
1. Introducción
Los analistas de datos suelen encontrarse con datos valiosos bloqueados en formatos semiestructurados, como cargas útiles JSON. Tradicionalmente, la extracción y preparación de estos datos para el análisis y el aprendizaje automático ha sido un obstáculo técnico importante, que requiere scripts de ETL complejos y la intervención de un equipo de ingeniería de datos.
En este codelab, se proporciona un plan técnico para que los analistas de datos superen este desafío de forma independiente. Demuestra un enfoque de "poco código" para compilar una canalización de IA de extremo a extremo. Aprenderás a pasar de un archivo CSV sin procesar en Google Cloud Storage a potenciar una función de recomendación basada en IA, usando solo las herramientas disponibles en BigQuery Studio.
El objetivo principal es demostrar un flujo de trabajo sólido, rápido y fácil de usar para los analistas que va más allá de los procesos complejos y con mucho código para generar valor comercial real a partir de tus datos.
Requisitos previos
- Conocimientos básicos sobre la consola de Google Cloud
- Habilidades básicas de la interfaz de línea de comandos y de Google Cloud Shell
Qué aprenderás
- Cómo transferir y transformar un archivo CSV directamente desde Google Cloud Storage con la Preparación de datos de BigQuery
- Cómo usar transformaciones sin código para analizar y compactar cadenas JSON anidadas dentro de tus datos
- Cómo crear un modelo remoto de BigQuery ML que se conecte a un modelo de base de Vertex AI para la incorporación de texto
- Cómo usar la función
ML.GENERATE_TEXT_EMBEDDINGpara convertir datos textuales en vectores numéricos - Cómo usar la función
ML.DISTANCEpara calcular la similitud del coseno y encontrar los elementos más similares en tu conjunto de datos
Requisitos
- Una cuenta de Google Cloud y un proyecto de Google Cloud
- Un navegador web, como Chrome
Conceptos clave
- Preparación de datos de BigQuery: Es una herramienta de BigQuery Studio que proporciona una interfaz visual interactiva para la limpieza y preparación de datos. Sugiere transformaciones y permite a los usuarios compilar canalizaciones de datos con un mínimo de código.
- Modelo remoto de BQML: Es un objeto de BigQuery ML que actúa como proxy para un modelo alojado en Vertex AI (como Gemini). Te permite invocar modelos de IA potentes y previamente entrenados con una sintaxis de SQL familiar.
- Embedding de vector: Es una representación numérica de los datos, como texto o imágenes. En este codelab, convertiremos descripciones de texto de obras de arte en vectores, en los que las descripciones similares generarán vectores que estarán "más cerca" entre sí en el espacio multidimensional.
- Similitud de coseno: Es una medida matemática que se usa para determinar qué tan similares son dos vectores. Es el núcleo de la lógica de nuestro motor de recomendaciones, que usa la función
ML.DISTANCEpara encontrar las obras de arte "más cercanas" (más similares).
2. Configuración y requisitos
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:

El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
Habilita las APIs obligatorias y configura el entorno
En Cloud Shell, ejecuta los siguientes comandos para establecer tu ID del proyecto, definir variables de entorno y habilitar todas las APIs necesarias para este codelab.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
Crea un conjunto de datos de BigQuery y un bucket de GCS
Crea un nuevo conjunto de datos de BigQuery para alojar nuestras tablas y un bucket de Google Cloud Storage para almacenar nuestro archivo CSV de origen.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
Prepara y sube los datos de muestra
Clona el repositorio de GitHub que contiene el archivo CSV de muestra y, luego, súbelo al bucket de GCS que acabas de crear.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. De GCS a BigQuery con la preparación de datos
En esta sección, usaremos una interfaz visual sin código para transferir nuestro archivo CSV desde GCS, limpiarlo y cargarlo en una nueva tabla de BigQuery.
Inicia Data Preparation y conéctate a la fuente
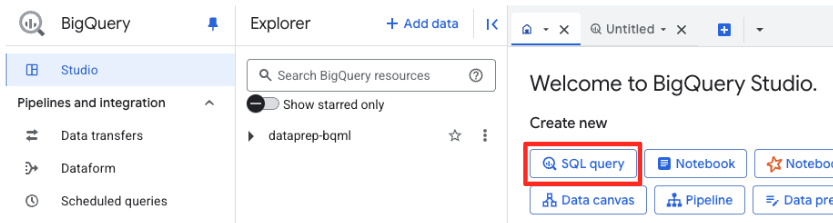
- En la consola de Google Cloud, navega a BigQuery Studio.
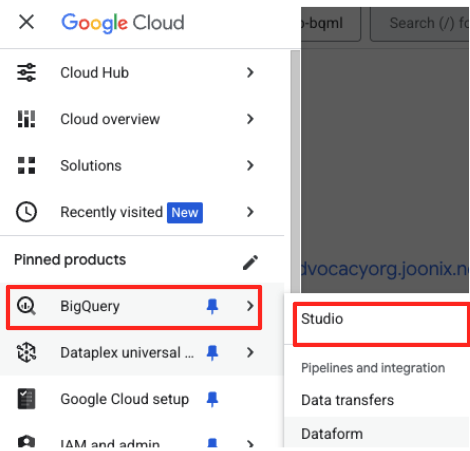
- En la página de bienvenida, haz clic en la tarjeta Preparación de datos para comenzar.
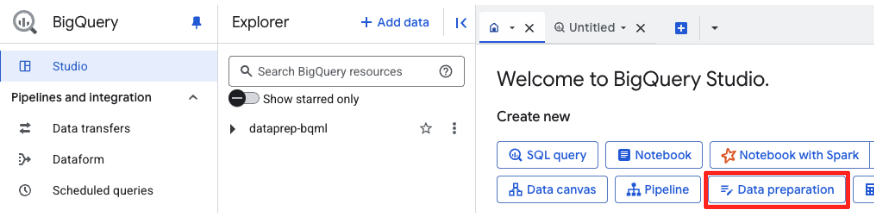
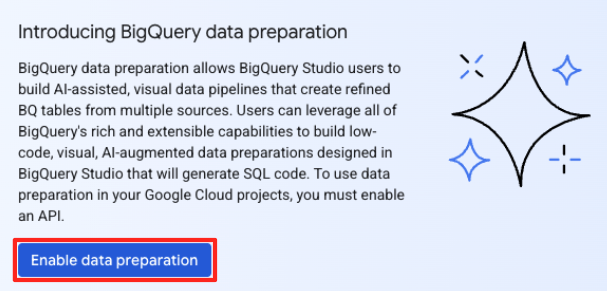
- Si es la primera vez que lo haces, es posible que debas habilitar las APIs requeridas. Haz clic en Habilitar para la "API de Gemini para Google Cloud" y la "API unificada de BigQuery". Una vez que estén habilitadas, puedes cerrar este panel.
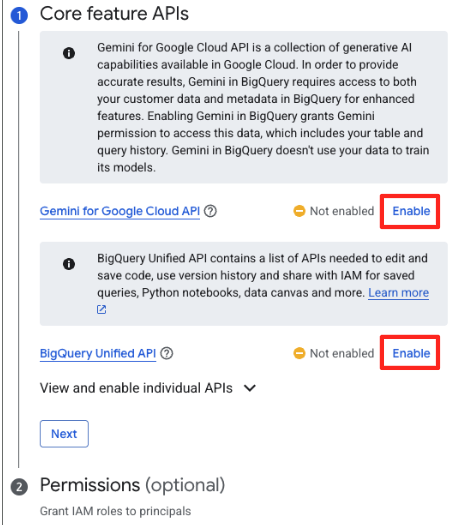
- En la ventana principal de Preparación de datos, en "Elige otras fuentes de datos", haz clic en Google Cloud Storage. Esto abrirá el panel "Preparar datos" a la derecha.
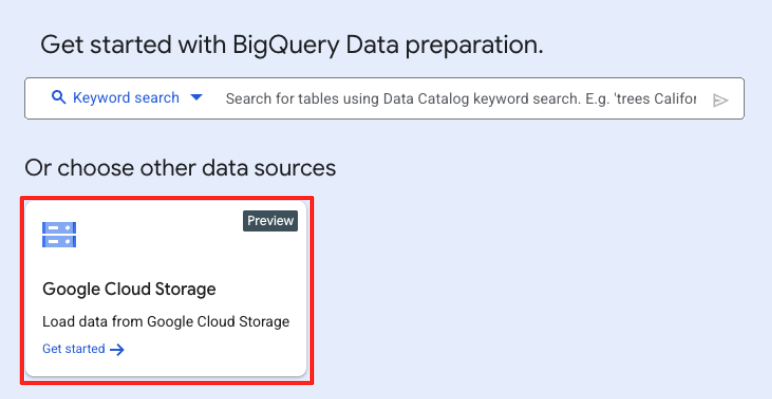
- Haz clic en el botón Explorar para seleccionar el archivo fuente.
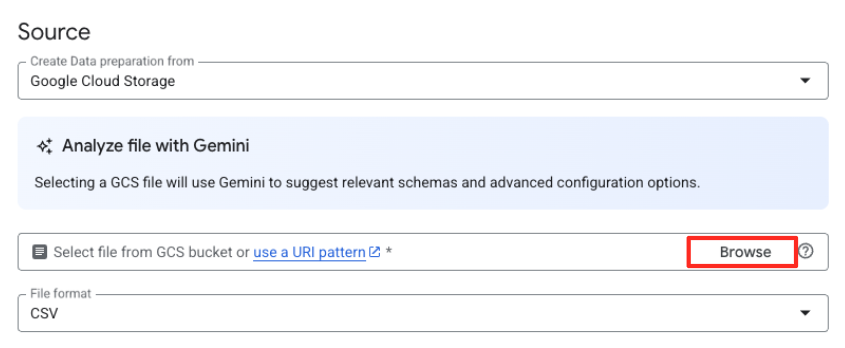
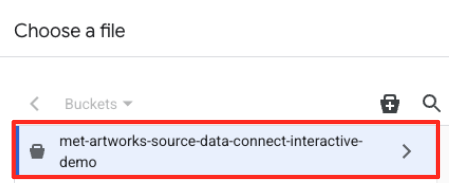
- Navega al bucket de GCS que creaste antes (
met-artworks-source-...) y selecciona el archivodataprep-met-bqml.csv. Haz clic en Seleccionar.
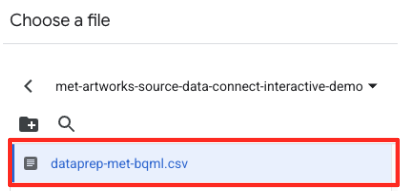
- A continuación, debes configurar una tabla de etapa de pruebas.
- En Conjunto de datos, selecciona el
met_art_datasetque creaste. - En Nombre de la tabla, ingresa un nombre, por ejemplo,
temp. - Haz clic en Crear.

Transforma y limpia los datos
- La preparación de datos de BigQuery ahora cargará una vista previa del CSV. Busca la columna
label_details_json, que contiene la cadena JSON larga. Haz clic en el encabezado de la columna para seleccionarla.
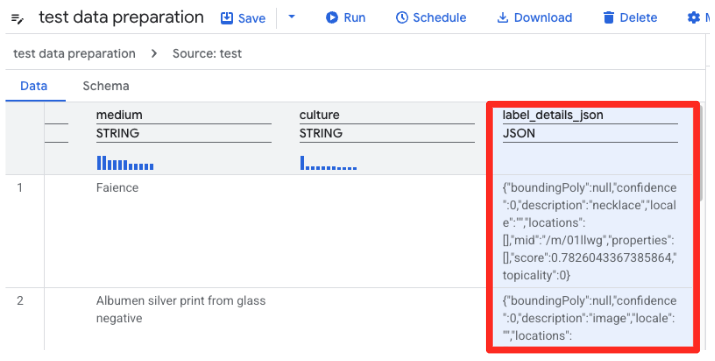
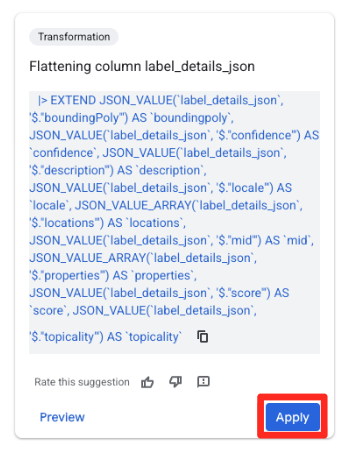
- En el panel Sugerencias de la derecha, Gemini en BigQuery sugerirá automáticamente transformaciones pertinentes. Haz clic en el botón Aplicar de la tarjeta “Aplanar columna
label_details_json”. Esto extraerá los campos anidados (description,score, etc.) en sus propias columnas de nivel superior.
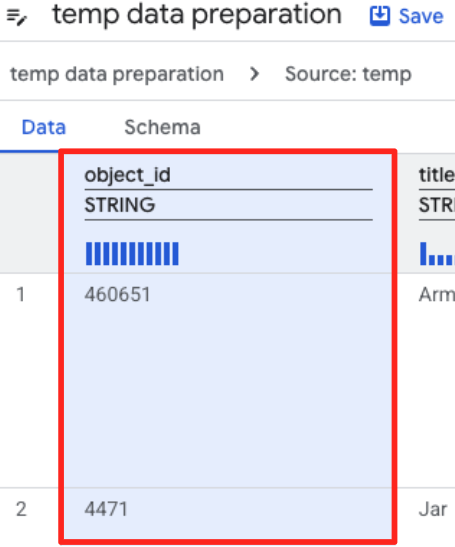
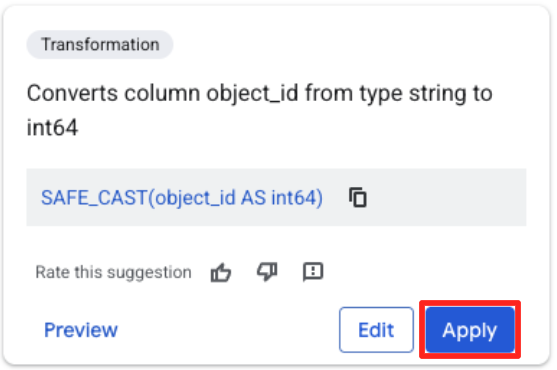
- Haz clic en la columna object_id y, luego, en el botón Aplicar del mensaje "Convierte la columna
object_iddel tipostringaint64".
Define el destino y ejecuta el trabajo
- En el panel de la derecha, haz clic en el botón Destino para configurar el resultado de la transformación.
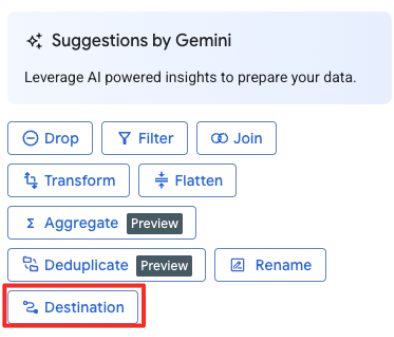
- Establece los detalles del destino:
- El conjunto de datos debe estar precompletado con
met_art_dataset. - Ingresa un nombre de tabla nuevo para el resultado:
met_art_flatten_table. - Haz clic en Guardar.
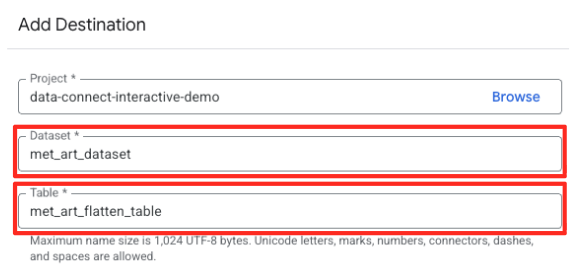
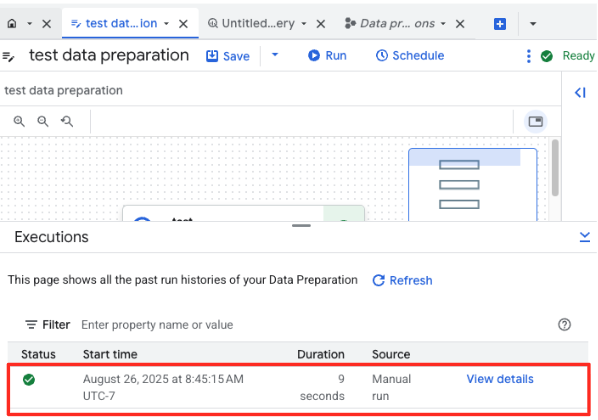
- Haz clic en el botón Ejecutar y espera a que se complete el trabajo de preparación de datos.
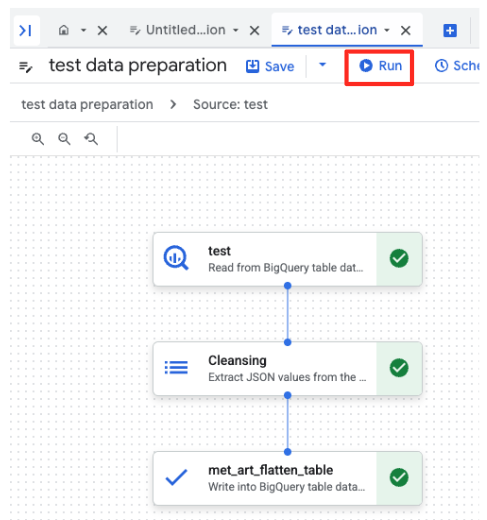
- Puedes supervisar el progreso del trabajo en la pestaña Ejecuciones, que se encuentra en la parte inferior de la página. Después de unos instantes, se completará el trabajo.
4. Cómo generar embeddings de vectores con BQML
Ahora que nuestros datos están limpios y estructurados, usaremos BigQuery ML para la tarea principal de IA: convertir las descripciones textuales de las obras de arte en incorporaciones de vectores numéricos.
Crea una conexión de BigQuery
Para permitir que BigQuery se comunique con los servicios de Vertex AI, primero debes crear una conexión de BigQuery.
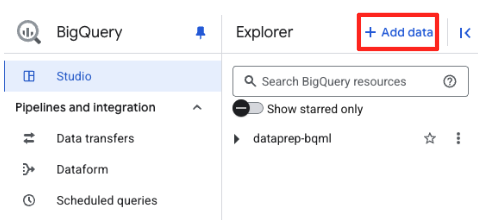
- En el panel Explorador de BigQuery Studio, haz clic en el botón "+ Agregar datos".
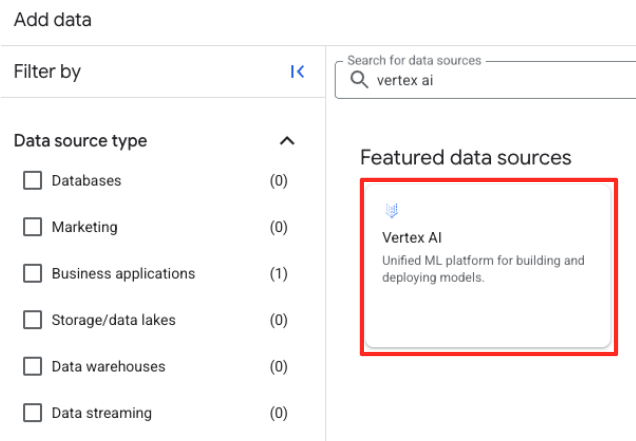
- En el panel de la derecha, usa la barra de búsqueda para escribir
Vertex AI. Selecciona BigQuery y, luego, federación de BigQuery en la lista filtrada.
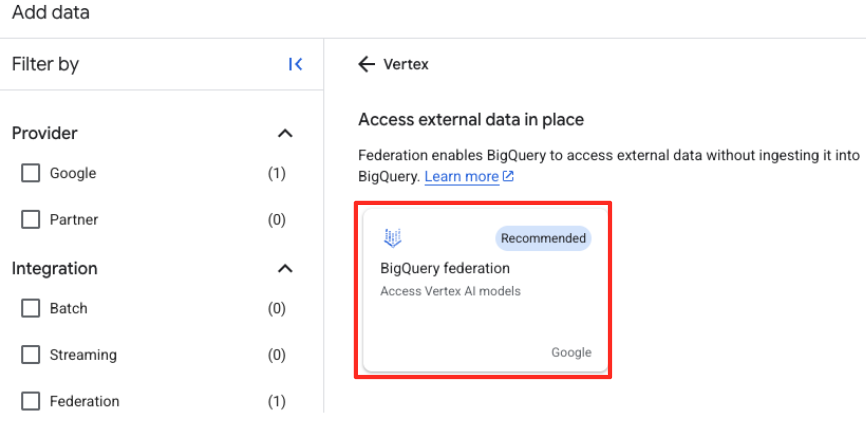
- Se abrirá el formulario Fuente de datos externa. Completa los siguientes detalles:
- ID de conexión: Ingresa el ID de conexión (p.ej.,
bqml-vertex-connection - Tipo de ubicación: Asegúrate de que esté seleccionada la opción Multirregión.
- Ubicación: Selecciona la ubicación (p.ej.,
US).
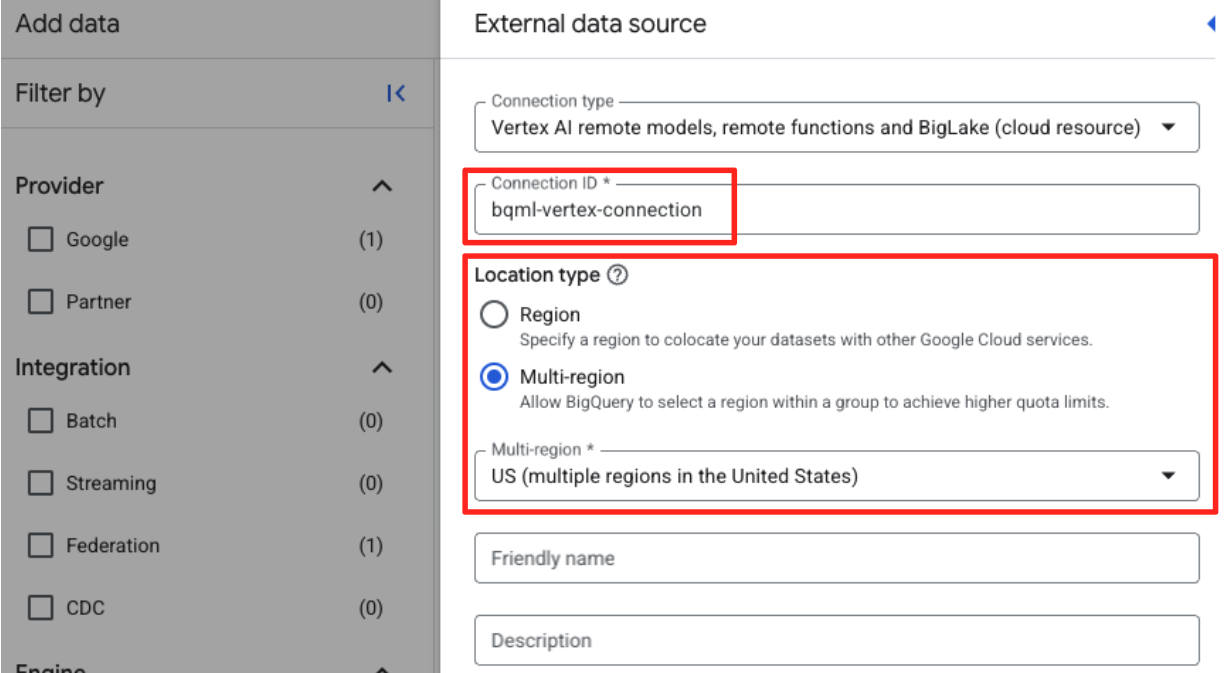
- Una vez que se cree la conexión, aparecerá un diálogo de confirmación. Haz clic en Ir a la conexión o Conexiones externas en la pestaña Explorador. En la página de detalles de la conexión, copia el ID completo en el portapapeles. Es la identidad de la cuenta de servicio que BigQuery usará para llamar a Vertex AI.
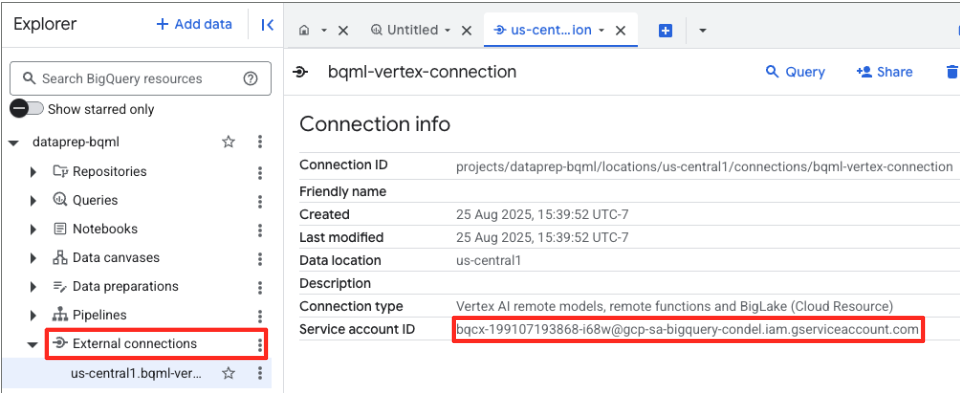
- En el menú de navegación de la consola de Google Cloud, ve a IAM y administración > IAM.
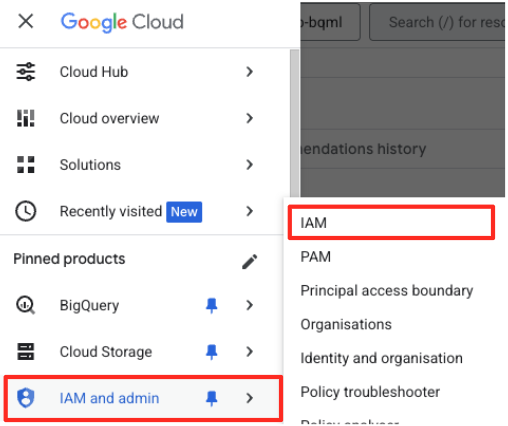
- Haz clic en el botón "Otorgar acceso".
- Pega la cuenta de servicio que copiaste en el paso anterior en el campo Principales nuevas.
- Asigna "Usuario de Vertex AI" en el menú desplegable Rol y haz clic en "Guardar".
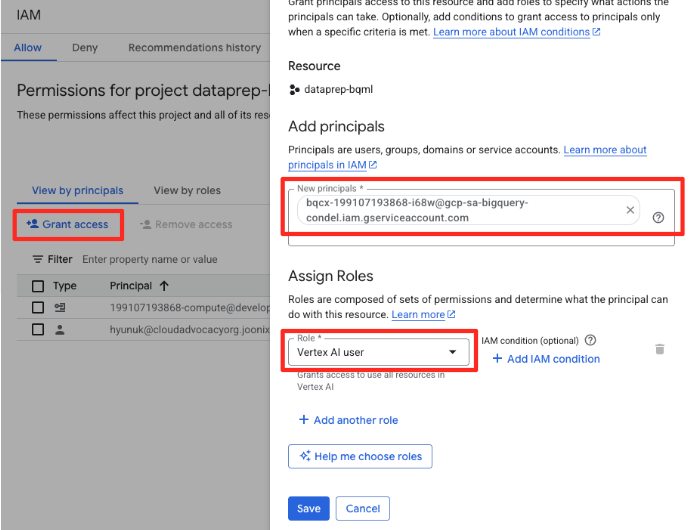
Este paso crítico garantiza que BigQuery tenga la autorización adecuada para usar los modelos de Vertex AI en tu nombre.
Crea un modelo remoto
En BigQuery Studio, abre una nueva pestaña del editor de SQL. Aquí definirás el modelo de BQML que se conecta a Gemini.
Esta instrucción no entrena un modelo nuevo. Simplemente crea una referencia en BigQuery que apunta a un potente modelo gemini-embedding-001 previamente entrenado con la conexión que acabas de autorizar.
Copia toda la secuencia de comandos SQL que se muestra a continuación y pégala en el editor de BigQuery.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
Genera embeddings
Ahora, usaremos nuestro modelo de BQML para generar los embeddings de vectores. En lugar de simplemente convertir una sola etiqueta de texto para cada fila, usaremos un enfoque más sofisticado para crear un "resumen semántico" más enriquecido y significativo para cada obra de arte. Esto generará incorporaciones de mayor calidad y recomendaciones más precisas.
Esta consulta realiza un paso de preprocesamiento fundamental:
- Usa una cláusula
WITHpara crear primero una tabla temporal. - Dentro de ella,
GROUP BYcadaobject_idpara combinar toda la información sobre una sola obra de arte en una fila. - Usamos la función
STRING_AGGpara combinar todas las descripciones de texto separadas (como "Retrato", "Mujer", "Óleo sobre lienzo") en una sola cadena de texto integral, ordenándolas según su puntuación de relevancia.
Este texto combinado le brinda a la IA un contexto mucho más enriquecido sobre la obra de arte, lo que genera incorporaciones vectoriales más potentes y matizadas.
En una nueva pestaña del editor de SQL, pega y ejecuta la siguiente consulta:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
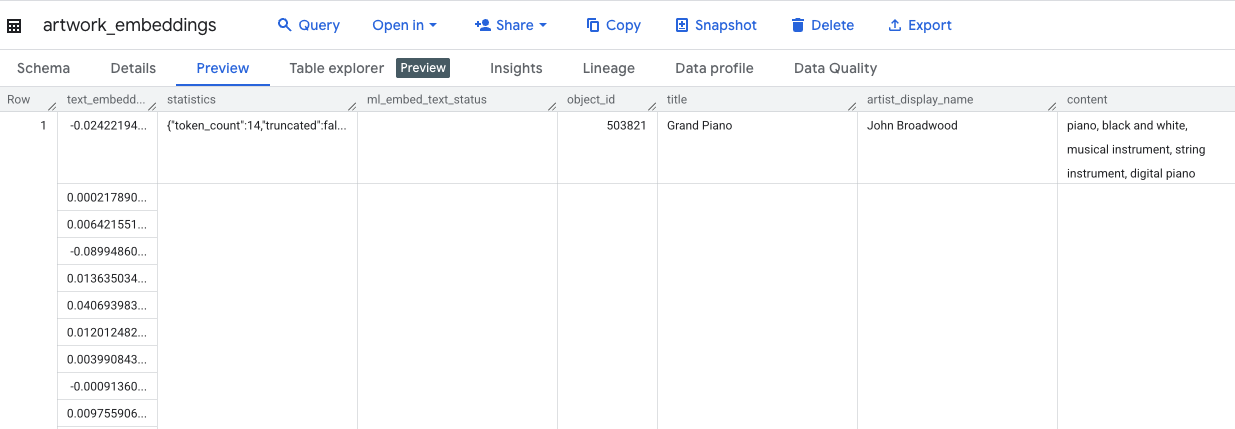
Esta consulta tardará aproximadamente 10 minutos. Una vez que se complete la consulta, verifica los resultados. En el panel Explorador, busca la nueva tabla artwork_embeddings y haz clic en ella. En el visualizador del esquema de la tabla, verás el object_id, la nueva columna ml_generate_text_embedding_result que contiene los vectores y la columna aggregated_labels que se usó como texto fuente.
5. Cómo encontrar obras de arte similares con SQL
Con las incorporaciones de vectores enriquecidas en contexto y de alta calidad que creamos, encontrar obras de arte temáticamente similares es tan simple como ejecutar una consulta en SQL. Usamos la función ML.DISTANCE para calcular la similitud del coseno entre vectores. Dado que nuestros embeddings se generaron a partir de texto agregado, los resultados de similitud serán más precisos y relevantes.
- En una nueva pestaña del editor de SQL, pega la siguiente consulta. Esta consulta simula la lógica principal de una aplicación de recomendaciones:
- Primero, selecciona el vector de una sola obra de arte específica (en este caso, "Cipreses" de Van Gogh, que tiene un
object_idde 436535). - Luego, calcula la distancia entre ese único vector y todos los demás vectores de la tabla.
- Por último, ordena los resultados por distancia (una distancia más pequeña significa más similitud) para encontrar las 10 coincidencias más cercanas.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- Ejecuta la consulta. En los resultados, se mostrarán los
object_ids, con las coincidencias más cercanas en la parte superior. La ilustración fuente aparecerá primero con una distancia de 0. Esta es la lógica principal que impulsa un motor de recomendaciones basado en IA, y la creaste por completo en BigQuery solo con SQL.
6. (OPCIONAL) Ejecuta la demostración en Cloud Shell
Para dar vida a los conceptos de este codelab, el repositorio que clonaste incluye una aplicación web simple. En esta demostración opcional, se usa la tabla artwork_embeddings que creaste para potenciar un motor de búsqueda visual, lo que te permite ver las recomendaciones basadas en IA en acción.
Para ejecutar la demostración en Cloud Shell, sigue estos pasos:
- Configura las variables de entorno: Antes de ejecutar la aplicación, debes configurar las variables de entorno PROJECT_ID y BIGQUERY_DATASET.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- Instala las dependencias y, luego, inicia el servidor de backend.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- Necesitarás una segunda pestaña de la terminal para ejecutar la aplicación de frontend. Haz clic en el ícono "+" para abrir una pestaña nueva de Cloud Shell.

- Ahora, en la nueva pestaña, ejecuta el siguiente comando para instalar las dependencias y ejecutar el servidor de frontend:
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
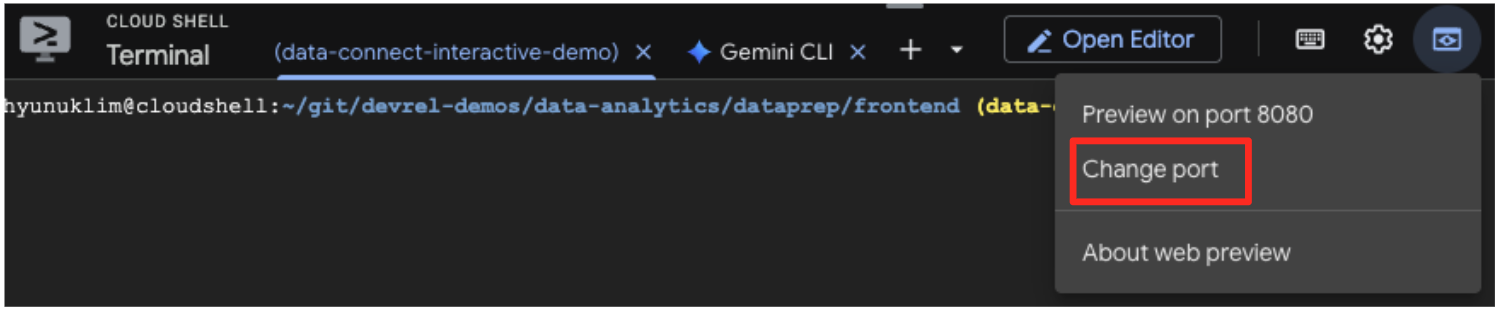
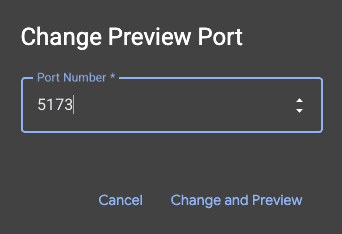
- Obtén una vista previa de la aplicación: En la barra de herramientas de Cloud Shell, haz clic en el ícono de Vista previa en la Web y selecciona Vista previa en el puerto 5173. Se abrirá una pestaña nueva del navegador con la aplicación en ejecución. Ahora puedes usar la aplicación para buscar obras de arte y ver la búsqueda por similitud en acción.
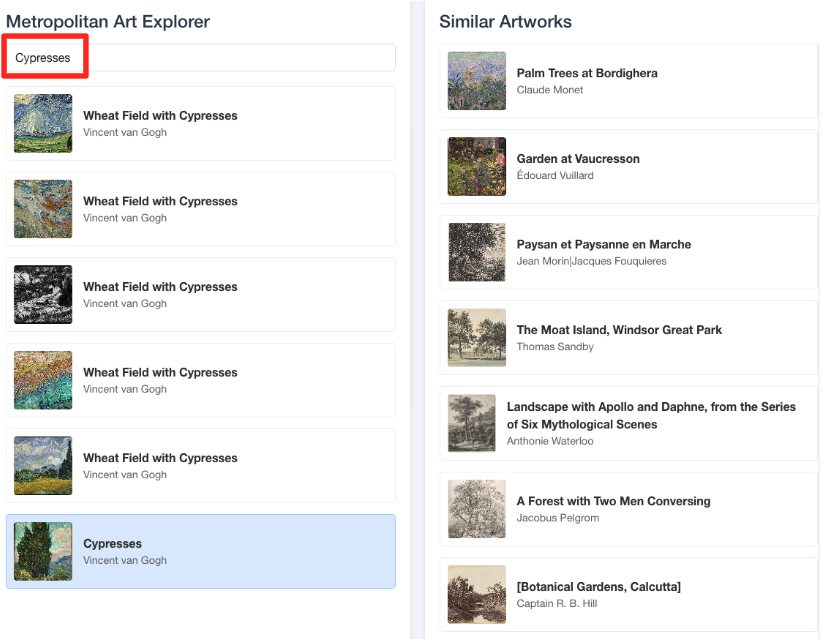
- Para volver a conectar esta demostración visual con el trabajo que realizaste en el editor de SQL de BigQuery, intenta escribir "Cipreses" en la barra de búsqueda. Esta es la misma ilustración(
object_id=436535) que usaste en la búsquedaML.DISTANCE. Luego, haz clic en la imagen de los cipreses cuando aparezca en el panel izquierdo. Observarás los resultados a la derecha. La aplicación muestra las obras de arte más similares, lo que demuestra visualmente el poder de la búsqueda de similitud de vectores que creaste.
7. Limpia tu entorno
Para evitar que se apliquen cargos futuros a tu cuenta de Google Cloud por los recursos que usaste en este codelab, debes borrar los recursos que creaste.
Ejecuta los siguientes comandos en la terminal de Cloud Shell para quitar la cuenta de servicio, la conexión de BigQuery, el bucket de GCS y el conjunto de datos de BigQuery.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
Cómo quitar la conexión de BigQuery y el bucket de GCS
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
Borra el conjunto de datos de BigQuery
Por último, borra el conjunto de datos de BigQuery. Este comando es irreversible. La marca -f (forzar) quita el conjunto de datos y todas sus tablas sin solicitar confirmación.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. ¡Felicitaciones!
Compilaste correctamente una canalización de datos potenciada por IA de extremo a extremo.
Comenzaste con un archivo CSV sin procesar en un bucket de GCS, usaste la interfaz de código bajo de BigQuery Data Prep para transferir y aplanar datos JSON complejos, creaste un potente modelo remoto de BQML para generar incorporaciones de vectores de alta calidad con un modelo de Gemini y ejecutaste una consulta de búsqueda de similitud para encontrar elementos relacionados.
Ahora tienes el patrón fundamental para compilar flujos de trabajo asistidos por IA en Google Cloud, que transforman los datos sin procesar en aplicaciones inteligentes con rapidez y sencillez.
Próximos pasos
- Visualiza tus resultados en Looker Studio: Conecta tu tabla de
artwork_embeddingsBigQuery directamente a Looker Studio (¡es gratis!). Puedes crear un panel interactivo en el que los usuarios puedan seleccionar una obra de arte y ver una galería visual de las piezas más similares sin escribir código de frontend. - Automatiza con consultas programadas: No necesitas una herramienta de organización compleja para mantener actualizadas tus incorporaciones. Usa la función Consultas programadas integradas de BigQuery para volver a ejecutar automáticamente la consulta
ML.GENERATE_TEXT_EMBEDDINGa diario o semanalmente. - Genera una app con la CLI de Gemini: Usa la CLI de Gemini para generar una aplicación completa con solo describir tu requisito en texto simple. Esto te permite crear rápidamente un prototipo funcional para tu búsqueda por similitud sin escribir el código de Python de forma manual.
- Lee la documentación: