
1. مقدمة
يواجه محللو البيانات غالبًا بيانات قيّمة محظورة في تنسيقات شبه منظَّمة، مثل حمولات JSON. لقد كان استخراج هذه البيانات وإعدادها للتحليل وتعلُّم الآلة يشكّل تقليديًا عقبة فنية كبيرة، إذ كان يتطلّب عادةً نصوصًا برمجية معقّدة لاستخراج البيانات وتحويلها وتحميلها وتدخّل فريق هندسة البيانات.
يقدّم هذا الدرس التطبيقي حول الترميز مخططًا فنيًا لمحلّلي البيانات للتغلّب على هذا التحدّي بشكل مستقل. يوضّح هذا المستند نهجًا "يقل الاعتماد فيه على الرموز البرمجية" لإنشاء مسار متكامل للذكاء الاصطناعي. ستتعرّف على كيفية الانتقال من ملف CSV أوّلي في Google Cloud Storage إلى تشغيل ميزة اقتراحات مستندة إلى الذكاء الاصطناعي، وذلك باستخدام الأدوات المتاحة في BigQuery Studio فقط.
الهدف الأساسي هو عرض سير عمل قوي وسريع وسهل الاستخدام للمحللين يتجاوز العمليات المعقّدة التي تتضمّن الكثير من الرموز البرمجية من أجل تحقيق قيمة تجارية حقيقية من بياناتك.
المتطلبات الأساسية
- فهم أساسي لـ Google Cloud Console
- مهارات أساسية في واجهة سطر الأوامر وGoogle Cloud Shell
ما ستتعلمه
- كيفية استيعاب ملف CSV وتحويله مباشرةً من Google Cloud Storage باستخدام "إعداد البيانات في BigQuery"
- كيفية استخدام عمليات التحويل بدون ترميز لتحليل سلاسل JSON المتداخلة وتسويتها ضمن بياناتك
- كيفية إنشاء نموذج بعيد في BigQuery ML يتصل بنموذج أساسي في Vertex AI لتضمين النصوص
- كيفية استخدام الدالة
ML.GENERATE_TEXT_EMBEDDINGلتحويل البيانات النصية إلى متجهات رقمية - كيفية استخدام الدالة
ML.DISTANCEلحساب التشابه الجيب التمامي والعثور على العناصر الأكثر تشابهًا في مجموعة البيانات
المتطلبات
- حساب Google Cloud ومشروع Google Cloud
- متصفّح ويب، مثل Chrome
المفاهيم الأساسية
- إعداد البيانات في BigQuery: هي أداة ضمن BigQuery Studio توفّر واجهة تفاعلية مرئية لتنظيف البيانات وإعدادها. يقترح عمليات تحويل ويسمح للمستخدمين بإنشاء مسارات بيانات بأقل قدر ممكن من الرموز البرمجية.
- نموذج عن بُعد في BigQuery ML: هو عنصر في BigQuery ML يعمل كخادم وكيل لنموذج مستضاف على Vertex AI (مثل Gemini). تتيح لك هذه الخدمة استدعاء نماذج ذكاء اصطناعي قوية ومدرَّبة مسبقًا باستخدام بنية SQL مألوفة.
- التضمين المتّجهي: هو تمثيل رقمي للبيانات، مثل النصوص أو الصور. في هذا الدرس التطبيقي حول الترميز، سنحوّل الأوصاف النصية للأعمال الفنية إلى متّجهات، حيث تؤدي الأوصاف المتشابهة إلى متّجهات "أقرب" إلى بعضها البعض في مساحة متعدّدة الأبعاد.
- تشابه جيب التمام: هو مقياس رياضي يُستخدَم لتحديد مدى التشابه بين خطين متجهين. وهي أساس منطق محرّك الاقتراحات لدينا، وتستخدمها الدالة
ML.DISTANCEللعثور على الأعمال الفنية "الأقرب" (الأكثر تشابهًا).
2. الإعداد والمتطلبات
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس العملي Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
من Google Cloud Console، انقر على رمز Cloud Shell في شريط الأدوات أعلى يسار الصفحة:

لن يستغرق توفير البيئة والاتصال بها سوى بضع لحظات. عند الانتهاء، من المفترض أن يظهر لك ما يلي:

يتم تحميل هذه الآلة الافتراضية مزوّدة بكل أدوات التطوير التي ستحتاج إليها. توفّر هذه الخدمة دليلًا منزليًا ثابتًا بسعة 5 غيغابايت، وتعمل على Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إكمال جميع المهام في هذا الدرس العملي ضمن المتصفّح. لست بحاجة إلى تثبيت أي تطبيق.
تفعيل واجهات برمجة التطبيقات المطلوبة وإعداد البيئة
داخل Cloud Shell، شغِّل الأوامر التالية لضبط رقم تعريف مشروعك وتحديد متغيّرات البيئة وتفعيل جميع واجهات برمجة التطبيقات اللازمة لهذا الدرس التطبيقي حول الترميز.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
إنشاء مجموعة بيانات في BigQuery وحزمة في "خدمة التخزين السحابي من Google"
أنشئ مجموعة بيانات جديدة في BigQuery لتضمين جداولنا وحزمة في Google Cloud Storage لتخزين ملف CSV المصدر.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
إعداد بيانات النموذج وتحميلها
استنسِخ مستودع GitHub الذي يحتوي على نموذج ملف CSV، ثم حمِّله إلى حزمة GCS التي أنشأتها للتو.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3- من GCS إلى BigQuery باستخدام "إعداد البيانات"
في هذا القسم، سنستخدم واجهة مرئية لا تتطلّب كتابة أي رمز لاستيعاب ملف CSV من "خدمة التخزين السحابي من Google" وتنظيفه وتحميله إلى جدول BigQuery جديد.
تشغيل "إعداد البيانات" والربط بالمصدر
- في Google Cloud Console، انتقِل إلى BigQuery Studio.
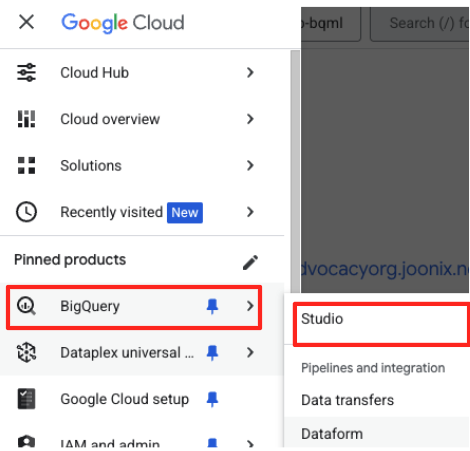
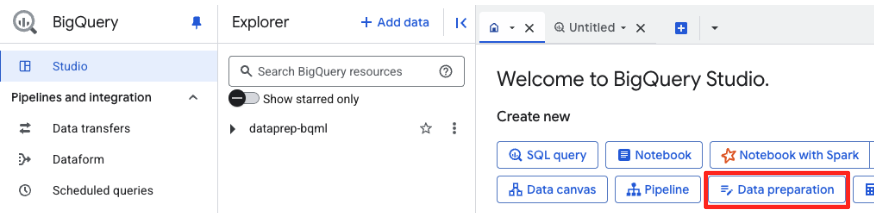
- في صفحة الترحيب، انقر على بطاقة "إعداد البيانات" للبدء.
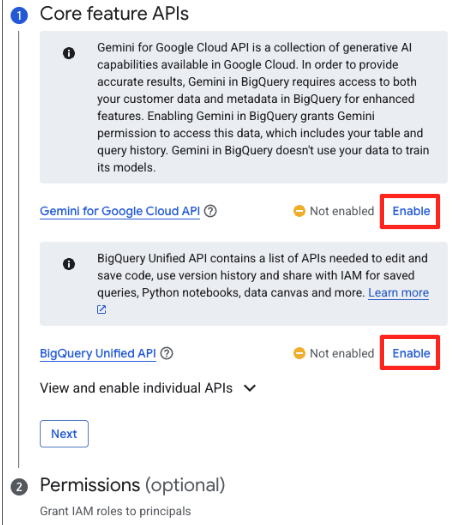
- إذا كانت هذه هي المرة الأولى، قد تحتاج إلى تفعيل واجهات برمجة التطبيقات المطلوبة. انقر على "تفعيل" (Enable) لكلّ من "Gemini في Google Cloud API" و"واجهة BigQuery Unified API". بعد تفعيلها، يمكنك إغلاق هذه اللوحة.
- في نافذة "إعداد البيانات" الرئيسية، ضِمن "اختيار مصادر بيانات أخرى"، انقر على Google Cloud Storage. سيؤدي ذلك إلى فتح لوحة "إعداد البيانات" على يسار الصفحة.

- انقر على الزر "تصفّح" لاختيار ملف المصدر.
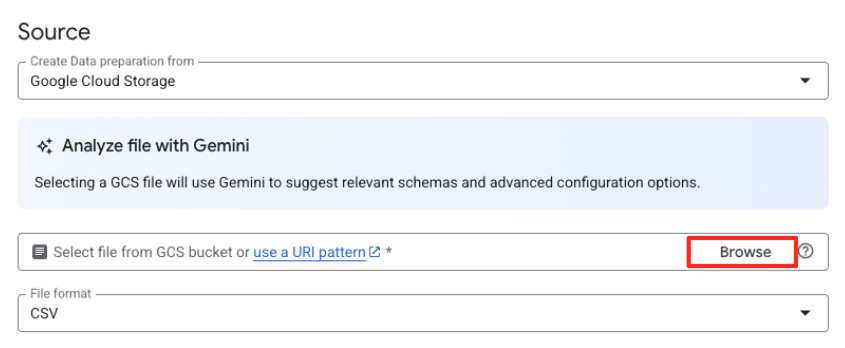
- انتقِل إلى حزمة GCS التي أنشأتها سابقًا (
met-artworks-source-...) واختَر الملفdataprep-met-bqml.csv. انقر على "اختيار".
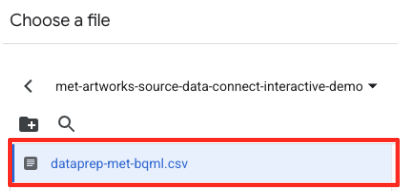
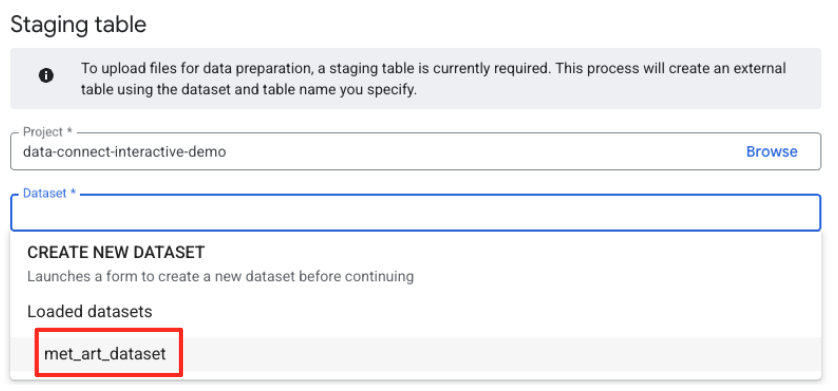
- بعد ذلك، عليك ضبط جدول مرحلي.
- بالنسبة إلى "مجموعة البيانات"، اختَر
met_art_datasetالتي أنشأتها. - في حقل "اسم الجدول" (Table name)، أدخِل اسمًا، مثل
temp. - انقر على "إنشاء".
تحويل البيانات وتنظيمها
- ستحمّل ميزة "إعداد البيانات" في BigQuery الآن معاينة لملف CSV. ابحث عن العمود
label_details_jsonالذي يحتوي على سلسلة JSON الطويلة. انقر على رأس العمود لتحديده.
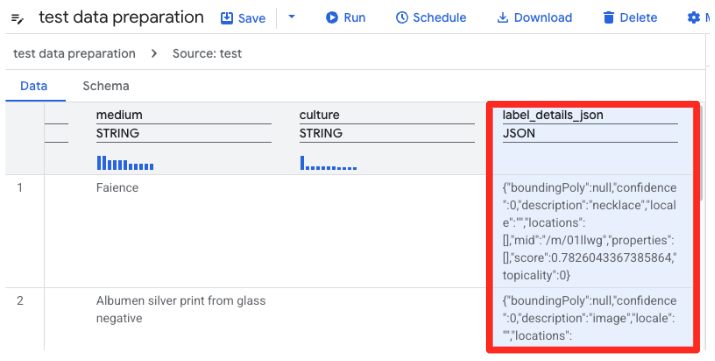
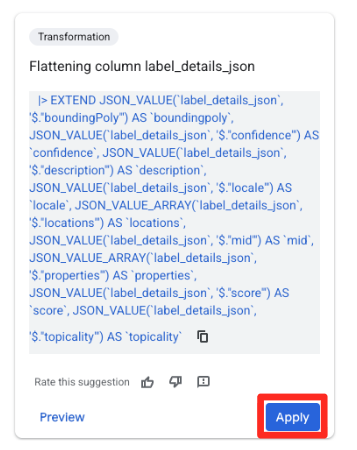
- في لوحة الاقتراحات على يسار الشاشة، سيقترح "Gemini في BigQuery" تلقائيًا عمليات تحويل ذات صلة. انقر على الزرّ "تطبيق" في بطاقة "عمود التسوية
label_details_json". سيؤدي ذلك إلى استخراج الحقول المتداخلة (descriptionوscoreوما إلى ذلك) إلى أعمدة خاصة بها في المستوى الأعلى.
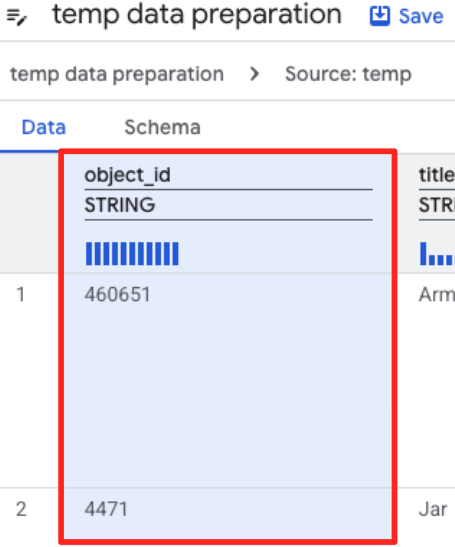
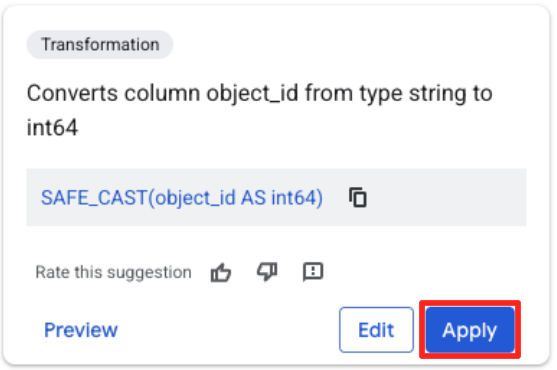
- انقر على عمود object_id، ثمّ انقر على زرّ "تطبيق" في "تحويل العمود
object_idمن النوعstringإلىint64".
تحديد الوجهة وتشغيل المهمة
- في اللوحة على يسار الصفحة، انقر على الزر "المكان المقصود" (Destination) لإعداد مخرجات عملية التحويل.
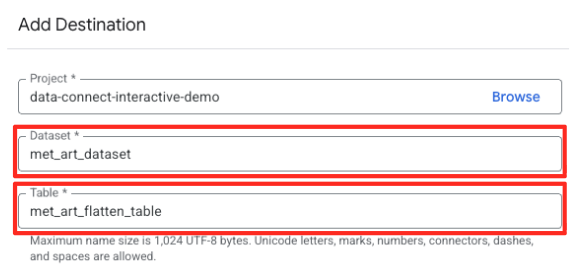
- اضبط تفاصيل الوجهة:
- يجب ملء مجموعة البيانات مسبقًا بالقيمة
met_art_dataset. - أدخِل اسم جدول جديدًا للناتج:
met_art_flatten_table. - انقر على "حفظ".
- انقر على الزر "تشغيل" (Run)، وانتظِر إلى أن تكتمل مهمة إعداد البيانات.
- يمكنك مراقبة مستوى تقدّم المهمة في علامة التبويب "عمليات التنفيذ" أسفل الصفحة. بعد بضع لحظات، سيتم إكمال المهمة.
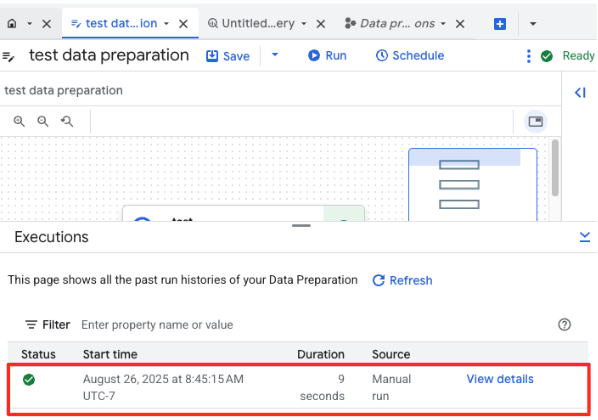
4. إنشاء تضمينات متّجهة باستخدام BQML
بعد أن أصبحت بياناتنا نظيفة ومنظَّمة، سنستخدم BigQuery ML لتنفيذ مهمة الذكاء الاصطناعي الأساسية، وهي تحويل الأوصاف النصية للأعمال الفنية إلى تضمينات متجهة رقمية.
إنشاء عملية ربط BigQuery
للسماح لـ BigQuery بالتواصل مع خدمات Vertex AI، عليك أولاً إنشاء BigQuery Connection.
- في لوحة "المستكشف" في BigQuery Studio، انقر على الزر "+ إضافة بيانات".
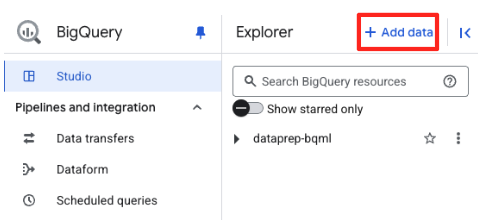
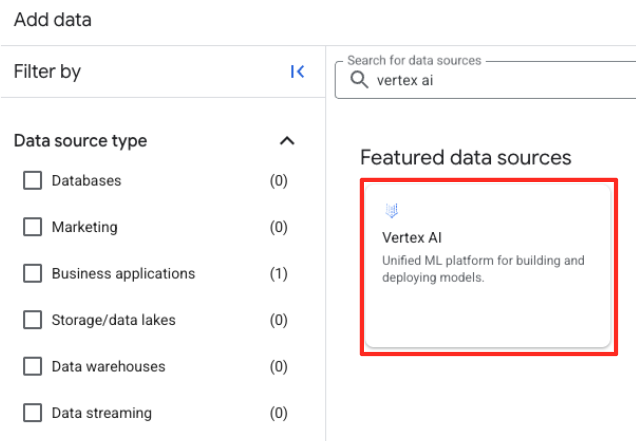
- في اللوحة اليسرى، استخدِم شريط البحث لكتابة
Vertex AI. اختَرها، ثمّ اختَر BigQuery federation من القائمة التي تمّت فلترتها.
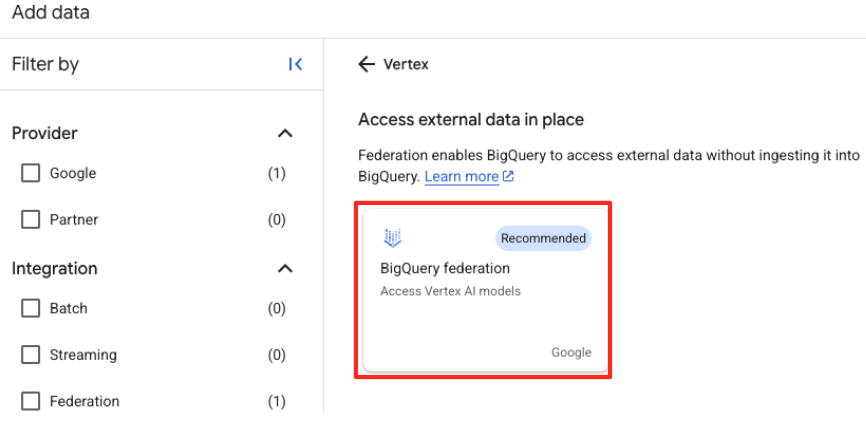
- سيؤدي ذلك إلى فتح نموذج مصدر البيانات الخارجية. أدخِل التفاصيل التالية:
- معرّف الاتصال: أدخِل معرّف الاتصال (مثل
bqml-vertex-connection) - نوع الموقع الجغرافي: تأكَّد من اختيار "نطاق جغرافي متعدد المناطق".
- الموقع الجغرافي: اختَر الموقع الجغرافي (مثل
US).
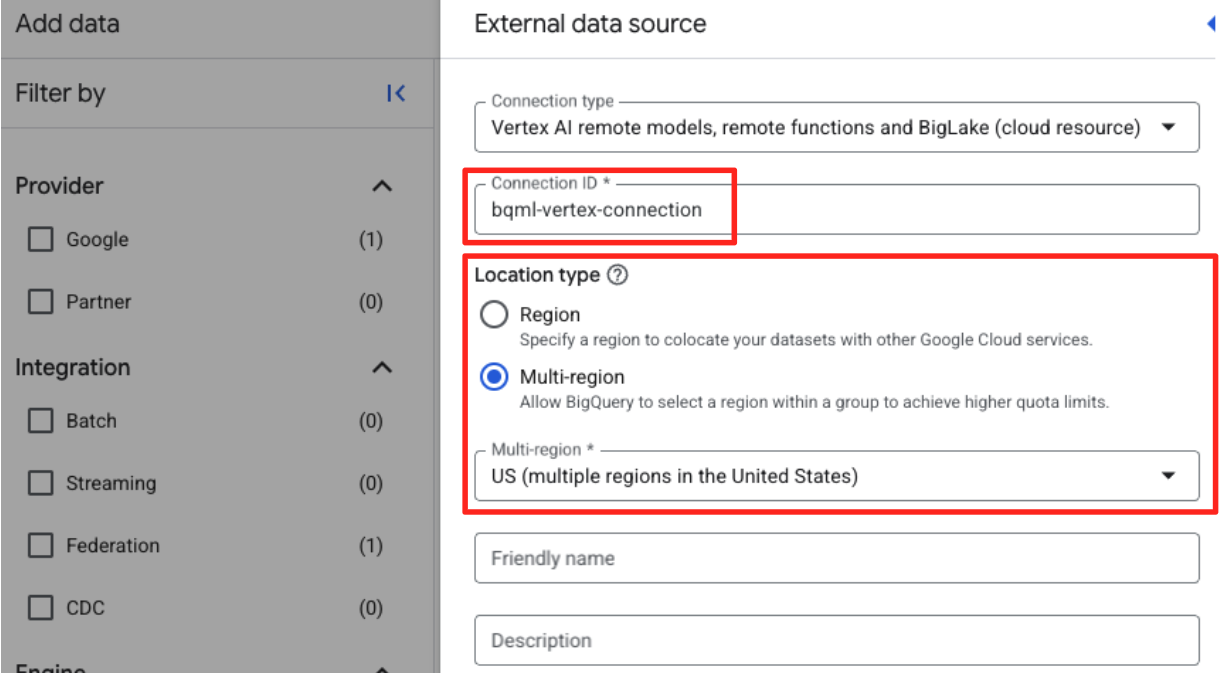
- بعد إنشاء عملية الربط، سيظهر مربّع حوار للتأكيد. انقر على "الانتقال إلى الاتصال" أو "الاتصالات الخارجية" في علامة التبويب "المستكشف". في صفحة تفاصيل الربط، انسخ رقم التعريف الكامل إلى الحافظة. هذه هي هوية حساب الخدمة التي ستستخدمها BigQuery لاستدعاء Vertex AI.
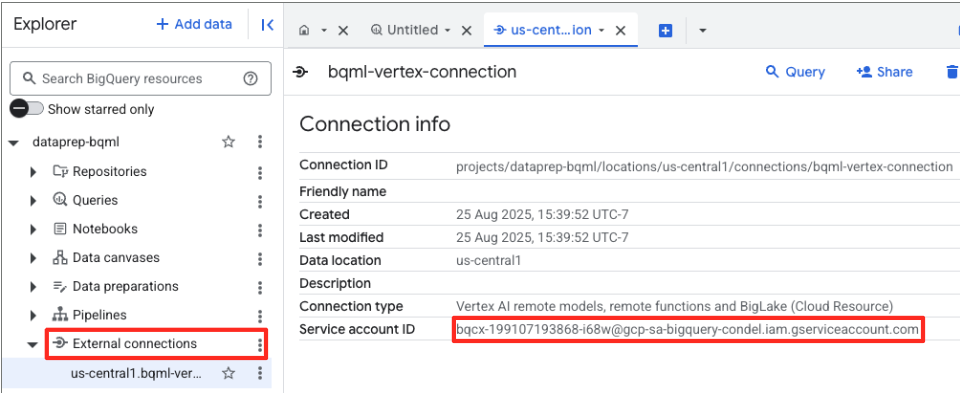
- في قائمة التنقّل في Google Cloud Console، انتقِل إلى "المشرف وإدارة الهوية وإمكانية الوصول" > "إدارة الهوية وإمكانية الوصول".
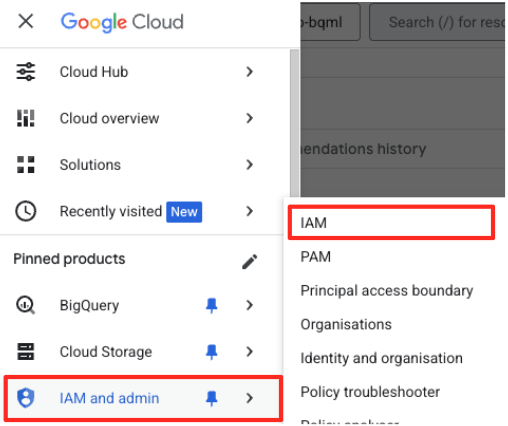
- انقر على الزر "منح الإذن بالوصول".
- ألصِق حساب الخدمة الذي نسخته في الخطوة السابقة في حقل "العناصر الرئيسية الجديدة".
- عيِّن دور مستخدم Vertex AI في القائمة المنسدلة "الدور"، ثم انقر على "حفظ".
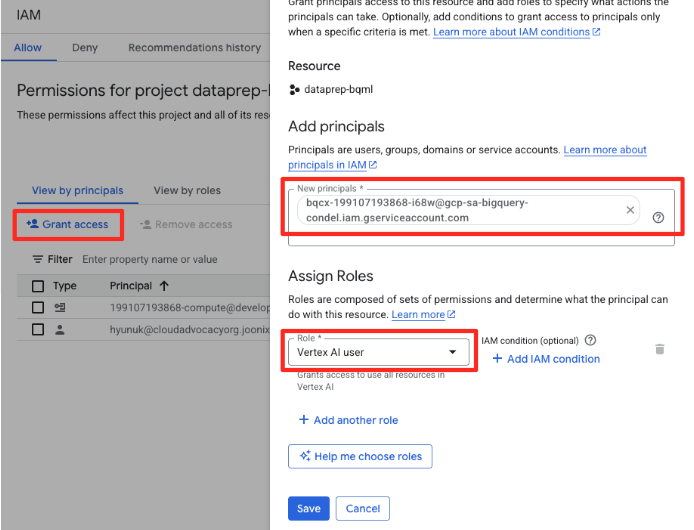
تضمن هذه الخطوة المهمة حصول BigQuery على التفويض المناسب لاستخدام نماذج Vertex AI بالنيابة عنك.
إنشاء نموذج Remote
في BigQuery Studio، افتح علامة تبويب جديدة لمحرّر SQL. هذا هو المكان الذي ستحدّد فيه نموذج BQML الذي يرتبط بـ Gemini.
لا تؤدي هذه العبارة إلى تدريب نموذج جديد. ما عليك سوى إنشاء مرجع في BigQuery يشير إلى نموذج gemini-embedding-001 قوي ومدرَّب مسبقًا باستخدام الاتصال الذي سمحت به للتو.
انسخ نص SQL البرمجي بالكامل أدناه والصقه في محرِّر BigQuery.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
إنشاء تضمينات
الآن، سنستخدم نموذج BQML لإنشاء عمليات التضمين المتجهة. بدلاً من مجرد تحويل تصنيف نصي واحد لكل صف، سنستخدم أسلوبًا أكثر تطورًا لإنشاء "ملخّص دلالي" أكثر ثراءً ودلالةً لكل عمل فني. سيؤدي ذلك إلى إنشاء تضمينات ذات جودة أعلى وتقديم اقتراحات أكثر دقةً.
ينفّذ طلب البحث هذا خطوة معالجة مسبقة مهمة:
- يستخدم هذا الاستعلام عبارة
WITHلإنشاء جدول مؤقت أولاً. - داخل هذا الجدول،
GROUP BYكلobject_idلدمج جميع المعلومات حول عمل فني واحد في صف واحد. - نستخدم الدالة
STRING_AGGلدمج جميع الأوصاف النصية المنفصلة (مثل "صورة شخصية" و"امرأة" و"لوحة زيتية على قماش") في سلسلة نصية واحدة شاملة، مع ترتيبها حسب درجة الصلة.
يمنح هذا النص المدمج الذكاء الاصطناعي سياقًا أكثر تفصيلاً حول العمل الفني، ما يؤدي إلى إنشاء تضمينات متجهة أكثر دقة وفعالية.
في علامة تبويب جديدة لمحرّر SQL، الصِق الاستعلام التالي وشغِّله:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
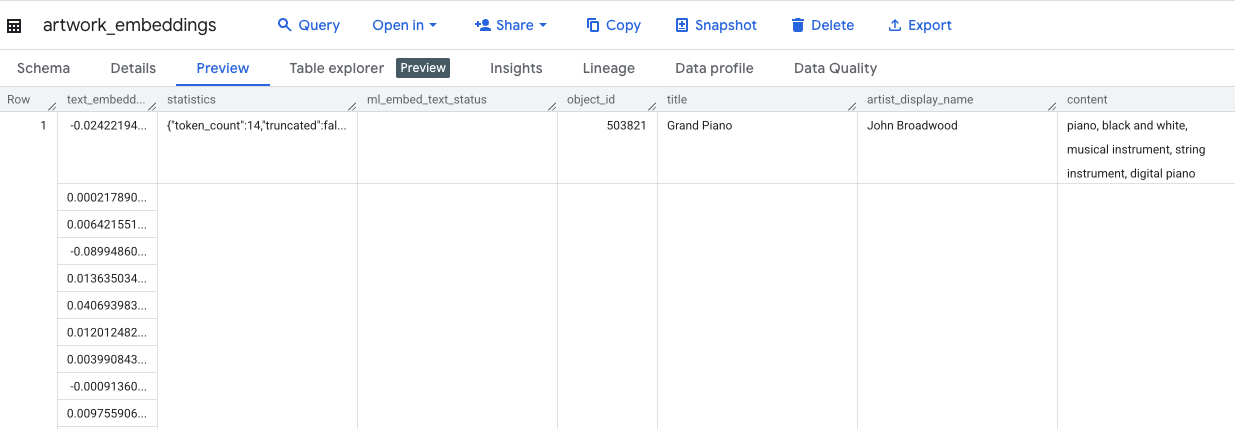
سيستغرق تنفيذ هذا الطلب حوالي 10 دقائق. بعد اكتمال طلب البحث، تحقَّق من النتائج. في لوحة "المستكشف"، ابحث عن artwork_embeddings الجدول الجديد وانقر عليه. في عارض مخطط الجدول، سترى object_id وعمود ml_generate_text_embedding_result الجديد الذي يحتوي على المتجهات، بالإضافة إلى عمود aggregated_labels الذي تم استخدامه كنص مصدر.
5- العثور على أعمال فنية مشابهة باستخدام SQL
بعد إنشاء عمليات التضمين المتجهة عالية الجودة والغنية بالسياق، يصبح العثور على أعمال فنية متشابهة من حيث الموضوع بسيطًا مثل تنفيذ طلب بحث SQL. نستخدم الدالة ML.DISTANCE لحساب التشابه بين المتجهات استنادًا إلى جيب التمام. وبما أنّ عمليات التضمين تم إنشاؤها من نصوص مجمّعة، ستكون نتائج التشابه أكثر دقة وملاءمةً.
- في علامة تبويب جديدة لمحرّر SQL، الصِق الاستعلام التالي. يحاكي طلب البحث هذا المنطق الأساسي لتطبيق الاقتراحات:
- في البداية، يتم اختيار المتّجه لعمل فني واحد ومحدّد (في هذه الحالة، "أشجار السرو" لفان غوخ، والتي تحمل
object_idبقيمة 436535). - ثم يتم حساب المسافة بين هذا المتّجه الفردي وجميع المتّجهات الأخرى في الجدول.
- وأخيرًا، يتم ترتيب النتائج حسب المسافة (المسافة الأقصر تعني تطابقًا أكبر) للعثور على أفضل 10 نتائج مطابقة.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- نفِّذ الاستعلام. ستعرض النتائج
object_id، مع ظهور النتائج الأقرب إلى طلبك في الأعلى. ستظهر صورة العمل الفني المصدر أولاً بمسافة 0. هذه هي المنطق الأساسي الذي يتيح محرّك اقتراحات مستند إلى الذكاء الاصطناعي، وقد أنشأته بالكامل في BigQuery باستخدام SQL فقط.
6. (اختياري) تشغيل العرض التوضيحي في Cloud Shell
لتطبيق المفاهيم الواردة في هذا الدرس التطبيقي حول الترميز، يتضمّن المستودع الذي استنسخته تطبيق ويب بسيطًا. يستخدم هذا العرض التوضيحي الاختياري جدول artwork_embeddings الذي أنشأته لتشغيل محرك بحث مرئي، ما يتيح لك رؤية الاقتراحات المستندة إلى الذكاء الاصطناعي أثناء عملها.
لتشغيل العرض التوضيحي في Cloud Shell، اتّبِع الخطوات التالية:
- ضبط متغيّرات البيئة: قبل تشغيل التطبيق، عليك ضبط متغيّرات البيئة PROJECT_ID وBIGQUERY_DATASET.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- ثبِّت التبعيات وابدأ تشغيل خادم الخلفية.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- ستحتاج إلى علامة تبويب ثانية في Terminal لتشغيل تطبيق الواجهة الأمامية. انقر على رمز "+" لفتح علامة تبويب Cloud Shell جديدة.

- الآن، في علامة التبويب الجديدة، نفِّذ الأمر التالي لتثبيت التبعيات وتشغيل خادم الواجهة الأمامية
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- معاينة التطبيق: في شريط أدوات Cloud Shell، انقر على رمز "معاينة الويب" واختَر "معاينة على المنفذ 5173". سيؤدي ذلك إلى فتح علامة تبويب متصفّح جديدة يتم فيها تشغيل التطبيق. يمكنك الآن استخدام التطبيق للبحث عن أعمال فنية ومشاهدة ميزة "البحث المشابه" أثناء عملها.
- لربط هذا العرض التوضيحي المرئي بالعمل الذي أجريته في محرِّر SQL في BigQuery، جرِّب كتابة "أشجار السرو" في شريط البحث. هذا هو العمل الفني نفسه(
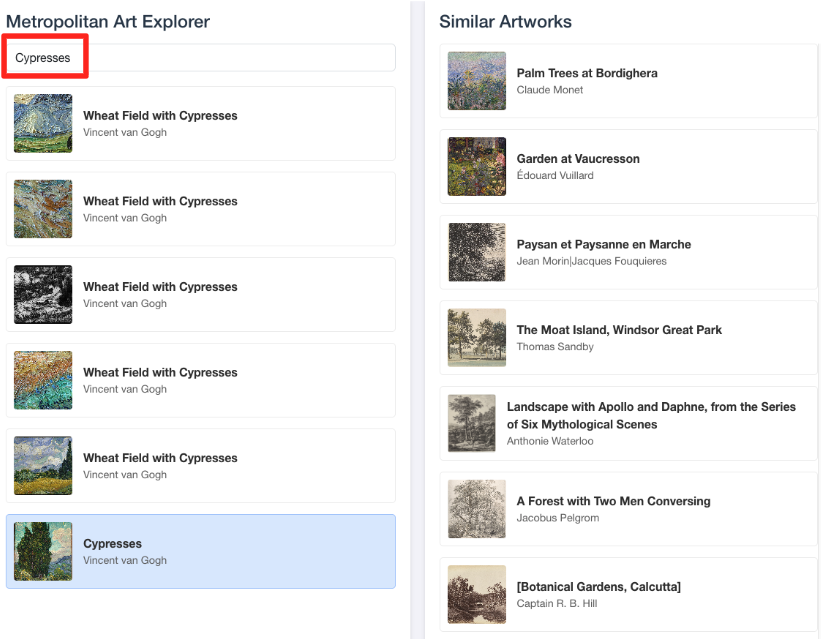
object_id=436535) الذي استخدمته في طلب البحثML.DISTANCE. بعد ذلك، انقر على صورة أشجار السرو عندما تظهر في اللوحة اليمنى، وستلاحظ النتائج على اليسار. يعرض التطبيق الأعمال الفنية الأكثر تشابهًا، ما يوضّح بشكل مرئي فعالية البحث عن التشابه المتجهي الذي أنشأته.
7. تنظيف البيئة
لتجنُّب تكبُّد رسوم مستقبلية على حسابك على Google Cloud مقابل الموارد المستخدَمة في هذا الدرس العملي، عليك حذف الموارد التي أنشأتها.
نفِّذ الأوامر التالية في نافذة Cloud Shell لإزالة حساب الخدمة وعملية ربط BigQuery وحزمة GCS ومجموعة بيانات BigQuery.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
إزالة عملية الربط بأداة BigQuery وحزمة GCS
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
حذف مجموعة بيانات BigQuery
أخيرًا، احذف مجموعة بيانات BigQuery. لا يمكن التراجع عن هذا الأمر. تزيل العلامة -f (فرض) مجموعة البيانات وجميع جداولها بدون طلب تأكيد.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. تهانينا!
لقد أنشأت بنجاح مسار بيانات شاملاً مستندًا إلى الذكاء الاصطناعي.
بدأت بملف CSV أولي في حزمة GCS، واستخدمت واجهة BigQuery Data Prep ذات الرمز المنخفض لنقل بيانات JSON المعقّدة وتسويتها، وأنشأت نموذجًا قويًا عن بُعد في BQML لإنشاء عمليات تضمين متّجهة عالية الجودة باستخدام نموذج Gemini، ونفّذت طلب بحث عن التشابه للعثور على عناصر ذات صلة.
أصبحت الآن مجهّزًا بالنمط الأساسي لإنشاء سير عمل مستنِد إلى الذكاء الاصطناعي على Google Cloud، ما يتيح لك تحويل البيانات الأولية إلى تطبيقات ذكية بسرعة وسهولة.
الخطوات التالية
- عرض النتائج بشكل مرئي في Looker Studio: اربط جدول
artwork_embeddingsBigQuery مباشرةً بأداة Looker Studio (بدون أي تكلفة). يمكنك إنشاء لوحة بيانات تفاعلية يمكن للمستخدمين من خلالها اختيار عمل فني والاطّلاع على معرض مرئي لأكثر الأعمال الفنية تشابهًا بدون كتابة أي رمز للواجهة الأمامية. - الأتمتة باستخدام "طلبات البحث المجدوَلة": لست بحاجة إلى أداة تنسيق معقّدة لإبقاء تضميناتك محدَّثة. استخدِم ميزة الاستعلامات المجدوَلة المضمّنة في BigQuery لإعادة تنفيذ الاستعلام
ML.GENERATE_TEXT_EMBEDDINGتلقائيًا بشكل يومي أو أسبوعي. - إنشاء تطبيق باستخدام Gemini CLI: استخدِم Gemini CLI لإنشاء تطبيق كامل من خلال وصف متطلباتك بنص عادي. يتيح لك ذلك إنشاء نموذج أولي سريع للبحث عن التشابه بدون كتابة رمز Python البرمجي يدويًا.
- قراءة المستندات: