
1. Introduzione
Gli analisti dei dati si trovano spesso di fronte a dati preziosi bloccati in formati semi-strutturati come i payload JSON. L'estrazione e la preparazione di questi dati per l'analisi e il machine learning sono sempre stati un ostacolo tecnico significativo, che in genere richiede script ETL complessi e l'intervento di un team di data engineering.
Questo codelab fornisce un progetto tecnico per consentire agli analisti di dati di superare questa sfida in modo indipendente. Mostra un approccio "low-code" per la creazione di una pipeline AI end-to-end. Scoprirai come passare da un file CSV non elaborato in Google Cloud Storage all'attivazione di una funzionalità di suggerimenti basata sull'AI, utilizzando solo gli strumenti disponibili in BigQuery Studio.
L'obiettivo principale è dimostrare un flusso di lavoro solido, veloce e facile da usare per gli analisti, che vada oltre i processi complessi e basati sul codice per generare un valore aziendale reale dai tuoi dati.
Prerequisiti
- Una comprensione di base della console Google Cloud
- Competenze di base nell'interfaccia a riga di comando e in Google Cloud Shell
Cosa imparerai a fare
- Come importare e trasformare un file CSV direttamente da Google Cloud Storage utilizzando BigQuery Data Preparation.
- Come utilizzare le trasformazioni no-code per analizzare e appiattire le stringhe JSON nidificate all'interno dei dati.
- Come creare un modello remoto BigQuery ML che si connette a un modello di base Vertex AI per l'incorporamento di testo.
- Come utilizzare la funzione
ML.GENERATE_TEXT_EMBEDDINGper convertire i dati testuali in vettori numerici. - Come utilizzare la funzione
ML.DISTANCEper calcolare la somiglianza del coseno e trovare gli elementi più simili nel tuo set di dati.
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome
Concetti fondamentali
- Preparazione dei dati di BigQuery:uno strumento all'interno di BigQuery Studio che fornisce un'interfaccia visiva e interattiva per la pulizia e la preparazione dei dati. Suggerisce trasformazioni e consente agli utenti di creare pipeline di dati con codice minimo.
- Modello remoto BQML:un oggetto BigQuery ML che funge da proxy per un modello ospitato su Vertex AI (come Gemini). Consente di richiamare modelli di AI preaddestrati e potenti utilizzando la sintassi SQL che conosci.
- Vector embedding:una rappresentazione numerica dei dati, come testo o immagini. In questo codelab, convertiremo le descrizioni testuali delle opere d'arte in vettori, in cui descrizioni simili generano vettori "più vicini" nello spazio multidimensionale.
- Similarità del coseno:una misura matematica utilizzata per determinare il grado di somiglianza tra due vettori. È il fulcro della logica del nostro motore di suggerimenti, utilizzato dalla funzione
ML.DISTANCEper trovare le opere più "vicine" (più simili).
2. Configurazione e requisiti
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:

Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
Abilita le API richieste e configura l'ambiente
In Cloud Shell, esegui i seguenti comandi per impostare l'ID progetto, definire le variabili di ambiente e abilitare tutte le API necessarie per questo codelab.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
Crea un set di dati BigQuery e un bucket GCS
Crea un nuovo set di dati BigQuery per ospitare le tabelle e un bucket Google Cloud Storage per archiviare il file CSV di origine.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
Prepara e carica i dati di esempio
Clona il repository GitHub contenente il file CSV di esempio, quindi caricalo nel bucket GCS che hai appena creato.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. Da GCS a BigQuery con la preparazione dei dati
In questa sezione, utilizzeremo un'interfaccia visiva senza codice per importare il file CSV da GCS, pulirlo e caricarlo in una nuova tabella BigQuery.
Avviare la preparazione dei dati e connettersi all'origine
- Nella console Google Cloud, vai a BigQuery Studio.
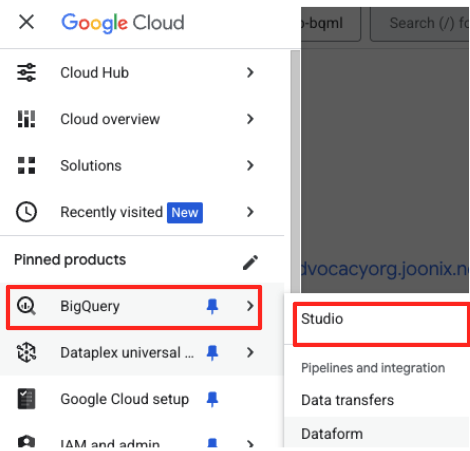
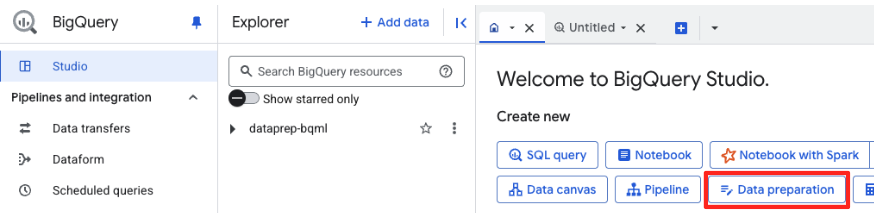
- Nella pagina di benvenuto, fai clic sulla scheda Preparazione dei dati per iniziare.
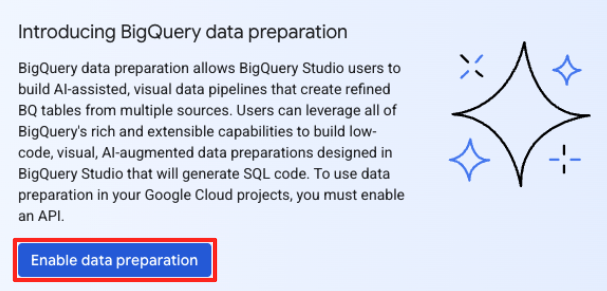
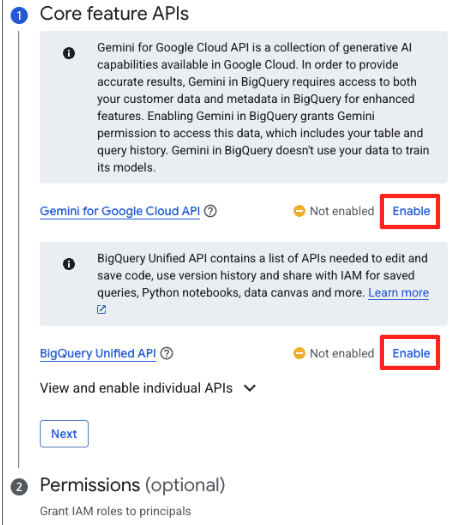
- Se è la prima volta, potrebbe essere necessario abilitare le API richieste. Fai clic su Abilita sia per l'"API Gemini for Google Cloud" sia per l'"API BigQuery Unified". Una volta attivate, puoi chiudere questo riquadro.
- Nella finestra principale Preparazione dei dati, fai clic su Google Cloud Storage nella sezione "Scegli altre origini dati". A destra si aprirà il riquadro "Prepara i dati".
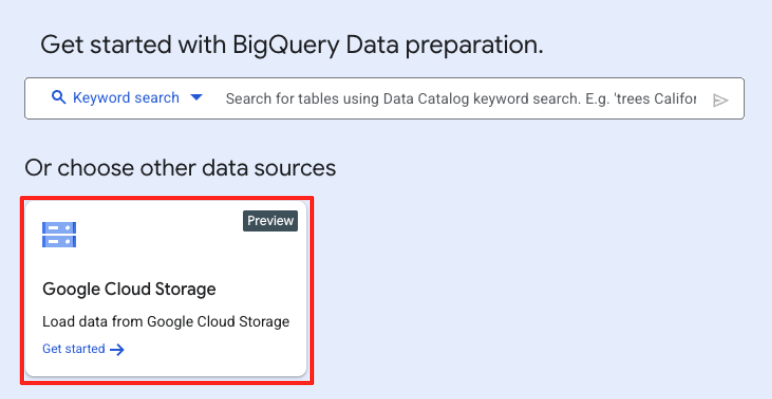
- Fai clic sul pulsante Sfoglia per selezionare il file di origine.
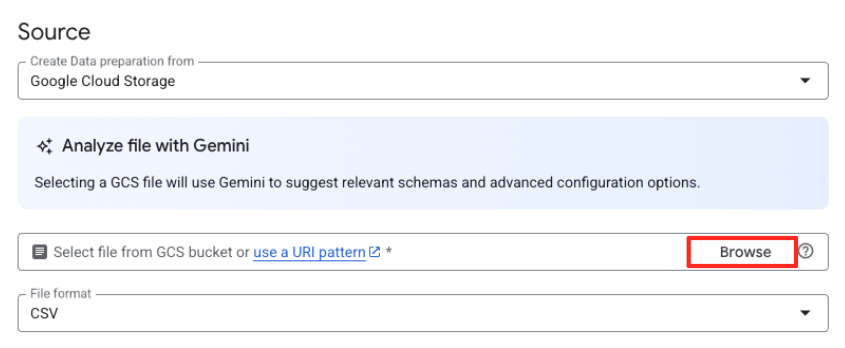
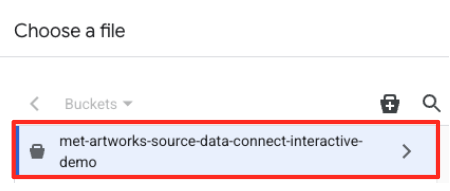
- Vai al bucket GCS che hai creato in precedenza (
met-artworks-source-...) e seleziona il filedataprep-met-bqml.csv. Fai clic su Seleziona.
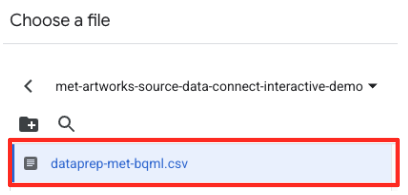
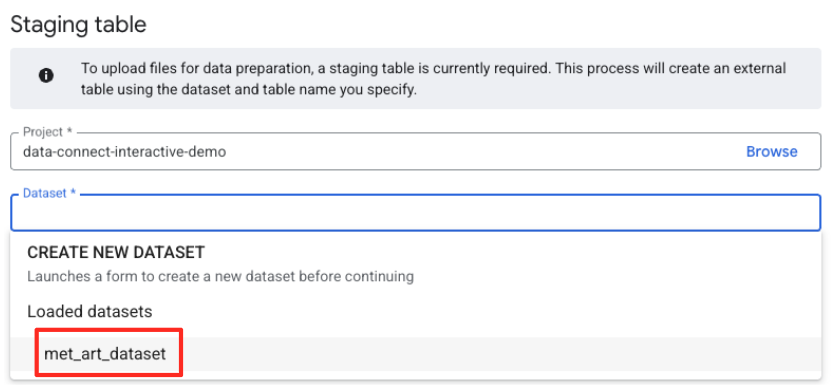
- A questo punto devi configurare una tabella di gestione temporanea.
- Per Set di dati, seleziona
met_art_datasetche hai creato. - In Nome tabella, inserisci un nome, ad esempio
temp. - Fai clic su Crea.
Trasformare e pulire i dati
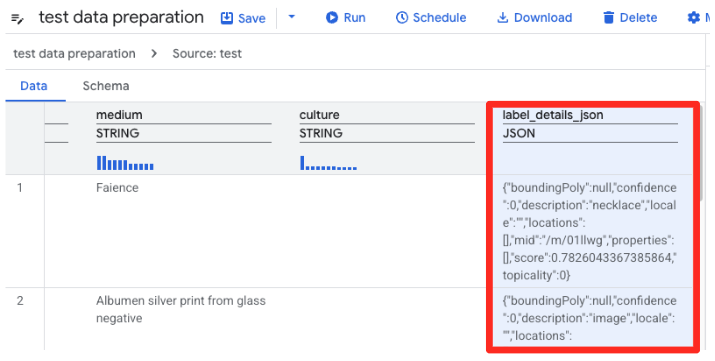
- La preparazione dei dati di BigQuery ora caricherà un'anteprima del file CSV. Trova la colonna
label_details_json, che contiene la lunga stringa JSON. Fai clic sull'intestazione della colonna per selezionarla.
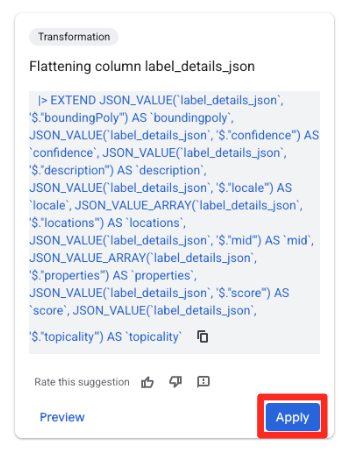
- Nel riquadro Suggerimenti a destra, Gemini in BigQuery suggerirà automaticamente le trasformazioni pertinenti. Fai clic sul pulsante Applica nella scheda "Colonna di compressione
label_details_json". In questo modo, i campi nidificati (description,scoree così via) verranno estratti in colonne di primo livello separate.
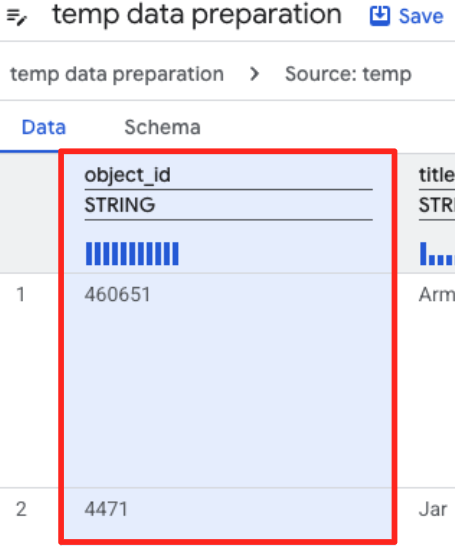
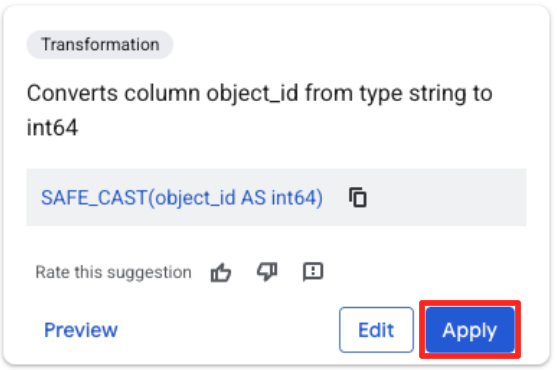
- Fai clic sulla colonna object_id e poi sul pulsante Applica nella sezione "Converte la colonna
object_iddal tipostringaint64".
Definisci la destinazione ed esegui il job
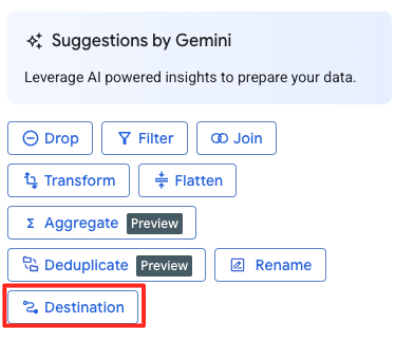
- Nel riquadro a destra, fai clic sul pulsante Destinazione per configurare l'output della trasformazione.
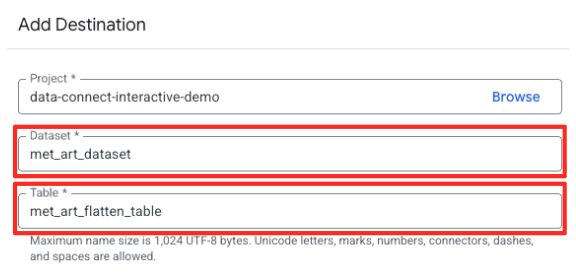
- Imposta i dettagli della destinazione:
- Il set di dati deve essere precompilato con
met_art_dataset. - Inserisci un nuovo nome tabella per l'output:
met_art_flatten_table. - Fai clic su Salva.
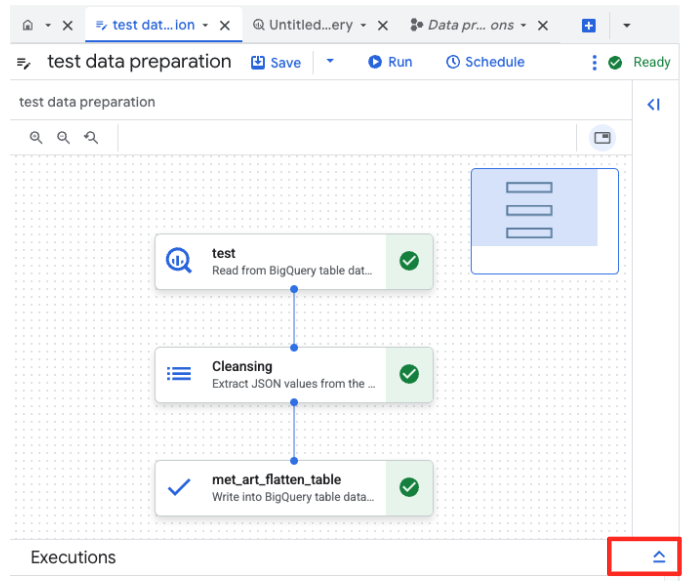
- Fai clic sul pulsante Esegui e attendi il completamento del job di preparazione dei dati.
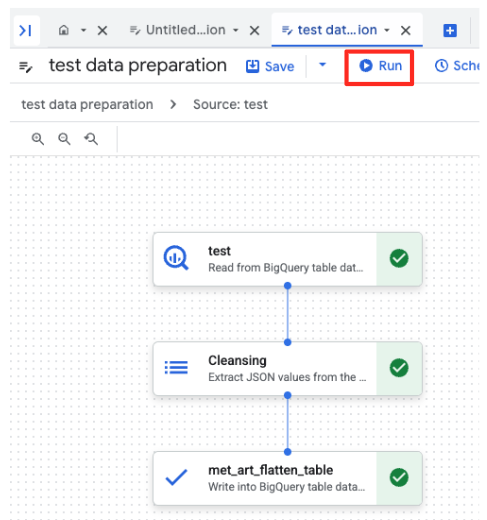
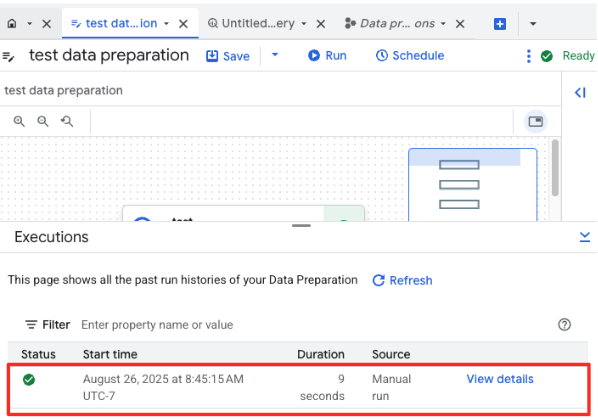
- Puoi monitorare l'avanzamento del job nella scheda Esecuzioni nella parte inferiore della pagina. Dopo qualche istante, il job verrà completato.
4. Generare vector embedding con BQML
Ora che i nostri dati sono puliti e strutturati, utilizzeremo BigQuery ML per l'attività di AI principale: convertire le descrizioni testuali delle opere d'arte in incorporamenti vettoriali numerici.
Crea una connessione BigQuery
Per consentire a BigQuery di comunicare con i servizi Vertex AI, devi prima creare una connessione BigQuery.
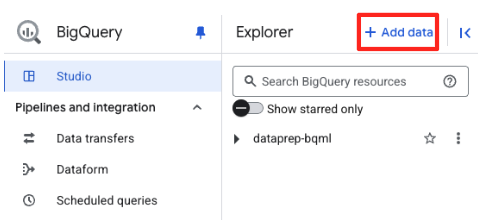
- Nel riquadro Explorer di BigQuery Studio, fai clic sul pulsante "+ Aggiungi dati".
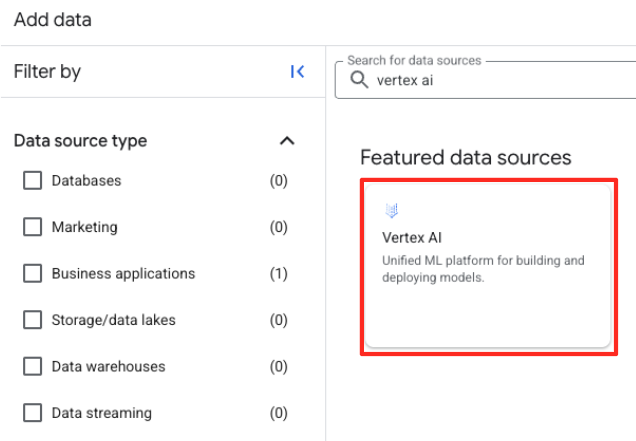
- Nel riquadro a destra, utilizza la barra di ricerca per digitare
Vertex AI. Selezionalo e poi seleziona la federazione BigQuery dall'elenco filtrato.
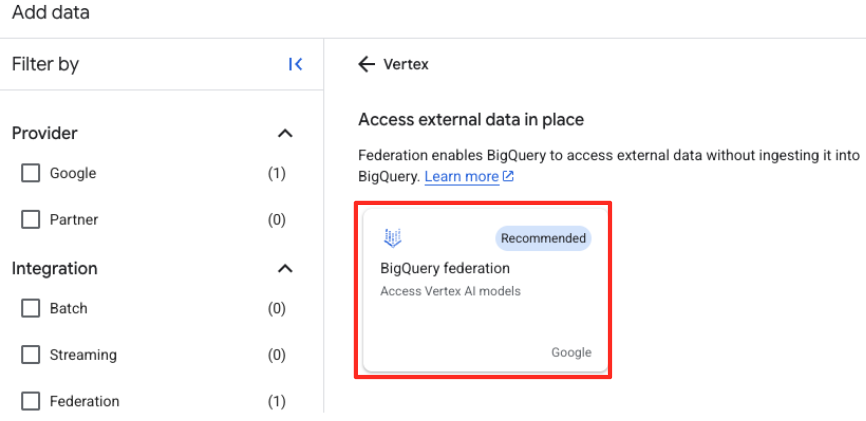
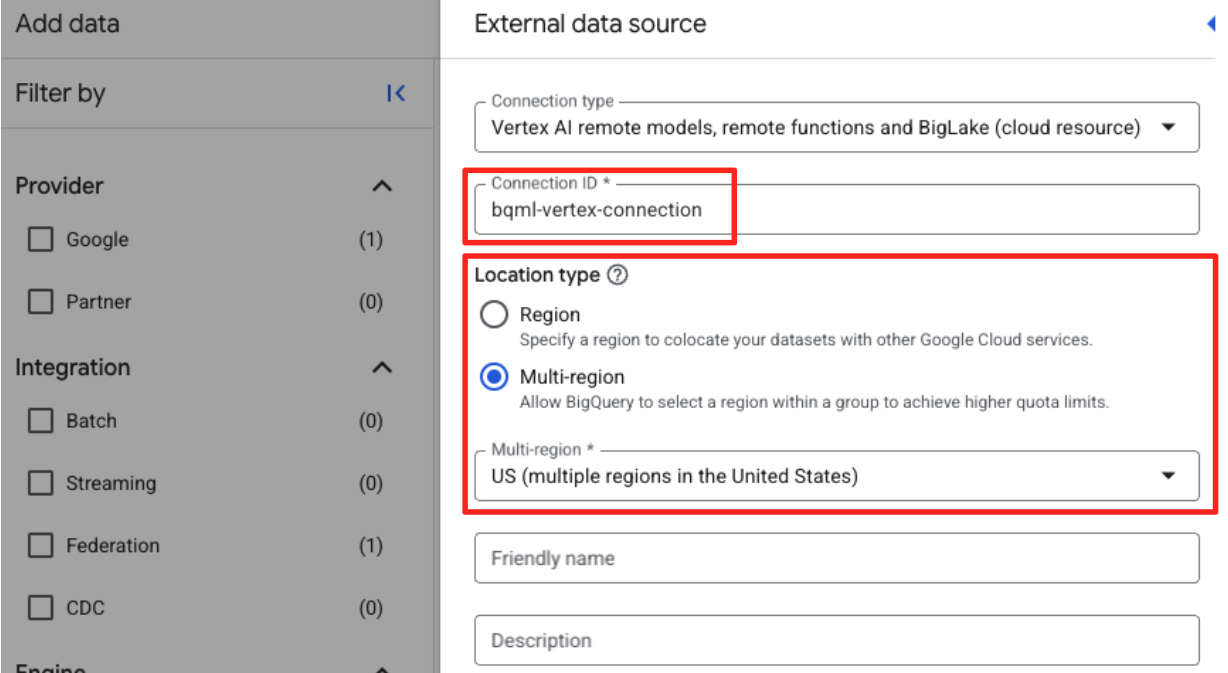
- Si aprirà il modulo Origine dati esterna. Inserisci i seguenti dettagli:
- ID connessione: inserisci l'ID connessione (ad es.
bqml-vertex-connection) - Tipo di località: assicurati che sia selezionato Più regioni.
- Località: seleziona la località (ad es.
US).
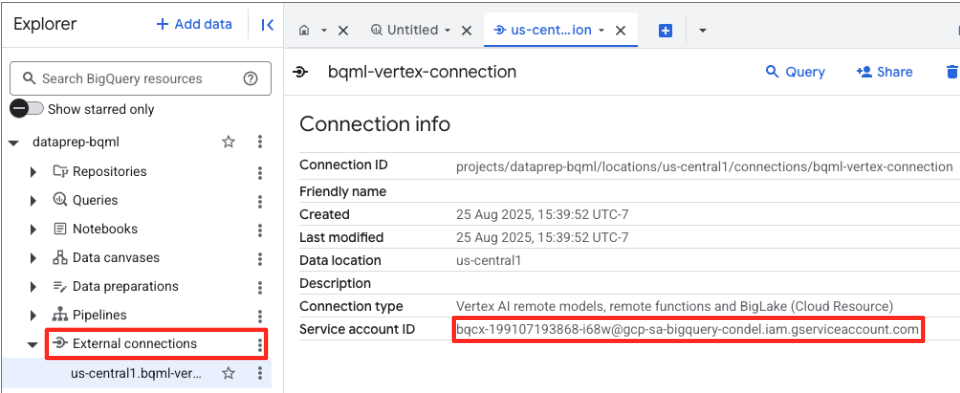
- Una volta creata la connessione, viene visualizzata una finestra di dialogo di conferma. Fai clic su Vai a connessione o Connessioni esterne nella scheda Explorer. Nella pagina dei dettagli della connessione, copia l'ID completo negli appunti. Si tratta dell'identità del service account che BigQuery utilizzerà per chiamare Vertex AI.
- Nel menu di navigazione di Google Cloud Console, vai a IAM e amministrazione > IAM.
- Fai clic sul pulsante "Concedi l'accesso".
- Incolla il service account che hai copiato nel passaggio precedente nel campo Nuove entità.
- Assegna "Utente Vertex AI" nel menu a discesa Ruolo e fai clic su "Salva".
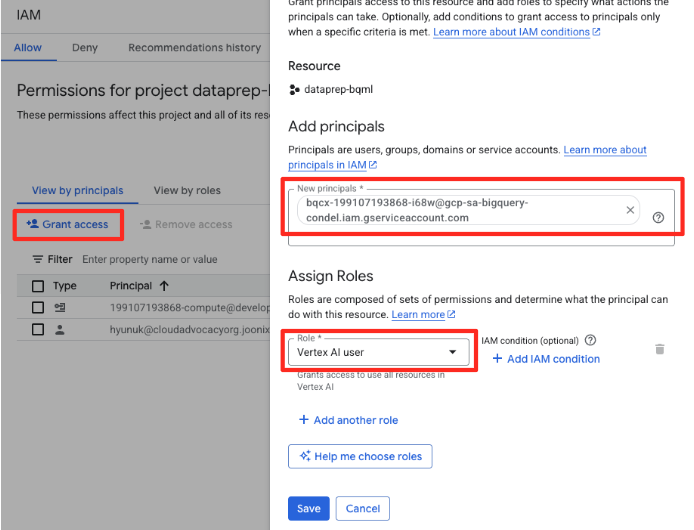
Questo passaggio fondamentale garantisce che BigQuery disponga dell'autorizzazione appropriata per utilizzare i modelli Vertex AI per tuo conto.
Crea un modello remoto
In BigQuery Studio, apri una nuova scheda dell'editor SQL. Qui definirai il modello BQML che si connette a Gemini.
Questa istruzione non addestra un nuovo modello. Crea semplicemente un riferimento in BigQuery che punta a un potente modello gemini-embedding-001 preaddestrato utilizzando la connessione che hai appena autorizzato.
Copia l'intero script SQL riportato di seguito e incollalo nell'editor di BigQuery.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
Genera incorporamenti
Ora utilizzeremo il modello BQML per generare i vector embedding. Anziché convertire semplicemente una singola etichetta di testo per ogni riga, utilizzeremo un approccio più sofisticato per creare un "riepilogo semantico" più ricco e significativo per ogni grafica. In questo modo, gli incorporamenti saranno di qualità superiore e i consigli più accurati.
Questa query esegue un passaggio di preelaborazione fondamentale:
- Utilizza una clausola
WITHper creare prima una tabella temporanea. - Al suo interno,
GROUP BYogniobject_idper combinare tutte le informazioni su una singola opera d'arte in una riga. - Utilizziamo la funzione
STRING_AGGper unire tutte le descrizioni di testo separate (come "Ritratto", "Donna", "Olio su tela") in un'unica stringa di testo completa, ordinandole in base al punteggio di pertinenza.
Questo testo combinato fornisce all'AI un contesto molto più ricco sull'artwork, portando a incorporamenti vettoriali più sfumati ed efficaci.
In una nuova scheda dell'editor SQL, incolla ed esegui la seguente query:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
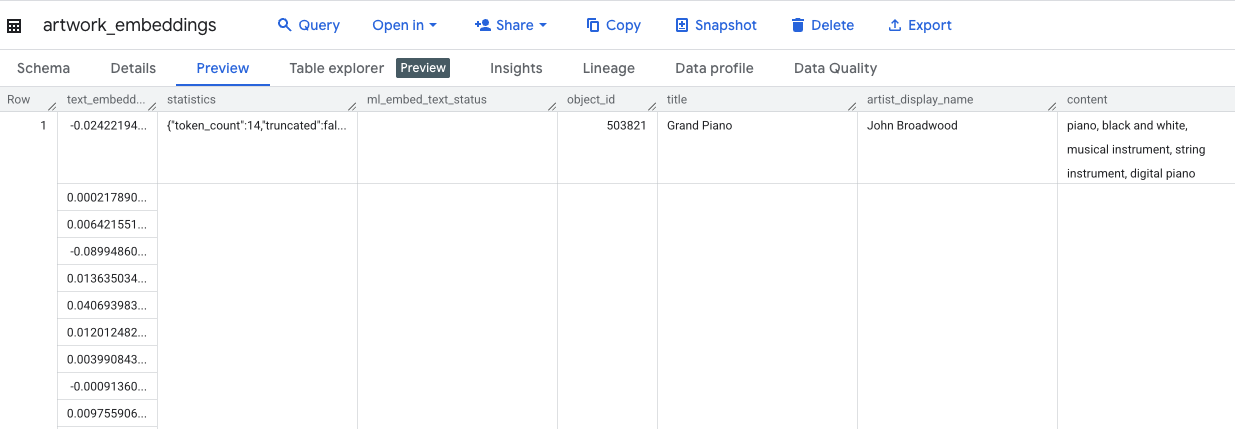
Questa richiesta richiederà circa 10 minuti. Una volta completata la query, verifica i risultati. Nel riquadro Explorer, individua la nuova tabella artwork_embeddings e fai clic. Nel visualizzatore dello schema della tabella, vedrai object_id, la nuova colonna ml_generate_text_embedding_result contenente i vettori e anche la colonna aggregated_labels utilizzata come testo di origine.
5. Trovare opere d'arte simili con SQL
Con i nostri vector embedding di alta qualità e ricchi di contesto creati, trovare opere d'arte simili per tema è semplice come eseguire una query SQL. Utilizziamo la funzione ML.DISTANCE per calcolare la similarità del coseno tra i vettori. Poiché gli incorporamenti sono stati generati da testo aggregato, i risultati di similarità saranno più precisi e pertinenti.
- In una nuova scheda dell'editor SQL, incolla la query seguente. Questa query simula la logica principale di un'applicazione di consigli:
- Innanzitutto, seleziona il vettore di una singola opera specifica (in questo caso, "Cipressi" di Van Gogh, che ha un
object_iddi 436535). - Quindi, calcola la distanza tra questo singolo vettore e tutti gli altri vettori della tabella.
- Infine, ordina i risultati in base alla distanza (una distanza più breve indica una maggiore somiglianza) per trovare le 10 corrispondenze più vicine.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- Esegui la query. I risultati mostreranno gli
object_id, con le corrispondenze più vicine in cima. L'artwork di origine verrà visualizzato per primo con una distanza pari a 0. Questa è la logica di base che alimenta un motore di suggerimenti AI e l'hai creata interamente in BigQuery utilizzando solo SQL.
6. (FACOLTATIVO) Esecuzione della demo in Cloud Shell
Per dare vita ai concetti di questo codelab, il repository che hai clonato include una semplice applicazione web. Questa demo facoltativa utilizza la tabella artwork_embeddings che hai creato per alimentare un motore di ricerca visiva, consentendoti di vedere i consigli basati sull'AI in azione.
Per eseguire la demo in Cloud Shell:
- Imposta le variabili di ambiente: prima di eseguire l'applicazione, devi impostare le variabili di ambiente PROJECT_ID e BIGQUERY_DATASET.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- Installa le dipendenze e avvia il server di backend.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- Per eseguire l'applicazione frontend, avrai bisogno di una seconda scheda del terminale. Fai clic sull'icona "+" per aprire una nuova scheda di Cloud Shell.

- Ora, nella nuova scheda, esegui il seguente comando per installare le dipendenze ed eseguire il server di frontend
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- Visualizza l'anteprima dell'applicazione: nella barra degli strumenti di Cloud Shell, fai clic sull'icona Anteprima web e seleziona Anteprima sulla porta 5173. Si aprirà una nuova scheda del browser con l'applicazione in esecuzione. Ora puoi utilizzare l'applicazione per cercare opere d'arte e vedere la ricerca di similarità in azione.
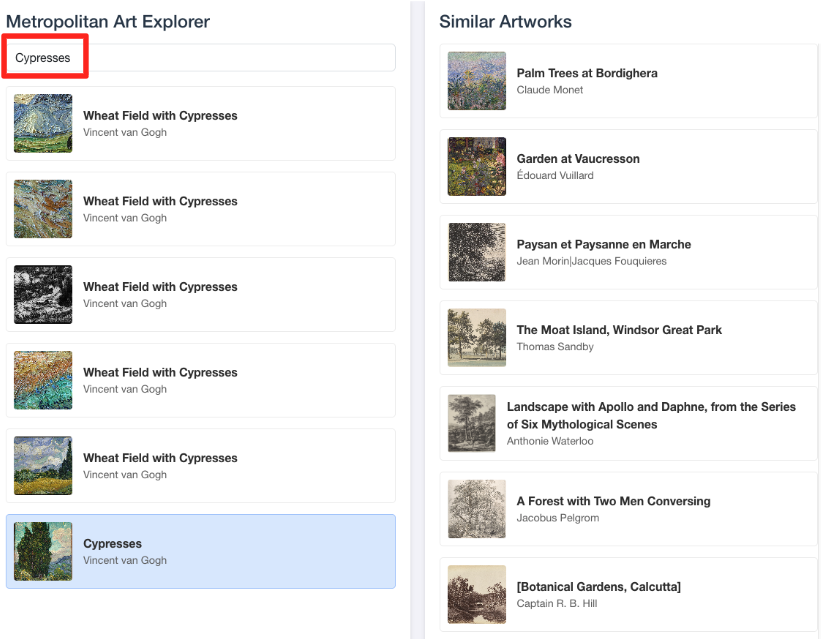
- Per collegare questa demo visiva al lavoro svolto nell'editor SQL di BigQuery, prova a digitare "Cipressi" nella barra di ricerca. Si tratta della stessa copertina(
object_id=436535) che hai utilizzato nella queryML.DISTANCE. Poi fai clic sull'immagine dei cipressi quando viene visualizzata nel riquadro a sinistra e osserva i risultati a destra. L'applicazione mostra le opere d'arte più simili, dimostrando visivamente la potenza della ricerca di somiglianze vettoriali che hai creato.
7. Pulizia dell'ambiente
Per evitare che al tuo account Google Cloud vengano addebitati costi futuri per le risorse utilizzate in questo codelab, devi eliminare le risorse che hai creato.
Esegui i seguenti comandi nel terminale Cloud Shell per rimuovere il service account, la connessione BigQuery, il bucket GCS e il set di dati BigQuery.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
Rimuovere la connessione BigQuery e il bucket GCS
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
Elimina il set di dati BigQuery
Infine, elimina il set di dati BigQuery. Questo comando è irreversibile. Il flag -f (force) rimuove il set di dati e tutte le relative tabelle senza richiedere la conferma.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. Complimenti!
Hai creato una pipeline di dati end-to-end basata sull'AI.
Hai iniziato con un file CSV non elaborato in un bucket GCS, hai utilizzato l'interfaccia low-code di BigQuery Data Prep per importare e appiattire dati JSON complessi, hai creato un potente modello remoto BQML per generare incorporamenti vettoriali di alta qualità con un modello Gemini e hai eseguito una query di ricerca di similarità per trovare elementi correlati.
Ora disponi del pattern fondamentale per creare workflow basati sull'AI su Google Cloud, trasformando i dati non elaborati in applicazioni intelligenti in modo rapido e semplice.
Passaggi successivi
- Visualizza i risultati in Looker Studio:collega la tabella BigQuery
artwork_embeddingsdirettamente a Looker Studio (è senza costi). Puoi creare una dashboard interattiva in cui gli utenti possono selezionare un'opera d'arte e visualizzare una galleria visiva delle opere più simili senza scrivere codice frontend. - Automatizza con le query pianificate:non hai bisogno di uno strumento di orchestrazione complesso per mantenere aggiornati gli incorporamenti. Utilizza la funzionalità Query pianificate integrate di BigQuery per eseguire nuovamente la query
ML.GENERATE_TEXT_EMBEDDINGautomaticamente su base giornaliera o settimanale. - Genera un'app con Gemini CLI:utilizza Gemini CLI per generare un'applicazione completa semplicemente descrivendo il tuo requisito in testo normale. In questo modo, puoi creare rapidamente un prototipo funzionante per la ricerca per similarità senza scrivere manualmente il codice Python.
- Leggi la documentazione: