
1. Giới thiệu
Trong phòng thí nghiệm này, bạn sẽ tìm hiểu cách sử dụng BigQuery Machine Learning để suy luận bằng các mô hình từ xa ( mô hình Gemini) nhằm phân tích hình ảnh áp phích phim và tạo bản tóm tắt về các bộ phim dựa trên áp phích ngay trong kho dữ liệu BigQuery.

Hình ảnh ở trên: Một mẫu hình ảnh áp phích phim mà bạn sẽ phân tích.
BigQuery là một nền tảng phân tích dữ liệu hoàn toàn được quản lý và sẵn sàng sử dụng AI, giúp bạn tối đa hoá giá trị từ dữ liệu của mình và được thiết kế để hỗ trợ nhiều công cụ, nhiều định dạng và nhiều đám mây. Một trong những tính năng chính của BigQuery là BigQuery Machine Learning để suy luận, cho phép bạn tạo và chạy các mô hình học máy (ML) bằng cách sử dụng các truy vấn GoogleSQL.
Gemini là một nhóm các mô hình AI tạo sinh do Google phát triển và được thiết kế cho các trường hợp sử dụng đa phương thức.
Chạy các mô hình học máy bằng cách sử dụng truy vấn GoogleSQL
Thông thường, việc thực hiện học máy (ML) hoặc trí tuệ nhân tạo (AI) trên các tập dữ liệu lớn đòi hỏi khả năng lập trình và kiến thức sâu rộng về các khung ML. Điều này giới hạn việc phát triển giải pháp cho một nhóm nhỏ chuyên gia trong mỗi công ty. Với công nghệ học máy của BigQuery để suy luận, chuyên viên SQL có thể sử dụng các công cụ và kỹ năng hiện có liên quan đến SQL để xây dựng mô hình, cũng như tạo kết quả từ các mô hình ngôn ngữ lớn và Cloud AI API.
Điều kiện tiên quyết
- Có kiến thức cơ bản về Google Cloud Console
- Có kinh nghiệm sử dụng BigQuery là một điểm cộng
Kiến thức bạn sẽ học được
- Cách định cấu hình môi trường và tài khoản để sử dụng API
- Cách tạo mối kết nối Tài nguyên trên đám mây trong BigQuery
- Cách tạo tập dữ liệu và bảng đối tượng trong BigQuery cho hình ảnh áp phích phim
- Cách tạo các mô hình từ xa của Gemini trong BigQuery
- Cách đưa ra câu lệnh cho mô hình Gemini để cung cấp bản tóm tắt phim cho từng áp phích
- Cách tạo vectơ nhúng văn bản cho bộ phim xuất hiện trong mỗi áp phích
- Cách sử dụng BigQuery
VECTOR_SEARCHđể so khớp hình ảnh áp phích phim với những bộ phim có liên quan chặt chẽ trong tập dữ liệu
Bạn cần có
- Một Tài khoản Google Cloud và Dự án Google Cloud đã bật tính năng thanh toán
- Một trình duyệt web như Chrome
2. Thiết lập và yêu cầu
Thiết lập môi trường theo tốc độ của riêng bạn
- Đăng nhập vào Google Cloud Console rồi tạo một dự án mới hoặc sử dụng lại một dự án hiện có. Nếu chưa có tài khoản Gmail hoặc Google Workspace, bạn phải tạo một tài khoản.

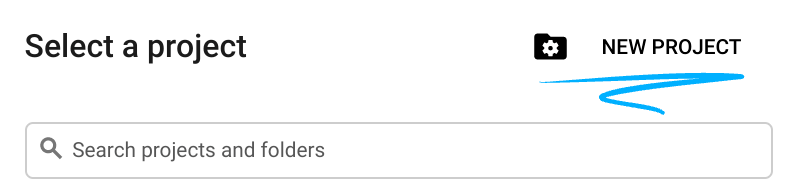
- Tên dự án là tên hiển thị của những người tham gia dự án này. Đây là một chuỗi ký tự mà các API của Google không sử dụng. Bạn luôn có thể cập nhật thông tin này.
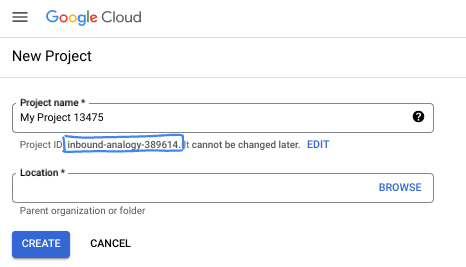
- Mã dự án là mã duy nhất trên tất cả các dự án trên Google Cloud và không thể thay đổi (bạn không thể thay đổi mã này sau khi đã đặt). Cloud Console sẽ tự động tạo một chuỗi duy nhất; thường thì bạn không cần quan tâm đến chuỗi này. Trong hầu hết các lớp học lập trình, bạn sẽ cần tham chiếu đến Mã dự án (thường được xác định là
PROJECT_ID). Nếu không thích mã nhận dạng được tạo, bạn có thể tạo một mã nhận dạng ngẫu nhiên khác. Hoặc bạn có thể thử tên người dùng của riêng mình để xem tên đó có được chấp nhận hay không. Bạn không thể thay đổi tên này sau bước này và tên này sẽ tồn tại trong suốt thời gian của dự án. - Để bạn nắm được thông tin, có một giá trị thứ ba là Số dự án mà một số API sử dụng. Tìm hiểu thêm về cả 3 giá trị này trong tài liệu.
- Tiếp theo, bạn cần bật tính năng thanh toán trong Cloud Console để sử dụng các tài nguyên/API trên đám mây. Việc thực hiện lớp học lập trình này sẽ không tốn nhiều chi phí, nếu có. Để tắt các tài nguyên nhằm tránh bị tính phí ngoài phạm vi hướng dẫn này, bạn có thể xoá các tài nguyên đã tạo hoặc xoá dự án. Người dùng mới của Google Cloud đủ điều kiện tham gia chương trình Dùng thử miễn phí trị giá 300 USD.
Khởi động Cloud Shell
Mặc dù có thể vận hành Google Cloud từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, bạn sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trên Cloud.
Trên Bảng điều khiển Google Cloud, hãy nhấp vào biểu tượng Cloud Shell trên thanh công cụ ở trên cùng bên phải:

Quá trình này chỉ mất vài phút để cung cấp và kết nối với môi trường. Khi quá trình này kết thúc, bạn sẽ thấy như sau:

Máy ảo này được trang bị tất cả các công cụ phát triển mà bạn cần. Nó cung cấp một thư mục chính có dung lượng 5 GB và chạy trên Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và hoạt động xác thực. Bạn có thể thực hiện mọi thao tác trong lớp học lập trình này trong trình duyệt. Bạn không cần cài đặt bất cứ thứ gì.
3. Trước khi bắt đầu
Có một số bước thiết lập để làm việc với các mô hình Gemini trong BigQuery, bao gồm cả việc bật API, tạo mối kết nối tài nguyên trên Cloud và cấp cho tài khoản dịch vụ của mối kết nối tài nguyên trên Cloud một số quyền nhất định. Bạn chỉ cần thực hiện các bước này một lần cho mỗi dự án và chúng tôi sẽ đề cập đến các bước này trong một vài phần tiếp theo.
Cho phép API
Trong Cloud Shell, hãy đảm bảo bạn đã thiết lập mã dự án:
gcloud config set project [YOUR-PROJECT-ID]
Đặt biến môi trường PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Định cấu hình khu vực mặc định để sử dụng cho các mô hình Vertex AI. Đọc thêm về các địa điểm có cung cấp Vertex AI. Trong ví dụ này, chúng ta đang sử dụng khu vực us-central1.
gcloud config set compute/region us-central1
Đặt biến môi trường REGION:
REGION=$(gcloud config get-value compute/region)
Bật tất cả các dịch vụ cần thiết:
gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Kết quả dự kiến sau khi chạy tất cả các lệnh trên:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Tạo mối kết nối Tài nguyên trên đám mây
Trong nhiệm vụ này, bạn sẽ tạo một kết nối Tài nguyên trên đám mây, cho phép BigQuery truy cập vào các tệp hình ảnh trong Cloud Storage và thực hiện các lệnh gọi đến Vertex AI.
- Trong Google Cloud Console, trên Trình đơn điều hướng (
 ), hãy nhấp vào BigQuery.
), hãy nhấp vào BigQuery.
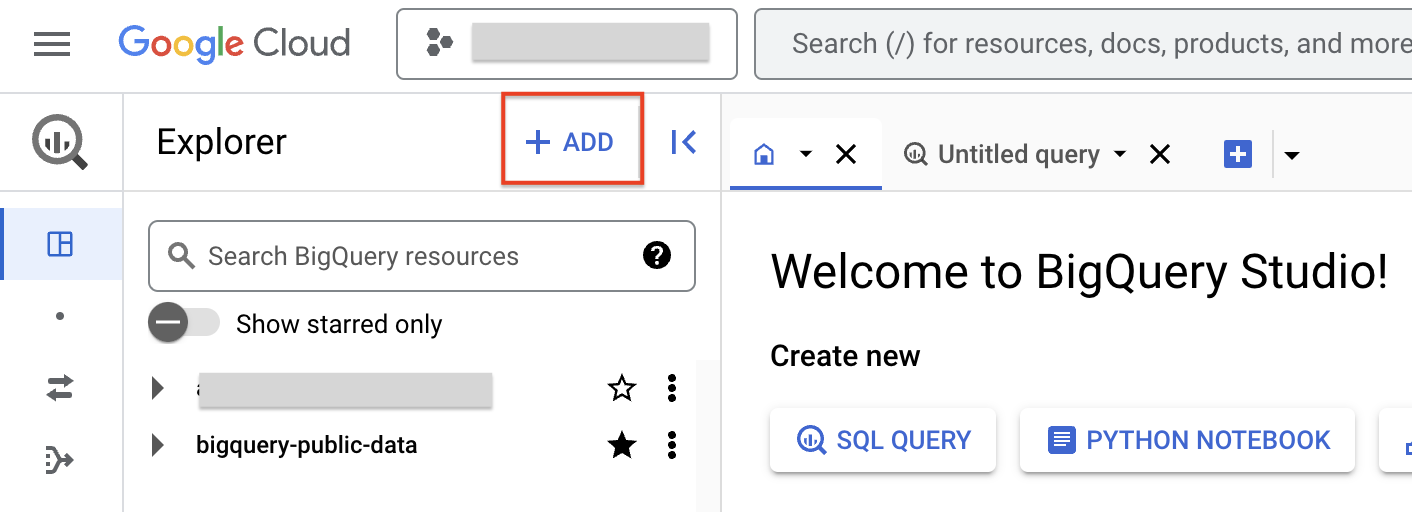
- Để tạo mối kết nối, hãy nhấp vào + THÊM, rồi nhấp vào Kết nối với nguồn dữ liệu bên ngoài.
- Trong danh sách Connection type (Loại kết nối), hãy chọn Vertex AI remote models, remote functions and BigLake (Cloud Resource) (Mô hình từ xa, hàm từ xa và BigLake (Tài nguyên đám mây) của Vertex AI).
- Trong trường Mã kết nối, hãy nhập gemini_conn cho mối kết nối của bạn.
- Đối với Loại vị trí, hãy chọn Nhiều khu vực, rồi chọn Hoa Kỳ trong trình đơn thả xuống.
- Sử dụng các chế độ cài đặt mặc định cho các chế độ cài đặt khác.
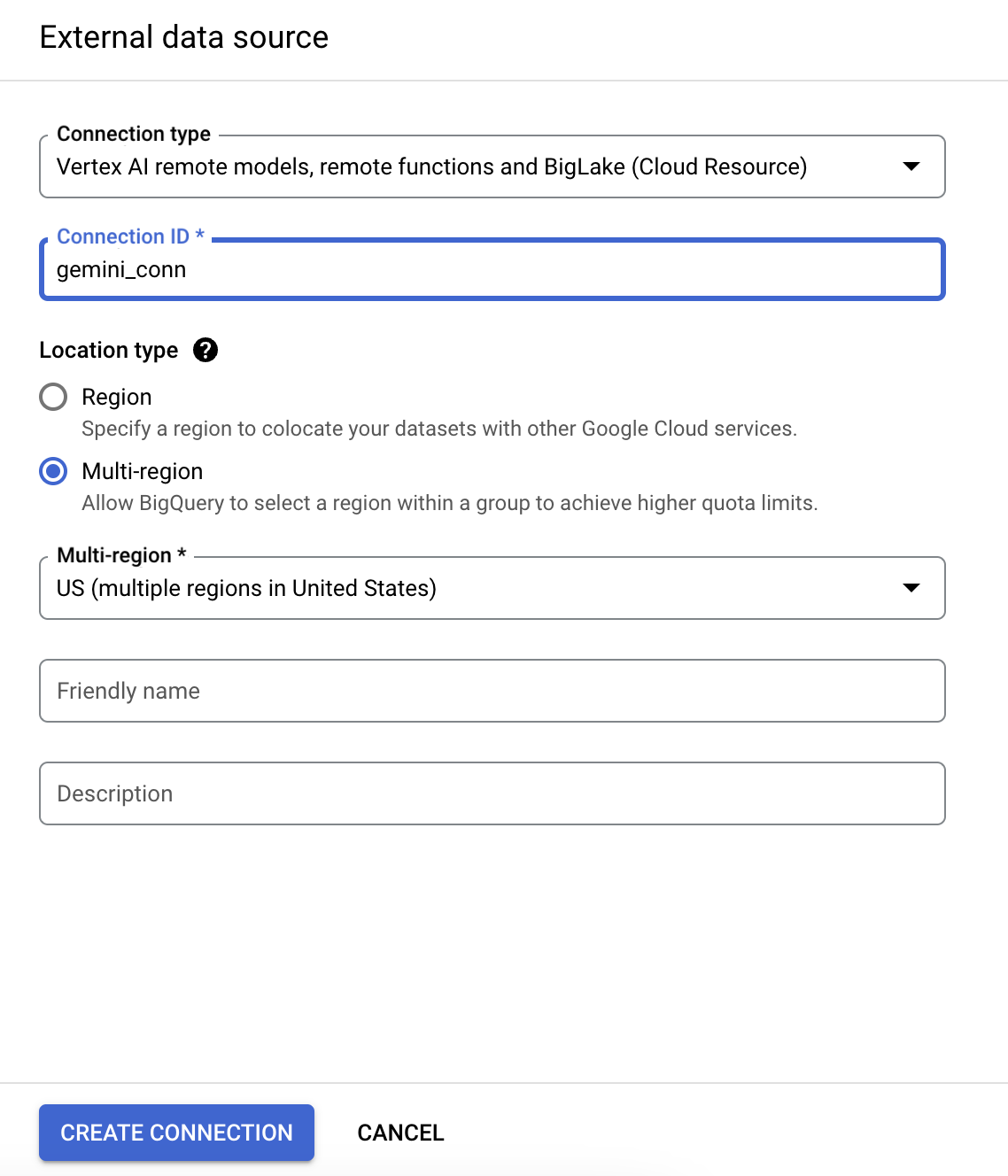
- Nhấp vào Tạo mối kết nối.
- Nhấp vào CHUYỂN ĐẾN TRANG KẾT NỐI.
- Trong ngăn Connection info (Thông tin kết nối), hãy sao chép mã nhận dạng tài khoản dịch vụ vào một tệp văn bản để dùng trong nhiệm vụ tiếp theo. Bạn cũng sẽ thấy rằng kết nối này được thêm vào phần Kết nối bên ngoài của dự án trong BigQuery Explorer.
5. Cấp quyền IAM cho tài khoản dịch vụ của mối kết nối
Trong nhiệm vụ này, bạn cấp quyền IAM cho tài khoản dịch vụ của mối kết nối Cloud Resource thông qua một vai trò để cho phép tài khoản này truy cập vào các dịch vụ Vertex AI.
- Trong bảng điều khiển Cloud, trên Trình đơn điều hướng, hãy nhấp vào IAM và Quản trị.
- Nhấp vào Cấp quyền truy cập.
- Trong trường Bên giao đại lý mới, hãy nhập mã tài khoản dịch vụ mà bạn đã sao chép trước đó.
- Trong trường Chọn vai trò, hãy nhập Vertex AI, rồi chọn vai trò Người dùng Vertex AI.
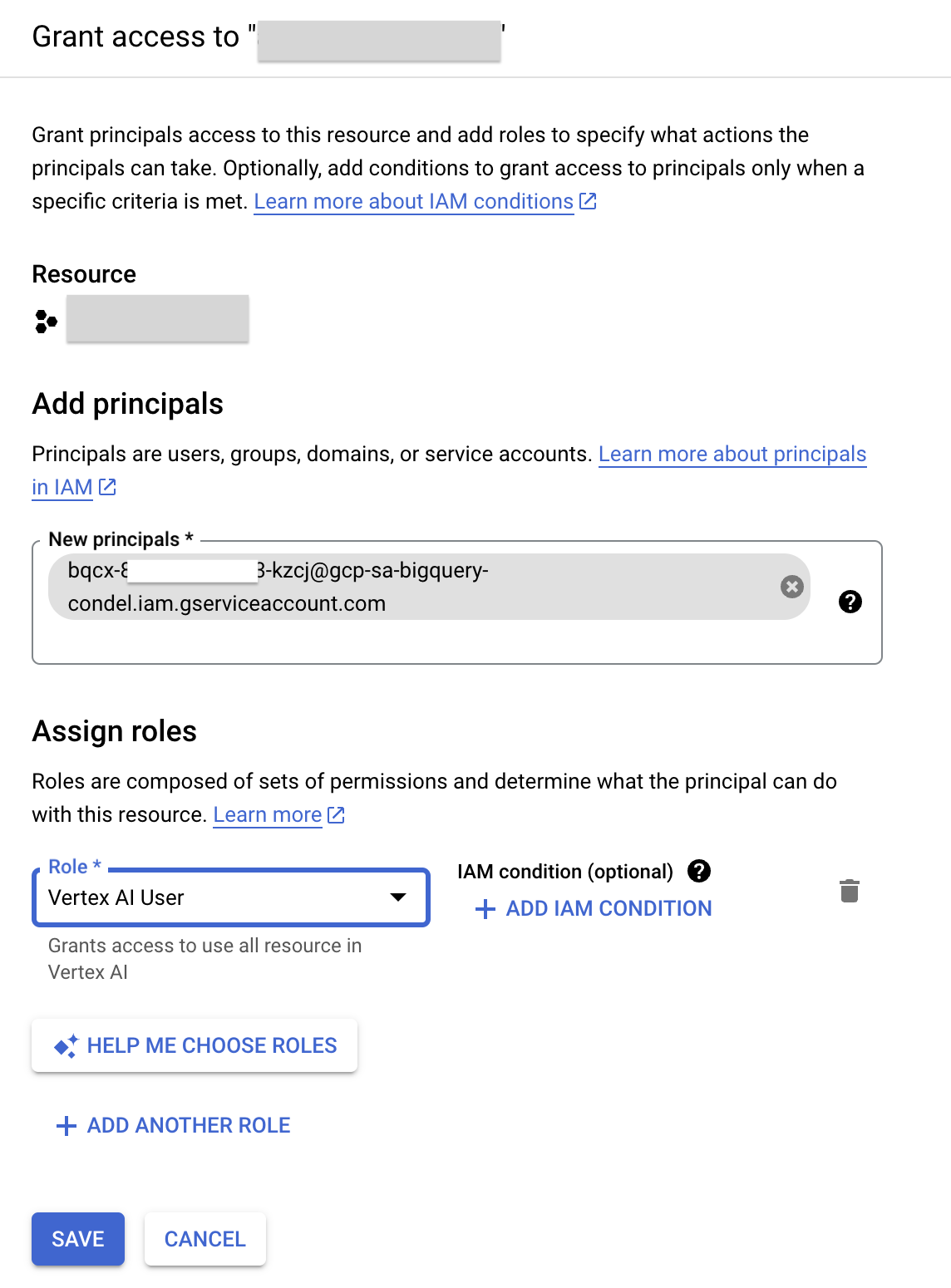
- Nhấp vào Lưu. Kết quả là mã tài khoản dịch vụ hiện có vai trò Người dùng Vertex AI.
6. Tạo tập dữ liệu và bảng đối tượng trong BigQuery cho hình ảnh áp phích phim
Trong nhiệm vụ này, bạn sẽ tạo một tập dữ liệu cho dự án và một bảng đối tượng trong tập dữ liệu đó để lưu trữ hình ảnh áp phích.
Tập dữ liệu gồm các hình ảnh áp phích phim được dùng trong hướng dẫn này được lưu trữ trong một bộ chứa công khai của Google Cloud Storage: gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters
Tạo tập dữ liệu
Bạn sẽ tạo một tập dữ liệu để lưu trữ các đối tượng cơ sở dữ liệu, bao gồm cả bảng và mô hình, được dùng trong hướng dẫn này.
- Trong bảng điều khiển Google Cloud, hãy chọn Trình đơn điều hướng ( ), rồi chọn BigQuery.
- Trong bảng Explorer (Trình khám phá), bên cạnh tên dự án, hãy chọn View actions (Xem các thao tác) (
 ), rồi chọn Create dataset (Tạo tập dữ liệu).
), rồi chọn Create dataset (Tạo tập dữ liệu). - Trong ngăn Tạo tập dữ liệu, hãy nhập thông tin sau:
- Mã tập dữ liệu: gemini_demo
- Loại vị trí: chọn Nhiều khu vực
- Nhiều khu vực: chọn Hoa Kỳ
- Giữ nguyên các trường khác theo mặc định.
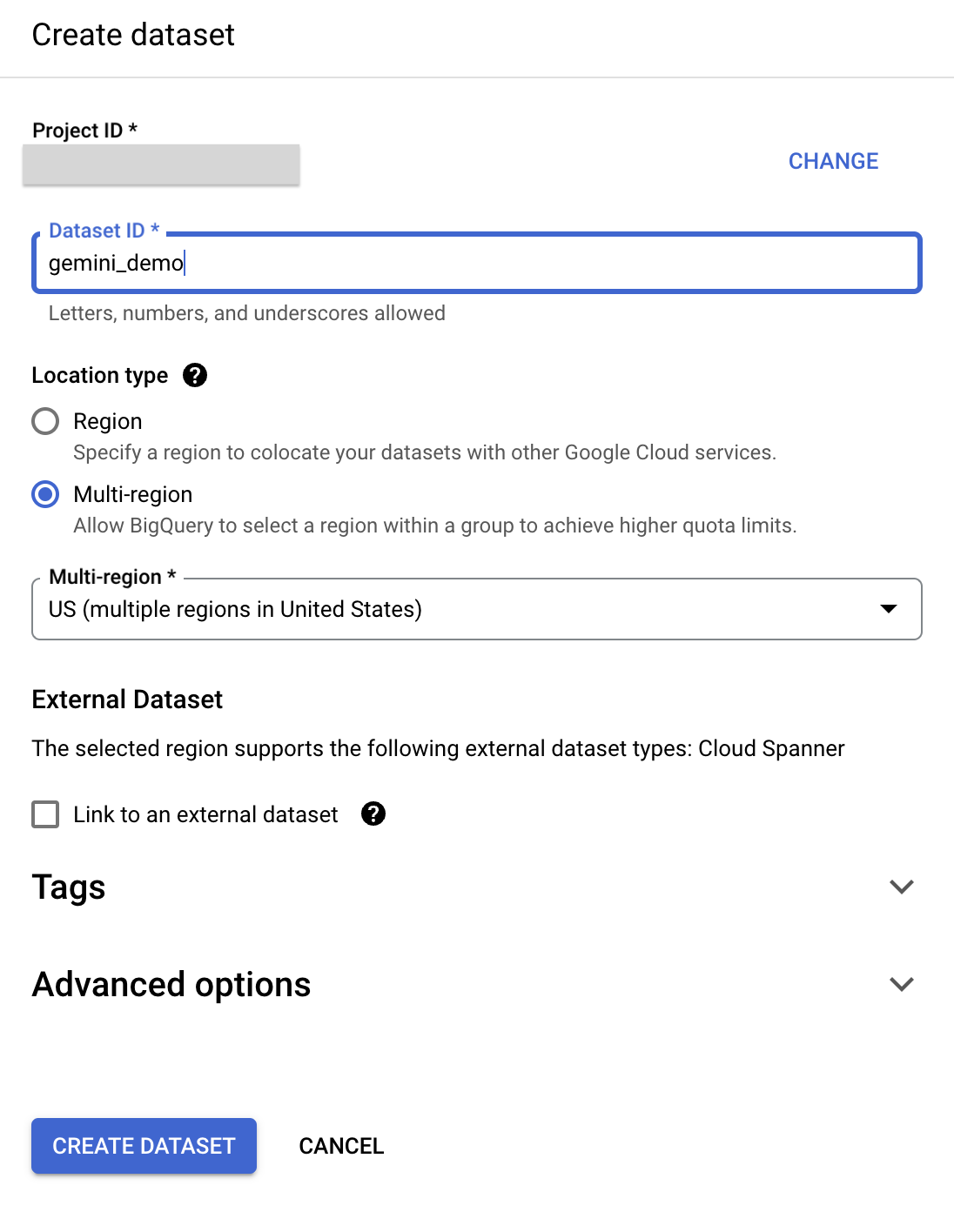
- Nhấp vào Tạo tập dữ liệu.
Kết quả là tập dữ liệu gemini_demo được tạo và liệt kê bên dưới dự án của bạn trong Trình khám phá BigQuery.
Tạo bảng đối tượng
BigQuery không chỉ lưu trữ dữ liệu có cấu trúc mà còn có thể truy cập vào dữ liệu không có cấu trúc (chẳng hạn như hình ảnh áp phích) thông qua các bảng đối tượng.
Bạn tạo một bảng đối tượng bằng cách trỏ đến một bộ chứa Cloud Storage. Bảng đối tượng kết quả sẽ có một hàng cho mỗi đối tượng trong bộ chứa cùng với đường dẫn lưu trữ và siêu dữ liệu của đối tượng đó.
Để tạo bảng đối tượng, bạn sẽ sử dụng một truy vấn SQL.
- Nhấp vào dấu + để Tạo truy vấn SQL mới.
- Trong trình chỉnh sửa truy vấn, hãy dán truy vấn bên dưới.
CREATE OR REPLACE EXTERNAL TABLE
`gemini_demo.movie_posters`
WITH CONNECTION `us.gemini_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters/*']
);
- Chạy truy vấn. Kết quả là một bảng đối tượng
movie_postersđược thêm vào tập dữ liệugemini_demovà được tải bằngURI(vị trí Cloud Storage) của mỗi hình ảnh áp phích phim. - Trong Trình khám phá, hãy nhấp vào biểu tượng
movie_postersrồi xem xét giản đồ và thông tin chi tiết. Bạn có thể truy vấn bảng này để xem xét các bản ghi cụ thể.
7. Tạo mô hình từ xa Gemini trong BigQuery
Giờ đây, khi đã tạo bảng đối tượng, bạn có thể bắt đầu làm việc với bảng đó. Trong tác vụ này, bạn sẽ tạo một mô hình từ xa cho Gemini 1.5 Flash để cung cấp mô hình này trong BigQuery.
Tạo mô hình từ xa Gemini 1.5 Flash
- Nhấp vào dấu + để Tạo truy vấn SQL mới.
- Trong trình chỉnh sửa truy vấn, hãy dán truy vấn bên dưới rồi kích hoạt truy vấn đó.
CREATE OR REPLACE MODEL `gemini_demo.gemini_1_5_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'gemini-1.5-flash')
Kết quả là mô hình gemini_1_5_flash được tạo và bạn thấy mô hình này được thêm vào tập dữ liệu gemini_demo, trong phần mô hình.
- Trong Trình khám phá, hãy nhấp vào mô hình
gemini_1_5_flashrồi xem thông tin chi tiết.
8. Đưa ra câu lệnh cho mô hình Gemini để cung cấp bản tóm tắt phim cho từng áp phích
Trong nhiệm vụ này, bạn sẽ sử dụng mô hình từ xa Gemini mà bạn vừa tạo để phân tích hình ảnh áp phích phim và tạo bản tóm tắt cho từng bộ phim.
Bạn có thể gửi yêu cầu đến mô hình bằng cách sử dụng hàm ML.GENERATE_TEXT, tham chiếu đến mô hình trong các tham số.
Phân tích hình ảnh bằng mô hình Gemini 1.5 Flash
- Tạo và chạy một truy vấn mới bằng câu lệnh SQL sau:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results` AS (
SELECT
uri,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
TABLE `gemini_demo.movie_posters`,
STRUCT( 0.2 AS temperature,
'For the movie represented by this poster, what is the movie title and year of release? Answer in JSON format with two keys: title, year. title should be string, year should be integer. Do not use JSON decorators.' AS PROMPT,
TRUE AS FLATTEN_JSON_OUTPUT)));
Khi truy vấn chạy, BigQuery sẽ nhắc mô hình Gemini cho từng hàng của bảng đối tượng, kết hợp hình ảnh với câu lệnh tĩnh được chỉ định. Kết quả là bảng movie_posters_results được tạo.
- Bây giờ, hãy xem kết quả. Tạo và chạy một truy vấn mới bằng câu lệnh SQL sau:
SELECT * FROM `gemini_demo.movie_posters_results`
Kết quả là các hàng cho mỗi áp phích phim có URI (vị trí của hình ảnh áp phích phim trên Cloud Storage) và một kết quả JSON bao gồm tiêu đề phim và năm phát hành phim từ mô hình Gemini 1.5 Flash.
Bạn có thể truy xuất những kết quả này theo cách dễ đọc hơn bằng cách sử dụng truy vấn tiếp theo. Truy vấn này sử dụng SQL để trích xuất tiêu đề phim và năm phát hành từ các câu trả lời này vào các cột mới.
- Tạo và chạy một truy vấn mới bằng câu lệnh SQL sau:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_formatted` AS (
SELECT
uri,
JSON_VALUE(ml_generate_text_llm_result, "$.title") AS title,
JSON_VALUE(ml_generate_text_llm_result, "$.year") AS year
FROM
`gemini_demo.movie_posters_results` results )
Kết quả là bảng movie_posters_result_formatted được tạo.
- Bạn có thể truy vấn bảng bằng truy vấn bên dưới để xem các hàng đã tạo.
SELECT * FROM `gemini_demo.movie_posters_results_formatted`
Xin lưu ý rằng kết quả của cột URI vẫn giữ nguyên, nhưng giờ đây, JSON đã được chuyển đổi thành các cột title và year cho mỗi hàng.
Yêu cầu mô hình Gemini 1.5 Flash cung cấp bản tóm tắt phim
Điều gì sẽ xảy ra nếu bạn muốn biết thêm thông tin về từng bộ phim này, chẳng hạn như bản tóm tắt bằng văn bản của từng bộ phim? Trường hợp sử dụng tạo nội dung này rất phù hợp với một mô hình LLM như mô hình Gemini 1.5 Flash.
- Bạn có thể dùng Gemini 1.5 Flash để cung cấp bản tóm tắt phim cho từng áp phích bằng cách chạy truy vấn bên dưới:
SELECT
uri,
title,
year,
prompt,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
(
SELECT
CONCAT('Provide a short summary of movie titled ',title, ' from the year ',year,'.') AS prompt,
uri,
title,
year
FROM
`gemini_demo.movie_posters_results_formatted`
LIMIT
20 ),
STRUCT(0.2 AS temperature,
TRUE AS FLATTEN_JSON_OUTPUT));
Lưu ý trường ml_generate_text_llm_result của kết quả; trường này bao gồm một bản tóm tắt ngắn về bộ phim.
9. Tạo các mục nhúng văn bản bằng mô hình từ xa
Giờ đây, bạn có thể kết hợp dữ liệu có cấu trúc mà bạn đã tạo với dữ liệu có cấu trúc khác trong kho dữ liệu. Tập dữ liệu công khai của IMDB có trong BigQuery chứa nhiều thông tin về phim, bao gồm cả điểm xếp hạng của người xem và một số đánh giá mẫu của người dùng ở dạng văn bản tự do. Dữ liệu này có thể giúp bạn phân tích sâu hơn về các áp phích phim và hiểu được cách mọi người cảm nhận về những bộ phim này.
Để kết hợp dữ liệu, bạn sẽ cần một khoá. Trong trường hợp này, tên phim do mô hình Gemini tạo có thể không hoàn toàn khớp với tên trong tập dữ liệu IMDB.
Trong nhiệm vụ này, bạn sẽ tạo các vectơ nhúng văn bản của tên và năm phát hành phim từ cả hai tập dữ liệu, sau đó sử dụng khoảng cách giữa các vectơ nhúng này để kết hợp tên phim gần nhất trên IMDB với tên phim trên áp phích trong tập dữ liệu mới tạo.
Tạo mô hình từ xa
Để tạo các vectơ nhúng văn bản, bạn sẽ cần tạo một mô hình từ xa mới trỏ đến điểm cuối text-multilingual-embedding-002.
- Tạo và chạy một truy vấn mới bằng câu lệnh SQL sau:
CREATE OR REPLACE MODEL `gemini_demo.text_embedding`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
Kết quả là mô hình text_embedding được tạo và xuất hiện trong trình khám phá bên dưới tập dữ liệu gemini_demo.
Tạo các vectơ nhúng văn bản cho tiêu đề và năm liên quan đến áp phích
Giờ đây, bạn sẽ sử dụng mô hình từ xa này với hàm ML.GENERATE_EMBEDDING để tạo một mục nhúng cho từng tiêu đề và năm của áp phích phim.
- Tạo và chạy một truy vấn mới bằng câu lệnh SQL sau:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
uri
FROM
`gemini_demo.movie_posters_results_formatted` ),
STRUCT(TRUE AS flatten_json_output)));
Kết quả là bảng movie_poster_results_embeddings được tạo có chứa các vectơ nhúng cho nội dung văn bản được nối cho từng hàng của bảng gemini_demo.movie_posters_results_formatted.
- Bạn có thể xem kết quả của truy vấn bằng truy vấn mới bên dưới:
SELECT * FROM `gemini_demo.movie_posters_results_embeddings`
Tại đây, bạn sẽ thấy các mục nhúng (các vectơ được biểu thị bằng số) cho từng bộ phim do mô hình tạo ra.
Tạo các vectơ nhúng văn bản cho một tập hợp con của tập dữ liệu IMDB
Bạn sẽ tạo một chế độ xem dữ liệu mới từ một tập dữ liệu công khai của IMDB. Tập dữ liệu này chỉ chứa những bộ phim được phát hành trước năm 1935 (khoảng thời gian đã biết của các bộ phim trong hình ảnh áp phích).
- Tạo và chạy một truy vấn mới bằng câu lệnh SQL sau:
CREATE OR REPLACE VIEW
`gemini_demo.imdb_movies` AS (
WITH
reviews AS (
SELECT
reviews.movie_id AS movie_id,
title.primary_title AS title,
title.start_year AS year,
reviews.review AS review
FROM
`bigquery-public-data.imdb.reviews` reviews
LEFT JOIN
`bigquery-public-data.imdb.title_basics` title
ON
reviews.movie_id = title.tconst)
SELECT
DISTINCT(movie_id),
title,
year
FROM
reviews
WHERE
year < 1935)
Kết quả là một chế độ xem mới chứa danh sách mã nhận dạng, tiêu đề và năm phát hành riêng biệt của phim trong bảng bigquery-public-data.imdb.reviews cho tất cả các bộ phim trong tập dữ liệu được phát hành trước năm 1935.
- Giờ đây, bạn sẽ tạo các mục nhúng cho một nhóm nhỏ phim trên IMDB bằng quy trình tương tự như trong phần trước. Tạo và chạy một truy vấn mới bằng câu lệnh SQL sau:
CREATE OR REPLACE TABLE
`gemini_demo.imdb_movies_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING( MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
movie_id
FROM
`gemini_demo.imdb_movies` ),
STRUCT(TRUE AS flatten_json_output) )
WHERE
ml_generate_embedding_status = '' );
Kết quả của truy vấn là một bảng chứa các mục nhúng cho nội dung văn bản của bảng gemini_demo.imdb_movies.
Ghép các hình ảnh áp phích phim với IMDB movie_id bằng BigQuery VECTOR_SEARCH
Bây giờ, bạn có thể kết hợp hai bảng bằng cách sử dụng hàm VECTOR_SEARCH.
- Tạo và chạy một truy vấn mới bằng câu lệnh SQL sau:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE');
Truy vấn này dùng hàm VECTOR_SEARCH để tìm hàng xóm gần nhất trong bảng gemini_demo.imdb_movies_embeddings cho từng hàng trong bảng gemini_demo.movie_posters_results_embeddings. Hàng xóm gần nhất được tìm thấy bằng cách sử dụng chỉ số khoảng cách cosine, xác định mức độ tương tự của hai mục nhúng.
Bạn có thể dùng truy vấn này để tìm bộ phim tương tự nhất trong tập dữ liệu IMDB cho từng bộ phim mà Gemini 1.5 Flash xác định được trong áp phích phim. Ví dụ: bạn có thể dùng truy vấn này để tìm kết quả khớp gần nhất cho bộ phim "Au Secours!" trong tập dữ liệu công khai của IMDB. Tập dữ liệu này tham chiếu đến bộ phim này bằng tiêu đề tiếng Anh là "Help!".
- Tạo và chạy một truy vấn mới để kết hợp một số thông tin bổ sung về điểm xếp hạng phim có trong tập dữ liệu công khai của IMDB:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance,
imdb.average_rating,
imdb.num_votes
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE') DATA
LEFT JOIN
`bigquery-public-data.imdb.title_ratings` imdb
ON
base.movie_id = imdb.tconst
ORDER BY
imdb.average_rating DESC
Truy vấn này tương tự như truy vấn trước. Hệ thống này vẫn sử dụng các biểu diễn bằng số đặc biệt (gọi là vectơ nhúng) để tìm những bộ phim tương tự với một áp phích phim nhất định. Tuy nhiên, nó cũng kết hợp điểm xếp hạng trung bình và số phiếu bầu cho từng bộ phim lân cận gần nhất từ một bảng riêng biệt trong tập dữ liệu công khai của IMDB.
10. Xin chúc mừng
Chúc mừng bạn đã hoàn thành lớp học lập trình này. Bạn đã tạo thành công một bảng đối tượng cho hình ảnh áp phích trong BigQuery, tạo một mô hình Gemini từ xa, sử dụng mô hình đó để nhắc mô hình Gemini phân tích hình ảnh và cung cấp bản tóm tắt phim, tạo các vectơ nhúng văn bản cho tiêu đề phim và sử dụng các vectơ nhúng đó để so khớp hình ảnh áp phích phim với tiêu đề phim có liên quan trong tập dữ liệu IMDB.
Nội dung đã đề cập
- Cách định cấu hình môi trường và tài khoản để sử dụng API
- Cách tạo mối kết nối Tài nguyên trên đám mây trong BigQuery
- Cách tạo tập dữ liệu và bảng đối tượng trong BigQuery cho hình ảnh áp phích phim
- Cách tạo các mô hình từ xa của Gemini trong BigQuery
- Cách đưa ra câu lệnh cho mô hình Gemini để cung cấp bản tóm tắt phim cho từng áp phích
- Cách tạo vectơ nhúng văn bản cho bộ phim xuất hiện trong mỗi áp phích
- Cách sử dụng BigQuery
VECTOR_SEARCHđể so khớp hình ảnh áp phích phim với những bộ phim có liên quan chặt chẽ trong tập dữ liệu
Các bước tiếp theo / tìm hiểu thêm