
1. Tổng quan
Trong bài thực hành này, bạn sẽ sử dụng BigQuery DataFrames từ một sổ tay Python trong BigQuery Studio để làm sạch và phân tích tập dữ liệu công khai về doanh số bán rượu ở Iowa. Tận dụng các chức năng BigQuery ML và hàm từ xa để khám phá thông tin chi tiết.
Bạn sẽ tạo một sổ tay Python để so sánh doanh số bán hàng ở các khu vực địa lý. Bạn có thể điều chỉnh để sử dụng trên mọi dữ liệu có cấu trúc.
Mục tiêu
Trong bài thực hành này, bạn sẽ tìm hiểu cách thực hiện các thao tác sau:
- Kích hoạt và sử dụng sổ tay Python trong BigQuery Studio
- Kết nối với BigQuery bằng gói BigQuery DataFrames
- Tạo mô hình hồi quy tuyến tính bằng BigQuery ML
- Thực hiện các phép tổng hợp và kết hợp phức tạp bằng cách sử dụng cú pháp quen thuộc như pandas
2. Yêu cầu
- Một trình duyệt, chẳng hạn như Chrome hoặc Firefox
- Một dự án trên Google Cloud đã bật tính năng thanh toán
Trước khi bắt đầu
Để làm theo hướng dẫn trong lớp học lập trình này, bạn cần có một Dự án Google Cloud đã bật BigQuery Studio và một tài khoản thanh toán được kết nối.
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Google Cloud của mình. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không
- Làm theo hướng dẫn để Bật BigQuery Studio để quản lý tài sản.
Chuẩn bị BigQuery Studio
Tạo một sổ tay trống và kết nối sổ tay đó với một thời gian chạy.
- Chuyển đến BigQuery Studio trong Google Cloud Console.
- Nhấp vào biểu tượng ▼ bên cạnh nút +.
- Chọn Sổ tay Python.
- Đóng bộ chọn mẫu.
- Chọn + Code (Mã) để tạo một ô mã mới.
- Cài đặt phiên bản mới nhất của gói BigQuery DataFrames từ ô mã.Nhập lệnh sau.
%pip install --upgrade bigframes --quiet
3. Đọc một tập dữ liệu công khai
Khởi chạy gói BigQuery DataFrames bằng cách chạy đoạn mã sau trong một ô mã mới:
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
Lưu ý: trong hướng dẫn này, chúng ta sẽ sử dụng "chế độ sắp xếp một phần" thử nghiệm, cho phép thực hiện các truy vấn hiệu quả hơn khi được dùng với tính năng lọc tương tự như pandas. Một số tính năng của pandas yêu cầu một thứ tự hoặc chỉ mục nghiêm ngặt có thể không hoạt động.
Kiểm tra phiên bản gói bigframes bằng
bpd.__version__
Hướng dẫn này yêu cầu phiên bản 1.27.0 trở lên.
Bán lẻ rượu ở Iowa
Tập dữ liệu về doanh số bán lẻ rượu ở Iowa được cung cấp trên BigQuery thông qua chương trình tập dữ liệu công khai của Google Cloud. Tập dữ liệu này chứa mọi giao dịch mua rượu bán buôn của các nhà bán lẻ ở tiểu bang Iowa để bán cho cá nhân kể từ ngày 1 tháng 1 năm 2012. Dữ liệu được thu thập bởi Phòng Đồ uống có cồn thuộc Bộ Thương mại Iowa.
Trong BigQuery, hãy truy vấn bigquery-public-data.iowa_liquor_sales.sales để phân tích doanh số bán lẻ rượu ở Iowa. Sử dụng phương thức bigframes.pandas.read_gbq() để tạo DataFrame từ một chuỗi truy vấn hoặc mã nhận dạng bảng.
Chạy mã sau trong một ô mã mới để tạo DataFrame có tên "df":
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
Khám phá thông tin cơ bản về DataFrame
Sử dụng phương thức DataFrame.peek() để tải một mẫu nhỏ của dữ liệu xuống.
Chạy ô này:
df.peek()
Kết quả đầu ra dự kiến:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
Lưu ý: head() yêu cầu sắp xếp và thường kém hiệu quả hơn peek() nếu bạn muốn trực quan hoá một mẫu dữ liệu.
Giống như với pandas, hãy sử dụng thuộc tính DataFrame.dtypes để xem tất cả các cột có sẵn và các kiểu dữ liệu tương ứng. Các thông tin này được hiển thị theo cách tương thích với pandas.
Chạy ô này:
df.dtypes
Kết quả đầu ra dự kiến:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
Phương thức DataFrame.describe() truy vấn một số số liệu thống kê cơ bản từ DataFrame. Chạy DataFrame.to_pandas() để tải các số liệu thống kê tóm tắt này xuống dưới dạng pandas DataFrame.
Chạy ô này:
df.describe("all").to_pandas()
Kết quả đầu ra dự kiến:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
4. Trực quan hoá và làm sạch dữ liệu
Tập dữ liệu về doanh số bán lẻ rượu ở Iowa cung cấp thông tin địa lý chi tiết, bao gồm cả vị trí của các cửa hàng bán lẻ. Sử dụng những dữ liệu này để xác định xu hướng và sự khác biệt giữa các khu vực địa lý.
Trực quan hoá doanh số bán hàng theo mã bưu chính
Có một số phương thức trực quan hoá tích hợp sẵn, chẳng hạn như DataFrame.plot.hist(). Hãy sử dụng phương thức này để so sánh doanh số bán rượu theo mã bưu chính.
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
Kết quả đầu ra dự kiến:
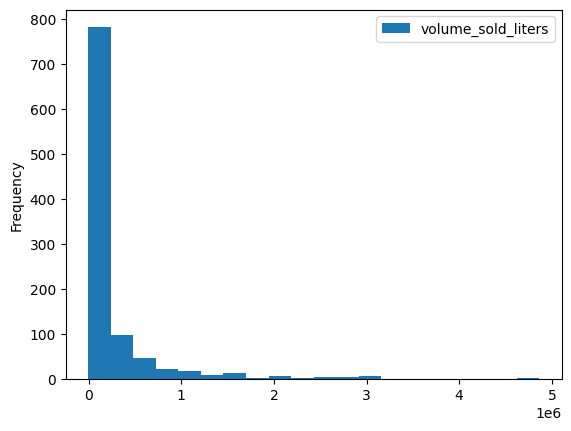
Sử dụng biểu đồ thanh để xem mã bưu chính nào bán được nhiều đồ uống có cồn nhất.
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Kết quả đầu ra dự kiến:
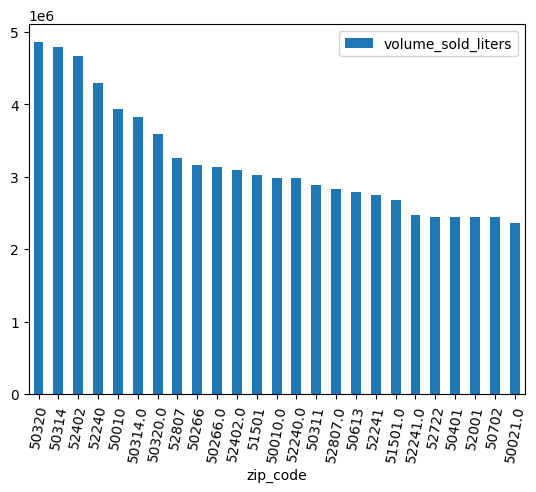
Làm sạch dữ liệu
Một số mã bưu chính có dấu .0 ở cuối. Có thể là trong quá trình thu thập dữ liệu, mã bưu chính đã vô tình được chuyển đổi thành giá trị dấu phẩy động. Sử dụng biểu thức chính quy để dọn dẹp mã ZIP và lặp lại quy trình phân tích.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Kết quả đầu ra dự kiến:
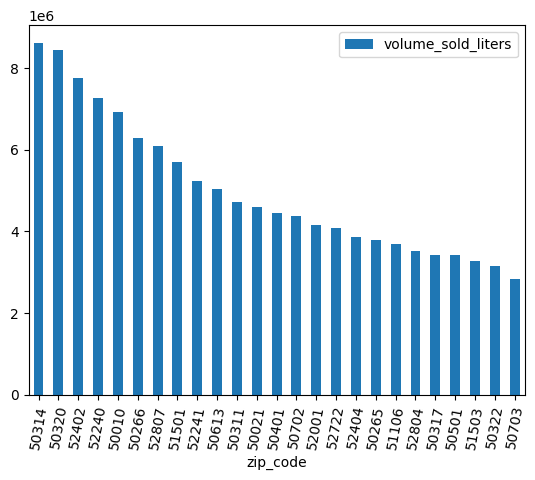
5. Khám phá mối tương quan trong doanh số
Tại sao một số mã bưu chính bán được nhiều hơn những mã khác? Một giả thuyết cho rằng điều này là do sự khác biệt về quy mô dân số. Mã bưu chính có dân số đông hơn có thể sẽ bán được nhiều rượu hơn.
Kiểm định giả thuyết này bằng cách tính mối tương quan giữa dân số và doanh số bán rượu.
Kết hợp với các tập dữ liệu khác
Kết hợp với một tập dữ liệu dân số, chẳng hạn như cuộc khảo sát khu vực lập bảng mã bưu chính của Cuộc khảo sát cộng đồng Hoa Kỳ của Cục Thống kê Dân số Hoa Kỳ.
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
Khảo sát cộng đồng Hoa Kỳ xác định các tiểu bang theo GEOID. Trong trường hợp các khu vực lập bảng mã bưu chính, GEOID bằng với mã bưu chính.
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
Tạo biểu đồ tán xạ để so sánh dân số theo khu vực lập bảng mã bưu chính với số lít rượu đã bán.
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
Kết quả đầu ra dự kiến:
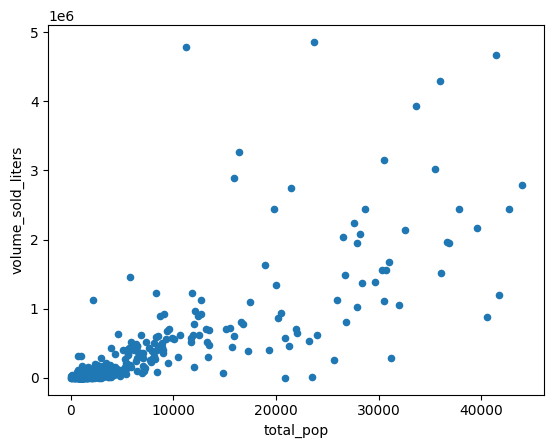
Tính hệ số tương quan
Xu hướng này có vẻ gần như tuyến tính. Điều chỉnh mô hình hồi quy tuyến tính cho dữ liệu này để kiểm tra mức độ dự đoán doanh số bán rượu của dân số.
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
Kiểm tra độ vừa vặn bằng phương thức score.
model.score(feature_columns, label_columns).to_pandas()
Đầu ra mẫu:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
Vẽ đường phù hợp nhất bằng cách gọi hàm predict trên một dải giá trị dân số.
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
Kết quả đầu ra dự kiến:
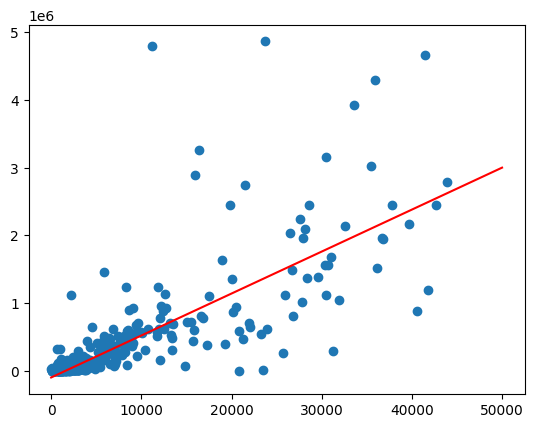
Giải quyết phương sai không đồng nhất
Dữ liệu trong biểu đồ trước có vẻ như là phương sai không đồng nhất. Phương sai xung quanh đường thẳng phù hợp nhất tăng lên cùng với số lượng dân số.
Có lẽ lượng đồ uống có cồn mà mỗi người mua là tương đối ổn định.
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
Kết quả đầu ra dự kiến:
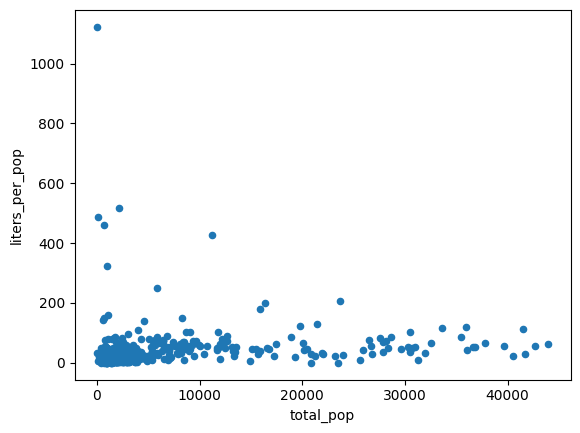
Tính số lít rượu trung bình đã mua theo 2 cách:
- Lượng cồn trung bình mà mỗi người mua ở Iowa là bao nhiêu?
- Số lượng đồ uống có cồn trung bình được mua trên mỗi người ở tất cả mã bưu chính là bao nhiêu.
Trong (1), chỉ số này phản ánh lượng đồ uống có cồn được mua ở toàn bộ tiểu bang. Trong (2), giá trị này phản ánh mã bưu chính trung bình, không nhất thiết phải giống với (1) vì mỗi mã bưu chính có số lượng người dùng khác nhau.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
Kết quả đầu ra dự kiến: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
Kết quả đầu ra dự kiến: 67.139
Vẽ các giá trị trung bình này, tương tự như trên.
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
Kết quả đầu ra dự kiến:
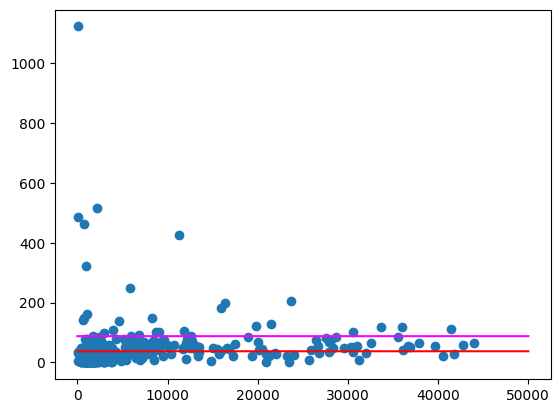
Vẫn có một số mã bưu chính là giá trị ngoại lệ khá lớn, đặc biệt là ở những khu vực có ít dân cư. Bạn có thể tự suy đoán lý do cho việc này. Ví dụ: có thể một số mã ZIP có dân số thấp nhưng mức tiêu thụ cao vì chỉ có một cửa hàng rượu ở khu vực đó. Nếu vậy, việc tính toán dựa trên dân số của các mã ZIP lân cận có thể loại bỏ những điểm ngoại lệ này.
6. So sánh các loại rượu được bán
Ngoài dữ liệu địa lý, cơ sở dữ liệu bán lẻ rượu của Iowa cũng chứa thông tin chi tiết về mặt hàng đã bán. Có lẽ bằng cách phân tích những dữ liệu này, chúng ta có thể thấy được sự khác biệt về sở thích giữa các khu vực địa lý.
Khám phá các danh mục
Các mục được phân loại trong cơ sở dữ liệu. Có bao nhiêu danh mục?
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
Kết quả đầu ra dự kiến: 103
Những danh mục nào phổ biến nhất theo số lượng?
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
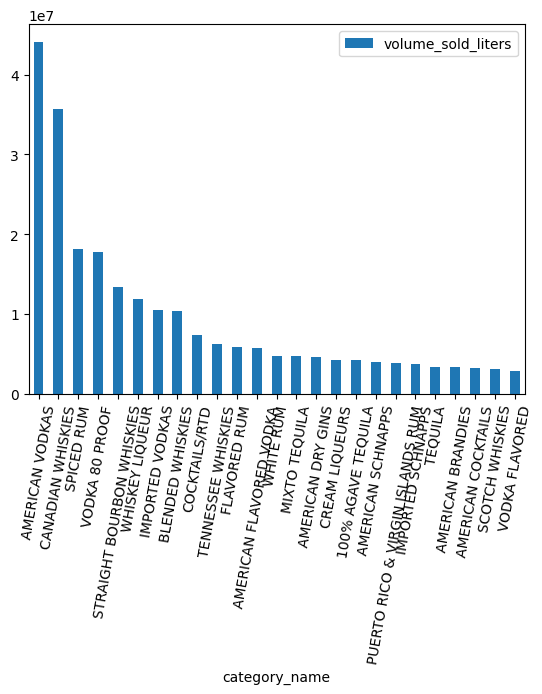
Làm việc với kiểu dữ liệu ARRAY
Có nhiều danh mục cho từng loại rượu whisky, rượu rum, rượu vodka và nhiều loại khác. Tôi muốn nhóm những thứ này lại với nhau.
Bắt đầu bằng cách chia tên danh mục thành các từ riêng biệt bằng phương thức Series.str.split(). Huỷ lồng mảng mà phương thức này tạo bằng cách sử dụng phương thức explode().
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)
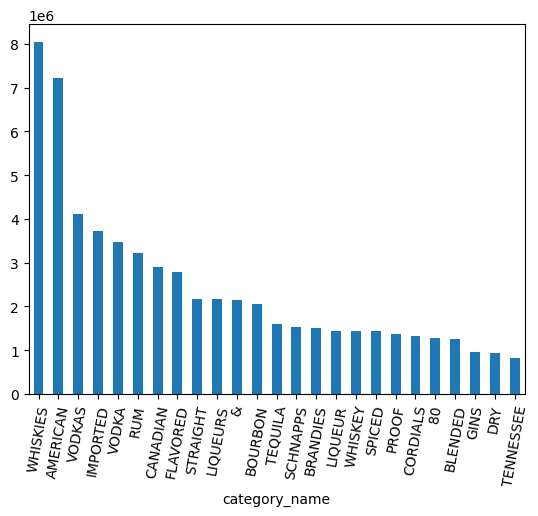
category_parts.nunique()
Kết quả đầu ra dự kiến: 113
Nhìn vào biểu đồ ở trên, dữ liệu vẫn có VODKA tách biệt với VODKAS. Bạn cần nhóm thêm để thu gọn các danh mục thành một nhóm nhỏ hơn.
7. Sử dụng NLTK với BigQuery DataFrames
Chỉ với khoảng 100 danh mục, bạn có thể viết một số phương pháp phỏng đoán hoặc thậm chí tạo mối liên kết theo cách thủ công từ danh mục đến loại đồ uống có cồn rộng hơn. Ngoài ra, bạn có thể sử dụng một mô hình ngôn ngữ lớn như Gemini để tạo mối liên kết như vậy. Hãy thử lớp học lập trình Khai thác thông tin chi tiết từ dữ liệu không có cấu trúc bằng BigQuery DataFrames để sử dụng BigQuery DataFrames với Gemini.
Thay vào đó, hãy sử dụng một gói xử lý ngôn ngữ tự nhiên truyền thống hơn là NLTK để xử lý những dữ liệu này. Ví dụ: công nghệ được gọi là "stemmer" có thể hợp nhất danh từ số nhiều và số ít thành cùng một giá trị.
Sử dụng NLTK để rút gọn từ
Gói NLTK cung cấp các phương thức xử lý ngôn ngữ tự nhiên có thể truy cập từ Python. Cài đặt gói để dùng thử.
%pip install nltk
Tiếp theo, hãy nhập gói. Kiểm tra phiên bản. Chúng ta sẽ dùng hàm này sau trong hướng dẫn.
import nltk
nltk.__version__
Một cách chuẩn hoá từ là "cắt" từ. Thao tác này sẽ xoá mọi hậu tố, chẳng hạn như "s" ở cuối cho số nhiều.
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
Hãy thử với một vài từ.
stem("WHISKEY")
Kết quả đầu ra dự kiến: whiskey
stem("WHISKIES")
Kết quả đầu ra dự kiến: whiski
Rất tiếc, điều này không liên kết rượu whisky với rượu whiskey. Chương trình phân tích hình thái không hoạt động hiệu quả với số nhiều bất quy tắc. Hãy thử dùng một chương trình phân tích hình thái ngôn ngữ. Chương trình này sử dụng các kỹ thuật tinh vi hơn để xác định từ gốc, còn gọi là "lemma".
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
Hãy thử với một vài từ.
lemmatize("WHISKIES")
Kết quả đầu ra dự kiến: whisky
lemmatize("WHISKY")
Kết quả đầu ra dự kiến: whisky
lemmatize("WHISKEY")
Kết quả đầu ra dự kiến: whiskey
Rất tiếc, công cụ phân tích hình thái này không liên kết "whiskey" với cùng một từ gốc như "whiskies". Vì từ này đặc biệt quan trọng đối với cơ sở dữ liệu bán lẻ rượu của Iowa, hãy tự động liên kết từ này với cách viết theo tiếng Anh của Mỹ bằng cách sử dụng từ điển.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Hãy thử với một vài từ.
lemmatize("WHISKIES")
Kết quả đầu ra dự kiến: whiskey
lemmatize("WHISKEY")
Kết quả đầu ra dự kiến: whiskey
Xin chúc mừng! Công cụ phân tích hình thái này sẽ giúp thu hẹp các danh mục. Để sử dụng tính năng này với BigQuery, bạn phải triển khai tính năng này lên đám mây.
Thiết lập dự án để triển khai hàm
Trước khi triển khai hàm này lên đám mây để BigQuery có thể truy cập vào hàm này, bạn cần thiết lập một lần.
Tạo một ô mã mới và thay thế your-project-id bằng mã dự án trên đám mây của Google mà bạn đang dùng cho hướng dẫn này.
project_id = "your-project-id"
Tạo một tài khoản dịch vụ không có quyền nào, vì hàm này không cần quyền truy cập vào bất kỳ tài nguyên đám mây nào.
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
Kết quả đầu ra dự kiến: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
Tạo một tập dữ liệu BigQuery để lưu trữ hàm.
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
Triển khai một hàm từ xa
Bật Cloud Functions API nếu bạn chưa bật.
!gcloud services enable cloudfunctions.googleapis.com
Giờ đây, hãy triển khai hàm cho tập dữ liệu mà bạn vừa tạo. Thêm một đối tượng trang trí @bpd.remote_function vào hàm mà bạn đã tạo ở các bước trước.
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Quá trình triển khai sẽ mất khoảng 2 phút.
Sử dụng các chức năng trên thiết bị từ xa
Sau khi quá trình triển khai hoàn tất, bạn có thể kiểm thử hàm này.
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
Kết quả đầu ra dự kiến:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
8. So sánh mức tiêu thụ đồ uống có cồn theo quận
Giờ đây, hàm lemmatize đã có sẵn, hãy dùng hàm này để kết hợp các danh mục.
Tìm từ phù hợp nhất để tóm tắt danh mục
Trước tiên, hãy tạo một DataFrame gồm tất cả danh mục trong cơ sở dữ liệu.
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
Kết quả đầu ra dự kiến:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
Tiếp theo, hãy tạo một DataFrame gồm tất cả các từ trong danh mục, ngoại trừ một số từ bổ sung như dấu chấm câu và "mặt hàng".
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
Kết quả đầu ra dự kiến:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
Xin lưu ý rằng bằng cách phân tích hình thái sau khi nhóm, bạn sẽ giảm tải cho Cloud Function. Bạn có thể áp dụng hàm lemmatize cho từng hàng trong số hàng triệu hàng trong cơ sở dữ liệu, nhưng việc này sẽ tốn kém hơn so với việc áp dụng hàm này sau khi nhóm và có thể cần tăng hạn mức.
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
Kết quả đầu ra dự kiến:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
Sau khi các từ đã được quy về dạng cơ sở, bạn cần chọn dạng cơ sở tóm tắt tốt nhất danh mục. Vì không có nhiều từ chức năng trong các danh mục, hãy sử dụng phương pháp phỏng đoán rằng nếu một từ xuất hiện trong nhiều danh mục khác, thì có thể từ đó sẽ phù hợp hơn với vai trò là từ tóm tắt (ví dụ: rượu whisky).
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
Kết quả đầu ra dự kiến:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
Giờ đây, khi có một từ gốc duy nhất tóm tắt từng danh mục, hãy hợp nhất từ gốc này vào DataFrame ban đầu.
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
Kết quả đầu ra dự kiến:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
So sánh các quận
So sánh doanh số bán hàng ở từng quận để xem có sự khác biệt nào không.
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
Tìm sản phẩm (từ gốc) được bán nhiều nhất ở mỗi quận.
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
Kết quả đầu ra dự kiến:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
Các quận này khác nhau như thế nào?
county_max_lemma.groupby("lemma").size().to_pandas()
Kết quả đầu ra dự kiến:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
Ở hầu hết các quận, rượu whiskey là sản phẩm phổ biến nhất theo số lượng, còn rượu vodka phổ biến nhất ở 15 quận. Hãy so sánh điều này với các loại rượu phổ biến nhất trên toàn tiểu bang.
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
Kết quả đầu ra dự kiến:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
Rượu whisky và rượu vodka có thể tích gần bằng nhau, trong đó rượu vodka có thể tích cao hơn một chút so với rượu whisky trên toàn tiểu bang.
So sánh tỷ lệ
Điểm đặc biệt về doanh số bán hàng ở mỗi quận là gì? Điều gì khiến hạt này khác biệt so với phần còn lại của tiểu bang?
Sử dụng thước đo h của Cohen để tìm ra những lượng bán rượu có sự khác biệt lớn nhất so với lượng bán dự kiến dựa trên tỷ lệ bán hàng trên toàn tiểu bang.
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
Sau khi đo lường h của Cohen cho từng từ gốc, hãy tìm sự khác biệt lớn nhất so với tỷ lệ trên toàn tiểu bang ở mỗi quận.
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
Kết quả đầu ra dự kiến:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
Giá trị h của Cohen càng lớn thì càng có nhiều khả năng có sự khác biệt mang ý nghĩa thống kê về lượng đồ uống có cồn thuộc loại đó được tiêu thụ so với mức trung bình của tiểu bang. Đối với các giá trị dương nhỏ hơn, mức tiêu thụ có sự khác biệt so với mức trung bình của toàn tiểu bang, nhưng có thể là do sự khác biệt ngẫu nhiên.
Lưu ý: Quận EL PASO không phải là quận ở Iowa. Điều này có thể cho thấy bạn cần phải dọn dẹp dữ liệu trước khi hoàn toàn phụ thuộc vào những kết quả này.
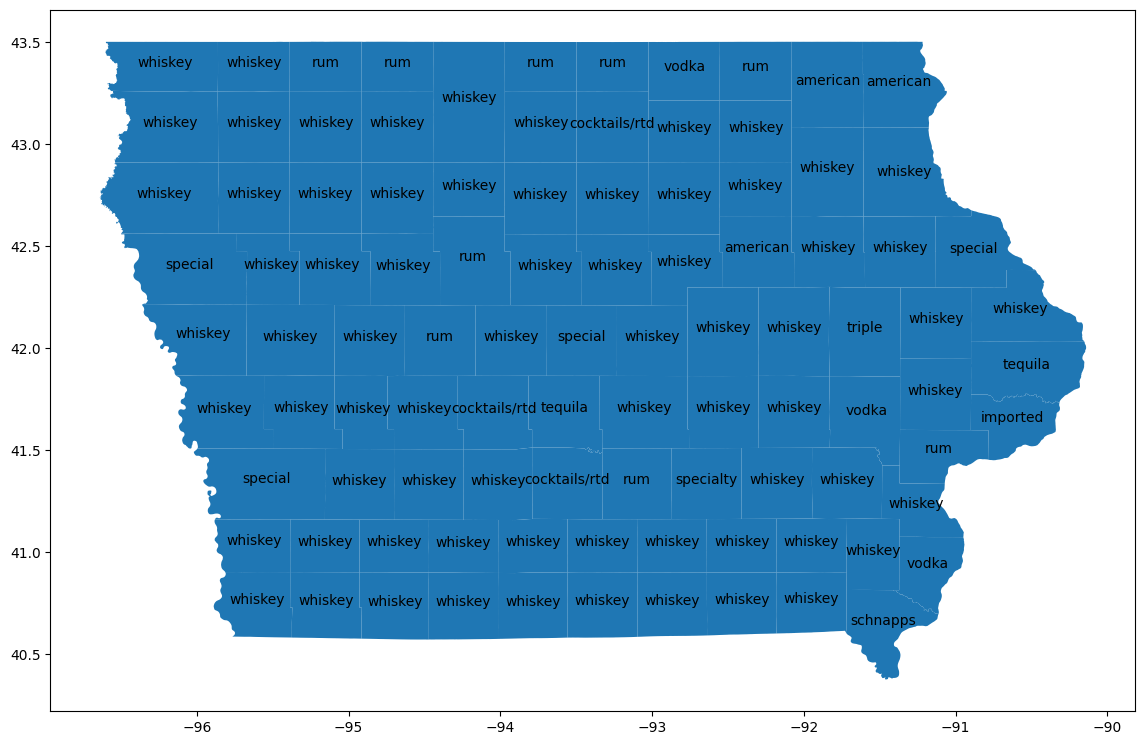
Trực quan hoá các hạt
Kết hợp với bảng bigquery-public-data.geo_us_boundaries.counties để lấy khu vực địa lý cho từng quận. Tên quận không phải là tên duy nhất ở Hoa Kỳ, vì vậy hãy lọc để chỉ bao gồm các quận ở Iowa. Mã FIPS của Iowa là "19".
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
Kết quả đầu ra dự kiến:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
Sử dụng GeoPandas để trực quan hoá những điểm khác biệt này trên bản đồ.
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)
9. Dọn dẹp
Nếu đã tạo một dự án trên đám mây mới trên Google Cloud cho hướng dẫn này, bạn có thể xoá dự án đó để tránh bị tính thêm phí cho các bảng hoặc tài nguyên khác đã tạo.
Hoặc xoá Cloud Functions, tài khoản dịch vụ và tập dữ liệu đã tạo cho hướng dẫn này.
10. Xin chúc mừng!
Bạn đã dọn dẹp và phân tích dữ liệu có cấu trúc bằng BigQuery DataFrames. Trong quá trình này, bạn đã khám phá Tập dữ liệu công khai của Google Cloud, sổ tay Python trong BigQuery Studio, BigQuery ML, BigQuery Remote Functions và sức mạnh của BigQuery DataFrames. Thật tuyệt vời!
Các bước tiếp theo
- Áp dụng các bước này cho những dữ liệu khác, chẳng hạn như cơ sở dữ liệu tên ở Hoa Kỳ.
- Hãy thử tạo mã Python trong sổ tay. Sổ tay Python trong BigQuery Studio được hỗ trợ bởi Colab Enterprise. Lưu ý: Tôi thấy việc yêu cầu Gemini giúp tạo dữ liệu kiểm thử khá hữu ích.
- Khám phá các sổ tay mẫu cho BigQuery DataFrames trên GitHub.
- Tạo lịch biểu để chạy sổ tay trong BigQuery Studio.
- Triển khai Hàm từ xa bằng BigQuery DataFrames để tích hợp các gói Python của bên thứ ba với BigQuery.