
1. 소개
데이터 분석가는 JSON 페이로드와 같은 반구조화된 형식으로 잠긴 유용한 데이터를 자주 접합니다. 분석 및 머신러닝을 위해 이 데이터를 추출하고 준비하는 것은 기존에 상당한 기술적 장애물이었으며, 복잡한 ETL 스크립트와 데이터 엔지니어링팀의 개입이 필요했습니다.
이 Codelab은 데이터 분석가가 이 문제를 독립적으로 해결할 수 있는 기술 청사진을 제공합니다. 엔드 투 엔드 AI 파이프라인을 빌드하는 '로우 코드' 접근 방식을 보여줍니다. BigQuery Studio 내에서 제공되는 도구만 사용하여 Google Cloud Storage의 원시 CSV 파일에서 AI 기반 추천 기능을 지원하는 방법을 알아봅니다.
기본 목표는 복잡하고 코드가 많은 프로세스를 넘어 데이터에서 실제 비즈니스 가치를 창출하는 강력하고 빠르며 분석가 친화적인 워크플로를 보여주는 것입니다.
기본 요건
- Google Cloud 콘솔에 관한 기본적인 이해
- 명령줄 인터페이스 및 Google Cloud Shell의 기본 기술
학습할 내용
- BigQuery 데이터 준비를 사용하여 Google Cloud Storage에서 직접 CSV 파일을 수집하고 변환하는 방법
- 데이터 내에서 중첩된 JSON 문자열을 파싱하고 평면화하기 위해 노코드 변환을 사용하는 방법
- 텍스트 임베딩을 위해 Vertex AI 기반 모델에 연결되는 BigQuery ML 원격 모델을 만드는 방법
ML.GENERATE_TEXT_EMBEDDING함수를 사용하여 텍스트 데이터를 숫자 벡터로 변환하는 방법ML.DISTANCE함수를 사용하여 코사인 유사성을 계산하고 데이터세트에서 가장 유사한 항목을 찾는 방법
필요한 항목
- Google Cloud 계정 및 Google Cloud 프로젝트
- 웹브라우저(예: Chrome)
주요 개념
- BigQuery 데이터 준비: BigQuery Studio 내의 도구로, 데이터 정리 및 준비를 위한 대화형 시각적 인터페이스를 제공합니다. 변환을 제안하고 사용자가 최소한의 코드로 데이터 파이프라인을 빌드할 수 있도록 지원합니다.
- BQML 원격 모델: Vertex AI (예: Gemini)에서 호스팅되는 모델의 프록시 역할을 하는 BigQuery ML 객체입니다. 이를 통해 익숙한 SQL 구문을 사용하여 강력한 사전 학습된 AI 모델을 호출할 수 있습니다.
- 벡터 임베딩: 텍스트나 이미지와 같은 데이터의 수치적 표현입니다. 이 Codelab에서는 작품의 텍스트 설명을 벡터로 변환합니다. 유사한 설명은 다차원 공간에서 서로 '가까운' 벡터를 생성합니다.
- 코사인 유사도: 두 벡터가 얼마나 유사한지 확인하는 데 사용되는 수학적 측정입니다.
ML.DISTANCE함수가 '가장 가까운' (가장 유사한) 작품을 찾는 데 사용되는 추천 엔진 로직의 핵심입니다.
2. 설정 및 요건
Cloud Shell 시작
Google Cloud를 노트북에서 원격으로 실행할 수 있지만, 이 Codelab에서는 Cloud에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용합니다.
Google Cloud Console의 오른쪽 상단 툴바에 있는 Cloud Shell 아이콘을 클릭합니다.

환경을 프로비저닝하고 연결하는 데 몇 분 정도 소요됩니다. 완료되면 다음과 같이 표시됩니다.

가상 머신에는 필요한 개발 도구가 모두 들어있습니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab의 모든 작업은 브라우저 내에서 수행할 수 있습니다. 아무것도 설치할 필요가 없습니다.
필요한 API 사용 설정 및 환경 구성
Cloud Shell에서 다음 명령어를 실행하여 프로젝트 ID를 설정하고, 환경 변수를 정의하고, 이 Codelab에 필요한 모든 API를 사용 설정합니다.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
BigQuery 데이터 세트 및 GCS 버킷 만들기
테이블을 저장할 새 BigQuery 데이터 세트와 소스 CSV 파일을 저장할 Google Cloud Storage 버킷을 만듭니다.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
샘플 데이터 준비 및 업로드
샘플 CSV 파일이 포함된 GitHub 저장소를 클론한 다음 방금 만든 GCS 버킷에 업로드합니다.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. 데이터 준비를 사용하여 GCS에서 BigQuery로
이 섹션에서는 시각적 노코드 인터페이스를 사용하여 GCS에서 CSV 파일을 수집하고, 정리하고, 새 BigQuery 테이블에 로드합니다.
데이터 준비 실행 및 소스에 연결
- Google Cloud 콘솔에서 BigQuery Studio로 이동합니다.
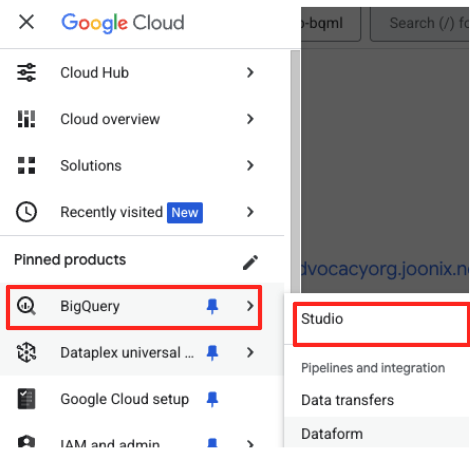
- 시작하려면 환영 페이지에서 데이터 준비 카드를 클릭합니다.
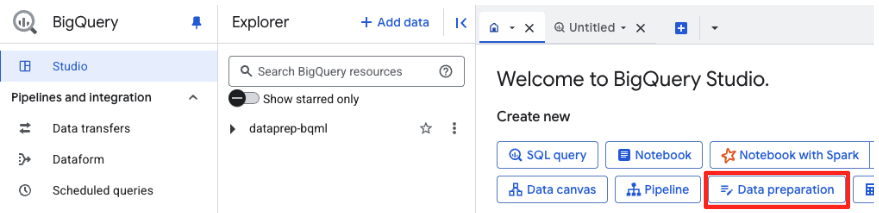
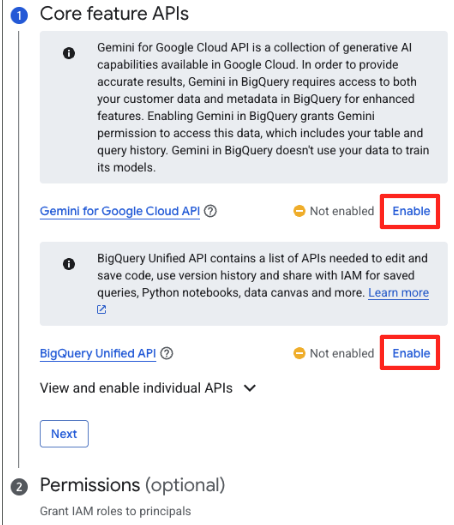
- 처음 사용하는 경우 필요한 API를 사용 설정해야 할 수 있습니다. 'Google Cloud를 위한 Gemini API'와 'BigQuery 통합 API' 모두에 대해 사용 설정을 클릭합니다. 사용 설정이 완료되면 이 패널을 닫아도 됩니다.
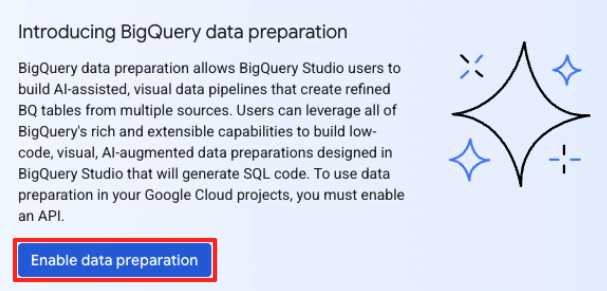
- 기본 데이터 준비 창의 '다른 데이터 소스 선택'에서 Google Cloud Storage를 클릭합니다. 그러면 오른쪽에 '데이터 준비' 패널이 열립니다.
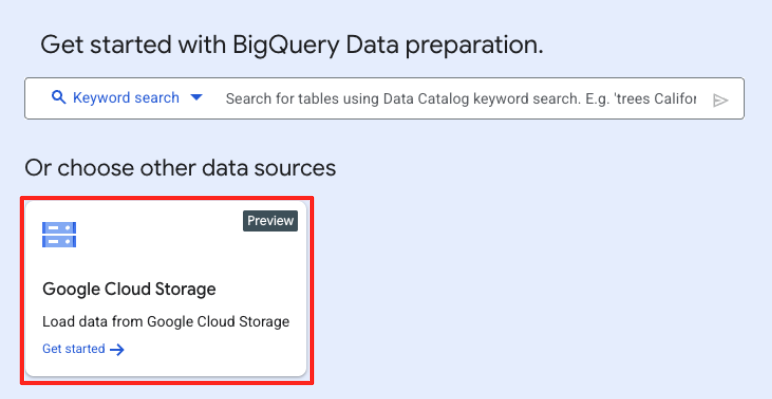
- '찾아보기' 버튼을 클릭하여 소스 파일을 선택합니다.
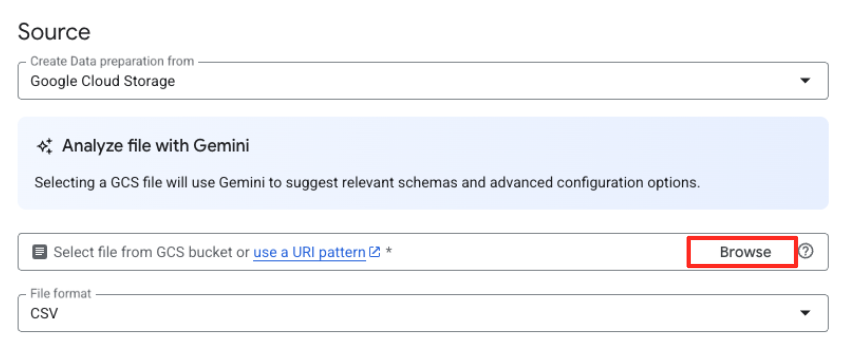
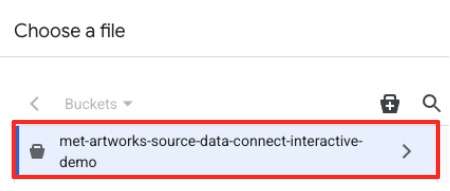
- 이전에 만든 GCS 버킷 (
met-artworks-source-...)으로 이동하여dataprep-met-bqml.csv파일을 선택합니다. 선택을 클릭합니다.
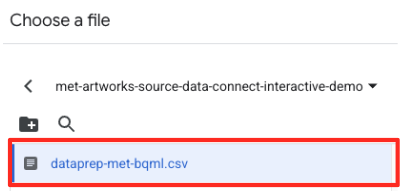
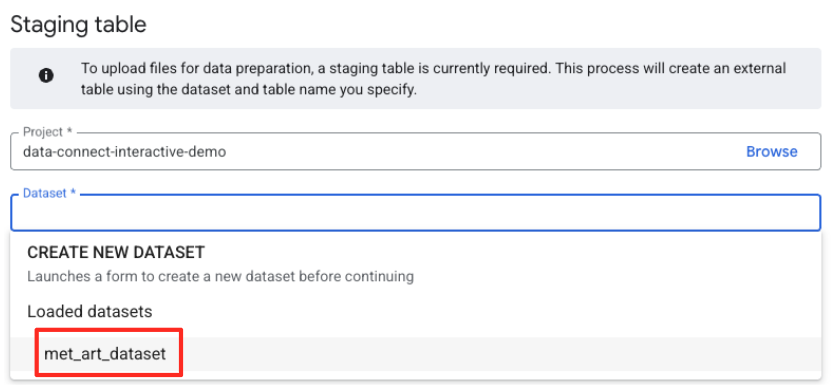
- 다음으로 스테이징 테이블을 구성해야 합니다.
- 데이터 세트에서 만든
met_art_dataset를 선택합니다. - 테이블 이름에
temp와 같은 이름을 입력합니다. - '만들기'를 클릭합니다.
데이터 변환 및 정리
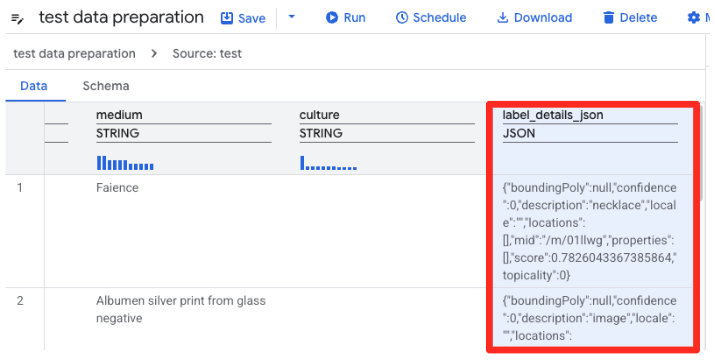
- 이제 BigQuery의 데이터 준비 기능에서 CSV의 미리보기를 로드합니다. 긴 JSON 문자열이 포함된
label_details_json열을 찾습니다. 열 헤더를 클릭하여 선택합니다.
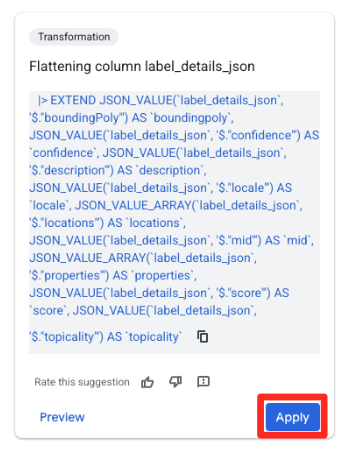
- 오른쪽의 추천 패널에서 BigQuery의 Gemini가 관련 변환을 자동으로 추천합니다. '열
label_details_json병합' 카드에서 적용 버튼을 클릭합니다. 그러면 중첩된 필드 (description,score등)가 자체 최상위 열로 추출됩니다.
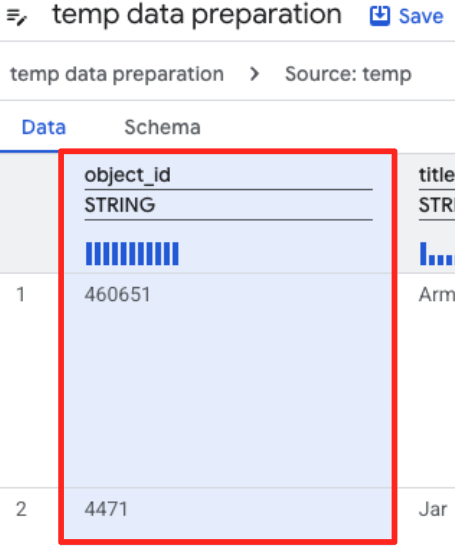
- object_id 열을 클릭하고 'Converts column
object_idfrom typestringtoint64.
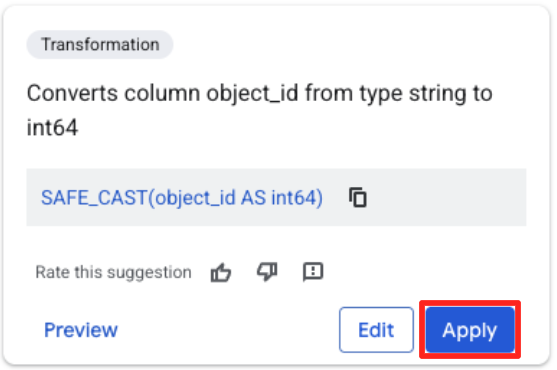
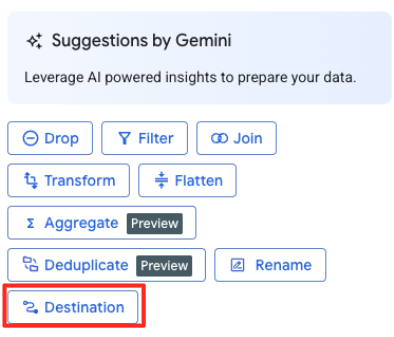
대상 정의 및 작업 실행
- 오른쪽 패널에서 대상 버튼을 클릭하여 변환의 출력을 구성합니다.
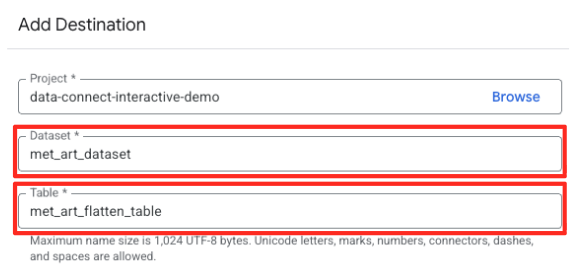
- 대상 세부정보를 설정합니다.
- 데이터 세트가
met_art_dataset로 미리 채워져 있어야 합니다. - 출력의 새 테이블 이름
met_art_flatten_table을 입력합니다. - 저장을 클릭합니다.
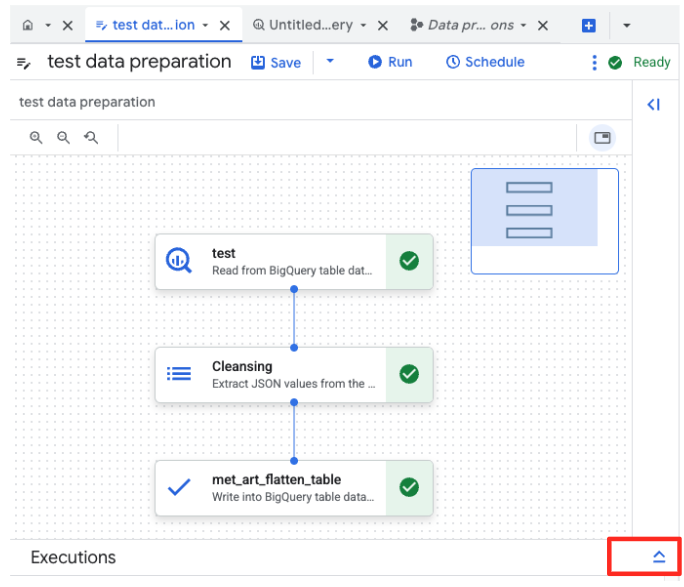
- 실행 버튼을 클릭하고 데이터 준비 작업이 완료될 때까지 기다립니다.
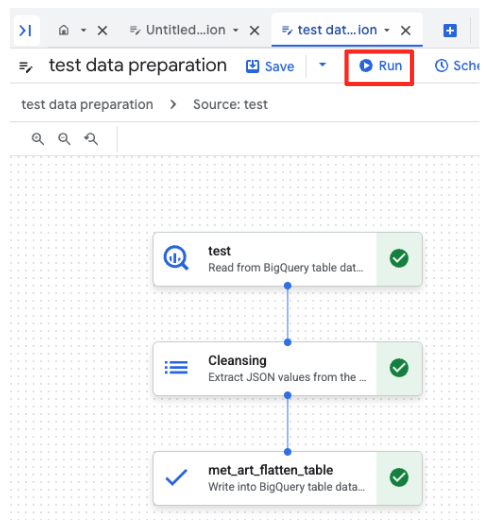
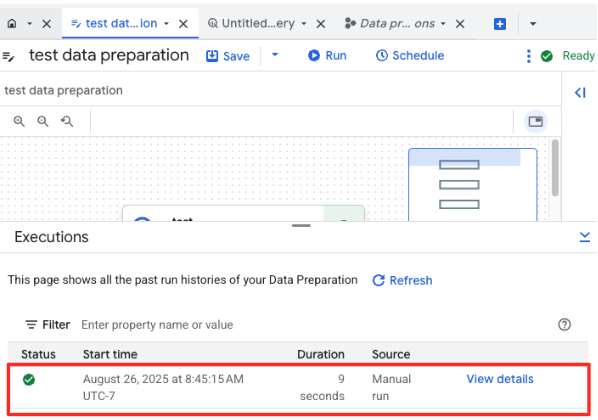
- 페이지 하단의 '실행' 탭에서 작업 진행 상황을 모니터링할 수 있습니다. 잠시 후 작업이 완료됩니다.
4. BQML로 벡터 임베딩 생성
이제 데이터가 정리되고 구조화되었으므로 BigQuery ML을 사용하여 핵심 AI 작업인 작품의 텍스트 설명을 숫자 벡터 삽입으로 변환합니다.
BigQuery 연결 만들기
BigQuery가 Vertex AI 서비스와 통신하도록 허용하려면 먼저 BigQuery 연결을 만들어야 합니다.
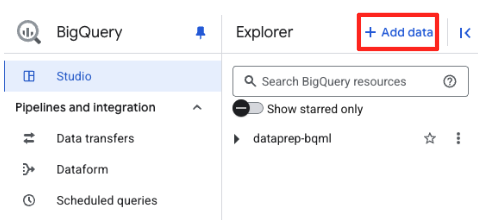
- BigQuery Studio의 탐색기 패널에서 '+ 데이터 추가' 버튼을 클릭합니다.
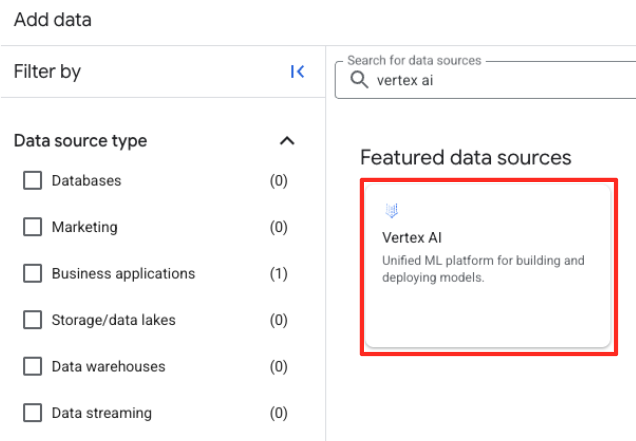
- 오른쪽 패널에서 검색창을 사용하여
Vertex AI을 입력합니다. 필터링된 목록에서 BigQuery 페더레이션을 선택합니다.
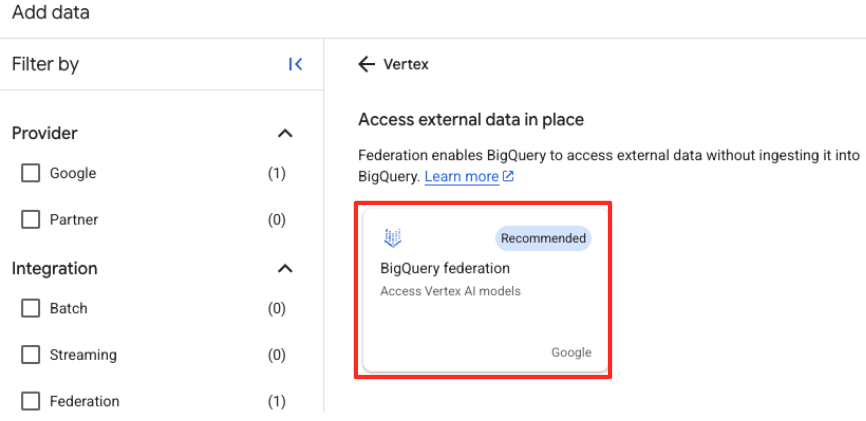
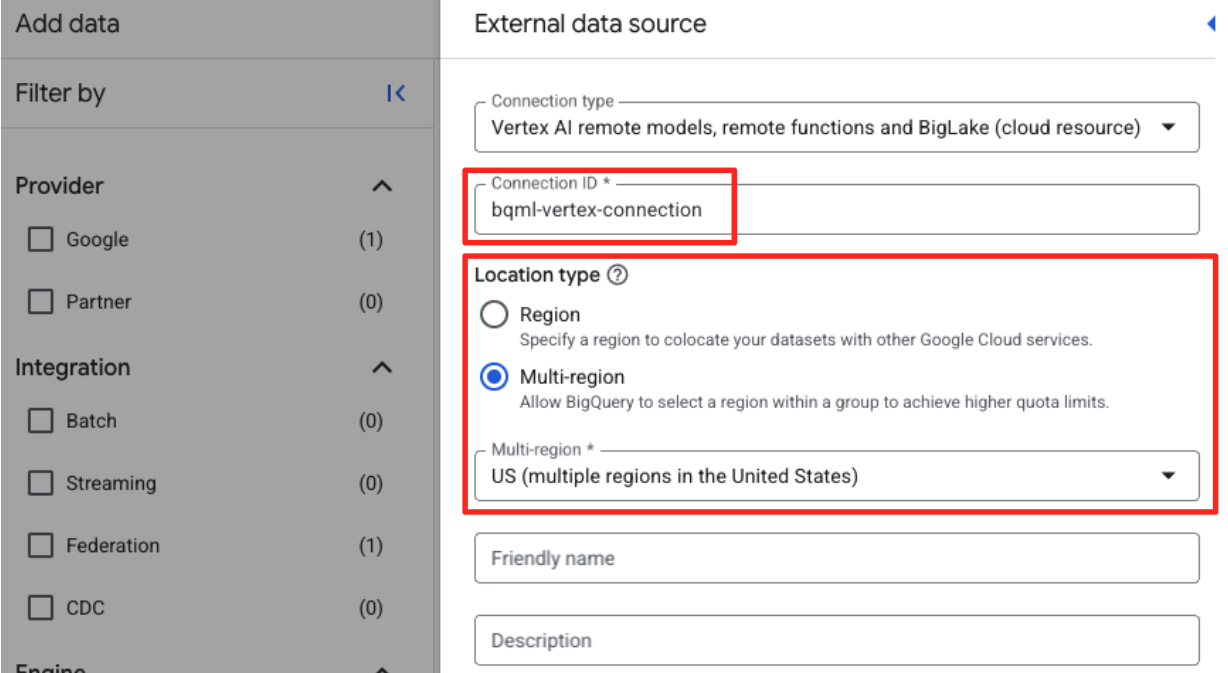
- 그러면 외부 데이터 소스 양식이 열립니다. 다음 세부정보를 입력합니다.
- 연결 ID: 연결 ID (예:
bqml-vertex-connection)를 입력합니다. - 위치 유형: 멀티 리전이 선택되어 있는지 확인합니다.
- 위치: 위치 (예:
US)를 선택합니다.
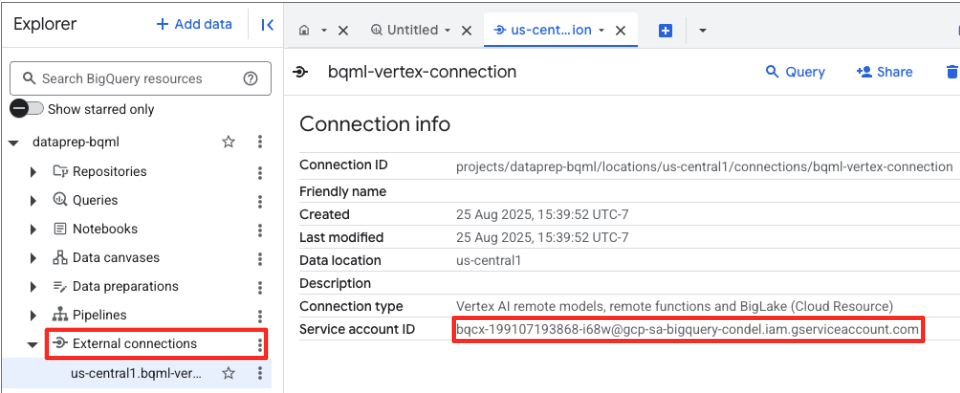
- 연결이 생성되면 확인 대화상자가 표시됩니다. 탐색기 탭에서 연결 또는 외부 연결로 이동을 클릭합니다. 연결 세부정보 페이지에서 전체 ID를 클립보드에 복사합니다. BigQuery가 Vertex AI를 호출하는 데 사용할 서비스 계정 ID입니다.
- Google Cloud 콘솔 탐색 메뉴에서 IAM 및 관리자 > IAM으로 이동합니다.
- '액세스 권한 부여' 버튼을 클릭합니다.
- 이전 단계에서 복사한 서비스 계정을 '새 주 구성원' 필드에 붙여넣습니다.
- 역할 드롭다운에서 'Vertex AI 사용자'를 할당하고 '저장'을 클릭합니다.
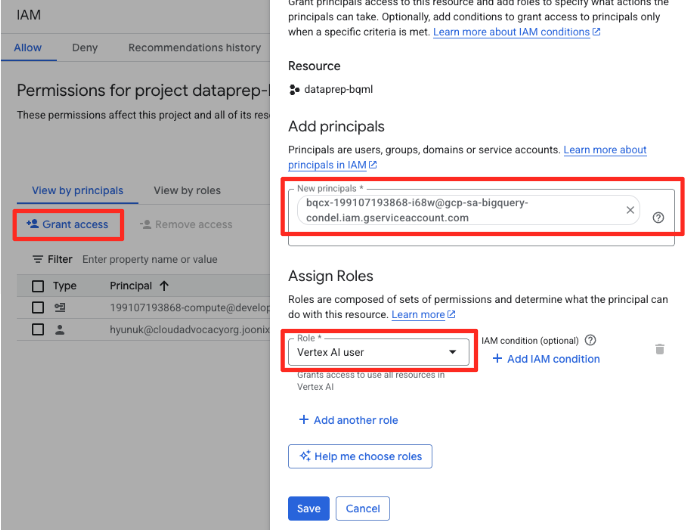
이 중요한 단계를 통해 BigQuery가 사용자를 대신하여 Vertex AI 모델을 사용할 수 있는 적절한 권한을 갖게 됩니다.
원격 모델 만들기
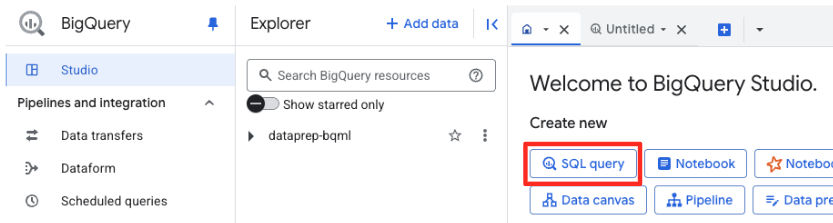
BigQuery Studio에서 새 SQL 편집기 탭을 엽니다. 여기에서 Gemini에 연결되는 BQML 모델을 정의합니다.
이 문은 새 모델을 학습시키지 않습니다. 방금 승인한 연결을 사용하여 강력한 사전 학습된 gemini-embedding-001 모델을 가리키는 참조를 BigQuery에 만듭니다.
아래 SQL 스크립트 전체를 복사하여 BigQuery 편집기에 붙여넣습니다.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
임베딩 생성
이제 BQML 모델을 사용하여 벡터 임베딩을 생성합니다. 각 행에 대해 하나의 텍스트 라벨을 변환하는 대신 더 정교한 접근 방식을 사용하여 각 작품에 대해 더 풍부하고 의미 있는 '의미론적 요약'을 만듭니다. 이렇게 하면 고품질의 삽입과 더 정확한 추천이 제공됩니다.
이 쿼리는 중요한 전처리 단계를 실행합니다.
WITH절을 사용하여 먼저 임시 테이블을 만듭니다.- 내부에서 각
object_id를GROUP BY하여 단일 작품에 관한 모든 정보를 하나의 행으로 결합합니다. - Google에서는
STRING_AGG함수를 사용하여 별도의 텍스트 설명 (예: '인물', '여성', '캔버스에 유화')을 관련성 점수에 따라 순서를 정하여 하나의 포괄적인 텍스트 문자열로 병합합니다.
이 결합된 텍스트는 AI에 작품에 관한 훨씬 풍부한 컨텍스트를 제공하여 더 미묘하고 강력한 벡터 임베딩을 생성합니다.
새 SQL 편집기 탭에서 다음 쿼리를 붙여넣고 실행합니다.
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
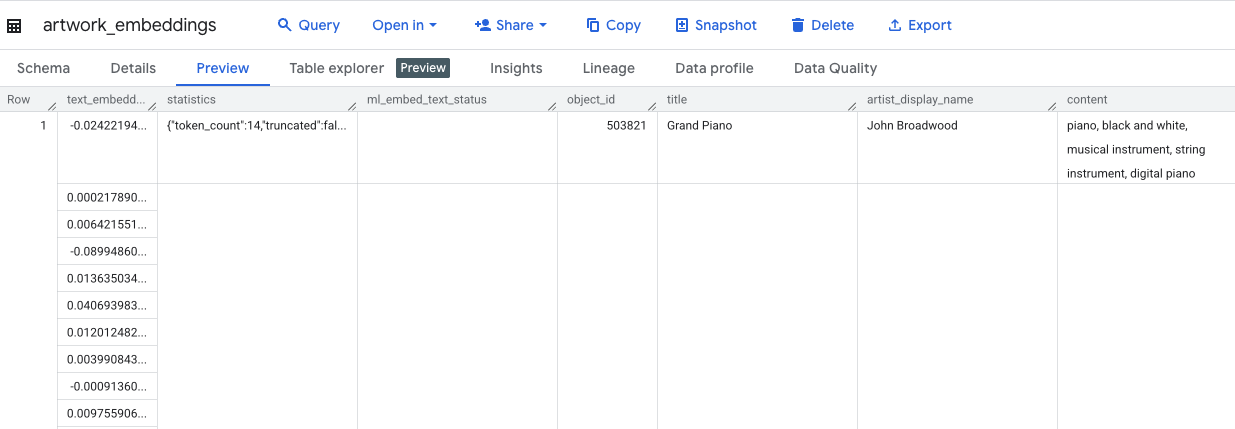
이 쿼리에는 약 10분이 소요됩니다. 쿼리가 완료되면 결과를 확인합니다. 탐색기 패널에서 새 artwork_embeddings 테이블을 찾아 클릭합니다. 표 스키마 뷰어에는 object_id, 벡터가 포함된 새 ml_generate_text_embedding_result 열, 소스 텍스트로 사용된 aggregated_labels 열이 표시됩니다.
5. SQL로 유사한 예술작품 찾기
고품질의 풍부한 컨텍스트 벡터 임베딩을 생성하면 SQL 쿼리를 실행하는 것만큼 간단하게 주제가 유사한 작품을 찾을 수 있습니다. ML.DISTANCE 함수를 사용하여 벡터 간의 코사인 유사성을 계산합니다. 임베딩이 집계된 텍스트에서 생성되었기 때문에 유사성 결과가 더 정확하고 관련성이 높습니다.
- 새 SQL 편집기 탭에 다음 쿼리를 붙여넣습니다. 이 쿼리는 추천 애플리케이션의 핵심 로직을 시뮬레이션합니다.
- 먼저 단일한 특정 작품 (이 경우
object_id가 436535인 반 고흐의 '사이프러스')의 벡터를 선택합니다. - 그런 다음 해당 단일 벡터와 표에 있는 다른 모든 벡터 간의 거리를 계산합니다.
- 마지막으로 거리 (거리가 짧을수록 유사성이 높음)를 기준으로 결과를 정렬하여 가장 근접한 상위 10개 일치 항목을 찾습니다.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- 쿼리를 실행합니다. 결과에는
object_id가 표시되며, 가장 일치하는 항목이 맨 위에 표시됩니다. 소스 아트는 거리가 0인 상태로 먼저 표시됩니다. 이는 AI 추천 엔진을 지원하는 핵심 로직이며, SQL만 사용하여 BigQuery 내에서 완전히 빌드했습니다.
6. (선택사항) Cloud Shell에서 데모 실행
이 Codelab의 개념을 구현하기 위해 클론한 저장소에는 간단한 웹 애플리케이션이 포함되어 있습니다. 이 선택사항 데모는 생성한 artwork_embeddings 테이블을 사용하여 시각적 검색 엔진을 지원하므로 AI 기반 추천을 직접 확인할 수 있습니다.
Cloud Shell에서 데모를 실행하려면 다음 단계를 따르세요.
- 환경 변수 설정: 애플리케이션을 실행하기 전에 PROJECT_ID 및 BIGQUERY_DATASET 환경 변수를 설정해야 합니다.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- 종속 항목을 설치하고 백엔드 서버를 시작합니다.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- 프런트엔드 애플리케이션을 실행하려면 두 번째 터미널 탭이 필요합니다. '+' 아이콘을 클릭하여 새 Cloud Shell 탭을 엽니다.

- 이제 새 탭에서 다음 명령어를 실행하여 종속 항목을 설치하고 프런트엔드 서버를 실행합니다.
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- 애플리케이션 미리보기: Cloud Shell 툴바에서 웹 미리보기 아이콘을 클릭하고 포트 5173에서 미리보기를 선택합니다. 그러면 애플리케이션이 실행되는 새 브라우저 탭이 열립니다. 이제 애플리케이션을 사용하여 작품을 검색하고 유사성 검색이 작동하는 것을 확인할 수 있습니다.
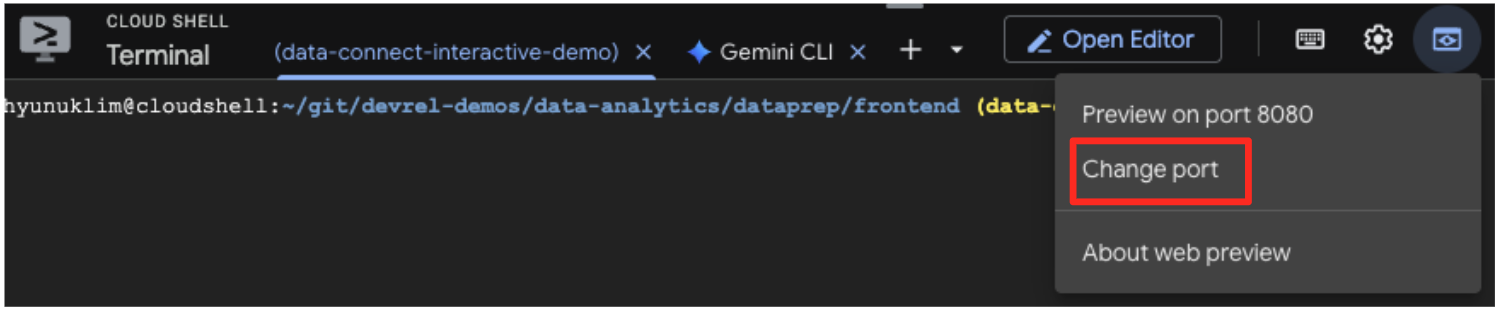
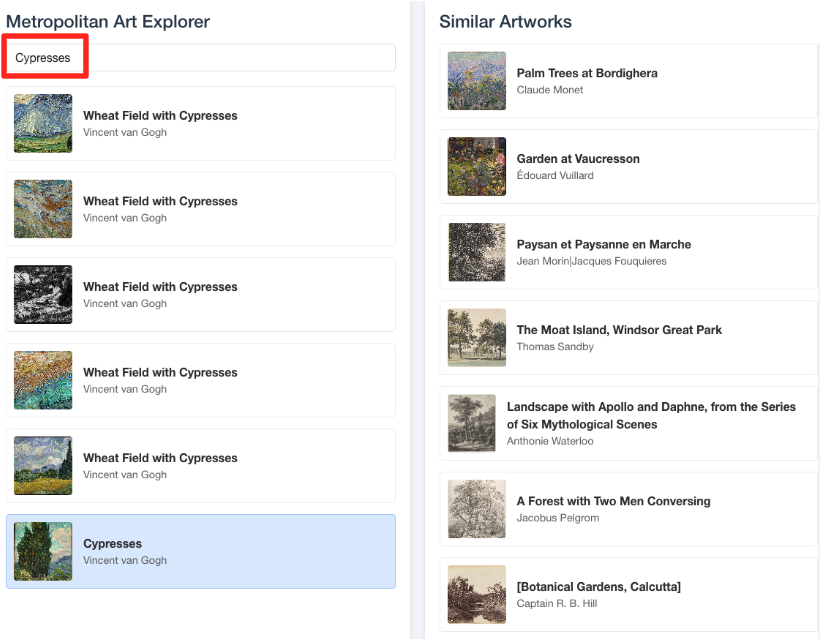
- 이 시각적 데모를 BigQuery SQL 편집기에서 수행한 작업에 다시 연결하려면 검색창에 'Cypresses'를 입력해 보세요.
ML.DISTANCE쿼리에서 사용한 것과 동일한 아트워크(object_id=436535)입니다. 그런 다음 왼쪽 패널에 사이프러스 이미지가 표시되면 클릭하면 오른쪽에 결과가 표시됩니다. 애플리케이션은 가장 유사한 작품을 표시하여 빌드한 벡터 유사성 검색의 기능을 시각적으로 보여줍니다.
7. 환경 정리
이 Codelab에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 만든 리소스를 삭제해야 합니다.
Cloud Shell 터미널에서 다음 명령어를 실행하여 서비스 계정, BigQuery 연결, GCS 버킷, BigQuery 데이터 세트를 삭제합니다.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
BigQuery 연결 및 GCS 버킷 삭제
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
BigQuery 데이터 세트 삭제
마지막으로 BigQuery 데이터 세트를 삭제합니다. 이 명령어는 되돌릴 수 없습니다. -f (강제) 플래그는 확인 메시지를 표시하지 않고 데이터 세트와 모든 테이블을 삭제합니다.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. 축하합니다.
엔드 투 엔드 AI 기반 데이터 파이프라인을 성공적으로 빌드했습니다.
GCS 버킷의 원시 CSV 파일로 시작하여 BigQuery 데이터 준비 도구의 로우 코드 인터페이스를 사용하여 복잡한 JSON 데이터를 수집하고 평면화하고, 강력한 BQML 원격 모델을 만들어 Gemini 모델로 고품질 벡터 임베딩을 생성하고, 유사성 검색 쿼리를 실행하여 관련 항목을 찾았습니다.
이제 Google Cloud에서 AI 지원 워크플로를 빌드하여 원시 데이터를 빠르고 간편하게 지능형 애플리케이션으로 변환하는 기본 패턴을 갖추게 되었습니다.
다음 단계
- Looker Studio에서 결과 시각화:
artwork_embeddingsBigQuery 테이블을 Looker Studio에 직접 연결합니다 (무료). 프런트엔드 코드를 작성하지 않고도 사용자가 작품을 선택하고 가장 유사한 작품의 시각적 갤러리를 볼 수 있는 대화형 대시보드를 빌드할 수 있습니다. - 예약된 쿼리로 자동화: 복잡한 오케스트레이션 도구가 없어도 임베딩을 최신 상태로 유지할 수 있습니다. BigQuery의 기본 제공 예약된 쿼리 기능을 사용하여
ML.GENERATE_TEXT_EMBEDDING쿼리를 매일 또는 매주 자동으로 다시 실행합니다. - Gemini CLI로 앱 생성: Gemini CLI를 사용하여 일반 텍스트로 요구사항을 설명하기만 하면 완전한 애플리케이션을 생성할 수 있습니다. 이를 통해 Python 코드를 수동으로 작성하지 않고도 유사성 검색을 위한 작동 가능한 프로토타입을 빠르게 빌드할 수 있습니다.
- 문서 읽기: