Введите следующую команду.
%pip install --upgrade bigframes --quiet
3. Прочитайте общедоступный набор данных.
Для инициализации пакета BigQuery DataFrames выполните следующую команду в новой ячейке кода:
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
Примечание: в этом руководстве мы используем экспериментальный «режим частичного упорядочивания», который позволяет выполнять более эффективные запросы при использовании с фильтрацией, аналогичной той, что применяется в pandas. Некоторые функции pandas, требующие строгого упорядочивания или индекса, могут не работать.
Проверьте версию пакета bigframes с помощью
bpd.__version__
Для выполнения этого руководства требуется версия 1.27.0 или более поздняя.
Розничная продажа алкогольных напитков в Айове
Данные о розничных продажах алкогольных напитков в штате Айова предоставляются в BigQuery через программу общедоступных наборов данных Google Cloud . Этот набор данных содержит информацию обо всех оптовых закупках алкогольных напитков в штате Айова розничными продавцами для продажи частным лицам с 1 января 2012 года. Сбор данных осуществляется Отделом алкогольных напитков Департамента торговли штата Айова.
В BigQuery выполните запрос к bigquery-public-data.iowa_liquor_sales.sales для анализа розничных продаж алкогольных напитков в Айове. Используйте метод bigframes.pandas.read_gbq() для создания DataFrame из строки запроса или идентификатора таблицы.
Выполните следующий код в новой ячейке, чтобы создать DataFrame с именем "df":
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
Узнайте основную информацию о DataFrame.
Используйте метод DataFrame.peek() для загрузки небольшого фрагмента данных.
Запустите эту ячейку:
df.peek()
Ожидаемый результат:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
Примечание: head() требует упорядочивания и, как правило, менее эффективна, чем peek() если вы хотите визуализировать выборку данных.
Как и в pandas, используйте свойство DataFrame.dtypes , чтобы увидеть все доступные столбцы и соответствующие им типы данных. Они представлены в формате, совместимом с pandas.
Запустите эту ячейку:
df.dtypes
Ожидаемый результат:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
Метод DataFrame.describe() запрашивает некоторые основные статистические данные из DataFrame. Для загрузки этих сводных статистических данных в виде DataFrame pandas используйте метод DataFrame.to_pandas() .
Запустите эту ячейку:
df.describe("all").to_pandas()
Ожидаемый результат:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
4. Визуализация и очистка данных.
Набор данных о розничных продажах алкогольных напитков в штате Айова содержит подробную географическую информацию, включая местоположение розничных магазинов. Используйте эти данные для выявления тенденций и различий в разных географических районах.
Визуализация продаж по почтовым индексам
Существует несколько встроенных методов визуализации, таких как DataFrame.plot.hist() . Используйте этот метод для сравнения продаж алкогольных напитков по почтовым индексам.
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
Ожидаемый результат:
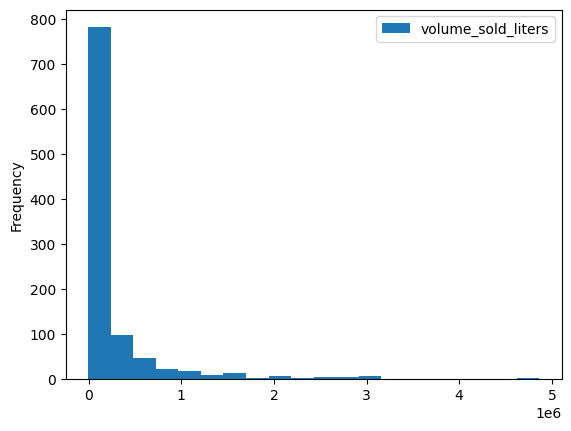
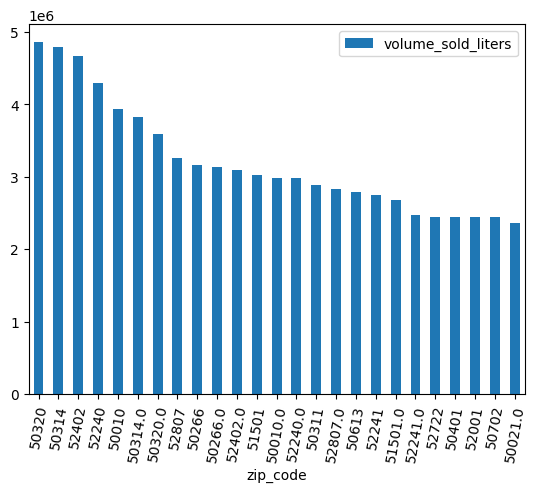
Используйте столбчатую диаграмму, чтобы увидеть, какие почтовые индексы предлагали самые продаваемые алкогольные напитки.
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Ожидаемый результат:
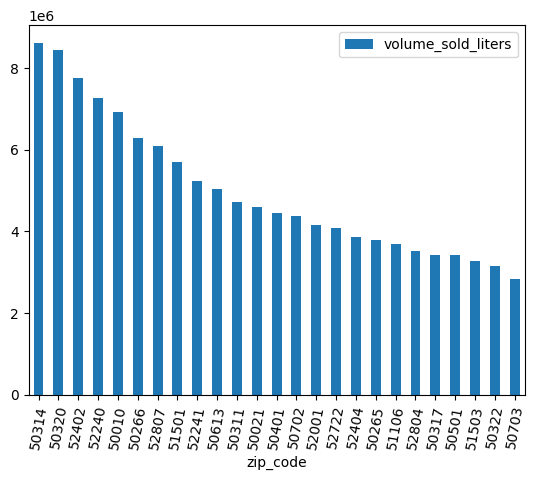
Очистка данных
В некоторых почтовых индексах в конце присутствует .0 . Возможно, в процессе сбора данных почтовые индексы были случайно преобразованы в значения с плавающей запятой. Используйте регулярные выражения для очистки почтовых индексов и повторите анализ.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Ожидаемый результат:
5. Выявите корреляции в продажах.
Почему в одних почтовых индексах продажи алкоголя выше, чем в других? Одна из гипотез заключается в различиях в численности населения. В почтовом индексе с большей численностью населения, скорее всего, будет продаваться больше алкоголя.
Проверьте эту гипотезу, рассчитав корреляцию между численностью населения и объемом продаж алкогольных напитков.
Объединить с другими наборами данных
Используйте для объединения данные о населении, например, данные из обследования почтовых индексов в рамках Американского обследования сообществ Бюро переписи населения США .
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
В рамках Американского обследования сообществ (American Community Survey) штаты идентифицируются по GEOID. В случае почтовых индексов GEOID равен почтовому индексу.
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
Создайте диаграмму рассеяния для сравнения численности населения в районах, охватываемых почтовыми индексами, с объемом проданного алкоголя в литрах.
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
Ожидаемый результат:
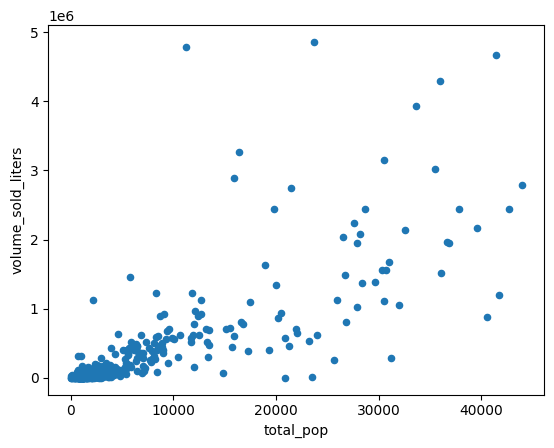
Рассчитайте корреляции
Тенденция выглядит приблизительно линейной. Для проверки того, насколько хорошо численность населения может прогнозировать продажи алкогольных напитков, можно построить модель линейной регрессии.
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
Проверьте, насколько хорошо подогнано изображение, используя метод score .
model.score(feature_columns, label_columns).to_pandas()
Пример выходных данных:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
Постройте линию наилучшего соответствия, вызвав функцию predict для диапазона значений генеральной совокупности.
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
Ожидаемый результат:
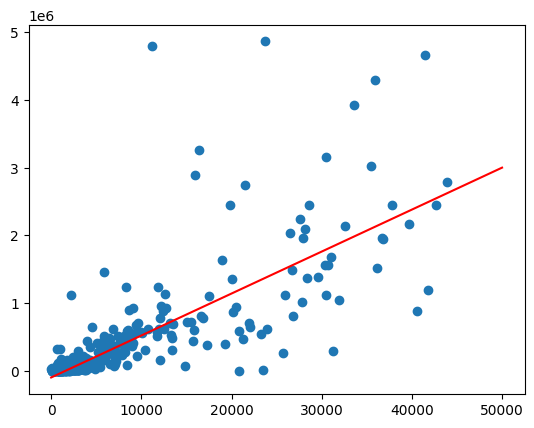
Решение проблемы гетероскедастичности
Данные на предыдущем графике, по-видимому, являются гетероскедастическими. Дисперсия относительно линии наилучшего соответствия возрастает с увеличением численности популяции.
Возможно, количество алкоголя, приобретаемого на человека, остается относительно постоянным.
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
Ожидаемый результат:
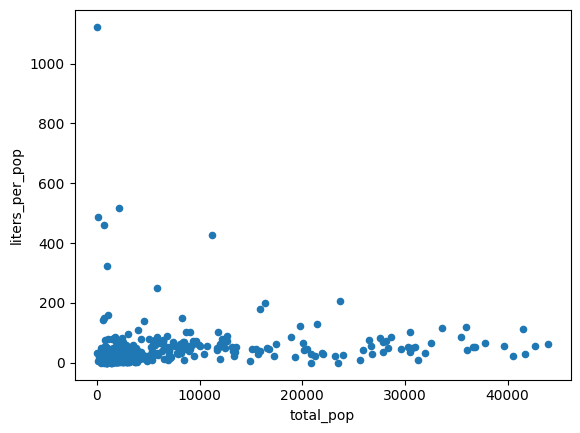
Рассчитайте среднее количество литров алкоголя, приобретенного двумя разными способами:
- Каково среднее количество алкоголя, приобретаемое одним человеком в штате Айова?
- Каково среднее количество алкоголя, приобретаемого на одного человека по всем почтовым индексам?
В (1) это отражает количество алкоголя, приобретаемого во всем штате. В (2) это отражает средний почтовый индекс, который не обязательно будет совпадать с (1), поскольку разные почтовые индексы имеют разную численность населения.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
Ожидаемый результат: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
Ожидаемый результат: 67.139
Постройте график этих средних значений, аналогично приведенному выше.
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
Ожидаемый результат:
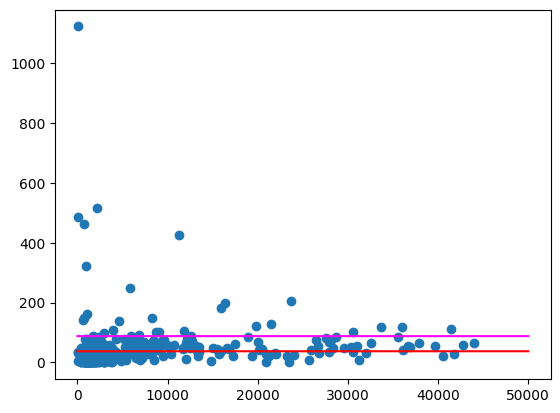
Некоторые почтовые индексы по-прежнему представляют собой довольно значительные отклонения от нормы, особенно в районах с меньшей плотностью населения. Предлагается лишь выдвинуть гипотезу о причинах этого явления. Например, возможно, что в некоторых районах с низкой плотностью населения наблюдается высокий уровень потребления алкоголя, поскольку там находится единственный в этом районе магазин спиртных напитков. В таком случае расчет на основе численности населения окружающих почтовых индексов может сгладить эти отклонения.
6. Сравнение видов продаваемых алкогольных напитков.
Помимо географических данных, база данных розничных продаж алкогольных напитков в Айове также содержит подробную информацию о продаваемом товаре. Возможно, проанализировав эти данные, мы сможем выявить различия во вкусах в разных географических регионах.
Изучите категории
В базе данных товары классифицированы по категориям. Сколько категорий существует?
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
Ожидаемый результат: 103
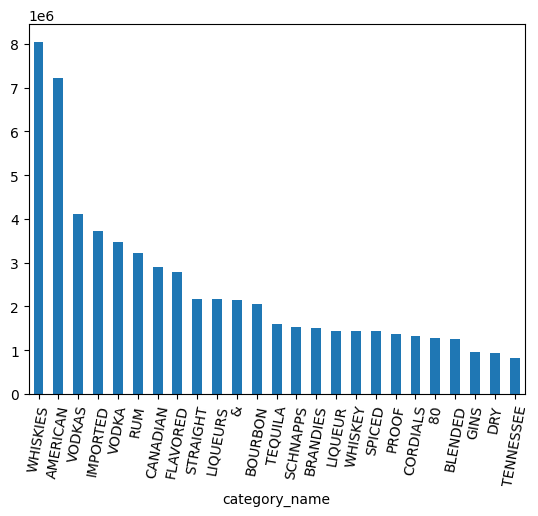
Какие категории пользуются наибольшей популярностью по объёму продаж?
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
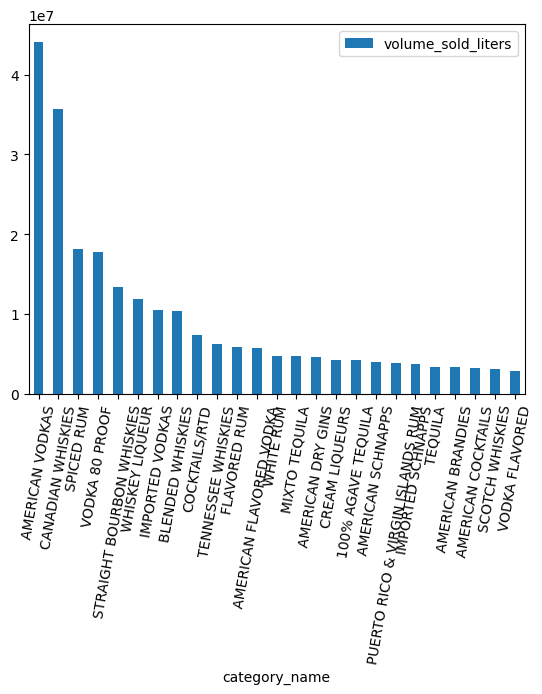
Работа с типом данных ARRAY
Существует несколько категорий виски, рома, водки и других напитков. Я хотел бы как-то их сгруппировать.
Для начала разделите названия категорий на отдельные слова, используя метод Series.str.split() . Затем разверните созданный массив, используя метод explode() .
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
category_parts.nunique()
Ожидаемый результат: 113
Глядя на диаграмму выше, данные по-прежнему содержат разделение VODKA и VODKAS. Необходимо провести дополнительную группировку, чтобы объединить категории в более компактный набор.
7. Использование NLTK с DataFrames BigQuery
При наличии всего около 100 категорий вполне возможно написать эвристические алгоритмы или даже вручную создать сопоставление между категориями и более широким набором типов алкогольных напитков. В качестве альтернативы можно использовать большую языковую модель, такую как Gemini, для создания такого сопоставления. Попробуйте пройти практическое занятие « Получение информации из неструктурированных данных с помощью BigQuery DataFrames», чтобы использовать BigQuery DataFrames с Gemini.
Вместо этого используйте более традиционный пакет обработки естественного языка, NLTK, для обработки этих данных. Например, технология, называемая «стеммером», может объединять существительные во множественном и единственном числе в одно и то же значение.
Использование NLTK для стемминга слов
Пакет NLTK предоставляет методы обработки естественного языка, доступные из Python. Установите пакет, чтобы попробовать его.
%pip install nltk
Далее импортируйте пакет. Проверьте версию. Она понадобится вам позже в этом руководстве.
import nltk
nltk.__version__
Один из способов стандартизации слов — это «укоренение» слова. При этом удаляются любые суффиксы, например, окончание «s» для множественного числа.
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
Попробуйте это на нескольких словах.
stem("WHISKEY")
Ожидаемый объем производства: whiskey
stem("WHISKIES")
Ожидаемый результат: whiski
К сожалению, это не сопоставило слово «whisky» с «whiskey». Стеммеры плохо работают с неправильными формами множественного числа. Попробуйте лемматизатор, который использует более сложные методы для определения базового слова, называемый «леммой».
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
Попробуйте это на нескольких словах.
lemmatize("WHISKIES")
Ожидаемый объем производства: whisky
lemmatize("WHISKY")
Ожидаемый объем производства: whisky
lemmatize("WHISKEY")
Ожидаемый объем производства: whiskey
К сожалению, этот лемматизатор не сопоставляет слово «whiskey» с той же леммой, что и слово «whiskies». Поскольку это слово особенно важно для базы данных розничной продажи алкогольных напитков в Айове, сопоставьте его с американским написанием вручную, используя словарь.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Попробуйте это на нескольких словах.
lemmatize("WHISKIES")
Ожидаемый объем производства: whiskey
lemmatize("WHISKEY")
Ожидаемый объем производства: whiskey
Поздравляем! Этот лемматизатор должен хорошо справляться с сужением категорий. Для использования с BigQuery его необходимо развернуть в облаке.
Настройте свой проект для развертывания функций.
Прежде чем развернуть это в облаке, чтобы BigQuery мог получить доступ к этой функции, вам потребуется выполнить одноразовую настройку.
Создайте новую ячейку с кодом и замените your-project-id на идентификатор проекта Google Cloud, который вы используете в этом руководстве.
project_id = "your-project-id"
Создайте учетную запись службы без каких-либо разрешений, поскольку этой функции не требуется доступ к облачным ресурсам.
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
Ожидаемый результат: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
Создайте набор данных BigQuery для хранения этой функции.
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
Развертывание удаленной функции
Включите API облачных функций, если он еще не включен.
!gcloud services enable cloudfunctions.googleapis.com
Теперь разверните свою функцию на только что созданном наборе данных. Добавьте декоратор @bpd.remote_function к функции, созданной на предыдущих шагах.
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Развертывание займет около двух минут.
Использование функций дистанционного управления
После завершения развертывания вы сможете протестировать эту функцию.
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
Ожидаемый результат:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
8. Сравнение потребления алкоголя по округам.
Теперь, когда доступна функция lemmatize , используйте её для объединения категорий.
Подбор слова, наиболее точно описывающего данную категорию.
Сначала создайте DataFrame, содержащий все категории из базы данных.
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
Ожидаемый результат:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
Далее создайте DataFrame, содержащий все слова в категориях, за исключением нескольких слов-паразитов, таких как знаки препинания и "предмет".
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
Ожидаемый результат:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
Обратите внимание, что лемматизация после группировки снижает нагрузку на вашу облачную функцию. Можно применить функцию лемматизации к каждой из нескольких миллионов строк в базе данных, но это обойдется дороже, чем применение после группировки, и может потребовать увеличения квоты.
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
Ожидаемый результат:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
Теперь, когда слова лемматизированы, вам нужно выбрать лемму, которая лучше всего описывает категорию. Поскольку в категориях не так много служебных слов, используйте эвристику: если слово встречается в нескольких других категориях, то, вероятно, лучше использовать его в качестве обобщающего слова (например, «виски»).
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
Ожидаемый результат:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
Теперь, когда есть единая лемма, суммирующая каждую категорию, объедините её с исходным DataFrame.
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
Ожидаемый результат:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
Сравнение округов
Сравните объемы продаж в каждом округе, чтобы увидеть, какие есть различия.
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
Найдите самый продаваемый товар (лемму) в каждом округе.
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
Ожидаемый результат:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
Насколько сильно отличаются эти округа друг от друга?
county_max_lemma.groupby("lemma").size().to_pandas()
Ожидаемый результат:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
В большинстве округов виски является самым популярным продуктом по объему продаж, а водка — самым популярным продуктом в 15 округах. Сравните это с самыми популярными видами крепких спиртных напитков по всему штату.
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
Ожидаемый результат:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
Виски и водка занимают примерно одинаковое место в рейтинге, при этом водка в целом по штату потребляется немного больше, чем виски.
Сравнение пропорций
Что уникального в продажах в каждом округе? Чем этот округ отличается от остальной части штата?
Используйте показатель Коэна h, чтобы определить, какие объемы продаж алкогольных напитков наиболее пропорционально отличаются от ожидаемых, исходя из доли продаж по всему штату.
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
Теперь, когда для каждой леммы измерен коэффициент Коэна h, найдите наибольшую разницу между долей по всему штату и долей в каждом округе.
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
Ожидаемый результат:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
Чем выше значение h Коэна, тем вероятнее наличие статистически значимой разницы в количестве потребляемого данного вида алкоголя по сравнению со средними показателями по штату. При меньших положительных значениях разница в потреблении отличается от среднего показателя по штату, но это может быть обусловлено случайными различиями.
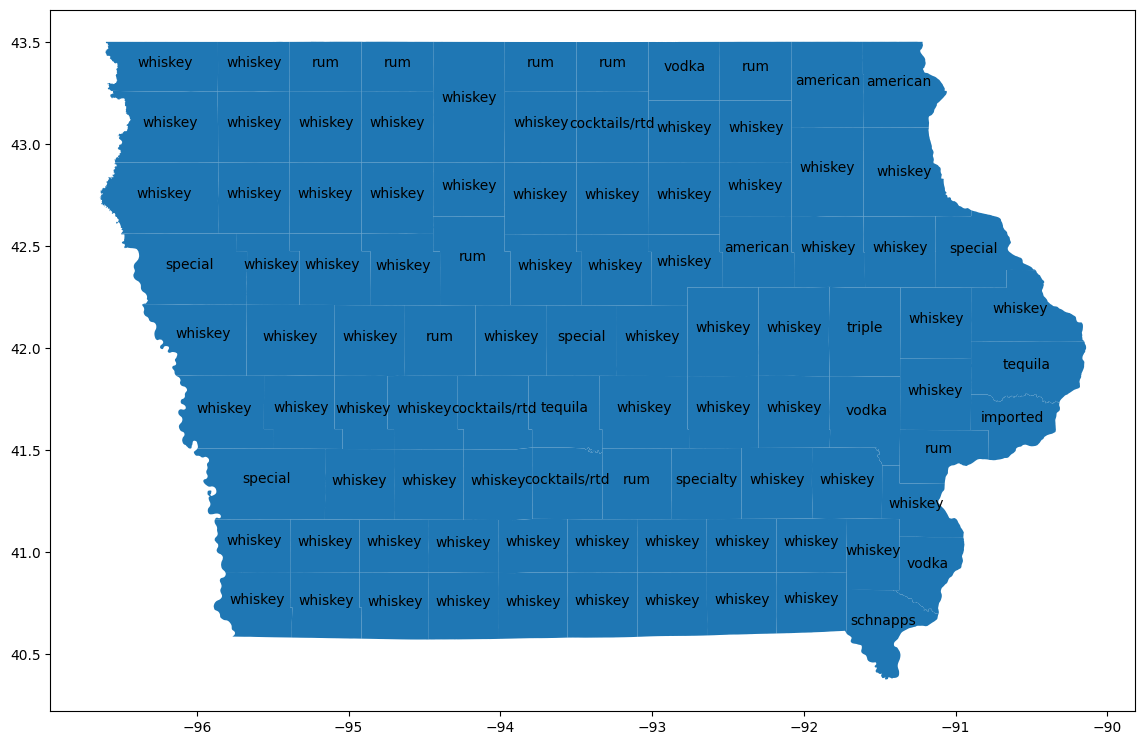
Примечание: округ Эль-Пасо, по всей видимости, не является округом в штате Айова, что может указывать на необходимость дополнительной очистки данных, прежде чем полностью полагаться на эти результаты.
Визуализация округов
Для получения географической области для каждого округа используйте таблицу bigquery-public-data.geo_us_boundaries.counties . Названия округов не уникальны по всей территории США, поэтому отфильтруйте данные, чтобы включить только округа из штата Айова. Код FIPS для Айовы — «19».
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
Ожидаемый результат:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
Используйте GeoPandas для визуализации этих различий на карте.
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)
9. Уборка
Если вы создали новый проект Google Cloud для этого руководства, вы можете удалить его , чтобы избежать дополнительных расходов на созданные таблицы или другие ресурсы.
В качестве альтернативы, можно удалить облачные функции, учетные записи служб и наборы данных, созданные для этого руководства.
10. Поздравляем!
Вы выполнили очистку и анализ структурированных данных с использованием BigQuery DataFrames. В процессе работы вы изучили общедоступные наборы данных Google Cloud, блокноты Python в BigQuery Studio, BigQuery ML, удаленные функции BigQuery и возможности BigQuery DataFrames. Отличная работа!
Следующие шаги
- Примените эти шаги к другим данным, например, к базе данных имен США .
- Попробуйте сгенерировать код Python в своем блокноте . Блокноты Python в BigQuery Studio работают на базе Colab Enterprise. Подсказка: я считаю, что обращение за помощью в генерации тестовых данных очень полезно.
- Ознакомьтесь с примерами блокнотов для работы с DataFrames BigQuery на GitHub.
- Создайте расписание для запуска блокнота в BigQuery Studio .
- Разверните удаленную функцию с использованием DataFrames BigQuery для интеграции сторонних пакетов Python с BigQuery.