
1. はじめに
データ アナリストは、JSON ペイロードなどの半構造化形式でロックされた貴重なデータに直面することがよくあります。このデータを抽出して分析と ML 用に準備することは、従来は大きな技術的なハードルであり、複雑な ETL スクリプトとデータ エンジニアリング チームの介入が必要でした。
この Codelab では、データ アナリストがこの課題に単独で取り組むための技術的なブループリントを提供します。これは、エンドツーエンドの AI パイプラインを構築する「ローコード」アプローチを示しています。このチュートリアルでは、Google Cloud Storage の生の CSV ファイルから、BigQuery Studio で利用可能なツールのみを使用して AI 駆動型のレコメンデーション機能を強化する方法を学びます。
主な目的は、複雑でコードの多いプロセスから脱却し、データから実際のビジネス価値を生み出す、堅牢で高速かつアナリストに優しいワークフローを実証することです。
前提条件
- Google Cloud コンソールの基本的な知識
- コマンドライン インターフェースと Google Cloud Shell の基本的なスキル
学習内容
- BigQuery Data Preparation を使用して、Google Cloud Storage から CSV ファイルを直接取り込んで変換する方法。
- ノーコード変換を使用して、データ内のネストされた JSON 文字列を解析してフラット化する方法。
- テキスト エンベディング用の Vertex AI 基盤モデルに接続する BigQuery ML リモートモデルを作成する方法。
ML.GENERATE_TEXT_EMBEDDING関数を使用してテキストデータを数値ベクトルに変換する方法。ML.DISTANCE関数を使用してコサイン類似度を計算し、データセット内で最も類似したアイテムを見つける方法。
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- ウェブブラウザ(Chrome など)
主なコンセプト
- BigQuery データ準備: BigQuery Studio 内のツール。データのクリーニングと準備を行うためのインタラクティブなビジュアル インターフェースを提供します。変換を提案し、ユーザーが最小限のコードでデータ パイプラインを構築できるようにします。
- BQML リモートモデル: Vertex AI(Gemini など)でホストされているモデルのプロキシとして機能する BigQuery ML オブジェクト。使い慣れた SQL 構文を使用して、強力な事前トレーニング済み AI モデルを呼び出すことができます。
- ベクトル エンベディング: テキストや画像などのデータの数値表現。この Codelab では、アートワークのテキスト説明をベクトルに変換します。類似する説明は、多次元空間で「近い」ベクトルになります。
- コサイン類似度: 2 つのベクトルがどの程度類似しているかを判断するために使用される数学的指標。これは、レコメンデーション エンジンのロジックの中核であり、
ML.DISTANCE関数で使用されて「最も近い」(最も類似した)アートワークを見つけます。
2. 設定と要件
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud Console で、右上のツールバーにある Cloud Shell アイコンをクリックします。

プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
必要な API を有効にして環境を構成する
Cloud Shell で次のコマンドを実行して、プロジェクト ID を設定し、環境変数を定義して、この Codelab に必要なすべての API を有効にします。
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
BigQuery データセットと GCS バケットを作成する
テーブルを格納する新しい BigQuery データセットと、ソース CSV ファイルを保存する Google Cloud Storage バケットを作成します。
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
サンプルデータを準備してアップロードする
サンプル CSV ファイルを含む GitHub リポジトリのクローンを作成し、作成した GCS バケットにアップロードします。
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. Data 準備を使用した GCS から BigQuery への移行
このセクションでは、ビジュアルなノーコード インターフェースを使用して、GCS から CSV ファイルを取り込み、クリーンアップして、新しい BigQuery テーブルに読み込みます。
データ準備を起動してソースに接続する
- Google Cloud コンソールで、BigQuery Studio に移動します。
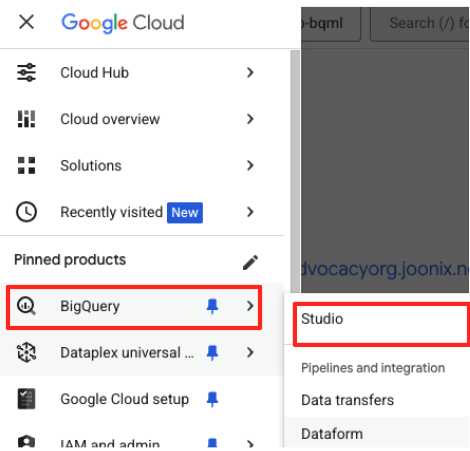
- ウェルカム ページで、[データ準備] カードをクリックして開始します。
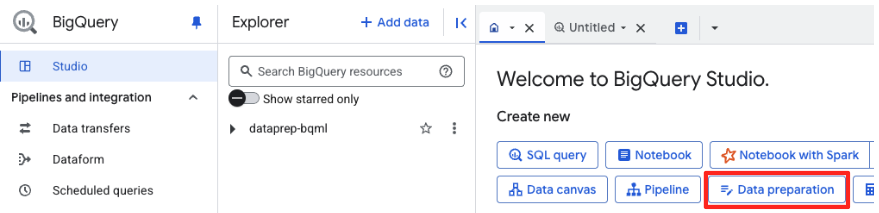
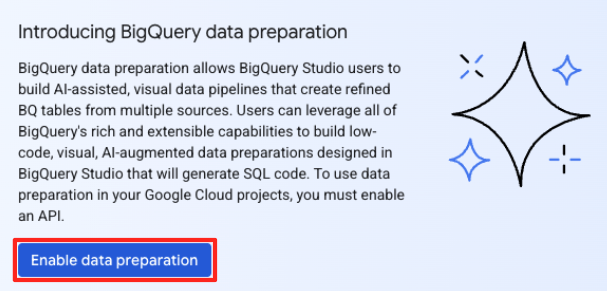
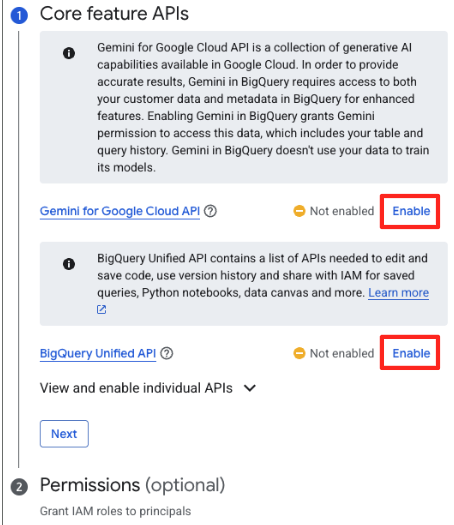
- 初めて使用する場合は、必要な API を有効にする必要があります。[Gemini for Google Cloud API] と [BigQuery Unified API] の両方で [有効にする] をクリックします。有効にしたら、このパネルを閉じることができます。
- メインの [データ準備] ウィンドウの [他のデータソースを選択] で、[Google Cloud Storage] をクリックします。右側に [データを準備] パネルが開きます。
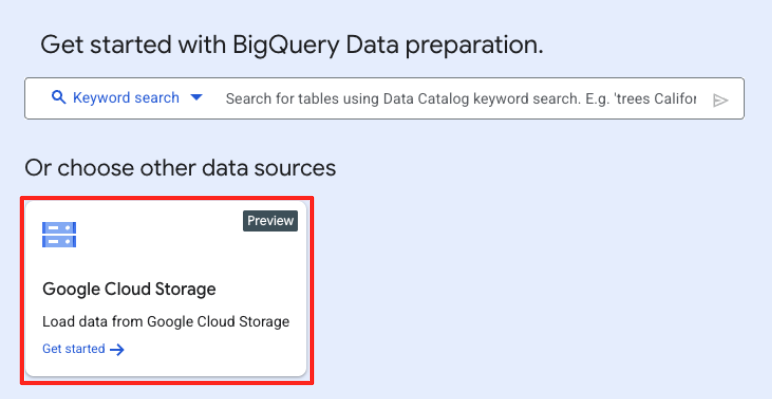
- [参照] ボタンをクリックして、ソースファイルを選択します。
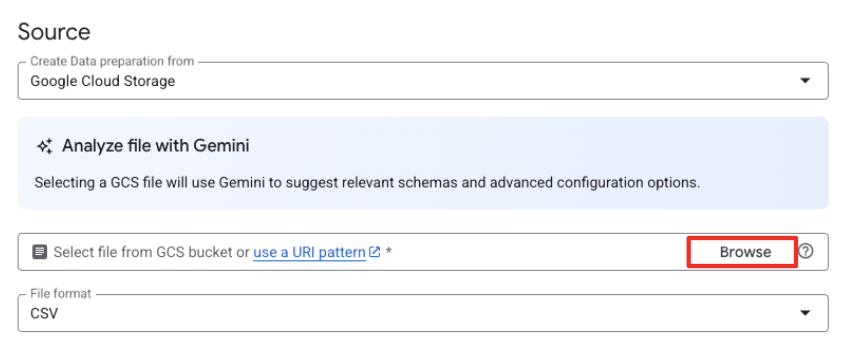
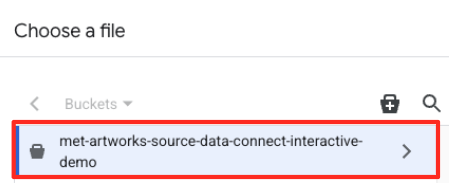
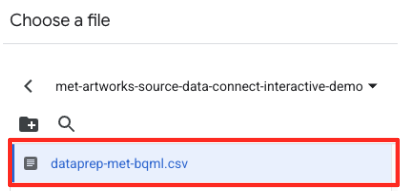
- 前に作成した GCS バケット(
met-artworks-source-...)に移動し、dataprep-met-bqml.csvファイルを選択します。[選択] をクリックします。
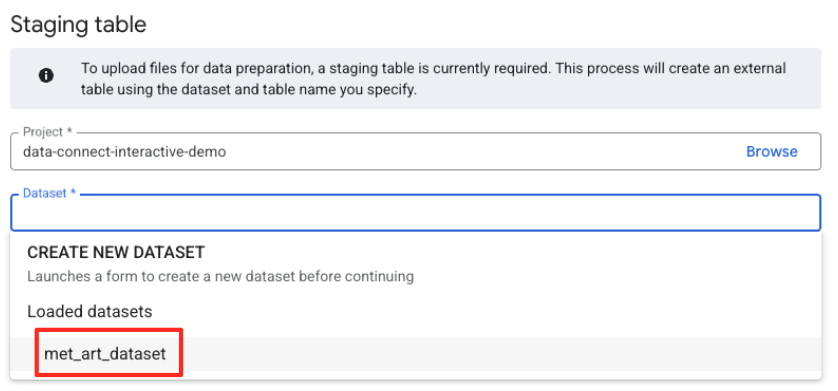
- 次に、ステージング テーブルを構成する必要があります。
- [データセット] で、作成した
met_art_datasetを選択します。 - [テーブル名] に名前を入力します(例:
temp)。 - [作成] をクリックします。
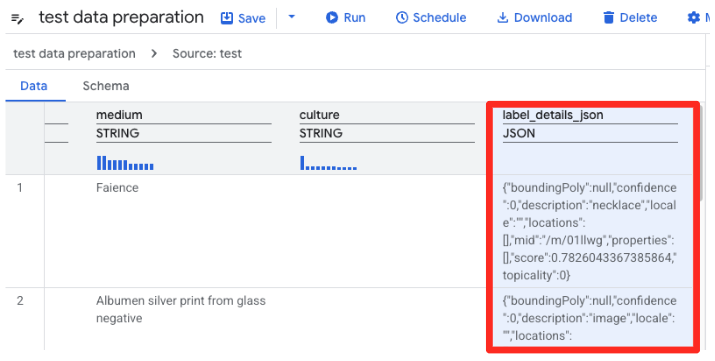
データの変換とクリーニング
- BigQuery のデータ準備機能で CSV のプレビューが読み込まれるようになりました。長い JSON 文字列を含む
label_details_json列を見つけます。列ヘッダーをクリックして選択します。
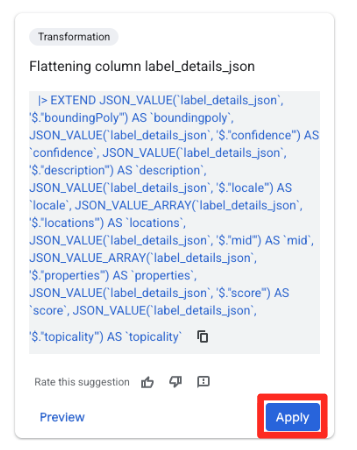
- 右側の [提案] パネルで、Gemini in BigQuery が関連する変換を自動的に提案します。[列の平坦化
label_details_json] カードの [適用] ボタンをクリックします。これにより、ネストされたフィールド(description、scoreなど)が独自のトップレベル列に抽出されます。
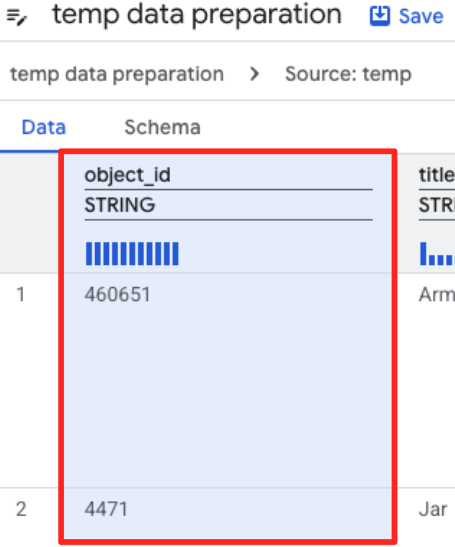
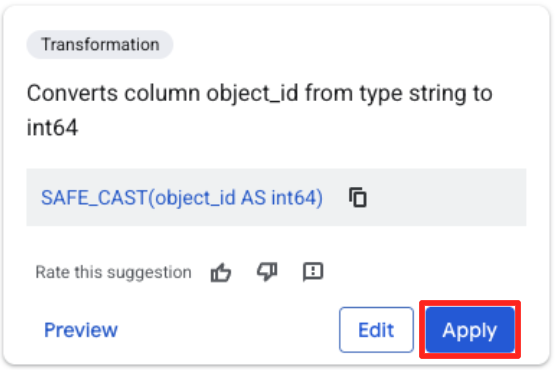
- object_id 列をクリックし、[列
object_idの型をstringからint64に変換します] の適用ボタンをクリックします。
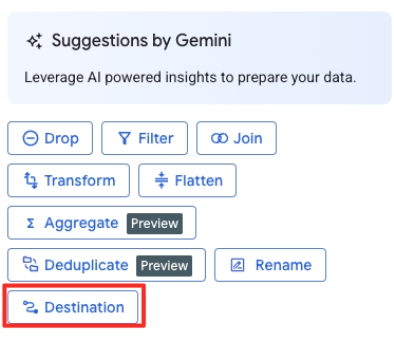
宛先を定義してジョブを実行する
- 右側のパネルで、[宛先] ボタンをクリックして変換の出力を構成します。
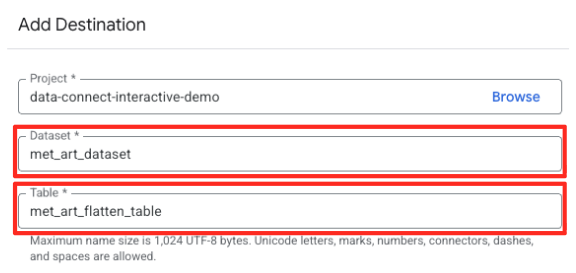
- 宛先の詳細を設定します。
- データセットには
met_art_datasetが事前入力されている必要があります。 - 出力の新しいテーブル名を入力します:
met_art_flatten_table。 - [保存] をクリックします。
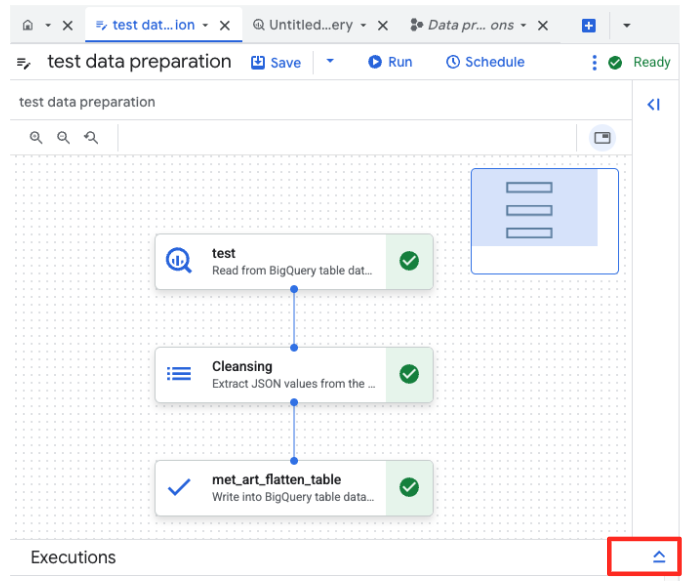
- [実行] ボタンをクリックし、データ準備ジョブが完了するまで待ちます。
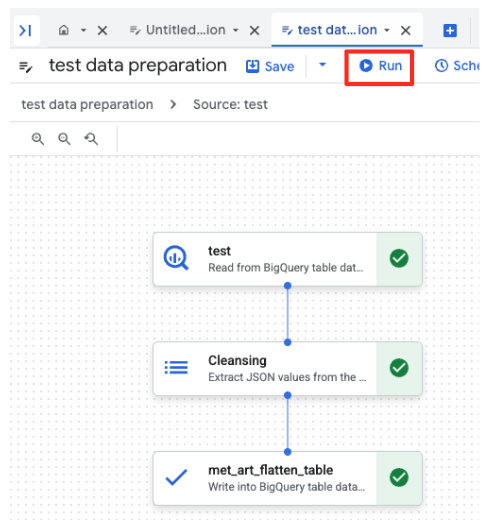
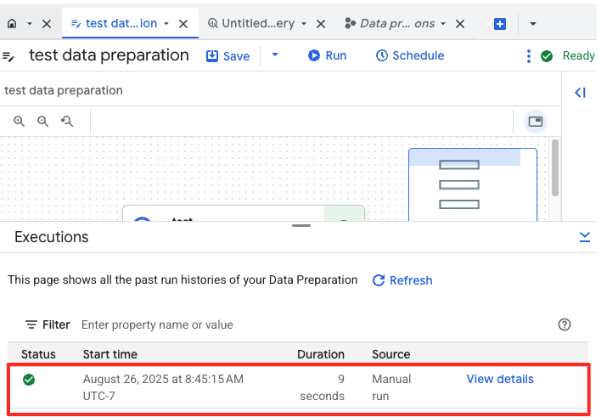
- ジョブの進行状況は、ページ下部の [実行] タブでモニタリングできます。しばらくすると、ジョブが完了します。
4. BQML を使用してベクトル エンベディングを生成する
データがクリーンで構造化されたので、BigQuery ML を使用して、アートワークのテキスト説明を数値ベクトル エンベディングに変換するというコア AI タスクを実行します。
BigQuery 接続を作成する
BigQuery が Vertex AI サービスと通信できるようにするには、まず BigQuery 接続を作成する必要があります。
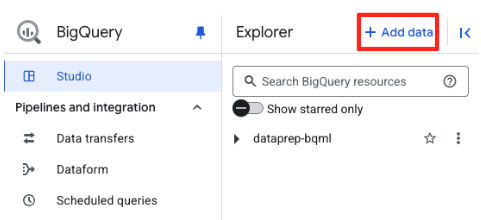
- BigQuery Studio の [エクスプローラ] パネルで、[+ データを追加] ボタンをクリックします。
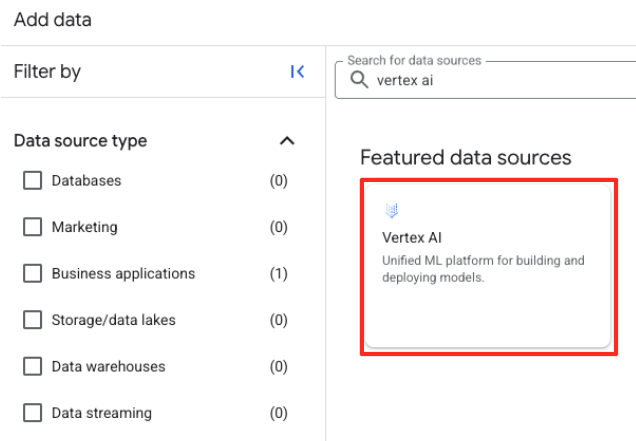
- 右側のパネルで、検索バーに「
Vertex AI」と入力します。フィルタされたリストから選択し、[BigQuery 連携] を選択します。
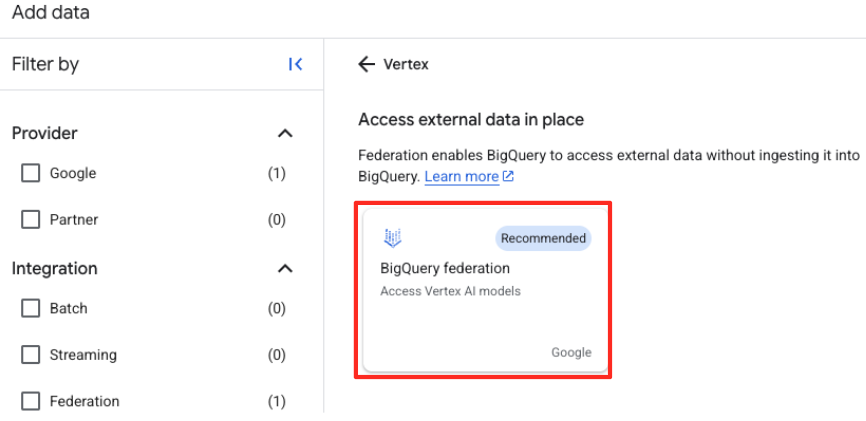
- [外部データソース] フォームが開きます。次の詳細情報を入力します。
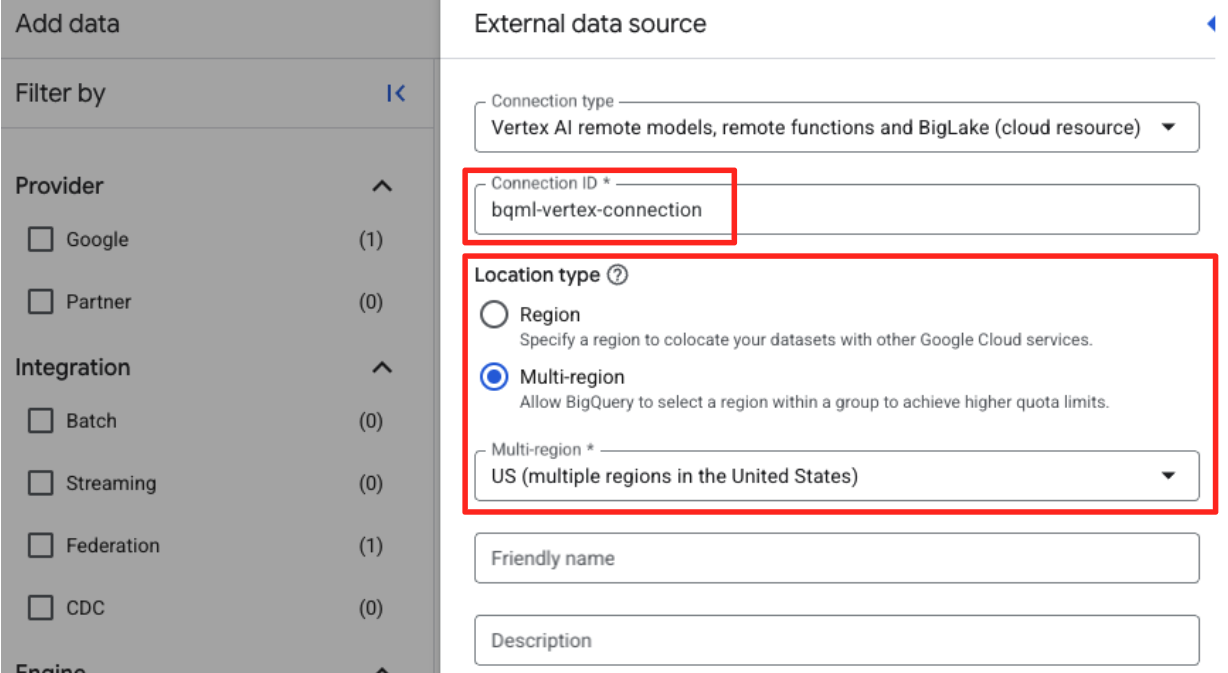
- 接続 ID: 接続 ID(例:
bqml-vertex-connection)を入力します。 - ロケーション タイプ: [マルチリージョン] が選択されていることを確認します。
- ロケーション: ロケーション(
USなど)を選択します。
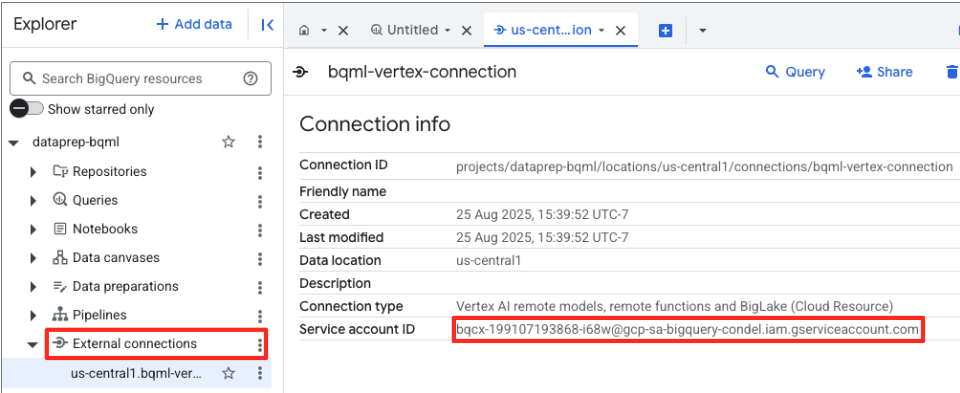
- 接続が作成されると、確認ダイアログが表示されます。[エクスプローラ] タブで [接続に移動] または [外部接続] をクリックします。接続の詳細ページで、完全な ID をクリップボードにコピーします。これは、BigQuery が Vertex AI の呼び出しに使用するサービス アカウント ID です。
- Google Cloud コンソールのナビゲーション メニューで、[IAM と管理] > [IAM] に移動します。
- [アクセス権を付与] ボタンをクリックします
- 前の手順でコピーしたサービス アカウントを [新しいプリンシパル] フィールドに貼り付けます。
- [ロール] プルダウンで [Vertex AI ユーザー] を割り当て、[保存] をクリックします。
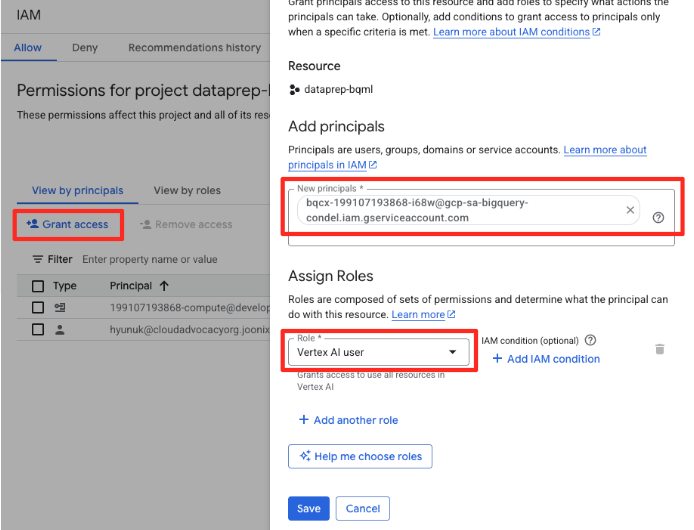
この重要な手順により、BigQuery がユーザーの代わりに Vertex AI モデルを使用するための適切な認可を取得します。
リモートモデルを作成する
BigQuery Studio で、新しい SQL エディタタブを開きます。ここで、Gemini に接続する BQML モデルを定義します。
このステートメントでは、新しいモデルはトレーニングされません。これは、承認した接続を使用して、強力な事前トレーニング済み gemini-embedding-001 モデルを指す参照を BigQuery に作成するだけです。
以下の SQL スクリプト全体をコピーして、BigQuery エディタに貼り付けます。
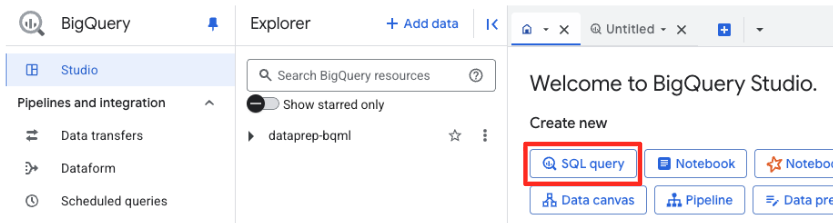
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
エンベディングを生成する
次に、BQML モデルを使用してベクトル エンベディングを生成します。各行のテキストラベルを単純に変換するのではなく、より高度なアプローチを使用して、各アートワークのよりリッチで意味のある「セマンティック サマリー」を作成します。これにより、エンベディングの品質が向上し、推奨事項の精度が高まります。
このクエリは、重要な前処理ステップを実行します。
- このクエリでは、最初に
WITH句を使用して一時テーブルを作成します。 - この中で、各
object_idをGROUP BYして、1 つのアートワークに関するすべての情報を 1 行にまとめます。 STRING_AGG関数を使用して、個別のテキスト説明(「肖像画」、「女性」、「油絵」など)をすべて 1 つの包括的なテキスト文字列に統合し、関連性スコアで並べ替えます。
この組み合わせたテキストにより、AI はアートワークに関するより豊富なコンテキストを取得し、よりニュアンスに富んだ強力なベクトル エンベディングを生成できます。
新しい SQL エディタタブで、次のクエリを貼り付けて実行します。
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
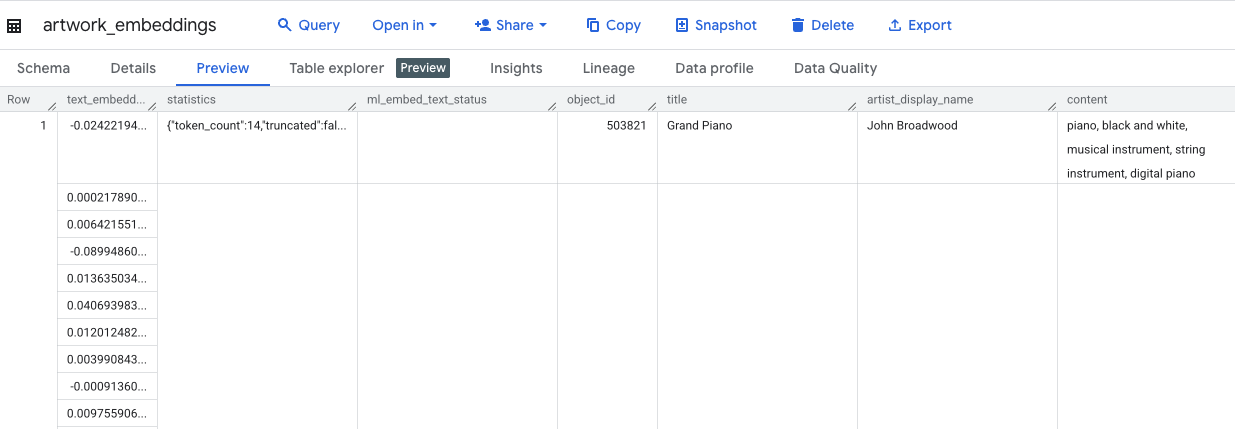
このクエリの所要時間は 10 分程度です。クエリが完了したら、結果を確認します。[エクスプローラ] パネルで、新しい artwork_embeddings テーブルを見つけてクリックします。テーブル スキーマ ビューアには、object_id、ベクトルを含む新しい ml_generate_text_embedding_result 列、ソーステキストとして使用された aggregated_labels 列が表示されます。
5. SQL を使用して類似するアートワークを見つける
高品質でコンテキストが豊富なベクトル エンベディングが作成されたら、テーマが類似したアートワークを見つけるのは、SQL クエリを実行するのと同じくらい簡単です。ML.DISTANCE 関数を使用して、ベクトル間のコサイン類似度を計算します。エンベディングは集計されたテキストから生成されるため、類似性スコアの精度と関連性が高くなります。
- 新しい SQL エディタタブに、次のクエリを貼り付けます。このクエリは、レコメンデーション アプリケーションのコアロジックをシミュレートします。
- まず、単一の特定の作品(この場合はゴッホの「糸杉」、
object_idは 436535)のベクトルを選択します。 - 次に、その単一のベクトルとテーブル内の他のすべてのベクトル間の距離を計算します。
- 最後に、距離(距離が短いほど類似性が高い)で結果を並べ替えて、最も近い上位 10 件の一致を検索します。
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- クエリを実行します。結果には
object_idが一覧表示され、最も一致するものが一番上に表示されます。ソース アートワークが最初に表示され、距離は 0 になります。これは AI レコメンデーション エンジンを強化するコアロジックであり、SQL のみを使用して BigQuery 内で完全に構築されています。
6. (省略可)Cloud Shell でデモを実行する
この Codelab のコンセプトを実際に体験できるように、クローンを作成したリポジトリにはシンプルなウェブ アプリケーションが含まれています。このオプションのデモでは、作成した artwork_embeddings テーブルを使用してビジュアル検索エンジンを強化し、AI を活用した推奨事項を実際に確認できます。
Cloud Shell でデモを実行するには、次の操作を行います。
- 環境変数を設定する: アプリケーションを実行する前に、PROJECT_ID 環境変数と BIGQUERY_DATASET 環境変数を設定する必要があります。
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- 依存関係をインストールしてバックエンド サーバーを起動します。
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- フロントエンド アプリケーションを実行するには、2 つ目のターミナルタブが必要です。[+] アイコンをクリックして、新しい Cloud Shell タブを開きます。

- 新しいタブで次のコマンドを実行して、依存関係をインストールし、フロントエンド サーバーを実行します。
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- アプリケーションをプレビューする: Cloud Shell ツールバーで、ウェブでプレビュー アイコンをクリックし、[ポート 5173 でプレビュー] を選択します。新しいブラウザタブが開き、アプリケーションが実行されます。アプリケーションを使用してアートワークを検索し、類似性検索の動作を確認できるようになりました。
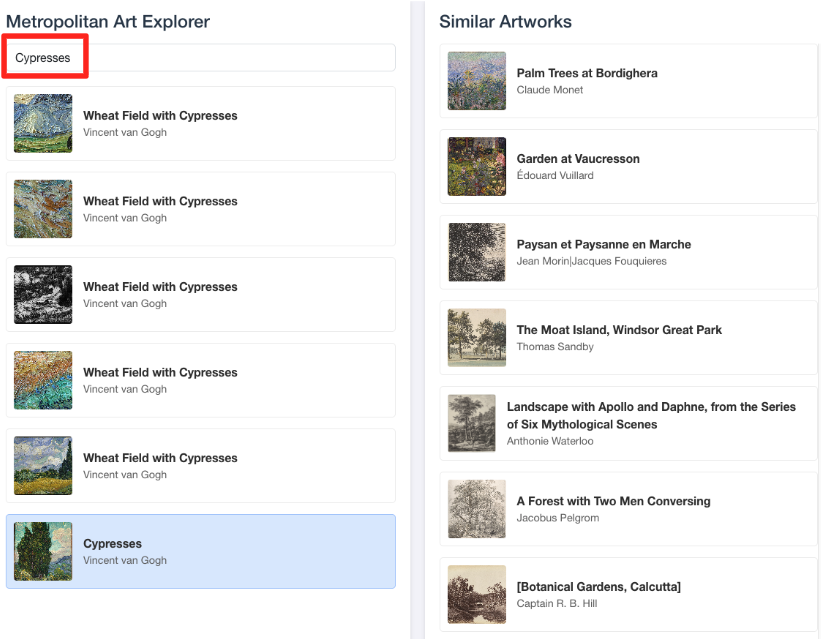
- このビジュアル デモを BigQuery SQL エディタで行った作業に接続するには、検索バーに「Cypresses」と入力してみてください。これは、
ML.DISTANCEクエリで使用したアートワーク(object_id=436535)と同じです。左側のパネルに [Cypresses] の画像が表示されたら、それをクリックします。右側に結果が表示されます。アプリケーションには、最も類似したアートワークが表示され、作成したベクトル類似性検索の威力が視覚的に示されます。
7. 環境をクリーンアップする
この Codelab で使用したリソースについて、Google Cloud アカウントに今後課金されないようにするには、作成したリソースを削除します。
Cloud Shell ターミナルで次のコマンドを実行して、サービス アカウント、BigQuery 接続、GCS バケット、BigQuery データセットを削除します。
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
BigQuery Connection と GCS バケットを削除する
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
BigQuery データセットの削除
最後に、BigQuery データセットを削除します。このコマンドは元に戻せません。-f(強制)フラグを指定すると、確認を求めるプロンプトが表示されずに、データセットとそのすべてのテーブルが削除されます。
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. 完了
これで、エンドツーエンドの AI 搭載データ パイプラインが正常に構築されました。
まず、GCS バケット内の未加工の CSV ファイルから始め、BigQuery Data Prep のローコード インターフェースを使用して複雑な JSON データを読み込んでフラット化し、強力な BQML リモートモデルを作成して Gemini モデルで高品質のベクトル エンベディングを生成し、類似性検索クエリを実行して関連アイテムを見つけました。
これで、Google Cloud で AI 支援ワークフローを構築し、未加工データをインテリジェントなアプリケーションに迅速かつ簡単に変換するための基本的なパターンを理解できました。
次のステップ
- Looker Studio で結果を可視化する:
artwork_embeddingsBigQuery テーブルを Looker Studio に直接接続します(無料)。ユーザーがアートワークを選択して、最も類似した作品のビジュアル ギャラリーを表示できるインタラクティブなダッシュボードを、フロントエンド コードを記述せずに構築できます。 - スケジュール設定されたクエリで自動化する: エンベディングを最新の状態に保つために、複雑なオーケストレーション ツールは必要ありません。BigQuery の組み込みのスケジュールされたクエリ機能を使用して、
ML.GENERATE_TEXT_EMBEDDINGクエリを毎日または毎週自動的に再実行します。 - Gemini CLI でアプリを生成する: Gemini CLI を使用して、要件をプレーン テキストで説明するだけで、完全なアプリケーションを生成できます。これにより、Python コードを手動で記述することなく、類似性検索の動作するプロトタイプをすばやく構築できます。
- ドキュメントを読む: