
1. Wprowadzenie
Analitycy danych często mają do czynienia z wartościowymi danymi zamkniętymi w półstrukturalnych formatach, takich jak ładunki JSON. Wydobywanie i przygotowywanie tych danych do analizy i uczenia maszynowego było dotychczas znacznym wyzwaniem technicznym, które wymagało złożonych skryptów ETL i interwencji zespołu inżynierów danych.
Te ćwiczenia zawierają techniczny plan działania, który pomoże analitykom danych samodzielnie rozwiązać ten problem. Pokazuje on podejście „low-code” do tworzenia kompleksowego potoku AI. Dowiesz się, jak przekształcić surowy plik CSV w Google Cloud Storage w funkcję rekomendacji opartą na AI, korzystając tylko z narzędzi dostępnych w BigQuery Studio.
Głównym celem jest zaprezentowanie solidnego, szybkiego i przyjaznego dla analityków przepływu pracy, który wykracza poza złożone procesy wymagające dużej ilości kodu i pozwala generować rzeczywistą wartość biznesową na podstawie danych.
Wymagania wstępne
- Podstawowa znajomość konsoli Google Cloud
- Podstawowe umiejętności w zakresie interfejsu wiersza poleceń i Google Cloud Shell
Czego się nauczysz
- Jak pozyskiwać i przekształcać plik CSV bezpośrednio z Google Cloud Storage za pomocą BigQuery Data Preparation.
- Jak za pomocą transformacji bez kodu analizować i spłaszczać zagnieżdżone ciągi JSON w danych.
- Jak utworzyć model zdalny BigQuery ML, który łączy się z modelem podstawowym Vertex AI na potrzeby wektorów dystrybucyjnych tekstu.
- Jak używać funkcji
ML.GENERATE_TEXT_EMBEDDINGdo przekształcania danych tekstowych w wektory liczbowe. - Jak używać funkcji
ML.DISTANCEdo obliczania podobieństwa cosinusowego i znajdowania najbardziej podobnych elementów w zbiorze danych.
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud
- przeglądarka, np. Chrome;
Kluczowe pojęcia
- Przygotowanie danych BigQuery: narzędzie w BigQuery Studio, które udostępnia interaktywny, wizualny interfejs do oczyszczania i przygotowywania danych. Sugeruje przekształcenia i umożliwia użytkownikom tworzenie potoków danych przy użyciu minimalnej ilości kodu.
- Model zdalny BQML: obiekt BigQuery ML, który działa jako serwer proxy modelu hostowanego w Vertex AI (np. Gemini). Umożliwia wywoływanie zaawansowanych, wstępnie wytrenowanych modeli AI przy użyciu znanej składni SQL.
- Wektor dystrybucyjny: numeryczna reprezentacja danych, np. tekstu lub obrazów. W tym laboratorium kodowania przekształcimy tekstowe opisy dzieł sztuki w wektory, w których podobne opisy będą skutkować wektorami „bliższymi” sobie w wielowymiarowej przestrzeni.
- Podobieństwo cosinusowe: miara matematyczna używana do określania podobieństwa 2 wektorów. Jest to podstawa logiki naszego systemu rekomendacji, używana przez funkcję
ML.DISTANCEdo znajdowania „najbliższych” (najbardziej podobnych) dzieł sztuki.
2. Konfiguracja i wymagania
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym module praktycznym będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:

Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
Włączanie wymaganych interfejsów API i konfigurowanie środowiska
W Cloud Shell uruchom te polecenia, aby ustawić identyfikator projektu, zdefiniować zmienne środowiskowe i włączyć wszystkie interfejsy API niezbędne do tego modułu.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
Utwórz zbiór danych BigQuery i zasobnik GCS
Utwórz nowy zbiór danych BigQuery, w którym będą przechowywane tabele, oraz zasobnik Cloud Storage, w którym będzie przechowywany źródłowy plik CSV.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
Przygotowywanie i przesyłanie przykładowych danych
Skopiuj repozytorium GitHub zawierające przykładowy plik CSV, a następnie prześlij go do utworzonego przed chwilą zasobnika GCS.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. Przenoszenie danych z GCS do BigQuery za pomocą przygotowania danych
W tej sekcji użyjemy wizualnego interfejsu bez kodu, aby pozyskać plik CSV z GCS, oczyścić go i wczytać do nowej tabeli BigQuery.
Uruchom przygotowywanie danych i połącz się ze źródłem
- W konsoli Google Cloud otwórz BigQuery Studio.
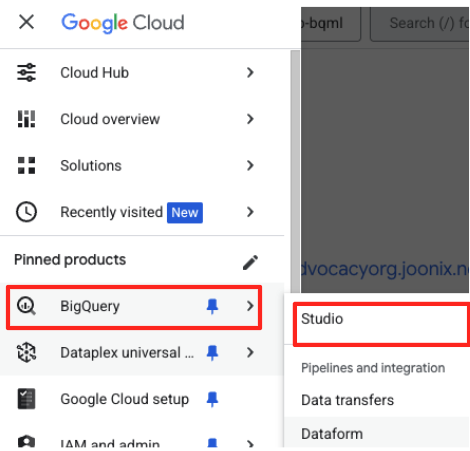
- Na stronie powitalnej kliknij kartę Przygotowanie danych, aby rozpocząć.
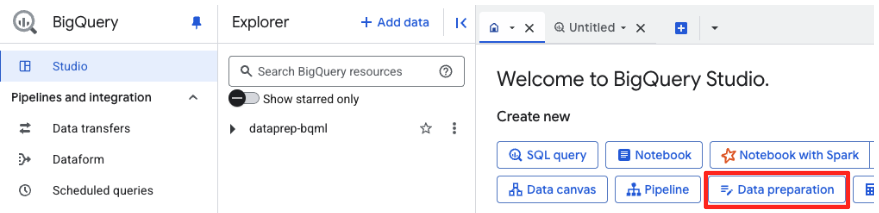
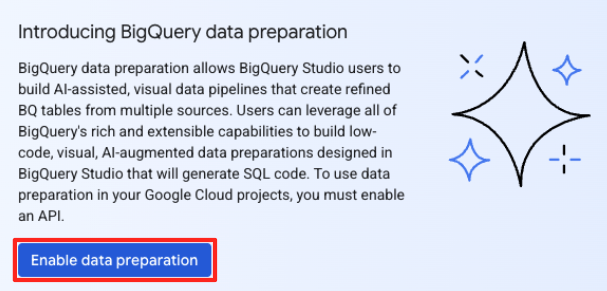
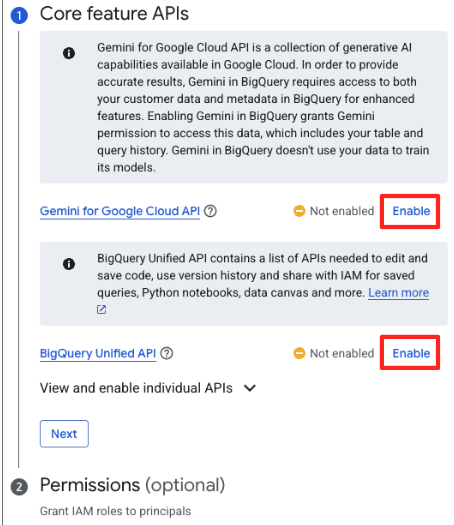
- Jeśli robisz to po raz pierwszy, może być konieczne włączenie wymaganych interfejsów API. Kliknij Włącz w przypadku interfejsów „Gemini for Google Cloud API” i „BigQuery Unified API”. Po włączeniu możesz zamknąć ten panel.
- W głównym oknie przygotowywania danych w sekcji „Wybierz inne źródła danych” kliknij Google Cloud Storage. Po prawej stronie otworzy się panel „Przygotuj dane”.
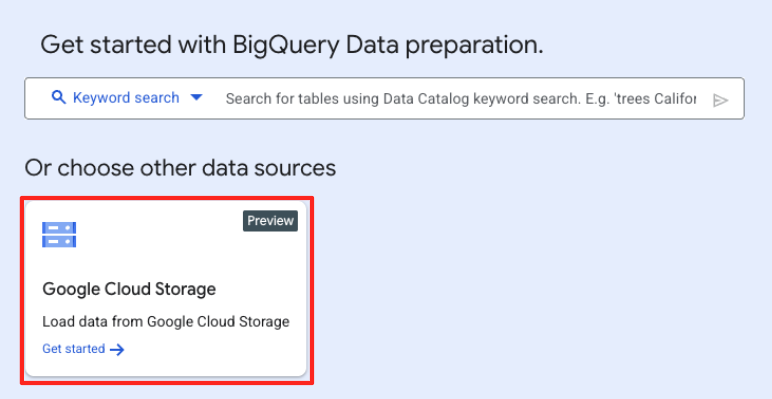
- Kliknij przycisk Przeglądaj, aby wybrać plik źródłowy.
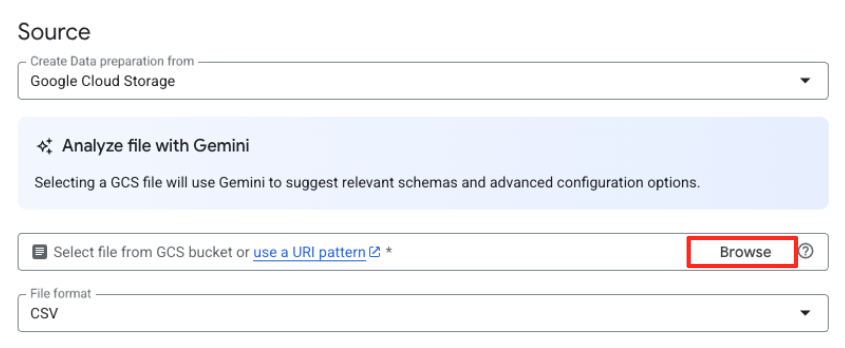
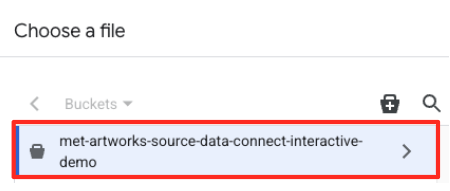
- Przejdź do utworzonego wcześniej zasobnika GCS (
met-artworks-source-...) i wybierz plikdataprep-met-bqml.csv. Kliknij Wybierz.
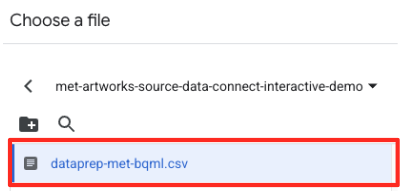
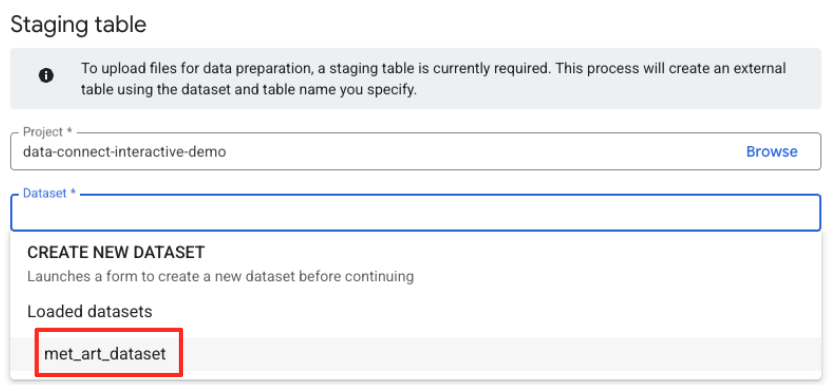
- Następnie musisz skonfigurować tabelę przejściową.
- W polu Zbiór danych wybierz utworzony przez siebie zbiór
met_art_dataset. - W polu Nazwa tabeli wpisz nazwę, np.
temp. - Kliknij Utwórz.
Przekształcanie i czyszczenie danych
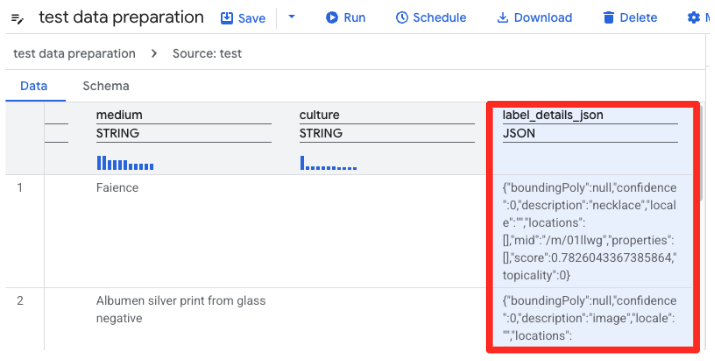
- Przygotowanie danych BigQuery wczyta teraz podgląd pliku CSV. Znajdź kolumnę
label_details_json, która zawiera długi ciąg znaków JSON. Kliknij nagłówek kolumny, aby ją zaznaczyć.
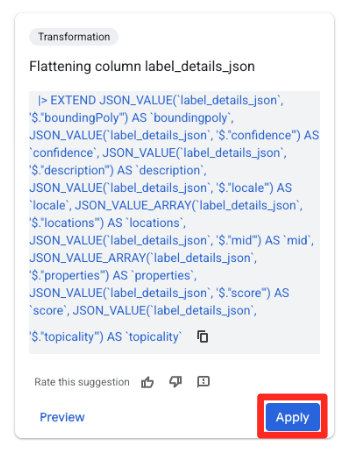
- W panelu Sugestie po prawej stronie Gemini in BigQuery automatycznie zaproponuje odpowiednie przekształcenia. Na karcie „Spłaszczanie kolumny
label_details_json” kliknij przycisk Zastosuj. Spowoduje to wyodrębnienie zagnieżdżonych pól (description,scoreitp.) do własnych kolumn najwyższego poziomu.
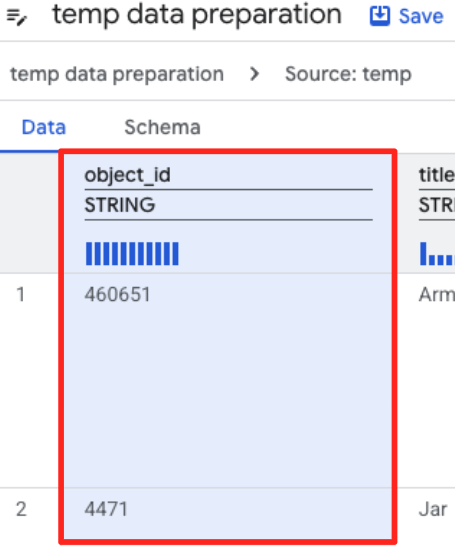
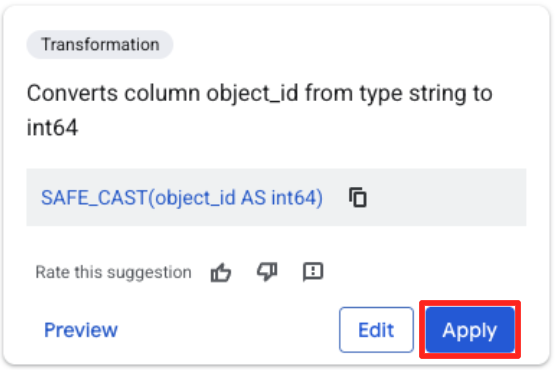
- Kliknij kolumnę object_id, a potem przycisk Zastosuj w sekcji „Konwertuje kolumnę
object_idz typustringnaint64”.
Określanie miejsca docelowego i uruchamianie zadania
- W panelu po prawej stronie kliknij przycisk Miejsce docelowe, aby skonfigurować dane wyjściowe przekształcenia.
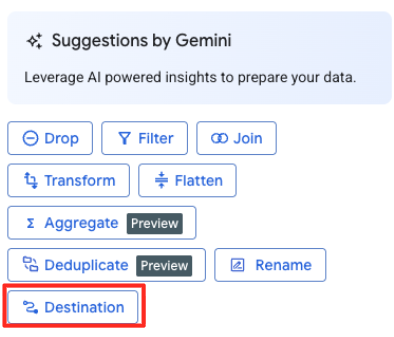
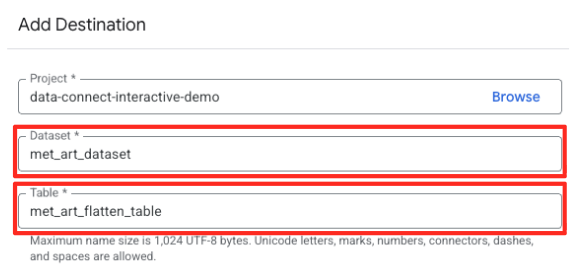
- Ustaw szczegóły miejsca docelowego:
- Zbiór danych powinien być wstępnie wypełniony wartością
met_art_dataset. - Wpisz nową nazwę tabeli wyjściowej:
met_art_flatten_table. - Kliknij Zapisz.
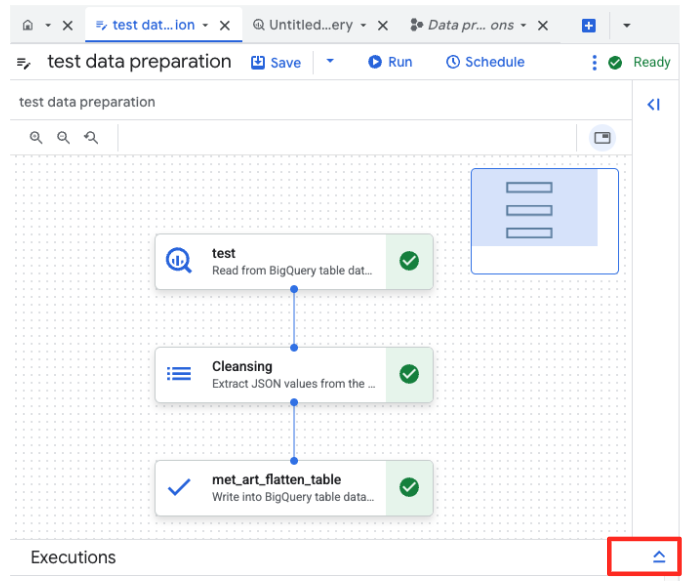
- Kliknij przycisk Uruchom i poczekaj, aż zadanie przygotowania danych się zakończy.
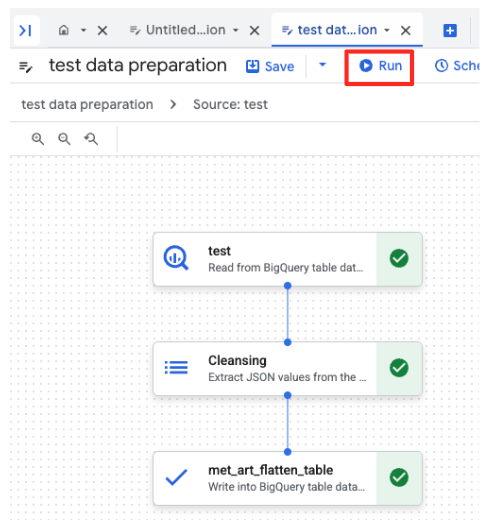
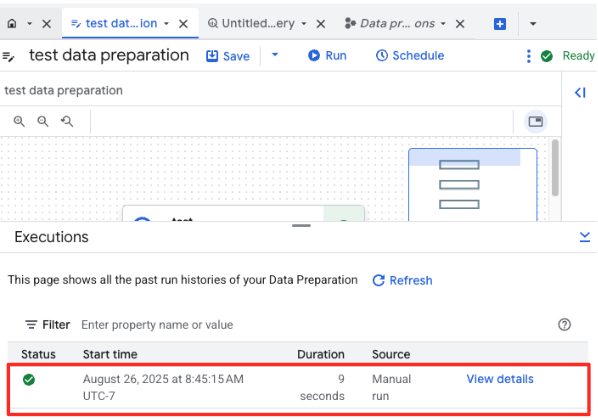
- Postęp zadania możesz śledzić na karcie Wykonania u dołu strony. Po chwili zadanie zostanie zakończone.
4. Generowanie wektorów dystrybucyjnych za pomocą BQML
Teraz, gdy nasze dane są oczyszczone i uporządkowane, użyjemy BigQuery ML do wykonania podstawowego zadania realizowanego z wykorzystaniem AI: przekształcenia tekstowych opisów dzieł sztuki w wektorowe osadzanie numeryczne.
Tworzenie połączenia z BigQuery
Aby umożliwić BigQuery komunikację z usługami Vertex AI, musisz najpierw utworzyć połączenie BigQuery.
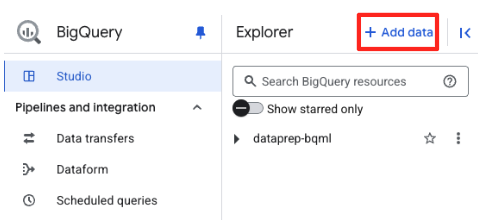
- W panelu Eksplorator w BigQuery Studio kliknij przycisk „+ Dodaj dane”.
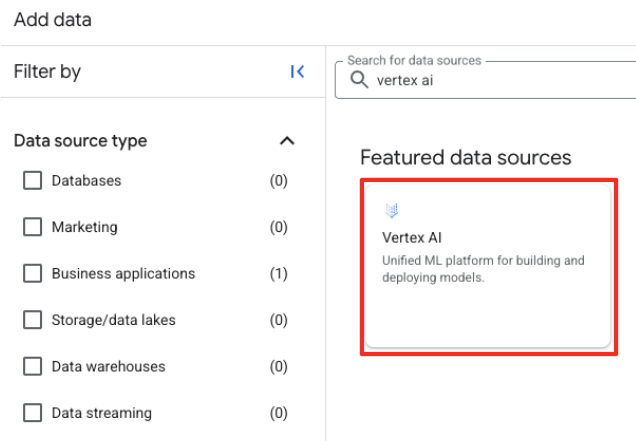
- W panelu po prawej stronie wpisz na pasku wyszukiwania
Vertex AI. Wybierz go, a potem z przefiltrowanej listy wybierz federację BigQuery.
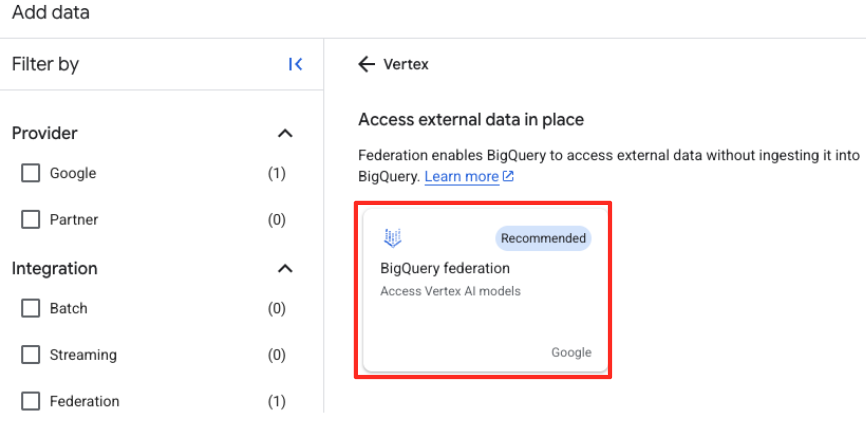
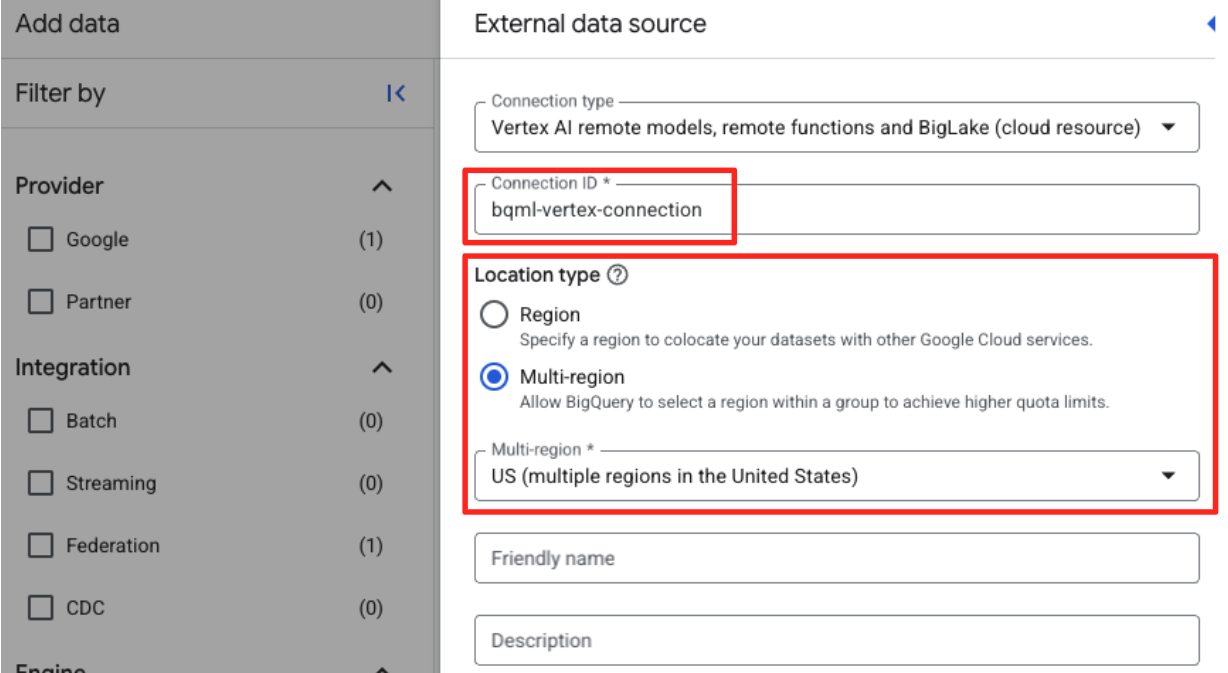
- Otworzy się formularz Zewnętrzne źródło danych. Podaj te informacje:
- Identyfikator połączenia: wpisz identyfikator połączenia (np.
bqml-vertex-connection). - Typ lokalizacji: upewnij się, że wybrano opcję Wiele regionów.
- Lokalizacja: wybierz lokalizację (np.
US).
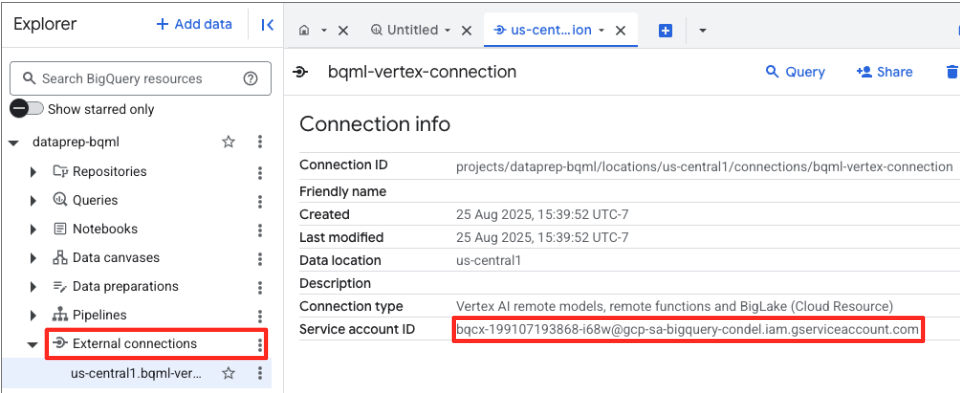
- Po utworzeniu połączenia pojawi się okno potwierdzenia. Na karcie Eksplorator kliknij Otwórz połączenie lub Połączenia zewnętrzne. Na stronie z informacjami o połączeniu skopiuj pełny identyfikator do schowka. Jest to tożsamość konta usługi, której BigQuery będzie używać do wywoływania Vertex AI.
- W menu nawigacyjnym konsoli Google Cloud kliknij Administracja > Uprawnienia.
- Kliknij przycisk „Przyznaj dostęp”.
- Wklej skopiowane w poprzednim kroku konto usługi w polu Nowe podmioty zabezpieczeń.
- W menu Rola przypisz rolę „Użytkownik Vertex AI” i kliknij „Zapisz”.
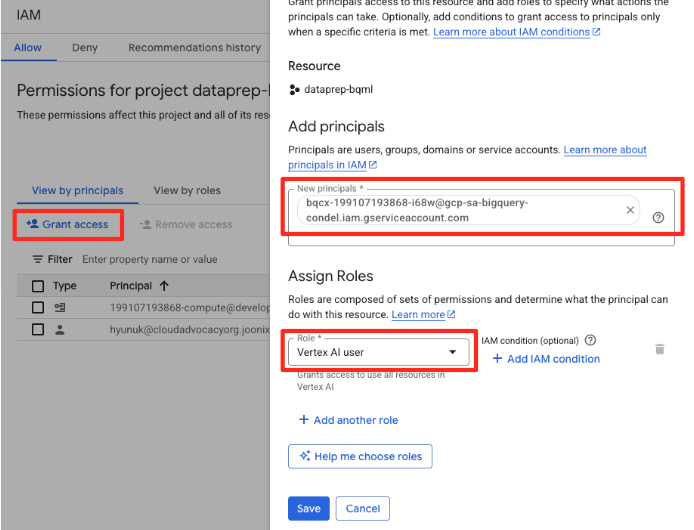
Ten ważny krok zapewnia BigQuery odpowiednią autoryzację do korzystania z modeli Vertex AI w Twoim imieniu.
Tworzenie modelu zdalnego
W BigQuery Studio otwórz nową kartę edytora SQL. W tym miejscu zdefiniujesz model BQML, który łączy się z Gemini.
Ta instrukcja nie trenuje nowego modelu. Po prostu tworzy odwołanie w BigQuery, które wskazuje zaawansowany, wstępnie wytrenowany model gemini-embedding-001, korzystając z połączenia, które właśnie zostało autoryzowane.
Skopiuj cały skrypt SQL poniżej i wklej go do edytora BigQuery.
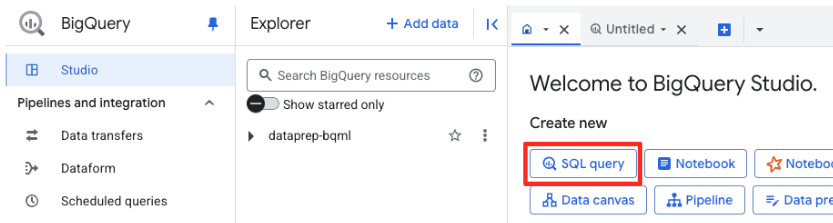
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
Generowanie wektorów dystrybucyjnych
Teraz użyjemy modelu BQML do wygenerowania wektorów dystrybucyjnych. Zamiast po prostu przekształcać pojedynczą etykietę tekstową w przypadku każdego wiersza, zastosujemy bardziej zaawansowane podejście, aby utworzyć bogatsze i bardziej znaczące „podsumowanie semantyczne” dla każdego dzieła sztuki. Dzięki temu uzyskasz osadzanie o wyższej jakości i trafniejsze rekomendacje.
To zapytanie wykonuje kluczowy krok przetwarzania wstępnego:
- Używa klauzuli
WITH, aby najpierw utworzyć tabelę tymczasową. - W tym celu
GROUP BYkażdyobject_id, aby połączyć wszystkie informacje o jednym dziele sztuki w jednym wierszu. - Używamy funkcji
STRING_AGG, aby połączyć wszystkie osobne opisy tekstowe (np. „Portret”, „Kobieta”, „Obraz olejny na płótnie”) w jeden kompleksowy ciąg tekstowy, porządkując je według wyniku trafności.
Ten połączony tekst zapewnia AI znacznie bogatszy kontekst dotyczący grafiki, co prowadzi do bardziej zniuansowanych i skutecznych osadzeń wektorowych.
Na nowej karcie edytora SQL wklej i uruchom to zapytanie:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
Wykonanie tego zapytania zajmie około 10 minut. Po zakończeniu zapytania sprawdź wyniki. W panelu Eksploratora znajdź nową tabelę artwork_embeddings i kliknij ją. W przeglądarce schematu tabeli zobaczysz ikonę object_id, nową kolumnę ml_generate_text_embedding_result zawierającą wektory oraz kolumnę aggregated_labels, która została użyta jako tekst źródłowy.
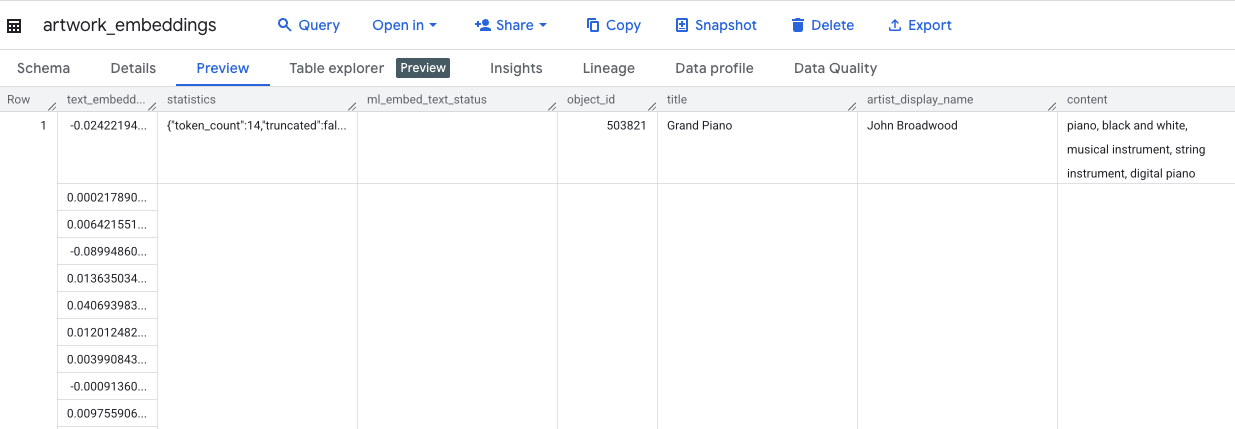
5. Wyszukiwanie podobnych dzieł sztuki za pomocą SQL
Po utworzeniu wysokiej jakości wektorów dystrybucyjnych z bogatym kontekstem znalezienie podobnych tematycznie dzieł sztuki jest tak proste, jak uruchomienie zapytania SQL. Do obliczania podobieństwa kosinusowego między wektorami używamy funkcji ML.DISTANCE. Ponieważ nasze osadzenia zostały wygenerowane na podstawie zagregowanego tekstu, wyniki podobieństwa będą dokładniejsze i trafniejsze.
- W nowej karcie edytora SQL wklej to zapytanie: To zapytanie symuluje podstawową logikę aplikacji rekomendacji:
- Najpierw wybiera wektor dla konkretnego dzieła sztuki (w tym przypadku „Cyprysy” Van Gogha, które mają
object_id436535). - Następnie oblicza odległość między tym pojedynczym wektorem a wszystkimi innymi wektorami w tabeli.
- Na koniec porządkuje wyniki według odległości (mniejsza odległość oznacza większe podobieństwo), aby znaleźć 10 najbliższych dopasowań.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- Uruchom zapytanie. Wyniki będą zawierać
object_id, a najbardziej zbliżone będą wyświetlane u góry. Najpierw pojawi się grafika źródłowa z odległością 0. Jest to podstawowa logika, która zasila silnik rekomendacji AI. Została ona w całości utworzona w BigQuery przy użyciu tylko SQL.
6. (OPCJONALNIE) Uruchamianie wersji demonstracyjnej w Cloud Shell
Aby zilustrować koncepcje przedstawione w tym module, sklonowane repozytorium zawiera prostą aplikację internetową. Ta opcjonalna wersja demonstracyjna wykorzystuje utworzoną przez Ciebie tabelę artwork_embeddings do zasilania wizualnej wyszukiwarki, dzięki czemu możesz zobaczyć w działaniu rekomendacje oparte na AI.
Aby uruchomić wersję demonstracyjną w Cloud Shell, wykonaj te czynności:
- Ustaw zmienne środowiskowe: przed uruchomieniem aplikacji musisz ustawić zmienne środowiskowe PROJECT_ID i BIGQUERY_DATASET.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- Zainstaluj zależności i uruchom serwer backendu.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- Aby uruchomić aplikację front-end, musisz otworzyć drugą kartę terminala. Kliknij ikonę „+”, aby otworzyć nową kartę Cloud Shell.

- Teraz na nowej karcie wykonaj to polecenie, aby zainstalować zależności i uruchomić serwer frontendu:
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- Wyświetl podgląd aplikacji: na pasku narzędzi Cloud Shell kliknij ikonę Podgląd w przeglądarce i wybierz Podgląd na porcie 5173. Otworzy się nowa karta przeglądarki z uruchomioną aplikacją. Teraz możesz używać aplikacji do wyszukiwania dzieł sztuki i sprawdzania działania wyszukiwania podobieństw.
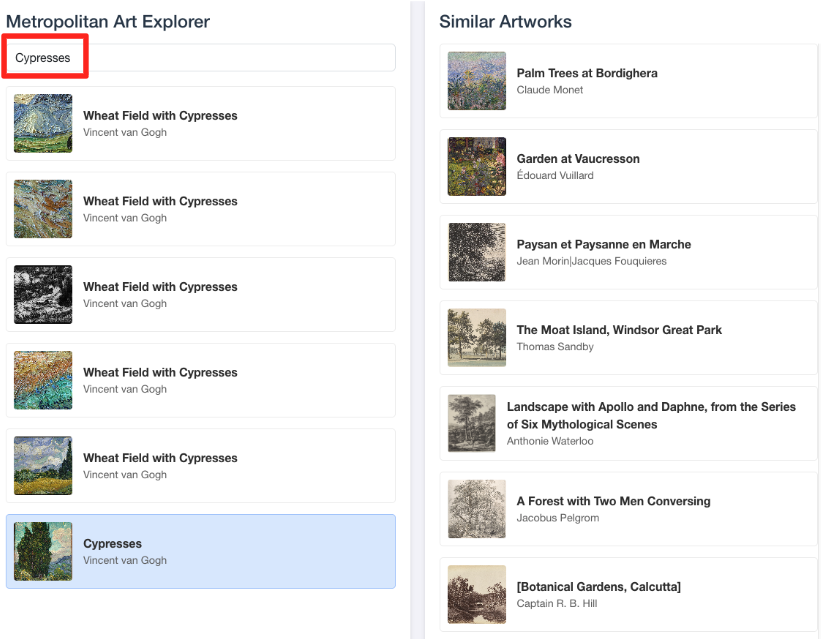
- Aby połączyć tę wizualną wersję demonstracyjną z pracą wykonaną w edytorze SQL BigQuery, wpisz „Cypresses” na pasku wyszukiwania. To to samo dzieło sztuki(
object_id=436535), którego użyto w zapytaniuML.DISTANCE. Następnie kliknij obraz Cyprysy, gdy pojawi się w panelu po lewej stronie. Wyniki zobaczysz po prawej stronie. Aplikacja wyświetla najbardziej podobne dzieła sztuki, wizualnie demonstrując możliwości utworzonego przez Ciebie wyszukiwania podobieństwa wektorowego.
7. Oczyszczanie środowiska
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby zużyte w tym ćwiczeniu, usuń utworzone zasoby.
Aby usunąć konto usługi, połączenie BigQuery, zasobnik GCS i zbiór danych BigQuery, uruchom w terminalu Cloud Shell te polecenia:
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
Usuwanie połączenia z BigQuery i zasobnika GCS
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
Usuwanie zbioru danych BigQuery
Na koniec usuń zbiór danych BigQuery. Tego polecenia nie można cofnąć. Flaga -f (force) usuwa zbiór danych i wszystkie jego tabele bez wyświetlania prośby o potwierdzenie.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. Gratulacje!
Udało Ci się utworzyć kompleksowy potok danych oparty na AI.
Zaczęliśmy od surowego pliku CSV w zasobniku GCS, użyliśmy interfejsu BigQuery Data Prep o niskim poziomie kodowania, aby wczytać i spłaszczyć złożone dane JSON, utworzyliśmy zaawansowany model zdalny BQML do generowania wysokiej jakości osadzeń wektorowych za pomocą modelu Gemini i wykonaliśmy zapytanie o wyszukiwanie podobieństw, aby znaleźć powiązane elementy.
Znasz już podstawowy wzorzec tworzenia w Google Cloud przepływów pracy wspomaganych przez AI, który umożliwia szybkie i proste przekształcanie nieprzetworzonych danych w inteligentne aplikacje.
Co dalej?
- Wizualizuj wyniki w Looker Studio: połącz tabelę
artwork_embeddingsBigQuery bezpośrednio z Looker Studio (jest to bezpłatne). Możesz utworzyć interaktywny panel, w którym użytkownicy mogą wybrać dzieło sztuki i zobaczyć wizualną galerię najbardziej podobnych prac bez pisania kodu interfejsu. - Automatyzacja za pomocą zaplanowanych zapytań: aby aktualizować osadzanie, nie potrzebujesz złożonego narzędzia do orkiestracji. Użyj wbudowanej funkcji zaplanowanych zapytań BigQuery, aby automatycznie ponownie uruchamiać zapytanie
ML.GENERATE_TEXT_EMBEDDINGcodziennie lub co tydzień. - Generowanie aplikacji za pomocą interfejsu wiersza poleceń Gemini: użyj interfejsu wiersza poleceń Gemini, aby wygenerować kompletną aplikację, opisując swoje wymagania w zwykłym tekście. Dzięki temu możesz szybko utworzyć działający prototyp wyszukiwania podobieństw bez ręcznego pisania kodu w Pythonie.
- Przeczytaj dokumentację: