
1. Introduction
Les analystes de données sont souvent confrontés à des données précieuses enfermées dans des formats semi-structurés tels que les charges utiles JSON. L'extraction et la préparation de ces données pour l'analyse et le machine learning ont toujours représenté un obstacle technique important. Elles nécessitent généralement des scripts ETL complexes et l'intervention d'une équipe d'ingénierie des données.
Cet atelier de programmation fournit un plan technique permettant aux analystes de données de relever ce défi de manière autonome. Il illustre une approche "low-code" pour créer un pipeline d'IA de bout en bout. Vous apprendrez à passer d'un fichier CSV brut dans Google Cloud Storage à une fonctionnalité de recommandation basée sur l'IA, en utilisant uniquement les outils disponibles dans BigQuery Studio.
L'objectif principal est de présenter un workflow robuste, rapide et adapté aux analystes, qui va au-delà des processus complexes et nécessitant beaucoup de code pour générer une véritable valeur commerciale à partir de vos données.
Prérequis
- Connaissances de base concernant la console Google Cloud
- Compétences de base concernant l'interface de ligne de commande et Google Cloud Shell
Points abordés
- Découvrez comment ingérer et transformer un fichier CSV directement depuis Google Cloud Storage à l'aide de la préparation des données BigQuery.
- Découvrez comment utiliser des transformations sans code pour analyser et aplatir les chaînes JSON imbriquées dans vos données.
- Comment créer un modèle distant BigQuery ML qui se connecte à un modèle de fondation Vertex AI pour l'embedding de texte.
- Utiliser la fonction
ML.GENERATE_TEXT_EMBEDDINGpour convertir des données textuelles en vecteurs numériques. - Utiliser la fonction
ML.DISTANCEpour calculer la similarité cosinus et trouver les éléments les plus similaires dans votre ensemble de données.
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome
Concepts clés
- Préparation des données BigQuery : outil de BigQuery Studio qui fournit une interface visuelle et interactive pour le nettoyage et la préparation des données. Elle suggère des transformations et permet aux utilisateurs de créer des pipelines de données avec un minimum de code.
- Modèle distant BQML : objet BigQuery ML qui sert de proxy à un modèle hébergé sur Vertex AI (comme Gemini). Elle vous permet d'appeler des modèles d'IA pré-entraînés performants à l'aide d'une syntaxe SQL familière.
- Embedding vectoriel : représentation numérique de données, telles que du texte ou des images. Dans cet atelier de programmation, nous allons convertir des descriptions textuelles d'œuvres d'art en vecteurs, où les descriptions similaires génèrent des vecteurs plus "proches" dans un espace multidimensionnel.
- Similarité cosinus : mesure mathématique utilisée pour déterminer le degré de similarité entre deux vecteurs. Il s'agit du cœur de la logique de notre moteur de recommandation, utilisé par la fonction
ML.DISTANCEpour trouver les œuvres les plus "proches" (les plus similaires).
2. Préparation
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :

Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
Activer les API requises et configurer l'environnement
Dans Cloud Shell, exécutez les commandes suivantes pour définir votre ID de projet, définir des variables d'environnement et activer toutes les API nécessaires pour cet atelier de programmation.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
Créer un ensemble de données BigQuery et un bucket GCS
Créez un ensemble de données BigQuery pour héberger nos tables et un bucket Google Cloud Storage pour stocker notre fichier CSV source.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
Préparer et importer les exemples de données
Clonez le dépôt GitHub contenant l'exemple de fichier CSV, puis importez-le dans le bucket GCS que vous venez de créer.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. De GCS à BigQuery avec la préparation des données
Dans cette section, nous allons utiliser une interface visuelle sans code pour ingérer notre fichier CSV depuis GCS, le nettoyer et le charger dans une nouvelle table BigQuery.
Lancer la préparation des données et se connecter à la source
- Dans la console Google Cloud, accédez à BigQuery Studio.
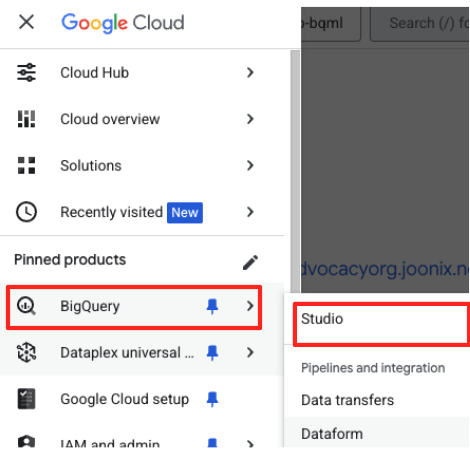
- Sur la page d'accueil, cliquez sur la fiche "Préparation des données" pour commencer.
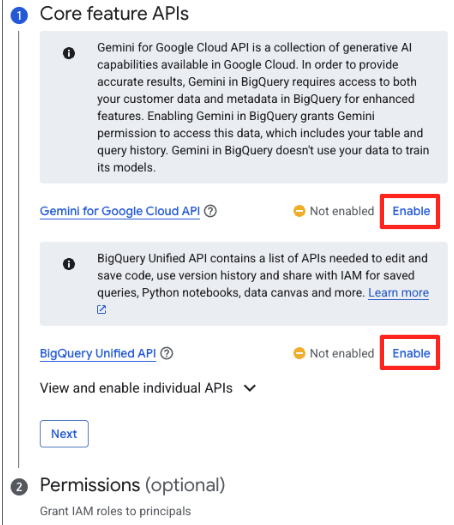
- Si c'est la première fois que vous utilisez cette fonctionnalité, vous devrez peut-être activer les API requises. Cliquez sur "Activer" pour l'API Gemini for Google Cloud et l'API BigQuery Unified. Une fois activées, vous pouvez fermer ce panneau.
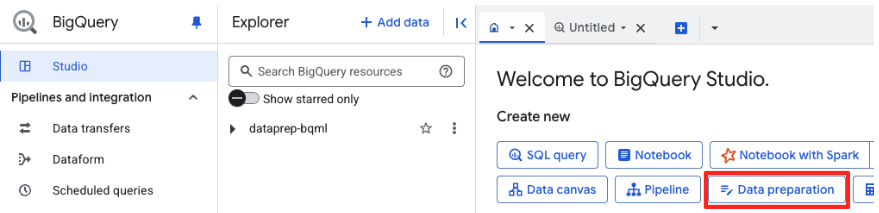
- Dans la fenêtre principale de préparation des données, sous "Choisir d'autres sources de données", cliquez sur Google Cloud Storage. Le panneau "Préparer les données" s'ouvre sur la droite.
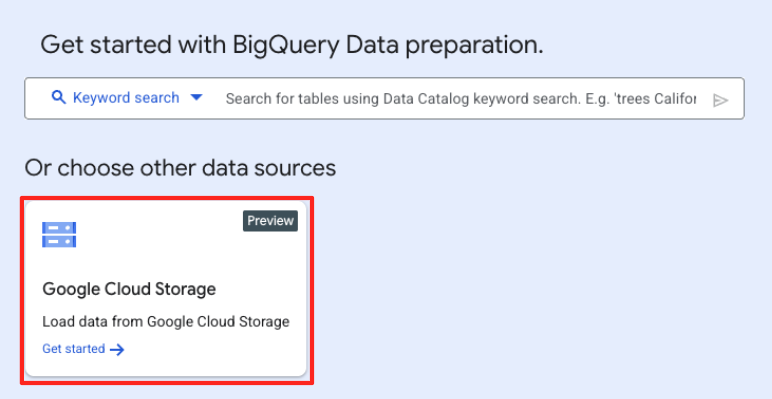
- Cliquez sur le bouton "Parcourir" pour sélectionner votre fichier source.
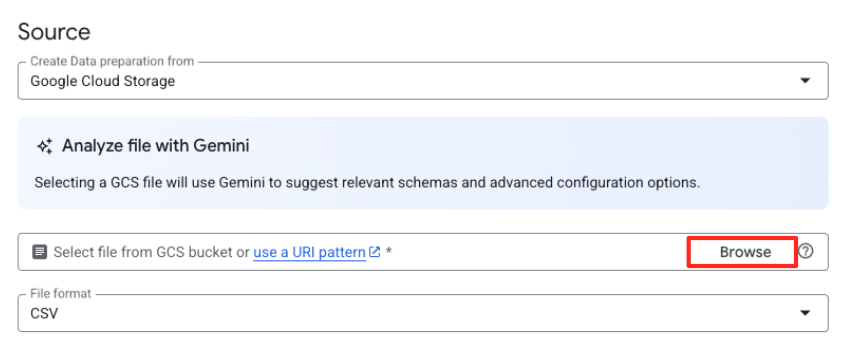
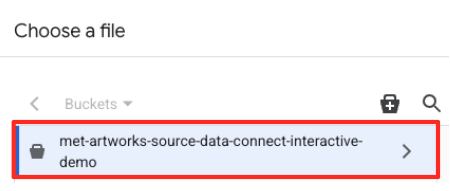
- Accédez au bucket GCS que vous avez créé précédemment (
met-artworks-source-...), puis sélectionnez le fichierdataprep-met-bqml.csv. Cliquez sur "Sélectionner".
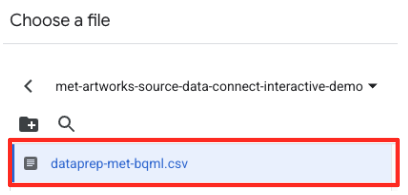
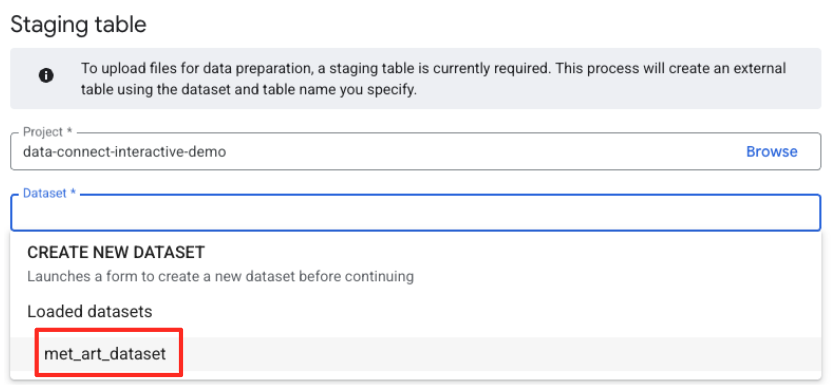
- Vous devez ensuite configurer une table intermédiaire.
- Pour "Ensemble de données", sélectionnez l'
met_art_datasetque vous avez créé. - Pour le nom de la table, saisissez un nom (par exemple,
temp). - Cliquez sur Créer.
Transformer et nettoyer les données
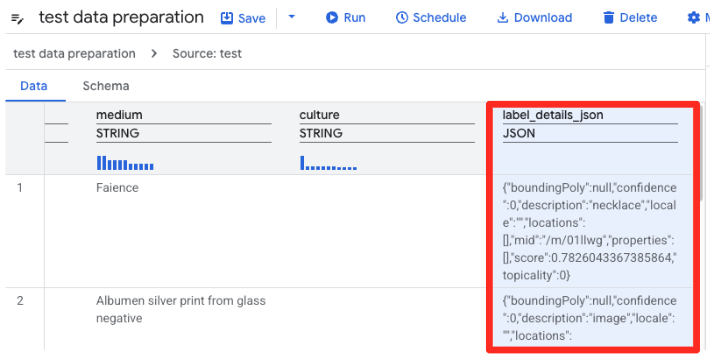
- La préparation des données de BigQuery charge désormais un aperçu du fichier CSV. Recherchez la colonne
label_details_json, qui contient la longue chaîne JSON. Cliquez sur l'en-tête de la colonne pour la sélectionner.
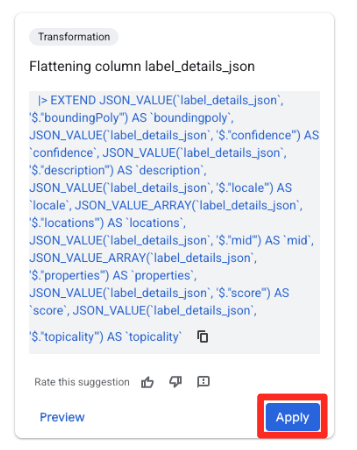
- Dans le panneau Suggestions à droite, Gemini dans BigQuery suggère automatiquement des transformations pertinentes. Cliquez sur le bouton "Appliquer" de la fiche "Aplatir la colonne
label_details_json". Les champs imbriqués (description,score, etc.) seront extraits dans leurs propres colonnes de niveau supérieur.
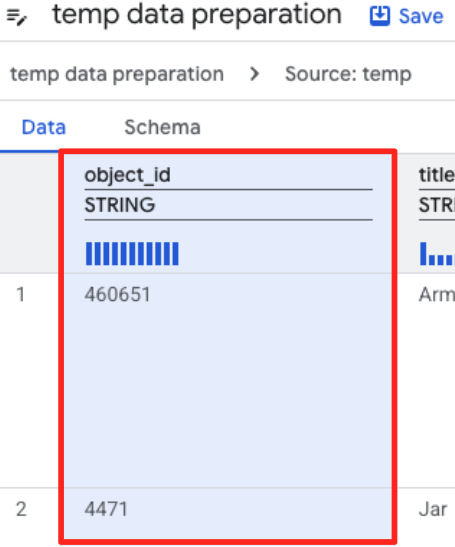
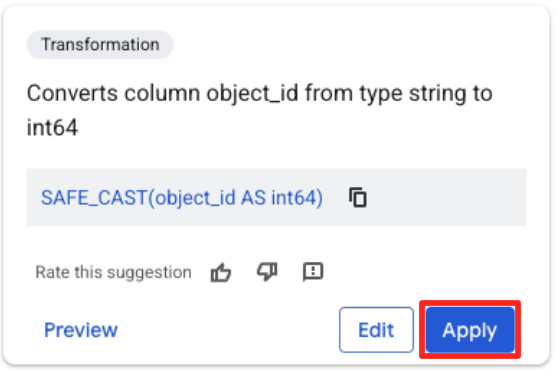
- Cliquez sur la colonne "object_id", puis sur le bouton "Convertit la colonne
object_iddu typestringau typeint64".
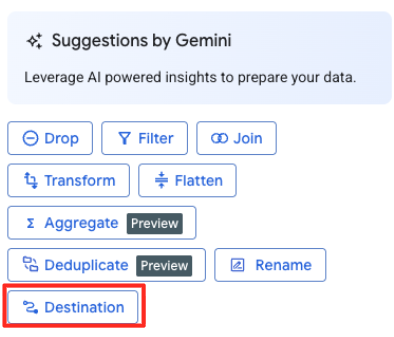
Définir la destination et exécuter le job
- Dans le panneau de droite, cliquez sur le bouton "Destination" pour configurer la sortie de votre transformation.
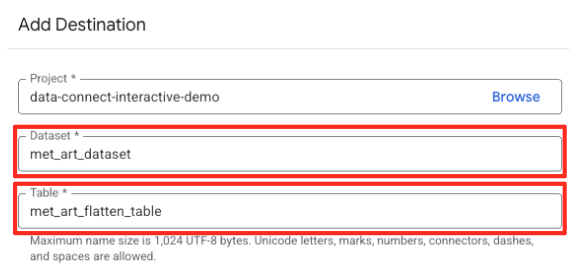
- Définissez les détails de la destination :
- Le champ "Ensemble de données" doit être prérempli avec
met_art_dataset. - Saisissez un nouveau nom de table pour la sortie :
met_art_flatten_table. - Cliquez sur "Enregistrer".
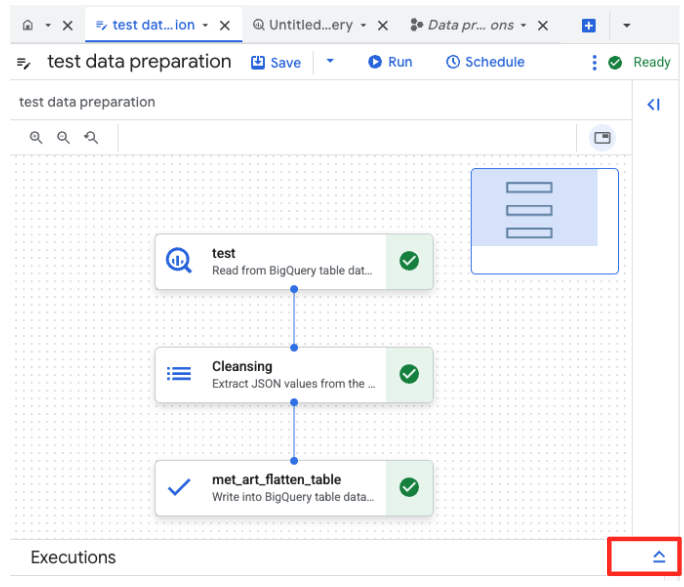
- Cliquez sur le bouton "Exécuter" et attendez la fin du job de préparation des données.
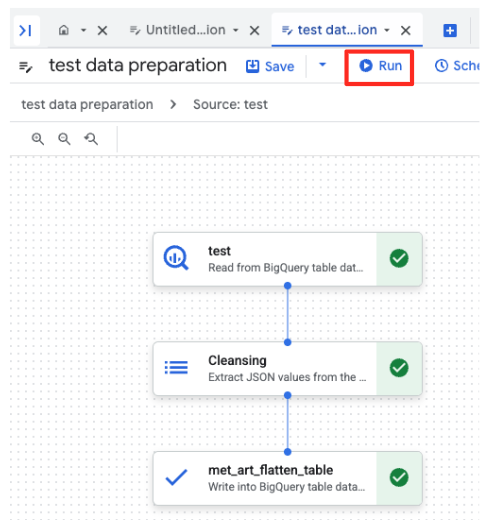
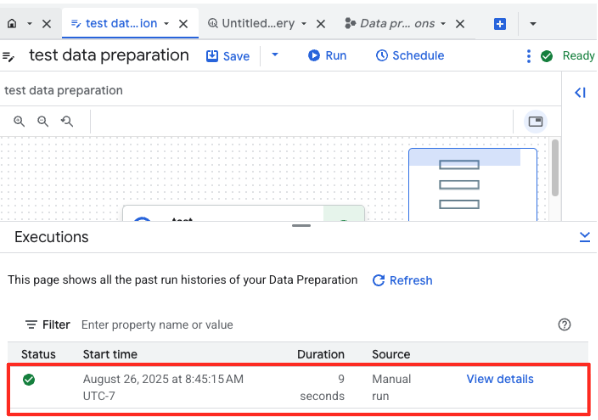
- Vous pouvez surveiller la progression du job dans l'onglet "Exécutions" en bas de la page. Au bout de quelques instants, le job se termine.
4. Générer des embeddings vectoriels avec BQML
Maintenant que nos données sont propres et structurées, nous allons utiliser BigQuery ML pour la tâche d'IA principale : convertir les descriptions textuelles des œuvres d'art en embeddings vectoriels numériques.
Créer une connexion BigQuery
Pour autoriser BigQuery à communiquer avec les services Vertex AI, vous devez d'abord créer une connexion BigQuery.
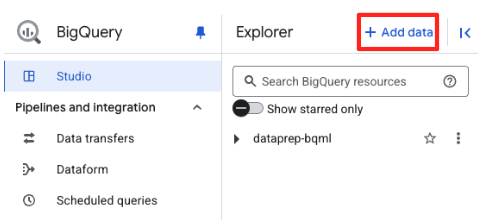
- Dans le panneau "Explorateur" de BigQuery Studio, cliquez sur le bouton "+ Ajouter des données".
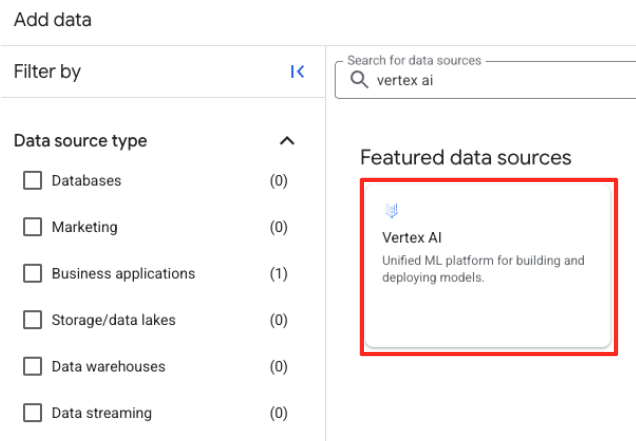
- Dans le panneau de droite, utilisez la barre de recherche pour saisir
Vertex AI. Sélectionnez-le, puis la fédération BigQuery dans la liste filtrée.
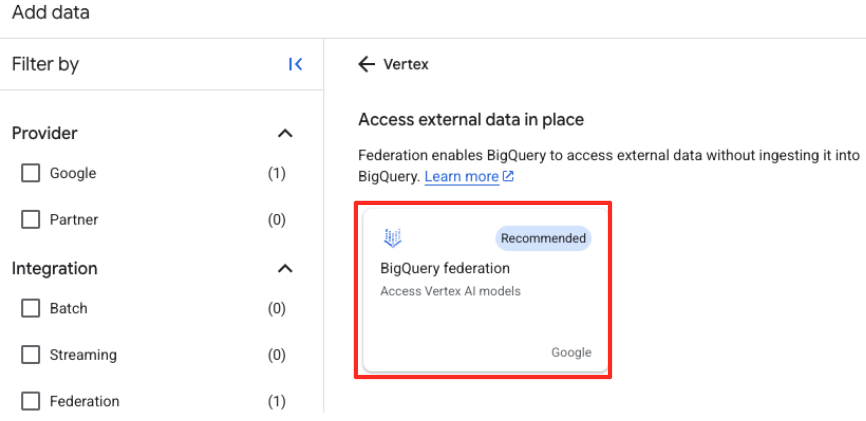
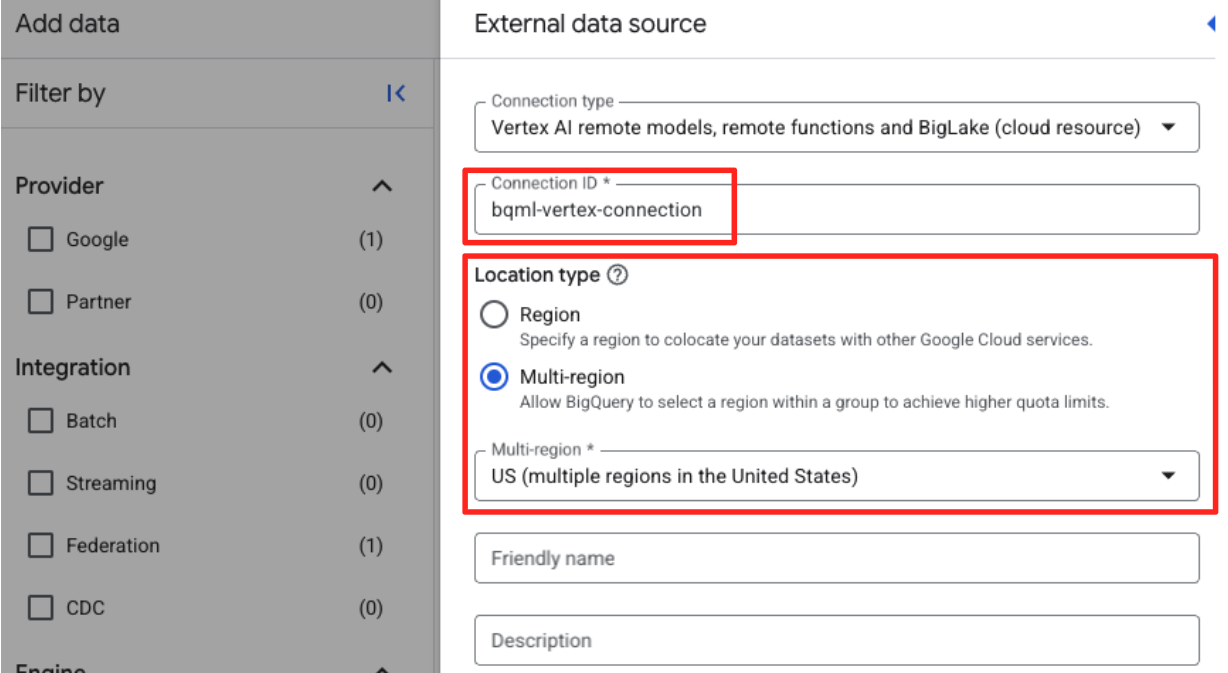
- Le formulaire "Source de données externe" s'affiche. Renseignez les informations suivantes :
- ID de connexion : saisissez l'ID de connexion (par exemple,
bqml-vertex-connection). - Type d'emplacement : assurez-vous que "Multirégional" est sélectionné.
- Emplacement : sélectionnez l'emplacement (par exemple,
US).
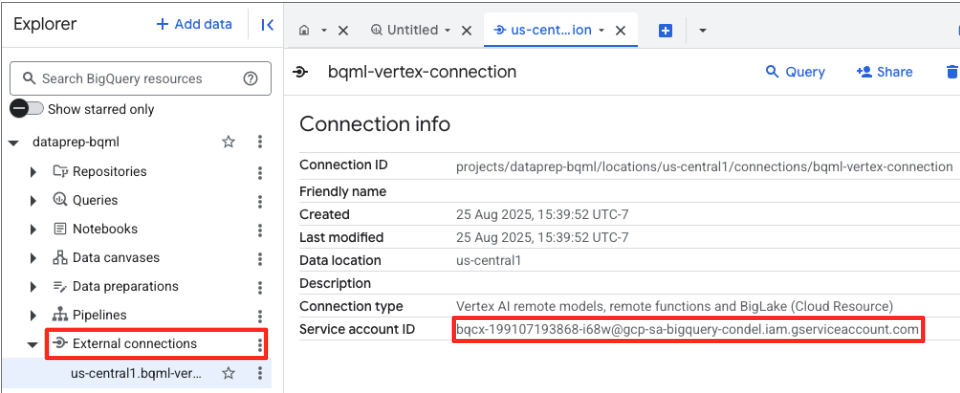
- Une fois la connexion créée, une boîte de dialogue de confirmation s'affiche. Cliquez sur "Accéder à la connexion" ou "Connexions externes" dans l'onglet "Explorateur". Sur la page d'informations sur la connexion, copiez l'ID complet dans votre presse-papiers. Il s'agit de l'identité du compte de service que BigQuery utilisera pour appeler Vertex AI.
- Dans le menu de navigation de la console Google Cloud, accédez à IAM et administration > IAM.
- Cliquez sur le bouton "Accorder l'accès".
- Collez le compte de service que vous avez copié à l'étape précédente dans le champ "Nouveaux comptes principaux".
- Attribuez le rôle Utilisateur Vertex AI dans le menu déroulant "Rôle", puis cliquez sur "Enregistrer".
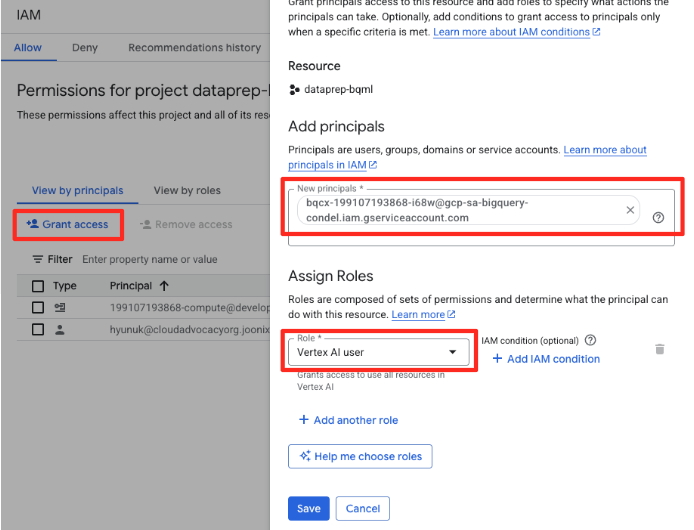
Cette étape essentielle permet de s'assurer que BigQuery dispose des autorisations appropriées pour utiliser les modèles Vertex AI en votre nom.
Créer un modèle distant
Dans BigQuery Studio, ouvrez un nouvel onglet de l'éditeur SQL. C'est ici que vous définirez le modèle BQML qui se connecte à Gemini.
Cette instruction n'entraîne pas de nouveau modèle. Il crée simplement une référence dans BigQuery qui pointe vers un puissant modèle gemini-embedding-001 pré-entraîné à l'aide de la connexion que vous venez d'autoriser.
Copiez l'intégralité du script SQL ci-dessous et collez-le dans l'éditeur BigQuery.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
Générer des embeddings
Nous allons maintenant utiliser notre modèle BQML pour générer les embeddings vectoriels. Au lieu de simplement convertir un libellé textuel unique pour chaque ligne, nous allons utiliser une approche plus sophistiquée pour créer un "résumé sémantique" plus riche et plus pertinent pour chaque œuvre. Vous obtiendrez ainsi des embeddings de meilleure qualité et des recommandations plus précises.
Cette requête effectue une étape de prétraitement essentielle :
- Elle utilise une clause
WITHpour créer d'abord une table temporaire. - À l'intérieur, nous
GROUP BYchaqueobject_idpour combiner toutes les informations sur une même œuvre d'art en une seule ligne. - Nous utilisons la fonction
STRING_AGGpour fusionner toutes les descriptions textuelles distinctes (comme "Portrait", "Femme", "Huile sur toile") en une seule chaîne de texte complète, en les classant par score de pertinence.
Ce texte combiné fournit à l'IA un contexte beaucoup plus riche sur l'œuvre d'art, ce qui permet d'obtenir des embeddings vectoriels plus nuancés et plus puissants.
Dans un nouvel onglet de l'éditeur SQL, collez et exécutez la requête suivante :
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
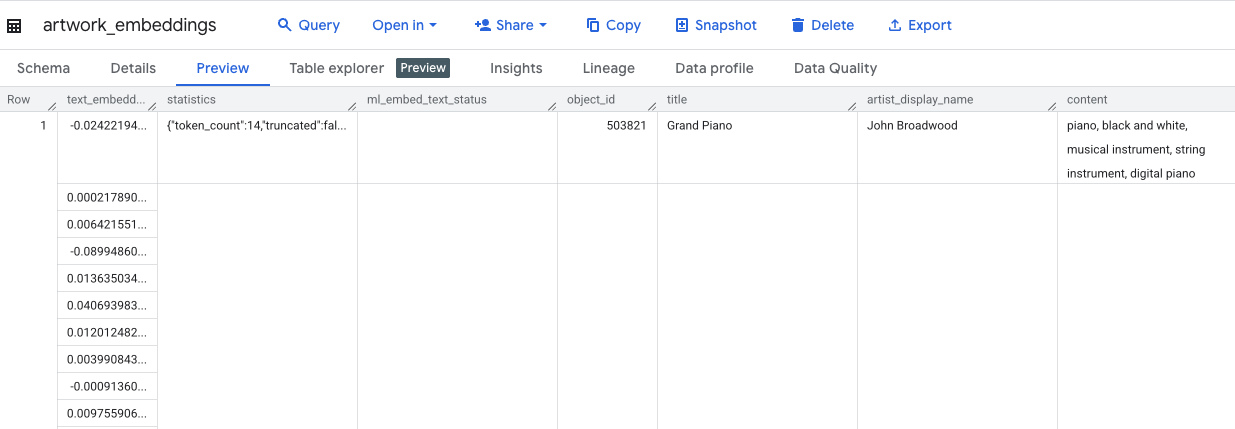
Cette requête prendra environ 10 minutes. Une fois la requête terminée, vérifiez les résultats. Dans le panneau "Explorateur", recherchez votre nouvelle table artwork_embeddings et cliquez dessus. Dans le lecteur de schéma de table, vous verrez object_id, la nouvelle colonne ml_generate_text_embedding_result contenant les vecteurs, ainsi que la colonne aggregated_labels qui a été utilisée comme texte source.
5. Trouver des œuvres d'art similaires avec SQL
Une fois nos embeddings vectoriels de haute qualité et riches en contexte créés, il suffit d'exécuter une requête SQL pour trouver des œuvres d'art similaires sur le plan thématique. Nous utilisons la fonction ML.DISTANCE pour calculer la similarité cosinus entre les vecteurs. Comme nos embeddings ont été générés à partir de texte agrégé, les résultats de similarité seront plus précis et pertinents.
- Dans un nouvel onglet de l'éditeur SQL, collez la requête suivante. Cette requête simule la logique de base d'une application de recommandation :
- Il sélectionne d'abord le vecteur d'une œuvre d'art spécifique (dans ce cas, "Cypresses" de Van Gogh, dont l'
object_idest de 436535). - Elle calcule ensuite la distance entre ce vecteur unique et tous les autres vecteurs du tableau.
- Enfin, il trie les résultats par distance (plus la distance est petite, plus les résultats sont similaires) pour trouver les 10 correspondances les plus proches.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- Exécutez la requête. Les résultats listent les
object_id, les correspondances les plus proches étant en haut de la liste. L'illustration source s'affiche en premier avec une distance de 0. Il s'agit de la logique de base qui alimente un moteur de recommandation d'IA, et vous l'avez entièrement créée dans BigQuery en utilisant uniquement SQL.
6. (FACULTATIF) Exécuter la démo dans Cloud Shell
Pour donner vie aux concepts de cet atelier de programmation, le dépôt que vous avez cloné inclut une application Web simple. Cette démo facultative utilise la table artwork_embeddings que vous avez créée pour alimenter un moteur de recherche visuel, ce qui vous permet de voir les recommandations basées sur l'IA en action.
Pour exécuter la démo dans Cloud Shell, procédez comme suit :
- Définissez les variables d'environnement : avant d'exécuter l'application, vous devez définir les variables d'environnement PROJECT_ID et BIGQUERY_DATASET.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- Installez les dépendances et démarrez le serveur de backend.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- Vous aurez besoin d'un deuxième onglet de terminal pour exécuter l'application frontend. Cliquez sur l'icône "+" pour ouvrir un nouvel onglet Cloud Shell.

- Dans le nouvel onglet, exécutez la commande suivante pour installer les dépendances et exécuter le serveur frontend.
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- Prévisualisez l'application : dans la barre d'outils Cloud Shell, cliquez sur l'icône Aperçu sur le Web, puis sélectionnez "Prévisualiser sur le port 5173". Un nouvel onglet de navigateur s'ouvre avec l'application en cours d'exécution. Vous pouvez désormais utiliser l'application pour rechercher des œuvres d'art et voir la recherche par similarité en action.
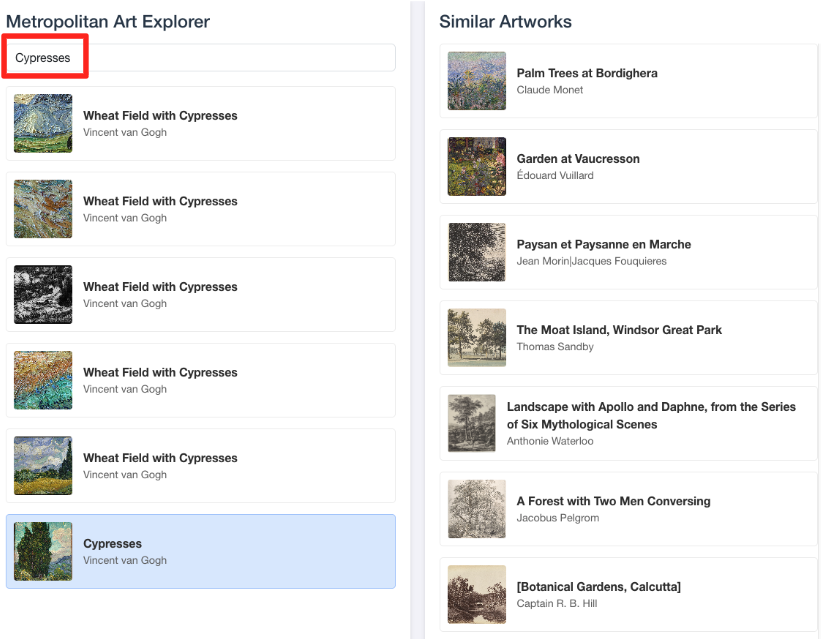
- Pour relier cette démo visuelle au travail que vous avez effectué dans l'éditeur SQL BigQuery, essayez de saisir "Cypresses" dans la barre de recherche. Il s'agit de la même illustration(
object_id=436535) que celle utilisée dans la requêteML.DISTANCE. Cliquez ensuite sur l'image des Cyprès lorsqu'elle apparaît dans le panneau de gauche. Les résultats s'affichent à droite. L'application affiche les œuvres les plus similaires, ce qui démontre visuellement la puissance de la recherche de similarité vectorielle que vous avez créée.
7. Nettoyer votre environnement
Pour éviter que les ressources utilisées dans cet atelier de programmation ne soient facturées sur votre compte Google Cloud, supprimez celles que vous avez créées.
Exécutez les commandes suivantes dans votre terminal Cloud Shell pour supprimer le compte de service, la connexion BigQuery, le bucket GCS et l'ensemble de données BigQuery.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
Supprimer la connexion BigQuery et le bucket GCS
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
Supprimer l'ensemble de données BigQuery
Enfin, supprimez l'ensemble de données BigQuery. Cette commande est irréversible. L'option -f (force) supprime l'ensemble de données et toutes ses tables sans demander de confirmation.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. Félicitations !
Vous avez créé un pipeline de données de bout en bout optimisé par l'IA.
Vous avez commencé avec un fichier CSV brut dans un bucket GCS, utilisé l'interface low-code de BigQuery Data Prep pour ingérer et aplatir des données JSON complexes, créé un modèle distant BQML puissant pour générer des embeddings vectoriels de haute qualité avec un modèle Gemini, et exécuté une requête de recherche par similarité pour trouver des éléments associés.
Vous disposez désormais du modèle fondamental pour créer des workflows assistés par l'IA sur Google Cloud, en transformant les données brutes en applications intelligentes rapidement et facilement.
Et ensuite ?
- Visualisez vos résultats dans Looker Studio : connectez votre table BigQuery
artwork_embeddingsdirectement à Looker Studio (sans frais). Vous pouvez créer un tableau de bord interactif dans lequel les utilisateurs peuvent sélectionner une œuvre d'art et afficher une galerie visuelle des œuvres les plus similaires, sans écrire de code frontend. - Automatisez avec les requêtes planifiées : vous n'avez pas besoin d'un outil d'orchestration complexe pour maintenir vos embeddings à jour. Utilisez la fonctionnalité Requêtes programmées intégrée à BigQuery pour réexécuter automatiquement la requête
ML.GENERATE_TEXT_EMBEDDINGquotidiennement ou hebdomadairement. - Générez une application avec la Gemini CLI : utilisez la Gemini CLI pour générer une application complète en décrivant simplement vos besoins en texte brut. Cela vous permet de créer rapidement un prototype fonctionnel pour votre recherche par similarité sans écrire manuellement le code Python.
- Consultez la documentation :