
1. Introdução
Os analistas de dados geralmente precisam lidar com dados valiosos bloqueados em formatos semiestruturados, como payloads JSON. A extração e preparação desses dados para análise e machine learning sempre foram um obstáculo técnico significativo, exigindo scripts ETL complexos e a intervenção de uma equipe de engenharia de dados.
Este codelab oferece um projeto técnico para que os analistas de dados superem esse desafio de forma independente. Ele demonstra uma abordagem de "pouco código" para criar um pipeline de IA completo. Você vai aprender a transformar um arquivo CSV bruto no Google Cloud Storage em um recurso de recomendação com tecnologia de IA usando apenas as ferramentas disponíveis no BigQuery Studio.
O objetivo principal é demonstrar um fluxo de trabalho robusto, rápido e fácil de usar para analistas que vai além de processos complexos e pesados em código para gerar valor comercial real com seus dados.
Pré-requisitos
- Conhecimentos básicos sobre o console do Google Cloud
- Habilidades básicas na interface de linha de comando e no Google Cloud Shell
O que você vai aprender
- Como ingerir e transformar um arquivo CSV diretamente do Google Cloud Storage usando a preparação de dados do BigQuery.
- Como usar transformações sem código para analisar e simplificar strings JSON aninhadas nos seus dados.
- Como criar um modelo remoto do BigQuery ML que se conecta a um modelo de fundação da Vertex AI para embedding de texto.
- Como usar a função
ML.GENERATE_TEXT_EMBEDDINGpara converter dados textuais em vetores numéricos. - Como usar a função
ML.DISTANCEpara calcular a similaridade de cossenos e encontrar os itens mais parecidos no seu conjunto de dados.
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome
Conceitos principais
- Preparo de dados do BigQuery:uma ferramenta do BigQuery Studio que oferece uma interface interativa e visual para limpeza e preparo de dados. Ele sugere transformações e permite que os usuários criem pipelines de dados com o mínimo de código.
- Modelo remoto do BQML:um objeto do BigQuery ML que atua como um proxy de um modelo hospedado na Vertex AI (como o Gemini). Ele permite invocar modelos de IA pré-treinados e avançados usando a sintaxe familiar do SQL.
- Embedding de vetor:uma representação numérica de dados, como texto ou imagens. Neste codelab, vamos converter descrições de texto de obras de arte em vetores, em que descrições semelhantes resultam em vetores "mais próximos" em um espaço multidimensional.
- Similaridade de cosseno:uma medida matemática usada para determinar a semelhança entre dois vetores. É o núcleo da lógica do nosso mecanismo de recomendação, usado pela função
ML.DISTANCEpara encontrar as obras de arte "mais próximas" (mais semelhantes).
2. Configuração e requisitos
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:

O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
Ativar as APIs necessárias e configurar o ambiente
No Cloud Shell, execute os comandos a seguir para definir o ID do projeto, definir variáveis de ambiente e ativar todas as APIs necessárias para este codelab.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
Criar um conjunto de dados do BigQuery e um bucket do GCS
Crie um conjunto de dados do BigQuery para armazenar as tabelas e um bucket do Cloud Storage para armazenar o arquivo CSV de origem.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
Preparar e fazer upload dos dados de amostra
Clone o repositório do GitHub que contém o arquivo CSV de amostra e faça upload dele para o bucket do GCS que você acabou de criar.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. Do GCS para o BigQuery com a preparação de dados
Nesta seção, vamos usar uma interface visual sem código para ingerir, limpar e carregar nosso arquivo CSV do GCS em uma nova tabela do BigQuery.
Iniciar a preparação de dados e se conectar à fonte
- No console do Google Cloud, acesse o BigQuery Studio.
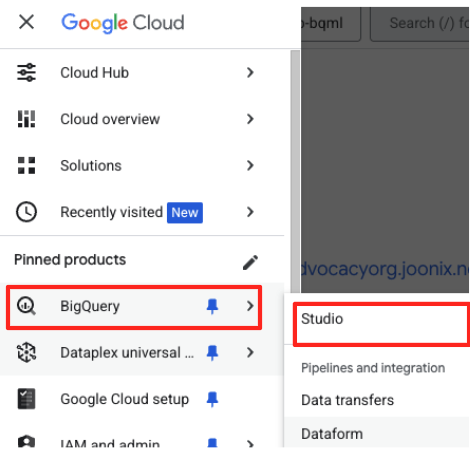
- Na página de boas-vindas, clique no card "Preparação de dados" para começar.
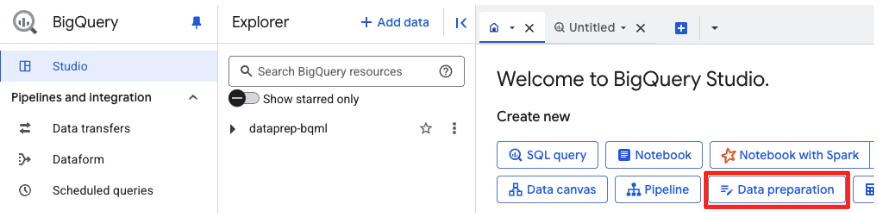
- Se esta for sua primeira vez, talvez seja necessário ativar as APIs necessárias. Clique em "Ativar" para a API Gemini para Google Cloud e a API BigQuery Unified. Depois de ativados, você pode fechar este painel.
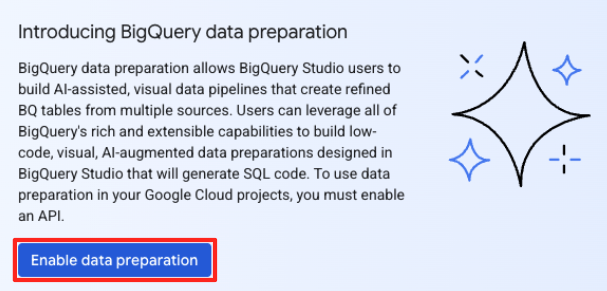
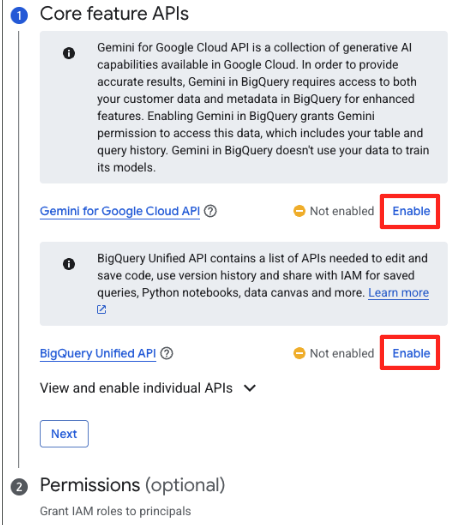
- Na janela principal de preparação de dados, em "Escolher outras fontes de dados", clique em Google Cloud Storage. Isso vai abrir o painel "Preparar dados" à direita.
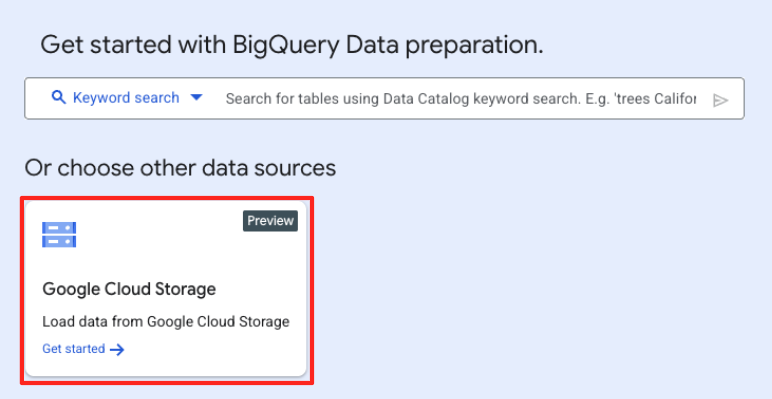
- Clique no botão "Procurar" para selecionar o arquivo de origem.
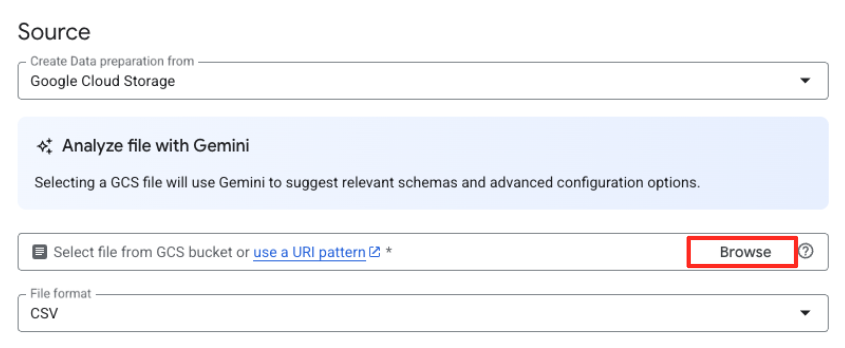
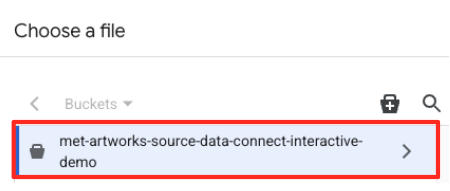
- Navegue até o bucket do GCS que você criou antes (
met-artworks-source-...) e selecione o arquivodataprep-met-bqml.csv. Clique em "Selecionar".
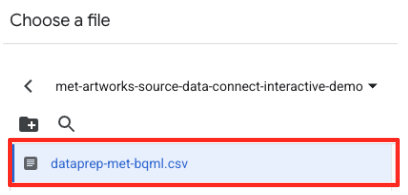
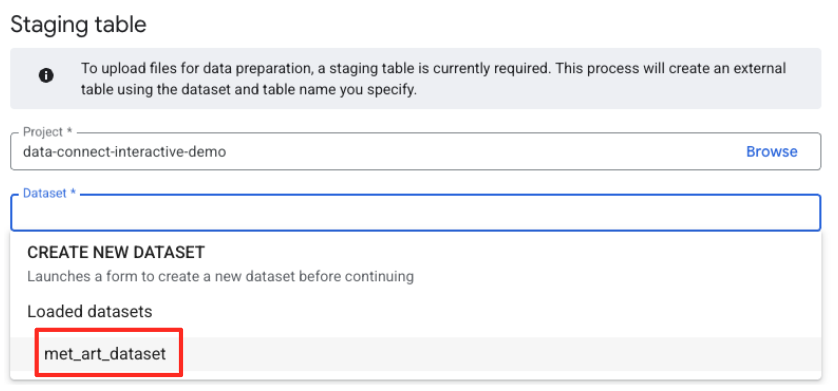
- Em seguida, configure uma tabela de staging.
- Em "Conjunto de dados", selecione o
met_art_datasetque você criou. - Em "Nome da tabela", insira um nome, por exemplo,
temp. - Clique em "Criar".
Transformar e limpar os dados
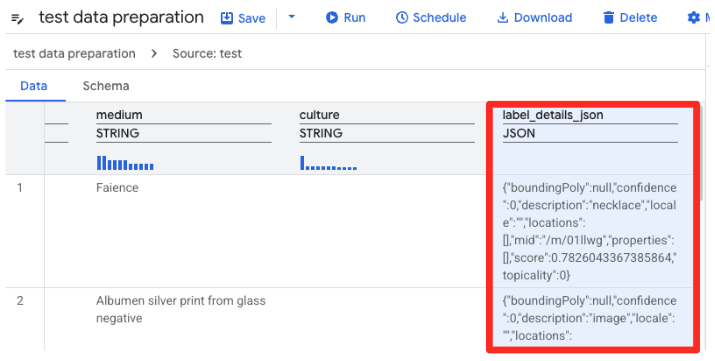
- A preparação de dados do BigQuery vai carregar uma prévia do CSV. Encontre a coluna
label_details_json, que contém a string JSON longa. Clique no cabeçalho da coluna para selecioná-la.
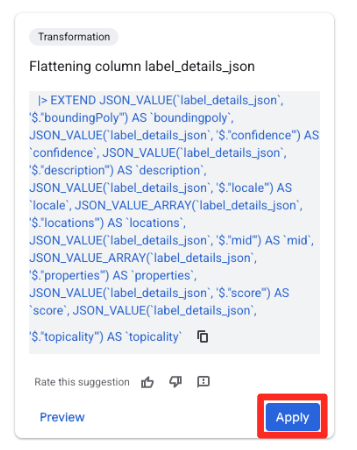
- No painel Sugestões à direita, o Gemini no BigQuery sugere automaticamente transformações relevantes. Clique no botão "Aplicar" no card "Coluna de redução
label_details_json". Isso extrai os campos aninhados (description,scoreetc.) para as próprias colunas de nível superior.
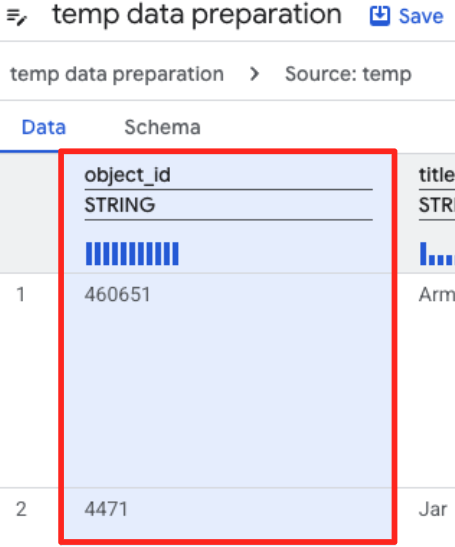
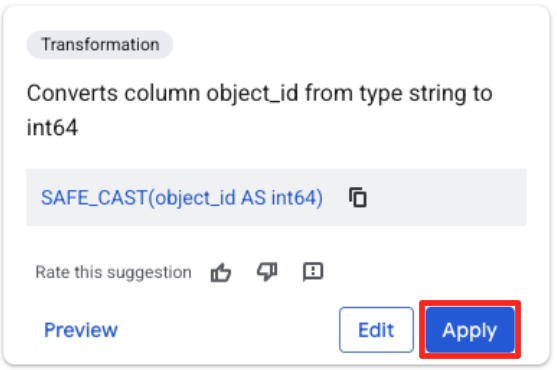
- Clique na coluna "object_id" e no botão "Aplicar" em "Converte a coluna
object_iddo tipostringparaint64".
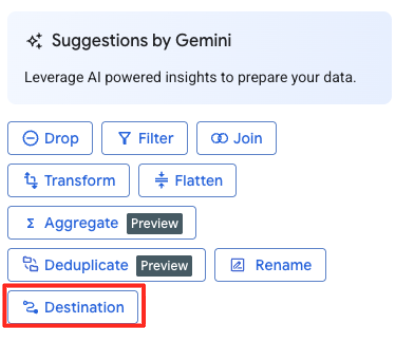
Definir o destino e executar o job
- No painel à direita, clique no botão "Destino" para configurar a saída da transformação.
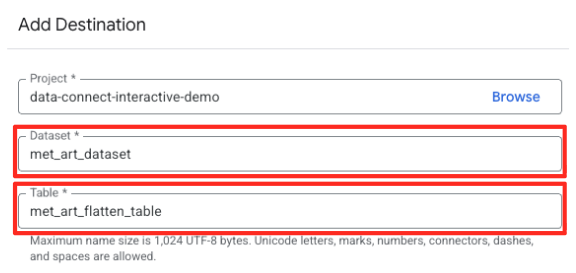
- Defina os detalhes do destino:
- O conjunto de dados precisa ser preenchido previamente com
met_art_dataset. - Insira um novo nome de tabela para a saída:
met_art_flatten_table. - Clique em "Salvar".
- Clique no botão "Executar" e aguarde a conclusão do job de preparação de dados.
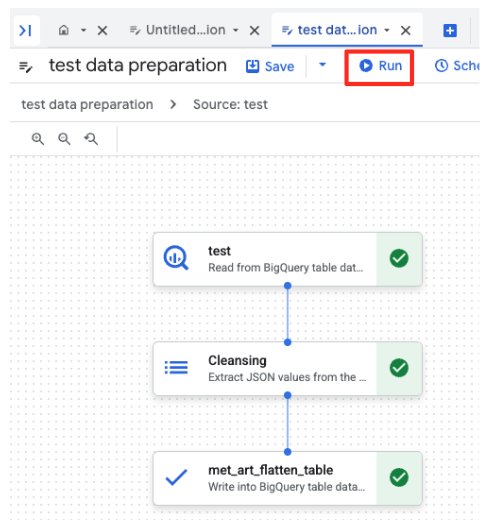
- É possível monitorar o progresso do job na guia "Execuções", na parte de baixo da página. Depois de alguns instantes, o job será concluído.
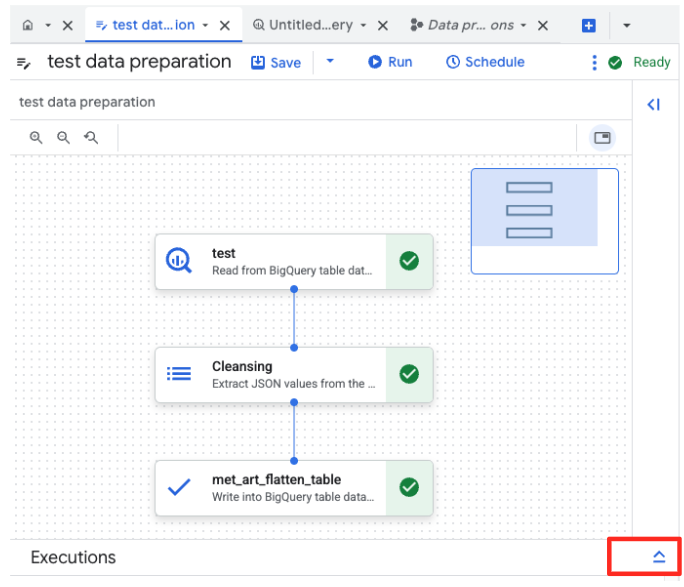
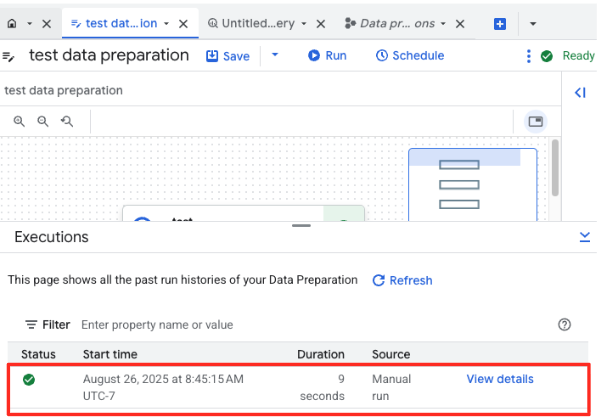
4. Gerar embeddings de vetor com o BQML
Agora que nossos dados estão limpos e estruturados, vamos usar o BigQuery ML para a principal tarefa de IA: converter as descrições textuais das obras de arte em embeddings de vetores numéricos.
Criar uma conexão do BigQuery
Para permitir que o BigQuery se comunique com os serviços da Vertex AI, primeiro crie uma conexão do BigQuery.
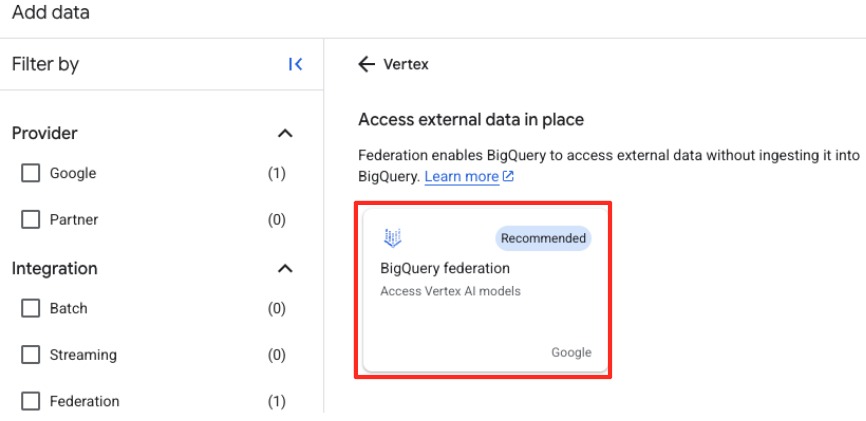
- No painel "Explorador" do BigQuery Studio, clique no botão "+ Adicionar dados".
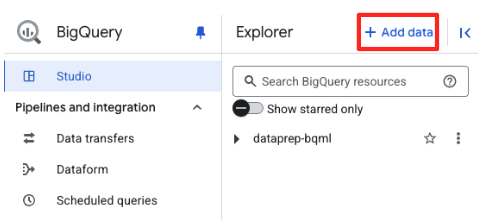
- No painel à direita, use a barra de pesquisa para digitar
Vertex AI. Selecione e clique em "Federação do BigQuery" na lista filtrada.
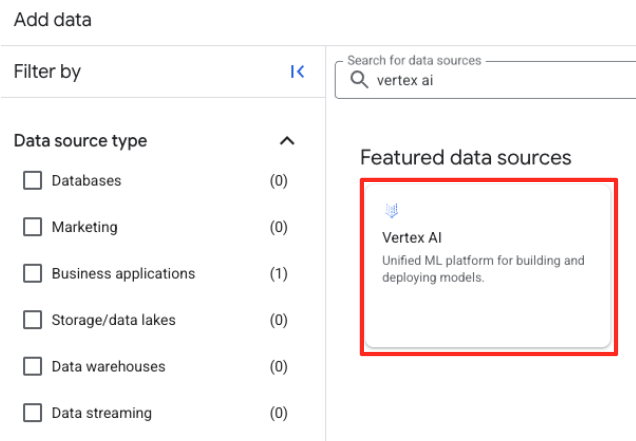
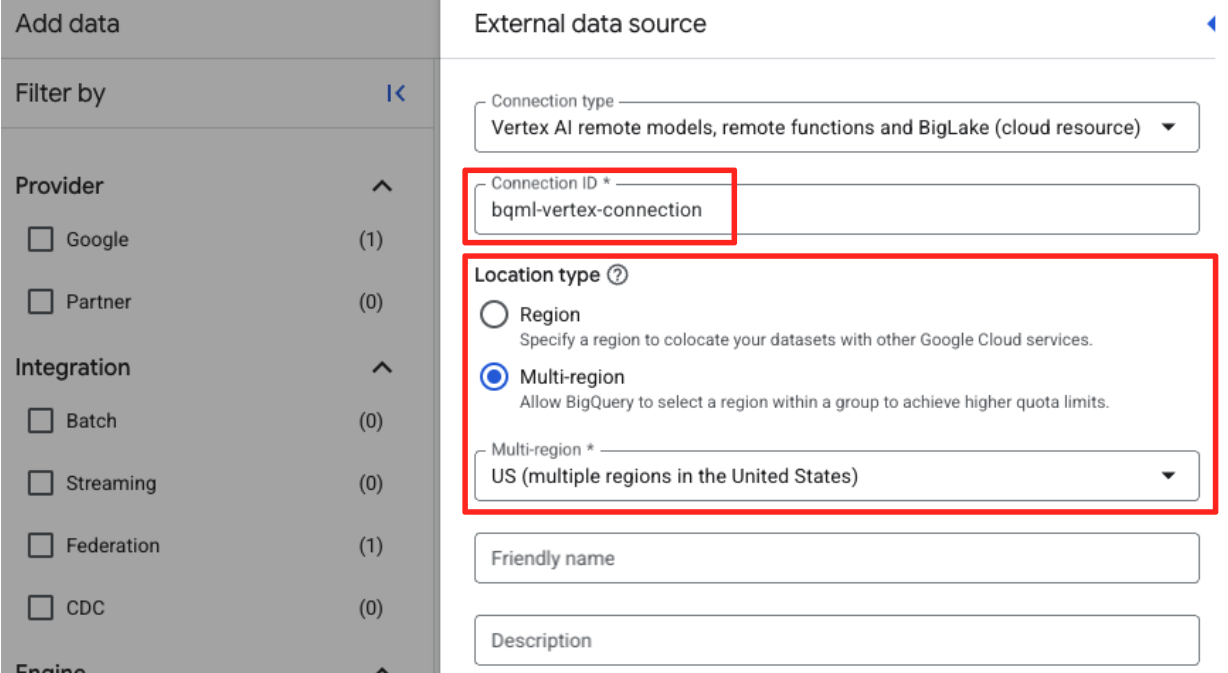
- Isso vai abrir o formulário "Fonte de dados externa". Preencha os seguintes detalhes:
- ID da conexão: insira o ID da conexão (por exemplo,
bqml-vertex-connection) - Tipo de local: verifique se a opção "Multirregional" está selecionada.
- Local: selecione o local (por exemplo,
US).
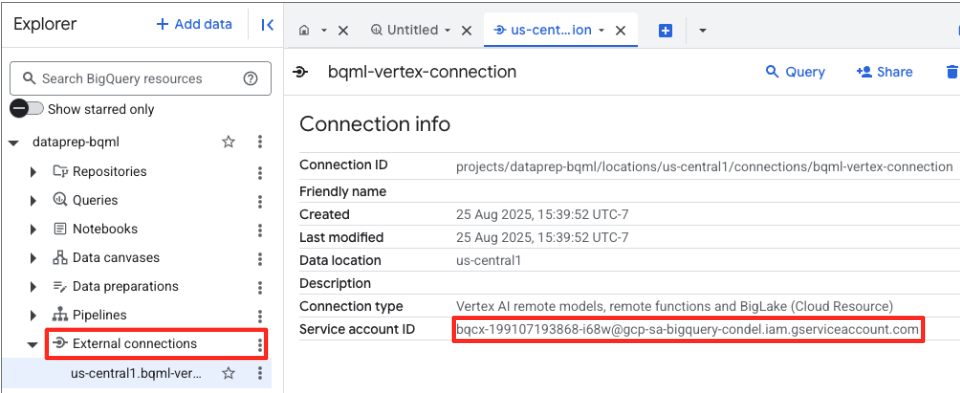
- Quando a conexão for criada, uma caixa de diálogo de confirmação vai aparecer. Clique em "Acessar conexão" ou "Conexões externas" na guia "Explorer". Na página de detalhes da conexão, copie o ID completo para a área de transferência. Essa é a identidade da conta de serviço que o BigQuery vai usar para chamar a Vertex AI.
- No menu de navegação do console do Google Cloud, acesse IAM e administrador > IAM.
- Clique no botão "Permitir acesso".
- Cole a conta de serviço que você copiou na etapa anterior no campo "Novos principais".
- Atribua "Usuário da Vertex AI" no menu suspenso "Papel" e clique em "Salvar".
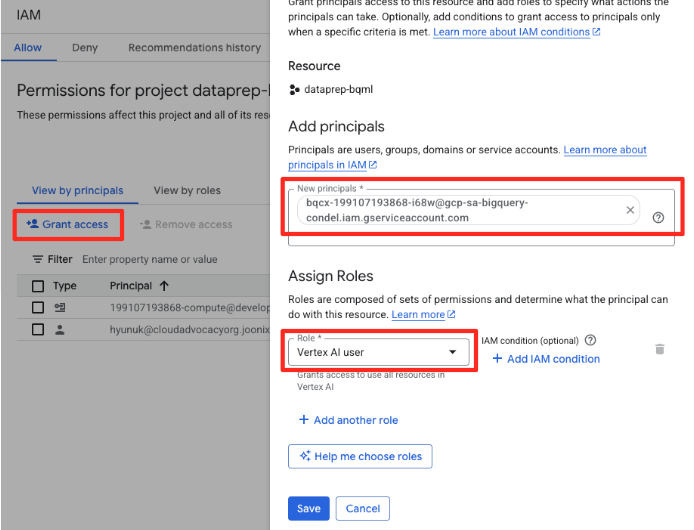
Essa etapa crítica garante que o BigQuery tenha a autorização adequada para usar modelos da Vertex AI em seu nome.
Criar um modelo remoto
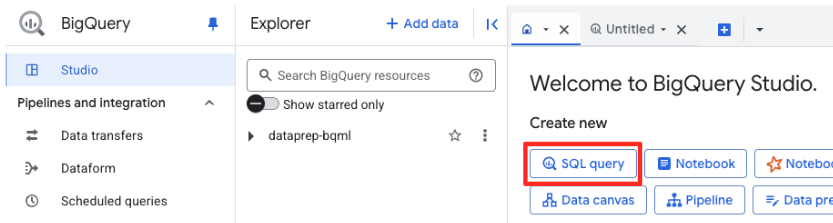
No BigQuery Studio, abra uma nova guia do editor de SQL. É aqui que você vai definir o modelo do BQML que se conecta ao Gemini.
Essa instrução não treina um novo modelo. Ele simplesmente cria uma referência no BigQuery que aponta para um modelo gemini-embedding-001 poderoso e pré-treinado usando a conexão que você acabou de autorizar.
Copie todo o script SQL abaixo e cole no editor do BigQuery.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
Gerar embeddings
Agora, vamos usar nosso modelo do BQML para gerar os embeddings de vetor. Em vez de simplesmente converter um único rótulo de texto para cada linha, vamos usar uma abordagem mais sofisticada para criar um "resumo semântico" mais rico e significativo para cada arte. Isso vai resultar em incorporações de maior qualidade e recomendações mais precisas.
Essa consulta executa uma etapa de pré-processamento essencial:
- Ela usa uma cláusula
WITHpara criar uma tabela temporária. - Dentro dele,
GROUP BYcadaobject_idpara combinar todas as informações sobre uma única arte em uma linha. - Usamos a função
STRING_AGGpara mesclar todas as descrições de texto separadas (como "Retrato", "Mulher", "Óleo sobre tela") em uma única string de texto abrangente, ordenando-as por pontuação de relevância.
Esse texto combinado oferece à IA um contexto muito mais rico sobre a arte, resultando em embeddings de vetores mais sutis e poderosos.
Em uma nova guia do editor de SQL, cole e execute a seguinte consulta:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
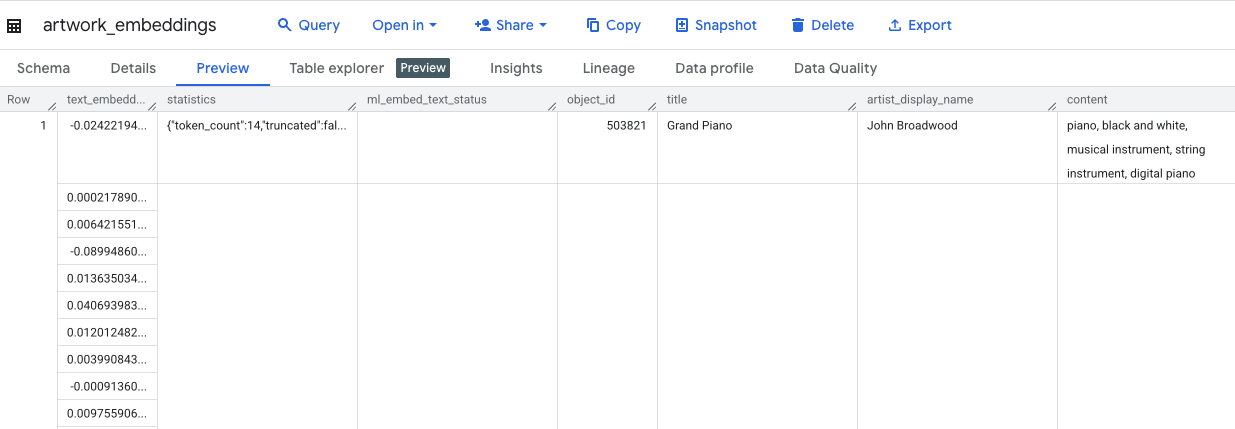
Essa consulta leva aproximadamente 10 minutos. Quando a consulta for concluída, verifique os resultados. No painel "Explorer", encontre e clique na nova tabela artwork_embeddings. No visualizador de esquema da tabela, você vai encontrar a object_id, a nova coluna ml_generate_text_embedding_result com os vetores e a coluna aggregated_labels, que foi usada como texto de origem.
5. Como encontrar obras de arte semelhantes com SQL
Com os embeddings de vetores de alta qualidade e ricos em contexto criados, encontrar obras de arte tematicamente semelhantes é tão simples quanto executar uma consulta SQL. Usamos a função ML.DISTANCE para calcular a semelhança de cossenos entre vetores. Como nossos embeddings foram gerados com base em texto agregado, os resultados de similaridade serão mais precisos e relevantes.
- Em uma nova guia do editor de SQL, cole a consulta a seguir. Essa consulta simula a lógica principal de um aplicativo de recomendação:
- Primeiro, ele seleciona o vetor de uma única obra de arte específica (neste caso, "Ciprestes", de Van Gogh, que tem um
object_idde 436535). - Em seguida, ele calcula a distância entre esse vetor único e todos os outros vetores na tabela.
- Por fim, ele ordena os resultados por distância (uma distância menor significa mais semelhança) para encontrar as 10 correspondências mais próximas.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- Execute a consulta. Os resultados vão listar
object_ids, com as correspondências mais próximas na parte de cima. A arte da origem vai aparecer primeiro com uma distância de 0. Essa é a lógica principal que alimenta um mecanismo de recomendação de IA, e você a criou inteiramente no BigQuery usando apenas SQL.
6. (OPCIONAL) Como executar a demonstração no Cloud Shell
Para dar vida aos conceitos deste codelab, o repositório clonado inclui um aplicativo da Web simples. Esta demonstração opcional usa a tabela artwork_embeddings que você criou para alimentar um mecanismo de pesquisa visual, permitindo que você veja as recomendações baseadas em IA em ação.
Para executar a demonstração no Cloud Shell, siga estas etapas:
- Defina as variáveis de ambiente: antes de executar o aplicativo, defina as variáveis de ambiente PROJECT_ID e BIGQUERY_DATASET.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- Instale as dependências e inicie o servidor de back-end.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- Você vai precisar de uma segunda guia do terminal para executar o aplicativo de front-end. Clique no ícone "+" para abrir uma nova guia do Cloud Shell.

- Agora, na nova guia, execute o seguinte comando para instalar dependências e executar o servidor de front-end:
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- Visualize o aplicativo: na barra de ferramentas do Cloud Shell, clique no ícone "Visualização da Web" e selecione "Visualizar na porta 5173". Uma nova guia do navegador será aberta com o aplicativo em execução. Agora você pode usar o aplicativo para pesquisar obras de arte e ver a pesquisa de similaridade em ação.
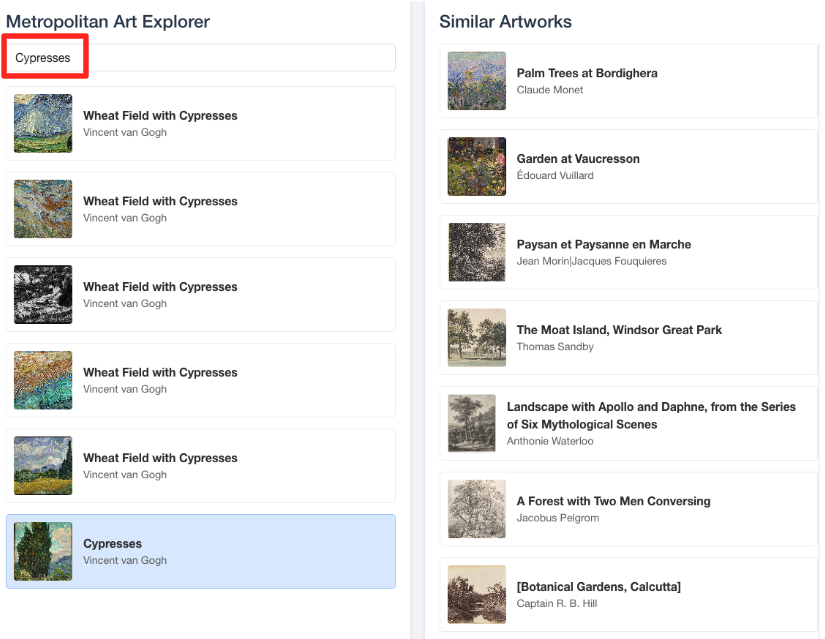
- Para conectar essa demonstração visual ao trabalho feito no editor de SQL do BigQuery, digite "Cypresses" na barra de pesquisa. Esta é a mesma arte(
object_id=436535) que você usou na consultaML.DISTANCE. Em seguida, clique na imagem "Cypress" quando ela aparecer no painel à esquerda. Os resultados vão aparecer à direita. O aplicativo mostra as obras de arte mais semelhantes, demonstrando visualmente o poder da pesquisa de similaridade vetorial que você criou.
7. Limpar o ambiente
Para evitar cobranças futuras na sua conta do Google Cloud pelos recursos usados neste codelab, exclua os recursos criados.
Execute os comandos a seguir no terminal do Cloud Shell para remover a conta de serviço, a conexão do BigQuery, o bucket do GCS e o conjunto de dados do BigQuery.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
Remover a conexão do BigQuery e o bucket do GCS
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
Excluir o conjunto de dados do BigQuery
Por fim, exclua o conjunto de dados do BigQuery. Esse comando é irreversível. A flag -f (forçar) remove o conjunto de dados e todas as tabelas dele sem pedir confirmação.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. Parabéns!
Você criou um pipeline de dados completo com tecnologia de IA.
Você começou com um arquivo CSV bruto em um bucket do GCS, usou a interface de pouco código do BigQuery Data Prep para ingerir e simplificar dados JSON complexos, criou um modelo remoto do BQML para gerar embeddings de vetor de alta qualidade com um modelo do Gemini e executou uma consulta de pesquisa de similaridade para encontrar itens relacionados.
Agora você tem o padrão fundamental para criar fluxos de trabalho com assistência de IA no Google Cloud, transformando dados brutos em aplicativos inteligentes com rapidez e simplicidade.
A seguir
- Visualize seus resultados no Looker Studio:conecte sua tabela do BigQuery
artwork_embeddingsdiretamente ao Looker Studio (é sem custo financeiro!). Você pode criar um painel interativo em que os usuários selecionam uma arte e veem uma galeria visual das peças mais semelhantes sem escrever nenhum código de front-end. - Automatize com consultas programadas:não é necessário ter uma ferramenta de orquestração complexa para manter os embeddings atualizados. Use o recurso Consultas programadas integrado do BigQuery para executar automaticamente a consulta
ML.GENERATE_TEXT_EMBEDDINGdiariamente ou semanalmente. - Gerar um app com a CLI do Gemini:use a CLI do Gemini para gerar um aplicativo completo apenas descrevendo sua exigência em texto simples. Assim, você pode criar rapidamente um protótipo funcional para sua pesquisa de similaridade sem escrever o código Python manualmente.
- Leia a documentação: