
1. Введение
Аналитики данных часто сталкиваются с ценными данными, хранящимися в полуструктурированных форматах, таких как JSON-данные. Извлечение и подготовка этих данных для анализа и машинного обучения традиционно представляют собой серьезную техническую проблему, требующую сложных ETL-скриптов и вмешательства команды инженеров данных.
Этот практический семинар предоставляет аналитикам данных техническую схему для самостоятельного решения этой задачи. Он демонстрирует подход «с минимальным количеством кода» к созданию комплексного конвейера обработки данных с использованием ИИ. Вы узнаете, как перейти от необработанного CSV-файла в Google Cloud Storage к созданию функции рекомендаций на основе ИИ, используя только инструменты, доступные в BigQuery Studio.
Основная цель — продемонстрировать надежный, быстрый и удобный для аналитиков рабочий процесс, который выходит за рамки сложных, ресурсоемких процессов и позволяет извлекать реальную бизнес-ценность из ваших данных.
Предварительные требования
- Базовое понимание консоли Google Cloud
- Базовые навыки работы с командной строкой и Google Cloud Shell.
Что вы узнаете
- Как загрузить и преобразовать CSV-файл непосредственно из Google Cloud Storage с помощью BigQuery Data Preparation.
- Как использовать преобразования без написания кода для анализа и преобразования вложенных JSON-строк в ваших данных в плоскую структуру.
- Как создать удалённую модель BigQuery ML, которая подключается к базовой модели Vertex AI для встраивания текста.
- Как использовать функцию
ML.GENERATE_TEXT_EMBEDDINGдля преобразования текстовых данных в числовые векторы. - Как использовать функцию
ML.DISTANCEдля вычисления косинусного сходства и поиска наиболее похожих элементов в вашем наборе данных.
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, например Chrome.
Ключевые понятия
- Подготовка данных в BigQuery: инструмент в составе BigQuery Studio, предоставляющий интерактивный визуальный интерфейс для очистки и подготовки данных. Он предлагает преобразования и позволяет пользователям создавать конвейеры обработки данных с минимальным количеством кода.
- BQML Remote Model: объект BigQuery ML, который выступает в качестве прокси для модели, размещенной на Vertex AI (например, Gemini). Он позволяет вызывать мощные, предварительно обученные модели ИИ, используя привычный синтаксис SQL.
- Векторное представление: числовое представление данных, таких как текст или изображения. В этом практическом занятии мы преобразуем текстовые описания произведений искусства в векторы, где похожие описания приводят к векторам, которые находятся «ближе» друг к другу в многомерном пространстве.
- Косинусное сходство: математическая мера, используемая для определения степени сходства двух векторов. Это основа логики нашей системы рекомендаций, используемая функцией
ML.DISTANCEдля поиска «наиболее близких» (наиболее похожих) произведений искусства.
2. Настройка и требования
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:

Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
Включите необходимые API и настройте среду.
Внутри Cloud Shell выполните следующие команды, чтобы установить идентификатор проекта, определить переменные среды и включить все необходимые API для этого практического занятия.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
Создайте набор данных BigQuery и сегмент GCS.
Создайте новый набор данных BigQuery для размещения наших таблиц и хранилище Google Cloud Storage для хранения исходного CSV-файла.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
Подготовьте и загрузите образец данных.
Клонируйте репозиторий GitHub, содержащий пример CSV-файла, а затем загрузите его в только что созданный вами бакет GCS.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. Переход от GCS к BigQuery с подготовкой данных.
В этом разделе мы воспользуемся визуальным интерфейсом без необходимости написания кода для импорта нашего CSV-файла из GCS, его очистки и загрузки в новую таблицу BigQuery.
Запустите подготовку данных и подключитесь к источнику.
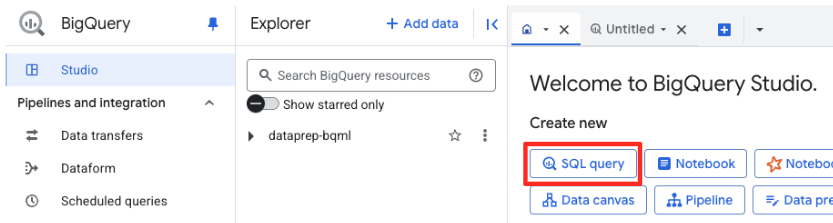
- В консоли Google Cloud перейдите в раздел BigQuery Studio.
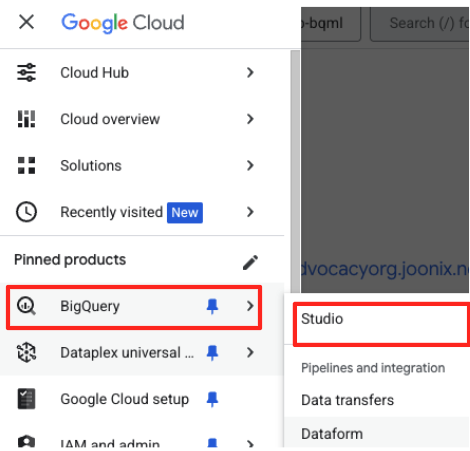
- На главной странице нажмите на карточку «Подготовка данных», чтобы начать.
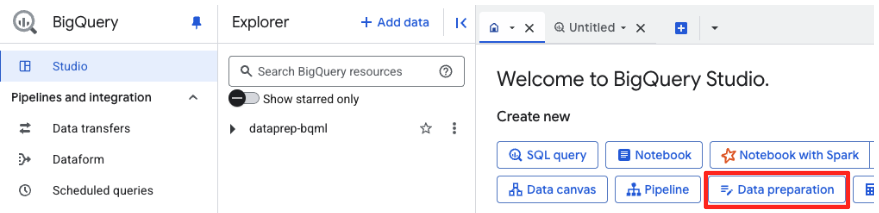
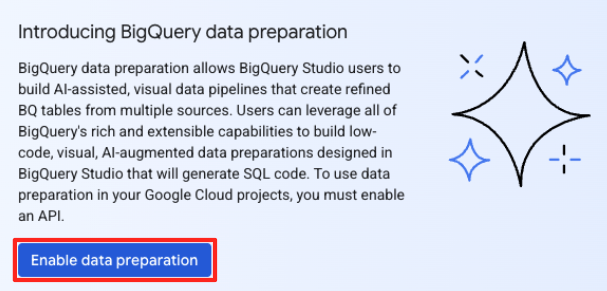
- Если вы используете API впервые, вам может потребоваться включить необходимые API. Нажмите «Включить» для «Gemini for Google Cloud API» и «BigQuery Unified API». После включения вы можете закрыть эту панель.
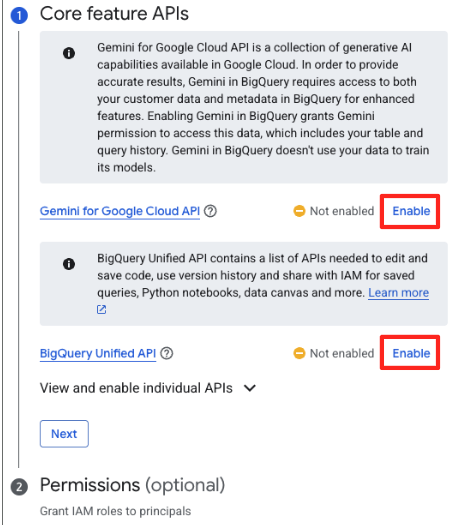
- В главном окне подготовки данных в разделе «Выберите другие источники данных» нажмите Google Cloud Storage. Это откроет панель «Подготовка данных» справа.
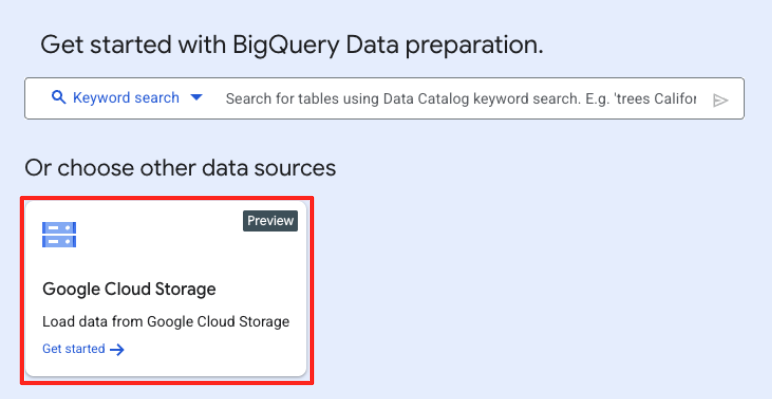
- Нажмите кнопку «Обзор», чтобы выбрать исходный файл.
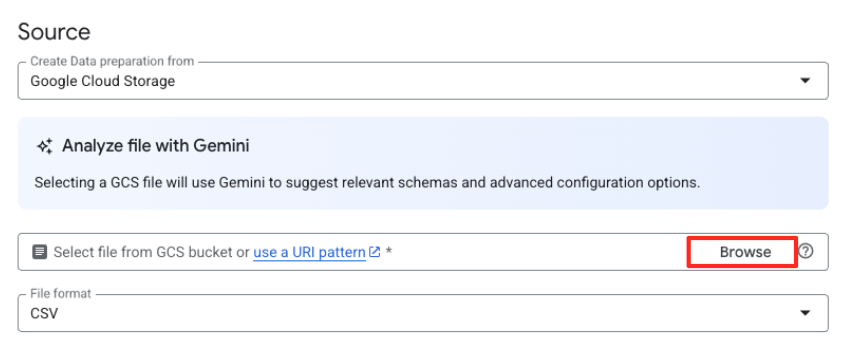
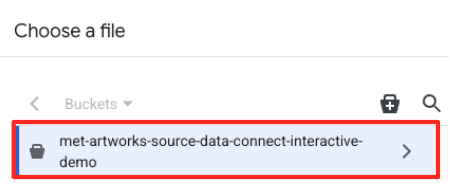
- Перейдите в созданный ранее сегмент GCS (
met-artworks-source-...) и выберите файлdataprep-met-bqml.csv. Нажмите «Выбрать».
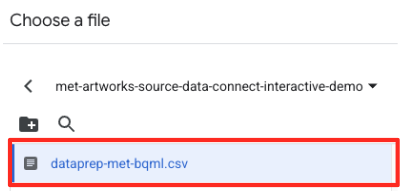
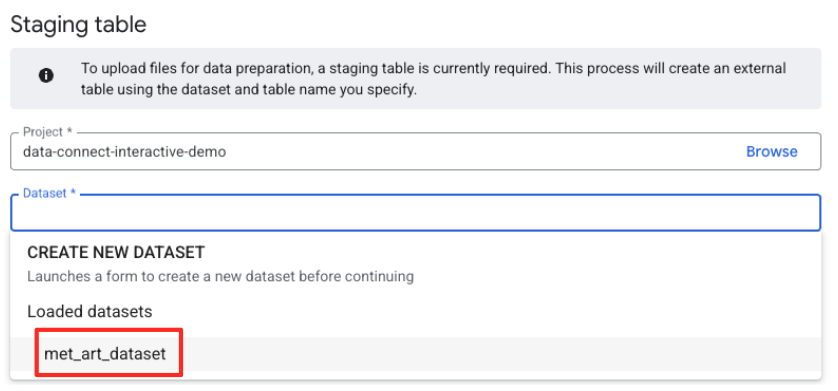
- Далее необходимо настроить промежуточную таблицу.
- В поле «Набор данных» выберите созданный вами набор
met_art_dataset. - В поле «Имя таблицы» введите имя, например,
temp. - Нажмите «Создать».
Преобразование и очистка данных
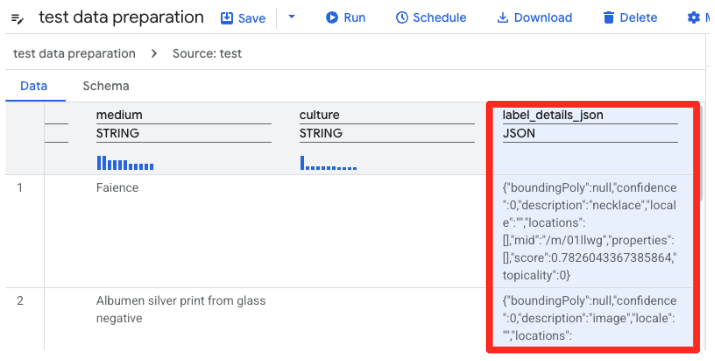
- В режиме подготовки данных BigQuery отобразится предварительный просмотр CSV-файла. Найдите столбец
label_details_json, содержащий длинную JSON-строку. Щелкните заголовок столбца, чтобы выбрать его.
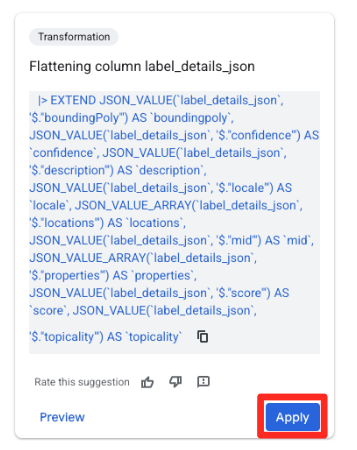
- В панели «Предложения» справа Gemini в BigQuery автоматически предложит соответствующие преобразования. Нажмите кнопку «Применить» на карточке «Сглаживание столбца
label_details_json». Это выведет вложенные поля (description,scoreи т. д.) в отдельные столбцы верхнего уровня.
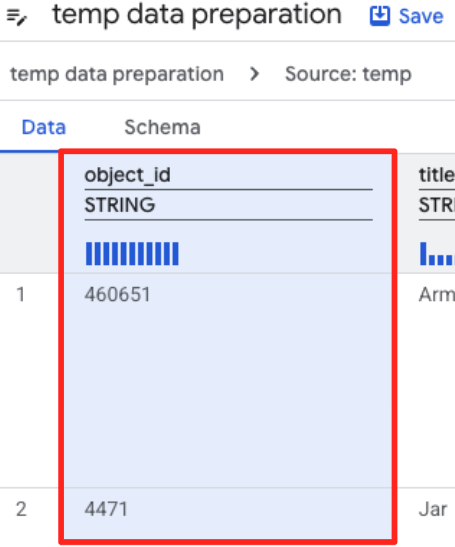
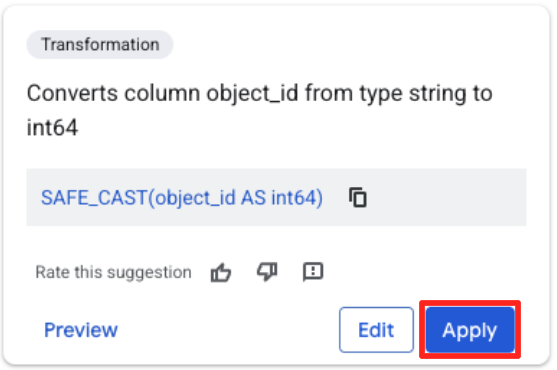
- Щелкните столбец object_id и нажмите кнопку «Применить» в поле «Преобразует столбец
object_idизstringтипа вint64.
Укажите место назначения и запустите задание.
- На правой панели нажмите кнопку «Назначение», чтобы настроить выходные данные преобразования.
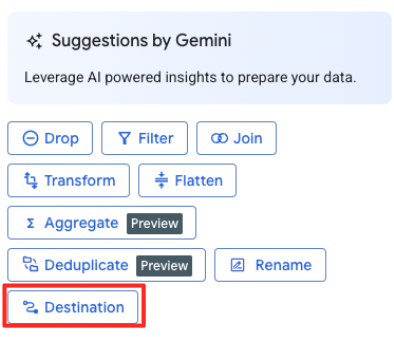
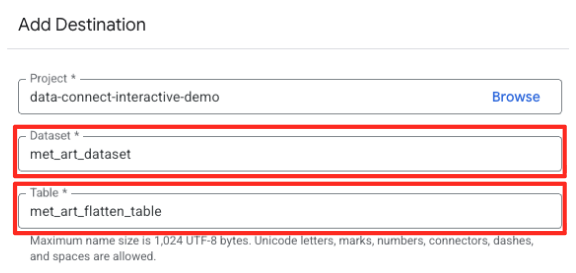
- Укажите параметры назначения:
- Набор данных должен быть предварительно заполнен значением
met_art_dataset. - Введите новое имя таблицы для вывода:
met_art_flatten_table. - Нажмите «Сохранить».
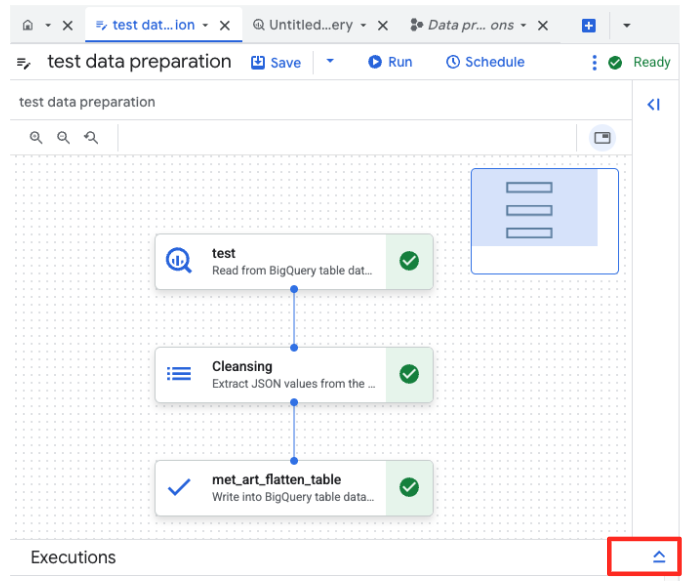
- Нажмите кнопку «Выполнить» и дождитесь завершения процесса подготовки данных.
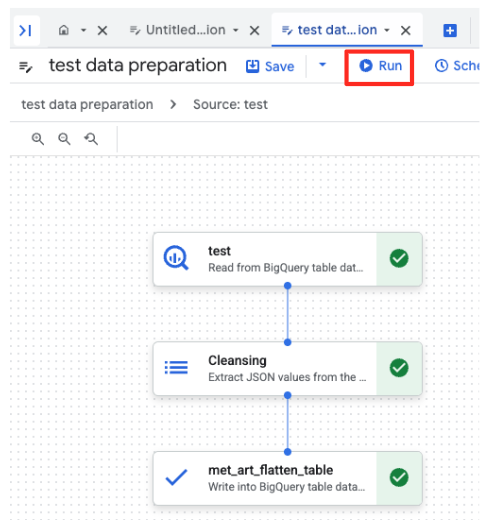
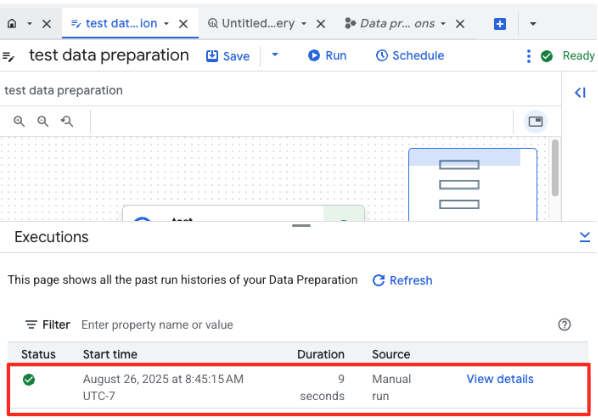
- Вы можете отслеживать ход выполнения задания на вкладке «Выполнения» внизу страницы. Через несколько мгновений задание завершится.
4. Генерация векторных представлений с помощью BQML
Теперь, когда наши данные очищены и структурированы, мы будем использовать BigQuery ML для основной задачи ИИ: преобразования текстовых описаний произведений искусства в числовые векторные представления.
Создайте подключение к BigQuery.
Для обеспечения взаимодействия BigQuery с сервисами Vertex AI необходимо сначала создать соединение BigQuery.
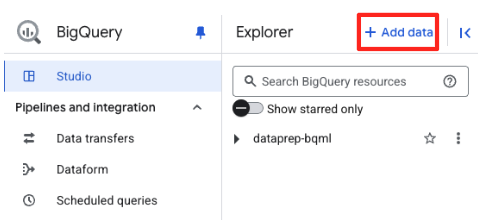
- В панели «Проводник» BigQuery Studio нажмите кнопку «+ Добавить данные».
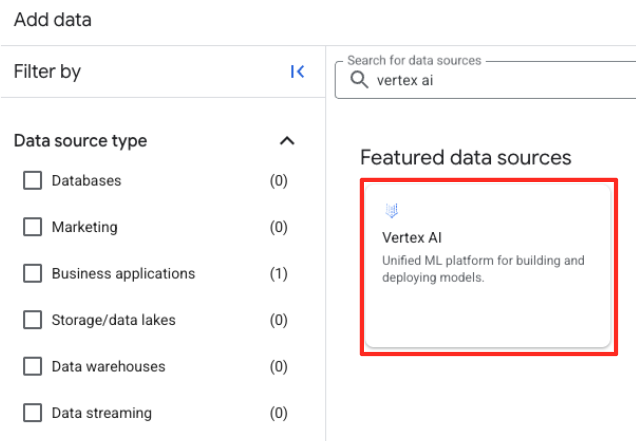
- В правой панели воспользуйтесь строкой поиска, чтобы ввести
Vertex AI. Выберите его, а затем BigQuery federation из отфильтрованного списка.
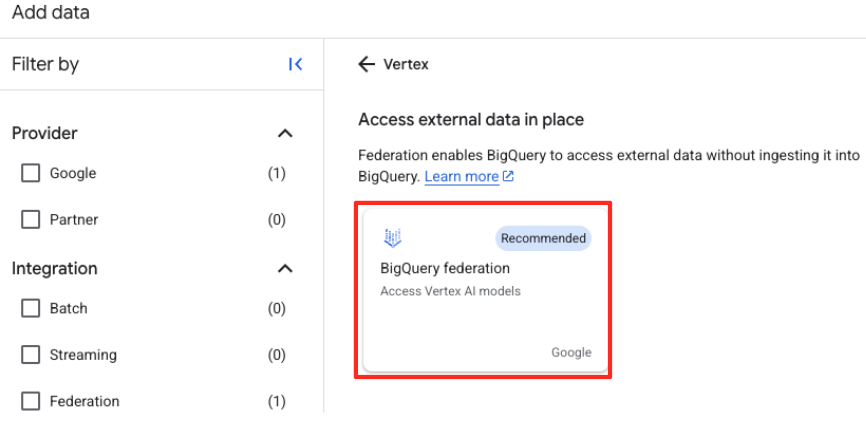
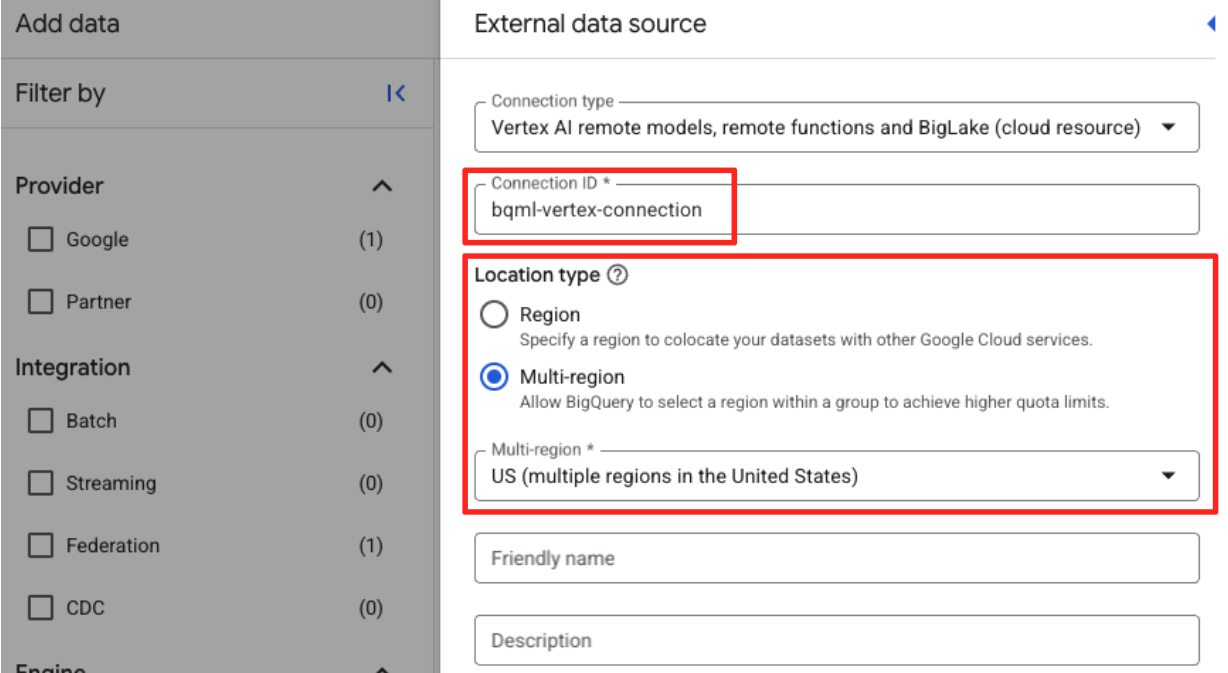
- Откроется форма «Внешний источник данных». Заполните следующие поля:
- Идентификатор соединения: Введите идентификатор соединения (например,
bqml-vertex-connection) - Тип местоположения: Убедитесь, что выбран параметр «Многорегиональный».
- Местоположение: Выберите местоположение (например,
US).
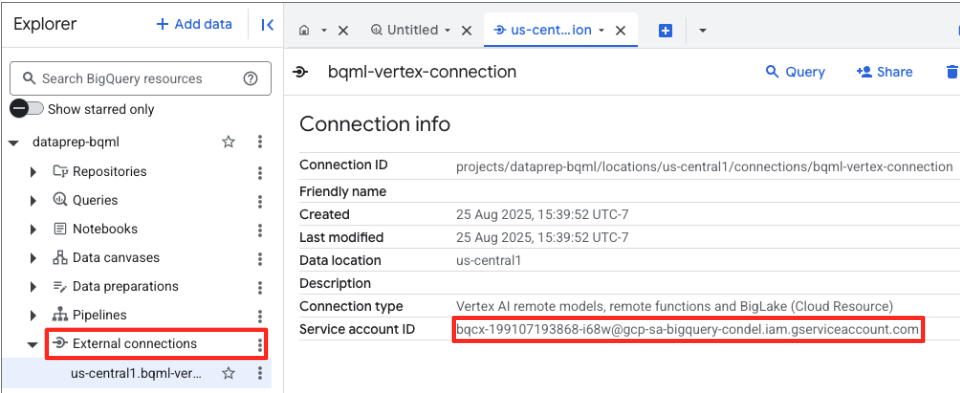
- После установления соединения появится диалоговое окно подтверждения. На вкладке «Проводник» нажмите «Перейти к соединению» или «Внешние соединения». На странице сведений о соединении скопируйте полный идентификатор в буфер обмена. Это идентификатор учетной записи службы, который BigQuery будет использовать для вызова Vertex AI.
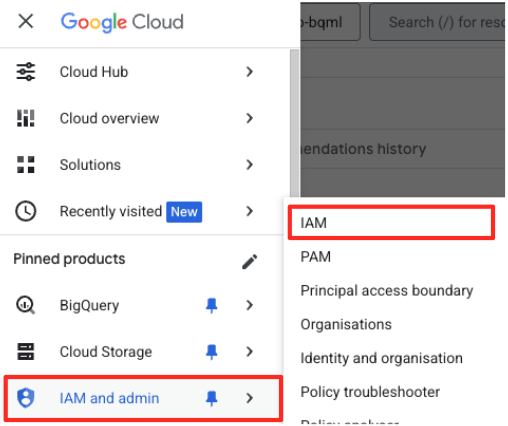
- В меню навигации консоли Google Cloud перейдите в раздел IAM и администрирование > IAM.
- Нажмите кнопку «Предоставить доступ».
- Вставьте учетную запись службы, скопированную на предыдущем шаге, в поле «Новые участники».
- В раскрывающемся списке «Роль» назначьте пользователя «Vertex AI » и нажмите «Сохранить».
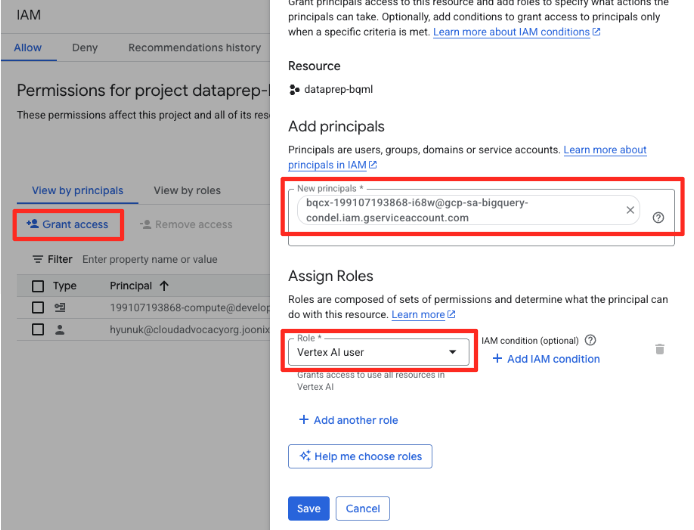
Этот важный шаг гарантирует, что BigQuery имеет надлежащие полномочия для использования моделей Vertex AI от вашего имени.
Создайте удаленную модель
В BigQuery Studio откройте новую вкладку редактора SQL. Здесь вы определите модель BQML, которая будет подключаться к Gemini.
Это утверждение не обучает новую модель. Оно просто создает ссылку в BigQuery, указывающую на мощную, предварительно обученную модель gemini-embedding-001 используя только что авторизованное соединение.
Скопируйте весь приведенный ниже SQL-скрипт и вставьте его в редактор BigQuery.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
Сгенерировать векторные представления
Теперь мы воспользуемся нашей моделью BQML для генерации векторных представлений. Вместо простого преобразования одной текстовой метки для каждой строки, мы применим более сложный подход для создания более полного и содержательного «семантического резюме» для каждого произведения искусства. Это приведет к получению более качественных представлений и более точных рекомендаций.
Этот запрос выполняет важный этап предварительной обработки:
- Для создания временной таблицы используется оператор
WITH. - Внутри него мы
GROUP BYкаждомуobject_id, чтобы объединить всю информацию об одном произведении искусства в одну строку. - Мы используем функцию
STRING_AGGдля объединения всех отдельных текстовых описаний (например, «Портрет», «Женщина», «Масло на холсте») в одну исчерпывающую текстовую строку, упорядочивая их по показателю релевантности.
Этот объединенный текст предоставляет искусственному интеллекту гораздо более богатый контекст об изображении произведения искусства, что приводит к более детальным и эффективным векторным представлениям.
В новой вкладке редактора SQL вставьте и выполните следующий запрос:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
Выполнение этого запроса займет приблизительно 10 минут. После завершения запроса проверьте результаты. В панели «Проводник» найдите новую таблицу artwork_embeddings и щелкните по ней. В окне просмотра схемы таблицы вы увидите object_id , новый столбец ml_generate_text_embedding_result содержащий векторы, а также столбец aggregated_labels, который использовался в качестве исходного текста.
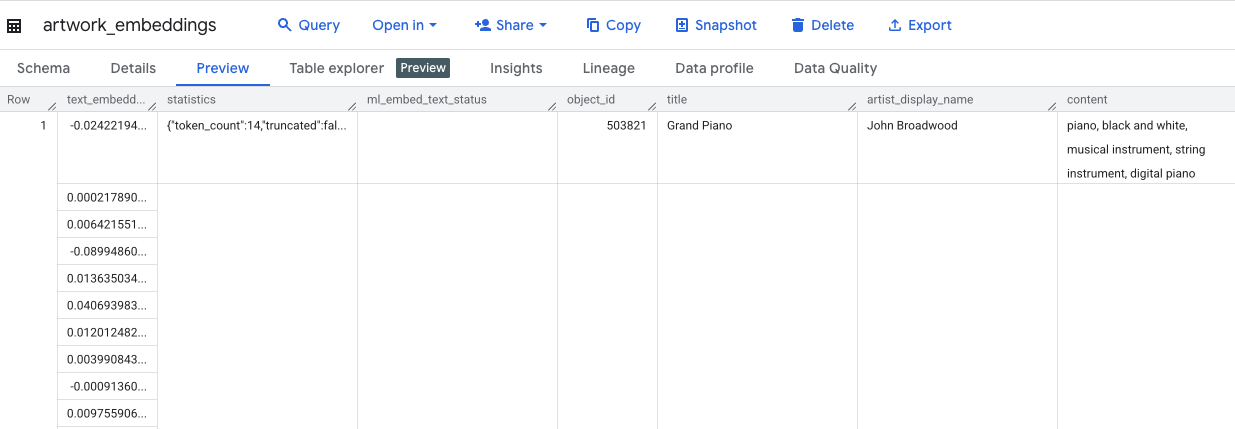
5. Поиск похожих произведений искусства с помощью SQL
Благодаря нашим высококачественным, контекстно-ориентированным векторным представлениям, поиск тематически похожих произведений искусства становится таким же простым, как выполнение SQL-запроса. Мы используем функцию ML.DISTANCE для вычисления косинусного сходства между векторами. Поскольку наши представления были сгенерированы на основе агрегированного текста, результаты сравнения будут более точными и релевантными.
- В новой вкладке редактора SQL вставьте следующий запрос. Этот запрос имитирует основную логику приложения для рекомендаций:
- Сначала выбирается вектор для конкретного произведения искусства (в данном случае, для картины Ван Гога «Кипарисы»,
object_idкоторой равен 436535). - Затем программа вычисляет расстояние между этим единственным вектором и всеми остальными векторами в таблице.
- Наконец, программа упорядочивает результаты по расстоянию (меньшее расстояние означает большее сходство), чтобы найти 10 наиболее близких совпадений.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- Выполните запрос. В результатах будут перечислены
object_id, при этом наиболее близкие совпадения будут вверху списка. Исходное изображение будет отображаться первым с нулевым расстоянием. Это основная логика, лежащая в основе системы рекомендаций на основе ИИ, и вы создали её полностью в BigQuery, используя только SQL.
6. (НЕОБЯЗАТЕЛЬНО) Запуск демонстрации в Cloud Shell
Чтобы воплотить концепции из этого практического занятия в жизнь, в клонированном вами репозитории содержится простое веб-приложение. Эта дополнительная демонстрация использует созданную вами таблицу artwork_embeddings для работы системы визуального поиска, позволяя вам увидеть рекомендации, основанные на искусственном интеллекте, в действии.
Чтобы запустить демонстрацию в Cloud Shell, выполните следующие действия:
- Установка переменных среды: Перед запуском приложения необходимо установить переменные среды PROJECT_ID и BIGQUERY_DATASET.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- Установите зависимости и запустите серверную часть.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- Для запуска фронтенд-приложения вам потребуется вторая вкладка терминала. Нажмите значок «+», чтобы открыть новую вкладку Cloud Shell.

- Теперь в новой вкладке выполните следующую команду, чтобы установить зависимости и запустить фронтенд-сервер.
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- Предварительный просмотр приложения: на панели инструментов Cloud Shell щелкните значок «Предварительный просмотр веб-страницы» и выберите «Предварительный просмотр на порту 5173». Откроется новая вкладка браузера с запущенным приложением. Теперь вы можете использовать приложение для поиска произведений искусства и увидеть, как работает поиск по сходству.
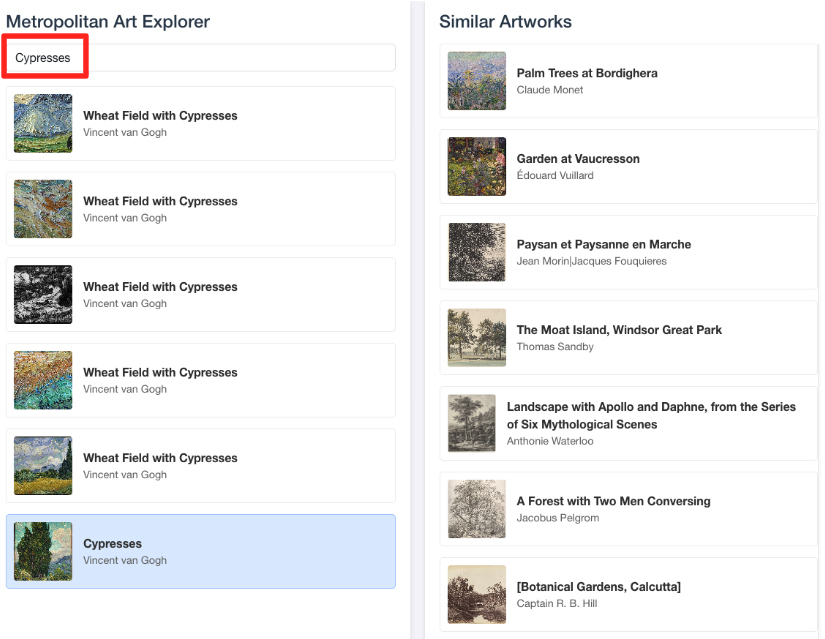
- Чтобы связать эту визуальную демонстрацию с работой, которую вы выполняли в редакторе SQL BigQuery, попробуйте ввести «Кипарисы» в строку поиска. Это то же самое изображение (
object_id=436535), которое вы использовали в запросеML.DISTANCE. Затем щелкните по изображению «Кипарисы», когда оно появится на левой панели, и вы увидите результаты справа. Приложение отобразит наиболее похожие изображения, наглядно демонстрируя возможности созданного вами поиска векторного сходства.
7. Очистка окружающей среды
Чтобы избежать в будущем списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом практическом занятии, вам следует удалить созданные вами ресурсы.
Выполните следующие команды в терминале Cloud Shell, чтобы удалить учетную запись службы, подключение к BigQuery, корзину GCS и набор данных BigQuery.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
Удалите подключение к BigQuery и хранилище GCS.
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
Удалите набор данных BigQuery.
Наконец, удалите набор данных BigQuery. Эта команда необратима. Флаг -f (принудительное удаление) удаляет набор данных и все его таблицы без запроса подтверждения.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. Поздравляем!
Вы успешно создали комплексный конвейер обработки данных на основе искусственного интеллекта.
Вы начали с необработанного CSV-файла в хранилище GCS, использовали интерфейс BigQuery Data Prep с низким уровнем кодирования для загрузки и преобразования сложных данных JSON в однородный формат, создали мощную удаленную модель BQML для генерации высококачественных векторных представлений с помощью модели Gemini и выполнили поисковый запрос на сходство для поиска связанных элементов.
Теперь вы владеете базовым шаблоном для построения рабочих процессов с использованием ИИ в Google Cloud, позволяющим быстро и просто преобразовывать необработанные данные в интеллектуальные приложения.
Что дальше?
- Визуализируйте результаты в Looker Studio: подключите таблицу
artwork_embeddingsиз BigQuery напрямую к Looker Studio (это бесплатно!). Вы можете создать интерактивную панель управления, где пользователи смогут выбрать произведение искусства и увидеть визуальную галерею наиболее похожих работ, не написав ни строчки кода на стороне клиента. - Автоматизируйте с помощью запланированных запросов: вам не понадобится сложный инструмент оркестрации для поддержания актуальности ваших эмбеддингов. Используйте встроенную функцию запланированных запросов BigQuery для автоматического повторного запуска запроса
ML.GENERATE_TEXT_EMBEDDINGежедневно или еженедельно. - Создайте приложение с помощью Gemini CLI: используйте Gemini CLI для создания готового приложения, просто описав свои требования в текстовом виде. Это позволит вам быстро создать рабочий прототип для поиска сходства без необходимости писать код на Python вручную.
- Ознакомьтесь с документацией: