
1. ভূমিকা
ডেটা বিশ্লেষকরা প্রায়শই JSON পেলোডের মতো আধা-কাঠামোগত বিন্যাসে আবদ্ধ মূল্যবান ডেটার সম্মুখীন হন। বিশ্লেষণ এবং মেশিন লার্নিংয়ের জন্য এই ডেটা নিষ্কাশন ও প্রস্তুত করা ঐতিহ্যগতভাবে একটি উল্লেখযোগ্য প্রযুক্তিগত বাধা ছিল, যার জন্য সাধারণত জটিল ETL স্ক্রিপ্ট এবং একটি ডেটা ইঞ্জিনিয়ারিং দলের হস্তক্ষেপের প্রয়োজন হতো।
এই কোডল্যাবটি ডেটা অ্যানালিস্টদের স্বাধীনভাবে এই প্রতিবন্ধকতাটি কাটিয়ে ওঠার জন্য একটি প্রযুক্তিগত রূপরেখা প্রদান করে। এটি একটি এন্ড-টু-এন্ড এআই পাইপলাইন তৈরির জন্য একটি "লো-কোড" পদ্ধতি প্রদর্শন করে। আপনি শিখবেন কীভাবে শুধুমাত্র BigQuery Studio-এর মধ্যে উপলব্ধ টুলগুলো ব্যবহার করে Google Cloud Storage-এর একটি সাধারণ CSV ফাইল থেকে একটি এআই-চালিত সুপারিশ ফিচারকে কার্যকর করা যায়।
এর প্রধান উদ্দেশ্য হলো একটি শক্তিশালী, দ্রুত এবং বিশ্লেষক-বান্ধব কর্মপ্রবাহ প্রদর্শন করা, যা জটিল ও কোড-নির্ভর প্রক্রিয়াগুলোকে অতিক্রম করে আপনার ডেটা থেকে প্রকৃত ব্যবসায়িক মূল্য তৈরি করে।
পূর্বশর্ত
- গুগল ক্লাউড কনসোল সম্পর্কে প্রাথমিক ধারণা
- কমান্ড লাইন ইন্টারফেস এবং গুগল ক্লাউড শেলে প্রাথমিক দক্ষতা
আপনি যা শিখবেন
- BigQuery Data Preparation ব্যবহার করে কীভাবে সরাসরি গুগল ক্লাউড স্টোরেজ থেকে একটি CSV ফাইল গ্রহণ ও রূপান্তর করা যায়।
- আপনার ডেটার মধ্যে থাকা নেস্টেড JSON স্ট্রিং পার্স এবং ফ্ল্যাটেন করতে কীভাবে নো-কোড ট্রান্সফরমেশন ব্যবহার করবেন।
- টেক্সট এমবেডিংয়ের জন্য ভার্টেক্স এআই ফাউন্ডেশন মডেলের সাথে সংযোগ স্থাপনকারী একটি বিগকোয়েরি এমএল রিমোট মডেল কীভাবে তৈরি করবেন।
- টেক্সচুয়াল ডেটাকে নিউমেরিক্যাল ভেক্টরে রূপান্তর করতে
ML.GENERATE_TEXT_EMBEDDINGফাংশনটি কীভাবে ব্যবহার করবেন। - আপনার ডেটাসেটের মধ্যে কোসাইন সিমিলারিটি গণনা করতে এবং সবচেয়ে সাদৃশ্যপূর্ণ আইটেমগুলো খুঁজে বের করতে কীভাবে
ML.DISTANCEফাংশনটি ব্যবহার করবেন।
আপনার যা যা লাগবে
- একটি গুগল ক্লাউড অ্যাকাউন্ট এবং গুগল ক্লাউড প্রজেক্ট
- ক্রোমের মতো একটি ওয়েব ব্রাউজার
মূল ধারণা
- BigQuery ডেটা প্রস্তুতি: BigQuery Studio-এর একটি টুল যা ডেটা পরিষ্কার এবং প্রস্তুতির জন্য একটি ইন্টারেক্টিভ, ভিজ্যুয়াল ইন্টারফেস প্রদান করে। এটি ডেটা রূপান্তরের পরামর্শ দেয় এবং ব্যবহারকারীদের ন্যূনতম কোড ব্যবহার করে ডেটা পাইপলাইন তৈরি করতে সাহায্য করে।
- BQML রিমোট মডেল: একটি BigQuery ML অবজেক্ট যা Vertex AI-তে হোস্ট করা কোনো মডেলের (যেমন Gemini) প্রক্সি হিসেবে কাজ করে। এটি আপনাকে পরিচিত SQL সিনট্যাক্স ব্যবহার করে শক্তিশালী, প্রি-ট্রেইনড AI মডেল চালু করার সুযোগ দেয়।
- ভেক্টর এমবেডিং: ডেটার, যেমন টেক্সট বা ছবির, একটি সাংখ্যিক উপস্থাপনা। এই কোডল্যাবে, আমরা শিল্পকর্মের টেক্সট বিবরণকে ভেক্টরে রূপান্তর করব, যেখানে একই ধরনের বিবরণের ফলে তৈরি হওয়া ভেক্টরগুলো বহুমাত্রিক স্থানে একে অপরের "কাছাকাছি" থাকে।
- কোসাইন সিমিলারিটি: দুটি ভেক্টর কতটা সাদৃশ্যপূর্ণ তা নির্ধারণ করতে ব্যবহৃত একটি গাণিতিক পরিমাপ। এটি আমাদের রিকমেন্ডেশন ইঞ্জিনের লজিকের মূল ভিত্তি, যা
ML.DISTANCEফাংশন দ্বারা 'নিকটতম' (সবচেয়ে সাদৃশ্যপূর্ণ) শিল্পকর্মগুলো খুঁজে বের করতে ব্যবহৃত হয়।
২. সেটআপ এবং প্রয়োজনীয়তা
ক্লাউড শেল শুরু করুন
যদিও গুগল ক্লাউড আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালনা করা যায়, এই কোডল্যাবে আপনি গুগল ক্লাউড শেল ব্যবহার করবেন, যা ক্লাউডে চালিত একটি কমান্ড লাইন পরিবেশ।
গুগল ক্লাউড কনসোল থেকে, উপরের ডানদিকের টুলবারে থাকা ক্লাউড শেল আইকনটিতে ক্লিক করুন:

পরিবেশটি প্রস্তুত করতে এবং এর সাথে সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগবে। এটি শেষ হলে, আপনি এইরকম কিছু দেখতে পাবেন:

এই ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার সমস্ত কাজ একটি ব্রাউজারের মধ্যেই করা যাবে। আপনাকে কিছুই ইনস্টল করতে হবে না।
প্রয়োজনীয় এপিআইগুলো সক্রিয় করুন এবং পরিবেশ কনফিগার করুন।
ক্লাউড শেলের ভিতরে, আপনার প্রজেক্ট আইডি সেট করতে, এনভায়রনমেন্ট ভেরিয়েবল নির্ধারণ করতে এবং এই কোডল্যাবের জন্য প্রয়োজনীয় সমস্ত এপিআই সক্রিয় করতে নিম্নলিখিত কমান্ডগুলি চালান।
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
একটি BigQuery ডেটাসেট এবং একটি GCS বাকেট তৈরি করুন
আমাদের টেবিলগুলো রাখার জন্য একটি নতুন BigQuery ডেটাসেট এবং আমাদের সোর্স CSV ফাইলটি সংরক্ষণের জন্য একটি Google Cloud Storage বাকেট তৈরি করুন।
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
নমুনা ডেটা প্রস্তুত করুন এবং আপলোড করুন
নমুনা CSV ফাইলটি ধারণকারী GitHub রিপোজিটরিটি ক্লোন করুন এবং তারপরে এটি আপনার এইমাত্র তৈরি করা GCS বাকেটে আপলোড করুন।
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
৩. ডেটা প্রস্তুতি সহ GCS থেকে BigQuery-তে রূপান্তর
এই অংশে, আমরা একটি ভিজ্যুয়াল, নো-কোড ইন্টারফেস ব্যবহার করে GCS থেকে আমাদের CSV ফাইলটি গ্রহণ করব, সেটিকে পরিমার্জন করব এবং একটি নতুন BigQuery টেবিলে লোড করব।
ডেটা প্রস্তুতি শুরু করুন এবং উৎসের সাথে সংযোগ স্থাপন করুন
- গুগল ক্লাউড কনসোলে, BigQuery Studio-তে যান।
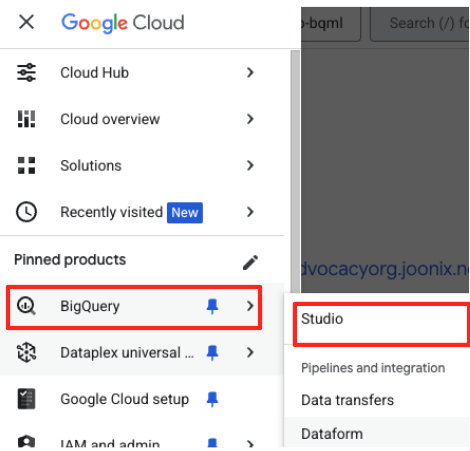
- স্বাগত পাতায়, শুরু করার জন্য ডেটা প্রস্তুতি কার্ডটিতে ক্লিক করুন।
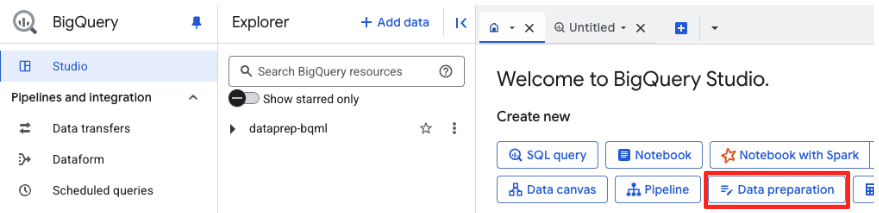
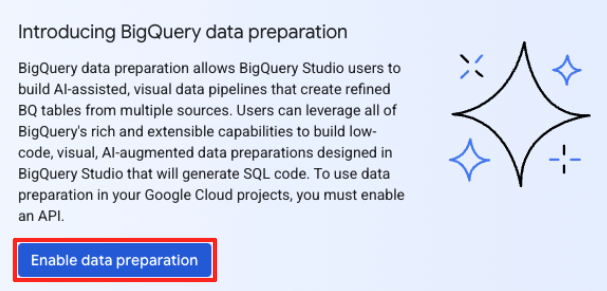
- আপনি যদি প্রথমবার এটি ব্যবহার করেন, তাহলে আপনাকে প্রয়োজনীয় এপিআইগুলো সক্রিয় করতে হতে পারে। 'Gemini for Google Cloud API' এবং 'BigQuery Unified API' উভয়ের জন্য 'Enable'-এ ক্লিক করুন। এগুলো সক্রিয় হয়ে গেলে, আপনি এই প্যানেলটি বন্ধ করতে পারেন।
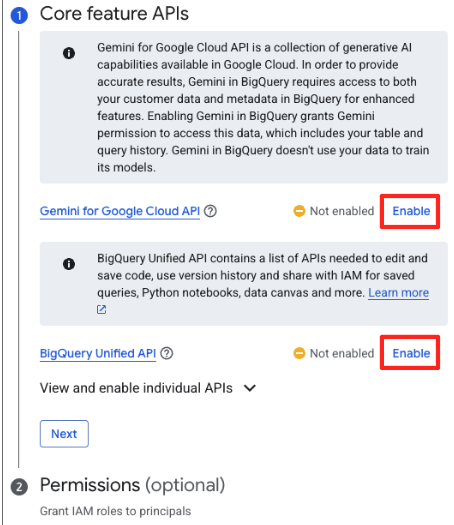
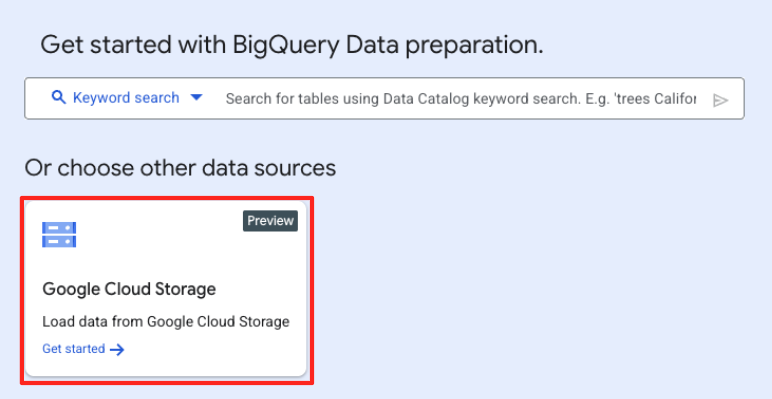
- মূল ডেটা প্রস্তুতি উইন্ডোতে, 'অন্যান্য ডেটা উৎস নির্বাচন করুন'-এর অধীনে, গুগল ক্লাউড স্টোরেজ-এ ক্লিক করুন। এটি ডানদিকে 'ডেটা প্রস্তুত করুন' প্যানেলটি খুলবে।
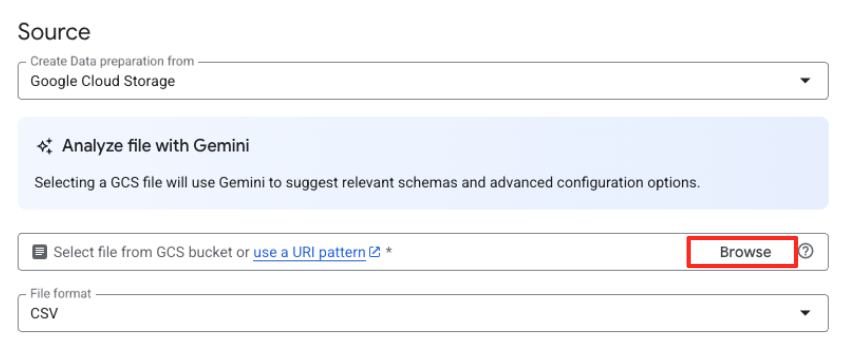
- আপনার উৎস ফাইলটি নির্বাচন করতে ব্রাউজ বোতামে ক্লিক করুন।
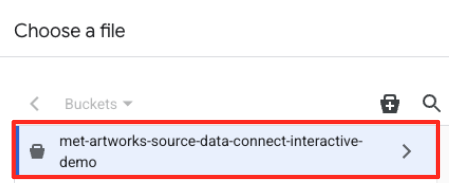
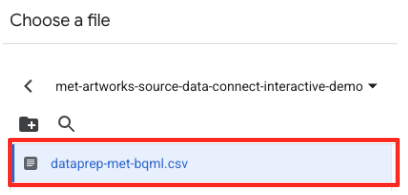
- আপনার পূর্বে তৈরি করা GCS বাকেটটিতে (
met-artworks-source-...) যান এবংdataprep-met-bqml.csvফাইলটি নির্বাচন করুন। সিলেক্ট-এ ক্লিক করুন।
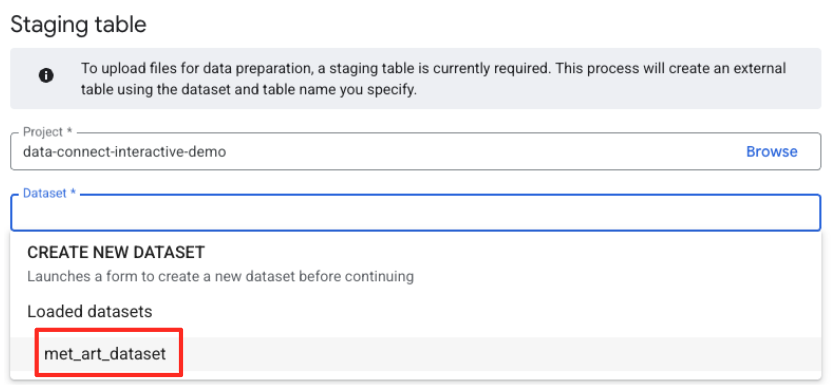
- এরপরে, আপনাকে একটি স্টেজিং টেবিল কনফিগার করতে হবে।
- ডেটা সেটের জন্য, আপনার তৈরি করা
met_art_datasetটি নির্বাচন করুন। - টেবিলের নামের জায়গায় একটি নাম লিখুন, যেমন,
temp। - তৈরি করুন-এ ক্লিক করুন।
ডেটা রূপান্তর ও পরিষ্কার করুন
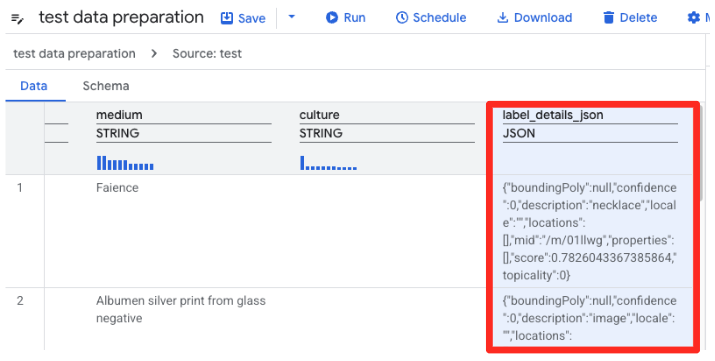
- BigQuery-এর ডেটা প্রিপারেশন এখন CSV-টির একটি প্রিভিউ লোড করবে।
label_details_jsonকলামটি খুঁজুন, যেটিতে দীর্ঘ JSON স্ট্রিংটি রয়েছে। কলাম হেডারটি সিলেক্ট করতে সেটির উপর ক্লিক করুন।
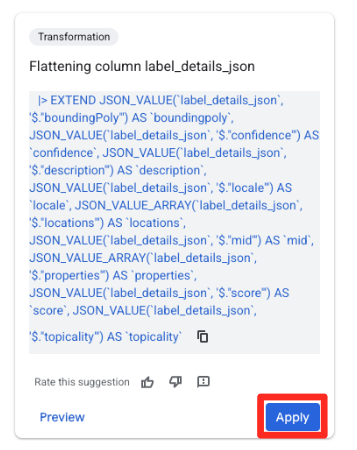
- ডানদিকের সাজেশন্স প্যানেলে, BigQuery-এর Gemini স্বয়ংক্রিয়ভাবে প্রাসঙ্গিক ট্রান্সফরমেশনগুলোর পরামর্শ দেবে। 'Flattening column
label_details_json' কার্ডটিতে থাকা অ্যাপ্লাই (Apply) বোতামে ক্লিক করুন। এটি নেস্টেড ফিল্ডগুলোকে (description,score, ইত্যাদি) তাদের নিজস্ব টপ-লেভেল কলামে এক্সট্র্যাক্ট করবে।
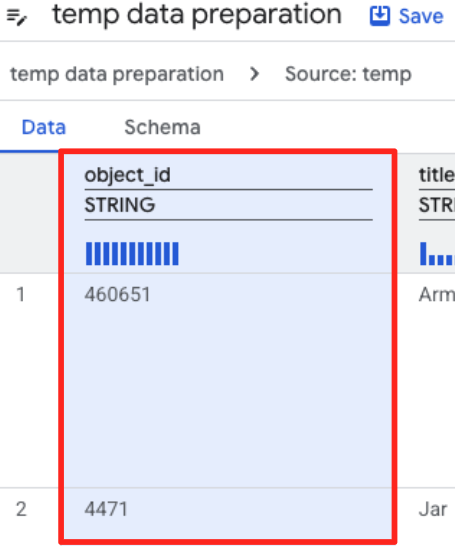
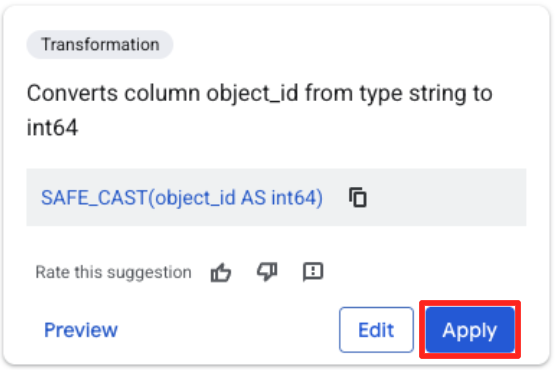
- `object_id` কলামে ক্লিক করুন, এবং "Converts column
object_idfrom typestringtoint64" বিকল্পের `apply` বোতামে ক্লিক করুন।
গন্তব্য নির্ধারণ করুন এবং কাজটি চালান
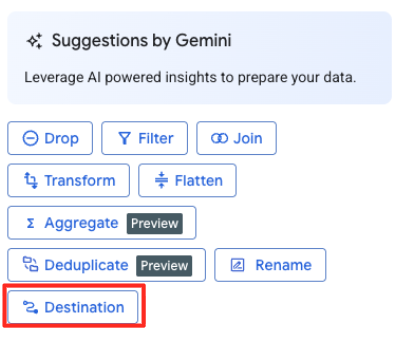
- ডানদিকের প্যানেলে, আপনার ট্রান্সফরমেশনের আউটপুট কনফিগার করতে ডেস্টিনেশন বাটনে ক্লিক করুন।
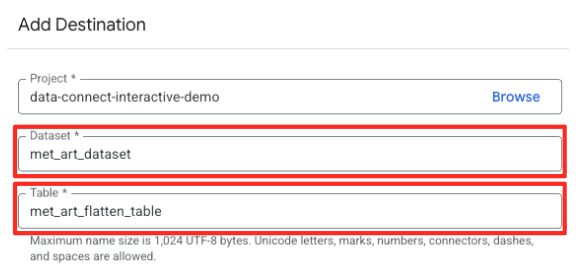
- গন্তব্যের বিবরণ সেট করুন:
- ডেটা সেটটি
met_art_datasetদিয়ে আগে থেকেই পূরণ করা উচিত। - আউটপুটের জন্য একটি নতুন টেবিলের নাম লিখুন:
met_art_flatten_table। - সংরক্ষণ করুন-এ ক্লিক করুন।
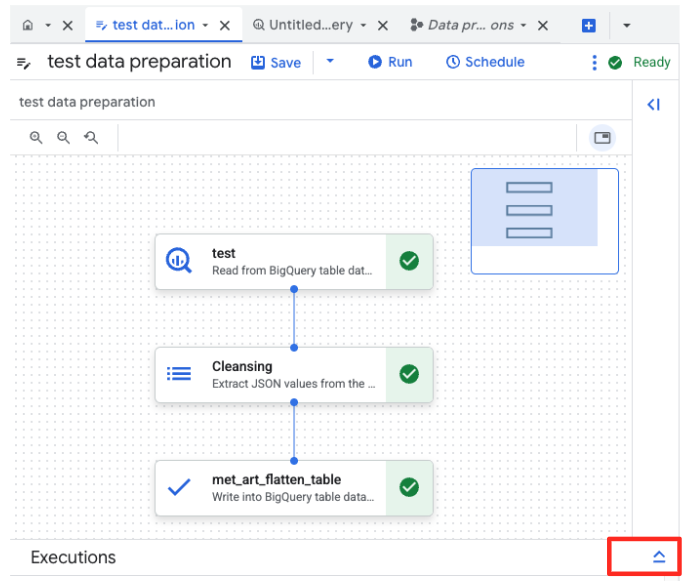
- রান বাটনে ক্লিক করুন এবং ডেটা প্রস্তুতির কাজটি সম্পন্ন হওয়া পর্যন্ত অপেক্ষা করুন।
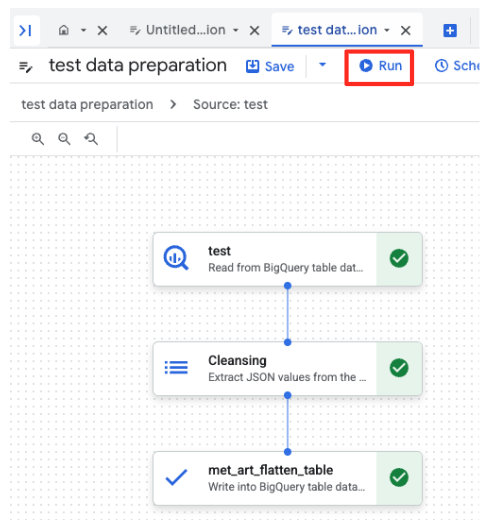
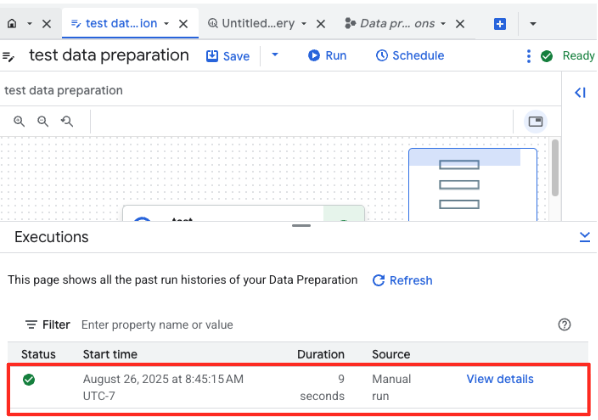
- আপনি পৃষ্ঠার নীচে থাকা 'এক্সিকিউশন' ট্যাবে কাজটি কতটা এগিয়েছে তা পর্যবেক্ষণ করতে পারবেন। কিছুক্ষণ পরেই কাজটি সম্পন্ন হবে।
৪. BQML ব্যবহার করে ভেক্টর এমবেডিং তৈরি করা
এখন যেহেতু আমাদের ডেটা পরিচ্ছন্ন ও সুসংগঠিত, আমরা মূল এআই কাজটি করার জন্য BigQuery ML ব্যবহার করব: শিল্পকর্মের পাঠ্য বিবরণগুলোকে সাংখ্যিক ভেক্টর এমবেডিং-এ রূপান্তর করা।
একটি BigQuery সংযোগ তৈরি করুন
BigQuery-কে Vertex AI পরিষেবাগুলির সাথে যোগাযোগ করার অনুমতি দিতে, আপনাকে প্রথমে একটি BigQuery সংযোগ তৈরি করতে হবে।
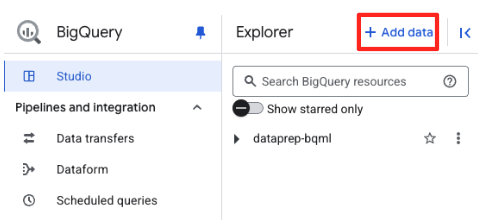
- BigQuery Studio-এর Explorer প্যানেলে, "+ Add data" বোতামটিতে ক্লিক করুন।
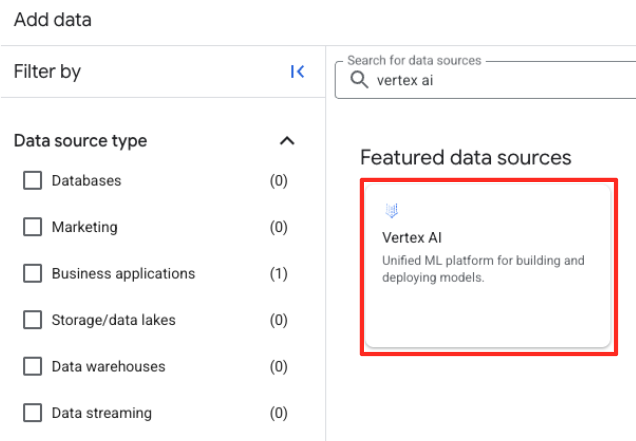
- ডানদিকের প্যানেলে, সার্চ বারে
Vertex AIটাইপ করুন। এটি নির্বাচন করুন এবং তারপর ফিল্টার করা তালিকা থেকে BigQuery federation নির্বাচন করুন।
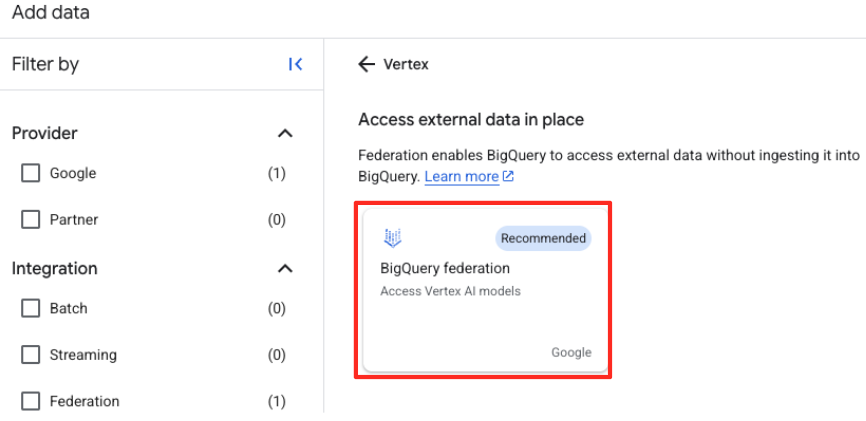
- এটি এক্সটার্নাল ডেটা সোর্স ফর্মটি খুলবে। নিম্নলিখিত বিবরণগুলি পূরণ করুন:
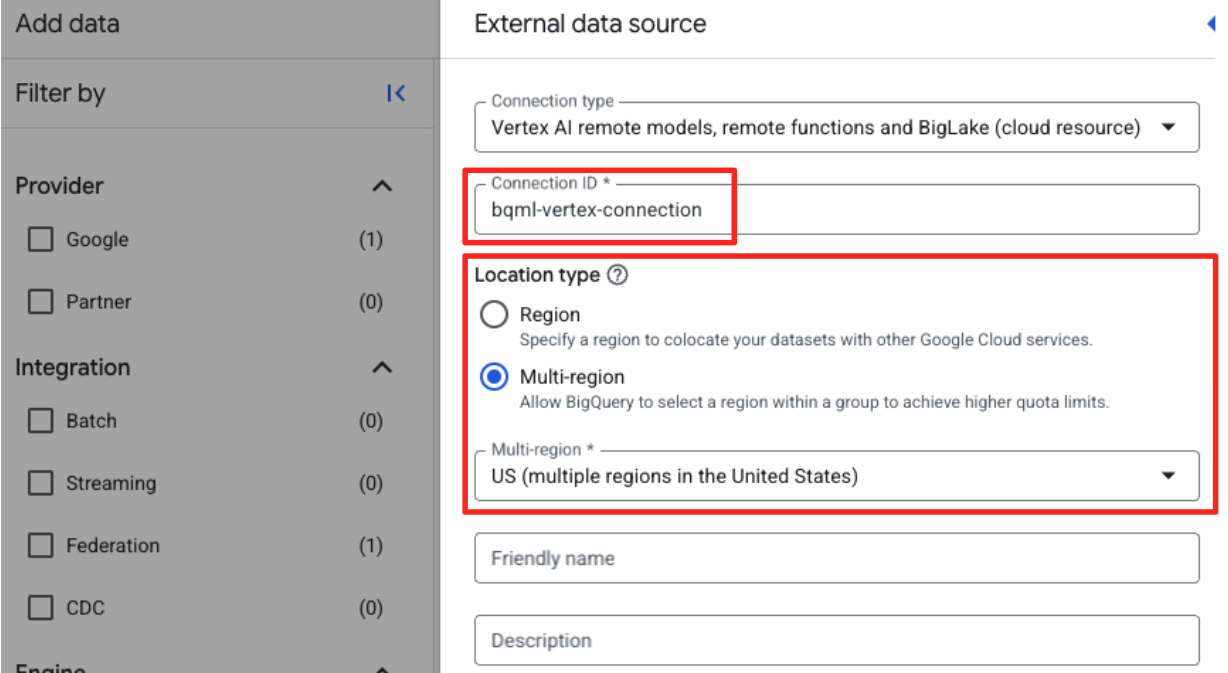
- সংযোগ আইডি: সংযোগ আইডিটি লিখুন (যেমন,
bqml-vertex-connection) - অবস্থানের ধরণ: নিশ্চিত করুন যে বহু-অঞ্চল নির্বাচন করা আছে।
- অবস্থান: অবস্থান নির্বাচন করুন (যেমন,
US)।
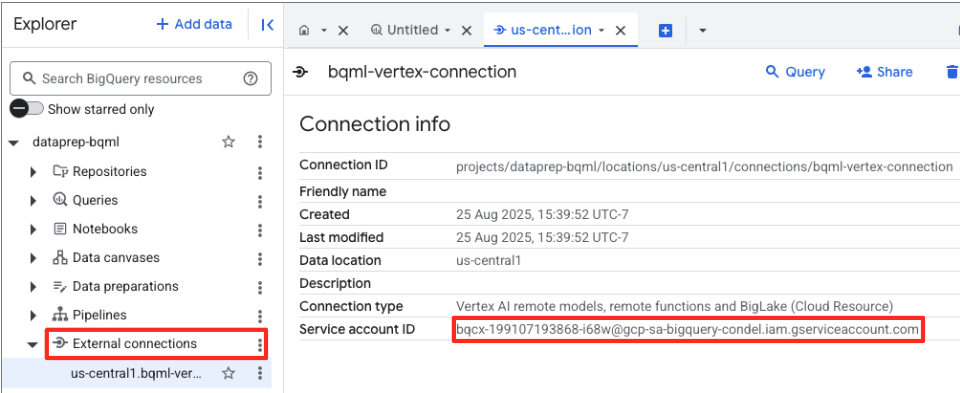
- সংযোগটি তৈরি হয়ে গেলে, একটি নিশ্চিতকরণ ডায়ালগ বক্স আসবে। এক্সপ্লোরার ট্যাবে থাকা ‘গো টু কানেকশন’ বা ‘এক্সটার্নাল কানেকশনস’-এ ক্লিক করুন। সংযোগের বিবরণ পৃষ্ঠায়, সম্পূর্ণ আইডিটি আপনার ক্লিপবোর্ডে কপি করুন। এটিই সেই সার্ভিস অ্যাকাউন্ট আইডেন্টিটি যা BigQuery, Vertex AI-কে কল করার জন্য ব্যবহার করবে।
- Google Cloud Console-এর নেভিগেশন মেনুতে, IAM & admin > IAM-এ যান।
- 'অ্যাক্সেস দিন' বোতামে ক্লিক করুন
- পূর্ববর্তী ধাপে কপি করা সার্ভিস অ্যাকাউন্টটি 'New principals' ফিল্ডে পেস্ট করুন।
- Role ড্রপডাউনে ' Vertex AI user ' নির্ধারণ করুন এবং 'Save'-এ ক্লিক করুন।
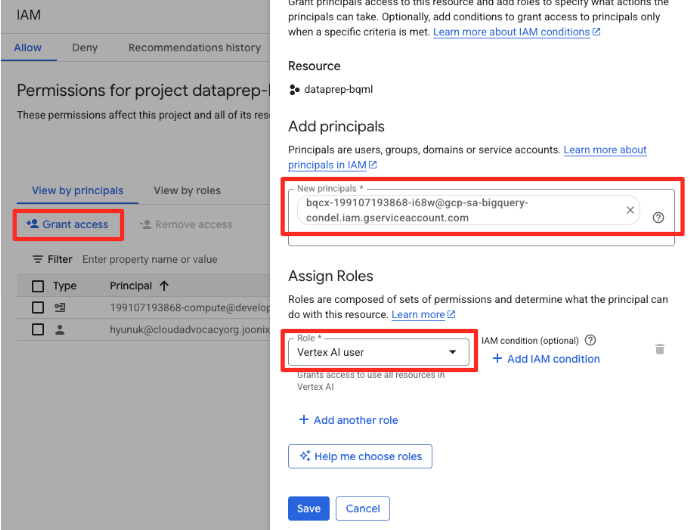
এই গুরুত্বপূর্ণ পদক্ষেপটি নিশ্চিত করে যে, আপনার পক্ষ থেকে Vertex AI মডেল ব্যবহার করার জন্য BigQuery-এর যথাযথ অনুমোদন রয়েছে।
একটি রিমোট মডেল তৈরি করুন
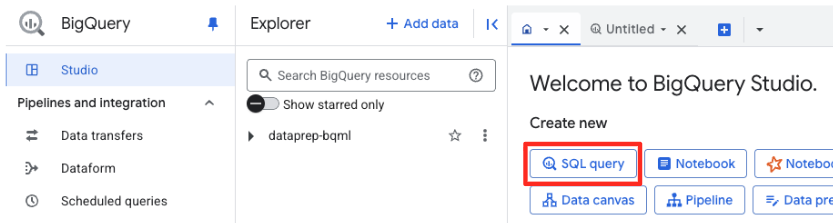
BigQuery Studio-তে একটি নতুন SQL এডিটর ট্যাব খুলুন। এখানেই আপনি Gemini-র সাথে সংযোগকারী BQML মডেলটি সংজ্ঞায়িত করবেন।
এই স্টেটমেন্টটি কোনো নতুন মডেলকে প্রশিক্ষণ দেয় না। এটি কেবল BigQuery-তে একটি রেফারেন্স তৈরি করে, যা আপনার অনুমোদিত সংযোগটি ব্যবহার করে একটি শক্তিশালী, পূর্ব-প্রশিক্ষিত gemini-embedding-001 মডেলকে নির্দেশ করে।
নিচের সম্পূর্ণ SQL স্ক্রিপ্টটি কপি করে BigQuery এডিটরে পেস্ট করুন।
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
এমবেডিং তৈরি করুন
এখন, আমরা আমাদের BQML মডেল ব্যবহার করে ভেক্টর এমবেডিং তৈরি করব। প্রতিটি সারির জন্য শুধু একটি টেক্সট লেবেল রূপান্তর করার পরিবর্তে, আমরা প্রতিটি শিল্পকর্মের জন্য একটি সমৃদ্ধ ও অধিক অর্থবহ 'সিমান্টিক সামারি' তৈরি করতে আরও উন্নত একটি পদ্ধতি ব্যবহার করব। এর ফলে উচ্চ-মানের এমবেডিং এবং আরও নির্ভুল সুপারিশ পাওয়া যাবে।
এই কোয়েরিটি একটি গুরুত্বপূর্ণ প্রাক-প্রক্রিয়াকরণ ধাপ সম্পাদন করে:
- এটি প্রথমে একটি অস্থায়ী টেবিল তৈরি করতে একটি
WITHক্লজ ব্যবহার করে। - এর ভেতরে, আমরা প্রতিটি
object_idGROUP BYএকটিমাত্র শিল্পকর্মের সমস্ত তথ্য একটি সারিতে একত্রিত করি। - আমরা
STRING_AGGফাংশনটি ব্যবহার করে সমস্ত আলাদা আলাদা পাঠ্য বিবরণ (যেমন 'Portrait', 'Woman', 'Oil on canvas') তাদের প্রাসঙ্গিকতা স্কোর অনুসারে সাজিয়ে একটি একক, পূর্ণাঙ্গ পাঠ্য স্ট্রিং-এ একত্রিত করি।
এই সম্মিলিত লেখাটি এআই-কে শিল্পকর্মটি সম্পর্কে আরও সমৃদ্ধ প্রেক্ষাপট প্রদান করে, যার ফলে আরও সূক্ষ্ম ও শক্তিশালী ভেক্টর এমবেডিং তৈরি হয়।
একটি নতুন SQL এডিটর ট্যাবে, নিম্নলিখিত কোয়েরিটি পেস্ট করে রান করুন:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
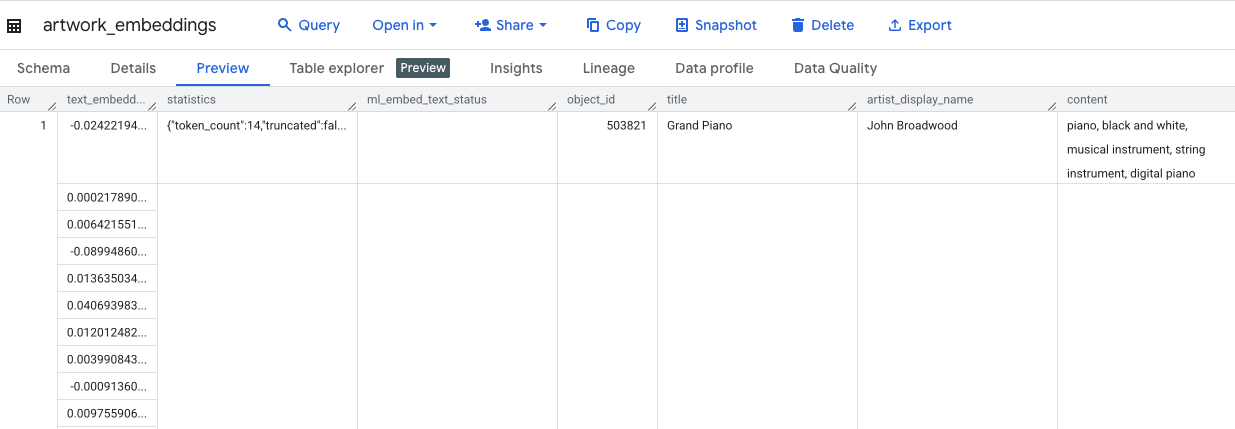
এই কোয়েরিটি সম্পন্ন হতে প্রায় ১০ মিনিট সময় লাগবে। কোয়েরিটি সম্পন্ন হলে, ফলাফলগুলো যাচাই করুন। এক্সপ্লোরার প্যানেলে, আপনার নতুন artwork_embeddings টেবিলটি খুঁজুন এবং সেটিতে ক্লিক করুন। টেবিল স্কিমা ভিউয়ারে, আপনি object_id , ভেক্টরগুলো ধারণকারী নতুন ml_generate_text_embedding_result কলামটি, এবং সোর্স টেক্সট হিসেবে ব্যবহৃত aggregated_labels কলামটি দেখতে পাবেন।
৫. SQL ব্যবহার করে অনুরূপ শিল্পকর্ম খুঁজে বের করা
আমাদের তৈরি করা উচ্চ-মানের ও তথ্যসমৃদ্ধ ভেক্টর এমবেডিংয়ের মাধ্যমে, বিষয়গতভাবে সাদৃশ্যপূর্ণ শিল্পকর্ম খুঁজে বের করা একটি SQL কোয়েরি চালানোর মতোই সহজ। আমরা ভেক্টরগুলোর মধ্যে কোসাইন সিমিলারিটি গণনা করার জন্য ML.DISTANCE ফাংশনটি ব্যবহার করি। যেহেতু আমাদের এমবেডিংগুলো একত্রিত টেক্সট থেকে তৈরি করা হয়েছে, তাই সাদৃশ্যের ফলাফলগুলো আরও নির্ভুল এবং প্রাসঙ্গিক হবে।
- একটি নতুন SQL এডিটর ট্যাবে নিম্নলিখিত কোয়েরিটি পেস্ট করুন। এই কোয়েরিটি একটি রিকমেন্ডেশন অ্যাপ্লিকেশনের মূল লজিককে অনুকরণ করে:
- এটি প্রথমে একটি নির্দিষ্ট শিল্পকর্মের ভেক্টর নির্বাচন করে (এই ক্ষেত্রে, ভ্যান গগের "সাইপ্রেসেস," যার
object_idহলো 436535)। - এরপর এটি সেই একক ভেক্টর এবং সারণিতে থাকা অন্য সব ভেক্টরের মধ্যেকার দূরত্ব গণনা করে।
- অবশেষে, এটি সবচেয়ে কাছাকাছি ১০টি মিল খুঁজে বের করার জন্য ফলাফলগুলোকে দূরত্ব অনুসারে সাজায় (কম দূরত্ব মানে বেশি সাদৃশ্য)।
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- কোয়েরিটি চালান। ফলাফলে
object_idগুলো তালিকাভুক্ত হবে, যার মধ্যে সবচেয়ে কাছের মিলগুলো সবার উপরে থাকবে। মূল শিল্পকর্মটি প্রথমে প্রদর্শিত হবে এবং এর দূরত্ব হবে ০। এটাই হলো একটি এআই সুপারিশ ইঞ্জিনকে চালিত করার মূল লজিক, এবং আপনি এটি শুধুমাত্র SQL ব্যবহার করে সম্পূর্ণভাবে BigQuery-এর মধ্যেই তৈরি করেছেন।
৬. (ঐচ্ছিক) ক্লাউড শেলে ডেমোটি চালানো
এই কোডল্যাবের ধারণাগুলোকে বাস্তবে রূপ দিতে, আপনার ক্লোন করা রিপোজিটরিটিতে একটি সাধারণ ওয়েব অ্যাপ্লিকেশন অন্তর্ভুক্ত রয়েছে। এই ঐচ্ছিক ডেমোটি আপনার তৈরি করা artwork_embeddings টেবিলটি ব্যবহার করে একটি ভিজ্যুয়াল সার্চ ইঞ্জিন পরিচালনা করে, যা আপনাকে এআই-চালিত সুপারিশগুলো বাস্তবে দেখতে দেয়।
ক্লাউড শেলে ডেমোটি চালানোর জন্য, এই ধাপগুলো অনুসরণ করুন:
- এনভায়রনমেন্ট ভেরিয়েবল সেট করুন: অ্যাপ্লিকেশনটি চালানোর আগে, আপনাকে PROJECT_ID এবং BIGQUERY_DATASET এনভায়রনমেন্ট ভেরিয়েবলগুলো সেট করতে হবে।
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- নির্ভরতাগুলো ইনস্টল করুন এবং ব্যাকএন্ড সার্ভার চালু করুন।
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- ফ্রন্টএন্ড অ্যাপ্লিকেশনটি চালানোর জন্য আপনার একটি দ্বিতীয় টার্মিনাল ট্যাবের প্রয়োজন হবে। একটি নতুন ক্লাউড শেল ট্যাব খোলার জন্য "+" আইকনে ক্লিক করুন।

- এখন, নতুন ট্যাবে, ডিপেন্ডেন্সি ইনস্টল করতে এবং ফ্রন্টএন্ড সার্ভার চালু করতে নিম্নলিখিত কমান্ডটি চালান।
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- অ্যাপ্লিকেশনটির প্রিভিউ দেখুন: ক্লাউড শেল টুলবারে, ওয়েব প্রিভিউ আইকনে ক্লিক করুন এবং পোর্ট 5173-এ প্রিভিউ নির্বাচন করুন। এটি একটি নতুন ব্রাউজার ট্যাব খুলবে যেখানে অ্যাপ্লিকেশনটি চালু থাকবে। এখন আপনি অ্যাপ্লিকেশনটি ব্যবহার করে শিল্পকর্ম অনুসন্ধান করতে এবং সাদৃশ্য অনুসন্ধানটি বাস্তবে দেখতে পারবেন।
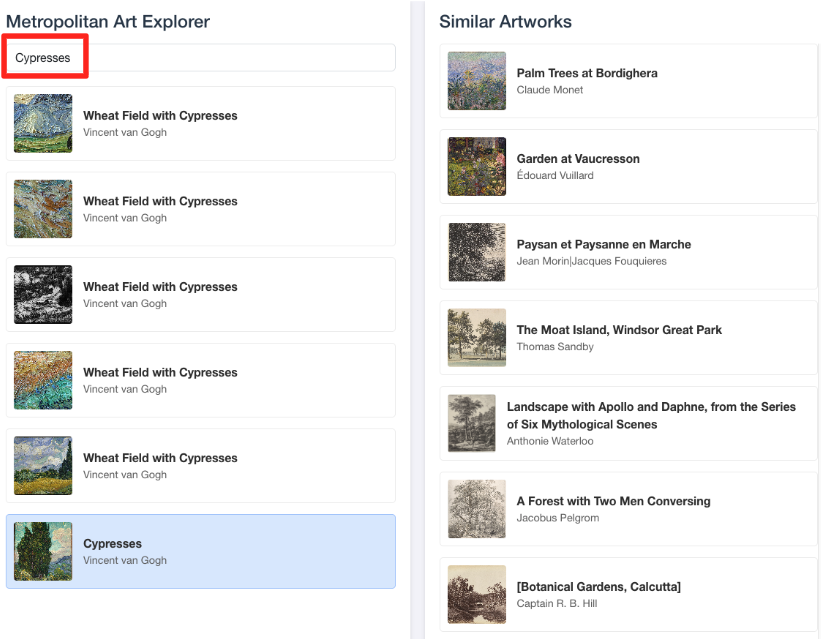
- BigQuery SQL এডিটরে আপনার করা কাজের সাথে এই ভিজ্যুয়াল ডেমোটিকে পুনরায় সংযুক্ত করতে, সার্চ বারে "Cypresses" টাইপ করার চেষ্টা করুন। এটি সেই একই শিল্পকর্ম (
object_id=436535) যা আপনিML.DISTANCEকোয়েরিতে ব্যবহার করেছিলেন। এরপর, বাম প্যানেলে Cypresses ছবিটি দেখা গেলে সেটির উপর ক্লিক করুন, আপনি ডানদিকে ফলাফলগুলো দেখতে পাবেন। অ্যাপ্লিকেশনটি সবচেয়ে সাদৃশ্যপূর্ণ শিল্পকর্মগুলো প্রদর্শন করে, যা আপনার তৈরি করা ভেক্টর সিমিলারিটি সার্চের শক্তিকে দৃশ্যত তুলে ধরে।
৭. আপনার পরিবেশ পরিষ্কার করা
এই কোডল্যাবে ব্যবহৃত রিসোর্সগুলোর জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে ভবিষ্যতে কোনো চার্জ হওয়া এড়াতে, আপনার তৈরি করা রিসোর্সগুলো মুছে ফেলা উচিত।
সার্ভিস অ্যাকাউন্ট, BigQuery কানেকশন, GCS Bucket এবং BigQuery ডেটাসেট অপসারণ করতে আপনার Cloud Shell টার্মিনালে নিম্নলিখিত কমান্ডগুলো চালান।
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
BigQuery সংযোগ এবং GCS বাকেট অপসারণ করুন
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
BigQuery ডেটাসেটটি মুছে ফেলুন
অবশেষে, BigQuery ডেটাসেটটি ডিলিট করুন। এই কমান্ডটি অপরিবর্তনীয়। -f (ফোর্স) ফ্ল্যাগটি কোনো নিশ্চিতকরণের অনুরোধ ছাড়াই ডেটাসেট এবং এর সমস্ত টেবিল মুছে ফেলে।
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
৮. অভিনন্দন!
আপনি সফলভাবে একটি এন্ড-টু-এন্ড, এআই-চালিত ডেটা পাইপলাইন তৈরি করেছেন।
আপনি একটি GCS বাকেটে থাকা একটি সাধারণ CSV ফাইল দিয়ে শুরু করেছেন, BigQuery Data Prep-এর লো-কোড ইন্টারফেস ব্যবহার করে জটিল JSON ডেটা ইনজেস্ট ও ফ্ল্যাটেন করেছেন, একটি Gemini মডেলের সাহায্যে উচ্চ-মানের ভেক্টর এমবেডিং তৈরি করার জন্য একটি শক্তিশালী BQML রিমোট মডেল তৈরি করেছেন, এবং সম্পর্কিত আইটেমগুলি খুঁজে বের করার জন্য একটি সিমিলারিটি সার্চ কোয়েরি চালিয়েছেন।
আপনি এখন গুগল ক্লাউডে এআই-সহায়তাযুক্ত ওয়ার্কফ্লো তৈরির মৌলিক কাঠামোটি জানেন, যা কাঁচা ডেটাকে দ্রুত ও সহজে বুদ্ধিমান অ্যাপ্লিকেশনে রূপান্তরিত করে।
এরপর কী?
- লুকার স্টুডিওতে আপনার ফলাফল ভিজ্যুয়ালাইজ করুন: আপনার
artwork_embeddingsBigQuery টেবিলটি সরাসরি লুকার স্টুডিওর সাথে সংযুক্ত করুন (এটি বিনামূল্যে!)। আপনি একটি ইন্টারেক্টিভ ড্যাশবোর্ড তৈরি করতে পারেন যেখানে ব্যবহারকারীরা কোনো ফ্রন্টএন্ড কোড না লিখেই একটি শিল্পকর্ম নির্বাচন করে সেটির সবচেয়ে সাদৃশ্যপূর্ণ শিল্পকর্মগুলোর একটি ভিজ্যুয়াল গ্যালারি দেখতে পারবেন। - শিডিউলড কোয়েরি দিয়ে স্বয়ংক্রিয় করুন: আপনার এমবেডিং আপ-টু-ডেট রাখতে কোনো জটিল অর্কেস্ট্রেশন টুলের প্রয়োজন নেই। BigQuery-এর বিল্ট-ইন শিডিউলড কোয়েরি ফিচারটি ব্যবহার করে দৈনিক বা সাপ্তাহিক ভিত্তিতে
ML.GENERATE_TEXT_EMBEDDINGকোয়েরিটি স্বয়ংক্রিয়ভাবে পুনরায় চালান। - জেমিনি সিএলআই দিয়ে একটি অ্যাপ তৈরি করুন: জেমিনি সিএলআই ব্যবহার করে শুধুমাত্র সাধারণ টেক্সটে আপনার প্রয়োজনীয়তা বর্ণনা করার মাধ্যমে একটি সম্পূর্ণ অ্যাপ্লিকেশন তৈরি করুন। এটি আপনাকে ম্যানুয়ালি পাইথন কোড না লিখেই আপনার সিমিলারিটি সার্চের জন্য দ্রুত একটি কার্যকরী প্রোটোটাইপ তৈরি করতে সাহায্য করে।
- ডকুমেন্টেশনটি পড়ুন: