
1. ภาพรวม
ในแล็บนี้ คุณจะได้ใช้ DataFrame ของ BigQuery จาก Notebook ของ Python ใน BigQuery Studio เพื่อล้างและวิเคราะห์ชุดข้อมูลสาธารณะเกี่ยวกับการขายสุราในรัฐไอโอวา ใช้ความสามารถของ BigQuery ML และฟังก์ชันระยะไกลเพื่อค้นพบข้อมูลเชิงลึก
คุณจะสร้างสมุดบันทึก Python เพื่อเปรียบเทียบยอดขายในพื้นที่ทางภูมิศาสตร์ต่างๆ ซึ่งสามารถปรับให้ทำงานกับ Structured Data ใดก็ได้
วัตถุประสงค์
ในแล็บนี้ คุณจะได้เรียนรู้วิธีทำงานต่อไปนี้
- เปิดใช้งานและใช้ Notebook ของ Python ใน BigQuery Studio
- เชื่อมต่อกับ BigQuery โดยใช้แพ็กเกจ BigQuery DataFrames
- สร้างการถดถอยเชิงเส้นโดยใช้ BigQuery ML
- ทำการรวมและการรวมที่ซับซ้อนโดยใช้ไวยากรณ์ที่คล้ายกับ pandas ที่คุ้นเคย
2. ข้อกำหนด
ก่อนเริ่มต้น
หากต้องการทำตามวิธีการในโค้ดแล็บนี้ คุณจะต้องมีโปรเจ็กต์ Google Cloud ที่เปิดใช้ BigQuery Studio และบัญชีสำหรับการเรียกเก็บเงินที่เชื่อมต่อ
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Google Cloud แล้ว ดูวิธีตรวจสอบว่าโปรเจ็กต์เปิดใช้การเรียกเก็บเงินแล้วหรือไม่
- ทำตามวิธีการเพื่อเปิดใช้ BigQuery Studio สำหรับการจัดการชิ้นงาน
เตรียม BigQuery Studio
สร้าง Notebook ว่างเปล่าและเชื่อมต่อกับรันไทม์
- ไปที่ BigQuery Studio ในคอนโซล Google Cloud
- คลิก ▼ ข้างปุ่ม +
- เลือก Python Notebook
- ปิดตัวเลือกเทมเพลต
- เลือก + โค้ดเพื่อสร้างเซลล์โค้ดใหม่
- ติดตั้งแพ็กเกจ BigQuery DataFrames เวอร์ชันล่าสุดจากโค้ดเซลล์ พิมพ์คำสั่งต่อไปนี้
%pip install --upgrade bigframes --quiet
3. อ่านชุดข้อมูลสาธารณะ
เริ่มต้นแพ็กเกจ BigQuery DataFrames โดยเรียกใช้คำสั่งต่อไปนี้ในโค้ดเซลล์ใหม่
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
หมายเหตุ: ในบทแนะนำนี้ เราใช้ "โหมดการเรียงลำดับบางส่วน" ซึ่งเป็นเวอร์ชันทดลอง ซึ่งช่วยให้การค้นหามีประสิทธิภาพมากขึ้นเมื่อใช้ร่วมกับการกรองแบบ pandas ฟีเจอร์บางอย่างของ Pandas ที่ต้องมีการจัดลำดับหรือดัชนีที่เข้มงวดอาจไม่ทำงาน
ตรวจสอบเวอร์ชันแพ็กเกจ bigframes ด้วย
bpd.__version__
บทแนะนำนี้ต้องใช้เวอร์ชัน 1.27.0 ขึ้นไป
ยอดขายปลีกสุราในไอโอวา
ชุดข้อมูลยอดขายปลีกเครื่องดื่มแอลกอฮอล์ในไอโอวามีให้บริการใน BigQuery ผ่านโปรแกรมชุดข้อมูลสาธารณะของ Google Cloud ชุดข้อมูลนี้ประกอบด้วยการซื้อเครื่องดื่มแอลกอฮอล์ทั้งหมดในรัฐไอโอวาโดยผู้ค้าปลีกเพื่อขายให้กับบุคคลธรรมดาตั้งแต่วันที่ 1 มกราคม 2012 โดยกองเครื่องดื่มแอลกอฮอล์ภายในกระทรวงพาณิชย์ของรัฐไอโอวาเป็นผู้รวบรวมข้อมูล
ใน BigQuery ให้ค้นหา bigquery-public-data.iowa_liquor_sales.sales เพื่อวิเคราะห์ยอดขายปลีกสุราในไอโอวา ใช้วิธี bigframes.pandas.read_gbq() เพื่อสร้าง DataFrame จากสตริงการค้นหาหรือรหัสตาราง
เรียกใช้คำสั่งต่อไปนี้ในโค้ดเซลล์ใหม่เพื่อสร้าง DataFrame ชื่อ "df"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
ดูข้อมูลพื้นฐานเกี่ยวกับ DataFrame
ใช้วิธี DataFrame.peek() เพื่อดาวน์โหลดตัวอย่างข้อมูลขนาดเล็ก
เรียกใช้เซลล์นี้
df.peek()
ผลลัพธ์ที่คาดไว้:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
หมายเหตุ: head() ต้องมีการเรียงลำดับ และโดยทั่วไปจะมีประสิทธิภาพน้อยกว่า peek() หากคุณต้องการแสดงตัวอย่างข้อมูลด้วยภาพ
เช่นเดียวกับ pandas ให้ใช้พร็อพเพอร์ตี้ DataFrame.dtypes เพื่อดูคอลัมน์ทั้งหมดที่มีอยู่และประเภทข้อมูลที่เกี่ยวข้อง โดยจะแสดงในลักษณะที่เข้ากันได้กับ Pandas
เรียกใช้เซลล์นี้
df.dtypes
ผลลัพธ์ที่คาดไว้:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
เมธอด DataFrame.describe() จะค้นหาสถิติพื้นฐานบางอย่างจาก DataFrame เรียกใช้ DataFrame.to_pandas() เพื่อดาวน์โหลดสถิติสรุปเหล่านี้เป็น Pandas DataFrame
เรียกใช้เซลล์นี้
df.describe("all").to_pandas()
ผลลัพธ์ที่คาดไว้:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
4. แสดงภาพและล้างข้อมูล
ชุดข้อมูลยอดขายปลีกสุราในรัฐไอโอวาให้ข้อมูลทางภูมิศาสตร์แบบละเอียด ซึ่งรวมถึงที่ตั้งของร้านค้าปลีก ใช้ข้อมูลเหล่านี้เพื่อระบุแนวโน้มและความแตกต่างในพื้นที่ทางภูมิศาสตร์ต่างๆ
แสดงภาพยอดขายต่อรหัสไปรษณีย์
มีวิธีการแสดงภาพในตัวหลายวิธี เช่น DataFrame.plot.hist() ใช้วิธีนี้เพื่อเปรียบเทียบยอดขายเครื่องดื่มแอลกอฮอล์ตามรหัสไปรษณีย์
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
ผลลัพธ์ที่คาดไว้:
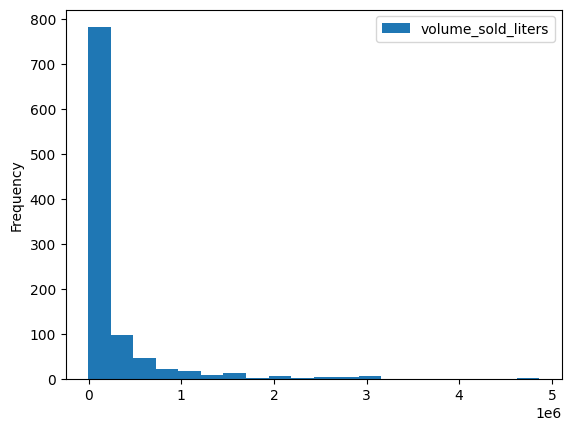
ใช้แผนภูมิแท่งเพื่อดูว่ารหัสไปรษณีย์ใดขายเครื่องดื่มแอลกอฮอล์ได้มากที่สุด
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
ผลลัพธ์ที่คาดไว้:
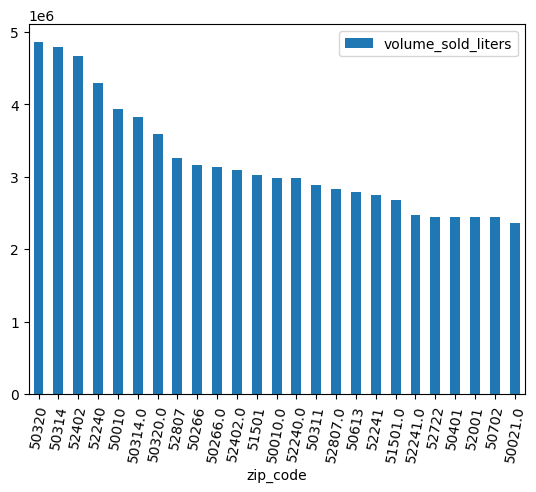
ล้างข้อมูล
รหัสไปรษณีย์บางรายการมี .0 ต่อท้าย อาจเป็นไปได้ว่าในกระบวนการเก็บรวบรวมข้อมูล รหัสไปรษณีย์ถูกแปลงเป็นค่าทศนิยมโดยไม่ตั้งใจ ใช้นิพจน์ทั่วไปเพื่อล้างรหัสไปรษณีย์และทําการวิเคราะห์ซ้ำ
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
ผลลัพธ์ที่คาดไว้:
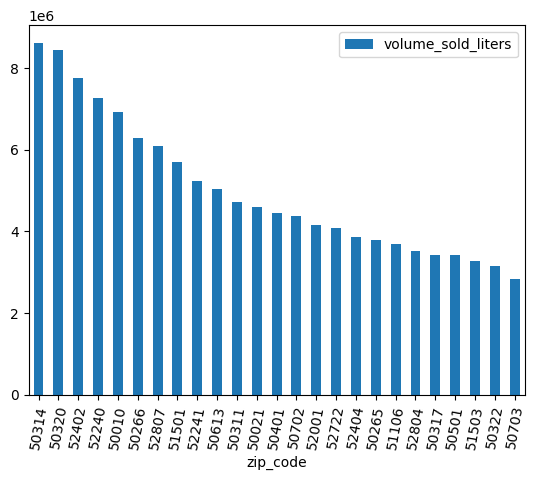
5. ค้นพบความสัมพันธ์ในการขาย
เหตุใดรหัสไปรษณีย์บางรหัสจึงขายได้มากกว่ารหัสอื่นๆ สมมติฐานหนึ่งคือความแตกต่างนี้เกิดจากขนาดประชากรที่แตกต่างกัน รหัสไปรษณีย์ที่มีประชากรมากกว่ามีแนวโน้มที่จะขายสุราได้มากกว่า
ทดสอบสมมติฐานนี้โดยคำนวณความสัมพันธ์ระหว่างประชากรกับปริมาณการขายสุรา
รวมกับชุดข้อมูลอื่นๆ
รวมกับชุดข้อมูลประชากร เช่น แบบสำรวจพื้นที่การจัดตารางรหัสไปรษณีย์ของแบบสำรวจชุมชนอเมริกันของสำนักงานสำมะโนประชากรของสหรัฐอเมริกา
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
การสำรวจชุมชนอเมริกันระบุรัฐตาม GEOID ในกรณีของพื้นที่ตารางรหัสไปรษณีย์ GEOID จะเท่ากับรหัสไปรษณีย์
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
สร้างแผนภูมิกระจายเพื่อเปรียบเทียบประชากรในพื้นที่รหัสไปรษณีย์กับปริมาณเครื่องดื่มแอลกอฮอล์ที่ขาย
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
ผลลัพธ์ที่คาดไว้:
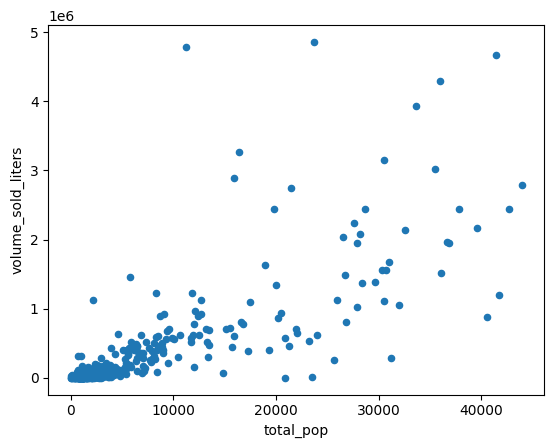
คำนวณสหสัมพันธ์
แนวโน้มดูเหมือนจะเป็นเส้นตรงโดยประมาณ ปรับโมเดลการถดถอยเชิงเส้นให้เข้ากับข้อมูลนี้เพื่อตรวจสอบว่าประชากรคาดการณ์ยอดขายสุราได้ดีเพียงใด
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
ตรวจสอบความเหมาะสมโดยใช้วิธี score
model.score(feature_columns, label_columns).to_pandas()
ตัวอย่างเอาต์พุต:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
วาดเส้นที่เหมาะสมที่สุดโดยเรียกใช้predictฟังก์ชันกับช่วงค่าประชากร
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
ผลลัพธ์ที่คาดไว้:
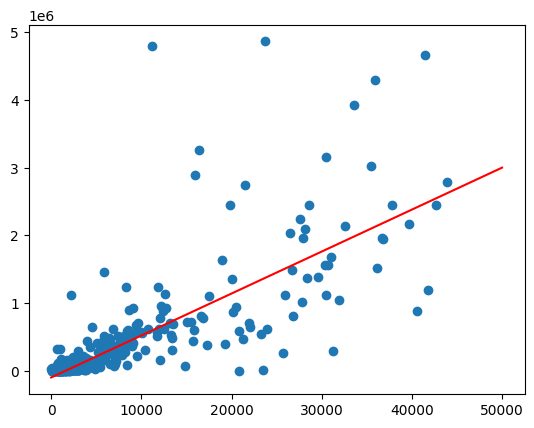
การจัดการความแปรปรวนไม่คงที่
ข้อมูลในแผนภูมิก่อนหน้าดูเหมือนจะเป็นแบบ Heteroscedastic ความแปรปรวนรอบเส้นแนวโน้มที่เหมาะสมที่สุดจะเพิ่มขึ้นตามจำนวนประชากร
ปริมาณเครื่องดื่มแอลกอฮอล์ที่ซื้อต่อคนอาจค่อนข้างคงที่
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
ผลลัพธ์ที่คาดไว้:
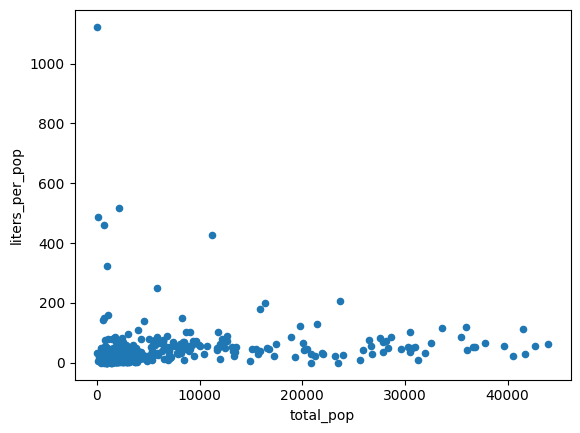
คำนวณปริมาณแอลกอฮอล์โดยเฉลี่ยที่ซื้อได้ 2 วิธีดังนี้
- รัฐไอโอวามีการซื้อเครื่องดื่มแอลกอฮอล์โดยเฉลี่ยเท่าใดต่อคน
- ปริมาณเครื่องดื่มแอลกอฮอล์ที่ซื้อต่อคนโดยเฉลี่ยในรหัสไปรษณีย์ทั้งหมด
ใน (1) จะแสดงปริมาณเครื่องดื่มแอลกอฮอล์ที่ซื้อในทั้งรัฐ ใน (2) จะแสดงรหัสไปรษณีย์เฉลี่ย ซึ่งอาจไม่เหมือนกับ (1) เนื่องจากรหัสไปรษณีย์แต่ละรหัสมีประชากรแตกต่างกัน
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
ผลลัพธ์ที่คาดไว้: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
ผลลัพธ์ที่คาดไว้: 67.139
พล็อตค่าเฉลี่ยเหล่านี้ในลักษณะเดียวกับด้านบน
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
ผลลัพธ์ที่คาดไว้:
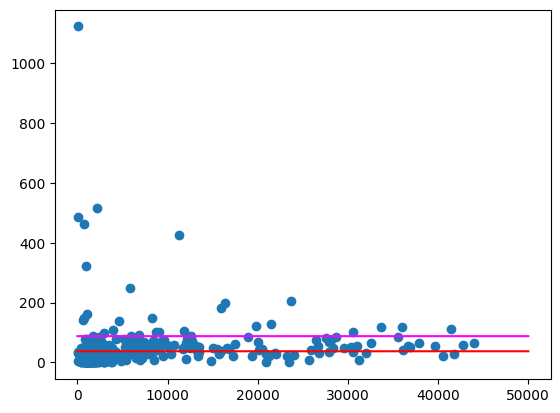
อย่างไรก็ตาม ยังมีรหัสไปรษณีย์บางรหัสที่ถือเป็นค่าผิดปกติที่ค่อนข้างมาก โดยเฉพาะในพื้นที่ที่มีประชากรน้อย คุณสามารถลองตั้งสมมติฐานว่าเหตุใดจึงเป็นเช่นนี้ได้ ตัวอย่างเช่น รหัสไปรษณีย์บางรหัสอาจมีประชากรน้อยแต่มีการบริโภคสูงเนื่องจากมีร้านขายเครื่องดื่มแอลกอฮอล์เพียงร้านเดียวในพื้นที่ หากเป็นเช่นนั้น การคำนวณตามประชากรของรหัสไปรษณีย์โดยรอบอาจทำให้ค่าผิดปกติเหล่านี้หายไป
6. เปรียบเทียบประเภทเครื่องดื่มแอลกอฮอล์ที่ขาย
นอกจากข้อมูลทางภูมิศาสตร์แล้ว ฐานข้อมูลยอดขายปลีกสุราในไอโอวายังมีข้อมูลโดยละเอียดเกี่ยวกับสินค้าที่ขายด้วย การวิเคราะห์ข้อมูลเหล่านี้อาจช่วยให้เราเห็นความแตกต่างของรสนิยมในพื้นที่ทางภูมิศาสตร์ต่างๆ
สำรวจหมวดหมู่
ระบบจะจัดหมวดหมู่รายการในฐานข้อมูล มีกี่หมวดหมู่
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
ผลลัพธ์ที่คาดไว้: 103
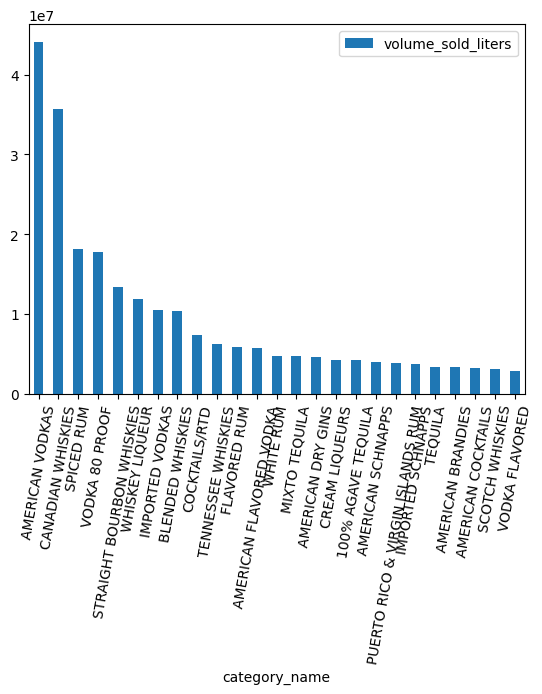
หมวดหมู่ใดได้รับความนิยมมากที่สุดตามปริมาณ
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
การทำงานกับประเภทข้อมูล ARRAY
วิสกี้ รัม วอดก้า และอื่นๆ มีหลายหมวดหมู่ ฉันอยากจัดกลุ่มรายการเหล่านี้เข้าด้วยกัน
เริ่มด้วยการแยกชื่อหมวดหมู่เป็นคำๆ โดยใช้เมธอด Series.str.split() ยกเลิกการซ้อนอาร์เรย์ที่สร้างขึ้นโดยใช้เมธอด explode()
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
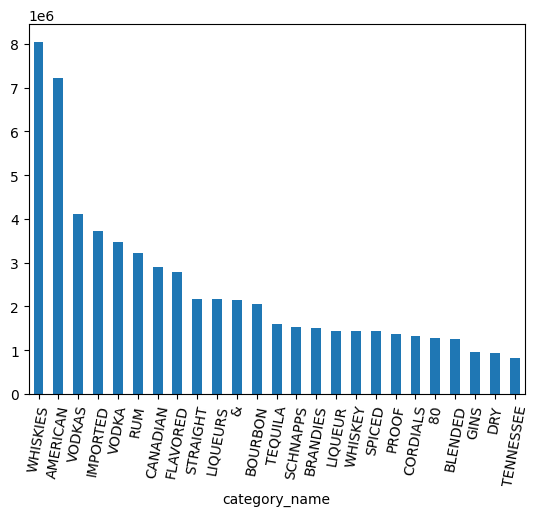
category_parts.nunique()
ผลลัพธ์ที่คาดไว้: 113
เมื่อดูแผนภูมิด้านบน ข้อมูลยังคงมี VODKA แยกจาก VODKAS ต้องจัดกลุ่มเพิ่มเติมเพื่อยุบหมวดหมู่ให้เหลือชุดที่เล็กลง
7. การใช้ NLTK กับ DataFrame ของ BigQuery
เนื่องจากมีหมวดหมู่เพียงประมาณ 100 หมวดหมู่ จึงเป็นไปได้ที่จะเขียนฮิวริสติกบางอย่างหรือแม้แต่สร้างการแมปจากหมวดหมู่ไปยังประเภทเครื่องดื่มแอลกอฮอล์ที่กว้างขึ้นด้วยตนเอง หรือจะใช้โมเดลภาษาขนาดใหญ่อย่าง Gemini เพื่อสร้างการแมปดังกล่าวก็ได้ ลองใช้ Codelab รับข้อมูลเชิงลึกจากข้อมูลที่ไม่มีโครงสร้างโดยใช้ BigQuery DataFrames เพื่อใช้ BigQuery DataFrames กับ Gemini
แต่ให้ใช้แพ็กเกจการประมวลผลภาษาธรรมชาติ (NLP) แบบดั้งเดิมอย่าง NLTK เพื่อประมวลผลข้อมูลเหล่านี้แทน เทคโนโลยีที่เรียกว่า "Stemmer" สามารถผสานคำนามที่เป็นเอกพจน์และพหูพจน์ให้เป็นค่าเดียวกันได้ เช่น
การใช้ NLTK เพื่อลดรูปคำ
แพ็กเกจ NLTK มีวิธีการประมวลผลภาษาธรรมชาติที่เข้าถึงได้จาก Python ติดตั้งแพ็กเกจเพื่อลองใช้
%pip install nltk
จากนั้นให้นำเข้าแพ็กเกจ ตรวจสอบเวอร์ชัน ซึ่งจะใช้ในบทแนะนำในภายหลัง
import nltk
nltk.__version__
วิธีหนึ่งในการกำหนดมาตรฐานคำคือการ "ตัด" คำ ซึ่งจะนำคำต่อท้ายออก เช่น "s" ที่ต่อท้ายคำเพื่อแสดงถึงคำที่เป็นพหูพจน์
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
ลองใช้กับคำ 2-3 คำ
stem("WHISKEY")
ผลลัพธ์ที่คาดไว้: whiskey
stem("WHISKIES")
ผลลัพธ์ที่คาดไว้: whiski
แต่ระบบไม่ได้แมปวิสกี้กับวิสกี้ Stemmer ทำงานได้ไม่ดีกับคำพหูพจน์ที่ผิดปกติ ลองใช้โปรแกรม Lemmatizer ซึ่งใช้เทคนิคที่ซับซ้อนกว่าในการระบุคำฐานที่เรียกว่า "Lemma"
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
ลองใช้กับคำ 2-3 คำ
lemmatize("WHISKIES")
ผลลัพธ์ที่คาดไว้: whisky
lemmatize("WHISKY")
ผลลัพธ์ที่คาดไว้: whisky
lemmatize("WHISKEY")
ผลลัพธ์ที่คาดไว้: whiskey
ขออภัย Lemmatizer นี้ไม่ได้แมป "whiskey" กับ Lemma เดียวกันกับ "whiskies" เนื่องจากคำนี้มีความสำคัญอย่างยิ่งสำหรับฐานข้อมูลการขายเครื่องดื่มแอลกอฮอล์ปลีกในไอโอวา ให้แมปคำนี้กับคำที่สะกดแบบอเมริกันด้วยตนเองโดยใช้พจนานุกรม
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
ลองใช้กับคำ 2-3 คำ
lemmatize("WHISKIES")
ผลลัพธ์ที่คาดไว้: whiskey
lemmatize("WHISKEY")
ผลลัพธ์ที่คาดไว้: whiskey
ยินดีด้วย Lemmatizer นี้ควรใช้ได้ดีในการจำกัดหมวดหมู่ หากต้องการใช้กับ BigQuery คุณต้องติดตั้งใช้งานในระบบคลาวด์
ตั้งค่าโปรเจ็กต์สำหรับการติดตั้งใช้งานฟังก์ชัน
ก่อนที่จะนำไปใช้กับระบบคลาวด์เพื่อให้ BigQuery เข้าถึงฟังก์ชันนี้ได้ คุณจะต้องทำการตั้งค่าครั้งเดียว
สร้างโค้ดเซลล์ใหม่ แล้วแทนที่ your-project-id ด้วยรหัสโปรเจ็กต์ Google Cloud ที่คุณใช้สำหรับบทแนะนำนี้
project_id = "your-project-id"
สร้างบัญชีบริการโดยไม่มีสิทธิ์ใดๆ เนื่องจากฟังก์ชันนี้ไม่จำเป็นต้องเข้าถึงทรัพยากรระบบคลาวด์
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
ผลลัพธ์ที่คาดไว้: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
สร้างชุดข้อมูล BigQuery เพื่อเก็บฟังก์ชัน
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
การทำให้ฟังก์ชันระยะไกลใช้งานได้
เปิดใช้ Cloud Functions API หากยังไม่ได้เปิดใช้
!gcloud services enable cloudfunctions.googleapis.com
ตอนนี้ ให้ติดตั้งใช้งานฟังก์ชันกับชุดข้อมูลที่คุณเพิ่งสร้าง เพิ่ม@bpd.remote_function Decorator ลงในฟังก์ชันที่คุณสร้างไว้ในขั้นตอนก่อนหน้า
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
การติดตั้งใช้งานจะใช้เวลาประมาณ 2 นาที
การใช้ฟังก์ชันรีโมต
เมื่อการติดตั้งใช้งานเสร็จสมบูรณ์แล้ว คุณจะทดสอบฟังก์ชันนี้ได้
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
ผลลัพธ์ที่คาดไว้:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
8. เปรียบเทียบการบริโภคเครื่องดื่มแอลกอฮอล์ตามเขต
ตอนนี้ฟังก์ชัน lemmatize พร้อมใช้งานแล้ว ให้ใช้ฟังก์ชันนี้เพื่อรวมหมวดหมู่
การค้นหาคำที่สรุปหมวดหมู่ได้ดีที่สุด
ก่อนอื่นให้สร้าง DataFrame ของหมวดหมู่ทั้งหมดในฐานข้อมูล
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
ผลลัพธ์ที่คาดไว้:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
จากนั้นสร้าง DataFrame ของคำทั้งหมดในหมวดหมู่ ยกเว้นคำเสริมบางคำ เช่น เครื่องหมายวรรคตอนและ "รายการ"
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
ผลลัพธ์ที่คาดไว้:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
โปรดทราบว่าการทำเลมมาไทเซชันหลังจากจัดกลุ่มจะช่วยลดภาระของ Cloud Function คุณสามารถใช้ฟังก์ชันการแปลงคำเป็นรูปแบบพื้นฐานกับแต่ละแถวจากหลายล้านแถวในฐานข้อมูลได้ แต่จะมีค่าใช้จ่ายมากกว่าการใช้ฟังก์ชันหลังจากจัดกลุ่ม และอาจต้องเพิ่มโควต้า
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
ผลลัพธ์ที่คาดไว้:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
เมื่อทำ Lemmatization คำแล้ว คุณต้องเลือก Lemma ที่สรุปหมวดหมู่ได้ดีที่สุด เนื่องจากหมวดหมู่มีคำฟังก์ชันไม่มาก ให้ใช้ฮิวริสติกที่ว่าหากคำปรากฏในหมวดหมู่อื่นๆ หลายหมวดหมู่ คำนั้นน่าจะเหมาะเป็นคำสรุปมากกว่า (เช่น วิสกี้)
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
ผลลัพธ์ที่คาดไว้:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
ตอนนี้มี Lemma เดียวที่สรุปแต่ละหมวดหมู่แล้ว ให้ผสาน Lemma นี้กับ DataFrame เดิม
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
ผลลัพธ์ที่คาดไว้:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
การเปรียบเทียบเทศมณฑล
เปรียบเทียบยอดขายในแต่ละเทศมณฑลเพื่อดูความแตกต่าง
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
ค้นหาผลิตภัณฑ์ (คำหลัก) ที่ขายได้มากที่สุดในแต่ละประเทศ
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
ผลลัพธ์ที่คาดไว้:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
แต่ละเขตแตกต่างกันอย่างไร
county_max_lemma.groupby("lemma").size().to_pandas()
ผลลัพธ์ที่คาดไว้:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
ในมณฑลส่วนใหญ่ วิสกี้เป็นผลิตภัณฑ์ที่ได้รับความนิยมมากที่สุดตามปริมาณ ส่วนวอดก้าได้รับความนิยมมากที่สุดใน 15 มณฑล เปรียบเทียบกับเครื่องดื่มแอลกอฮอล์ประเภทที่ได้รับความนิยมมากที่สุดทั่วทั้งรัฐ
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
ผลลัพธ์ที่คาดไว้:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
วิสกี้และวอดก้ามีปริมาณการดื่มเกือบเท่ากัน โดยวอดก้ามีปริมาณการดื่มสูงกว่าวิสกี้เล็กน้อยทั่วทั้งรัฐ
การเปรียบเทียบสัดส่วน
ยอดขายในแต่ละประเทศมีลักษณะเฉพาะอย่างไร อะไรทำให้เขตนี้แตกต่างจากส่วนอื่นๆ ของรัฐ
ใช้การวัดค่า h ของ Cohen เพื่อดูว่าปริมาณการขายเครื่องดื่มแอลกอฮอล์ใดที่แตกต่างจากที่คาดไว้มากที่สุดตามสัดส่วนของการขายทั่วทั้งรัฐ
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
เมื่อวัดค่า h ของ Cohen สำหรับแต่ละ Lemma แล้ว ให้หาความแตกต่างที่มากที่สุดจากสัดส่วนทั่วทั้งรัฐในแต่ละเขต
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
ผลลัพธ์ที่คาดไว้:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
ยิ่งค่า h ของ Cohen สูงขึ้นเท่าใด ก็ยิ่งมีแนวโน้มที่จะมีความแตกต่างอย่างมีนัยสำคัญทางสถิติในปริมาณเครื่องดื่มแอลกอฮอล์ประเภทนั้นๆ ที่บริโภคเมื่อเทียบกับค่าเฉลี่ยของรัฐ สำหรับค่าบวกที่น้อยกว่า ความแตกต่างในการบริโภคจะแตกต่างจากค่าเฉลี่ยทั่วทั้งรัฐ แต่อาจเกิดจากความแตกต่างแบบสุ่ม
หมายเหตุ: ดูเหมือนว่าเขต EL PASO ไม่ใช่เขตในไอโอวา ซึ่งอาจบ่งบอกถึงความจำเป็นในการล้างข้อมูลก่อนที่จะพึ่งพาผลลัพธ์เหล่านี้อย่างเต็มที่
การแสดงภาพเคาน์ตี
รวมกับbigquery-public-data.geo_us_boundaries.countiesตารางเพื่อรับพื้นที่ทางภูมิศาสตร์สำหรับแต่ละเขต ชื่อเขตอาจซ้ำกันได้ทั่วสหรัฐอเมริกา ดังนั้นให้กรองเพื่อรวมเฉพาะเขตจากไอโอวา รหัส FIPS สำหรับไอโอวาคือ "19"
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
ผลลัพธ์ที่คาดไว้:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
ใช้ GeoPandas เพื่อแสดงความแตกต่างเหล่านี้บนแผนที่
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)
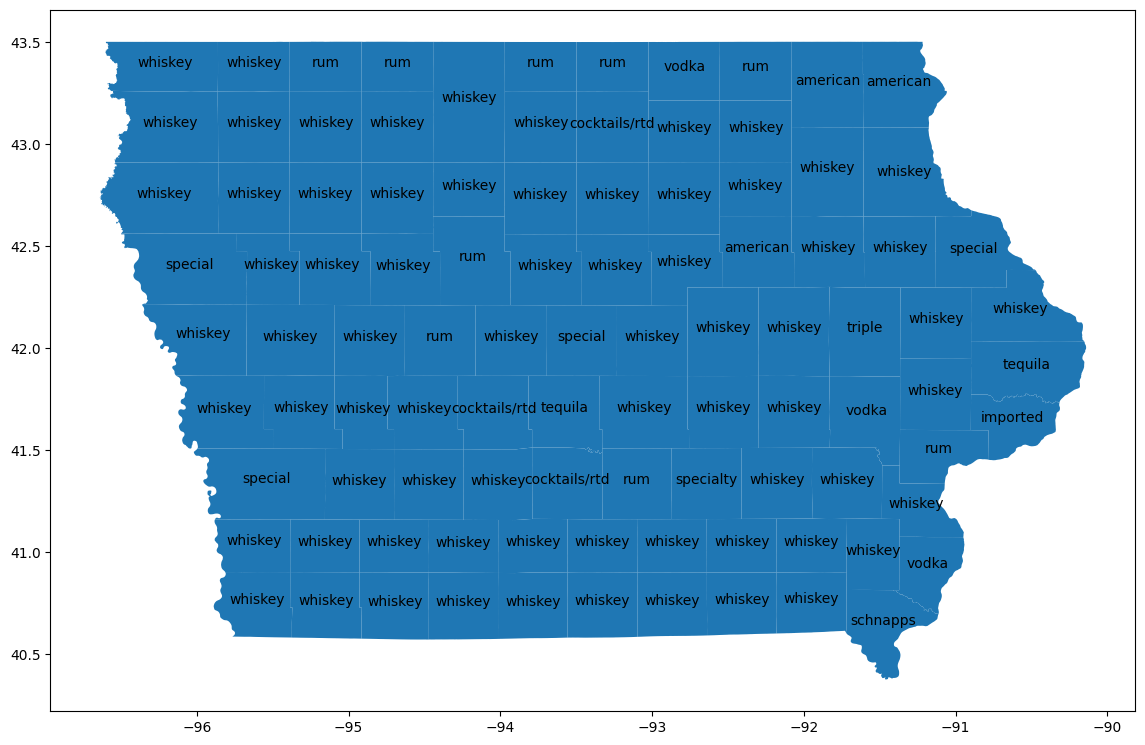
9. ล้างข้อมูล
หากสร้างโปรเจ็กต์ Google Cloud ใหม่สำหรับบทแนะนำนี้ คุณสามารถลบโปรเจ็กต์ดังกล่าวเพื่อป้องกันการเรียกเก็บเงินเพิ่มเติมสำหรับตารางหรือทรัพยากรอื่นๆ ที่สร้างขึ้น
หรือจะลบ Cloud Functions, บัญชีบริการ และชุดข้อมูลที่สร้างขึ้นสำหรับบทแนะนำนี้ก็ได้
10. ยินดีด้วย
คุณได้ล้างและวิเคราะห์ข้อมูลที่มีโครงสร้างโดยใช้ BigQuery DataFrames ในระหว่างนี้ คุณได้สำรวจชุดข้อมูลสาธารณะของ Google Cloud, Notebook ของ Python ใน BigQuery Studio, BigQuery ML, ฟังก์ชันระยะไกลของ BigQuery และศักยภาพของ BigQuery DataFrames ยอดเยี่ยมมาก
ขั้นตอนถัดไป
- ใช้ขั้นตอนเหล่านี้กับข้อมูลอื่นๆ เช่น ฐานข้อมูลชื่อในสหรัฐอเมริกา
- ลองสร้างโค้ด Python ใน Notebook สมุดบันทึก Python ใน BigQuery Studio ขับเคลื่อนโดย Colab Enterprise เคล็ดลับ: ฉันพบว่าการขอความช่วยเหลือในการสร้างข้อมูลทดสอบมีประโยชน์มาก
- สำรวจ Notebook ตัวอย่างสำหรับ BigQuery DataFrame บน GitHub
- สร้างกำหนดเวลาเพื่อเรียกใช้ Notebook ใน BigQuery Studio
- ติดตั้งใช้งานฟังก์ชันระยะไกลด้วย BigQuery DataFrames เพื่อผสานรวมแพ็กเกจ Python ของบุคคลที่สามกับ BigQuery