
1. Pengantar
Analis data sering kali menghadapi data berharga yang terkunci dalam format semi-terstruktur seperti payload JSON. Mengekstrak dan menyiapkan data ini untuk analisis dan machine learning secara tradisional merupakan hambatan teknis yang signifikan, yang biasanya memerlukan skrip ETL yang kompleks dan intervensi tim rekayasa data.
Codelab ini memberikan cetak biru teknis bagi analis data untuk mengatasi tantangan ini secara mandiri. Notebook ini menunjukkan pendekatan "low-code" untuk membangun pipeline AI end-to-end. Anda akan mempelajari cara mengubah file CSV mentah di Google Cloud Storage menjadi fitur rekomendasi berbasis AI, hanya menggunakan alat yang tersedia dalam BigQuery Studio.
Tujuan utamanya adalah untuk mendemonstrasikan alur kerja yang andal, cepat, dan mudah digunakan oleh analis yang melampaui proses kompleks dan berat kode untuk menghasilkan nilai bisnis nyata dari data Anda.
Prasyarat
- Pemahaman dasar tentang Konsol Google Cloud
- Keterampilan dasar dalam antarmuka command line dan Google Cloud Shell
Yang akan Anda pelajari
- Cara menyerap dan mengubah file CSV langsung dari Google Cloud Storage menggunakan Persiapan Data BigQuery.
- Cara menggunakan transformasi tanpa kode untuk menguraikan dan meratakan string JSON bertingkat dalam data Anda.
- Cara membuat model jarak jauh BigQuery ML yang terhubung ke model dasar Vertex AI untuk penyematan teks.
- Cara menggunakan fungsi
ML.GENERATE_TEXT_EMBEDDINGuntuk mengonversi data tekstual menjadi vektor numerik. - Cara menggunakan fungsi
ML.DISTANCEuntuk menghitung kemiripan kosinus dan menemukan item yang paling mirip dalam set data Anda.
Yang Anda butuhkan
- Akun Google Cloud dan Project Google Cloud
- Browser web seperti Chrome
Konsep utama
- Persiapan Data BigQuery: Alat dalam BigQuery Studio yang menyediakan antarmuka visual interaktif untuk pembersihan dan persiapan data. Fitur ini menyarankan transformasi dan memungkinkan pengguna membuat pipeline data dengan kode minimal.
- Model Jarak Jauh BQML: Objek BigQuery ML yang bertindak sebagai proxy untuk model yang dihosting di Vertex AI (seperti Gemini). BigQuery ML memungkinkan Anda memanggil model AI terlatih yang canggih menggunakan sintaksis SQL yang sudah dikenal.
- Embedding vektor: Representasi numerik data, seperti teks atau gambar. Dalam codelab ini, kita akan mengonversi deskripsi teks karya seni menjadi vektor, dengan deskripsi serupa menghasilkan vektor yang "lebih dekat" dalam ruang multidimensi.
- Kemiripan kosinus: Ukuran matematika yang digunakan untuk menentukan seberapa mirip dua vektor. Ini adalah inti dari logika mesin rekomendasi kami, yang digunakan oleh fungsi
ML.DISTANCEuntuk menemukan karya seni "terdekat" (paling mirip).
2. Penyiapan dan persyaratan
Mulai Cloud Shell
Meskipun Google Cloud dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam codelab ini, Anda akan menggunakan Google Cloud Shell, lingkungan command line yang berjalan di Cloud.
Dari Google Cloud Console, klik ikon Cloud Shell di toolbar kanan atas:

Hanya perlu waktu beberapa saat untuk penyediaan dan terhubung ke lingkungan. Jika sudah selesai, Anda akan melihat tampilan seperti ini:

Mesin virtual ini berisi semua alat pengembangan yang Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Semua pekerjaan Anda dalam codelab ini dapat dilakukan di browser. Anda tidak perlu menginstal apa pun.
Mengaktifkan API yang diperlukan dan mengonfigurasi lingkungan
Di dalam Cloud Shell, jalankan perintah berikut untuk menetapkan project ID, menentukan variabel lingkungan, dan mengaktifkan semua API yang diperlukan untuk codelab ini.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
Buat set data BigQuery dan Bucket GCS
Buat set data BigQuery baru untuk menampung tabel dan bucket Google Cloud Storage untuk menyimpan file CSV sumber.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
Menyiapkan dan Mengupload Data Sampel
Clone repositori GitHub yang berisi file CSV contoh, lalu upload ke bucket GCS yang baru saja Anda buat.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. Dari GCS ke BigQuery dengan Persiapan data
Di bagian ini, kita akan menggunakan antarmuka visual tanpa kode untuk menyerap file CSV dari GCS, membersihkannya, dan memuatnya ke dalam tabel BigQuery baru.
Luncurkan Penyiapan Data dan Hubungkan ke Sumber
- Di Konsol Google Cloud, buka BigQuery Studio.
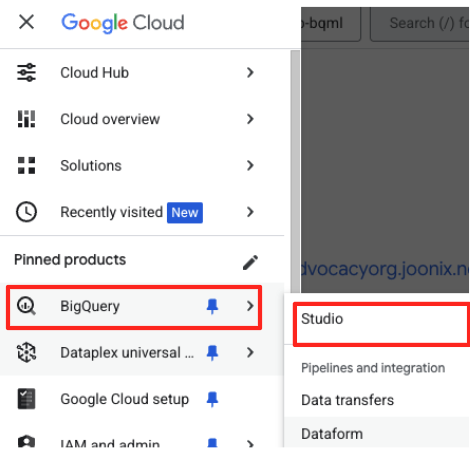
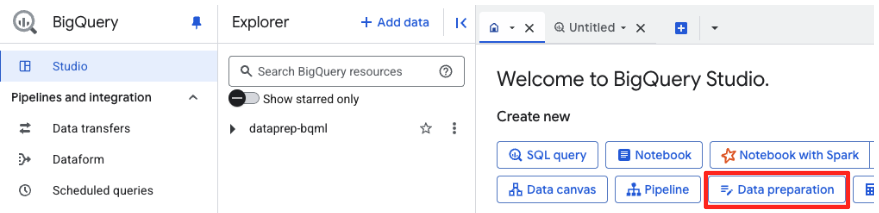
- Di halaman selamat datang, klik kartu Persiapan data untuk memulai.
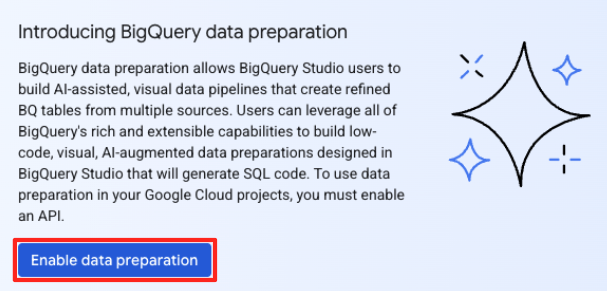
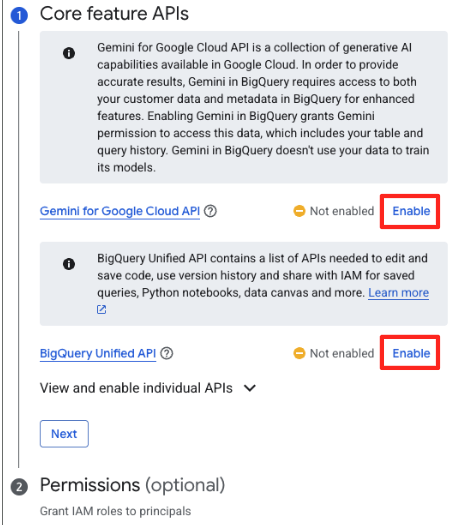
- Jika ini pertama kalinya, Anda mungkin perlu mengaktifkan API yang diperlukan. Klik Aktifkan untuk "Gemini for Google Cloud API" dan "BigQuery Unified API". Setelah diaktifkan, Anda dapat menutup panel ini.
- Di jendela Persiapan data utama, di bagian "pilih sumber data lain", klik Google Cloud Storage. Tindakan ini akan membuka panel "Siapkan data" di sebelah kanan.
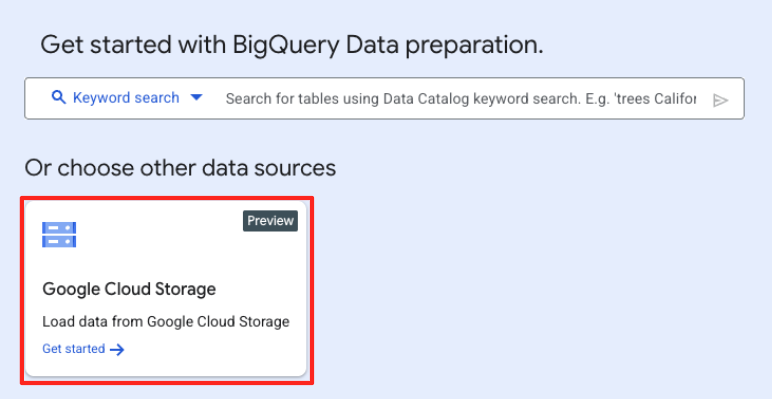
- Klik tombol Jelajahi untuk memilih file sumber Anda.
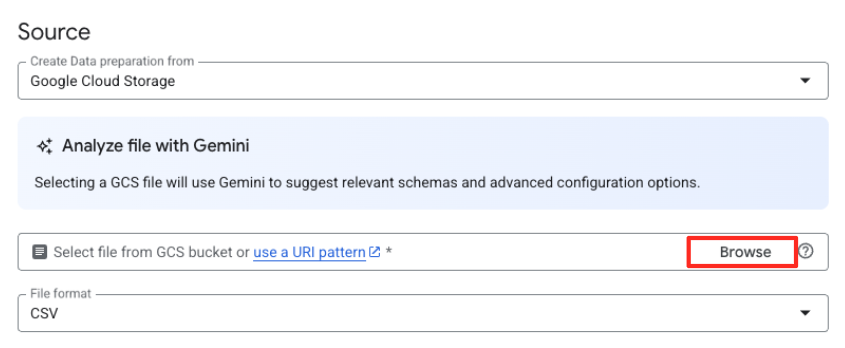
- Buka bucket GCS yang Anda buat sebelumnya (
met-artworks-source-...), lalu pilih filedataprep-met-bqml.csv. Klik Pilih.
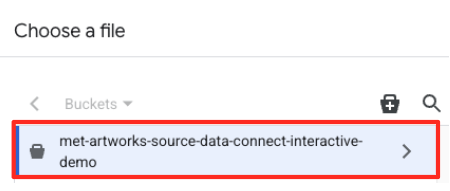
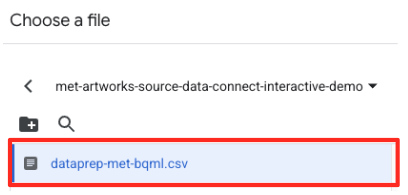
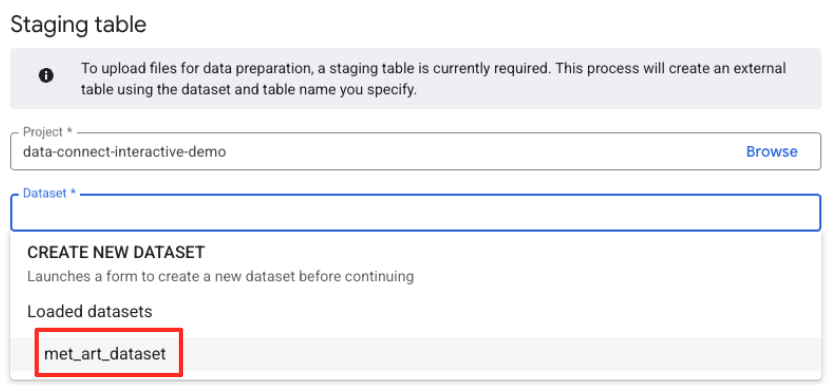
- Selanjutnya, Anda perlu mengonfigurasi tabel penahapan.
- Untuk Dataset, pilih
met_art_datasetyang Anda buat. - Untuk Nama tabel, masukkan nama, misalnya,
temp. - Klik Buat.
Mengubah dan Membersihkan Data
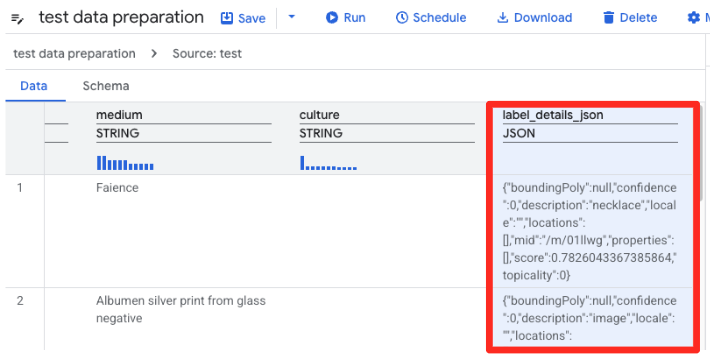
- Persiapan data BigQuery kini akan memuat pratinjau CSV. Temukan kolom
label_details_json, yang berisi string JSON panjang. Klik header kolom untuk memilihnya.
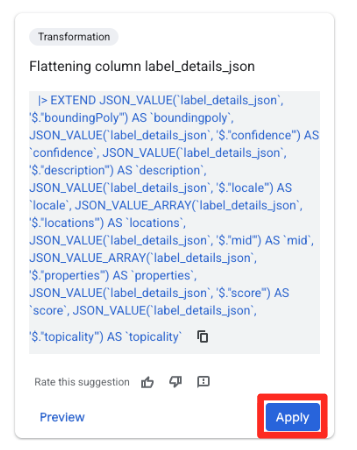
- Di panel Saran di sebelah kanan, Gemini di BigQuery akan otomatis menyarankan transformasi yang relevan. Klik tombol Terapkan pada kartu "Meratakan kolom
label_details_json". Tindakan ini akan mengekstrak kolom bertingkat (description,score, dll.) ke kolom tingkat teratasnya sendiri.
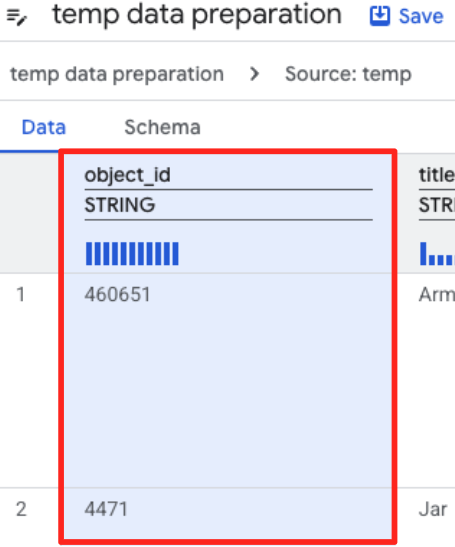
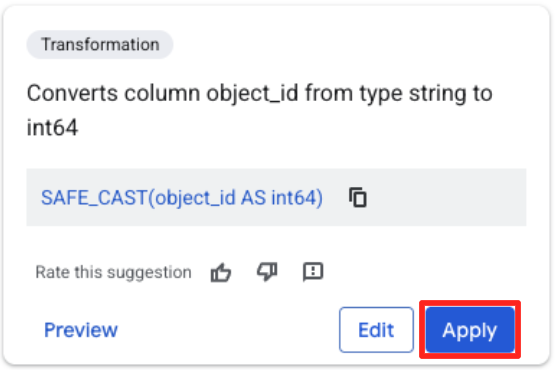
- Klik kolom object_id, lalu klik tombol terapkan pada "Mengonversi kolom
object_iddari jenisstringkeint64.
Menentukan Tujuan dan Menjalankan Tugas
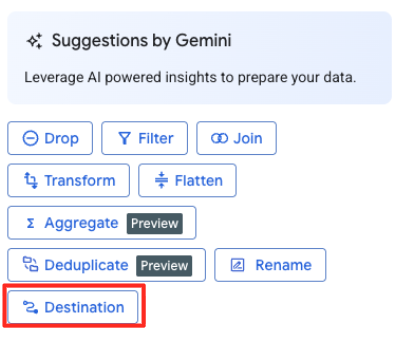
- Di panel sebelah kanan, klik tombol Tujuan untuk mengonfigurasi output transformasi Anda.
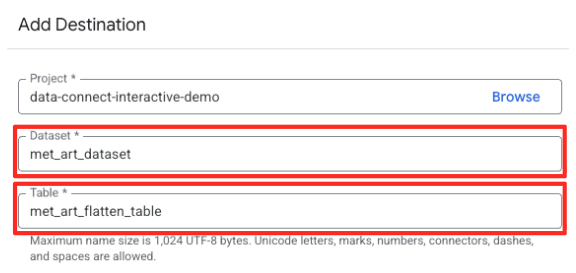
- Tetapkan detail tujuan:
- Set Data harus diisi sebelumnya dengan
met_art_dataset. - Masukkan Nama tabel baru untuk output:
met_art_flatten_table. - Klik Simpan.
- Klik tombol Run, dan tunggu hingga tugas penyiapan data selesai.
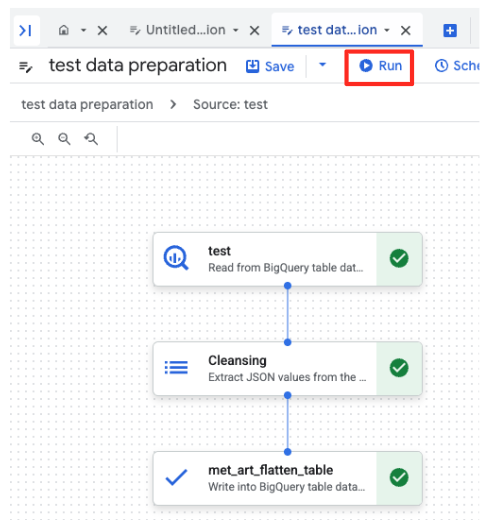
- Anda dapat memantau progres tugas di tab Eksekusi di bagian bawah halaman. Setelah beberapa saat, tugas akan selesai.
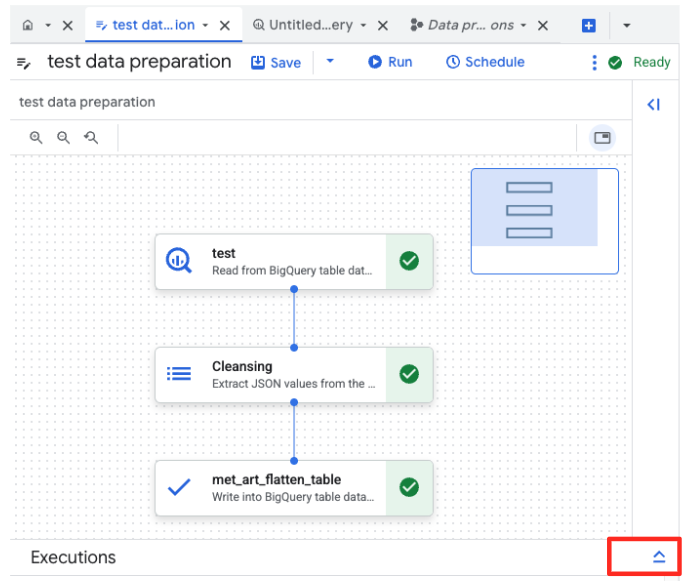
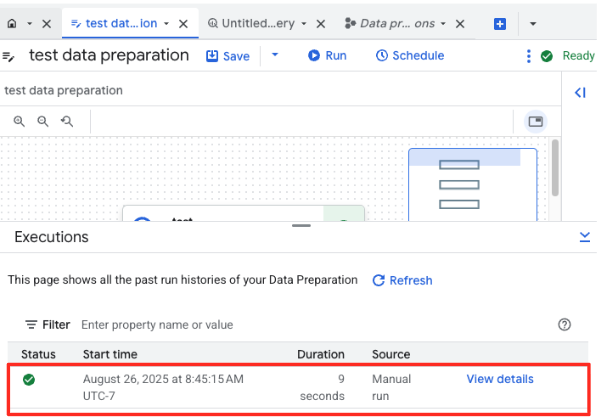
4. Membuat Embedding Vektor dengan BQML
Setelah data kita bersih dan terstruktur, kita akan menggunakan BigQuery ML untuk tugas AI inti: mengonversi deskripsi tekstual karya seni menjadi embedding vektor numerik.
Membuat Koneksi BigQuery
Agar BigQuery dapat berkomunikasi dengan layanan Vertex AI, Anda harus membuat Koneksi BigQuery terlebih dahulu.
- Di panel Explorer BigQuery Studio, klik tombol "+ Tambahkan data".
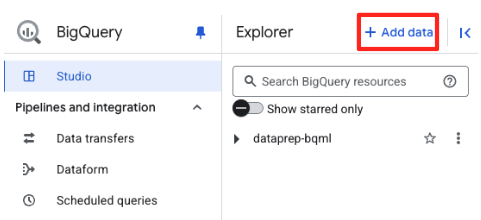
- Di panel sebelah kanan, gunakan kotak penelusuran untuk mengetik
Vertex AI. Pilih, lalu pilih federasi BigQuery dari daftar yang difilter.
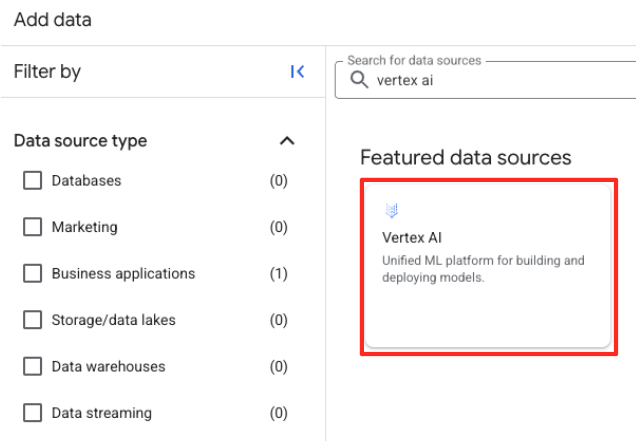
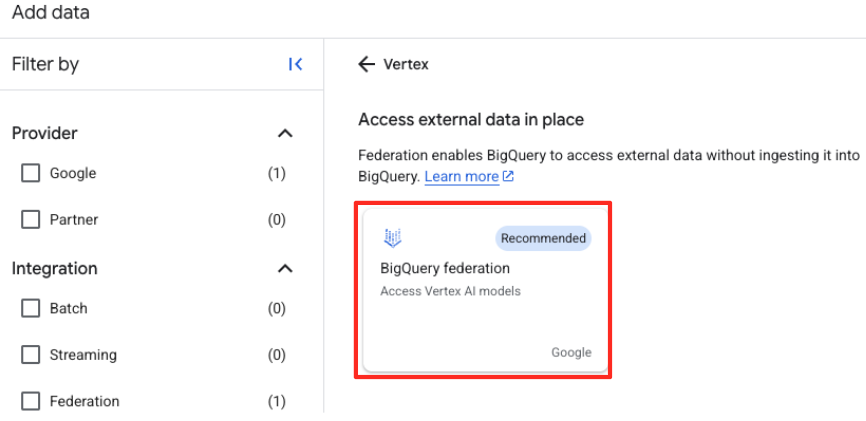
- Tindakan ini akan membuka formulir Sumber data eksternal. Isi detail berikut:
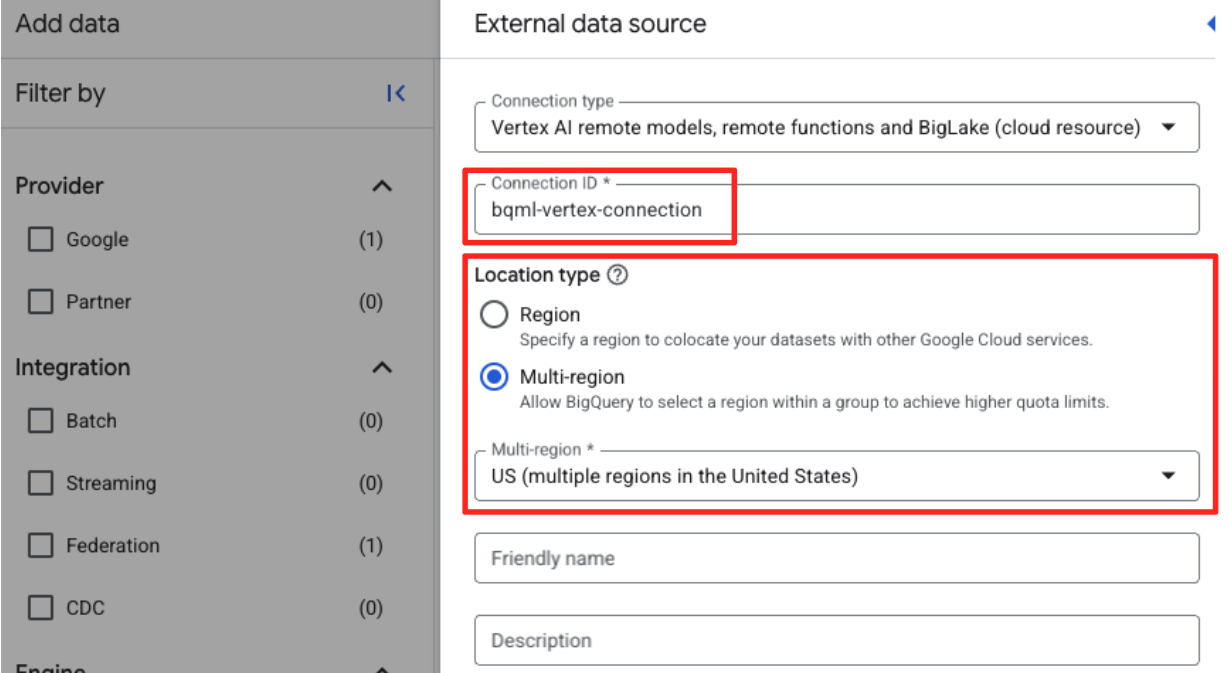
- ID Koneksi: Masukkan ID koneksi (misalnya,
bqml-vertex-connection) - Jenis Lokasi: Pastikan Multi-region dipilih.
- Lokasi: Pilih lokasi (misalnya,
US).
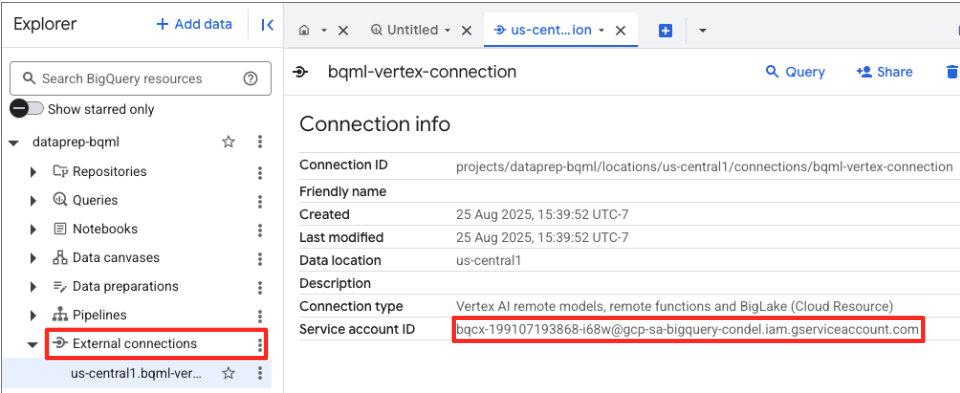
- Setelah koneksi dibuat, dialog konfirmasi akan muncul. Klik Buka Koneksi atau Koneksi eksternal di tab Explorer. Di halaman detail koneksi, salin ID lengkap ke papan klip Anda. Ini adalah identitas akun layanan yang akan digunakan BigQuery untuk memanggil Vertex AI.
- Di menu navigasi Konsol Google Cloud, buka IAM & admin > IAM.
- Klik tombol "Beri akses"
- Tempel akun layanan yang Anda salin pada langkah sebelumnya di kolom New principals.
- Tetapkan "Vertex AI user" di dropdown Role, lalu klik "Save".
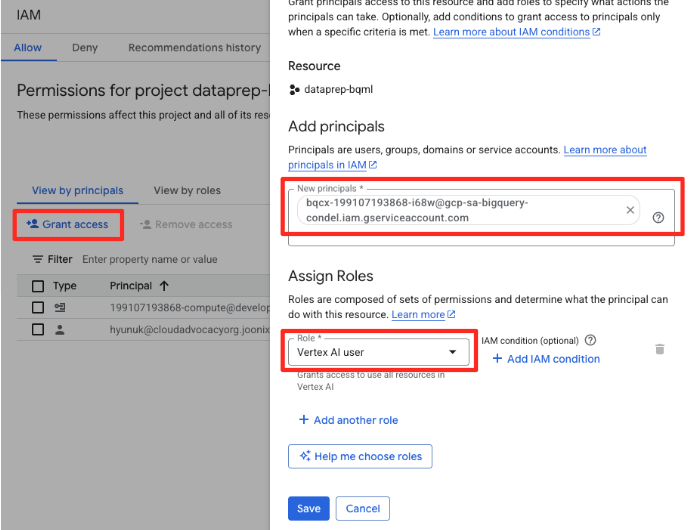
Langkah penting ini memastikan BigQuery memiliki otorisasi yang tepat untuk menggunakan model Vertex AI atas nama Anda.
Membuat model Jarak jauh
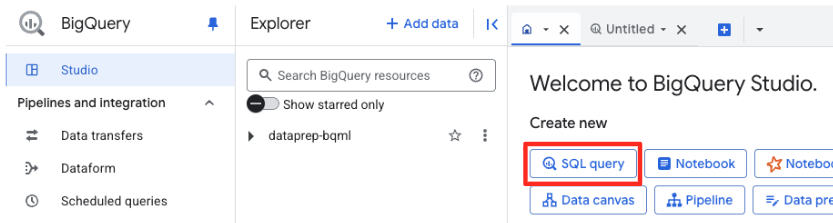
Di BigQuery Studio, buka tab editor SQL baru. Di sinilah Anda akan menentukan model BQML yang terhubung ke Gemini.
Pernyataan ini tidak melatih model baru. Model ini hanya membuat referensi di BigQuery yang mengarah ke model gemini-embedding-001 yang canggih dan telah dilatih sebelumnya menggunakan koneksi yang baru saja Anda beri otorisasi.
Salin seluruh skrip SQL di bawah dan tempelkan ke editor BigQuery.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
Membuat Embedding
Sekarang, kita akan menggunakan model BQML untuk menghasilkan embedding vektor. Alih-alih hanya mengonversi satu label teks untuk setiap baris, kita akan menggunakan pendekatan yang lebih canggih untuk membuat "ringkasan semantik" yang lebih kaya dan bermakna untuk setiap karya seni. Hal ini akan menghasilkan penyematan berkualitas lebih tinggi dan rekomendasi yang lebih akurat.
Kueri ini melakukan langkah praproses yang penting:
- Kueri ini menggunakan klausa
WITHuntuk membuat tabel sementara terlebih dahulu. - Di dalamnya, kita
GROUP BYsetiapobject_iduntuk menggabungkan semua informasi tentang satu karya seni ke dalam satu baris. - Kita menggunakan fungsi
STRING_AGGuntuk menggabungkan semua deskripsi teks terpisah (seperti 'Potret', 'Wanita', 'Lukisan cat minyak di atas kanvas') menjadi satu string teks yang komprehensif, dengan mengurutkannya berdasarkan skor relevansinya.
Teks gabungan ini memberikan konteks yang jauh lebih kaya tentang karya seni kepada AI, sehingga menghasilkan embedding vektor yang lebih mendalam dan efektif.
Di tab editor SQL baru, tempel dan jalankan kueri berikut:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
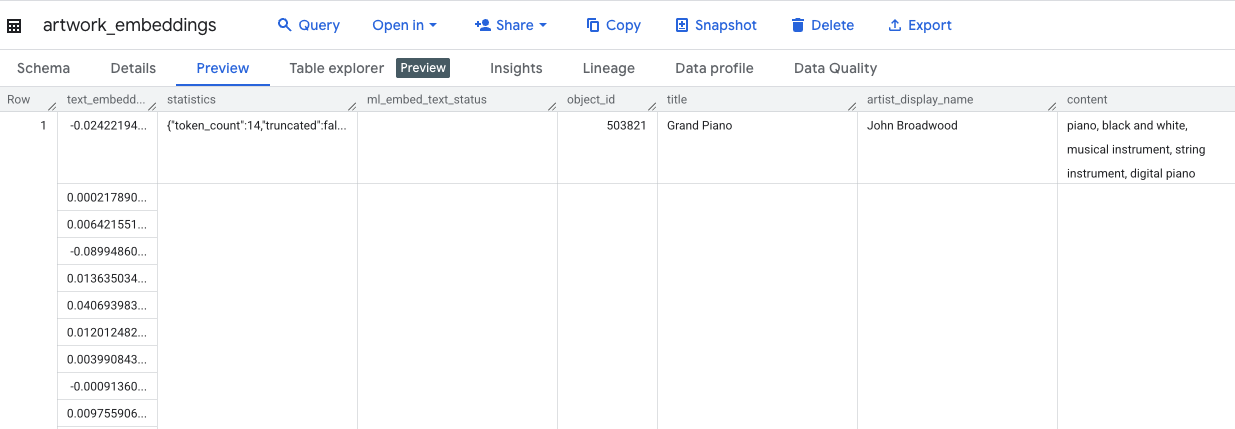
Kueri ini akan memerlukan waktu sekitar 10 menit. Setelah kueri selesai, verifikasi hasilnya. Di panel Explorer, temukan tabel artwork_embeddings baru Anda, lalu klik. Di penampil skema tabel, Anda akan melihat object_id, kolom ml_generate_text_embedding_result baru yang berisi vektor, dan juga kolom aggregated_labels yang digunakan sebagai teks sumber.
5. Menemukan Karya Seni Serupa dengan SQL
Dengan embedding vektor berkualitas tinggi dan kaya konteks yang dibuat, menemukan karya seni yang serupa secara tematis semudah menjalankan kueri SQL. Kita menggunakan fungsi ML.DISTANCE untuk menghitung kesamaan kosinus antara vektor. Karena sematan kami dihasilkan dari teks gabungan, hasil kemiripan akan lebih akurat dan relevan.
- Di tab editor SQL baru, tempel kueri berikut. Kueri ini menyimulasikan logika inti aplikasi rekomendasi:
- Pertama-tama, vektor dipilih untuk satu karya seni tertentu (dalam hal ini, "Cypresses" karya Van Gogh, yang memiliki
object_id436535). - Kemudian, model ini menghitung jarak antara satu vektor tersebut dan semua vektor lain dalam tabel.
- Terakhir, model mengurutkan hasil berdasarkan jarak (jarak yang lebih kecil berarti lebih mirip) untuk menemukan 10 kecocokan teratas yang paling dekat.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- Jalankan kueri ini. Hasilnya akan mencantumkan
object_id, dengan kecocokan terdekat di bagian atas. Gambar sumber akan muncul terlebih dahulu dengan jarak 0. Ini adalah logika inti yang mendukung mesin rekomendasi AI, dan Anda telah membuatnya sepenuhnya dalam BigQuery hanya dengan menggunakan SQL.
6. (OPSIONAL) Menjalankan demo di Cloud Shell
Untuk mewujudkan konsep dari codelab ini, repositori yang Anda clone menyertakan aplikasi web sederhana. Demo opsional ini menggunakan tabel artwork_embeddings yang Anda buat untuk mendukung mesin telusur visual, sehingga Anda dapat melihat cara kerja rekomendasi yang didukung AI.
Untuk menjalankan demo di Cloud Shell, ikuti langkah-langkah berikut:
- Tetapkan Variabel Lingkungan: Sebelum menjalankan aplikasi, Anda perlu menetapkan variabel lingkungan PROJECT_ID dan BIGQUERY_DATASET.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- Instal dependensi dan mulai server backend.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- Anda memerlukan tab terminal kedua untuk menjalankan aplikasi frontend. Klik ikon "+" untuk membuka tab Cloud Shell baru.

- Sekarang, di tab baru, jalankan perintah berikut untuk menginstal dependensi dan menjalankan server frontend
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- Lihat pratinjau aplikasi: Di toolbar Cloud Shell, klik ikon Web Preview, lalu pilih Preview on port 5173. Tindakan ini akan membuka tab browser baru dengan aplikasi yang sedang berjalan. Sekarang Anda dapat menggunakan aplikasi untuk menelusuri karya seni dan melihat cara kerja penelusuran kemiripan.
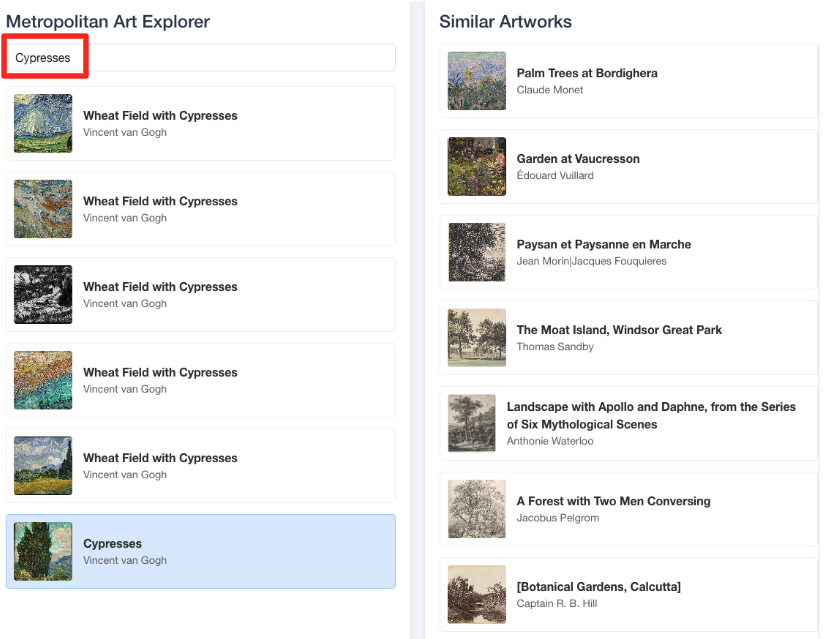
- Untuk menghubungkan kembali demo visual ini ke pekerjaan yang Anda lakukan di editor SQL BigQuery, coba ketik "Cypresses" di kotak penelusuran. Ini adalah karya seni yang sama(
object_id=436535) yang Anda gunakan dalam kueriML.DISTANCE. Kemudian, klik gambar Cypresses saat muncul di panel kiri, Anda akan melihat hasilnya di sebelah kanan. Aplikasi ini menampilkan karya seni yang paling mirip, yang secara visual menunjukkan kecanggihan penelusuran kemiripan vektor yang Anda buat.
7. Membersihkan lingkungan Anda
Agar tidak menimbulkan biaya di masa mendatang pada akun Google Cloud Anda untuk resource yang digunakan dalam codelab ini, Anda harus menghapus resource yang Anda buat.
Jalankan perintah berikut di terminal Cloud Shell untuk menghapus akun layanan, koneksi BigQuery, Bucket GCS, dan set data BigQuery.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
Menghapus Koneksi BigQuery dan Bucket GCS
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
Menghapus set data BigQuery
Terakhir, hapus set data BigQuery. Perintah ini tidak dapat diurungkan. Flag -f (force) menghapus set data dan semua tabelnya tanpa meminta konfirmasi.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. Selamat!
Anda telah berhasil membangun pipeline data end-to-end yang didukung AI.
Anda memulai dengan file CSV mentah di bucket GCS, menggunakan antarmuka low-code BigQuery Data Prep untuk menyerap dan meratakan data JSON yang kompleks, membuat model jarak jauh BQML yang canggih untuk menghasilkan embedding vektor berkualitas tinggi dengan model Gemini, dan menjalankan kueri penelusuran kemiripan untuk menemukan item terkait.
Sekarang Anda telah dilengkapi dengan pola dasar untuk membangun alur kerja yang dibantu AI di Google Cloud, mengubah data mentah menjadi aplikasi cerdas dengan cepat dan mudah.
Apa Selanjutnya?
- Memvisualisasikan hasil di Looker Studio: Hubungkan
artwork_embeddingstabel BigQuery Anda langsung ke Looker Studio (gratis!). Anda dapat membuat dasbor interaktif tempat pengguna dapat memilih karya seni dan melihat galeri visual dari karya yang paling mirip tanpa menulis kode frontend apa pun. - Otomatiskan dengan Kueri Terjadwal: Anda tidak memerlukan alat orkestrasi yang kompleks untuk terus memperbarui penyematan. Gunakan fitur Kueri Terjadwal bawaan BigQuery untuk menjalankan ulang kueri
ML.GENERATE_TEXT_EMBEDDINGsecara otomatis setiap hari atau mingguan. - Membuat aplikasi dengan Gemini CLI: Gunakan Gemini CLI untuk membuat aplikasi lengkap hanya dengan mendeskripsikan persyaratan Anda dalam teks biasa. Dengan begitu, Anda dapat dengan cepat membuat prototipe yang berfungsi untuk penelusuran kesamaan tanpa menulis kode Python secara manual.
- Baca dokumentasi: