
1. מבוא
אנליסטים של נתונים נתקלים לעיתים קרובות בנתונים חשובים שנעולים בפורמטים חצי-מובנים כמו מטען ייעודי (payload) של JSON. שליפה והכנה של הנתונים האלה לצורך ניתוח ולמידת מכונה היו בעבר אתגר טכני משמעותי, שדרש בדרך כלל סקריפטים מורכבים של ETL והתערבות של צוות הנדסת נתונים.
ב-codelab הזה מוצג תרשים טכני שיעזור לנתח נתונים להתמודד עם האתגר הזה באופן עצמאי. הוא מדגים גישה של "עם תכנות מינימלי" לבניית צינור עיבוד נתונים של AI מקצה לקצה. תלמדו איך להשתמש רק בכלים שזמינים ב-BigQuery Studio כדי להפוך קובץ CSV גולמי ב-Google Cloud Storage לתכונת המלצות מבוססת-AI.
המטרה העיקרית היא להדגים תהליך עבודה חזק, מהיר וידידותי לאנליסטים, שחורג מתהליכים מורכבים שכוללים הרבה קוד, כדי להפיק ערך עסקי אמיתי מהנתונים.
דרישות מוקדמות
- הבנה בסיסית של מסוף Google Cloud
- מיומנויות בסיסיות בממשק שורת הפקודה וב-Google Cloud Shell
מה תלמדו
- איך להטמיע ולשנות קובץ CSV ישירות מ-Google Cloud Storage באמצעות הכלי להכנת נתונים ב-BigQuery.
- איך משתמשים בהמרות בלי צורך בתכנות כדי לנתח ולשטח מחרוזות JSON מוטמעות בנתונים.
- איך ליצור מודל מרוחק של BigQuery ML שמתחבר למודל בסיס של Vertex AI להטמעת טקסט.
- איך משתמשים בפונקציה
ML.GENERATE_TEXT_EMBEDDINGכדי להמיר נתונים טקסטואליים לווקטורים מספריים. - איך משתמשים בפונקציה
ML.DISTANCEכדי לחשב את הדמיון הקוסינוסי ולמצוא את הפריטים הדומים ביותר במערך הנתונים.
מה תצטרכו
- חשבון Google Cloud ופרויקט Google Cloud
- דפדפן אינטרנט כמו Chrome
מושגים מרכזיים
- הכנת נתונים ב-BigQuery: כלי ב-BigQuery Studio שמספק ממשק אינטראקטיבי ויזואלי לניקוי ולהכנה של נתונים. הוא מציע טרנספורמציות ומאפשר למשתמשים ליצור צינורות עיבוד נתונים עם מינימום קוד.
- מודל מרוחק של BQML: אובייקט של BigQuery ML שמשמש כפרוקסי למודל שמתארח ב-Vertex AI (כמו Gemini). היא מאפשרת להפעיל מודלים חזקים של AI שעברו אימון מראש, באמצעות תחביר SQL מוכר.
- הטמעת וקטורים: ייצוג מספרי של נתונים, כמו טקסט או תמונות. ב-codelab הזה נמיר תיאורי טקסט של יצירות אומנות לווקטורים, כך שתיאורים דומים יניבו וקטורים שיהיו 'קרובים יותר' זה לזה במרחב רב-ממדי.
- דמיון קוסינוס: מדד מתמטי שמשמש לקביעת מידת הדמיון בין שני וקטורים. היא מהווה את ליבת הלוגיקה של מנוע ההמלצות שלנו, ומשמשת את הפונקציה
ML.DISTANCEכדי למצוא את יצירות האומנות ה"קרובות" ביותר (הדומות ביותר).
2. הגדרה ודרישות
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-codelab הזה תשתמשו ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:

יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, אמור להופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
הפעלת ממשקי API נדרשים והגדרת הסביבה
ב-Cloud Shell, מריצים את הפקודות הבאות כדי להגדיר את מזהה הפרויקט, להגדיר משתני סביבה ולהפעיל את כל ממשקי ה-API הנדרשים ל-codelab הזה.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
יצירת מערך נתונים ב-BigQuery ודליקט ב-GCS
יוצרים מערך נתונים חדש ב-BigQuery כדי לאחסן את הטבלאות, וקטגוריה של Cloud Storage כדי לאחסן את קובץ ה-CSV של המקור.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
הכנה והעלאה של נתוני הדגימה
משכפלים את מאגר GitHub שמכיל את קובץ ה-CSV לדוגמה ואז מעלים אותו לקטגוריית GCS שיצרתם.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. מ-GCS ל-BigQuery עם הכנה של נתונים
בקטע הזה נשתמש בממשק ויזואלי בלי צורך בתכנות כדי להטמיע את קובץ ה-CSV מ-GCS, לנקות אותו ולטעון אותו לטבלה חדשה ב-BigQuery.
הפעלת הכנת נתונים וקישור למקור
- במסוף Google Cloud, עוברים אל BigQuery Studio.
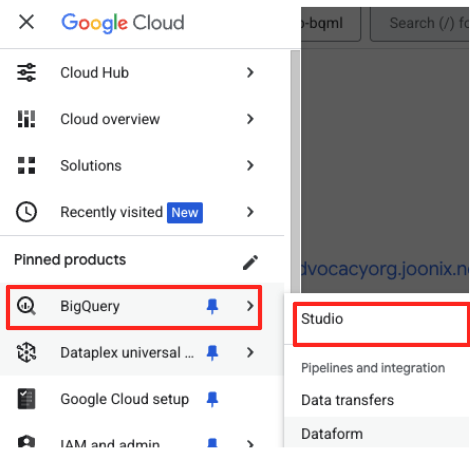
- בדף הפתיחה, לוחצים על כרטיס ההכנה של הנתונים כדי להתחיל.
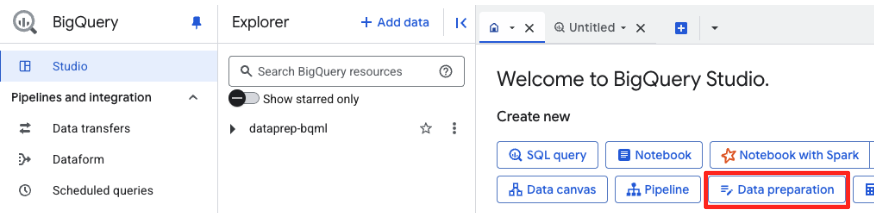
- אם זו הפעם הראשונה שאתם עושים זאת, יכול להיות שתצטרכו להפעיל את ממשקי ה-API הנדרשים. לוחצים על Enable (הפעלה) גם עבור Gemini for Google Cloud API וגם עבור BigQuery Unified API. אחרי שמפעילים אותם, אפשר לסגור את החלונית הזו.
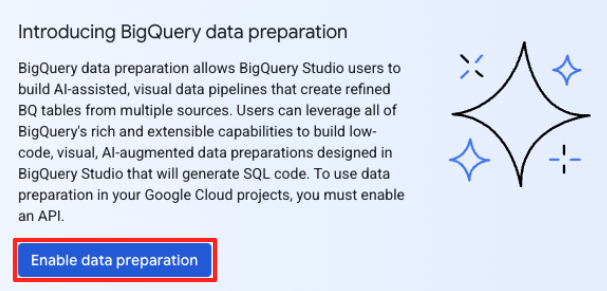
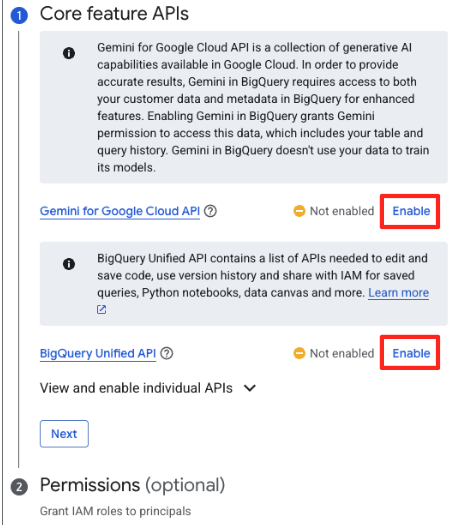
- בחלון הראשי של הכנת הנתונים, בקטע 'בחירת מקורות נתונים אחרים', לוחצים על Google Cloud Storage. החלונית 'הכנת נתונים' תיפתח בצד שמאל.
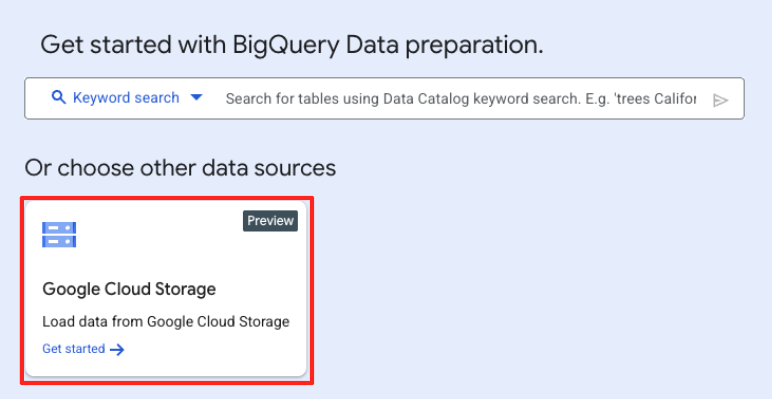
- לוחצים על הלחצן 'עיון' כדי לבחור את קובץ המקור.
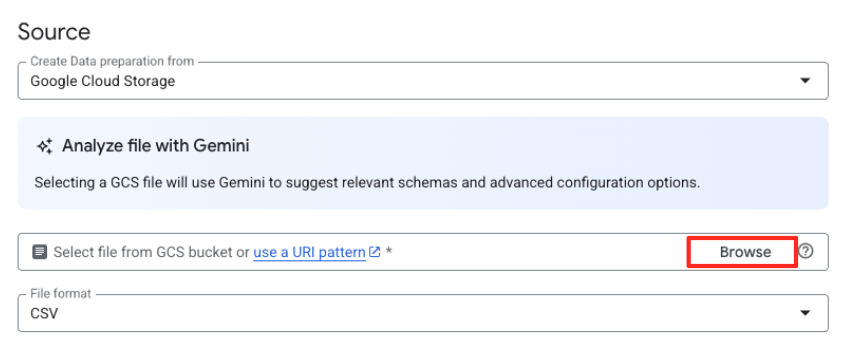
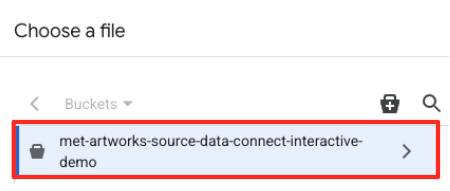
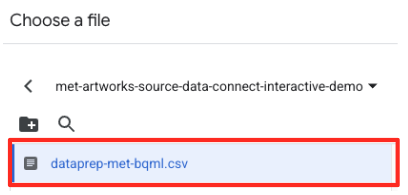
- עוברים אל קטגוריית GCS שיצרתם קודם (
met-artworks-source-...) ובוחרים את הקובץdataprep-met-bqml.csv. לוחצים על 'בחירה'.
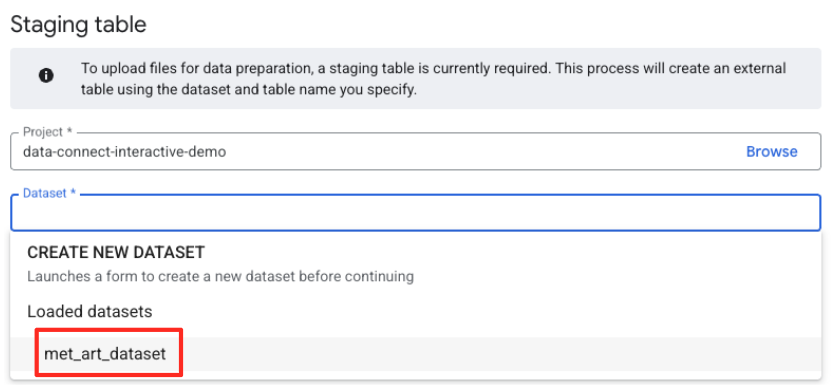
- בשלב הבא, צריך להגדיר טבלת ביניים.
- בקטע Dataset (מערך נתונים), בוחרים את
met_art_datasetשיצרתם. - בשדה Table name (שם הטבלה), מזינים שם, לדוגמה,
temp. - לוחצים על 'יצירה'.
טרנספורמציה וניקוי של הנתונים
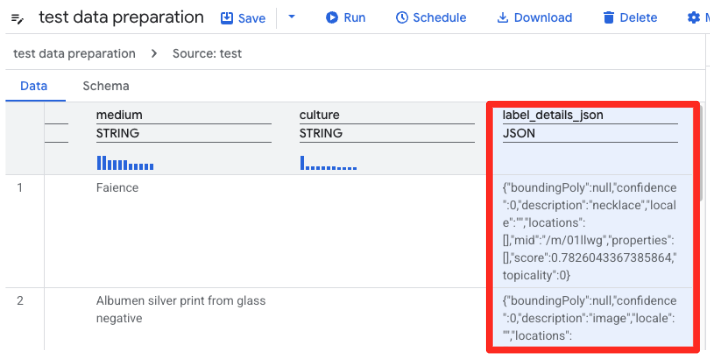
- בתצוגה המקדימה של קובץ ה-CSV שנטען ב-BigQuery, מחפשים את העמודה
label_details_json, שמכילה את מחרוזת ה-JSON הארוכה. לוחצים על כותרת העמודה כדי לבחור אותה.
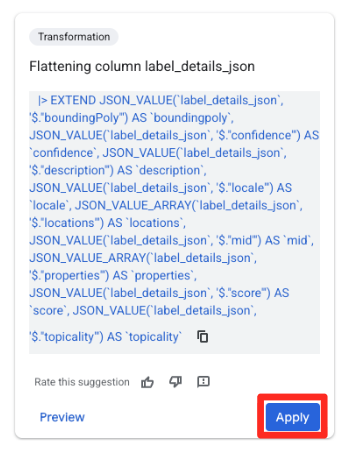
- בחלונית הצעות שמופיעה בצד שמאל, Gemini ב-BigQuery יציע באופן אוטומטי טרנספורמציות רלוונטיות. לוחצים על הלחצן Apply (החלה) בכרטיס Flattening column
label_details_json(השטחת העמודהlabel_details_json). הפעולה הזו תחלץ את השדות בתוך השדות (description,scoreוכו') לעמודות משלהם ברמה העליונה.
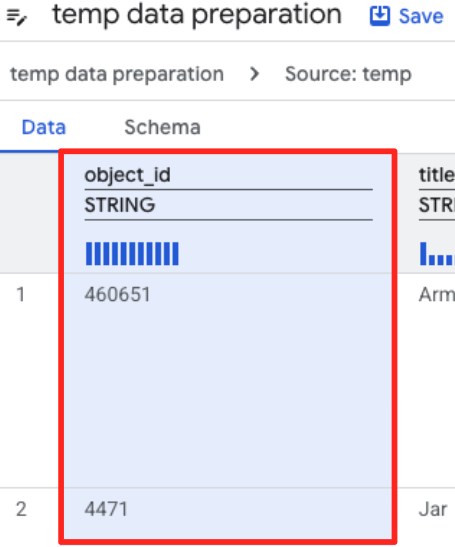
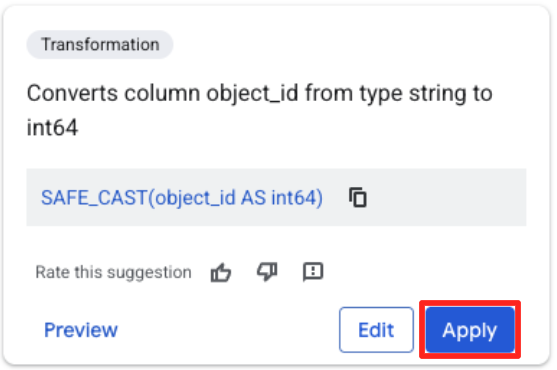
- לוחצים על העמודה object_id ואז על הלחצן 'המרת העמודה
object_idמסוגstringל-int64'.
הגדרת היעד והפעלת העבודה
- בחלונית השמאלית, לוחצים על לחצן היעד כדי להגדיר את הפלט של ההמרה.
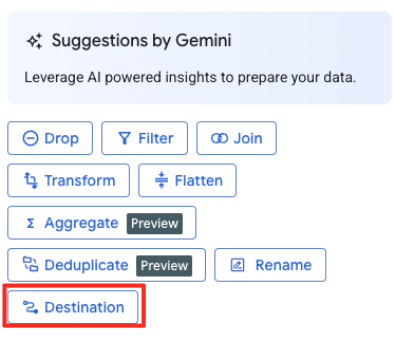
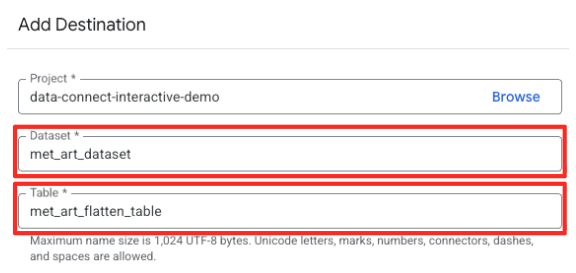
- מגדירים את פרטי היעד:
- קבוצת הנתונים צריכה להיות מאוכלסת מראש בערך
met_art_dataset. - מזינים שם חדש לטבלה של הפלט:
met_art_flatten_table. - לוחצים על 'שמירה'.
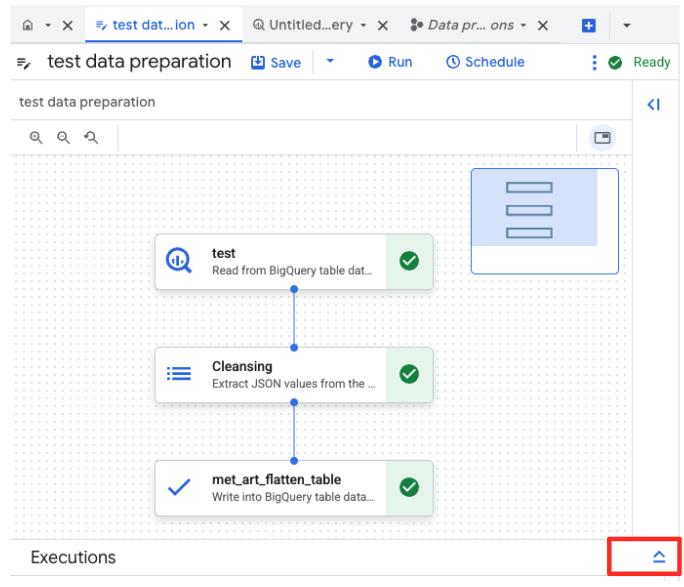
- לוחצים על הלחצן 'הפעלה' ומחכים עד שמשימת הכנת הנתונים תושלם.
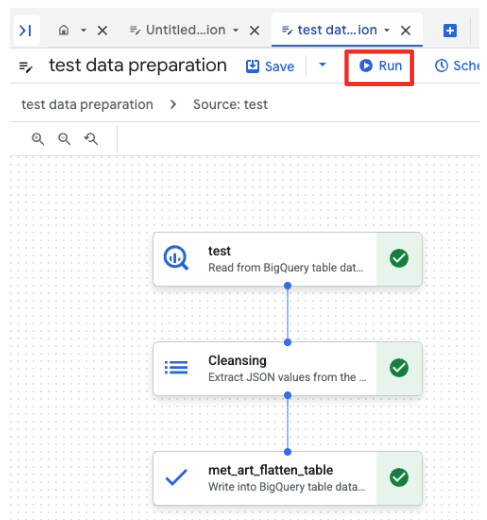
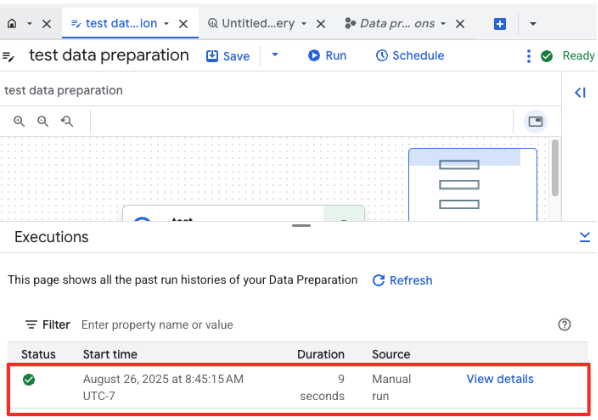
- אפשר לעקוב אחרי התקדמות העבודה בכרטיסייה 'הפעלות' בתחתית הדף. אחרי כמה רגעים, המשימה תסתיים.
4. יצירת הטמעות וקטורים באמצעות BQML
עכשיו, אחרי שהנתונים שלנו נקיים ומובנים, נשתמש ב-BigQuery ML למשימת AI הליבה: המרת התיאורים הטקסטואליים של יצירות האומנות להטמעות של וקטורים מספריים.
יצירת חיבור ל-BigQuery
כדי לאפשר ל-BigQuery לתקשר עם שירותי Vertex AI, קודם צריך ליצור חיבור ל-BigQuery.
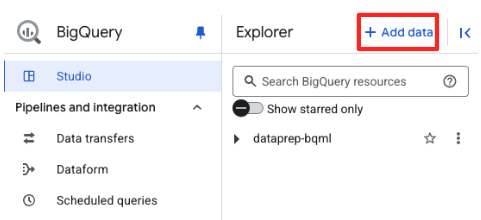
- בחלונית Explorer ב-BigQuery Studio, לוחצים על הלחצן '+ הוספת נתונים'.
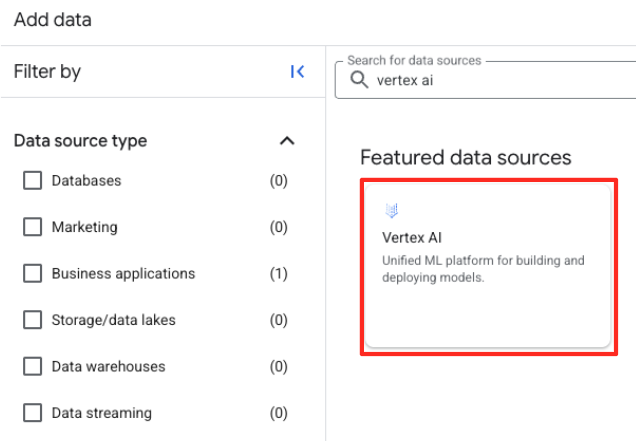
- בחלונית השמאלית, מקלידים
Vertex AIבסרגל החיפוש. בוחרים אותו ואז בוחרים באפשרות BigQuery federation (פדרציה של BigQuery) מתוך הרשימה המסוננת.
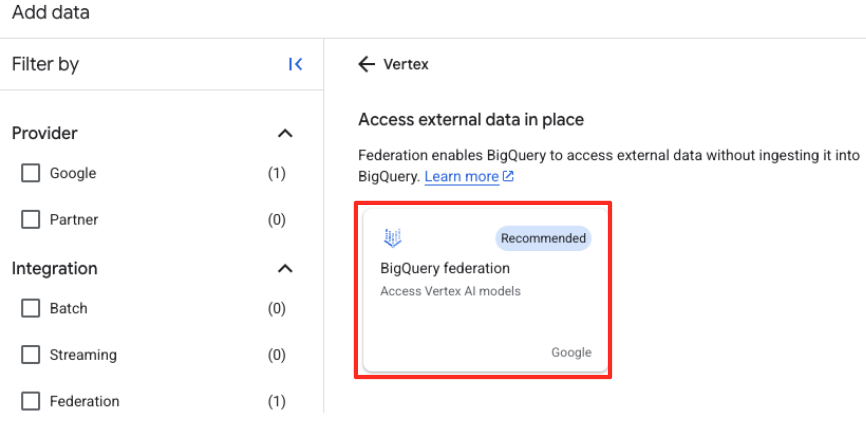
- ייפתח טופס של מקור נתונים חיצוני. ממלאים את הפרטים הבאים:
- מזהה החיבור: מזינים את מזהה החיבור (לדוגמה,
bqml-vertex-connection) - סוג המיקום: מוודאים שהאפשרות 'מספר אזורים' נבחרה.
- מיקום: בוחרים את המיקום (לדוגמה,
US).
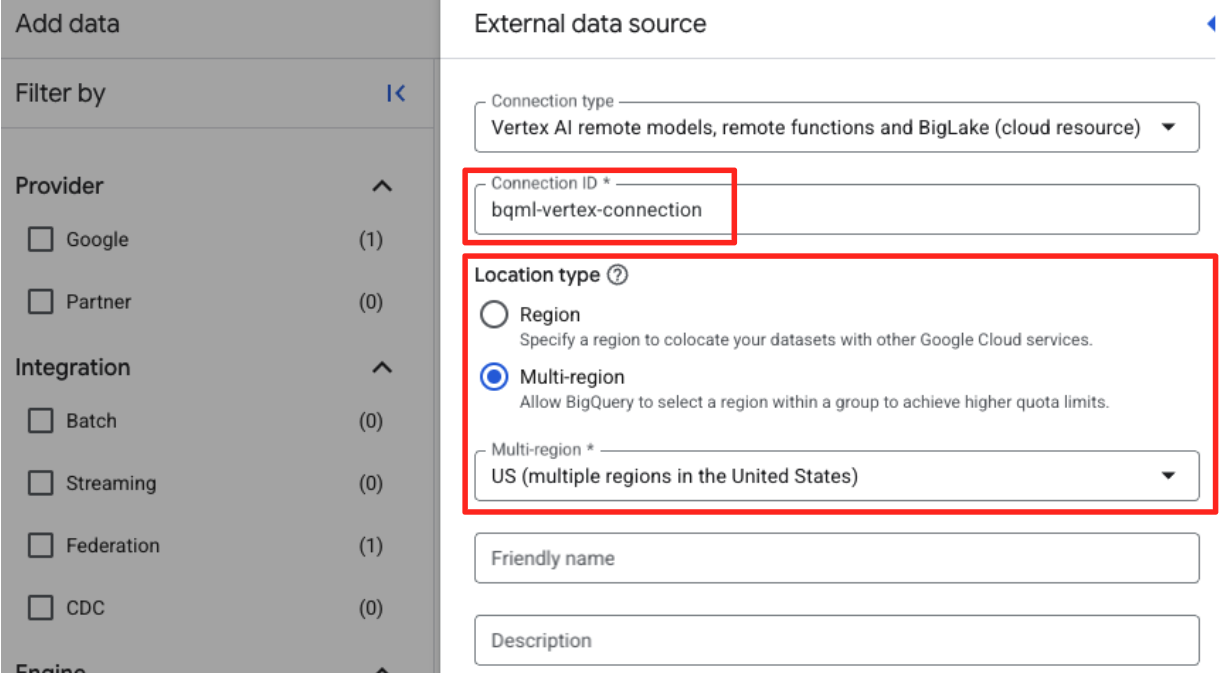
- אחרי יצירת החיבור, תופיע תיבת דו-שיח לאישור. בכרטיסייה 'סייר', לוחצים על 'מעבר לחיבור' או על 'חיבורים חיצוניים'. בדף פרטי החיבור, מעתיקים את המזהה המלא ללוח. זוהי הזהות של חשבון השירות ש-BigQuery ישתמש בה כדי להתקשר ל-Vertex AI.
- בתפריט הניווט של מסוף Google Cloud, עוברים אל IAM & admin (ניהול IAM) > IAM.
- לוחצים על הלחצן 'אישור גישה'.
- מדביקים את חשבון השירות שהעתקתם בשלב הקודם בשדה New principals (עקרונות חדשים).
- בתפריט הנפתח 'תפקיד', בוחרים באפשרות משתמש Vertex AI ולוחצים על 'שמירה'.
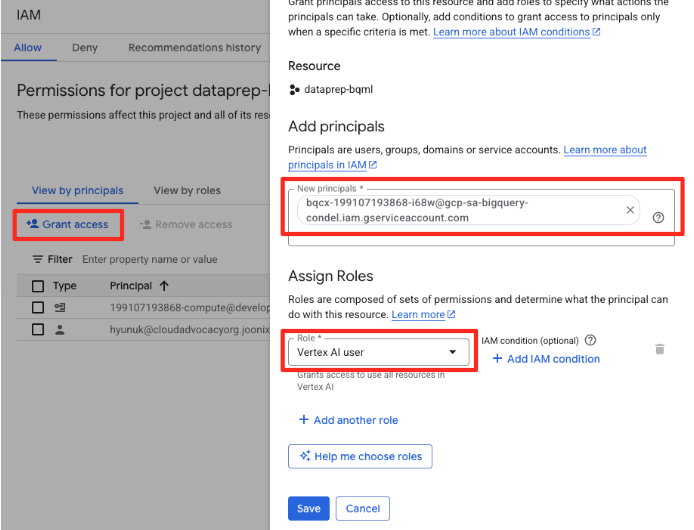
השלב הזה חשוב מאוד כדי לוודא של-BigQuery יש הרשאה מתאימה להשתמש במודלים של Vertex AI בשמכם.
יצירת מודל Remote
ב-BigQuery Studio, פותחים כרטיסייה חדשה של עורך SQL. כאן מגדירים את מודל BQML שמתחבר ל-Gemini.
ההצהרה הזו לא מאמנת מודל חדש. הוא פשוט יוצר ב-BigQuery הפניה למודל gemini-embedding-001 עוצמתי שאומן מראש, באמצעות החיבור שאישרתם זה עתה.
מעתיקים את כל סקריפט ה-SQL שבהמשך ומדביקים אותו בעורך של BigQuery.
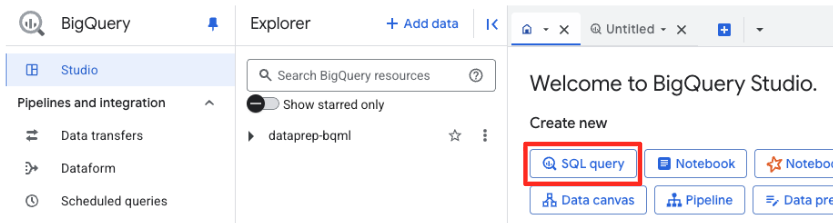
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
יצירת הטמעות
עכשיו נשתמש במודל BQML כדי ליצור את הטמעות הווקטורים. במקום להמיר פשוט תווית טקסט אחת לכל שורה, נשתמש בגישה מתוחכמת יותר כדי ליצור 'סיכום סמנטי' עשיר ומשמעותי יותר לכל יצירת אמנות. כך תקבלו הטמעות איכותיות יותר והמלצות מדויקות יותר.
השאילתה הזו מבצעת שלב קריטי של עיבוד מקדים:
- היא משתמשת בתנאי
WITHכדי ליצור קודם טבלה זמנית. - בתוך ה-
GROUP BY, אנחנוobject_idכלobject_idכדי לשלב את כל המידע על יצירת אמנות אחת בשורה אחת. - אנחנו משתמשים בפונקציה
STRING_AGGכדי למזג את כל תיאורי הטקסט הנפרדים (כמו 'דיוקן', 'אישה', 'שמן על בד') למחרוזת טקסט אחת מקיפה, ומסדרים אותם לפי ציון הרלוונטיות שלהם.
הטקסט המשולב הזה מספק ל-AI הקשר עשיר יותר לגבי יצירת האומנות, וכך מוביל להטמעות וקטוריות מדויקות ועוצמתיות יותר.
בכרטיסייה חדשה של עורך SQL, מדביקים את השאילתה הבאה ומריצים אותה:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
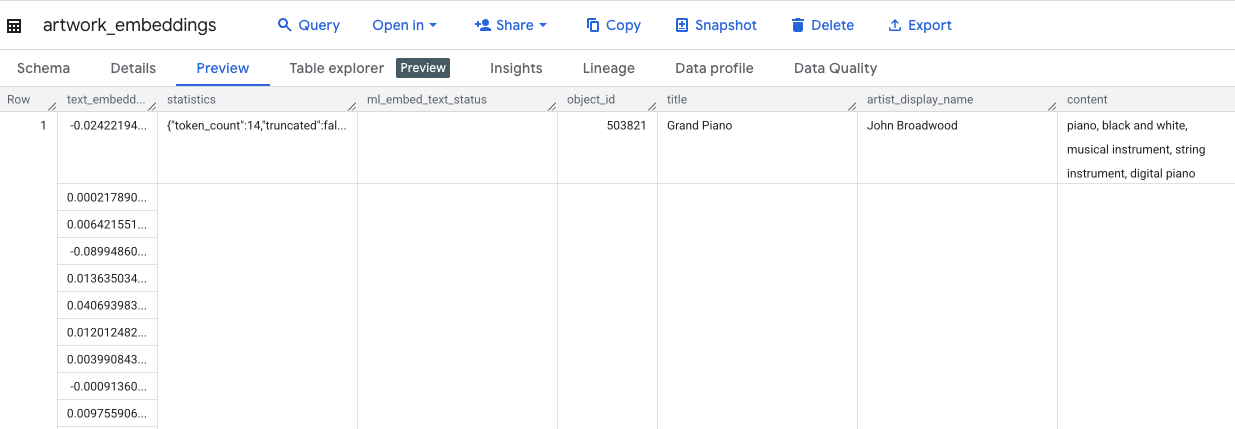
השאילתה הזו תימשך כ-10 דקות. אחרי שהשאילתה מסתיימת, מאמתים את התוצאות. בחלונית Explorer, מאתרים את הטבלה החדשה artwork_embeddings ולוחצים עליה. בתצוגת הסכימה של הטבלה, תופיע העמודה object_id, העמודה החדשה ml_generate_text_embedding_result שמכילה את הווקטורים, וגם העמודה aggregated_labels ששימשה כטקסט המקור.
5. חיפוש יצירות אמנות דומות באמצעות SQL
אחרי שיוצרים הטבעות וקטוריות איכותיות ועשירות בהקשר, אפשר למצוא יצירות אמנות דומות מבחינת נושא פשוט על ידי הפעלת שאילתת SQL. אנחנו משתמשים בפונקציה ML.DISTANCE כדי לחשב את הדמיון הקוסינוסי בין וקטורים. ההטמעות שלנו נוצרו מטקסט מצטבר, ולכן תוצאות הדמיון יהיו מדויקות ורלוונטיות יותר.
- בכרטיסייה חדשה של עורך SQL, מדביקים את השאילתה הבאה. השאילתה הזו מדמה את הלוגיקה הבסיסית של אפליקציית המלצות:
- קודם בוחרים את הווקטור של יצירת אמנות ספציפית (במקרה הזה, 'ברושים' של ואן גוך, שה-
object_idשלה הוא 436535). - לאחר מכן, המערכת מחשבת את המרחק בין הווקטור הזה לבין כל שאר הווקטורים בטבלה.
- לבסוף, המערכת ממיינת את התוצאות לפי מרחק (מרחק קטן יותר מצביע על דמיון רב יותר) כדי למצוא את 10 ההתאמות הקרובות ביותר.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- מריצים את השאילתה. ברשימת התוצאות יופיעו
object_ids, וההתאמות הכי קרובות יופיעו בראש הרשימה. יצירת האומנות המקורית תופיע ראשונה עם מרחק של 0. זהו הלוגיקה הבסיסית שמפעילה מנוע המלצות מבוסס-AI, ויצרתם אותה כולה ב-BigQuery באמצעות SQL בלבד.
6. (אופציונלי) הפעלת ההדגמה ב-Cloud Shell
כדי להמחיש את המושגים מתוך ה-codelab הזה, המאגר ששיבטתם כולל אפליקציית אינטרנט פשוטה. הדמו האופציונלי הזה משתמש בטבלת artwork_embeddings שיצרתם כדי להפעיל מנוע חיפוש חזותי, וכך מאפשר לכם לראות את ההמלצות מבוססות ה-AI בפעולה.
כדי להפעיל את ההדגמה ב-Cloud Shell:
- הגדרת משתני סביבה: לפני שמריצים את האפליקציה, צריך להגדיר את משתני הסביבה PROJECT_ID ו-BIGQUERY_DATASET.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- מתקינים את יחסי התלות ומפעילים את שרת הקצה העורפי.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
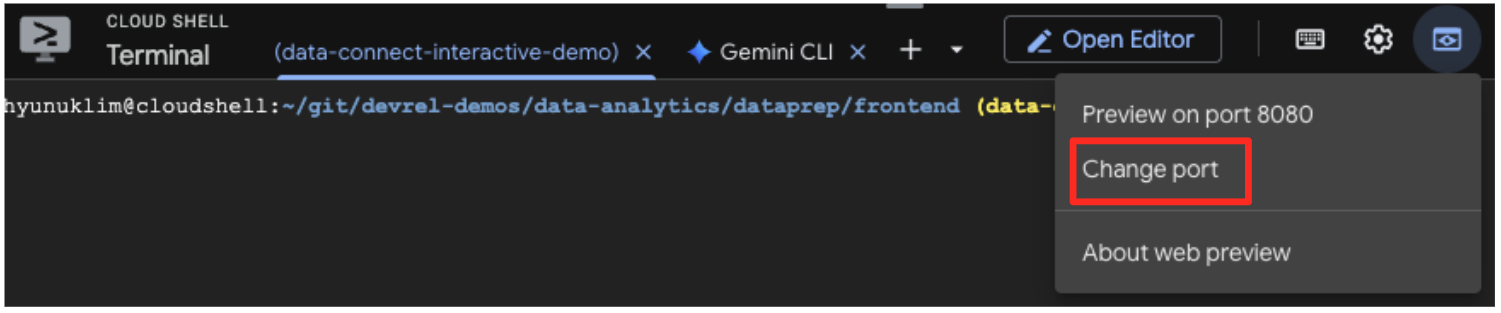
- כדי להריץ את אפליקציית ה-Frontend, צריך כרטיסייה שנייה בטרמינל. לוחצים על סמל הפלוס (+) כדי לפתוח כרטיסייה חדשה ב-Cloud Shell.

- עכשיו, בכרטיסייה החדשה, מריצים את הפקודה הבאה כדי להתקין את התלויות ולהפעיל את שרת הקצה הקדמי
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- תצוגה מקדימה של האפליקציה: בסרגל הכלים של Cloud Shell, לוחצים על סמל התצוגה המקדימה באינטרנט ובוחרים באפשרות 'תצוגה מקדימה ביציאה 5173'. תיפתח כרטיסייה חדשה בדפדפן עם האפליקציה. עכשיו אפשר להשתמש באפליקציה כדי לחפש יצירות אמנות ולראות את החיפוש לפי דמיון בפעולה.
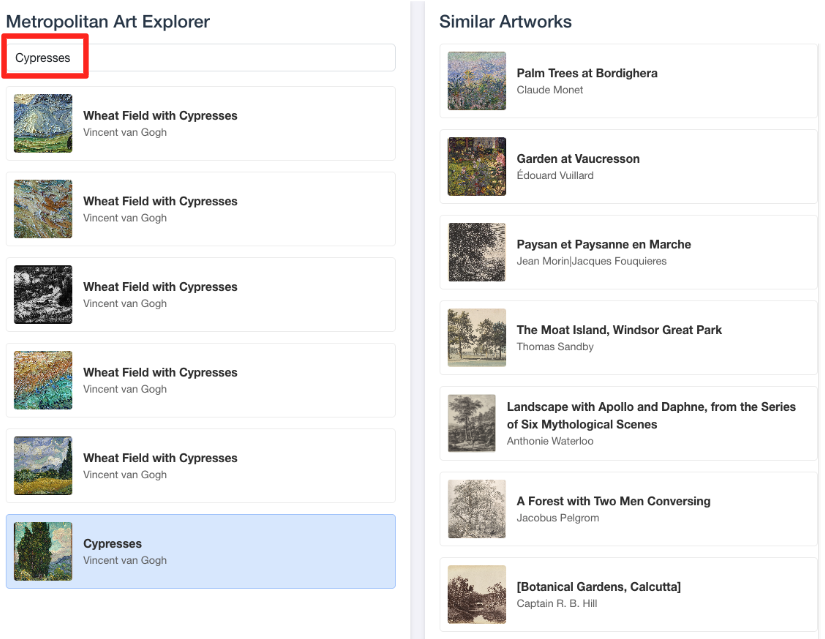
- כדי לקשר את ההדגמה החזותית הזו לעבודה שביצעתם בעורך ה-SQL של BigQuery, נסו להקליד 'ברושים' בסרגל החיפוש. זו אותה יצירת אומנות(
object_id=436535) שבה השתמשת בשאילתהML.DISTANCE. אחר כך לוחצים על התמונה של ברושים כשהיא מופיעה בחלונית הימנית, והתוצאות יופיעו בחלונית השמאלית. האפליקציה מציגה את יצירות האומנות הכי דומות, וממחישה את היכולות של חיפוש הדמיון הווקטורי שיצרתם.
7. פינוי מקום בסביבה
כדי להימנע מחיובים עתידיים בחשבון Google Cloud על המשאבים שבהם השתמשתם ב-Codelab הזה, מומלץ למחוק את המשאבים שיצרתם.
מריצים את הפקודות הבאות במסוף Cloud Shell כדי להסיר את חשבון השירות, את החיבור ל-BigQuery, את דלי ה-GCS ואת מערך הנתונים של BigQuery.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
הסרת החיבור ל-BigQuery ולמאגר GCS
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
מחיקת מערך הנתונים ב-BigQuery
לבסוף, מוחקים את מערך הנתונים ב-BigQuery. אי אפשר לבטל את הפקודה הזו. הדגל -f (force) מסיר את מערך הנתונים ואת כל הטבלאות שלו בלי לבקש אישור.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. מעולה!
יצרתם בהצלחה פייפליין נתונים מקצה לקצה שמבוסס-AI.
התחלתם עם קובץ CSV גולמי בדלי GCS, השתמשתם בממשק עם תכנות מינימלי של BigQuery Data Prep כדי להטמיע ולשטח נתוני JSON מורכבים, יצרתם מודל BQML מרחוק כדי ליצור הטמעות וקטוריות באיכות גבוהה באמצעות מודל Gemini, והרצתם שאילתת חיפוש דמיון כדי למצוא פריטים קשורים.
עכשיו יש לכם את התבנית הבסיסית לבניית תהליכי עבודה בעזרת AI ב-Google Cloud, כדי להפוך נתונים גולמיים לאפליקציות חכמות במהירות ובפשטות.
מה השלב הבא?
- יצירת תרשים של התוצאות ב-Looker Studio: מקשרים את טבלת
artwork_embeddingsBigQuery ישירות ל-Looker Studio (השימוש ב-Looker Studio הוא בחינם). אתם יכולים לבנות לוח בקרה אינטראקטיבי שבו המשתמשים יכולים לבחור יצירת אמנות ולראות גלריה ויזואלית של היצירות הכי דומות, בלי לכתוב קוד frontend. - אוטומציה באמצעות שאילתות מתוזמנות: לא צריך כלי תזמור מורכב כדי לשמור על עדכניות ההטמעות. משתמשים בתכונה Scheduled Queries (שאילתות מתוזמנות) המובנית ב-BigQuery כדי להריץ מחדש את השאילתה
ML.GENERATE_TEXT_EMBEDDINGבאופן אוטומטי על בסיס יומי או שבועי. - יצירת אפליקציה באמצעות Gemini CLI: אפשר להשתמש ב-Gemini CLI כדי ליצור אפליקציה שלמה על ידי תיאור הדרישה בטקסט פשוט. כך תוכלו ליצור במהירות אב טיפוס פעיל לחיפוש דמיון בלי לכתוב את קוד ה-Python באופן ידני.
- קוראים את התיעוד: