
1. Giriş
Veri analistleri genellikle JSON yükleri gibi yarı yapılandırılmış biçimlerde kilitlenmiş değerli verilerle karşı karşıya kalır. Bu verilerin analiz ve makine öğrenimi için ayıklanması ve hazırlanması, geleneksel olarak önemli bir teknik engel olmuştur. Genellikle karmaşık ETL komut dosyaları ve bir veri mühendisliği ekibinin müdahalesi gerekir.
Bu codelab, veri analistlerinin bu zorluğun üstesinden bağımsız olarak gelmeleri için teknik bir plan sunar. Uçtan uca yapay zeka ardışık düzeni oluşturmak için "az kod kullanılan" bir yaklaşım gösterir. Yalnızca BigQuery Studio'da bulunan araçları kullanarak Google Cloud Storage'daki ham CSV dosyasından yapay zeka destekli bir öneri özelliğine nasıl geçeceğinizi öğreneceksiniz.
Buradaki temel amaç, verilerinizden gerçek iş değeri elde etmek için karmaşık ve kod ağırlıklı süreçlerin ötesine geçen sağlam, hızlı ve analist dostu bir iş akışı göstermektir.
Ön koşullar
- Google Cloud Console hakkında temel bilgiler
- Komut satırı arayüzü ve Google Cloud Shell'de temel beceriler
Neler öğreneceksiniz?
- BigQuery Veri Hazırlama'yı kullanarak doğrudan Google Cloud Storage'dan bir CSV dosyasını nasıl alıp dönüştüreceğinizi öğrenin.
- Verilerinizdeki iç içe yerleştirilmiş JSON dizelerini ayrıştırmak ve düzleştirmek için kodsuz dönüşümleri kullanma
- Metin yerleştirme için Vertex AI temel modeline bağlanan bir BigQuery ML uzak modeli oluşturma
- Metin verilerini sayısal vektörlere dönüştürmek için
ML.GENERATE_TEXT_EMBEDDINGişlevini kullanma - Kosinüs benzerliğini hesaplamak ve veri kümenizdeki en benzer öğeleri bulmak için
ML.DISTANCEişlevini kullanma.
Gerekenler
- Google Cloud hesabı ve Google Cloud projesi
- Chrome gibi bir web tarayıcısı
Temel kavramlar
- BigQuery veri hazırlama: BigQuery Studio'da bulunan ve veri temizleme ile hazırlama için etkileşimli, görsel bir arayüz sağlayan bir araçtır. Dönüşümler önerir ve kullanıcıların minimum düzeyde kodla veri ardışık düzenleri oluşturmasına olanak tanır.
- BQML Remote Model: Vertex AI'da (ör. Gemini) barındırılan bir model için proxy görevi gören bir BigQuery ML nesnesi. Bu sayede, tanıdık SQL söz dizimini kullanarak güçlü ve önceden eğitilmiş yapay zeka modellerini çağırabilirsiniz.
- Vektör yerleştirme: Metin veya resim gibi verilerin sayısal gösterimi. Bu codelab'de, sanat eserlerinin metin açıklamalarını vektörlere dönüştüreceğiz. Benzer açıklamalar, çok boyutlu uzayda birbirine "daha yakın" vektörlerle sonuçlanacak.
- Kosinüs benzerliği: İki vektörün ne kadar benzer olduğunu belirlemek için kullanılan matematiksel bir ölçü. Bu, "en yakın" (en benzer) sanat eserlerini bulmak için
ML.DISTANCEişlevi tarafından kullanılan öneri motorumuzun mantığının temelidir.
2. Kurulum ve şartlar
Cloud Shell'i başlatma
Google Cloud, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir. Ancak bu codelab'de, Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacaksınız.
Google Cloud Console'da sağ üstteki araç çubuğunda Cloud Shell simgesini tıklayın:

Ortamın temel hazırlığı ve bağlanması yalnızca birkaç dakikanızı alır. İşlem tamamlandığında aşağıdakine benzer bir sonuç görürsünüz:

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki tüm çalışmalarınızı tarayıcıda yapabilirsiniz. Herhangi bir şey yüklemeniz gerekmez.
Gerekli API'leri etkinleştirme ve ortamı yapılandırma
Cloud Shell'de, proje kimliğinizi ayarlamak, ortam değişkenlerini tanımlamak ve bu codelab için gerekli tüm API'leri etkinleştirmek üzere aşağıdaki komutları çalıştırın.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
BigQuery veri kümesi ve GCS paketi oluşturma
Tablolarımızı barındıracak yeni bir BigQuery veri kümesi ve kaynak CSV dosyamızı depolayacak bir Google Cloud Storage paketi oluşturun.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
Örnek Verileri Hazırlama ve Yükleme
Örnek CSV dosyasını içeren GitHub deposunu klonlayın ve yeni oluşturduğunuz GCS paketine yükleyin.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. Veri hazırlama ile GCS'den BigQuery'ye
Bu bölümde, GCS'deki CSV dosyamızı almak, temizlemek ve yeni bir BigQuery tablosuna yüklemek için görsel ve kodsuz bir arayüz kullanacağız.
Veri hazırlama özelliğini başlatma ve kaynağa bağlanma
- Google Cloud Console'da BigQuery Studio'ya gidin.
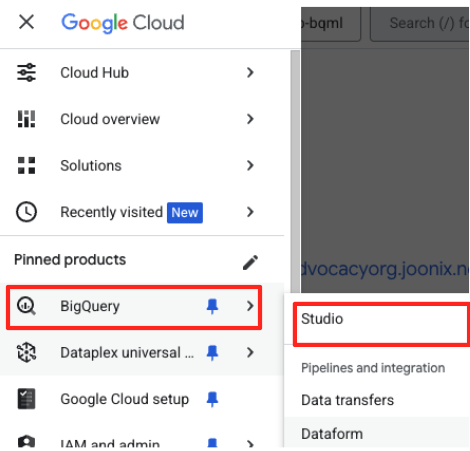
- Başlamak için karşılama sayfasında Veri hazırlama kartını tıklayın.
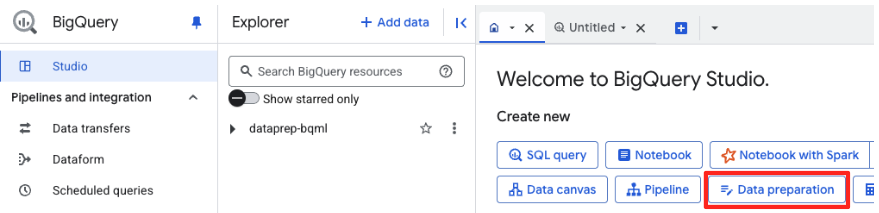
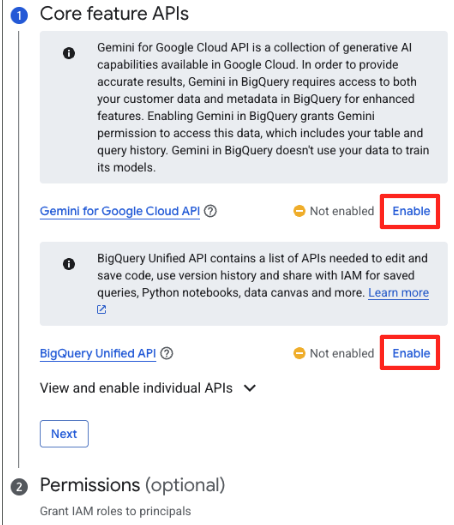
- Bu işlemi ilk kez yapıyorsanız gerekli API'leri etkinleştirmeniz gerekebilir. Hem "Google Cloud için Gemini API" hem de "BigQuery Unified API" için Etkinleştir'i tıklayın. Etkinleştirildikten sonra bu paneli kapatabilirsiniz.
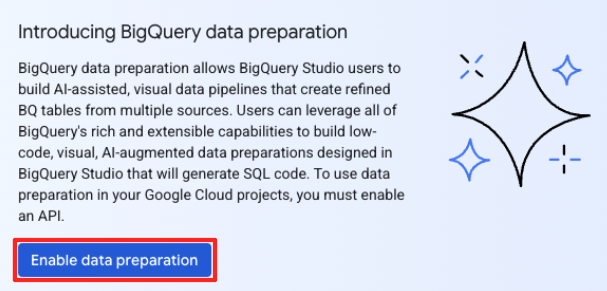
- Ana Veri hazırlama penceresinde, "diğer veri kaynaklarını seçin" bölümünde Google Cloud Storage'ı tıklayın. Bu işlem, sağ tarafta "Verileri hazırla" panelini açar.
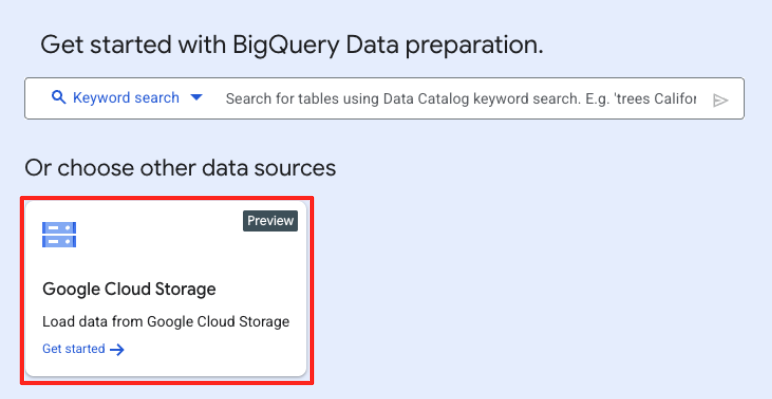
- Kaynak dosyanızı seçmek için Göz at düğmesini tıklayın.
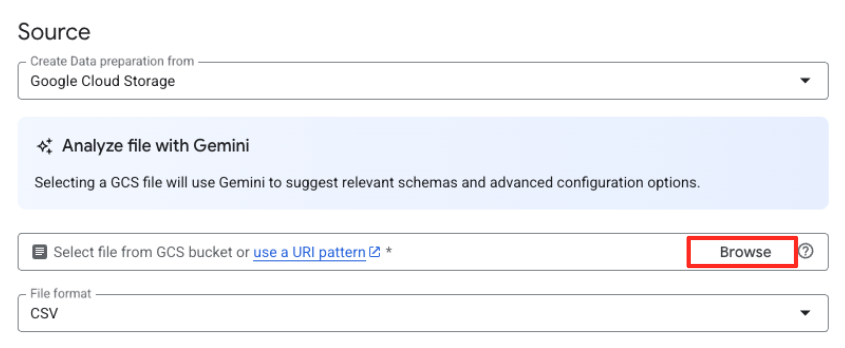
- Daha önce oluşturduğunuz GCS paketine (
met-artworks-source-...) gidin vedataprep-met-bqml.csvdosyasını seçin. Seç'i tıklayın.
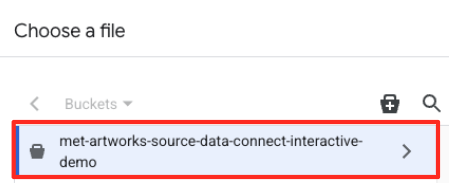
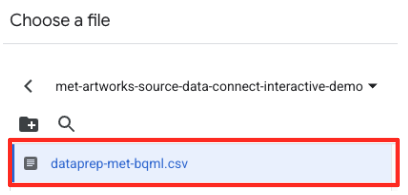
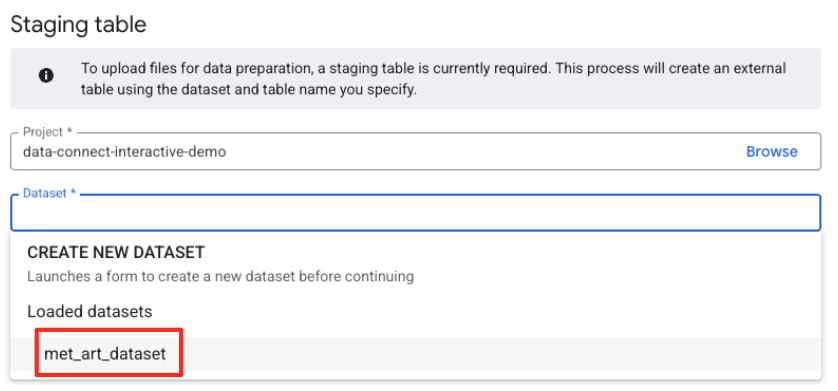
- Ardından, bir hazırlama tablosu yapılandırmanız gerekir.
- Veri kümesi için oluşturduğunuz
met_art_datasetöğesini seçin. - Tablo adı alanına bir ad girin (örneğin,
temp). - Oluştur'u tıklayın.
Verileri Dönüştürme ve Temizleme
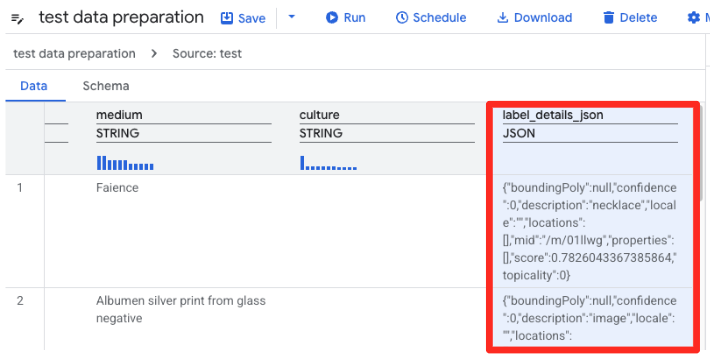
- BigQuery'nin veri hazırlama özelliği artık CSV'nin önizlemesini yükleyecek. Uzun JSON dizesini içeren
label_details_jsonsütununu bulun. Sütun başlığını tıklayarak seçin.
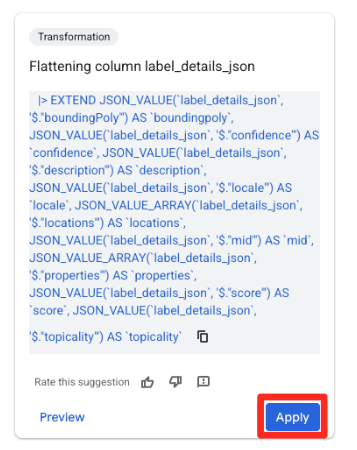
- Sağdaki Öneriler panelinde, BigQuery'deki Gemini otomatik olarak alakalı dönüşümler önerir. "Sütunu düzleştirme
label_details_json" kartında Uygula düğmesini tıklayın. Bu işlem, iç içe yerleştirilmiş alanları (description,scorevb.) kendi üst düzey sütunlarına ayırır.
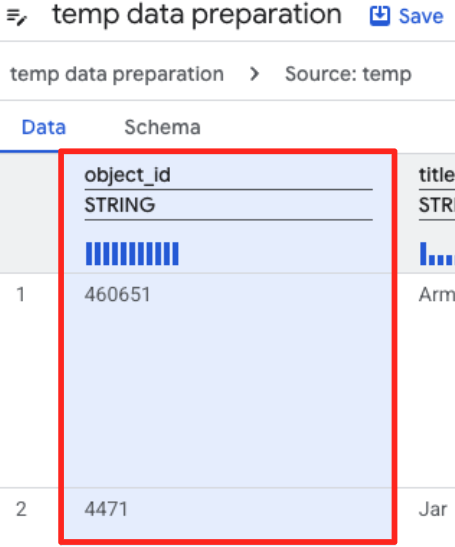
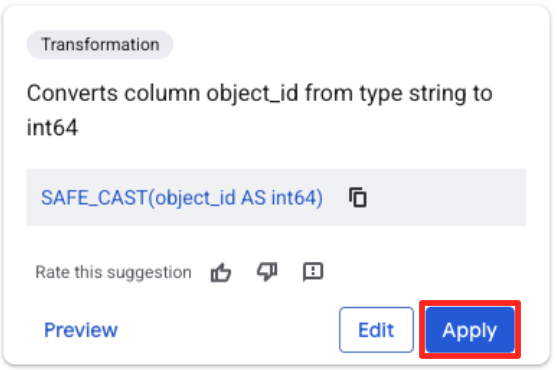
- object_id sütununu ve "Sütun
object_id, türstring'tenint64'ye dönüştürülüyor" bölümündeki uygula düğmesini tıklayın.
Hedefi Tanımlama ve İşi Çalıştırma
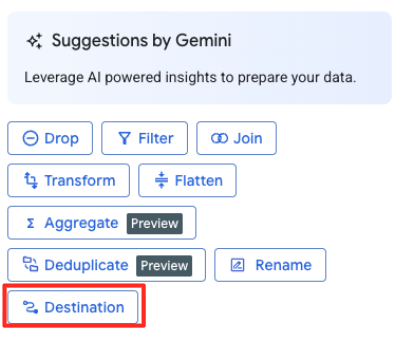
- Sağdaki panelde, dönüştürme işleminizin çıkışını yapılandırmak için Hedef düğmesini tıklayın.
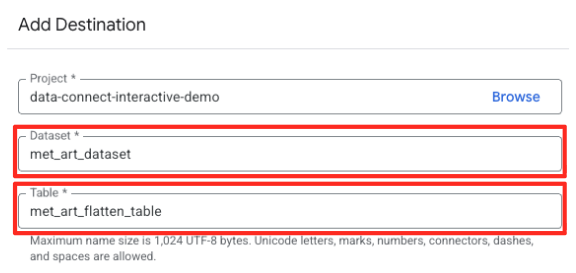
- Hedef ayrıntılarını ayarlayın:
- Veri kümesi,
met_art_datasetile önceden doldurulmalıdır. - Çıkış için yeni bir tablo adı girin:
met_art_flatten_table. - Kaydet'i tıklayın.
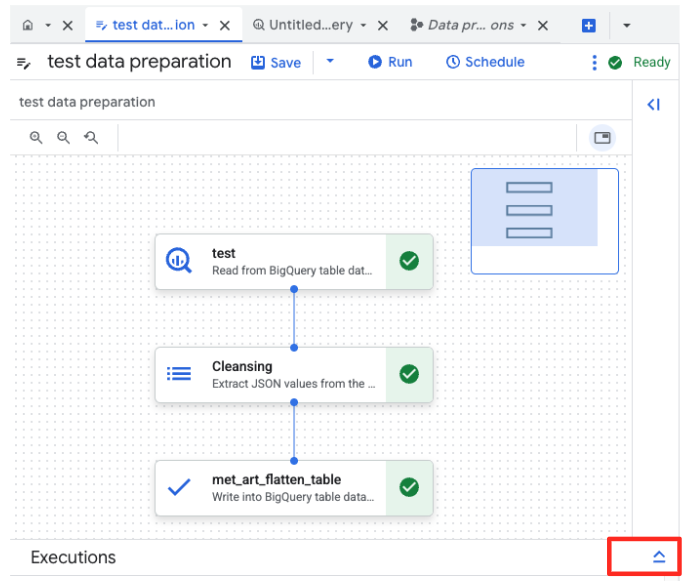
- Çalıştır düğmesini tıklayın ve veri hazırlama işinin tamamlanmasını bekleyin.
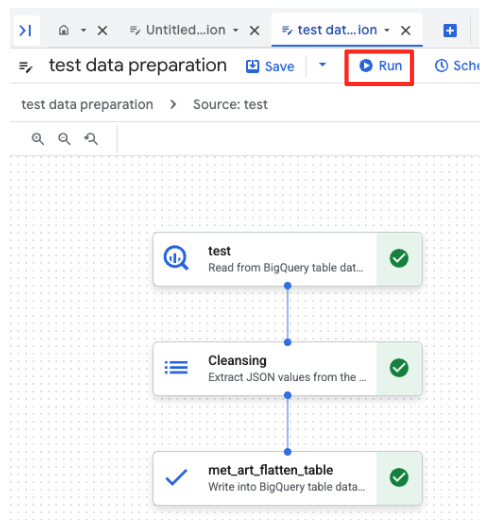
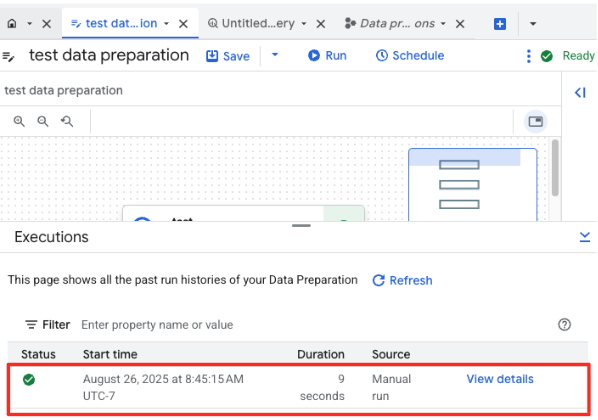
- İşin ilerleme durumunu sayfanın alt kısmındaki Yürütmeler sekmesinden izleyebilirsiniz. İşlem birkaç dakika içinde tamamlanır.
4. BQML ile vektör yerleştirmeleri oluşturma
Verilerimiz artık temiz ve yapılandırılmış olduğundan temel yapay zeka görevi için BigQuery ML'yi kullanacağız: Sanat eserinin metin açıklamalarını sayısal vektör yerleştirmelerine dönüştürme.
BigQuery bağlantısı oluşturma
BigQuery'nin Vertex AI hizmetleriyle iletişim kurmasına izin vermek için önce bir BigQuery bağlantısı oluşturmanız gerekir.
- BigQuery Studio'nun Explorer panelinde "+ Veri ekle" düğmesini tıklayın.
- Sağdaki panelde, arama çubuğunu kullanarak
Vertex AIyazın. Bu seçeneği ve ardından filtrelenmiş listeden BigQuery federasyonunu seçin.
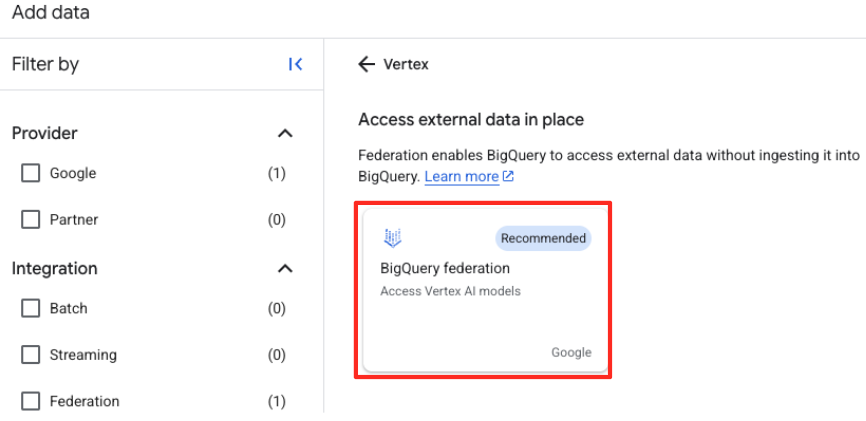
- Bu işlem, Harici veri kaynağı formunu açar. Aşağıdaki ayrıntıları girin:
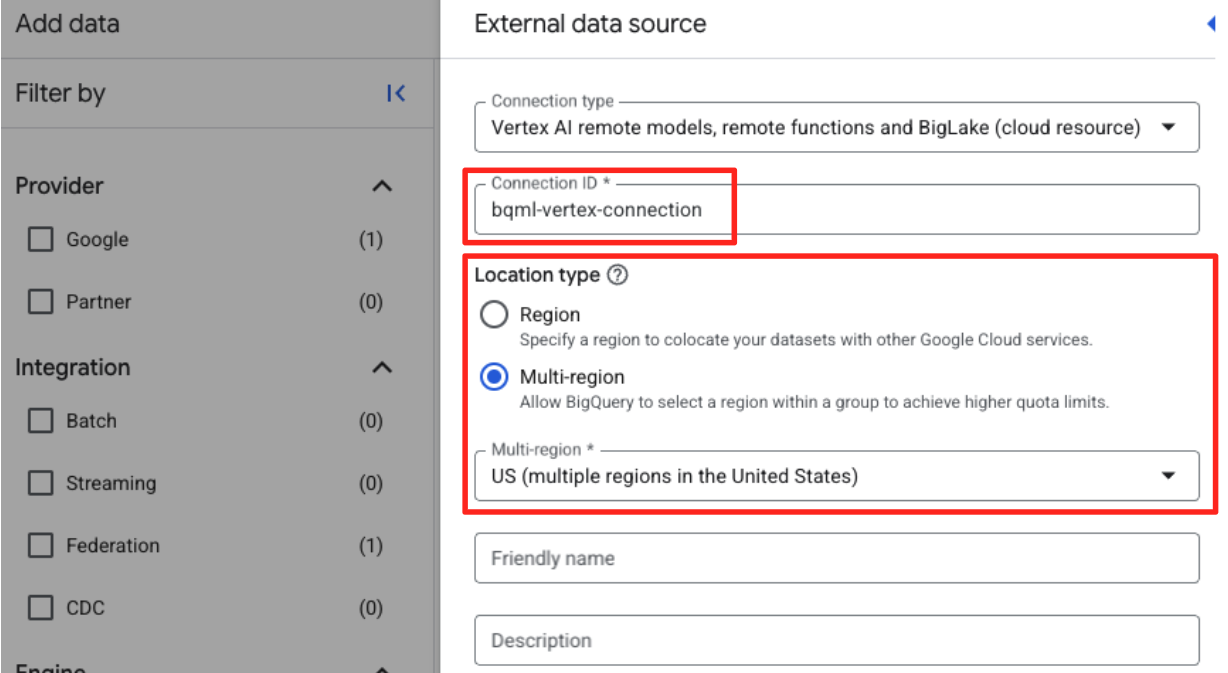
- Bağlantı kimliği: Bağlantı kimliğini girin (ör.
bqml-vertex-connection) - Konum Türü: Çoklu bölge seçildiğinden emin olun.
- Konum: Konumu seçin (ör.
US).
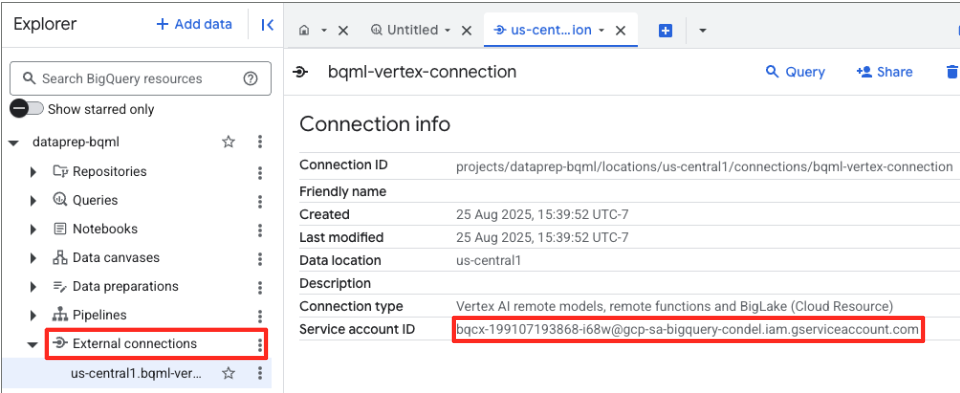
- Bağlantı oluşturulduktan sonra bir onay iletişim kutusu gösterilir. Gezgin sekmesinde Bağlantıya git'i veya Harici bağlantılar'ı tıklayın. Bağlantı ayrıntıları sayfasında, tam kimliği panonuza kopyalayın. Bu, BigQuery'nin Vertex AI'ı çağırmak için kullanacağı hizmet hesabı kimliğidir.
- Google Cloud Console gezinme menüsünde IAM ve yönetici > IAM'e gidin.
- "Erişim izni ver" düğmesini tıklayın.
- Önceki adımda kopyaladığınız hizmet hesabını Yeni ana hesaplar alanına yapıştırın.
- Rol açılır listesinde "Vertex AI kullanıcısı"nı atayın ve "Kaydet"i tıklayın.
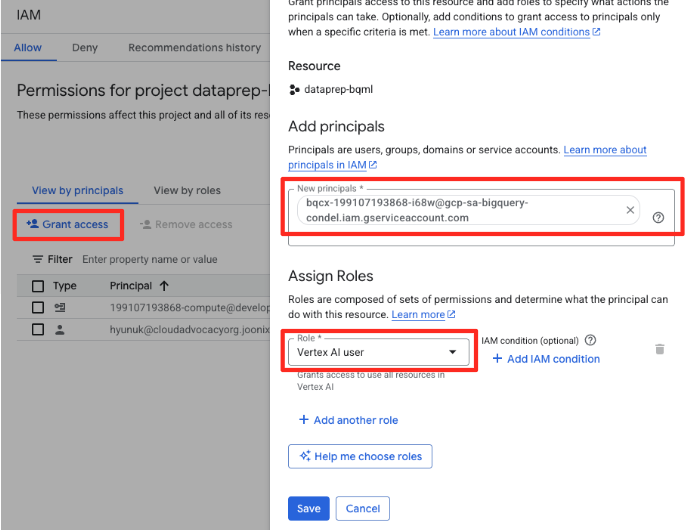
Bu kritik adım, BigQuery'nin sizin adınıza Vertex AI modellerini kullanmak için uygun yetkiye sahip olmasını sağlar.
Remote modeli oluşturma
BigQuery Studio'da yeni bir SQL düzenleyici sekmesi açın. Gemini'a bağlanacak BQML modelini burada tanımlarsınız.
Bu ifadeyle yeni bir model eğitilmez. Bu işlem, yetkilendirdiğiniz bağlantıyı kullanarak BigQuery'de güçlü ve önceden eğitilmiş bir gemini-embedding-001 modele işaret eden bir referans oluşturur.
Aşağıdaki SQL komut dosyasının tamamını kopyalayıp BigQuery düzenleyiciye yapıştırın.
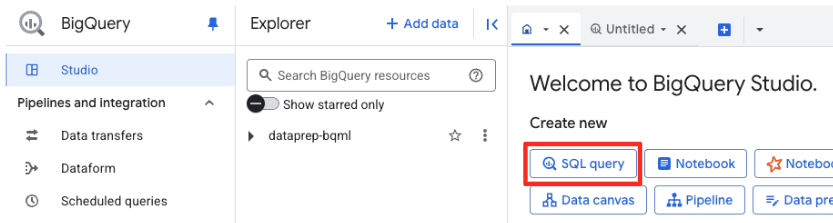
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
Yerleştirilmiş Öğeler Oluşturma
Şimdi vektör yerleştirmelerini oluşturmak için BQML modelimizi kullanacağız. Her satır için tek bir metin etiketini dönüştürmek yerine, her bir sanat eseri için daha zengin ve anlamlı bir "anlamsal özet" oluşturmak üzere daha gelişmiş bir yaklaşım kullanacağız. Bu sayede daha kaliteli yerleştirmeler ve daha doğru öneriler elde edebilirsiniz.
Bu sorgu, önemli bir ön işleme adımı gerçekleştirir:
- Önce geçici bir tablo oluşturmak için
WITHdeyimini kullanır. - İçinde, tek bir sanat eseriyle ilgili tüm bilgileri tek bir satırda birleştirmek için
GROUP BYherobject_id. - Ayrı metin açıklamalarının tümünü (ör. "Portre", "Kadın", "Tuval üzerine yağlı boya") tek ve kapsamlı bir metin dizesinde birleştirmek için
STRING_AGGişlevini kullanırız. Bu işlev, açıklamaları alaka düzeyine göre sıralar.
Bu birleştirilmiş metin, yapay zekaya sanat eseri hakkında çok daha zengin bir bağlam sunarak daha ayrıntılı ve güçlü vektör yerleştirmeleri oluşturmasını sağlar.
Yeni bir SQL düzenleyici sekmesinde aşağıdaki sorguyu yapıştırıp çalıştırın:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
Bu sorgu yaklaşık 10 dakika sürer. Sorgu tamamlandıktan sonra sonuçları doğrulayın. Gezgin panelinde yeni artwork_embeddings tablonuzu bulup tıklayın. Tablo şeması görüntüleyicide object_id, vektörleri içeren yeni ml_generate_text_embedding_result sütunu ve kaynak metin olarak kullanılan aggregated_labels sütununu görürsünüz.
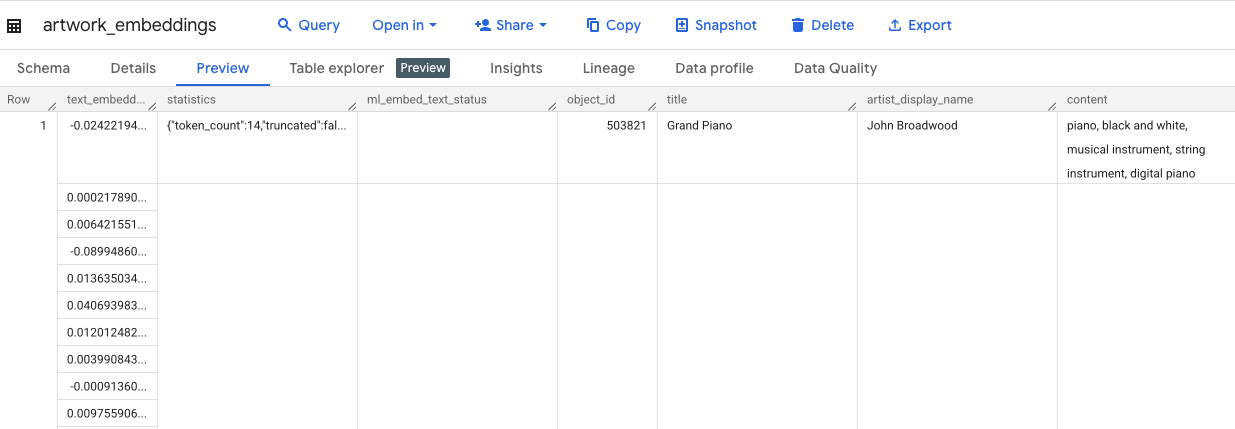
5. SQL ile Benzer Sanat Eserleri Bulma
Oluşturduğumuz yüksek kaliteli ve bağlam açısından zengin vektör yerleştirmeleri sayesinde, tematik olarak benzer sanat eserlerini bulmak SQL sorgusu çalıştırmak kadar kolaydır. Vektörler arasındaki kosinüs benzerliğini hesaplamak için ML.DISTANCE işlevini kullanırız. Yerleştirmelerimiz toplu metinden oluşturulduğu için benzerlik sonuçları daha doğru ve alakalı olacaktır.
- Yeni bir SQL düzenleyici sekmesine aşağıdaki sorguyu yapıştırın. Bu sorgu, bir öneri uygulamasının temel mantığını simüle eder:
- Öncelikle tek ve belirli bir sanat eseri için vektör seçilir (bu örnekte,
object_iddeğeri 436535 olan Van Gogh'un "Selviler" adlı eseri). - Ardından, bu tek vektör ile tablodaki diğer tüm vektörler arasındaki mesafeyi hesaplar.
- Son olarak, en yakın 10 eşleşmeyi bulmak için sonuçları mesafeye göre (daha kısa mesafe daha fazla benzerlik anlamına gelir) sıralar.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- Sorguyu çalıştırın. Sonuçlarda, en yakın eşleşmeler en üstte olacak şekilde
object_idlistelenir. Kaynak resim, 0 mesafeyle ilk sırada görünür. Bu, yapay zeka öneri motoruna güç veren temel mantıktır ve bunu tamamen BigQuery'de yalnızca SQL kullanarak oluşturmuşsunuzdur.
6. (İSTEĞE BAĞLI) Demoyu Cloud Shell'de çalıştırma
Bu codelab'deki kavramları hayata geçirmek için klonladığınız depoda basit bir web uygulaması bulunur. Bu isteğe bağlı demo, görsel arama motoruna güç vermek için oluşturduğunuz artwork_embeddings tablosunu kullanır. Böylece, yapay zeka destekli önerileri uygulamalı olarak görebilirsiniz.
Demoyu Cloud Shell'de çalıştırmak için aşağıdaki adımları uygulayın:
- Ortam değişkenlerini ayarlayın: Uygulamayı çalıştırmadan önce PROJECT_ID ve BIGQUERY_DATASET ortam değişkenlerini ayarlamanız gerekir.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- Bağımlılıkları yükleyin ve arka uç sunucusunu başlatın.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- Ön uç uygulamasını çalıştırmak için ikinci bir terminal sekmesine ihtiyacınız vardır. Yeni bir Cloud Shell sekmesi açmak için "+" simgesini tıklayın.

- Şimdi yeni sekmede, bağımlılıkları yüklemek ve ön uç sunucusunu çalıştırmak için aşağıdaki komutu yürütün.
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- Uygulamayı önizleme: Cloud Shell araç çubuğunda Web Önizlemesi simgesini tıklayın ve 5173 numaralı bağlantı noktasında önizle'yi seçin. Bu işlem, uygulamanın çalıştığı yeni bir tarayıcı sekmesi açar. Artık uygulamayı kullanarak sanat eserlerini arayabilir ve benzerlik arama özelliğini kullanabilirsiniz.
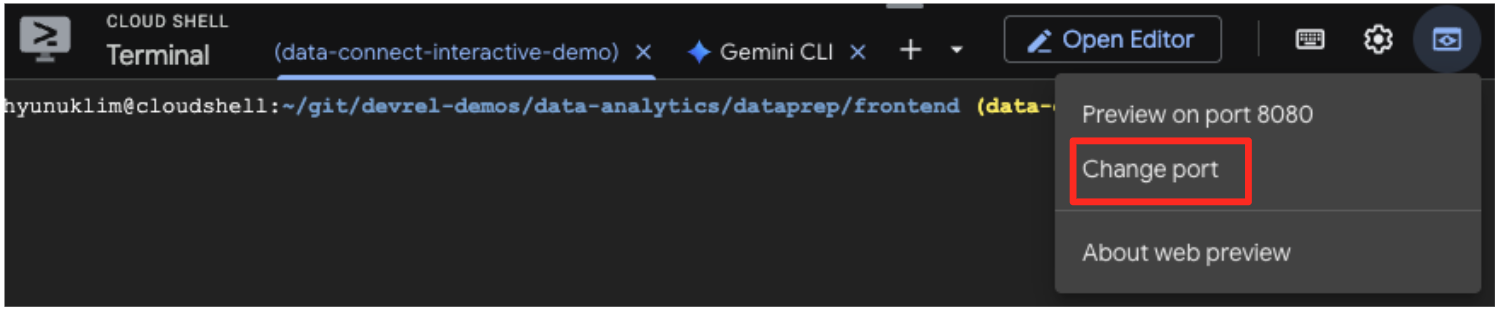
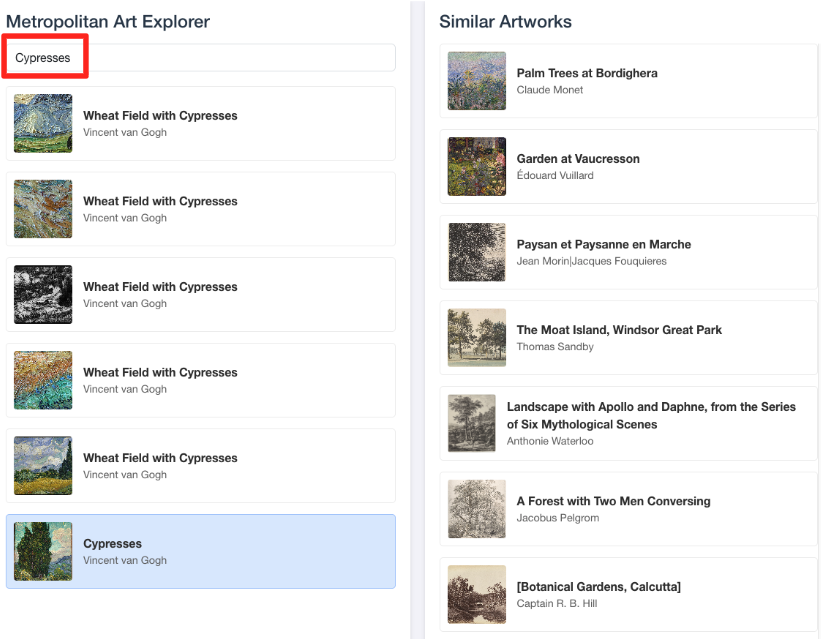
- Bu görsel demoyu BigQuery SQL düzenleyicide yaptığınız çalışmaya geri bağlamak için arama çubuğuna "Cypresses" yazmayı deneyin. Bu,
ML.DISTANCEsorgusunda kullandığınız eserle(object_id=436535) aynıdır. Ardından, sol panelde görünen Serviler resmini tıkladığınızda sonuçları sağ tarafta görürsünüz. Uygulama, en benzer sanat eserlerini göstererek oluşturduğunuz vektör benzerliği aramasının gücünü görsel olarak gösterir.
7. Ortamınızı temizleme
Bu codelab'de kullanılan kaynaklar için Google Cloud hesabınızın gelecekte ücretlendirilmesini önlemek istiyorsanız oluşturduğunuz kaynakları silmeniz gerekir.
Hizmet hesabını, BigQuery bağlantısını, GCS Bucket'ı ve BigQuery veri kümesini kaldırmak için Cloud Shell terminalinizde aşağıdaki komutları çalıştırın.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
BigQuery bağlantısını ve GCS paketini kaldırma
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
BigQuery veri kümesini silme
Son olarak, BigQuery veri kümesini silin. Bu komut geri alınamaz. -f (force) işareti, onay istemeden veri kümesini ve tüm tablolarını kaldırır.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. Tebrikler!
Uçtan uca, yapay zeka destekli bir veri ardışık düzenini başarıyla oluşturdunuz.
Bir GCS paketinde ham CSV dosyasıyla başladınız, karmaşık JSON verilerini almak ve düzleştirmek için BigQuery Data Prep'in az kodlu arayüzünü kullandınız, Gemini modeliyle yüksek kaliteli vektör yerleştirmeleri oluşturmak için güçlü bir BQML uzak modeli oluşturdunuz ve ilgili öğeleri bulmak için bir benzerlik arama sorgusu yürüttünüz.
Artık Google Cloud'da yapay zeka destekli iş akışları oluşturmak için temel bir kalıba sahipsiniz. Bu kalıp sayesinde ham verileri hızlı ve kolay bir şekilde akıllı uygulamalara dönüştürebilirsiniz.
Sırada ne var?
- Sonuçlarınızı Looker Studio'da görselleştirme:
artwork_embeddingsBigQuery tablonuzu doğrudan Looker Studio'ya bağlayın (ücretsizdir). Kullanıcıların bir sanat eseri seçebileceği ve en benzer parçaların görsel galerisini görebileceği etkileşimli bir kontrol paneli oluşturabilirsiniz. Bunun için herhangi bir ön uç kodu yazmanız gerekmez. - Planlanmış sorgularla otomasyon: Yerleştirmelerinizi güncel tutmak için karmaşık bir düzenleme aracına ihtiyacınız yoktur.
ML.GENERATE_TEXT_EMBEDDINGsorgusunu günlük veya haftalık olarak otomatik şekilde yeniden çalıştırmak için BigQuery'nin yerleşik Planlı Sorgular özelliğini kullanın. - Gemini CLI ile uygulama oluşturma: İhtiyacınızı düz metin olarak açıklayarak Gemini CLI ile eksiksiz bir uygulama oluşturun. Bu sayede, Python kodunu manuel olarak yazmadan benzerlik aramanız için hızlıca çalışan bir prototip oluşturabilirsiniz.
- Belgeleri okuyun: