
1. Wprowadzenie
W tym module dowiesz się, jak używać uczenia maszynowego w BigQuery do wnioskowania za pomocą modeli zdalnych ( modeli Gemini) w celu analizowania obrazów plakatów filmowych i generowania podsumowań filmów na podstawie plakatów bezpośrednio w hurtowni danych BigQuery.

Na zdjęciu powyżej: przykładowe obrazy plakatów filmowych, które będziesz analizować.
BigQuery to usługa w pełni zarządzana, platforma do analizy danych gotowa do współpracy z AI, która pomaga maksymalizować wartość danych i została zaprojektowana pod kątem obsługi wielu silników, formatów i chmur wielochmurowych. Jedną z jego kluczowych funkcji jest uczenie maszynowe w BigQuery do wnioskowania, które umożliwia tworzenie i uruchamianie modeli uczenia maszynowego za pomocą zapytań GoogleSQL.
Gemini to rodzina modeli generatywnej AI opracowanych przez Google, które są przeznaczone do zastosowań multimodalnych.
Uruchamianie modeli ML za pomocą zapytań GoogleSQL
Zazwyczaj wykonywanie uczenia maszynowego lub sztucznej inteligencji (AI) na dużych zbiorach danych wymaga rozbudowanego programowania i znajomości platform ML. Ogranicza to tworzenie rozwiązań do niewielkiej grupy specjalistów w każdej firmie. Dzięki uczeniu maszynowemu w BigQuery do wnioskowania użytkownicy SQL mogą używać dotychczasowych narzędzi i umiejętności SQL do tworzenia modeli oraz generowania wyników z modeli LLM i interfejsów Cloud AI API.
Wymagania wstępne
- Podstawowa znajomość konsoli Google Cloud
- Znajomość BigQuery będzie dodatkowym atutem.
Czego się nauczysz
- Jak skonfigurować środowisko i konto do korzystania z interfejsów API
- Jak utworzyć połączenie z zasobem Cloud w BigQuery
- Jak utworzyć zbiór danych i tabelę obiektów w BigQuery na potrzeby obrazów plakatów filmowych
- Jak utworzyć zdalne modele Gemini w BigQuery
- Jak poprosić model Gemini o podanie podsumowań filmów dla każdego plakatu
- Jak generować reprezentacje właściwościowe tekstu dla filmu przedstawionego na każdym plakacie
- Jak za pomocą BigQuery
VECTOR_SEARCHdopasować obrazy plakatów filmowych do powiązanych z nimi filmów w zbiorze danych
Czego potrzebujesz
- konto Google Cloud i projekt Google Cloud z włączonymi rozliczeniami;
- przeglądarka, np. Chrome;
2. Konfiguracja i wymagania
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.

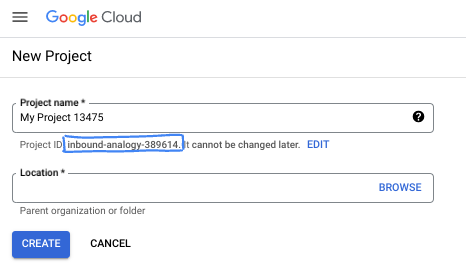
- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Jest to ciąg znaków, który nie jest używany przez interfejsy API Google. Zawsze możesz ją zaktualizować.
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Cloud automatycznie generuje unikalny ciąg znaków. Zwykle nie musisz się tym przejmować. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu (zwykle oznaczanego jako
PROJECT_ID). Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować inny losowy identyfikator. Możesz też spróbować własnej nazwy i sprawdzić, czy jest dostępna. Po tym kroku nie można go zmienić i pozostaje on taki przez cały czas trwania projektu. - Warto wiedzieć, że istnieje też trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
- Następnie musisz włączyć płatności w konsoli Cloud, aby korzystać z zasobów i interfejsów API Google Cloud. Wykonanie tego laboratorium nie będzie kosztować dużo, a może nawet nic. Aby wyłączyć zasoby i uniknąć naliczania opłat po zakończeniu tego samouczka, możesz usunąć utworzone zasoby lub projekt. Nowi użytkownicy Google Cloud mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym module praktycznym będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:

Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Zanim zaczniesz
Aby pracować z modelami Gemini w BigQuery, musisz wykonać kilka czynności konfiguracyjnych, m.in. włączyć interfejsy API, utworzyć połączenie z zasobem Cloud i przyznać kontu usługi połączenia z zasobem Cloud określone uprawnienia. Te czynności wykonuje się w projekcie tylko raz. Opisujemy je w kolejnych sekcjach.
włączyć interfejsy API,
W Cloud Shell sprawdź, czy identyfikator projektu jest skonfigurowany:
gcloud config set project [YOUR-PROJECT-ID]
Ustaw zmienną środowiskową PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Skonfiguruj domyślny region, który będzie używany w modelach Vertex AI. Więcej informacji o lokalizacjach, w których jest dostępna usługa Vertex AI W tym przykładzie używamy regionu us-central1.
gcloud config set compute/region us-central1
Ustaw zmienną środowiskową REGION:
REGION=$(gcloud config get-value compute/region)
Włącz wszystkie niezbędne usługi:
gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Oczekiwane dane wyjściowe po uruchomieniu wszystkich powyższych poleceń:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Tworzenie połączenia z zasobem Cloud
W tym zadaniu utworzysz połączenie z zasobem Cloud, które umożliwi BigQuery dostęp do plików obrazów w Cloud Storage i wykonywanie wywołań Vertex AI.
- W Menu nawigacyjnym (
 ) konsoli Google Cloud kliknij BigQuery.
) konsoli Google Cloud kliknij BigQuery.
- Aby utworzyć połączenie, kliknij + DODAJ, a potem Połączenia z zewnętrznymi źródłami danych.
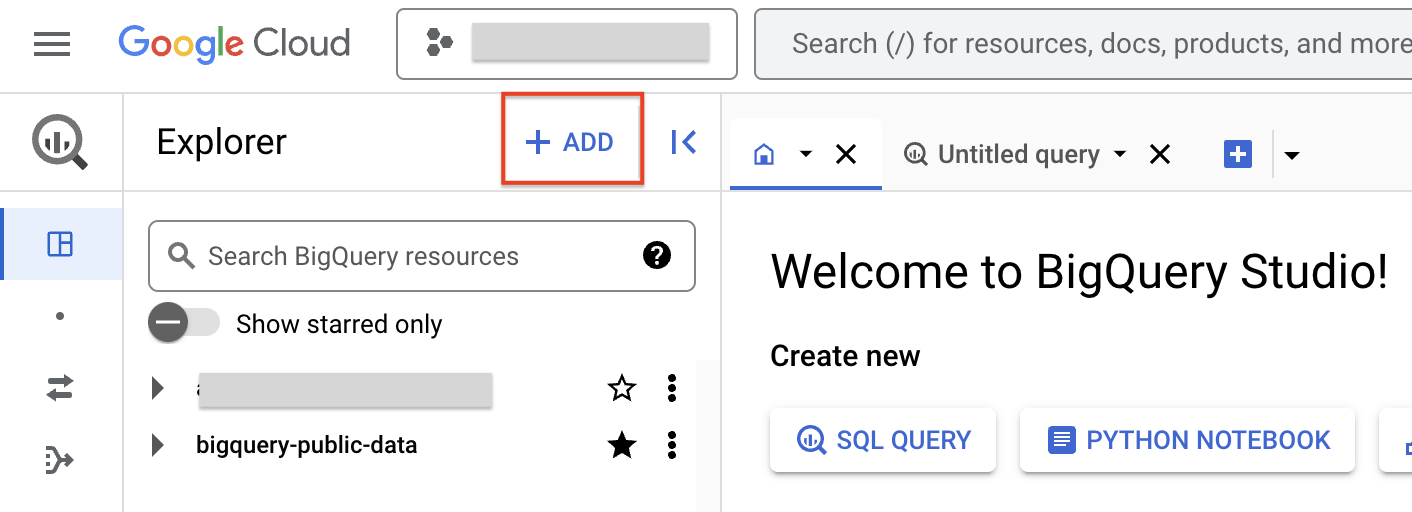
- Na liście Typ połączenia wybierz Modele zdalne Vertex AI, funkcje zdalne i BigLake (zasób Cloud).
- W polu Identyfikator połączenia wpisz gemini_conn.
- Jako Typ lokalizacji wybierz Wiele regionów, a następnie z menu wybierz US (wiele regionów).
- W pozostałych ustawieniach użyj wartości domyślnych.
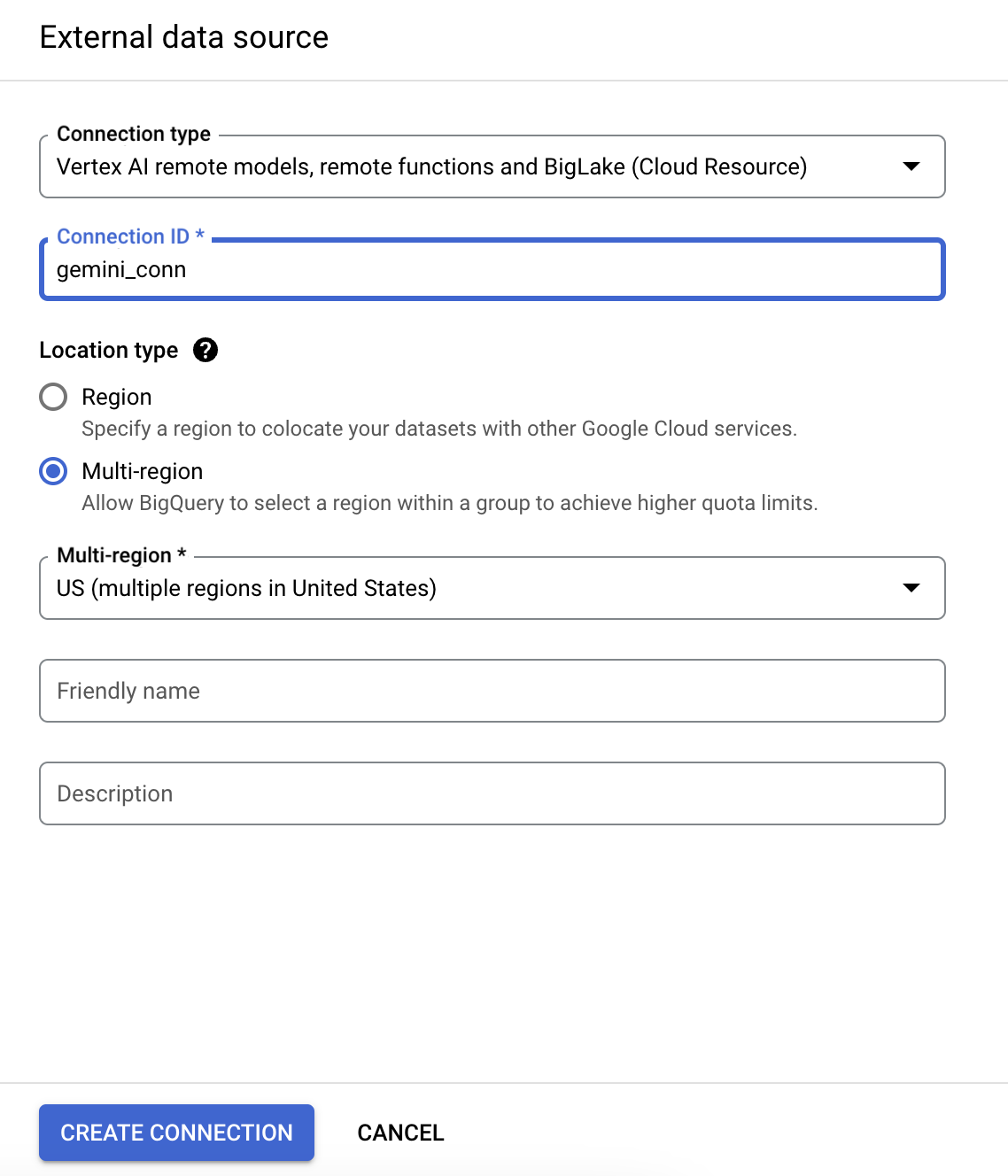
- Kliknij Utwórz połączenie.
- Kliknij PRZEJDŹ DO POŁĄCZENIA.
- W panelu Informacje o połączeniu skopiuj identyfikator konta usługi do pliku tekstowego, aby użyć go w następnym zadaniu. Zobaczysz też, że połączenie zostało dodane w sekcji Połączenia zewnętrzne w projekcie w Eksploratorze BigQuery.
5. Przyznawanie uprawnień IAM kontu usługi połączenia
W tym zadaniu przyznasz kontu usługi połączenia z zasobami w chmurze uprawnienia IAM za pomocą roli, aby umożliwić mu dostęp do usług Vertex AI.
- W konsoli Google Cloud w menu nawigacyjnym kliknij Uprawnienia i administracja.
- Kliknij Grant Access (Przyznaj dostęp).
- W polu Nowe podmioty zabezpieczeń wpisz skopiowany wcześniej identyfikator konta usługi.
- W polu Wybierz rolę wpisz Vertex AI, a następnie wybierz rolę Użytkownik Vertex AI.
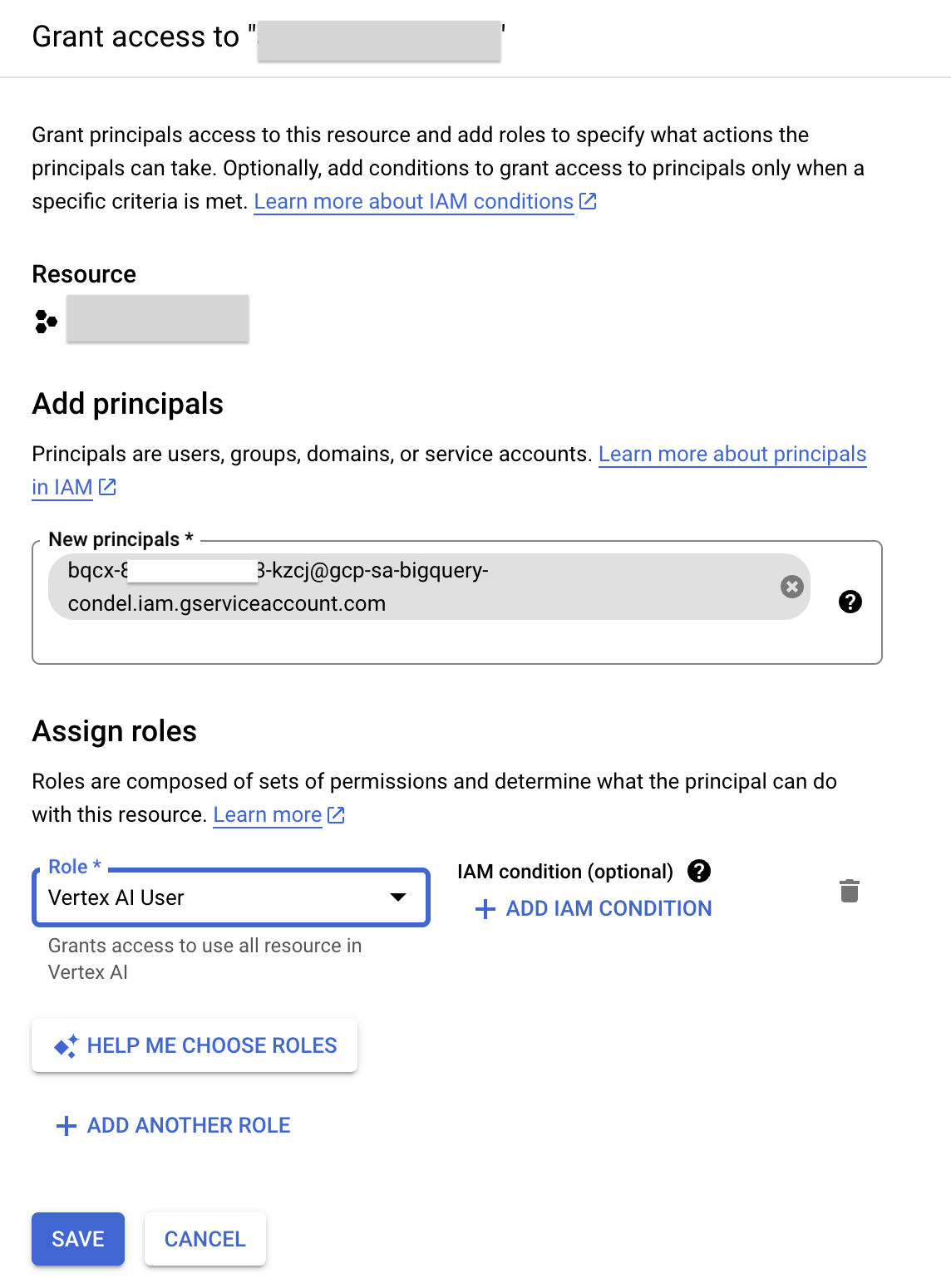
- Kliknij Zapisz. W rezultacie identyfikator konta usługi zawiera teraz rolę użytkownika Vertex AI.
6. Utwórz zbiór danych i tabelę obiektów w BigQuery na potrzeby obrazów plakatów filmowych.
W tym zadaniu utworzysz zbiór danych dla projektu i tabelę obiektów, w której będziesz przechowywać obrazy plakatów.
Zbiór danych z obrazami plakatów filmowych używany w tym samouczku jest przechowywany w publicznym zasobniku Cloud Storage: gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters
Tworzenie zbioru danych
Utworzysz zbiór danych do przechowywania obiektów bazy danych, w tym tabel i modeli, używanych w tym samouczku.
- W konsoli Google Cloud kliknij Menu nawigacyjne ( ), a następnie BigQuery.
- W panelu Eksplorator obok nazwy projektu kliknij Wyświetl działania (
 ), a następnie Utwórz zbiór danych.
), a następnie Utwórz zbiór danych. - W panelu Utwórz zbiór danych podaj te informacje:
- Identyfikator zbioru danych: gemini_demo
- Typ lokalizacji: wybierz Wiele regionów.
- Wiele regionów: wybierz Stany Zjednoczone.
- W pozostałych polach pozostaw wartości domyślne.
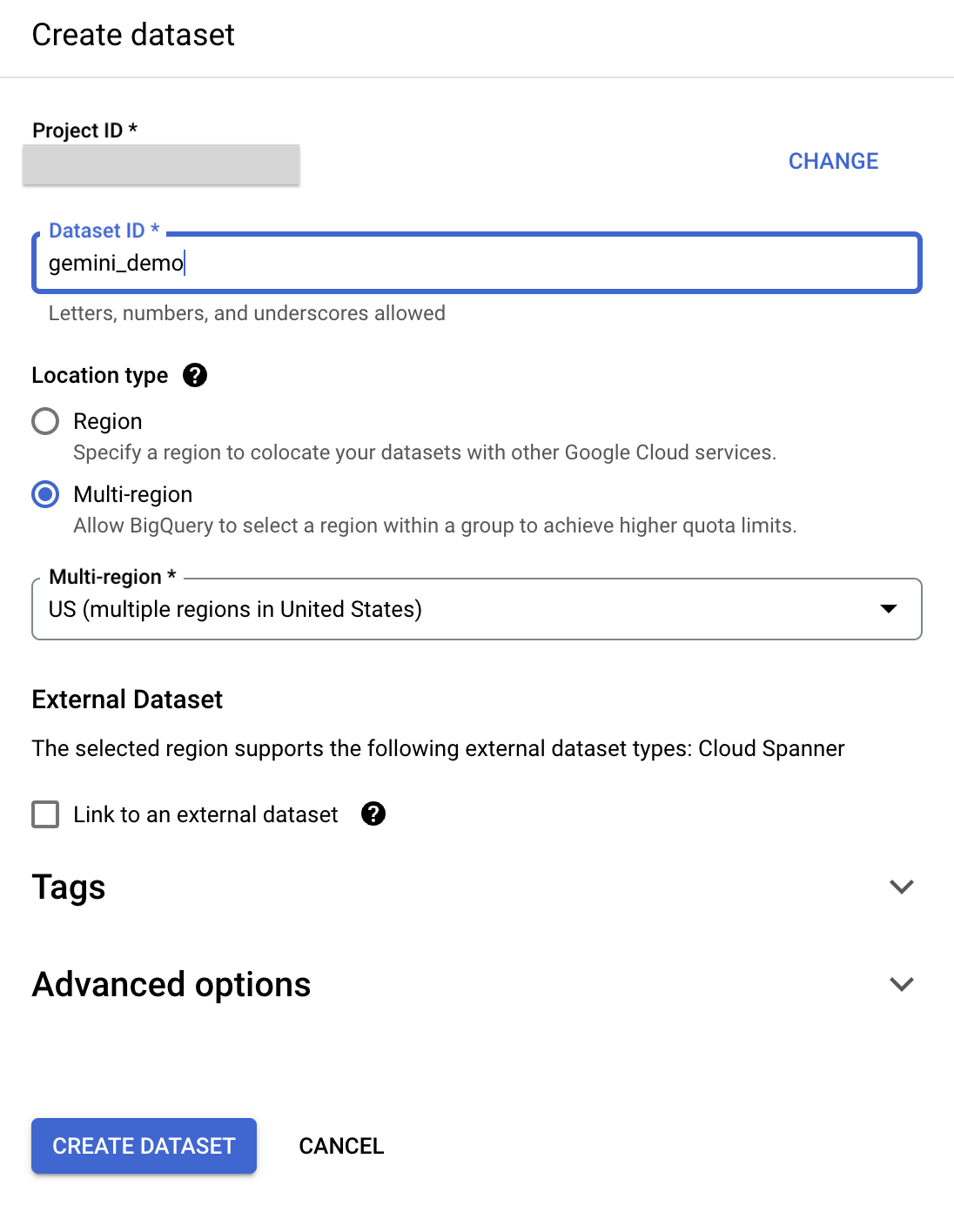
- Kliknij Utwórz zbiór danych.
W wyniku tego w Eksploratorze BigQuery pod Twoim projektem pojawi się zbiór danych gemini_demo.
Tworzenie tabeli obiektów
BigQuery przechowuje nie tylko dane strukturalne, ale też może uzyskiwać dostęp do danych nieustrukturyzowanych (takich jak obrazy plakatów) za pomocą tabel obiektów.
Tabelę obiektów tworzy się, wskazując zasobnik Cloud Storage. Wynikowa tabela obiektów zawiera wiersz dla każdego obiektu z zasobnika wraz ze ścieżką do niego i metadanymi.
Aby utworzyć tabelę obiektów, użyjesz zapytania SQL.
- Kliknij +, aby utworzyć nowe zapytanie SQL.
- W edytorze zapytań wklej zapytanie podane poniżej.
CREATE OR REPLACE EXTERNAL TABLE
`gemini_demo.movie_posters`
WITH CONNECTION `us.gemini_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters/*']
);
- Uruchom zapytanie. W rezultacie do zbioru danych
gemini_demozostanie dodana tabela obiektówmovie_posters, która będzie zawieraćURI(lokalizację w Cloud Storage) każdego obrazu plakatu filmowego. - W Eksploratorze kliknij
movie_postersi sprawdź schemat oraz szczegóły. Możesz wykonać zapytanie dotyczące tabeli, aby sprawdzić konkretne rekordy.
7. Tworzenie zdalnego modelu Gemini w BigQuery
Po utworzeniu tabeli obiektów możesz zacząć z nią pracować. W tym zadaniu utworzysz model zdalny dla Gemini 1.5 Flash, aby udostępnić go w BigQuery.
Utwórz zdalny model Gemini 1.5 Flash
- Kliknij +, aby utworzyć nowe zapytanie SQL.
- Wklej poniższe zapytanie do edytora zapytań i uruchom je.
CREATE OR REPLACE MODEL `gemini_demo.gemini_1_5_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'gemini-1.5-flash')
W wyniku tego zostanie utworzony model gemini_1_5_flash, który zobaczysz w sekcji modeli w zbiorze danych gemini_demo.
- W Eksploratorze kliknij model
gemini_1_5_flashi sprawdź szczegóły.
8. Poproś model Gemini o podanie podsumowań filmów dla każdego plakatu.
W tym zadaniu użyjesz utworzonego właśnie zdalnego modelu Gemini do analizowania obrazów plakatów filmowych i generowania podsumowań każdego filmu.
Możesz wysyłać żądania do modelu za pomocą funkcji ML.GENERATE_TEXT, odwołując się do modelu w parametrach.
Analizowanie obrazów za pomocą modelu Gemini 1.5 Flash
- Utwórz i uruchom nowe zapytanie za pomocą tej instrukcji SQL:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results` AS (
SELECT
uri,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
TABLE `gemini_demo.movie_posters`,
STRUCT( 0.2 AS temperature,
'For the movie represented by this poster, what is the movie title and year of release? Answer in JSON format with two keys: title, year. title should be string, year should be integer. Do not use JSON decorators.' AS PROMPT,
TRUE AS FLATTEN_JSON_OUTPUT)));
Gdy zapytanie zostanie uruchomione, BigQuery poprosi model Gemini o przetworzenie każdego wiersza tabeli obiektów, łącząc obraz z określonym statycznym promptem. W rezultacie movie_posters_results tabela zostanie utworzona.
- Zobaczmy teraz wyniki. Utwórz i uruchom nowe zapytanie za pomocą tej instrukcji SQL:
SELECT * FROM `gemini_demo.movie_posters_results`
Wynikiem są wiersze dla każdego plakatu filmowego z wartością URI (lokalizacja obrazu plakatu filmowego w Cloud Storage) oraz wynik w formacie JSON zawierający tytuł filmu i rok jego premiery uzyskany z modelu Gemini 1.5 Flash.
Wyniki te możesz pobrać w bardziej czytelny sposób, używając następującego zapytania. To zapytanie używa SQL do wyodrębniania tytułu filmu i roku premiery z tych odpowiedzi do nowych kolumn.
- Utwórz i uruchom nowe zapytanie za pomocą tej instrukcji SQL:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_formatted` AS (
SELECT
uri,
JSON_VALUE(ml_generate_text_llm_result, "$.title") AS title,
JSON_VALUE(ml_generate_text_llm_result, "$.year") AS year
FROM
`gemini_demo.movie_posters_results` results )
W rezultacie movie_posters_result_formatted tabela zostanie utworzona.
- Aby wyświetlić utworzone wiersze, możesz wysłać do tabeli to zapytanie:
SELECT * FROM `gemini_demo.movie_posters_results_formatted`
Zwróć uwagę, że wyniki w kolumnie URI pozostają takie same, ale JSON jest teraz przekształcany w kolumny title i year w przypadku każdego wiersza.
Poproś model Gemini 1.5 Flash o podsumowania filmów
A co, jeśli chcesz dowiedzieć się więcej o każdym z tych filmów, np. przeczytać ich podsumowanie? Ten przypadek użycia generowania treści idealnie nadaje się do modelu LLM, takiego jak Gemini 1.5 Flash.
- Aby uzyskać podsumowania filmów dla każdego plakatu, możesz użyć modelu Gemini 1.5 Flash i uruchomić to zapytanie:
SELECT
uri,
title,
year,
prompt,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
(
SELECT
CONCAT('Provide a short summary of movie titled ',title, ' from the year ',year,'.') AS prompt,
uri,
title,
year
FROM
`gemini_demo.movie_posters_results_formatted`
LIMIT
20 ),
STRUCT(0.2 AS temperature,
TRUE AS FLATTEN_JSON_OUTPUT));
Zwróć uwagę na pole ml_generate_text_llm_result w wynikach. Zawiera ono krótkie podsumowanie filmu.
9. Generowanie wektorów dystrybucyjnych tekstu za pomocą modelu zdalnego
Możesz teraz połączyć utworzone przez siebie dane strukturalne z innymi danymi strukturalnymi w swoim magazynie. Publiczny zbiór danych IMDB dostępny w BigQuery zawiera wiele informacji o filmach, w tym oceny widzów i przykładowe recenzje użytkowników w formie swobodnej. Te dane mogą pomóc w pogłębieniu analizy plakatów filmowych i zrozumieniu, jak te filmy były odbierane.
Aby połączyć dane, musisz mieć klucz. W takim przypadku tytuły filmów wygenerowane przez model Gemini mogą nie pasować idealnie do tytułów w zbiorze danych IMDB.
W tym zadaniu wygenerujesz wektory tekstu tytułów filmów i lat z obu zbiorów danych, a następnie użyjesz odległości między tymi wektorami, aby połączyć najbliższy tytuł z IMDb z tytułami plakatów filmowych z nowo utworzonego zbioru danych.
Tworzenie modelu zdalnego
Aby wygenerować wektory tekstu, musisz utworzyć nowy model zdalny wskazujący punkt końcowy text-multilingual-embedding-002.
- Utwórz i uruchom nowe zapytanie za pomocą tej instrukcji SQL:
CREATE OR REPLACE MODEL `gemini_demo.text_embedding`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
W wyniku tego zostanie utworzony model text_embedding, który pojawi się w eksploratorze pod zbiorem danych gemini_demo.
Generowanie wektorów tekstowych dla tytułu i roku powiązanych z plakatami
Teraz użyjesz tego modelu zdalnego z ML.GENERATE_EMBEDDING funkcją, aby utworzyć osadzenie dla każdego tytułu plakatu filmowego i roku.
- Utwórz i uruchom nowe zapytanie za pomocą tej instrukcji SQL:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
uri
FROM
`gemini_demo.movie_posters_results_formatted` ),
STRUCT(TRUE AS flatten_json_output)));
W wyniku tego powstaje tabela movie_poster_results_embeddings zawierająca wektory osadzeń dla treści tekstowych połączonych w każdym wierszu tabeli gemini_demo.movie_posters_results_formatted.
- Wyniki zapytania możesz wyświetlić za pomocą tego nowego zapytania:
SELECT * FROM `gemini_demo.movie_posters_results_embeddings`
W tym miejscu zobaczysz wektory dystrybucyjne (wektory reprezentowane przez liczby) wygenerowane przez model dla każdego filmu.
Generowanie osadzeń tekstu dla podzbioru zbioru danych IMDB
Utworzysz nowy widok danych z publicznego zbioru danych IMDB, który zawiera tylko filmy wydane przed 1935 rokiem (znany okres, z którego pochodzą filmy z plakatów).
- Utwórz i uruchom nowe zapytanie za pomocą tej instrukcji SQL:
CREATE OR REPLACE VIEW
`gemini_demo.imdb_movies` AS (
WITH
reviews AS (
SELECT
reviews.movie_id AS movie_id,
title.primary_title AS title,
title.start_year AS year,
reviews.review AS review
FROM
`bigquery-public-data.imdb.reviews` reviews
LEFT JOIN
`bigquery-public-data.imdb.title_basics` title
ON
reviews.movie_id = title.tconst)
SELECT
DISTINCT(movie_id),
title,
year
FROM
reviews
WHERE
year < 1935)
W wyniku tego powstanie nowy widok zawierający listę unikalnych identyfikatorów filmów, tytułów i lat premiery z tabeli bigquery-public-data.imdb.reviews dla wszystkich filmów w zbiorze danych wydanych przed 1935 rokiem.
- Teraz utworzysz wektory osadzeń dla podzbioru filmów z IMDB, stosując podobny proces jak w poprzedniej sekcji. Utwórz i uruchom nowe zapytanie za pomocą tej instrukcji SQL:
CREATE OR REPLACE TABLE
`gemini_demo.imdb_movies_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING( MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
movie_id
FROM
`gemini_demo.imdb_movies` ),
STRUCT(TRUE AS flatten_json_output) )
WHERE
ml_generate_embedding_status = '' );
Wynikiem zapytania jest tabela zawierająca wektory osadzenia dla treści tekstowej tabeli gemini_demo.imdb_movies.
Dopasowywanie obrazów plakatów filmowych do IMDB movie_id za pomocą BigQuery VECTOR_SEARCH
Teraz możesz złączyć te dwie tabele za pomocą funkcji VECTOR_SEARCH.
- Utwórz i uruchom nowe zapytanie za pomocą tej instrukcji SQL:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE');
Zapytanie używa funkcji VECTOR_SEARCH, aby znaleźć najbliższego sąsiada w tabeli gemini_demo.imdb_movies_embeddings dla każdego wiersza w tabeli gemini_demo.movie_posters_results_embeddings. Najbliższy sąsiad jest znajdowany przy użyciu miary odległości cosinusowej, która określa podobieństwo 2 wektorów dystrybucyjnych.
To zapytanie może służyć do znajdowania najbardziej podobnego filmu w zbiorze danych IMDB dla każdego filmu zidentyfikowanego przez Gemini 1.5 Flash na plakatach filmowych. Możesz na przykład użyć tego zapytania, aby znaleźć najbliższe dopasowanie do filmu „Au Secours!” w publicznym zbiorze danych IMDB, który odwołuje się do tego filmu pod angielskim tytułem „Help!”.
- Utwórz i wykonaj nowe zapytanie, aby złączyć dodatkowe informacje o ocenach filmów udostępnione w publicznym zbiorze danych IMDB:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance,
imdb.average_rating,
imdb.num_votes
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE') DATA
LEFT JOIN
`bigquery-public-data.imdb.title_ratings` imdb
ON
base.movie_id = imdb.tconst
ORDER BY
imdb.average_rating DESC
To zapytanie jest podobne do poprzedniego. Nadal używa specjalnych reprezentacji numerycznych zwanych osadzaniem wektorowym, aby znajdować filmy podobne do danego plakatu. Łączy też średnią ocenę i liczbę głosów oddanych na każdy z najbliższych filmów z osobnej tabeli z publicznego zbioru danych IMDB.
10. Gratulacje
Gratulujemy ukończenia ćwiczenia. Udało Ci się utworzyć tabelę obiektów dla obrazów plakatów w BigQuery, utworzyć zdalny model Gemini, użyć go do analizowania obrazów i podawania podsumowań filmów, wygenerować osadzanie tekstu dla tytułów filmów i użyć tych osadzania do dopasowania obrazów plakatów filmowych do powiązanych tytułów filmów w zbiorze danych IMDB.
Omówione zagadnienia
- Jak skonfigurować środowisko i konto do korzystania z interfejsów API
- Jak utworzyć połączenie z zasobem Cloud w BigQuery
- Jak utworzyć zbiór danych i tabelę obiektów w BigQuery na potrzeby obrazów plakatów filmowych
- Jak utworzyć zdalne modele Gemini w BigQuery
- Jak poprosić model Gemini o podanie podsumowań filmów dla każdego plakatu
- Jak generować reprezentacje właściwościowe tekstu dla filmu przedstawionego na każdym plakacie
- Jak za pomocą BigQuery
VECTOR_SEARCHdopasować obrazy plakatów filmowych do powiązanych z nimi filmów w zbiorze danych
Dalsze kroki / Więcej informacji