
1. परिचय
डेटा विश्लेषकों को अक्सर JSON पेलोड जैसे सेमी-स्ट्रक्चर्ड फ़ॉर्मैट में लॉक किए गए अहम डेटा का सामना करना पड़ता है. इस डेटा को विश्लेषण और मशीन लर्निंग के लिए तैयार करना, हमेशा से एक बड़ी तकनीकी चुनौती रही है. इसके लिए, आम तौर पर जटिल ईटीएल स्क्रिप्ट और डेटा इंजीनियरिंग टीम की ज़रूरत होती है.
इस कोडलैब में, डेटा विश्लेषकों के लिए एक टेक्निकल ब्लूप्रिंट दिया गया है. इसकी मदद से, वे इस चुनौती को खुद ही हल कर सकते हैं. इसमें, एआई की पूरी पाइपलाइन बनाने के लिए "लो-कोड" अप्रोच का इस्तेमाल किया गया है. आपको यह जानकारी मिलेगी कि Google Cloud Storage में मौजूद रॉ CSV फ़ाइल से, एआई की मदद से सुझाव देने वाली सुविधा को कैसे चालू किया जाए. इसके लिए, सिर्फ़ BigQuery Studio में उपलब्ध टूल का इस्तेमाल किया जाएगा.
इसका मुख्य मकसद, एक मज़बूत, तेज़, और विश्लेषक के लिए आसान वर्कफ़्लो दिखाना है. यह वर्कफ़्लो, जटिल और कोड-हैवी प्रोसेस से आगे बढ़कर, आपके डेटा से कारोबार के लिए असली वैल्यू जनरेट करता है.
ज़रूरी शर्तें
- Google Cloud Console की बुनियादी जानकारी
- कमांड लाइन इंटरफ़ेस और Google Cloud Shell की बुनियादी जानकारी
आपको क्या सीखने को मिलेगा
- BigQuery डेटा तैयारी की सुविधा का इस्तेमाल करके, Google Cloud Storage से सीधे तौर पर CSV फ़ाइल को कैसे शामिल और ट्रांसफ़ॉर्म करें.
- अपने डेटा में मौजूद नेस्ट की गई JSON स्ट्रिंग को पार्स और फ़्लैट करने के लिए, नो-कोड ट्रांसफ़ॉर्मेशन का इस्तेमाल कैसे करें.
- टेक्स्ट एम्बेडिंग के लिए, Vertex AI के फ़ाउंडेशन मॉडल से कनेक्ट होने वाला BigQuery ML रिमोट मॉडल बनाने का तरीका.
- टेक्स्ट वाले डेटा को संख्या वाले वेक्टर में बदलने के लिए,
ML.GENERATE_TEXT_EMBEDDINGफ़ंक्शन का इस्तेमाल कैसे करें. - कोसाइन सिमिलैरिटी का हिसाब लगाने और अपने डेटासेट में सबसे मिलते-जुलते आइटम ढूंढने के लिए,
ML.DISTANCEफ़ंक्शन का इस्तेमाल कैसे करें.
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- कोई वेब ब्राउज़र, जैसे कि Chrome
मुख्य सिद्धांत
- BigQuery में डेटा तैयार करना: यह BigQuery Studio में मौजूद एक टूल है. यह डेटा को साफ़ करने और तैयार करने के लिए, इंटरैक्टिव और विज़ुअल इंटरफ़ेस उपलब्ध कराता है. यह ट्रांसफ़ॉर्मेशन के सुझाव देता है. साथ ही, उपयोगकर्ताओं को कम से कम कोड का इस्तेमाल करके डेटा पाइपलाइन बनाने की अनुमति देता है.
- BQML रिमोट मॉडल: यह BigQuery ML ऑब्जेक्ट होता है. यह Vertex AI (जैसे, Gemini) पर होस्ट किए गए मॉडल के लिए प्रॉक्सी के तौर पर काम करता है. इसकी मदद से, पहले से ट्रेन किए गए एआई मॉडल को कॉल किया जा सकता है. इसके लिए, एसक्यूएल सिंटैक्स का इस्तेमाल किया जाता है.
- वेक्टर एम्बेडिंग: डेटा को संख्या के तौर पर दिखाना. जैसे, टेक्स्ट या इमेज. इस कोडलैब में, हम आर्टवर्क के टेक्स्ट ब्यौरे को वेक्टर में बदलेंगे. इसमें, एक जैसे ब्यौरे से ऐसे वेक्टर मिलेंगे जो मल्टी-डाइमेंशनल स्पेस में "करीब" होते हैं.
- कोसाइन सिमिलैरिटी: यह गणितीय मेज़रमेंट है. इसका इस्तेमाल यह तय करने के लिए किया जाता है कि दो वेक्टर कितने मिलते-जुलते हैं. यह हमारे सुझाव देने वाले इंजन के लॉजिक का मुख्य हिस्सा है. इसका इस्तेमाल
ML.DISTANCEफ़ंक्शन करता है, ताकि "सबसे मिलते-जुलते" (सबसे मिलते-जुलते) आर्टवर्क ढूंढे जा सकें.
2. सेटअप और ज़रूरी शर्तें
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:

इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, यह Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
ज़रूरी एपीआई चालू करना और एनवायरमेंट कॉन्फ़िगर करना
Cloud Shell में, अपने प्रोजेक्ट आईडी को सेट करने, एनवायरमेंट वैरिएबल तय करने, और इस कोडलैब के लिए ज़रूरी सभी एपीआई चालू करने के लिए, यहां दिए गए निर्देश चलाएं.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
BigQuery डेटासेट और GCS बकेट बनाना
टेबल को सेव करने के लिए एक नया BigQuery डेटासेट बनाएं. साथ ही, सोर्स CSV फ़ाइल को सेव करने के लिए एक Google Cloud Storage बकेट बनाएं.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
सैंपल डेटा तैयार करना और अपलोड करना
नमूना CSV फ़ाइल वाली GitHub रिपॉज़िटरी को क्लोन करें. इसके बाद, उसे अभी बनाई गई GCS बकेट में अपलोड करें.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. डेटा तैयार करने की सुविधा के साथ, GCS से BigQuery में डेटा ट्रांसफ़र करना
इस सेक्शन में, हम GCS से अपनी CSV फ़ाइल को शामिल करने, उसे साफ़ करने, और उसे नई BigQuery टेबल में लोड करने के लिए, विज़ुअल और नो-कोड इंटरफ़ेस का इस्तेमाल करेंगे.
डेटा तैयार करने की सुविधा लॉन्च करना और सोर्स से कनेक्ट करना
- Google Cloud Console में, BigQuery Studio पर जाएं.
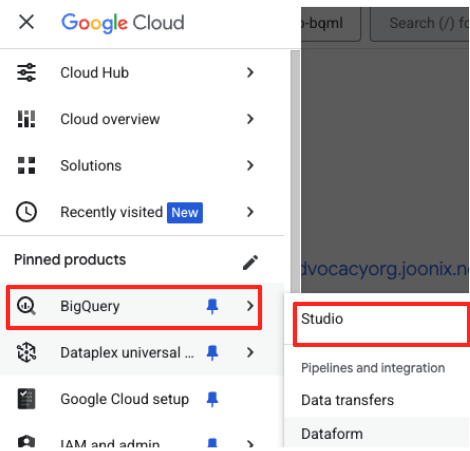
- शुरू करने के लिए, वेलकम पेज पर मौजूद डेटा तैयार करने वाले कार्ड पर क्लिक करें.
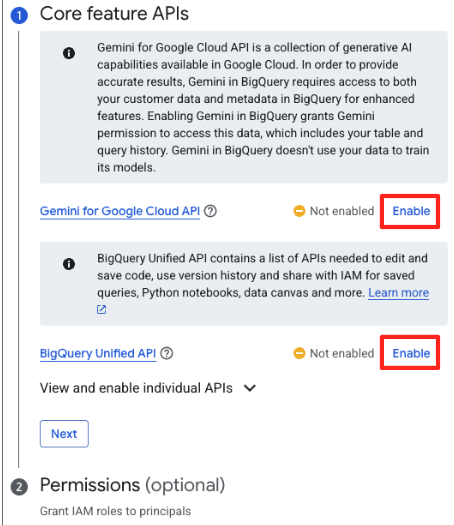
- अगर पहली बार ऐसा किया जा रहा है, तो आपको ज़रूरी एपीआई चालू करने पड़ सकते हैं. "Gemini for Google Cloud API" और "BigQuery Unified API", दोनों के लिए 'चालू करें' पर क्लिक करें. चालू होने के बाद, इस पैनल को बंद किया जा सकता है.
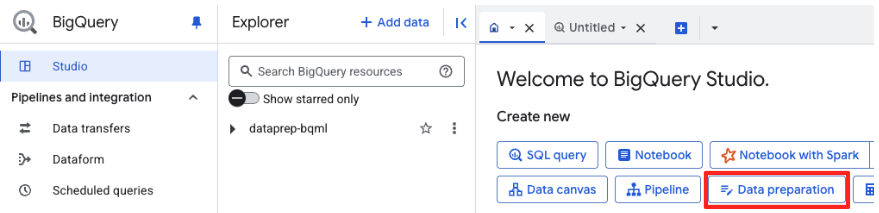
- डेटा तैयार करने वाली मुख्य विंडो में, "अन्य डेटा सोर्स चुनें" में जाकर, Google Cloud Storage पर क्लिक करें. इससे दाईं ओर "डेटा तैयार करें" पैनल खुलेगा.
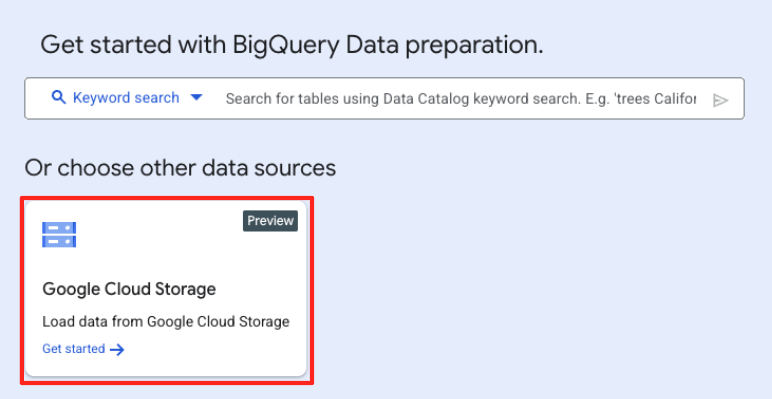
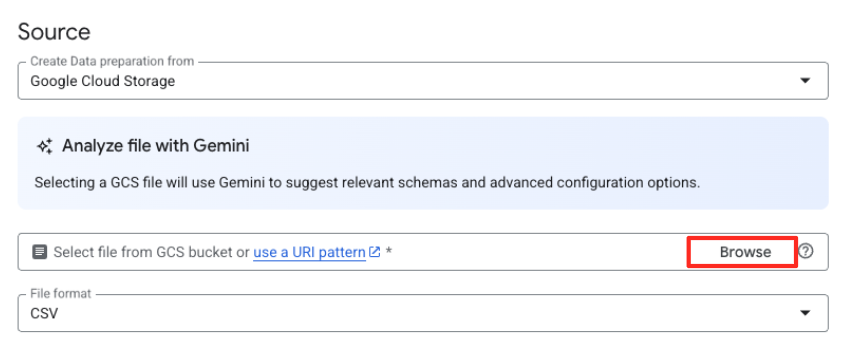
- अपनी सोर्स फ़ाइल चुनने के लिए, ब्राउज़ करें बटन पर क्लिक करें.
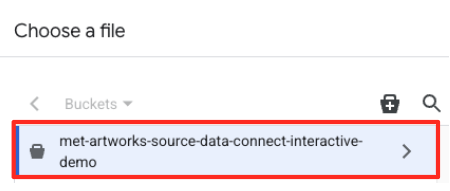
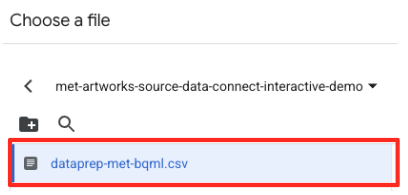
- आपने पहले जो GCS बकेट बनाया था (
met-artworks-source-...) उस पर जाएं औरdataprep-met-bqml.csvफ़ाइल चुनें. 'चुनें' पर क्लिक करें.
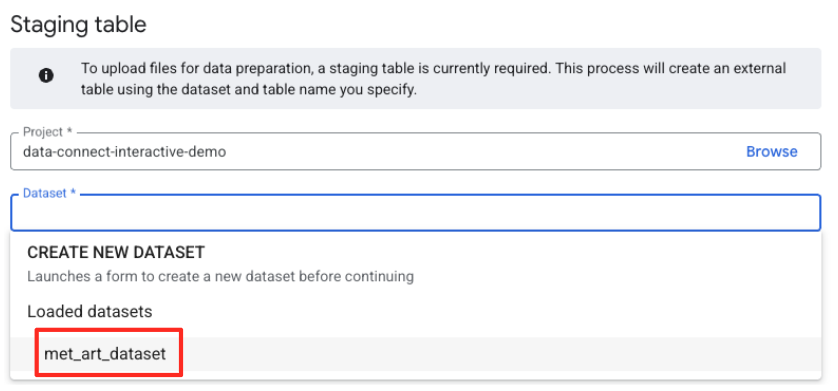
- इसके बाद, आपको एक स्टेजिंग टेबल कॉन्फ़िगर करनी होगी.
- डेटासेट के लिए,
met_art_datasetचुनें. - टेबल के नाम के लिए, कोई नाम डालें. उदाहरण के लिए,
temp. - 'बनाएं' पर क्लिक करें.
डेटा को बदलना और साफ़ करना
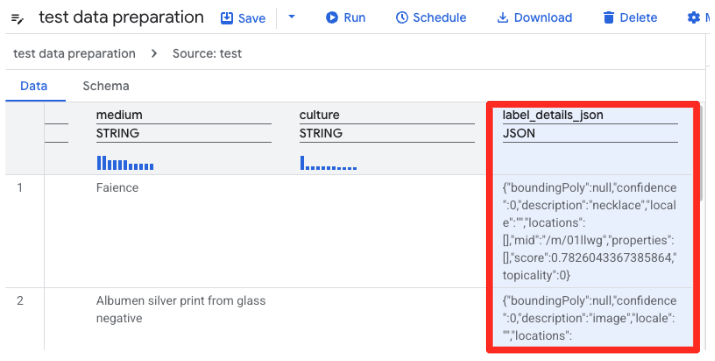
- BigQuery में डेटा तैयार करने की सुविधा, अब CSV फ़ाइल की झलक लोड करेगी.
label_details_jsonकॉलम ढूंढें. इसमें लंबी JSON स्ट्रिंग होती है. कॉलम हेडर को चुनने के लिए, उस पर क्लिक करें.
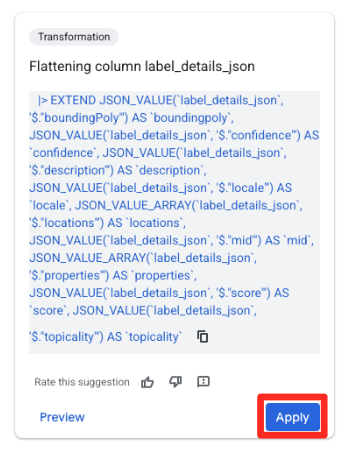
- दाईं ओर मौजूद सुझाव पैनल में, BigQuery में Gemini अपने-आप काम के ट्रांसफ़ॉर्मेशन का सुझाव देगा. "फ़्लैटनिंग कॉलम
label_details_json" कार्ड पर मौजूद, लागू करें बटन पर क्लिक करें. इससे नेस्ट किए गए फ़ील्ड (description,scoreवगैरह) अपने टॉप-लेवल के कॉलम में एक्सट्रैक्ट हो जाएंगे.
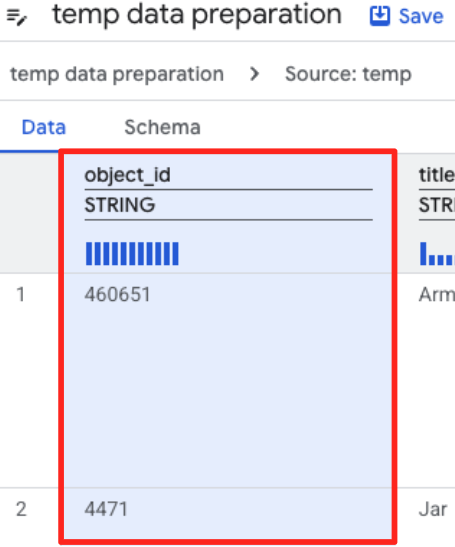
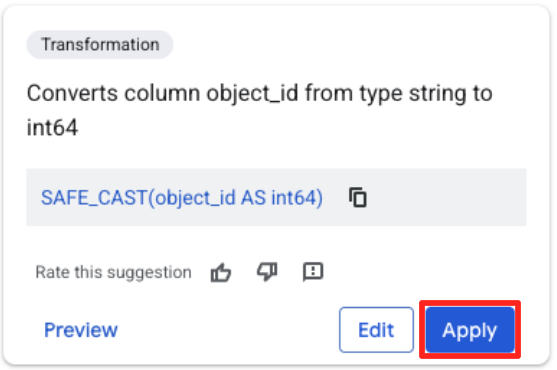
- object_id कॉलम पर क्लिक करें. इसके बाद, "कन्वर्ट कॉलम
object_idको टाइपstringसेint64में बदलें" पर मौजूद, लागू करें बटन पर क्लिक करें.
डेस्टिनेशन तय करना और जॉब चलाना
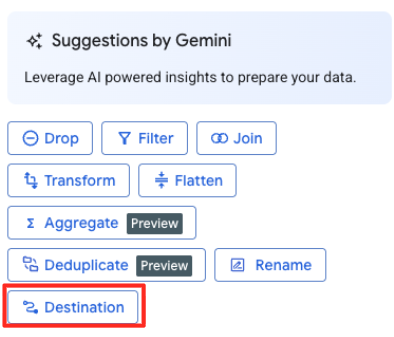
- दाएं हाथ वाले पैनल में, डेस्टिनेशन बटन पर क्लिक करके, ट्रांसफ़ॉर्मेशन के आउटपुट को कॉन्फ़िगर करें.
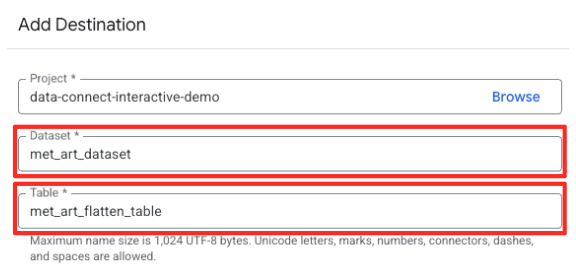
- डेस्टिनेशन की जानकारी सेट करें:
- डेटासेट में
met_art_datasetपहले से भरा होना चाहिए. - आउटपुट के लिए, टेबल का नया नाम डालें:
met_art_flatten_table. - 'सेव करें' पर क्लिक करें.
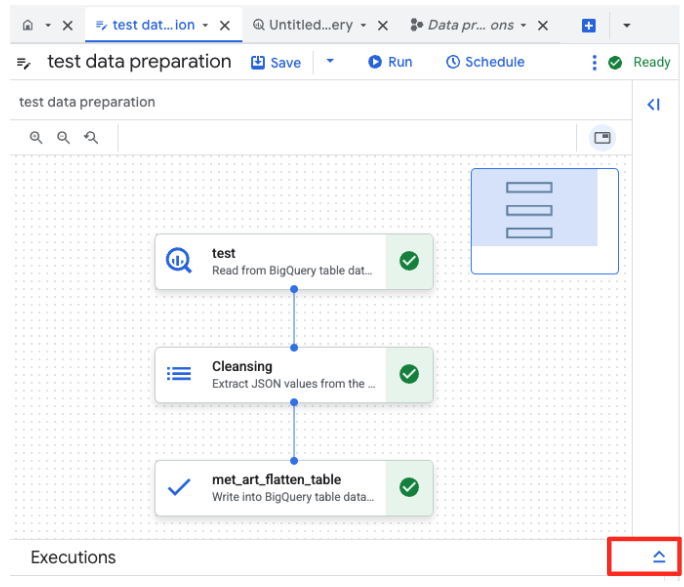
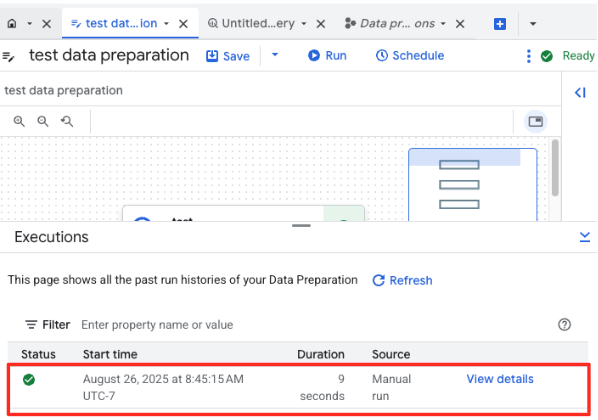
- 'चलाएं' बटन पर क्लिक करें और डेटा तैयार करने का काम पूरा होने तक इंतज़ार करें.
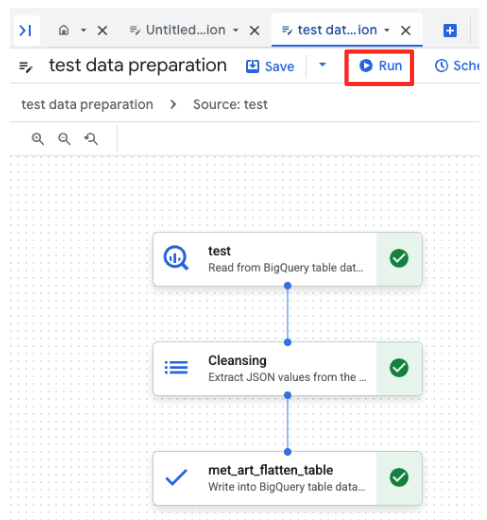
- पेज पर सबसे नीचे मौजूद 'एक्ज़ीक्यूशन' टैब में जाकर, जॉब की प्रोग्रेस देखी जा सकती है. कुछ ही देर में, जॉब पूरा हो जाएगा.
4. BQML की मदद से वेक्टर एंबेडिंग जनरेट करना
अब हमारा डेटा साफ़ और स्ट्रक्चर्ड हो गया है. इसलिए, हम एआई के मुख्य काम के लिए BigQuery ML का इस्तेमाल करेंगे. यह काम है, कलाकृति के टेक्स्ट वाले ब्यौरे को संख्यात्मक वेक्टर एम्बेडिंग में बदलना.
BigQuery कनेक्शन बनाना
BigQuery को Vertex AI सेवाओं के साथ कम्यूनिकेट करने की अनुमति देने के लिए, आपको पहले BigQuery कनेक्शन बनाना होगा.
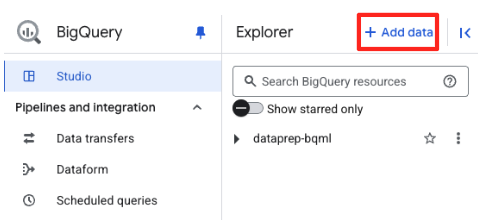
- BigQuery Studio के एक्सप्लोरर पैनल में, "+ डेटा जोड़ें" बटन पर क्लिक करें.
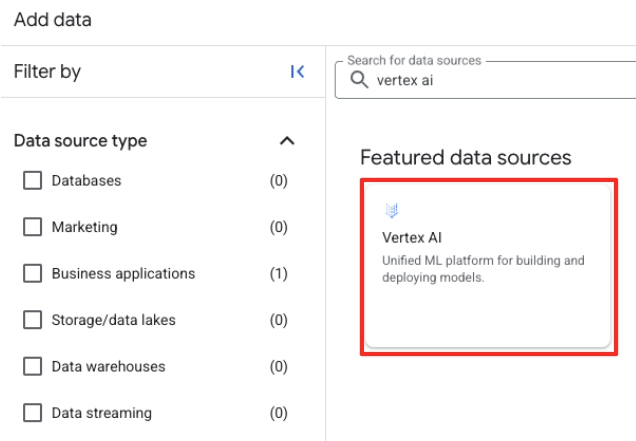
- दाईं ओर मौजूद पैनल में, खोज बार का इस्तेमाल करके
Vertex AIटाइप करें. इसे चुनें. इसके बाद, फ़िल्टर की गई सूची से BigQuery फ़ेडरेशन चुनें.
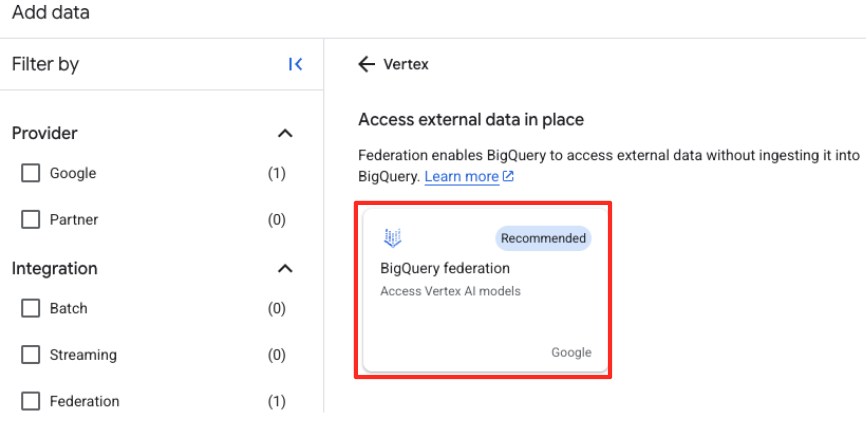
- इससे बाहरी डेटा सोर्स का फ़ॉर्म खुलेगा. यह जानकारी भरें:
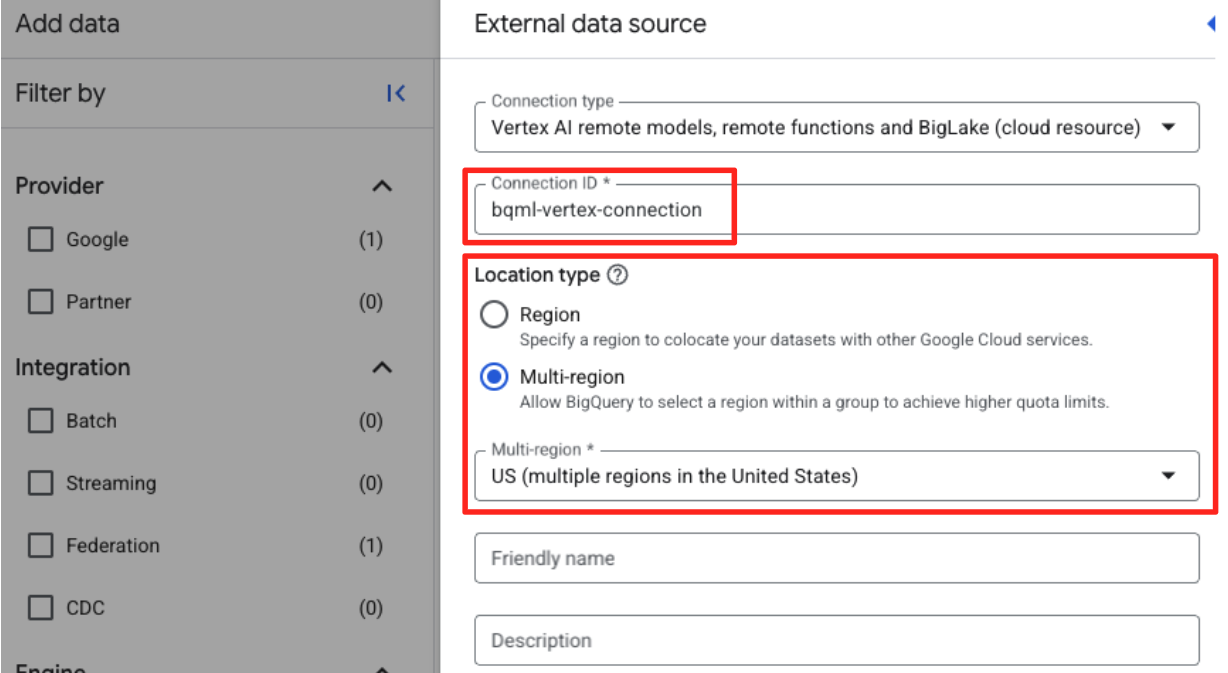
- कनेक्शन आईडी: कनेक्शन आईडी डालें. उदाहरण के लिए,
bqml-vertex-connection - जगह का टाइप: पक्का करें कि एक से ज़्यादा इलाके चुने गए हों.
- जगह: कोई जगह चुनें (जैसे,
US).
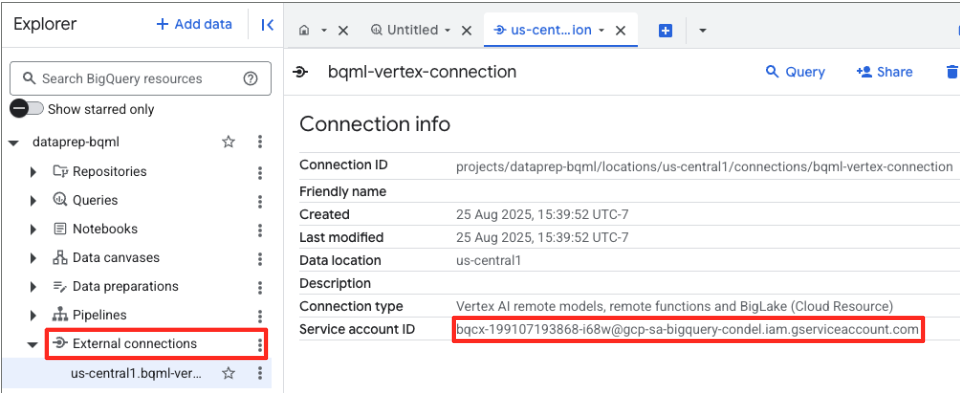
- कनेक्शन बन जाने के बाद, आपको पुष्टि करने वाला डायलॉग दिखेगा. एक्सप्लोरर टैब में, कनेक्शन पर जाएं या बाहरी कनेक्शन पर क्लिक करें. कनेक्शन की ज़्यादा जानकारी वाले पेज पर, पूरा आईडी अपने क्लिपबोर्ड पर कॉपी करें. यह सेवा खाते की वह पहचान है जिसका इस्तेमाल करके BigQuery, Vertex AI को कॉल करेगा.
- Google Cloud Console के नेविगेशन मेन्यू में, IAM और एडमिन > IAM पर जाएं.
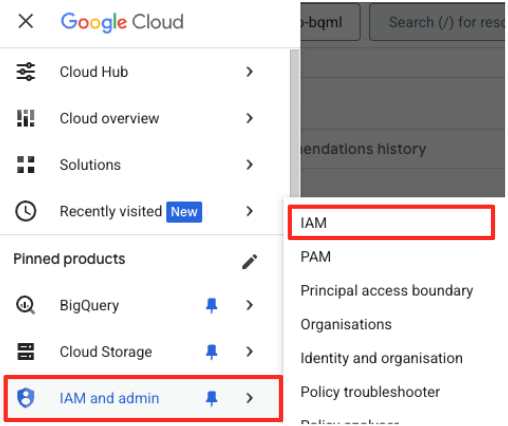
- "ऐक्सेस दें" बटन पर क्लिक करें
- पिछले चरण में कॉपी किए गए सेवा खाते को, 'नए प्रिंसिपल' फ़ील्ड में चिपकाएं.
- भूमिका वाले ड्रॉपडाउन में, "Vertex AI उपयोगकर्ता" असाइन करें. इसके बाद, "सेव करें" पर क्लिक करें.
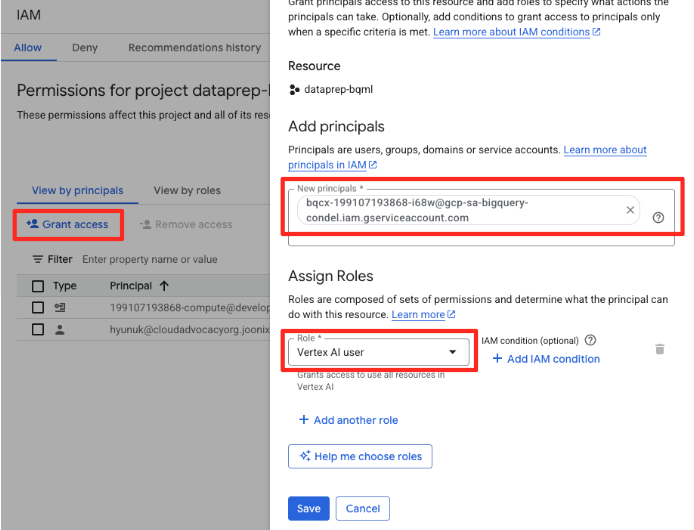
इस ज़रूरी चरण से यह पक्का किया जाता है कि BigQuery के पास, आपकी ओर से Vertex AI मॉडल का इस्तेमाल करने की अनुमति है.
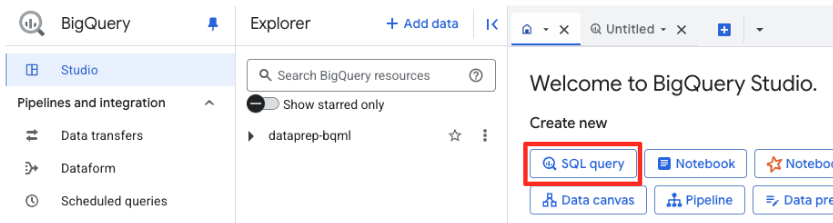
रिमोट मॉडल बनाना
BigQuery Studio में, नया एसक्यूएल एडिटर टैब खोलें. यहां आपको Gemini से कनेक्ट होने वाले BQML मॉडल को तय करना होगा.
इस स्टेटमेंट से कोई नया मॉडल ट्रेन नहीं होता है. यह BigQuery में सिर्फ़ एक रेफ़रंस बनाता है. यह रेफ़रंस, पहले से ट्रेन किए गए gemini-embedding-001 मॉडल की ओर ले जाता है. इसके लिए, यह उस कनेक्शन का इस्तेमाल करता है जिसे आपने अभी अनुमति दी है.
नीचे दी गई पूरी SQL स्क्रिप्ट को कॉपी करें और उसे BigQuery एडिटर में चिपकाएं.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
एम्बेडिंग जनरेट करना
अब हम वेक्टर एम्बेडिंग जनरेट करने के लिए, अपने BQML मॉडल का इस्तेमाल करेंगे. हम हर लाइन के लिए सिर्फ़ एक टेक्स्ट लेबल को बदलने के बजाय, ज़्यादा बेहतर तरीके का इस्तेमाल करेंगे. इससे हर आर्टवर्क के लिए, ज़्यादा जानकारी वाली और ज़्यादा काम की "सिमैंटिक समरी" बनाई जा सकेगी. इससे बेहतर क्वालिटी वाले एम्बेडिंग और ज़्यादा सटीक सुझाव मिलेंगे.
यह क्वेरी, प्रीप्रोसेसिंग का एक ज़रूरी चरण पूरा करती है:
- यह
WITHक्लॉज़ का इस्तेमाल करके, सबसे पहले एक अस्थायी टेबल बनाता है. - इसके अंदर, हम हर
object_idकोGROUP BYकरते हैं, ताकि एक ही आर्टवर्क की सारी जानकारी को एक लाइन में जोड़ा जा सके. - हम
STRING_AGGफ़ंक्शन का इस्तेमाल करके, टेक्स्ट के सभी अलग-अलग ब्यौरों (जैसे कि ‘पोर्ट्रेट', ‘महिला', ‘कैनवस पर तेल') को एक ही टेक्स्ट स्ट्रिंग में मर्ज करते हैं. साथ ही, उन्हें काम के होने के हिसाब से क्रम में लगाते हैं.
इस टेक्स्ट से, एआई को आर्टवर्क के बारे में ज़्यादा जानकारी मिलती है. इससे, ज़्यादा बारीकी से और बेहतर तरीके से वेक्टर एम्बेडिंग की जा सकती है.
नए एसक्यूएल एडिटर टैब में, यह क्वेरी चिपकाएं और चलाएं:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
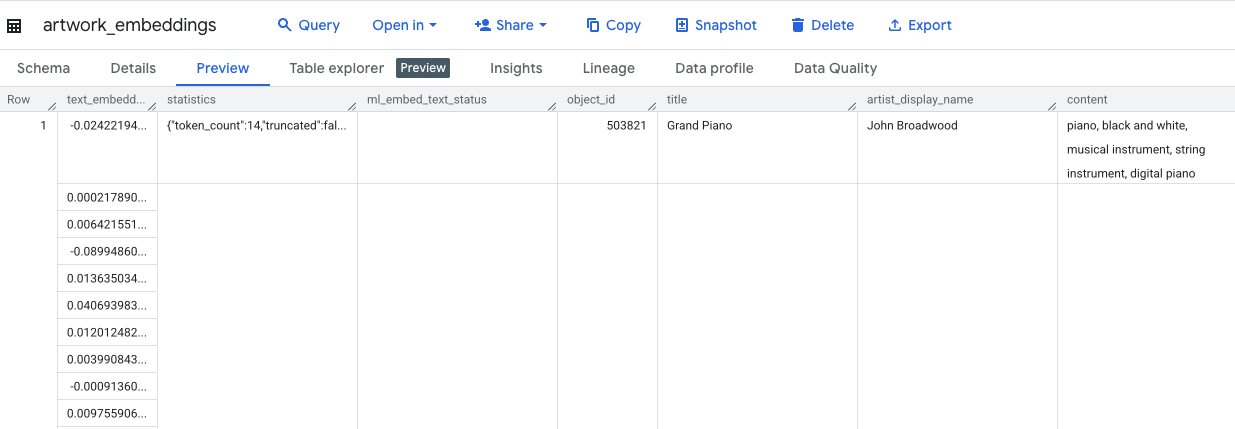
इस क्वेरी को पूरा होने में करीब 10 मिनट लगेंगे. क्वेरी पूरी होने के बाद, नतीजों की पुष्टि करें. एक्सप्लोरर पैनल में, अपनी नई artwork_embeddings टेबल ढूंढें और उस पर क्लिक करें. टेबल स्कीमा व्यूअर में, आपको object_id, नया ml_generate_text_embedding_result कॉलम दिखेगा. इसमें वेक्टर शामिल हैं. साथ ही, आपको aggregated_labels कॉलम भी दिखेगा, जिसका इस्तेमाल सोर्स टेक्स्ट के तौर पर किया गया था.
5. एसक्यूएल की मदद से मिलती-जुलती कलाकृतियां ढूंढना
हमने कॉन्टेक्स्ट के हिसाब से बेहतर क्वालिटी वाली वेक्टर एम्बेडिंग बनाई हैं. इनकी मदद से, थीम के हिसाब से मिलते-जुलते आर्टवर्क ढूंढना उतना ही आसान है जितना एसक्यूएल क्वेरी चलाना. हम वेक्टर के बीच कोसाइन समानता का हिसाब लगाने के लिए, ML.DISTANCE फ़ंक्शन का इस्तेमाल करते हैं. हमारे एम्बेडिंग, एग्रीगेट किए गए टेक्स्ट से जनरेट किए गए थे. इसलिए, समानता के नतीजे ज़्यादा सटीक और काम के होंगे.
- नए SQL एडिटर टैब में, यह क्वेरी चिपकाएं. इस क्वेरी में, सुझाव देने वाले ऐप्लिकेशन के मुख्य लॉजिक को सिम्युलेट किया गया है:
- यह सबसे पहले, किसी एक खास आर्टवर्क के लिए वेक्टर चुनता है. इस मामले में, यह वान गॉग के "साइप्रस" को चुनता है, जिसका
object_id436535 है. - इसके बाद, यह उस एक वेक्टर और टेबल में मौजूद अन्य सभी वेक्टर के बीच की दूरी का हिसाब लगाता है.
- आखिर में, यह दूरी के हिसाब से नतीजों को क्रम से लगाता है. कम दूरी का मतलब है कि नतीजे ज़्यादा मिलते-जुलते हैं. इससे, सबसे ज़्यादा मिलते-जुलते 10 नतीजे मिलते हैं.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- क्वेरी चलाएं. नतीजों में
object_idकी सूची दिखेगी. इसमें सबसे मिलते-जुलते नतीजे सबसे ऊपर दिखेंगे. सोर्स आर्टवर्क सबसे पहले दिखेगा. इसकी दूरी 0 होगी. यह एआई की मदद से सुझाव देने वाले इंजन का मुख्य लॉजिक है. इसे आपने सिर्फ़ एसक्यूएल का इस्तेमाल करके, पूरी तरह से BigQuery में बनाया है.
6. (ज़रूरी नहीं) Cloud Shell में डेमो चलाना
इस कोडलैब के कॉन्सेप्ट को समझने के लिए, क्लोन की गई रिपॉज़िटरी में एक सामान्य वेब ऐप्लिकेशन शामिल है. इस वैकल्पिक डेमो में, विज़ुअल सर्च इंजन को बेहतर बनाने के लिए, आपकी बनाई गई artwork_embeddings टेबल का इस्तेमाल किया जाता है. इससे आपको एआई पर आधारित सुझावों को ऐक्शन में देखने का मौका मिलता है.
Cloud Shell में डेमो चलाने के लिए, यह तरीका अपनाएं:
- एनवायरमेंट वैरिएबल सेट करना: ऐप्लिकेशन चलाने से पहले, आपको PROJECT_ID और BIGQUERY_DATASET एनवायरमेंट वैरिएबल सेट करने होंगे.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- डिपेंडेंसी इंस्टॉल करें और बैकएंड सर्वर शुरू करें.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- फ़्रंटएंड ऐप्लिकेशन चलाने के लिए, आपको दूसरे टर्मिनल टैब की ज़रूरत होगी. नया Cloud Shell टैब खोलने के लिए, "+" आइकॉन पर क्लिक करें.

- अब नए टैब में, डिपेंडेंसी इंस्टॉल करने और फ़्रंटएंड सर्वर चलाने के लिए, यह कमांड चलाएं
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- ऐप्लिकेशन की झलक देखें: Cloud Shell टूलबार में, वेब प्रीव्यू आइकॉन पर क्लिक करें. इसके बाद, पोर्ट 5173 पर झलक देखें को चुनें. इससे एक नया ब्राउज़र टैब खुलेगा, जिसमें ऐप्लिकेशन चल रहा होगा. अब ऐप्लिकेशन का इस्तेमाल करके, आर्टवर्क खोजे जा सकते हैं. साथ ही, मिलते-जुलते आर्टवर्क खोजने की सुविधा का इस्तेमाल किया जा सकता है.
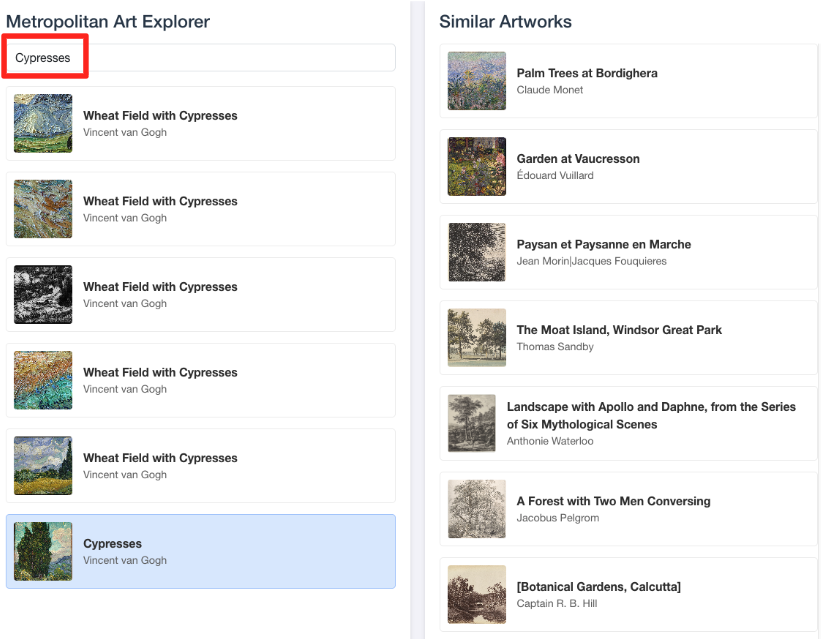
- इस विज़ुअल डेमो को BigQuery एसक्यूएल एडिटर में किए गए काम से वापस कनेक्ट करने के लिए, खोज बार में "Cypresses" टाइप करें. यह वही आर्टवर्क(
object_id=436535) है जिसका इस्तेमाल आपनेML.DISTANCEक्वेरी में किया था. इसके बाद, जब आपको बाएं पैनल में साइप्रस की इमेज दिखे, तो उस पर क्लिक करें. आपको दाईं ओर नतीजे दिखेंगे. इस ऐप्लिकेशन में, मिलती-जुलती कलाकृतियां दिखाई जाती हैं. इससे, आपको यह पता चलता है कि आपने जो वेक्टर सिमिलैरिटी सर्च बनाई है वह कितनी असरदार है.
7. अपने एनवायरमेंट को क्लीन अप करना
इस कोडलैब में इस्तेमाल की गई संसाधनों के लिए, अपने Google Cloud खाते से आने वाले समय में शुल्क न लिए जाने से बचने के लिए, आपको बनाए गए संसाधनों को मिटा देना चाहिए.
सेवा खाता, BigQuery कनेक्शन, GCS बकेट, और BigQuery डेटासेट हटाने के लिए, अपने Cloud Shell टर्मिनल में ये कमांड चलाएं.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
BigQuery कनेक्शन और GCS बकेट हटाना
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
BigQuery डेटासेट मिटाना
आखिर में, BigQuery डेटासेट मिटाएं. इस निर्देश को पहले जैसा नहीं किया जा सकता. -f (force) फ़्लैग, पुष्टि करने के लिए कहे बिना डेटासेट और उसकी सभी टेबल हटा देता है.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. बधाई हो!
आपने एआई की मदद से काम करने वाली एंड-टू-एंड डेटा पाइपलाइन बना ली है.
आपने GCS बकेट में मौजूद रॉ CSV फ़ाइल से शुरुआत की. इसके बाद, BigQuery Data Prep के लो-कोड इंटरफ़ेस का इस्तेमाल करके, जटिल JSON डेटा को शामिल किया और उसे फ़्लैट किया. साथ ही, Gemini मॉडल की मदद से अच्छी क्वालिटी की वेक्टर एम्बेडिंग जनरेट करने के लिए, BQML रिमोट मॉडल बनाया. इसके बाद, मिलते-जुलते आइटम ढूंढने के लिए, समानता खोज क्वेरी को लागू किया.
अब आपके पास Google Cloud पर एआई की मदद से वर्कफ़्लो बनाने का बुनियादी पैटर्न है. इसकी मदद से, रॉ डेटा को तेज़ी से और आसानी से स्मार्ट ऐप्लिकेशन में बदला जा सकता है.
आगे क्या करना है?
- Looker Studio में अपने नतीजों को विज़ुअलाइज़ करें: अपनी
artwork_embeddingsBigQuery टेबल को सीधे Looker Studio से कनेक्ट करें. इसके लिए, आपको कोई शुल्क नहीं देना होगा! आपके पास एक इंटरैक्टिव डैशबोर्ड बनाने का विकल्प होता है. इसमें उपयोगकर्ता किसी आर्टवर्क को चुन सकते हैं और उससे मिलते-जुलते आर्टवर्क की विज़ुअल गैलरी देख सकते हैं. इसके लिए, उन्हें कोई फ़्रंटएंड कोड लिखने की ज़रूरत नहीं होती. - शेड्यूल की गई क्वेरी की मदद से प्रोसेस को अपने-आप होने दें: एम्बेडिंग को अप-टू-डेट रखने के लिए, आपको किसी जटिल ऑर्केस्ट्रेशन टूल की ज़रूरत नहीं है.
ML.GENERATE_TEXT_EMBEDDINGक्वेरी को हर दिन या हर हफ़्ते अपने-आप फिर से चलाने के लिए, BigQuery की शेड्यूल की गई क्वेरी की इन-बिल्ट सुविधा का इस्तेमाल करें. - Gemini CLI की मदद से ऐप्लिकेशन जनरेट करना: Gemini CLI का इस्तेमाल करके, अपनी ज़रूरत के बारे में सामान्य टेक्स्ट में बताएँ और पूरा ऐप्लिकेशन जनरेट करें. इससे आपको Python कोड को मैन्युअल तरीके से लिखे बिना, समानता खोज के लिए तुरंत प्रोटोटाइप बनाने की सुविधा मिलती है.
- दस्तावेज़ पढ़ें: