
۱. مقدمه
تحلیلگران داده اغلب با دادههای ارزشمندی مواجه میشوند که در قالبهای نیمهساختاریافته مانند JSON قفل شدهاند. استخراج و آمادهسازی این دادهها برای تجزیه و تحلیل و یادگیری ماشینی، به طور سنتی یک مانع فنی قابل توجه بوده و به اسکریپتهای پیچیده ETL و مداخله یک تیم مهندسی داده نیاز دارد.
این آزمایشگاه کد، یک طرح فنی برای تحلیلگران داده فراهم میکند تا بتوانند به طور مستقل بر این چالش غلبه کنند. این آزمایشگاه، رویکردی «کمکد» برای ساخت یک خط لوله هوش مصنوعی سرتاسری را نشان میدهد. شما یاد خواهید گرفت که چگونه از یک فایل CSV خام در فضای ذخیرهسازی ابری گوگل، تنها با استفاده از ابزارهای موجود در BigQuery Studio، به یک ویژگی توصیه مبتنی بر هوش مصنوعی دست یابید.
هدف اصلی، نشان دادن یک گردش کار قوی، سریع و مناسب برای تحلیلگران است که فراتر از فرآیندهای پیچیده و سنگین کد حرکت میکند تا از دادههای شما ارزش تجاری واقعی ایجاد کند.
پیشنیازها
- درک اولیه از کنسول ابری گوگل
- مهارتهای پایه در رابط خط فرمان و پوسته ابری گوگل
آنچه یاد خواهید گرفت
- نحوه دریافت و تبدیل مستقیم یک فایل CSV از فضای ذخیرهسازی ابری گوگل با استفاده از آمادهسازی دادههای BigQuery.
- نحوه استفاده از تبدیلهای بدون کد برای تجزیه و مسطحسازی رشتههای JSON تو در تو در دادههای شما.
- چگونه یک مدل از راه دور BigQuery ML ایجاد کنیم که برای جاسازی متن به یک مدل پایه Vertex AI متصل شود.
- نحوه استفاده از تابع
ML.GENERATE_TEXT_EMBEDDINGبرای تبدیل دادههای متنی به بردارهای عددی. - نحوه استفاده از تابع
ML.DISTANCEبرای محاسبه شباهت کسینوسی و یافتن مشابهترین موارد در مجموعه دادههای شما.
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم
مفاهیم کلیدی
- آمادهسازی دادههای BigQuery: ابزاری در BigQuery Studio که یک رابط کاربری تعاملی و بصری برای پاکسازی و آمادهسازی دادهها ارائه میدهد. این ابزار تبدیلها را پیشنهاد میدهد و به کاربران امکان میدهد تا با حداقل کد، خطوط لوله داده بسازند.
- مدل از راه دور BQML: یک شیء BigQuery ML که به عنوان یک پروکسی برای مدلی که روی Vertex AI (مانند Gemini) میزبانی میشود، عمل میکند. این به شما امکان میدهد مدلهای هوش مصنوعی قدرتمند و از پیش آموزشدیده را با استفاده از سینتکس SQL آشنا فراخوانی کنید.
- جاسازی برداری: نمایش عددی دادهها، مانند متن یا تصاویر. در این آزمایشگاه کد، توضیحات متنی آثار هنری را به بردار تبدیل خواهیم کرد، که در آن توضیحات مشابه منجر به بردارهایی میشوند که در فضای چند بعدی به هم "نزدیکتر" هستند.
- شباهت کسینوسی: یک معیار ریاضی که برای تعیین میزان شباهت دو بردار استفاده میشود. این هسته منطق موتور پیشنهاد ما است که توسط تابع
ML.DISTANCEبرای یافتن "نزدیکترین" (شبیهترین) آثار هنری استفاده میشود.
۲. تنظیمات و الزامات
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:

آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
فعال کردن API های مورد نیاز و پیکربندی محیط
درون Cloud Shell، دستورات زیر را اجرا کنید تا شناسه پروژه خود را تنظیم کنید، متغیرهای محیطی را تعریف کنید و تمام API های لازم را برای این codelab فعال کنید.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
ایجاد یک مجموعه داده BigQuery و یک سطل GCS
یک مجموعه داده BigQuery جدید برای قرار دادن جداول خود و یک مخزن ذخیرهسازی ابری گوگل برای ذخیره فایل CSV منبع خود ایجاد کنید.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
آمادهسازی و بارگذاری دادههای نمونه
مخزن گیتهاب حاوی فایل CSV نمونه را کلون کنید و سپس آن را در باکت GCS که تازه ایجاد کردهاید آپلود کنید.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
۳. از GCS تا BigQuery با آمادهسازی دادهها
در این بخش، ما از یک رابط کاربری بصری و بدون کد برای دریافت فایل CSV خود از GCS، پاکسازی آن و بارگذاری آن در یک جدول جدید BigQuery استفاده خواهیم کرد.
آمادهسازی دادهها را آغاز کنید و به منبع متصل شوید
- در کنسول گوگل کلود، به BigQuery Studio بروید.
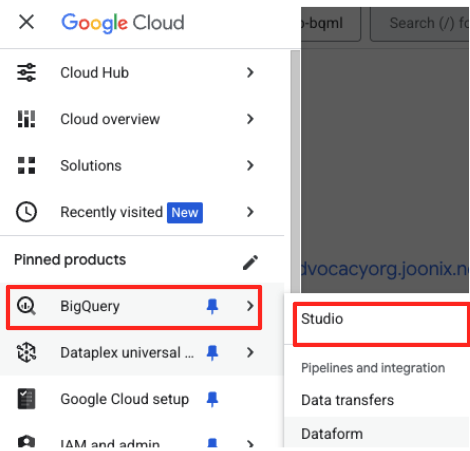
- در صفحه خوشامدگویی، برای شروع روی کارت آمادهسازی دادهها کلیک کنید.
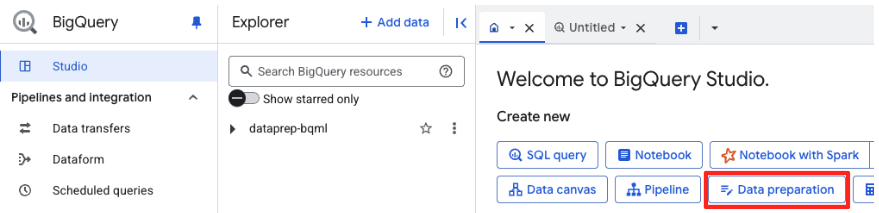
- اگر این اولین بار است که از این سرویس استفاده میکنید، ممکن است لازم باشد APIهای مورد نیاز را فعال کنید. برای هر دو گزینه "Gemini for Google Cloud API" و "BigQuery Unified API" روی گزینه "فعال کردن" کلیک کنید. پس از فعال شدن آنها، میتوانید این پنل را ببندید.
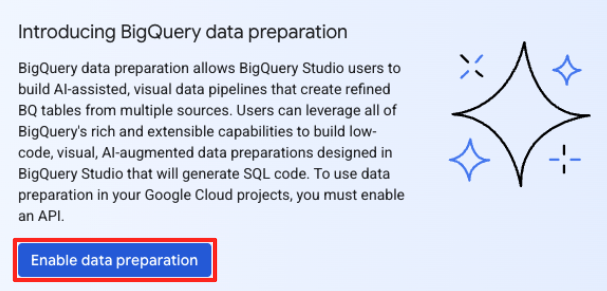
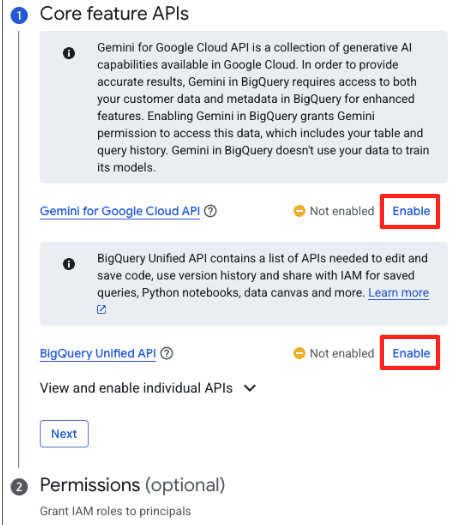
- در پنجره اصلی آمادهسازی دادهها، در قسمت «انتخاب سایر منابع داده»، روی Google Cloud Storage کلیک کنید. با این کار، پنل «آمادهسازی دادهها» در سمت راست باز میشود.
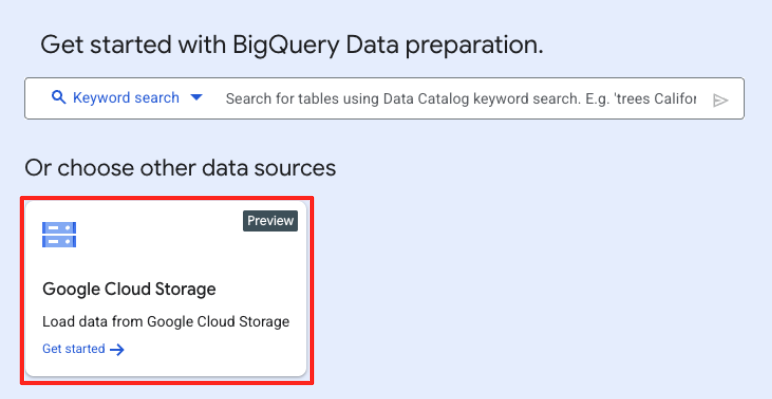
- برای انتخاب فایل منبع خود، روی دکمهی Browse کلیک کنید.
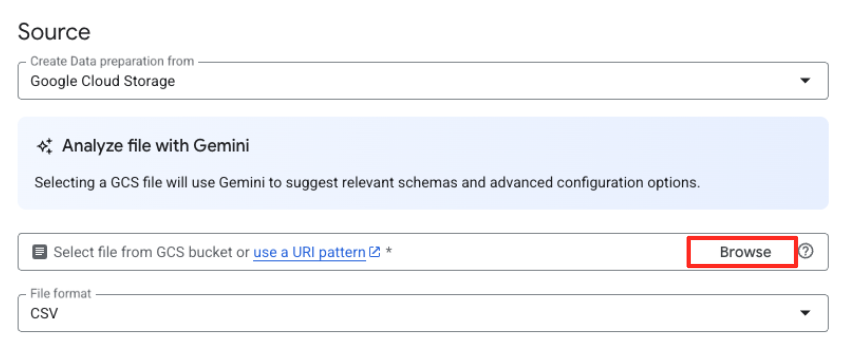
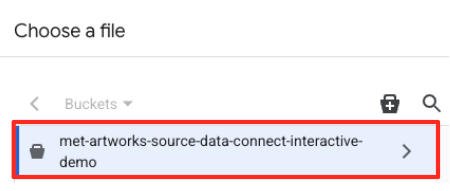
- به سطل GCS که قبلاً ایجاد کردهاید (
met-artworks-source-...) بروید و فایلdataprep-met-bqml.csvرا انتخاب کنید. روی انتخاب (Select) کلیک کنید.
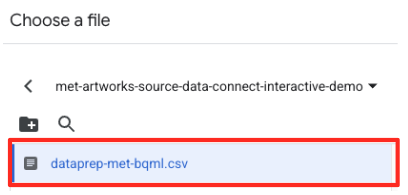
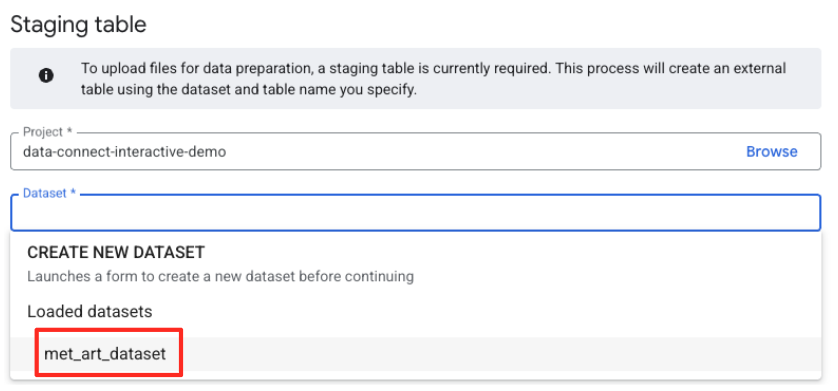
- در مرحله بعد، باید یک جدول مرحلهبندی پیکربندی کنید.
- برای Dataset،
met_art_datasetکه ایجاد کردهاید را انتخاب کنید. - برای نام جدول، یک نام وارد کنید، مثلاً
temp. - روی ایجاد کلیک کنید.
تبدیل و پاکسازی دادهها
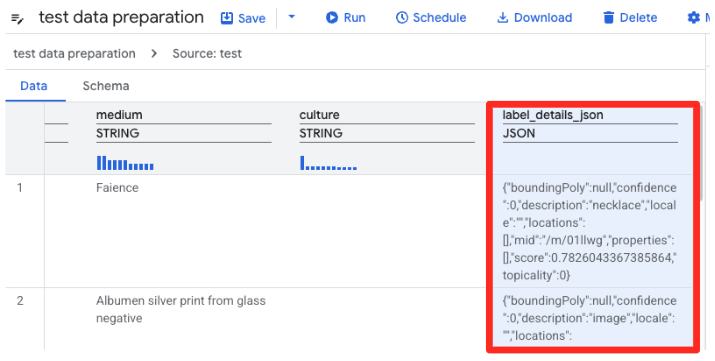
- آمادهسازی دادههای BigQuery اکنون پیشنمایشی از CSV را بارگذاری میکند. ستون
label_details_jsonرا که حاوی رشته طولانی JSON است، پیدا کنید. برای انتخاب آن، روی سربرگ ستون کلیک کنید.
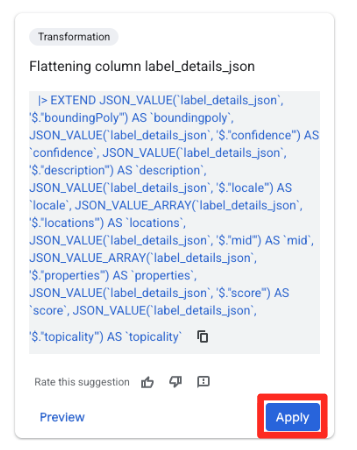
- در پنل پیشنهادات در سمت راست، Gemini در BigQuery به طور خودکار تبدیلهای مرتبط را پیشنهاد میدهد. روی دکمهی اعمال (Apply) در کارت "Flattening column
label_details_json" کلیک کنید. این کار فیلدهای تو در تو (description،scoreو غیره) را در ستونهای سطح بالای خود استخراج میکند.
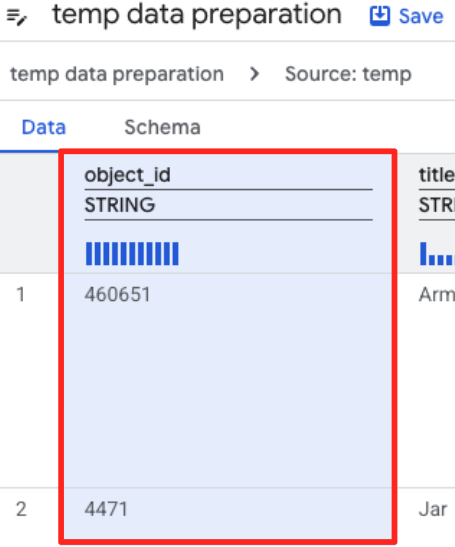
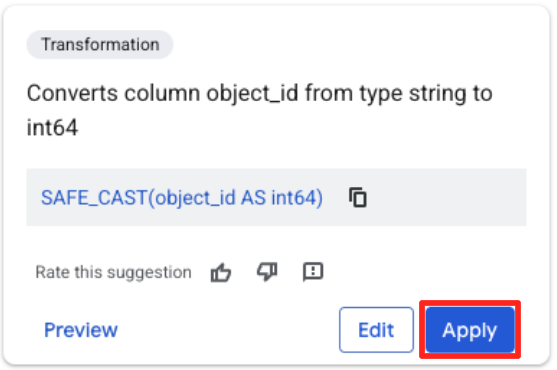
- روی ستون object_id کلیک کنید و روی دکمهی apply در کادر «Converts column
object_idfrom typestringtoint64کلیک کنید.
مقصد را تعریف کنید و کار را اجرا کنید
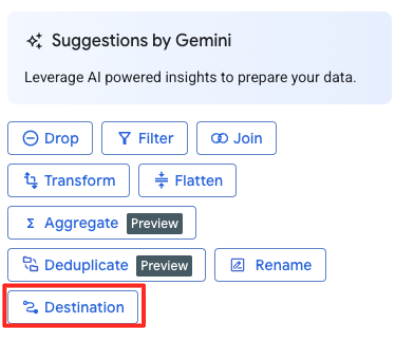
- در پنل سمت راست، روی دکمهی Destination کلیک کنید تا خروجی تبدیل خود را پیکربندی کنید.
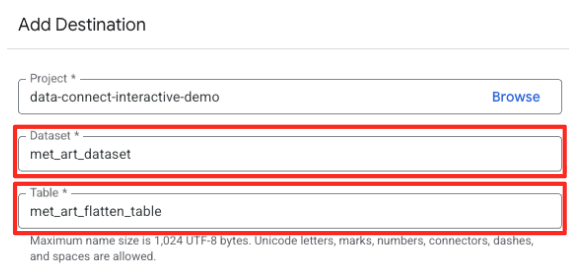
- جزئیات مقصد را تنظیم کنید:
- مجموعه داده باید از قبل با
met_art_datasetپر شده باشد. - یک نام جدول جدید برای خروجی وارد کنید:
met_art_flatten_table. - روی ذخیره کلیک کنید.
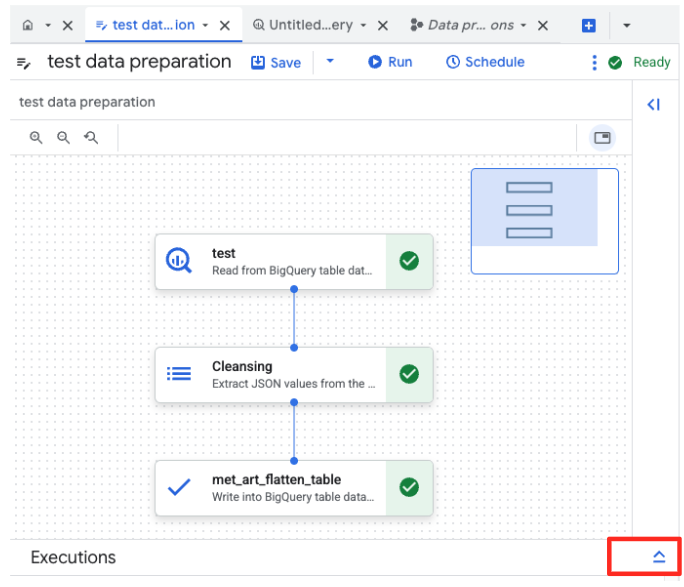
- روی دکمهی اجرا کلیک کنید و منتظر بمانید تا کار آمادهسازی دادهها به پایان برسد.
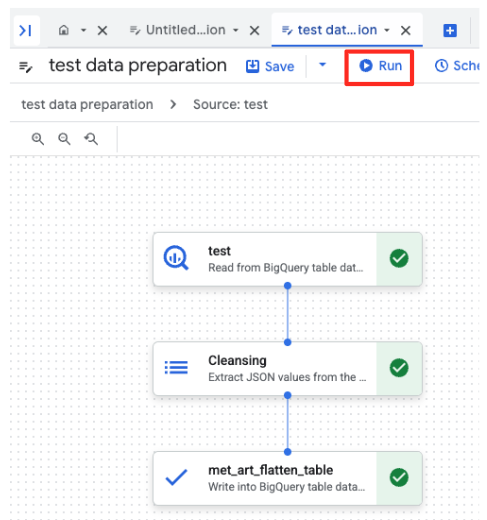
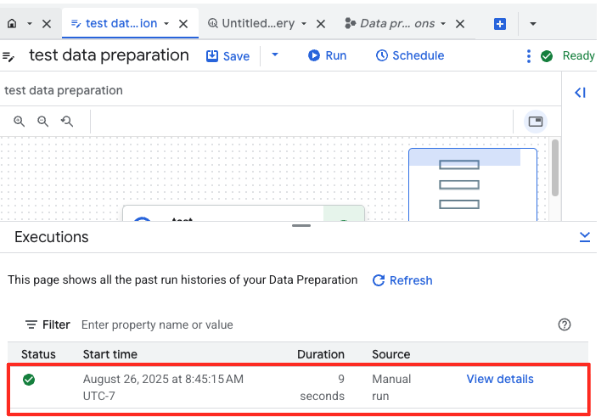
- شما میتوانید پیشرفت کار را در برگه «اجراها» در پایین صفحه مشاهده کنید. پس از چند لحظه، کار تکمیل خواهد شد.
۴. تولید جاسازیهای برداری با BQML
حالا که دادههای ما تمیز و ساختاریافته هستند، از BigQuery ML برای وظیفه اصلی هوش مصنوعی استفاده خواهیم کرد: تبدیل توضیحات متنی اثر هنری به جاسازیهای برداری عددی.
ایجاد اتصال BigQuery
برای اینکه BigQuery بتواند با سرویسهای هوش مصنوعی Vertex ارتباط برقرار کند، ابتدا باید یک اتصال BigQuery ایجاد کنید.
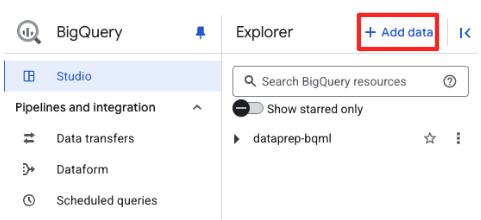
- در پنل اکسپلورر BigQuery Studio، روی دکمهی «+ افزودن داده» کلیک کنید.
- در پنل سمت راست، از نوار جستجو برای تایپ
Vertex AIاستفاده کنید. آن را انتخاب کنید و سپس BigQuery Federation را از لیست فیلتر شده انتخاب کنید.
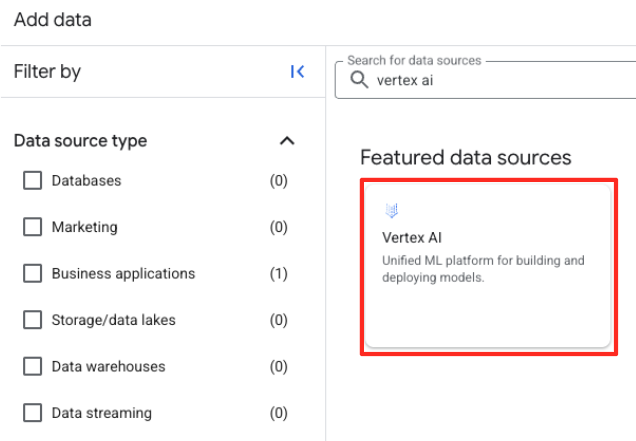
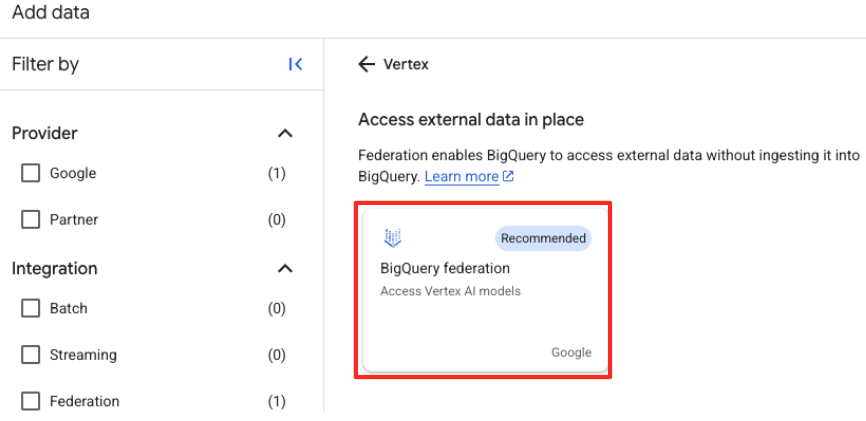
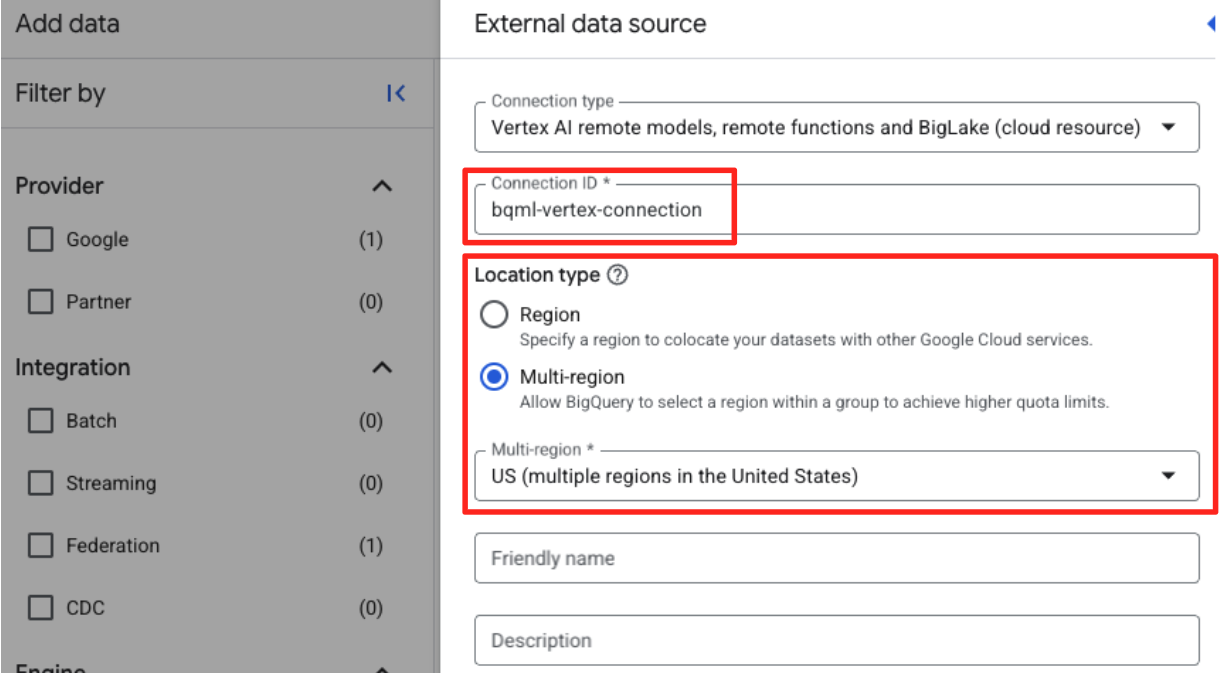
- این فرم منبع داده خارجی را باز میکند. جزئیات زیر را پر کنید:
- شناسه اتصال: شناسه اتصال را وارد کنید (مثلاً
bqml-vertex-connection) - نوع مکان: مطمئن شوید که گزینه چند منطقهای (Multi-region) انتخاب شده است.
- مکان: مکان مورد نظر (مثلاً
US) را انتخاب کنید.
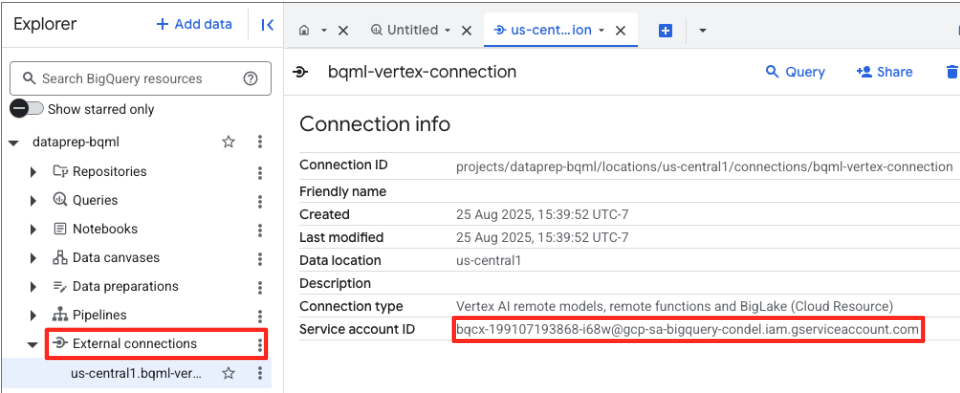
- پس از ایجاد اتصال، یک کادر محاورهای تأیید ظاهر میشود. در برگه Explorer، روی «برو به اتصال» یا «اتصالات خارجی» کلیک کنید. در صفحه جزئیات اتصال، شناسه کامل را در کلیپبورد خود کپی کنید. این شناسه حساب سرویس است که BigQuery برای فراخوانی Vertex AI از آن استفاده خواهد کرد.
- در منوی ناوبری کنسول ابری گوگل، به مسیر IAM & admin > IAM بروید.
- روی دکمه «اعطای دسترسی» کلیک کنید
- حساب کاربری سرویسی که در مرحله قبل کپی کردهاید را در فیلد New principals جایگذاری (paste) کنید.
- در منوی کشویی نقش، « کاربر هوش مصنوعی ورتکس » را تعیین کنید و روی «ذخیره» کلیک کنید.
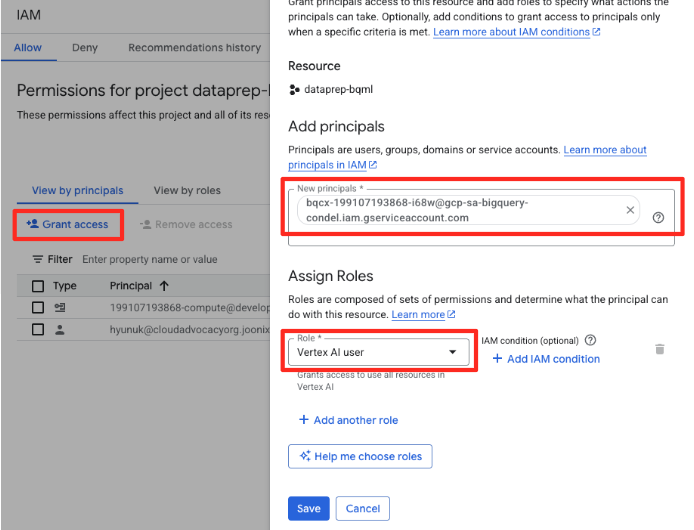
این مرحله حیاتی تضمین میکند که BigQuery مجوز لازم برای استفاده از مدلهای هوش مصنوعی Vertex را از طرف شما دارد.
ایجاد یک مدل از راه دور
در BigQuery Studio، یک تب جدید برای ویرایشگر SQL باز کنید. در اینجا مدل BQML را که به Gemini متصل میشود، تعریف خواهید کرد.
این دستور مدل جدیدی را آموزش نمیدهد. این صرفاً یک ارجاع در BigQuery ایجاد میکند که با استفاده از اتصالی که شما مجاز کردهاید، به یک مدل قدرتمند و از پیش آموزشدیدهی gemini-embedding-001 اشاره میکند.
کل اسکریپت SQL زیر را کپی کرده و در ویرایشگر BigQuery قرار دهید.
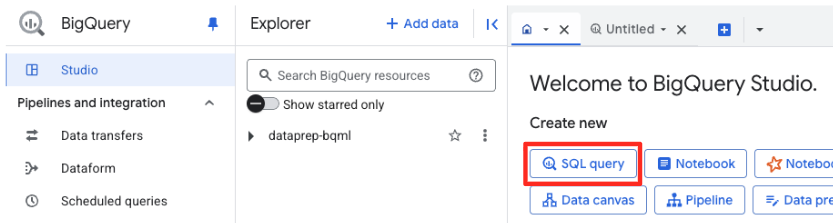
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
ایجاد جاسازیها
اکنون، ما از مدل BQML خود برای تولید جاسازیهای برداری استفاده خواهیم کرد. به جای تبدیل ساده یک برچسب متنی برای هر ردیف، از یک رویکرد پیچیدهتر برای ایجاد یک "خلاصه معنایی" غنیتر و معنادارتر برای هر اثر هنری استفاده خواهیم کرد. این امر منجر به جاسازیهای با کیفیت بالاتر و توصیههای دقیقتر خواهد شد.
این پرسوجو یک مرحله پیشپردازش حیاتی را انجام میدهد:
- از یک بند
WITHبرای ایجاد یک جدول موقت استفاده میکند. - درون آن، ما بر اساس هر
object_idGROUP BYتا تمام اطلاعات مربوط به یک اثر هنری را در یک ردیف ترکیب کنیم. - ما از تابع
STRING_AGGبرای ادغام تمام توضیحات متنی جداگانه (مانند «پرتره»، «زن»، «رنگ روغن روی بوم») در یک رشته متنی جامع و واحد استفاده میکنیم و آنها را بر اساس امتیاز مرتبط بودنشان مرتب میکنیم.
این متن ترکیبی، زمینه غنیتری از اثر هنری را در اختیار هوش مصنوعی قرار میدهد و منجر به جاسازیهای برداری ظریفتر و قدرتمندتر میشود.
در یک تب جدید ویرایشگر SQL، کوئری زیر را پیست کرده و اجرا کنید:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
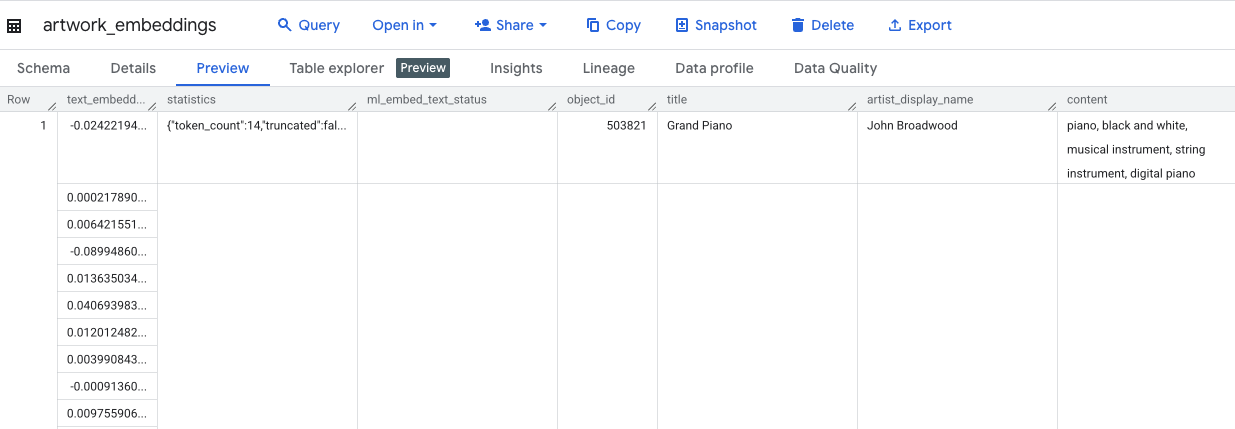
این پرسوجو تقریباً ۱۰ دقیقه طول خواهد کشید. پس از تکمیل پرسوجو، نتایج را تأیید کنید. در پنل اکسپلورر، جدول جدید artwork_embeddings خود را پیدا کرده و روی آن کلیک کنید. در نمایشگر طرحواره جدول، object_id ، ستون جدید ml_generate_text_embedding_result حاوی بردارها و همچنین ستون aggregated_labels که به عنوان متن منبع استفاده شده است را خواهید دید.
۵. یافتن آثار هنری مشابه با SQL
با تعبیههای برداری باکیفیت و غنی از متن ایجاد شده توسط ما، یافتن آثار هنری مشابه از نظر موضوعی به سادگی اجرای یک کوئری SQL است. ما از تابع ML.DISTANCE برای محاسبه شباهت کسینوسی بین بردارها استفاده میکنیم. از آنجا که تعبیههای ما از متن تجمیع شده تولید شدهاند، نتایج شباهت دقیقتر و مرتبطتر خواهند بود.
- در یک تب جدید ویرایشگر SQL، عبارت زیر را وارد کنید. این عبارت، منطق اصلی یک برنامهی توصیهگر را شبیهسازی میکند:
- ابتدا بردار مربوط به یک اثر هنری خاص (در این مورد، تابلوی "سروها" اثر ون گوگ که دارای
object_id۴۳۶۵۳۵ است) را انتخاب میکند. - سپس فاصله بین آن بردار واحد و تمام بردارهای دیگر موجود در جدول را محاسبه میکند.
- در نهایت، نتایج را بر اساس فاصله (فاصله کمتر به معنای شباهت بیشتر) مرتب میکند تا 10 مورد از نزدیکترین تطابقها را پیدا کند.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- کوئری را اجرا کنید. نتایج،
object_idها را فهرست میکنند و نزدیکترین تطابقها در بالا قرار میگیرند. تصویر منبع با فاصله ۰ ابتدا ظاهر میشود. این منطق اصلی است که یک موتور توصیه هوش مصنوعی را نیرو میدهد و شما آن را کاملاً در BigQuery و فقط با استفاده از SQL ساختهاید.
۶. (اختیاری) اجرای نسخه آزمایشی در Cloud Shell
برای زنده کردن مفاهیم این آزمایشگاه کد، مخزنی که شما کلون کردهاید شامل یک برنامه وب ساده است. این نسخه آزمایشی اختیاری از جدول artwork_embeddings که شما ایجاد کردهاید برای راهاندازی یک موتور جستجوی بصری استفاده میکند و به شما امکان میدهد توصیههای مبتنی بر هوش مصنوعی را در عمل مشاهده کنید.
برای اجرای نسخه آزمایشی در Cloud Shell، این مراحل را دنبال کنید:
- تنظیم متغیرهای محیطی: قبل از اجرای برنامه، باید متغیرهای محیطی PROJECT_ID و BIGQUERY_DATASET را تنظیم کنید.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- وابستگیها را نصب کنید و سرور backend را راهاندازی کنید.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- برای اجرای برنامه frontend به یک تب ترمینال دوم نیاز دارید. برای باز کردن یک تب جدید Cloud Shell، روی نماد "+" کلیک کنید.

- حالا، در تب جدید، دستور زیر را برای نصب وابستگیها و اجرای سرور frontend اجرا کنید.
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- پیشنمایش برنامه: در نوار ابزار Cloud Shell، روی آیکون پیشنمایش وب کلیک کنید و پیشنمایش را روی پورت ۵۱۷۳ انتخاب کنید. این کار یک برگه مرورگر جدید را با اجرای برنامه باز میکند. اکنون میتوانید از برنامه برای جستجوی آثار هنری استفاده کنید و جستجوی شباهت را در عمل مشاهده کنید.
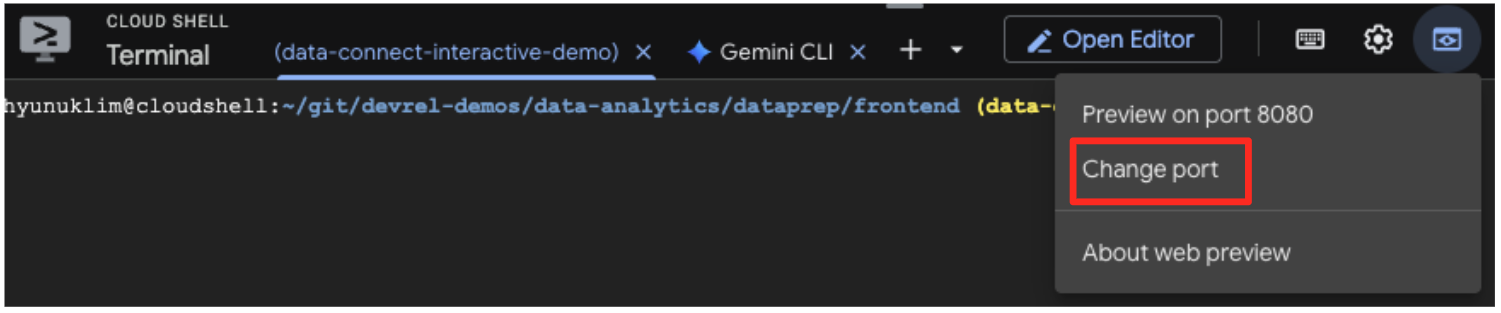
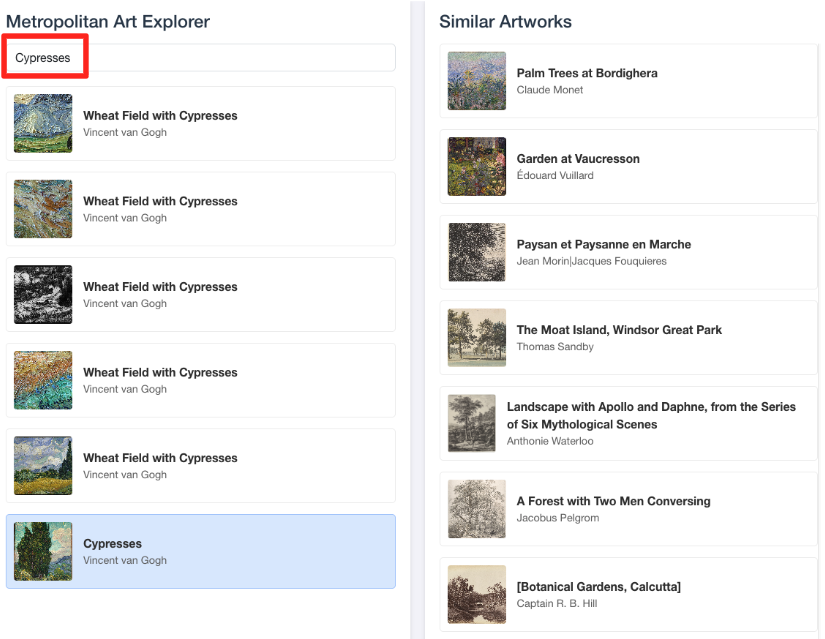
- برای اتصال این دموی تصویری به کاری که در ویرایشگر BigQuery SQL انجام دادهاید، عبارت "Cypresses" را در نوار جستجو تایپ کنید. این همان اثر هنری (
object_id=436535) است که در کوئریML.DISTANCEاستفاده کردید. سپس وقتی تصویر Cypresses در پنل سمت چپ ظاهر شد، روی آن کلیک کنید، نتایج را در سمت راست مشاهده خواهید کرد. برنامه، آثار هنری مشابه را نمایش میدهد و به صورت بصری قدرت جستجوی شباهت برداری که ساختهاید را نشان میدهد.
۷. تمیز کردن محیط زیست
برای جلوگیری از هزینههای بعدی برای حساب Google Cloud خود برای منابع استفاده شده در این آزمایشگاه کد، باید منابعی را که ایجاد کردهاید حذف کنید.
دستورات زیر را در ترمینال Cloud Shell خود اجرا کنید تا حساب سرویس، اتصال BigQuery، GCS Bucket و مجموعه داده BigQuery حذف شوند.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
حذف اتصال BigQuery و سطل GCS
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
مجموعه داده BigQuery را حذف کنید
در نهایت، مجموعه داده BigQuery را حذف کنید. این دستور برگشتناپذیر است. گزینه -f (force) مجموعه داده و تمام جداول آن را بدون درخواست تأیید حذف میکند.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
۸. تبریک میگویم!
شما با موفقیت یک خط لوله داده سرتاسری مبتنی بر هوش مصنوعی ایجاد کردهاید.
شما با یک فایل CSV خام در یک سطل GCS شروع کردید، از رابط کاربری کمکد BigQuery Data Prep برای دریافت و مسطحسازی دادههای پیچیده JSON استفاده کردید، یک مدل از راه دور قدرتمند BQML برای تولید جاسازیهای برداری با کیفیت بالا با یک مدل Gemini ایجاد کردید و یک جستجوی تشابه برای یافتن موارد مرتبط اجرا کردید.
اکنون شما به الگوی اساسی برای ساخت گردشهای کاری مبتنی بر هوش مصنوعی در Google Cloud مجهز شدهاید و میتوانید دادههای خام را با سرعت و سادگی به برنامههای هوشمند تبدیل کنید.
قدم بعدی چیست؟
- نتایج خود را در Looker Studio تجسم کنید: جدول
artwork_embeddingsBigQuery خود را مستقیماً به Looker Studio متصل کنید (رایگان است!). میتوانید یک داشبورد تعاملی بسازید که در آن کاربران میتوانند یک اثر هنری را انتخاب کنند و یک گالری تصویری از قطعات مشابه را بدون نوشتن هیچ کد frontend مشاهده کنند. - خودکارسازی با کوئریهای زمانبندیشده: برای بهروز نگهداشتن جاسازیهای خود به ابزار پیچیدهی تنظیم نیاز ندارید. از ویژگی داخلی کوئریهای زمانبندیشدهی BigQuery برای اجرای خودکار کوئری
ML.GENERATE_TEXT_EMBEDDINGبهصورت روزانه یا هفتگی استفاده کنید. - تولید یک برنامه با Gemini CLI: از Gemini CLI برای تولید یک برنامه کامل، صرفاً با توصیف نیاز خود به صورت متن ساده، استفاده کنید. این به شما امکان میدهد بدون نوشتن کد پایتون به صورت دستی، به سرعت یک نمونه اولیه کاربردی برای جستجوی شباهت خود بسازید.
- مستندات را مطالعه کنید: