
1. Einführung
In diesem Lab lernen Sie, wie Sie BigQuery Machine Learning für Inferenzen mit Remote-Modellen ( Gemini-Modellen) verwenden, um Bilder von Filmplakaten zu analysieren und Zusammenfassungen der Filme basierend auf den Plakaten direkt in Ihrem BigQuery-Data Warehouse zu erstellen.

Oben abgebildet: Eine Auswahl der Filmplakate, die Sie analysieren werden.
BigQuery ist eine vollständig verwaltete, KI-fähige Datenanalyseplattform, mit der Sie die Wertschöpfung aus Daten maximieren können. Sie ist als Multi-Engine-, Multi-Format- und Multi-Cloud-Plattform konzipiert. Ein zentrales Feature ist BigQuery Machine Learning für Inferenzen. Damit können Sie ML-Modelle (Machine Learning) mithilfe von GoogleSQL-Abfragen erstellen und ausführen.
Gemini ist eine Reihe von auf generativer KI basierenden Modellen, die von Google entwickelt wurden und auf multimodale Anwendungsfälle ausgelegt sind.
ML-Modelle mit GoogleSQL-Abfragen ausführen
Normalerweise erfordert die Anwendung von ML oder künstlicher Intelligenz (KI) für große Datasets umfangreiche Programmier- und ML-Framework-Kenntnisse. Das beschränkt die Entwicklung von Lösungen in den meisten Unternehmen auf einen kleinen Personenkreis. Mit BigQuery Machine Learning für Inferenzen können SQL-Anwender vorhandene SQL-Tools und ‑Fertigkeiten nutzen, um Modelle zu erstellen und Ergebnisse aus LLMs und Cloud AI APIs zu generieren.
Voraussetzungen
- Grundlegende Kenntnisse der Google Cloud Console
- Erfahrung mit BigQuery ist ein Pluspunkt
Lerninhalte
- Umgebung und Konto für die Verwendung von APIs konfigurieren
- Cloud-Ressourcenverbindung in BigQuery erstellen
- Dataset und Objekttabelle in BigQuery für Bilder von Filmplakaten erstellen
- Gemini-Remote-Modelle in BigQuery erstellen
- Prompts an das Gemini-Modell senden, um für jedes Plakat eine Zusammenfassung des Films zu generieren
- Texteinbettungen für die auf den Plakaten abgebildeten Filme erstellen
- Mit BigQuery
VECTOR_SEARCHBilder von Filmplakaten mit ähnlichen Filmen im Dataset abgleichen
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt mit aktivierter Abrechnung
- Ein Webbrowser wie Chrome
2. Einrichtung und Anforderungen
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

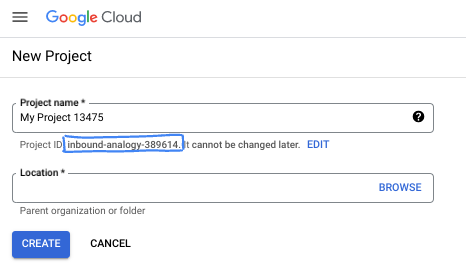
- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Es handelt sich um einen String, der nicht von Google APIs verwendet wird. Sie können sie jederzeit aktualisieren.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich (kann nach dem Festlegen nicht mehr geändert werden). In der Cloud Console wird automatisch ein eindeutiger String generiert. Normalerweise ist es nicht wichtig, wie dieser String aussieht. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie es mit einem eigenen Namen versuchen und sehen, ob er verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/-APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um Kosten zu vermeiden, die über diese Anleitung hinausgehen, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können am kostenlosen Testzeitraum mit einem Guthaben von 300$ teilnehmen.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:

Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Hinweis
Für die Arbeit mit Gemini-Modellen in BigQuery sind einige Einrichtungsschritte erforderlich, darunter das Aktivieren von APIs, das Erstellen einer Cloud-Ressourcenverbindung und das Erteilen bestimmter Berechtigungen für das Dienstkonto für die Cloud-Ressourcenverbindung. Diese Schritte sind einmalig pro Projekt und werden in den nächsten Abschnitten behandelt.
APIs aktivieren
Prüfen Sie in Cloud Shell, ob Ihre Projekt-ID eingerichtet ist:
gcloud config set project [YOUR-PROJECT-ID]
Legen Sie die Umgebungsvariable PROJECT_ID fest:
PROJECT_ID=$(gcloud config get-value project)
Konfigurieren Sie die Standardregion, die für die Vertex AI-Modelle verwendet werden soll. Weitere Informationen zu verfügbaren Standorten für Vertex AI In diesem Beispiel verwenden wir die Region us-central1.
gcloud config set compute/region us-central1
Legen Sie die Umgebungsvariable REGION fest:
REGION=$(gcloud config get-value compute/region)
Aktivieren Sie alle erforderlichen Dienste:
gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Erwartete Ausgabe nach Ausführung aller oben genannten Befehle:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Cloud-Ressourcenverbindung erstellen
In dieser Aufgabe erstellen Sie eine Cloud-Ressourcenverbindung, mit der BigQuery auf Bilddateien in Cloud Storage zugreifen und Vertex AI aufrufen kann.
- Klicken Sie in der Google Cloud Console im Navigationsmenü (
 ) auf BigQuery.
) auf BigQuery.
- Klicken Sie auf + HINZUFÜGEN und dann auf Verbindungen zu externen Datenquellen, um eine Verbindung zu erstellen.
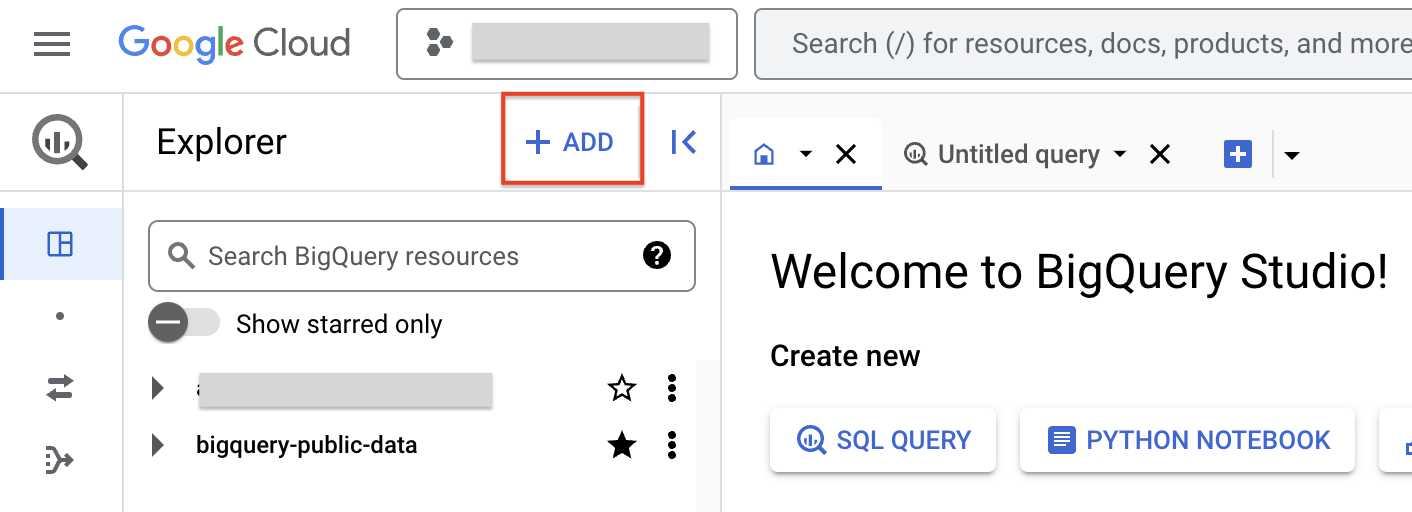
- Wählen Sie in der Liste „Verbindungstyp“ die Option Vertex AI-Remote-Modelle, Remote-Funktionen und BigLake (Cloud-Ressource) aus.
- Geben Sie für Ihre Verbindung im Feld „Verbindungs-ID“ gemini_conn ein.
- Wählen Sie als Standorttyp die Option Multiregional und dann USA (multiregional) aus.
- Verwenden Sie für die anderen Optionen jeweils die Standardeinstellung.
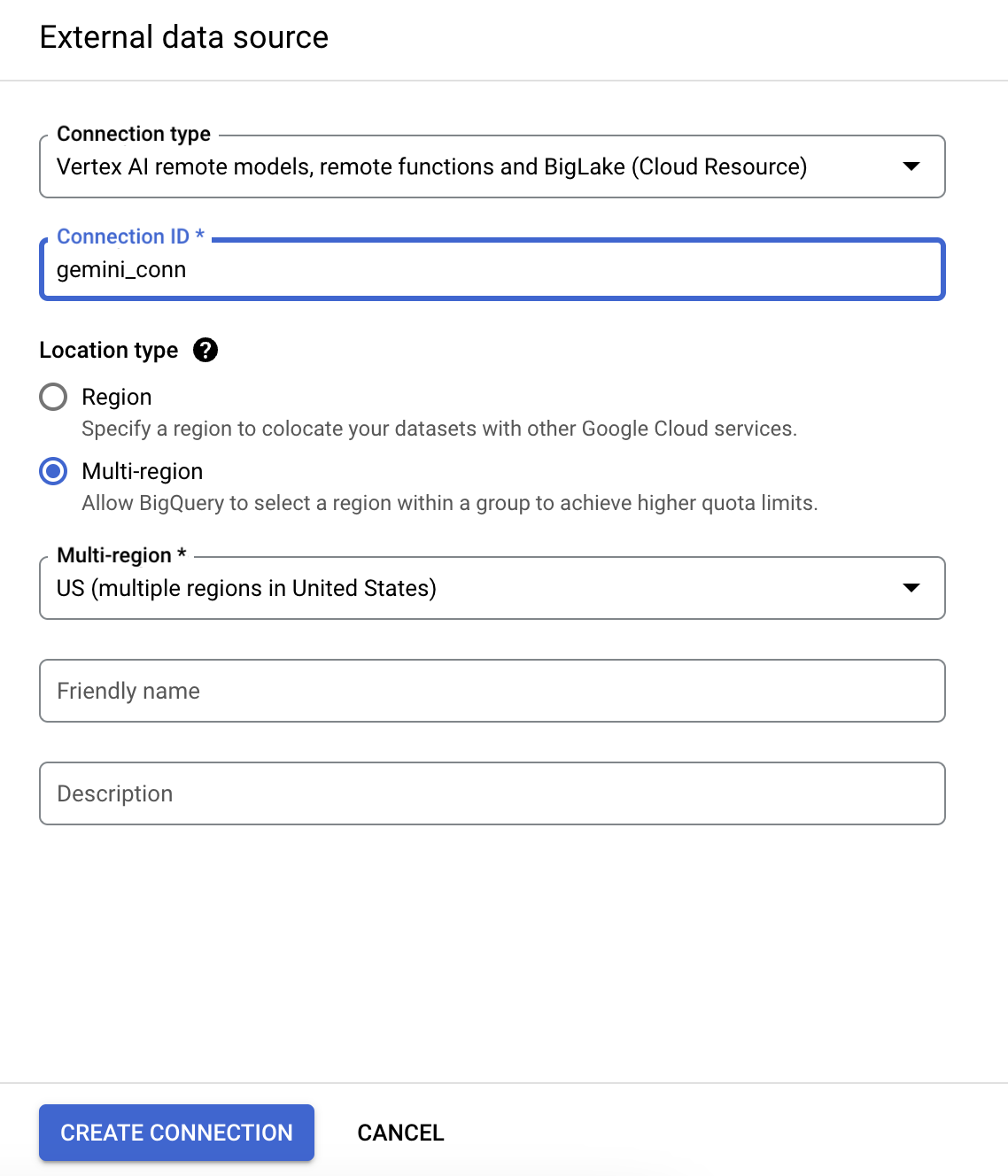
- Klicken Sie auf Verbindung erstellen.
- Klicken Sie auf ZUR VERBINDUNG.
- Kopieren Sie aus dem Bereich „Verbindungsinformationen“ die Dienstkonto-ID in eine Textdatei. Sie werden sie für die nächste Aufgabe benötigen. Die Verbindung ist ebenfalls im BigQuery Explorer Ihres Projekts im Abschnitt „Externe Verbindungen“ zu finden.
5. Dem Dienstkonto der Verbindung IAM-Berechtigungen gewähren
In dieser Aufgabe gewähren Sie dem Dienstkonto der Cloud-Ressourcenverbindung eine Rolle mit IAM-Berechtigungen, mit denen der Zugriff auf Vertex AI-Dienste möglich ist.
- Klicken Sie in der Google Cloud Console im Navigationsmenü auf IAM und Verwaltung.
- Klicken Sie auf Zugriff gewähren.
- Geben Sie im Feld Neue Hauptkonten die Dienstkonto-ID ein, die Sie zuvor kopiert haben.
- Wählen Sie im Feld „Rolle auswählen“ die Option Vertex AI und dann Vertex AI User aus.
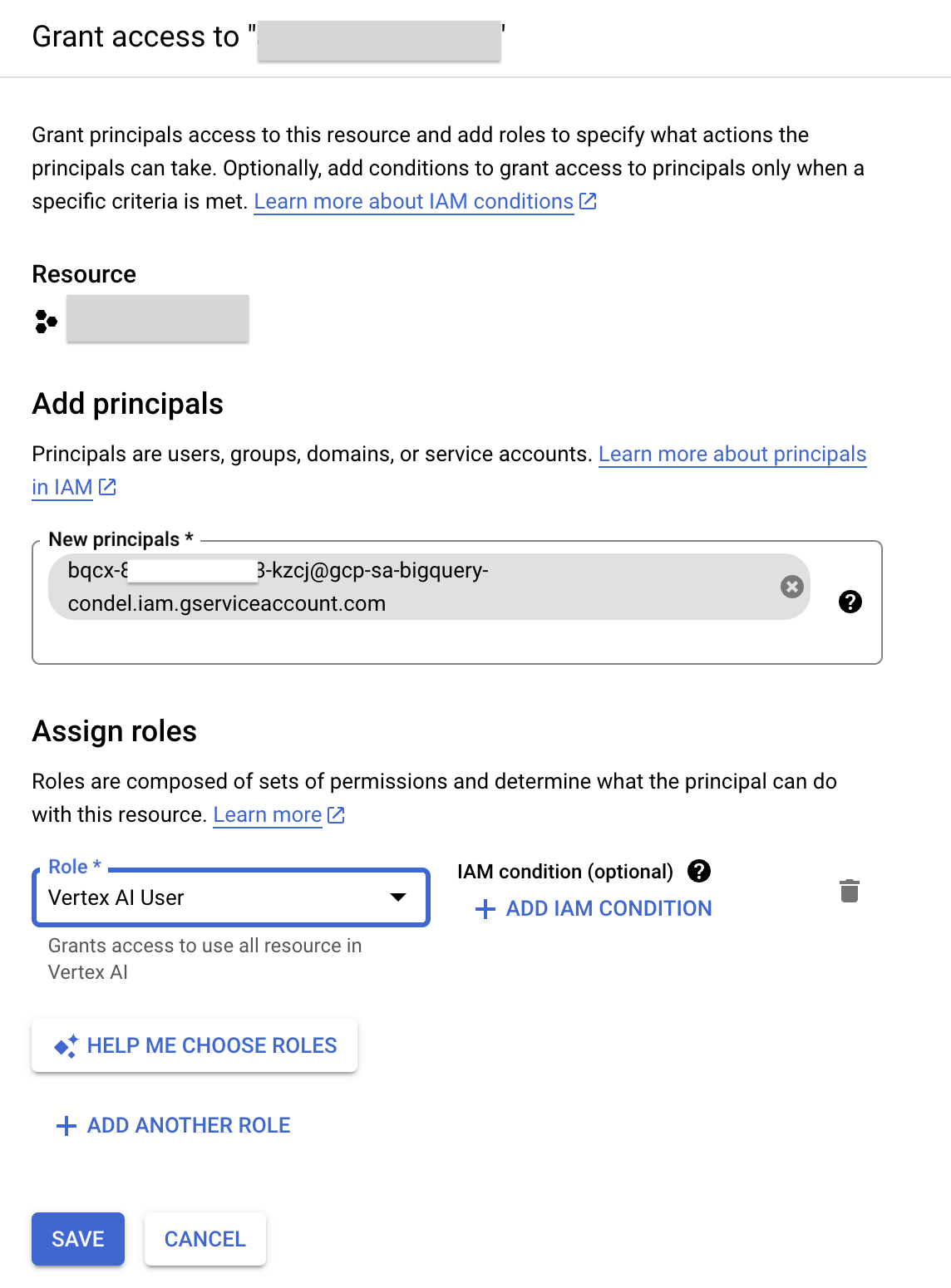
- Klicken Sie auf Speichern. Die Dienstkonto-ID beinhaltet nun die Rolle „Vertex AI User“.
6. Dataset und Objekttabelle in BigQuery für Bilder von Filmplakaten erstellen
In dieser Aufgabe erstellen Sie ein Dataset für das Projekt und eine Objekttabelle darin, um die Plakatbilder zu speichern.
Das in dieser Anleitung verwendete Dataset mit Filmposterbildern wird in einem öffentlichen Google Cloud Storage-Bucket gespeichert: gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters
Dataset erstellen
Sie erstellen ein Dataset, um Datenbankobjekte zu speichern, einschließlich Tabellen und Modelle, die in dieser Anleitung verwendet werden.
- Klicken Sie in der Google Cloud Console auf das Navigationsmenü ( ) und dann auf BigQuery.
- Wählen Sie im Bereich Explorer neben Ihrem Projektnamen die Option Aktionen ansehen (
 ) und dann Dataset erstellen aus.
) und dann Dataset erstellen aus. - Geben Sie im Bereich Dataset erstellen folgende Informationen ein:
- Dataset-ID: gemini_demo
- Wählen Sie als Standorttyp Mehrere Regionen aus.
- Multiregional: USA auswählen
- Übernehmen Sie für alle anderen Felder die Standardeinstellung.
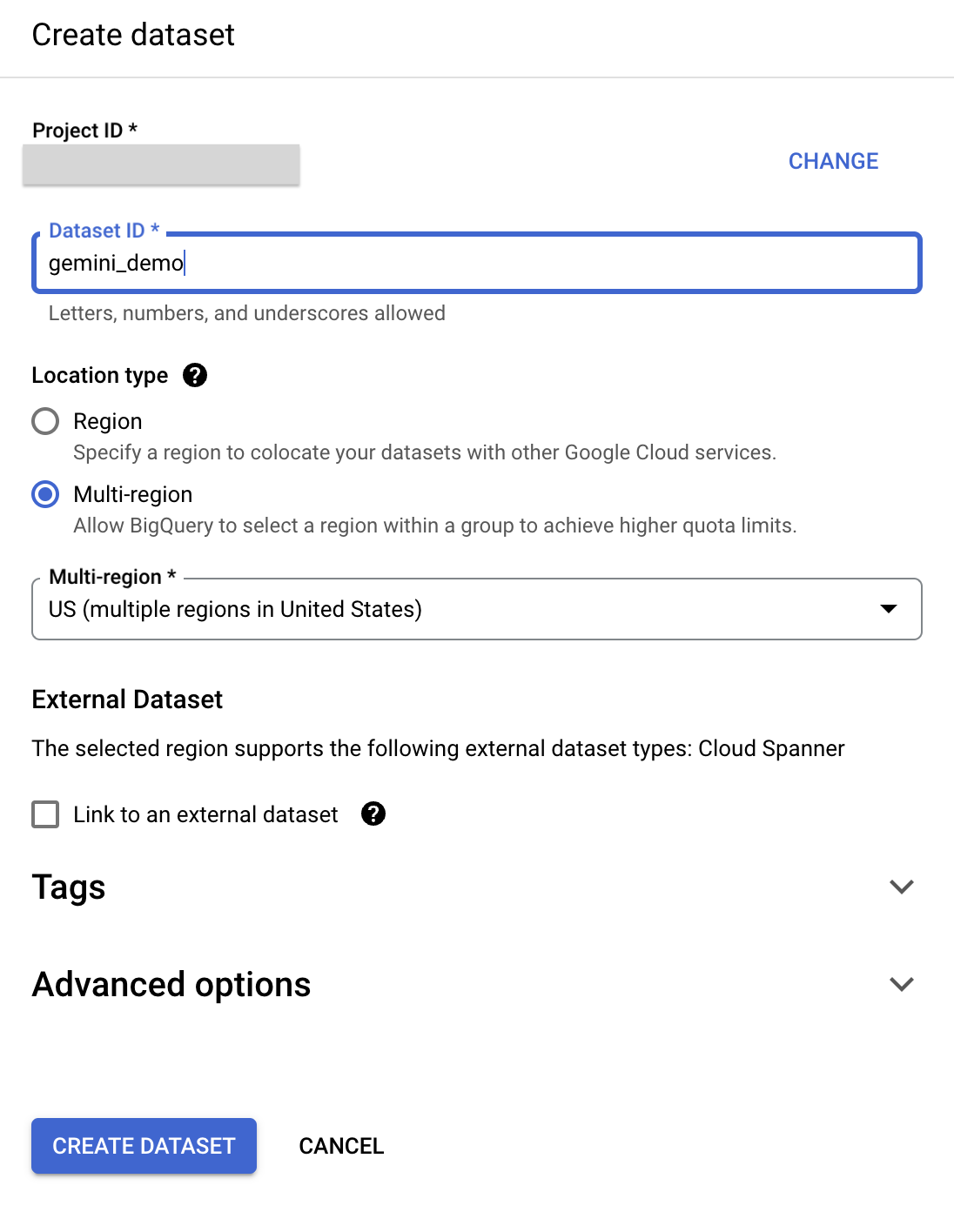
- Klicken Sie auf Dataset erstellen.
Das Dataset gemini_demo ist nun erstellt und wird im BigQuery Explorer unter Ihrem Projekt aufgeführt.
Objekttabelle erstellen
BigQuery enthält nicht nur strukturierte Daten, sondern kann über Objekttabellen auch auf unstrukturierte Daten wie die Posterbilder zugreifen.
Sie erstellen eine Objekttabelle, indem Sie auf einen Cloud Storage-Bucket verweisen. Die resultierende Objekttabelle enthält eine Zeile für jedes Objekt aus dem Bucket mit seinem Speicherpfad und seinen Metadaten.
Zum Erstellen der Objekttabelle verwenden Sie eine SQL-Abfrage.
- Klicken Sie auf das Symbol +, um eine neue SQL-Abfrage zu erstellen.
- Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrageeditor ein.
CREATE OR REPLACE EXTERNAL TABLE
`gemini_demo.movie_posters`
WITH CONNECTION `us.gemini_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters/*']
);
- Führen Sie die Abfrage aus. Die Objekttabelle
movie_posterswird dem Datasetgemini_demohinzugefügt und mit demURI(dem Cloud Storage-Speicherort) der Filmplakatbilder gefüllt. - Klicken Sie im Explorer auf
movie_postersund prüfen Sie das Schema und die Details. Sie können nun die Tabelle zur Prüfung einzelner Datensätze abfragen.
7. Gemini-Remote-Modell in BigQuery erstellen
Die Objekttabelle wurde erstellt und kann nun verwendet werden. In dieser Aufgabe erstellen Sie ein Remote-Modell für Gemini 1.5 Flash, um es in BigQuery verfügbar zu machen.
Gemini 1.5 Flash-Remote-Modell erstellen
- Klicken Sie auf das Symbol +, um eine neue SQL-Abfrage zu erstellen.
- Kopieren Sie die folgende Abfrage, fügen Sie sie in den Abfrageeditor ein und führen Sie sie aus.
CREATE OR REPLACE MODEL `gemini_demo.gemini_1_5_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'gemini-1.5-flash')
Das Modell gemini_1_5_flash ist nun erstellt und dem Dataset gemini_demo im Abschnitt „Modelle“ hinzugefügt.
- Klicken Sie im Explorer auf das Modell
gemini_1_5_flashund prüfen Sie die Details.
8. Prompts an Gemini-Modell senden, um für jedes Plakat eine Zusammenfassung des Films zu generieren
In dieser Aufgabe analysieren Sie mit dem gerade erstellten Gemini-Remote-Modell Bilder von Filmplakaten und generieren für jeden Film eine Zusammenfassung.
Sie können Anfragen an das Modell senden, indem Sie die Funktion ML.GENERATE_TEXT verwenden und im Parameter auf das Modell verweisen.
Bilder mit dem Gemini 1.5 Flash-Modell analysieren
- Erstellen Sie mit der folgenden SQL-Anweisung eine neue Abfrage und führen Sie sie aus:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results` AS (
SELECT
uri,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
TABLE `gemini_demo.movie_posters`,
STRUCT( 0.2 AS temperature,
'For the movie represented by this poster, what is the movie title and year of release? Answer in JSON format with two keys: title, year. title should be string, year should be integer. Do not use JSON decorators.' AS PROMPT,
TRUE AS FLATTEN_JSON_OUTPUT)));
Wenn die Abfrage ausgeführt wird, fordert BigQuery das Gemini-Modell für jede Zeile der Objekttabelle auf und kombiniert das Bild mit dem angegebenen statischen Prompt. Nun ist die Tabelle movie_posters_results erstellt.
- Sehen wir uns nun die Ergebnisse an. Erstellen Sie mit der folgenden SQL-Anweisung eine neue Abfrage und führen Sie sie aus:
SELECT * FROM `gemini_demo.movie_posters_results`
Es werden Zeilen für jedes Filmplakat mit dem URI (dem Cloud Storage-Speicherort des Filmplakatbilds) sowie einer JSON-Ausgabe mit dem Filmtitel und dem Jahr der Veröffentlichung des Films aus dem Gemini 1.5 Flash-Modell angezeigt.
Mit folgender Abfrage lassen sich die Ergebnisse in übersichtlicher Form darstellen. In dieser Abfrage wird SQL verwendet, um den Filmtitel und das Erscheinungsjahr aus diesen Antworten in neue Spalten zu extrahieren.
- Erstellen Sie mit der folgenden SQL-Anweisung eine neue Abfrage und führen Sie sie aus:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_formatted` AS (
SELECT
uri,
JSON_VALUE(ml_generate_text_llm_result, "$.title") AS title,
JSON_VALUE(ml_generate_text_llm_result, "$.year") AS year
FROM
`gemini_demo.movie_posters_results` results )
Nun ist die Tabelle movie_posters_result_formatted erstellt.
- Mit folgender Abfrage lassen sich die erstellten Tabellenreihen visualisieren.
SELECT * FROM `gemini_demo.movie_posters_results_formatted`
Beachten Sie, dass sich die ausgegebene URI-Spalte nicht verändert, die JSON-Ausgabe aber in die title- und year-Spalten konvertiert wird.
Prompts für Filmzusammenfassungen an das Gemini 1.5 Flash-Modell senden
Was wäre, wenn Sie etwas mehr Informationen zu jedem dieser Filme haben möchten, z. B. eine Textzusammenfassung? Dieser Anwendungsfall für die Inhaltsgenerierung eignet sich hervorragend für ein LLM-Modell wie Gemini 1.5 Flash.
- Mit Gemini 1.5 Flash können Sie für jedes Plakat eine Filmzusammenfassung bereitstellen. Führen Sie dazu die folgende Abfrage aus:
SELECT
uri,
title,
year,
prompt,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
(
SELECT
CONCAT('Provide a short summary of movie titled ',title, ' from the year ',year,'.') AS prompt,
uri,
title,
year
FROM
`gemini_demo.movie_posters_results_formatted`
LIMIT
20 ),
STRUCT(0.2 AS temperature,
TRUE AS FLATTEN_JSON_OUTPUT));
Beachten Sie das Feld ml_generate_text_llm_result in den Ergebnissen. Es enthält eine kurze Zusammenfassung des Films.
9. Texteinbettungen mit einem Remote-Modell generieren
Sie können die erstellten strukturierten Daten jetzt mit anderen strukturierten Daten in Ihrem Data Warehouse verknüpfen. Das öffentliche IMDB-Dataset, das in BigQuery verfügbar ist, enthält eine Vielzahl von Informationen zu Filmen, darunter Bewertungen von Zuschauern und einige Beispiele für Freiform-Nutzerrezensionen. Anhand dieser Daten können Sie Ihre Analyse der Filmposter vertiefen und nachvollziehen, wie diese Filme wahrgenommen wurden.
Zum Zusammenführen von Daten benötigen Sie einen Schlüssel. In diesem Fall stimmen die vom Gemini-Modell generierten Filmtitel möglicherweise nicht genau mit den Titeln im IMDb-Dataset überein.
In dieser Aufgabe generieren Sie Texteinbettungen der Filmtitel und ‑jahre aus beiden Datasets und verwenden dann den Abstand zwischen diesen Einbettungen, um den ähnlichsten IMDb-Titel mit den Filmtiteln aus Ihrem neu erstellten Dataset zu verknüpfen.
Remote-Modell erstellen
Zum Generieren der Texteinbettungen müssen Sie ein neues Remote-Modell erstellen, das auf den Endpunkt text-multilingual-embedding-002 verweist.
- Erstellen Sie mit der folgenden SQL-Anweisung eine neue Abfrage und führen Sie sie aus:
CREATE OR REPLACE MODEL `gemini_demo.text_embedding`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
Das Modell text_embedding ist nun erstellt und wird im Explorer unter dem Dataset gemini_demo angezeigt.
Texteinbettungen für den Titel und das Jahr der Plakate generieren
Sie verwenden dieses Remote-Modell jetzt mit der ML.GENERATE_EMBEDDING-Funktion, um für jeden Filmpostertitel und jedes Jahr ein Embedding zu erstellen.
- Erstellen Sie mit der folgenden SQL-Anweisung eine neue Abfrage und führen Sie sie aus:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
uri
FROM
`gemini_demo.movie_posters_results_formatted` ),
STRUCT(TRUE AS flatten_json_output)));
Als Ergebnis wird die Tabelle movie_poster_results_embeddings erstellt, die die Einbettungen für den verketteten Textinhalt für jede Zeile der Tabelle gemini_demo.movie_posters_results_formatted enthält.
- Die Ergebnisse der Abfrage können Sie mit der folgenden neuen Abfrage aufrufen:
SELECT * FROM `gemini_demo.movie_posters_results_embeddings`
Sie sehen die vom Modell generierten Einbettungen (Vektoren, die durch Zahlen dargestellt werden) für jeden Film.
Texteinbettungen für einen Teil des IMDb-Datasets generieren
Sie erstellen eine neue Ansicht mit Daten aus einem öffentlichen IMDb-Dataset, die nur die Filme enthält, die vor 1935 veröffentlicht wurden (dem bekannten Zeitraum der Filme auf den Posterbildern).
- Erstellen Sie mit der folgenden SQL-Anweisung eine neue Abfrage und führen Sie sie aus:
CREATE OR REPLACE VIEW
`gemini_demo.imdb_movies` AS (
WITH
reviews AS (
SELECT
reviews.movie_id AS movie_id,
title.primary_title AS title,
title.start_year AS year,
reviews.review AS review
FROM
`bigquery-public-data.imdb.reviews` reviews
LEFT JOIN
`bigquery-public-data.imdb.title_basics` title
ON
reviews.movie_id = title.tconst)
SELECT
DISTINCT(movie_id),
title,
year
FROM
reviews
WHERE
year < 1935)
Die neue Ansicht enthält eine Liste der Film-IDs, Titel und Veröffentlichungsjahre aus der Tabelle bigquery-public-data.imdb.reviews für alle Filme im Dataset, die vor 1935 veröffentlicht wurden.
- Jetzt erstellen Sie Einbettungen für die Teilmenge der Filme aus IMDB. Das Verfahren ist ähnlich wie im vorherigen Abschnitt. Erstellen Sie mit der folgenden SQL-Anweisung eine neue Abfrage und führen Sie sie aus:
CREATE OR REPLACE TABLE
`gemini_demo.imdb_movies_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING( MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
movie_id
FROM
`gemini_demo.imdb_movies` ),
STRUCT(TRUE AS flatten_json_output) )
WHERE
ml_generate_embedding_status = '' );
Die Abfrage liefert eine Tabelle, die die Einbettungen für den Textinhalt der Tabelle gemini_demo.imdb_movies enthält.
Filmposterbilder mithilfe von BigQuery VECTOR_SEARCH mit der IMDb-movie_id abgleichen
Jetzt können Sie die beiden Tabellen mit der Funktion VECTOR_SEARCH verknüpfen.
- Erstellen Sie mit der folgenden SQL-Anweisung eine neue Abfrage und führen Sie sie aus:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE');
In der Abfrage wird die Funktion VECTOR_SEARCH verwendet, um für jede Zeile in der Tabelle gemini_demo.movie_posters_results_embeddings den nächsten Nachbarn in der Tabelle gemini_demo.imdb_movies_embeddings zu finden. Der nächste Nachbar wird mithilfe des Kosinus-Abstandsmesswerts ermittelt, anhand dessen sich bestimmen lässt, wie ähnlich sich zwei Einbettungen sind.
Mit dieser Abfrage kann der ähnlichste Film im IMDb-Dataset für jeden der von Gemini 1.5 Flash in den Filmplakaten identifizierten Filme gefunden werden. Sie können beispielsweise die ähnlichste Entsprechung für den Film „Au Secours!“ im öffentlichen IMDb-Dataset finden, in dem dieser Film unter dem englischen Titel „Help!“ enthalten ist.
- Erstellen Sie eine neue Abfrage und führen Sie sie aus, um zusätzliche Informationen zu den Filmbewertungen aus dem öffentlichen IMDb-Dataset einzubinden:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance,
imdb.average_rating,
imdb.num_votes
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE') DATA
LEFT JOIN
`bigquery-public-data.imdb.title_ratings` imdb
ON
base.movie_id = imdb.tconst
ORDER BY
imdb.average_rating DESC
Diese Abfrage ähnelt der vorherigen. Auch hier werden spezielle numerische Darstellungen, sogenannte Vektoreinbettungen, dazu verwendet, Filme zu finden, die einem bestimmten Filmplakat ähneln. Es werden jedoch auch die durchschnittliche Bewertung und die Anzahl der Bewertungen für jeden als nächsten Nachbarn identifizierten Film aus einer separaten Tabelle des öffentlichen IMDb-Datasets hinzugefügt.
10. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs. Sie haben erfolgreich eine Objekttabelle für Ihre Posterbilder in BigQuery erstellt, ein Gemini-Remote-Modell erstellt, das Modell verwendet, um das Gemini-Modell aufzufordern, Bilder zu analysieren und Filminhaltsangaben bereitzustellen, Texteinbettungen für Filmtitel generiert und diese Einbettungen verwendet, um Bilder von Filmplakaten mit dem entsprechenden Filmtitel im IMDB-Dataset abzugleichen.
Behandelte Themen
- Umgebung und Konto für die Verwendung von APIs konfigurieren
- Cloud-Ressourcenverbindung in BigQuery erstellen
- Dataset und Objekttabelle in BigQuery für Bilder von Filmplakaten erstellen
- Gemini-Remote-Modelle in BigQuery erstellen
- Prompts an das Gemini-Modell senden, um für jedes Plakat eine Zusammenfassung des Films zu generieren
- Texteinbettungen für die auf den Plakaten abgebildeten Filme erstellen
- Mit BigQuery
VECTOR_SEARCHBilder von Filmplakaten mit ähnlichen Filmen im Dataset abgleichen
Weitere Informationen