
1. Einführung
Datenanalysten haben es oft mit wertvollen Daten zu tun, die in halbstrukturierten Formaten wie JSON-Payloads gespeichert sind. Das Extrahieren und Vorbereiten dieser Daten für Analysen und maschinelles Lernen war bisher eine erhebliche technische Hürde, die komplexe ETL-Skripts und die Unterstützung eines Data-Engineering-Teams erforderte.
Dieses Codelab bietet Datenanalysten eine technische Vorlage, mit der sie diese Herausforderung selbstständig meistern können. Es wird ein Low-Code-Ansatz zum Erstellen einer End-to-End-KI-Pipeline demonstriert. Sie erfahren, wie Sie mit den Tools in BigQuery Studio aus einer unformatierten CSV-Datei in Google Cloud Storage eine KI-basierte Empfehlungsfunktion erstellen.
Das Hauptziel besteht darin, einen robusten, schnellen und analystenfreundlichen Workflow zu demonstrieren, der über komplexe, codeintensive Prozesse hinausgeht, um aus Ihren Daten einen echten Geschäftswert zu generieren.
Voraussetzungen
- Grundlegende Kenntnisse der Google Cloud Console
- Grundkenntnisse in der Befehlszeile und Google Cloud Shell
Lerninhalte
- Hier erfahren Sie, wie Sie eine CSV-Datei mit BigQuery Data Preparation direkt aus Google Cloud Storage aufnehmen und transformieren.
- Hier erfahren Sie, wie Sie verschachtelte JSON-Strings in Ihren Daten mithilfe von No-Code-Transformationen parsen und zusammenfassen.
- So erstellen Sie ein BigQuery ML-Remote-Modell, das eine Verbindung zu einem Vertex AI Foundation Model für Texteinbettung herstellt.
- Wie Sie die Funktion
ML.GENERATE_TEXT_EMBEDDINGverwenden, um Textdaten in numerische Vektoren zu konvertieren. - Wie Sie mit der Funktion
ML.DISTANCEdie Kosinus-Ähnlichkeit berechnen und die ähnlichsten Elemente in Ihrem Dataset finden.
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome
Wichtige Konzepte
- BigQuery-Datenvorbereitung:Ein Tool in BigQuery Studio, das eine interaktive, visuelle Oberfläche zum Bereinigen und Vorbereiten von Daten bietet. Es schlägt Transformationen vor und ermöglicht es Nutzern, Datenpipelines mit minimalem Code zu erstellen.
- BQML-Remote-Modell:Ein BigQuery ML-Objekt, das als Proxy für ein in Vertex AI gehostetes Modell (z. B. Gemini) fungiert. Damit können Sie leistungsstarke, vortrainierte KI-Modelle mit der bekannten SQL-Syntax aufrufen.
- Vektoreinbettung:Eine numerische Darstellung von Daten wie Text oder Bildern. In diesem Codelab wandeln wir Textbeschreibungen von Kunstwerken in Vektoren um. Ähnliche Beschreibungen führen zu Vektoren, die im mehrdimensionalen Raum „näher“ beieinander liegen.
- Kosinus-Ähnlichkeit:Ein mathematisches Maß, mit dem bestimmt wird, wie ähnlich sich zwei Vektoren sind. Sie ist das Herzstück der Logik unserer Empfehlungs-Engine und wird von der Funktion
ML.DISTANCEverwendet, um die „nächstgelegenen“ (ähnlichsten) Grafiken zu finden.
2. Einrichtung und Anforderungen
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:

Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
Erforderliche APIs aktivieren und Umgebung konfigurieren
Führen Sie in Cloud Shell die folgenden Befehle aus, um Ihre Projekt-ID festzulegen, Umgebungsvariablen zu definieren und alle für dieses Codelab erforderlichen APIs zu aktivieren.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
BigQuery-Dataset und GCS-Bucket erstellen
Erstellen Sie ein neues BigQuery-Dataset für unsere Tabellen und einen Google Cloud Storage-Bucket zum Speichern unserer CSV-Quelldatei.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
Beispieldaten vorbereiten und hochladen
Klonen Sie das GitHub-Repository mit der CSV-Beispieldatei und laden Sie sie dann in den GCS-Bucket hoch, den Sie gerade erstellt haben.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. Datenvorbereitung: Daten von GCS nach BigQuery übertragen
In diesem Abschnitt verwenden wir eine visuelle No-Code-Oberfläche, um unsere CSV-Datei aus GCS aufzunehmen, zu bereinigen und in eine neue BigQuery-Tabelle zu laden.
Datenaufbereitung starten und Verbindung zur Quelle herstellen
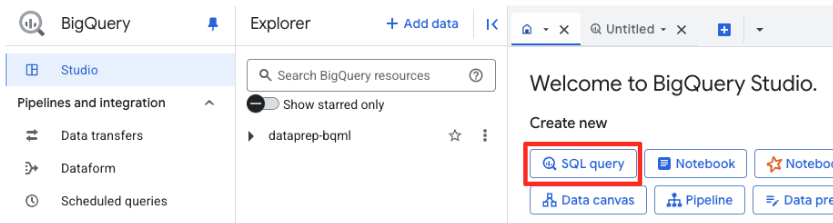
- Rufen Sie in der Google Cloud Console BigQuery Studio auf.
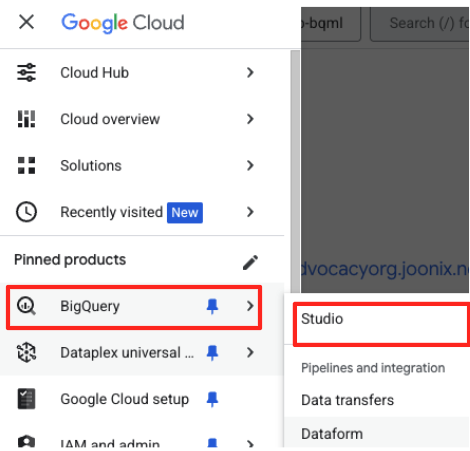
- Klicken Sie auf der Willkommensseite auf die Karte „Datenvorbereitung“, um zu beginnen.
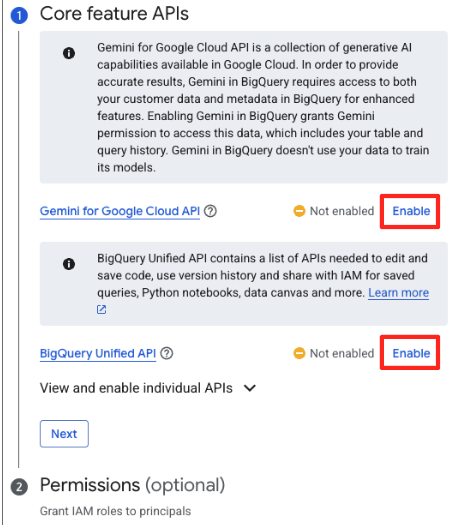
- Wenn Sie die Funktion zum ersten Mal verwenden, müssen Sie möglicherweise die erforderlichen APIs aktivieren. Klicken Sie sowohl für die „Gemini for Google Cloud API“ als auch für die „BigQuery Unified API“ auf „Aktivieren“. Sobald sie aktiviert sind, können Sie diesen Bereich schließen.
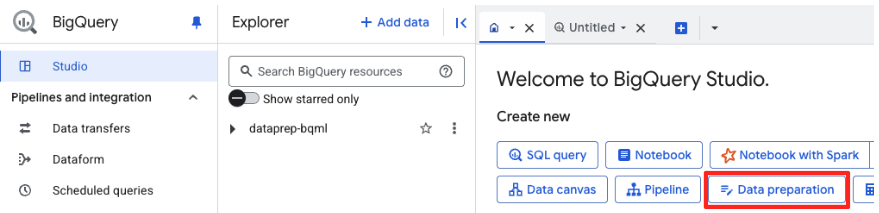
- Klicken Sie im Hauptfenster „Datenvorbereitung“ unter „Andere Datenquellen auswählen“ auf „Google Cloud Storage“. Dadurch wird der Bereich „Daten vorbereiten“ auf der rechten Seite geöffnet.
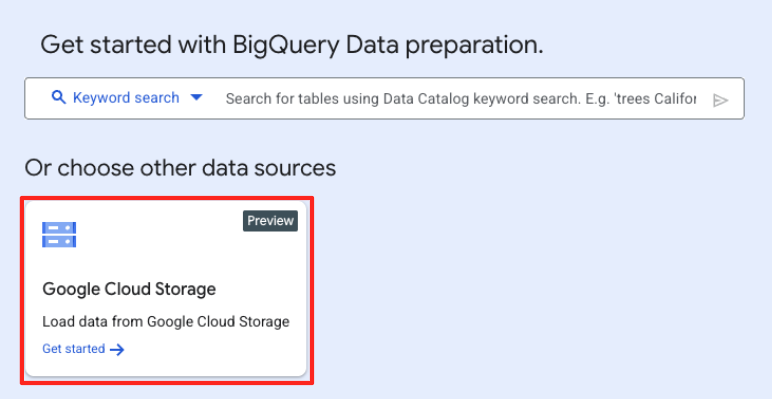
- Klicken Sie auf die Schaltfläche „Durchsuchen“, um die Quelldatei auszuwählen.
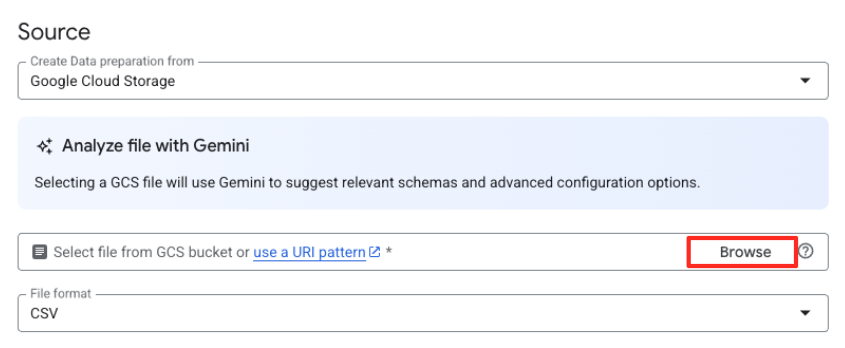
- Rufen Sie den GCS-Bucket auf, den Sie zuvor erstellt haben (
met-artworks-source-...), und wählen Sie die Dateidataprep-met-bqml.csvaus. Klicken Sie auf Auswählen.
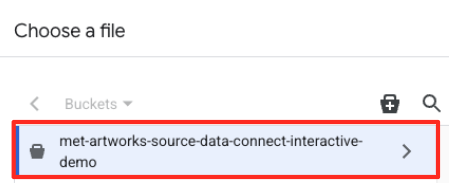
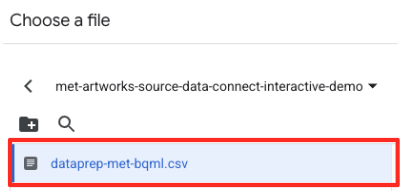
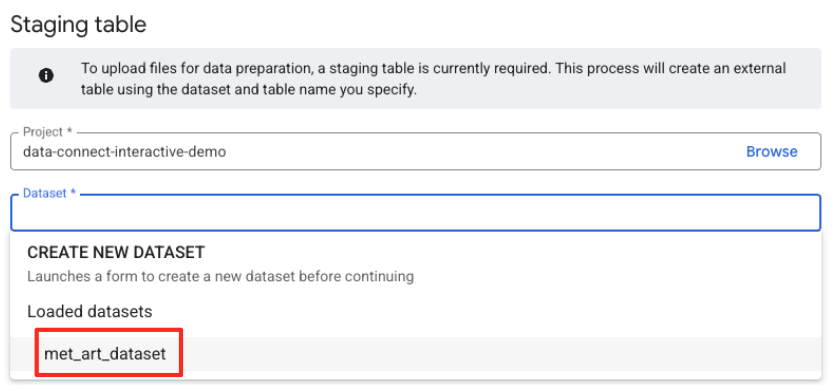
- Als Nächstes müssen Sie eine Staging-Tabelle konfigurieren.
- Wählen Sie unter „Dataset“ das von Ihnen erstellte
met_art_datasetaus. - Geben Sie unter „Tabellenname“ einen Namen ein, z. B.
temp. - Klicken Sie auf „Erstellen“.
Daten transformieren und bereinigen
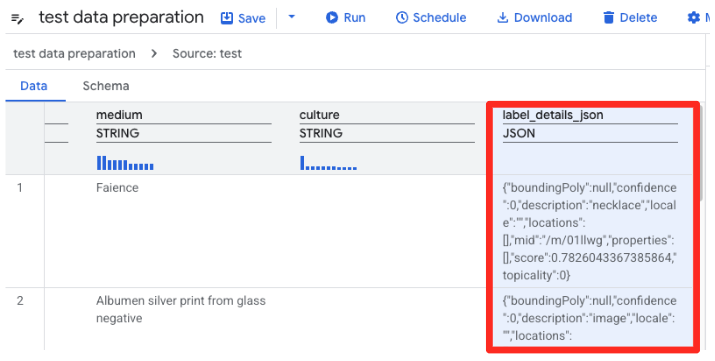
- In der BigQuery-Datenvorbereitung wird jetzt eine Vorschau der CSV-Datei geladen. Suchen Sie die Spalte
label_details_json, die den langen JSON-String enthält. Klicken Sie auf die Spaltenüberschrift, um sie auszuwählen.
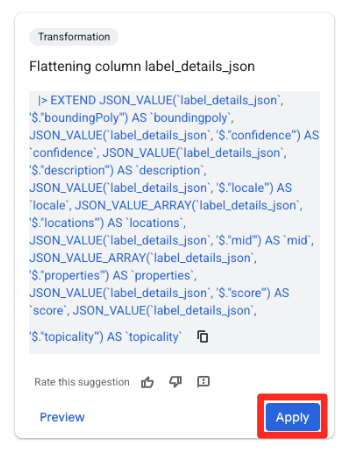
- Im Bereich Vorschläge auf der rechten Seite schlägt Gemini in BigQuery automatisch relevante Transformationen vor. Klicken Sie auf der Karte „Spalte
label_details_jsonzusammenführen“ auf die Schaltfläche „Übernehmen“. Dadurch werden die verschachtelten Felder (description,scoreusw.) in eigene Spalten der obersten Ebene extrahiert.
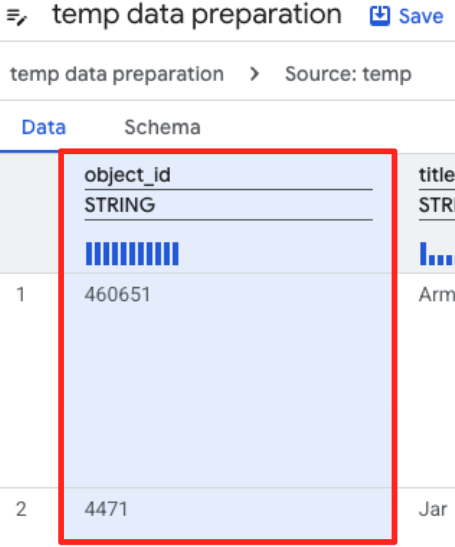
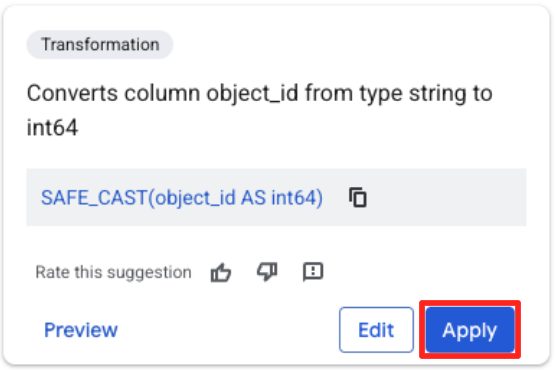
- Klicken Sie auf die Spalte „object_id“ und dann auf die Schaltfläche „Spalte
object_idvom Typstringinint64konvertieren“.
Ziel definieren und Job ausführen
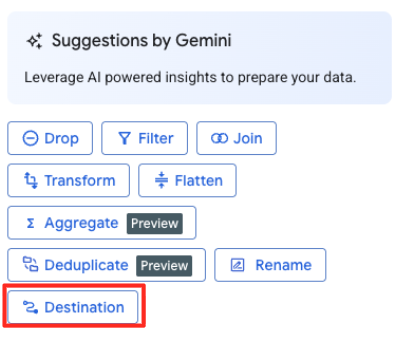
- Klicken Sie im rechten Bereich auf die Schaltfläche „Ziel“, um die Ausgabe der Transformation zu konfigurieren.
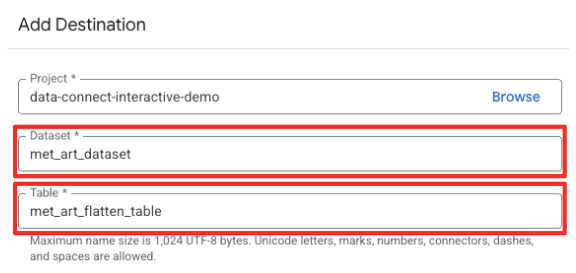
- Geben Sie die Zieldetails an:
- Das Dataset sollte bereits mit
met_art_datasetausgefüllt sein. - Geben Sie einen neuen Tabellennamen für die Ausgabe ein:
met_art_flatten_table. - Klicken Sie auf „Speichern“.
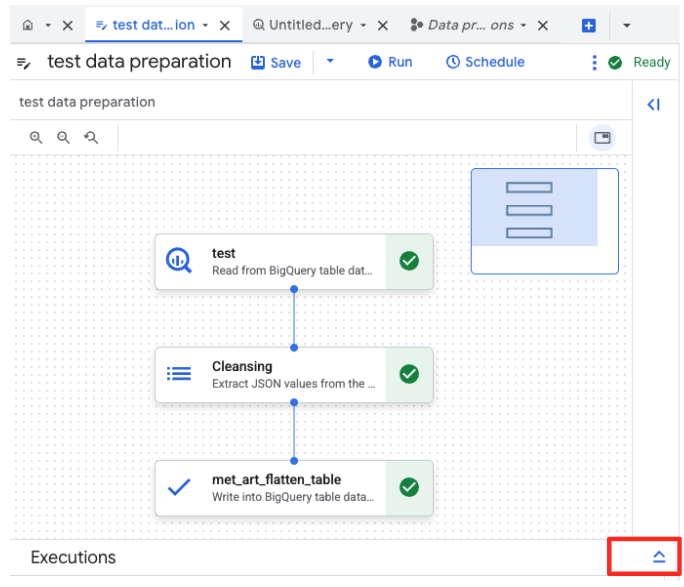
- Klicken Sie auf die Schaltfläche „Ausführen“ und warten Sie, bis der Job zur Datenvorbereitung abgeschlossen ist.
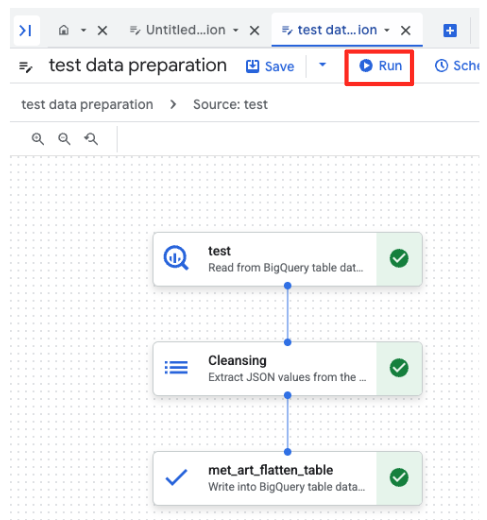
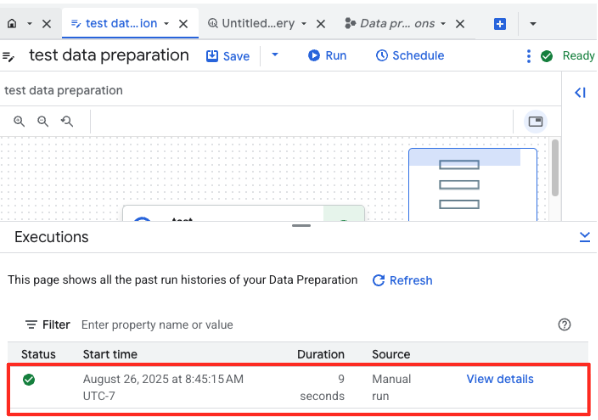
- Sie können den Fortschritt des Jobs unten auf der Seite auf dem Tab „Ausführungen“ verfolgen. Nach einigen Augenblicken ist der Job abgeschlossen.
4. Vektoreinbettungen mit BQML generieren
Nachdem unsere Daten bereinigt und strukturiert sind, verwenden wir BigQuery ML für die zentrale KI-Aufgabe: die Umwandlung der Textbeschreibungen der Kunstwerke in numerische Vektoreinbettungen.
BigQuery-Verbindung erstellen
Damit BigQuery mit Vertex AI-Diensten kommunizieren kann, müssen Sie zuerst eine BigQuery-Verbindung erstellen.
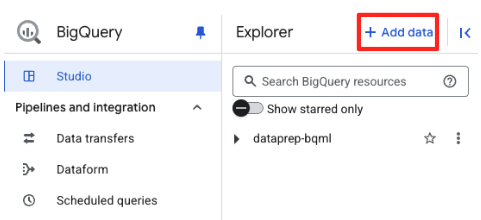
- Klicken Sie im Bereich „Explorer“ von BigQuery Studio auf die Schaltfläche „+ Daten hinzufügen“.
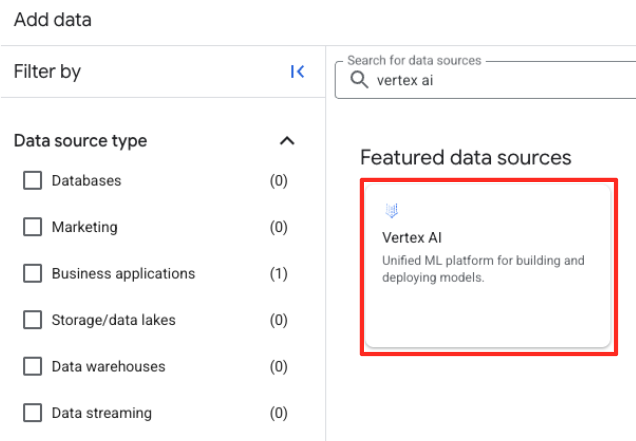
- Geben Sie im rechten Bereich in die Suchleiste
Vertex AIein. Wählen Sie es und dann „BigQuery-Föderation“ aus der gefilterten Liste aus.
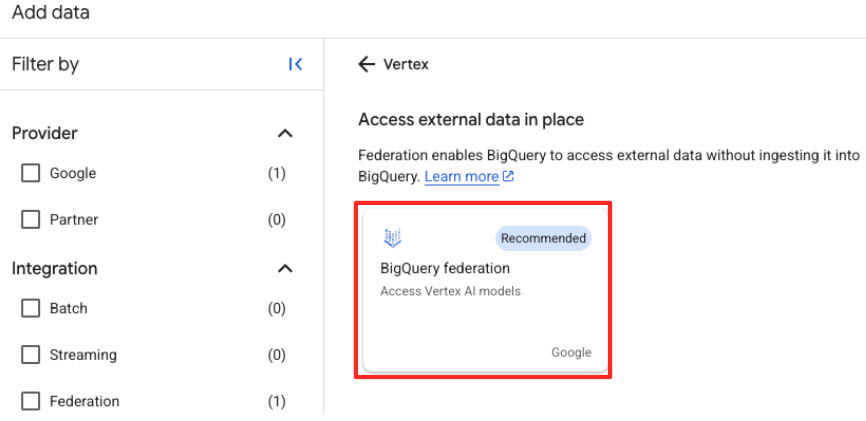
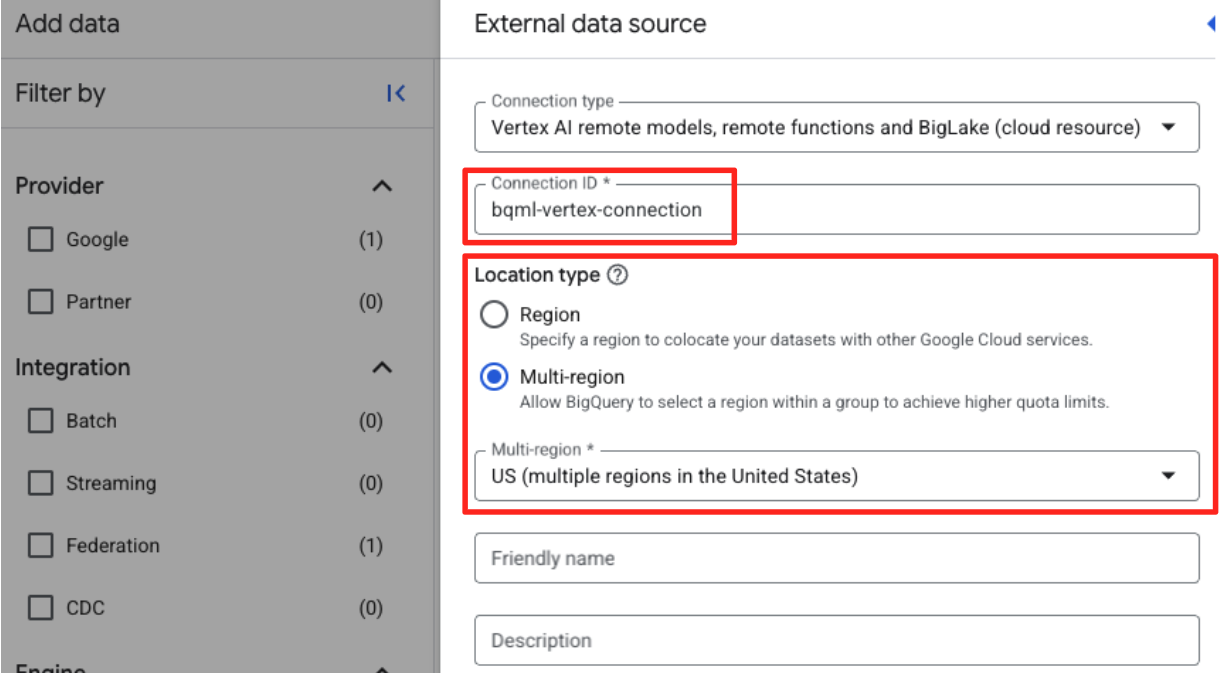
- Dadurch wird das Formular „Externe Datenquelle“ geöffnet. Geben Sie die folgenden Informationen ein:
- Verbindungs-ID: Geben Sie die Verbindungs-ID ein (z. B.
bqml-vertex-connection). - Standorttyp: Achten Sie darauf, dass „Mehrere Regionen“ ausgewählt ist.
- Standort: Wählen Sie den Standort aus, z.B.
US.
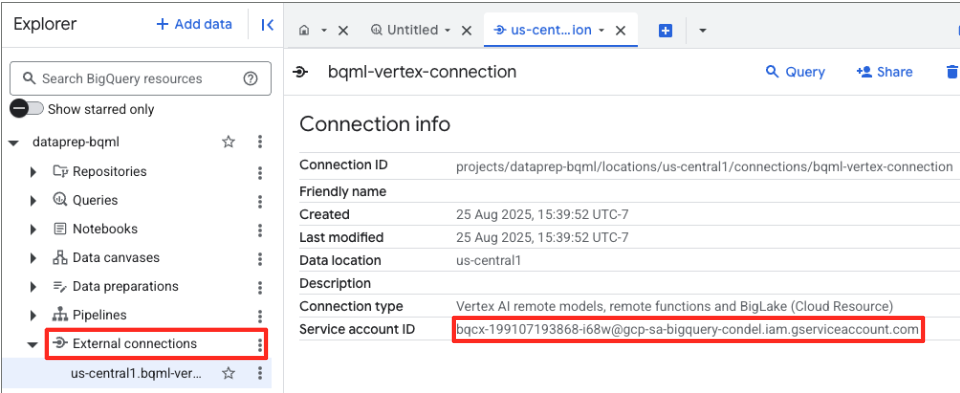
- Nachdem die Verbindung hergestellt wurde, wird ein Bestätigungsdialogfeld angezeigt. Klicken Sie auf dem Tab „Explorer“ auf „Zur Verbindung“ oder „Externe Verbindungen“. Kopieren Sie auf der Seite mit den Verbindungsinformationen die vollständige ID in die Zwischenablage. Dies ist die Dienstkontoidentität, die BigQuery zum Aufrufen von Vertex AI verwendet.
- Klicken Sie im Navigationsmenü der Google Cloud Console auf „IAM & Verwaltung“ > „IAM“.
- Klicken Sie auf die Schaltfläche „Zugriff gewähren“.
- Fügen Sie das im vorherigen Schritt kopierte Dienstkonto in das Feld „Neue Hauptkonten“ ein.
- Weisen Sie im Drop-down-Menü „Rolle“ die Rolle Vertex AI-Nutzer zu und klicken Sie auf „Speichern“.
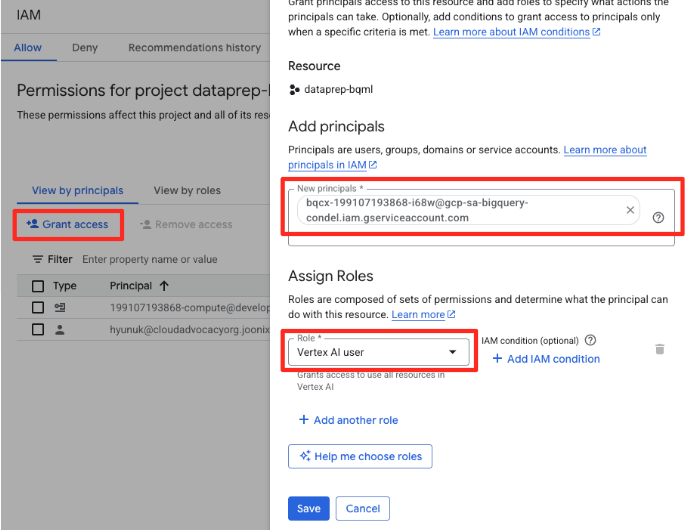
Dieser wichtige Schritt sorgt dafür, dass BigQuery die richtige Autorisierung hat, Vertex AI-Modelle in Ihrem Namen zu verwenden.
Remote-Modell erstellen
Öffnen Sie in BigQuery Studio einen neuen SQL-Editor-Tab. Hier definieren Sie das BQML-Modell, das mit Gemini verbunden wird.
Durch diese Anweisung wird kein neues Modell trainiert. Es wird lediglich eine Referenz in BigQuery erstellt, die über die gerade autorisierte Verbindung auf ein leistungsstarkes, vortrainiertes gemini-embedding-001-Modell verweist.
Kopieren Sie das gesamte SQL-Skript unten und fügen Sie es in den BigQuery-Editor ein.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
Einbettungen generieren
Als Nächstes verwenden wir unser BQML-Modell, um die Vektoreinbettungen zu generieren. Anstatt für jede Zeile nur ein einzelnes Textlabel zu konvertieren, verwenden wir einen ausgefeilteren Ansatz, um für jedes Kunstwerk eine aussagekräftigere „semantische Zusammenfassung“ zu erstellen. Das führt zu hochwertigeren Einbettungen und genaueren Empfehlungen.
Mit dieser Abfrage wird ein wichtiger Vorverarbeitungsschritt ausgeführt:
- Dazu wird zuerst eine temporäre Tabelle mit einer
WITH-Klausel erstellt. - Darin
GROUP BYwir jedeobject_id, um alle Informationen zu einem einzelnen Kunstwerk in einer Zeile zusammenzufassen. - Wir verwenden die
STRING_AGG-Funktion, um alle separaten Textbeschreibungen (z. B. „Porträt“, „Frau“, „Öl auf Leinwand“) in einer einzigen, umfassenden Textzeichenfolge zusammenzuführen und sie nach ihrem Relevanzwert zu sortieren.
Dieser kombinierte Text bietet der KI einen viel umfassenderen Kontext für das Kunstwerk, was zu differenzierteren und leistungsstärkeren Vektoreinbettungen führt.
Fügen Sie die folgende Abfrage in einen neuen SQL-Editor-Tab ein und führen Sie sie aus:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
Diese Abfrage dauert etwa 10 Minuten. Prüfen Sie die Ergebnisse, sobald die Abfrage abgeschlossen ist. Suchen Sie im Bereich „Explorer“ nach der neuen Tabelle artwork_embeddings und klicken Sie darauf. In der Tabellenschema-Ansicht sehen Sie die Spalte object_id, die neue Spalte ml_generate_text_embedding_result mit den Vektoren sowie die Spalte „aggregated_labels“, die als Quelltext verwendet wurde.
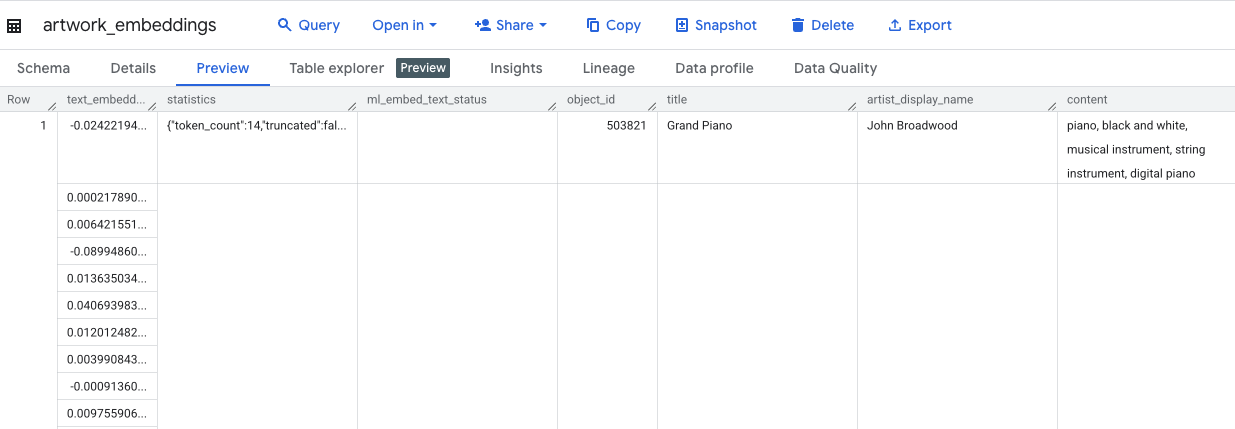
5. Ähnliche Kunstwerke mit SQL finden
Mit unseren hochwertigen, kontextreichen Vektoreinbettungen ist es ganz einfach, thematisch ähnliche Kunstwerke zu finden – es genügt eine SQL-Abfrage. Wir verwenden die ML.DISTANCE-Funktion, um die Kosinusähnlichkeit zwischen Vektoren zu berechnen. Da unsere Einbettungen aus aggregiertem Text generiert wurden, sind die Ähnlichkeitsergebnisse genauer und relevanter.
- Fügen Sie die folgende Abfrage in einen neuen SQL-Editor-Tab ein. Diese Abfrage simuliert die Kernlogik einer Empfehlungsanwendung:
- Zuerst wird der Vektor für ein einzelnes, bestimmtes Kunstwerk ausgewählt (in diesem Fall „Zypressen“ von Van Gogh mit einem
object_idvon 436535). - Anschließend wird die Distanz zwischen diesem einzelnen Vektor und allen anderen Vektoren in der Tabelle berechnet.
- Schließlich werden die Ergebnisse nach Distanz sortiert (eine kleinere Distanz bedeutet eine größere Ähnlichkeit), um die zehn ähnlichsten Übereinstimmungen zu finden.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- Führen Sie die Abfrage aus. In den Ergebnissen werden
object_idaufgeführt, wobei die besten Übereinstimmungen oben stehen. Das Quell-Artwork wird zuerst mit einem Abstand von 0 angezeigt. Das ist die Kernlogik, die eine KI-Empfehlungs-Engine antreibt. Sie haben sie vollständig in BigQuery und nur mit SQL erstellt.
6. (OPTIONAL) Demo in Cloud Shell ausführen
Damit Sie die Konzepte aus diesem Codelab nachvollziehen können, enthält das geklonte Repository eine einfache Webanwendung. In dieser optionalen Demo wird die von Ihnen erstellte Tabelle artwork_embeddings verwendet, um eine visuelle Suchmaschine zu betreiben. So können Sie die KI-gestützten Empfehlungen in Aktion sehen.
So führen Sie die Demo in Cloud Shell aus:
- Umgebungsvariablen festlegen: Bevor Sie die Anwendung ausführen, müssen Sie die Umgebungsvariablen PROJECT_ID und BIGQUERY_DATASET festlegen.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- Installieren Sie die Abhängigkeiten und starten Sie den Backend-Server.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- Sie benötigen einen zweiten Terminaltab, um die Frontend-Anwendung auszuführen. Klicken Sie auf das Pluszeichen (+), um einen neuen Cloud Shell-Tab zu öffnen.

- Führen Sie nun im neuen Tab den folgenden Befehl aus, um Abhängigkeiten zu installieren und den Frontend-Server auszuführen.
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- Vorschau der Anwendung ansehen: Klicken Sie in der Cloud Shell-Symbolleiste auf das Symbol für die Webvorschau und wählen Sie „Vorschau auf Port 5173“ aus. Dadurch wird ein neuer Browsertab mit der ausgeführten Anwendung geöffnet. Sie können jetzt mit der Anwendung nach Kunstwerken suchen und die Ähnlichkeitssuche in Aktion sehen.
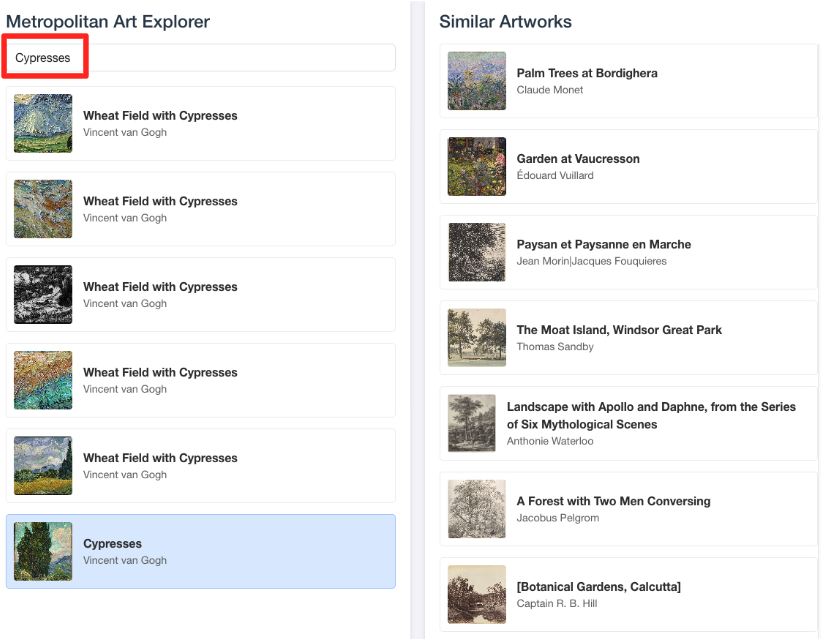
- Wenn Sie diese visuelle Demo mit Ihrer Arbeit im BigQuery-SQL-Editor verknüpfen möchten, geben Sie „Zypressen“ in die Suchleiste ein. Das ist dasselbe Artwork(
object_id=436535), das Sie in derML.DISTANCE-Anfrage verwendet haben. Klicken Sie dann auf das Bild „Zypressen“, wenn es im linken Bereich angezeigt wird. Die Ergebnisse werden rechts angezeigt. Die Anwendung zeigt die ähnlichsten Kunstwerke an und demonstriert so die Leistungsfähigkeit der von Ihnen entwickelten Suche nach Vektorähnlichkeit.
7. Umgebung bereinigen
Damit Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen nicht in Rechnung gestellt werden, sollten Sie die erstellten Ressourcen löschen.
Führen Sie die folgenden Befehle in Ihrem Cloud Shell-Terminal aus, um das Dienstkonto, die BigQuery-Verbindung, den GCS-Bucket und das BigQuery-Dataset zu entfernen.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
BigQuery-Verbindung und GCS-Bucket entfernen
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
BigQuery-Dataset löschen
Löschen Sie zum Schluss das BigQuery-Dataset. Dieser Befehl kann nicht rückgängig gemacht werden. Mit dem Flag „-f“ (force) wird das Dataset mit allen zugehörigen Tabellen entfernt, ohne dass eine Bestätigung erforderlich ist.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. Glückwunsch!
Sie haben eine durchgängige, KI-basierte Datenpipeline erstellt.
Sie haben mit einer unaufbereiteten CSV-Datei in einem GCS-Bucket begonnen, die Low-Code-Oberfläche von BigQuery Data Prep verwendet, um komplexe JSON-Daten aufzunehmen und zu vereinfachen, ein leistungsstarkes BQML-Remotemodell erstellt, um mit einem Gemini-Modell hochwertige Vektoreinbettungen zu generieren, und eine Ähnlichkeitssuchanfrage ausgeführt, um ähnliche Elemente zu finden.
Sie kennen jetzt das grundlegende Muster für die Entwicklung KI-gestützter Workflows in Google Cloud, mit dem Sie Rohdaten schnell und einfach in intelligente Anwendungen umwandeln können.
Wie geht es weiter?
- Ergebnisse in Looker Studio visualisieren:Verbinden Sie Ihre
artwork_embeddings-BigQuery-Tabelle direkt mit Looker Studio (kostenlos). Sie können ein interaktives Dashboard erstellen, in dem Nutzer ein Kunstwerk auswählen und eine visuelle Galerie der ähnlichsten Werke sehen können, ohne Frontend-Code schreiben zu müssen. - Automatisieren mit geplanten Abfragen:Sie benötigen kein komplexes Orchestrierungstool, um Ihre Einbettungen auf dem neuesten Stand zu halten. Verwenden Sie die integrierte Funktion für geplante Abfragen in BigQuery, um die
ML.GENERATE_TEXT_EMBEDDING-Abfrage automatisch täglich oder wöchentlich auszuführen. - App mit der Gemini CLI generieren:Mit der Gemini CLI können Sie eine vollständige Anwendung generieren, indem Sie Ihre Anforderungen in einfachem Text beschreiben. So können Sie schnell einen funktionierenden Prototyp für Ihre Ähnlichkeitssuche erstellen, ohne den Python-Code manuell schreiben zu müssen.
- Dokumentation lesen