
1. Giới thiệu
Nhà phân tích dữ liệu thường phải đối mặt với dữ liệu có giá trị bị khoá ở các định dạng bán cấu trúc như tải trọng JSON. Việc trích xuất và chuẩn bị dữ liệu này để phân tích và học máy thường là một trở ngại kỹ thuật đáng kể, thường đòi hỏi các tập lệnh ETL phức tạp và sự can thiệp của nhóm kỹ thuật dữ liệu.
Lớp học lập trình này cung cấp một bản thiết kế kỹ thuật để các nhà phân tích dữ liệu có thể tự mình vượt qua thách thức này. Nó minh hoạ phương pháp "ít mã" để xây dựng một quy trình AI toàn diện. Bạn sẽ tìm hiểu cách chuyển từ một tệp CSV thô trong Google Cloud Storage sang hỗ trợ một tính năng đề xuất dựa trên AI, chỉ bằng cách sử dụng các công cụ có trong BigQuery Studio.
Mục tiêu chính là minh hoạ một quy trình làm việc mạnh mẽ, nhanh chóng và thân thiện với nhà phân tích, vượt xa các quy trình phức tạp, nặng về mã để tạo ra giá trị kinh doanh thực sự từ dữ liệu của bạn.
Điều kiện tiên quyết
- Có kiến thức cơ bản về Google Cloud Console
- Kỹ năng cơ bản về giao diện dòng lệnh và Google Cloud Shell
Kiến thức bạn sẽ học được
- Cách nhập và chuyển đổi tệp CSV trực tiếp từ Google Cloud Storage bằng BigQuery Data Preparation.
- Cách sử dụng các phép biến đổi không cần lập trình để phân tích cú pháp và làm phẳng các chuỗi JSON lồng nhau trong dữ liệu của bạn.
- Cách tạo mô hình từ xa BigQuery ML kết nối với mô hình nền tảng Vertex AI để nhúng văn bản.
- Cách sử dụng hàm
ML.GENERATE_TEXT_EMBEDDINGđể chuyển đổi dữ liệu dạng văn bản thành vectơ số. - Cách sử dụng hàm
ML.DISTANCEđể tính độ tương đồng về cô-sin và tìm các mục tương tự nhất trong tập dữ liệu của bạn.
Bạn cần có
- Tài khoản Google Cloud và dự án trên Google Cloud
- Một trình duyệt web như Chrome
Các khái niệm chính
- Chuẩn bị dữ liệu BigQuery: Một công cụ trong BigQuery Studio cung cấp giao diện trực quan, tương tác để làm sạch và chuẩn bị dữ liệu. Công cụ này đề xuất các quy tắc chuyển đổi và cho phép người dùng tạo các quy trình dữ liệu với ít mã nhất.
- Mô hình từ xa BQML: Một đối tượng BigQuery ML đóng vai trò là một proxy cho mô hình được lưu trữ trên Vertex AI (chẳng hạn như Gemini). Nhờ đó, bạn có thể gọi các mô hình AI mạnh mẽ, được huấn luyện trước bằng cú pháp SQL quen thuộc.
- Vectơ nhúng: Một biểu diễn bằng số của dữ liệu, chẳng hạn như văn bản hoặc hình ảnh. Trong lớp học lập trình này, chúng ta sẽ chuyển đổi nội dung mô tả bằng văn bản về tác phẩm nghệ thuật thành vectơ, trong đó nội dung mô tả tương tự sẽ tạo ra các vectơ "gần" nhau hơn trong không gian đa chiều.
- Độ tương đồng cosine: Một chỉ số toán học được dùng để xác định mức độ tương đồng giữa hai vectơ. Đây là cốt lõi của logic trong công cụ đề xuất của chúng tôi, được hàm
ML.DISTANCEdùng để tìm ra những tác phẩm nghệ thuật "gần" (tương tự) nhất.
2. Thiết lập và yêu cầu
Khởi động Cloud Shell
Mặc dù có thể vận hành Google Cloud từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, bạn sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trên Cloud.
Trên Bảng điều khiển Google Cloud, hãy nhấp vào biểu tượng Cloud Shell trên thanh công cụ ở trên cùng bên phải:

Quá trình này chỉ mất vài phút để cung cấp và kết nối với môi trường. Khi quá trình này kết thúc, bạn sẽ thấy như sau:

Máy ảo này được trang bị tất cả các công cụ phát triển mà bạn cần. Nó cung cấp một thư mục chính có dung lượng 5 GB và chạy trên Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và hoạt động xác thực. Bạn có thể thực hiện mọi thao tác trong lớp học lập trình này trong trình duyệt. Bạn không cần cài đặt bất cứ thứ gì.
Bật các API bắt buộc và định cấu hình môi trường
Trong Cloud Shell, hãy chạy các lệnh sau để đặt mã dự án, xác định các biến môi trường và bật tất cả API cần thiết cho lớp học lập trình này.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
Tạo một tập dữ liệu BigQuery và một Nhóm GCS
Tạo một tập dữ liệu BigQuery mới để lưu trữ các bảng và một bộ chứa Google Cloud Storage để lưu trữ tệp CSV nguồn.
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
Chuẩn bị và tải dữ liệu mẫu lên
Sao chép kho lưu trữ GitHub chứa tệp CSV mẫu rồi tải tệp đó lên bộ chứa GCS mà bạn vừa tạo.
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. Từ GCS đến BigQuery bằng tính năng Chuẩn bị dữ liệu
Trong phần này, chúng ta sẽ sử dụng một giao diện trực quan, không cần mã để nhập tệp CSV từ GCS, làm sạch tệp đó và tải vào một bảng BigQuery mới.
Khởi chạy tính năng Chuẩn bị dữ liệu và Kết nối với nguồn
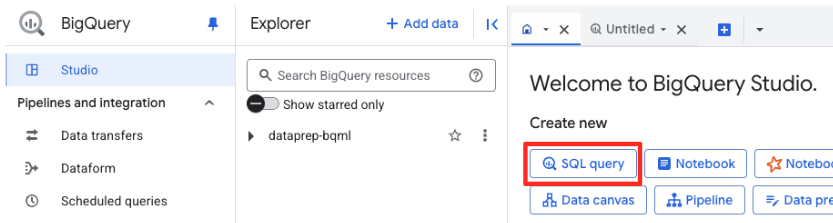
- Trong Google Cloud Console, hãy chuyển đến BigQuery Studio.
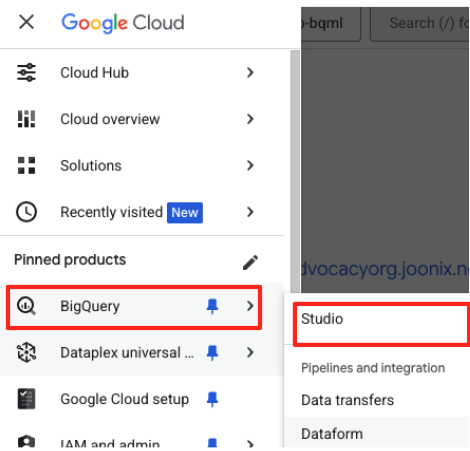
- Trong trang chào mừng, hãy nhấp vào thẻ Chuẩn bị dữ liệu để bắt đầu.
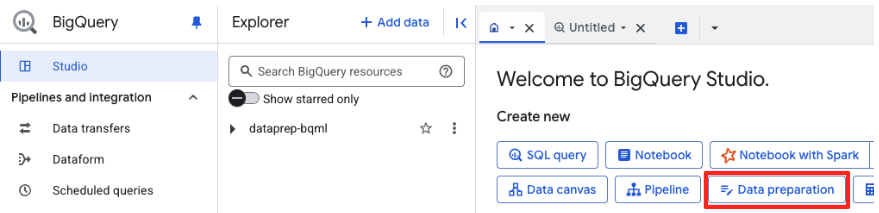
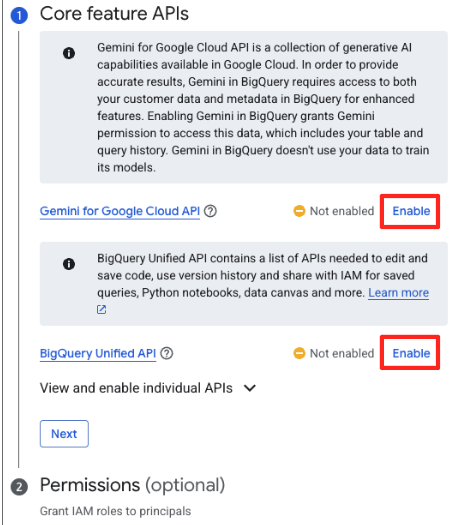
- Nếu đây là lần đầu tiên, bạn có thể cần bật các API bắt buộc. Nhấp vào Bật cho cả "Gemini for Google Cloud API" và "BigQuery Unified API". Sau khi bật, bạn có thể đóng bảng điều khiển này.
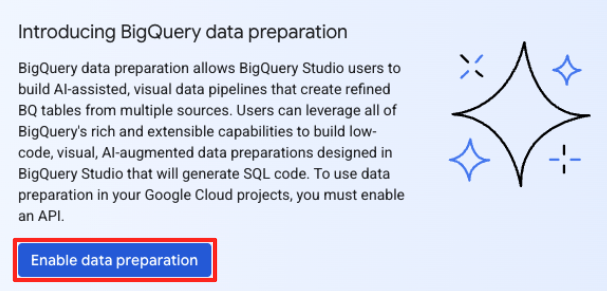
- Trong cửa sổ chính Chuẩn bị dữ liệu, trong mục "chọn nguồn dữ liệu khác", hãy nhấp vào Google Cloud Storage. Thao tác này sẽ mở bảng điều khiển "Chuẩn bị dữ liệu" ở bên phải.
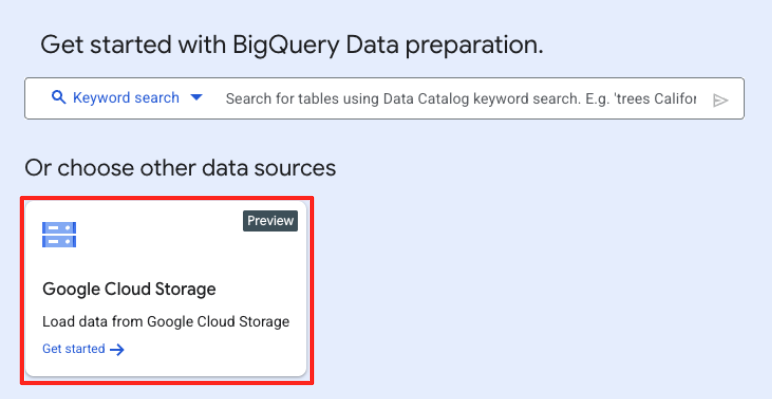
- Nhấp vào nút Duyệt qua để chọn tệp nguồn.
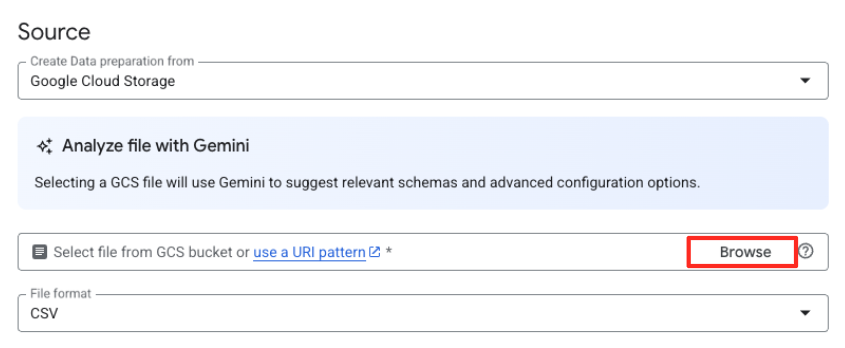
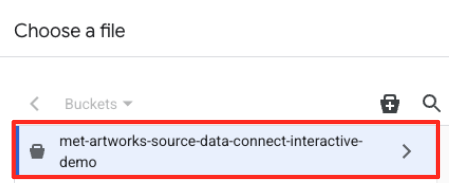
- Chuyển đến vùng lưu trữ GCS mà bạn đã tạo trước đó (
met-artworks-source-...) rồi chọn tệpdataprep-met-bqml.csv. Nhấp vào Chọn.
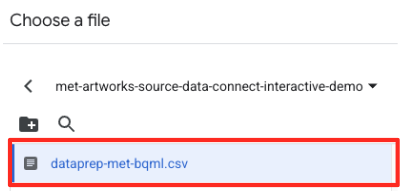
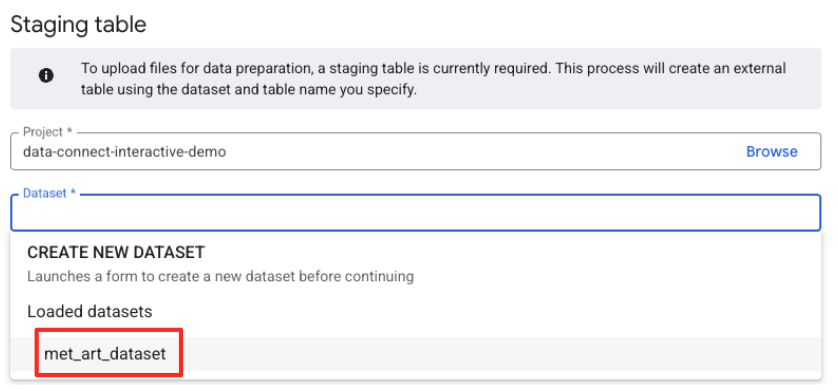
- Tiếp theo, bạn cần định cấu hình một bảng dàn dựng.
- Đối với Tập dữ liệu, hãy chọn
met_art_datasetmà bạn đã tạo. - Đối với Tên bảng, hãy nhập một tên, ví dụ:
temp. - Nhấp vào Tạo.
Chuyển đổi và làm sạch dữ liệu
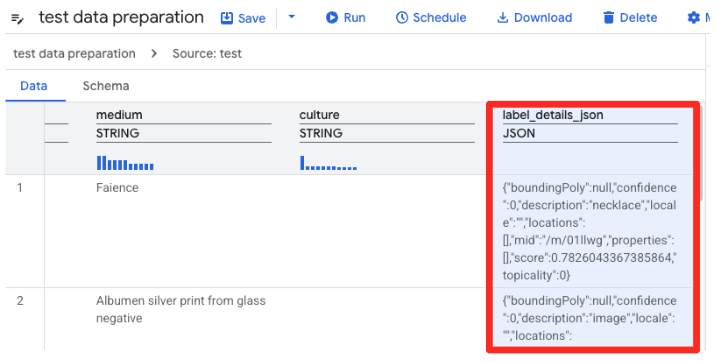
- Tính năng Chuẩn bị dữ liệu của BigQuery hiện sẽ tải bản xem trước của tệp CSV. Tìm cột
label_details_jsonchứa chuỗi JSON dài. Nhấp vào tiêu đề cột để chọn cột đó.
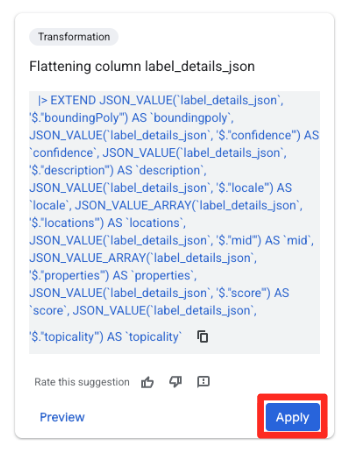
- Trong bảng Đề xuất ở bên phải, Gemini trong BigQuery sẽ tự động đề xuất các quy tắc chuyển đổi có liên quan. Nhấp vào nút Áp dụng trên thẻ "Làm phẳng cột
label_details_json". Thao tác này sẽ trích xuất các trường lồng nhau (description,score, v.v.) vào các cột cấp cao nhất của riêng chúng.
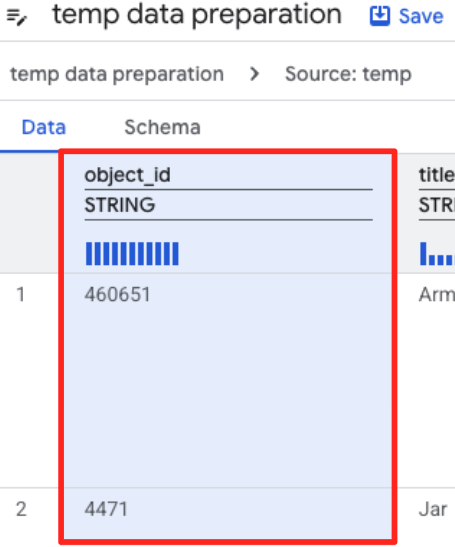
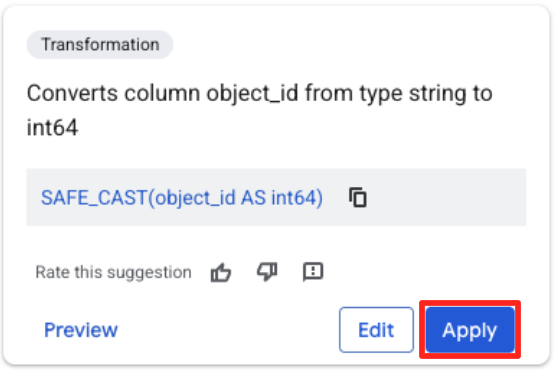
- Nhấp vào cột object_id, rồi nhấp vào nút áp dụng trên "Chuyển đổi cột
object_idtừ loạistringsangint64.
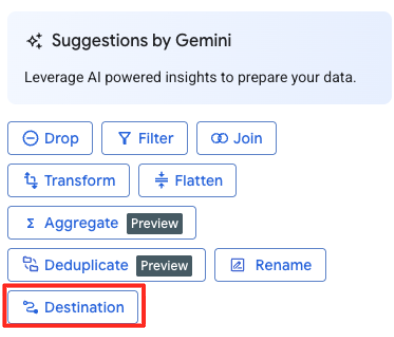
Xác định đích đến và chạy công việc
- Trong bảng điều khiển bên phải, hãy nhấp vào nút Đích đến để định cấu hình đầu ra của phép biến đổi.
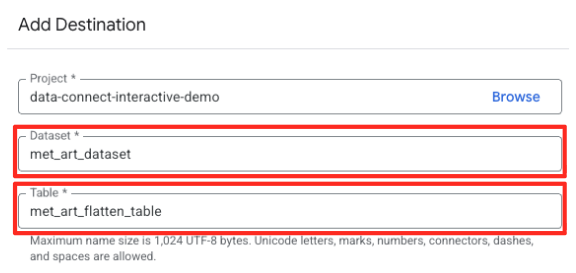
- Đặt thông tin chi tiết về đích đến:
- Tập dữ liệu phải được điền sẵn bằng
met_art_dataset. - Nhập tên Bảng mới cho đầu ra:
met_art_flatten_table. - Nhấp vào Lưu.
- Nhấp vào nút Chạy và đợi cho đến khi công việc chuẩn bị dữ liệu hoàn tất.
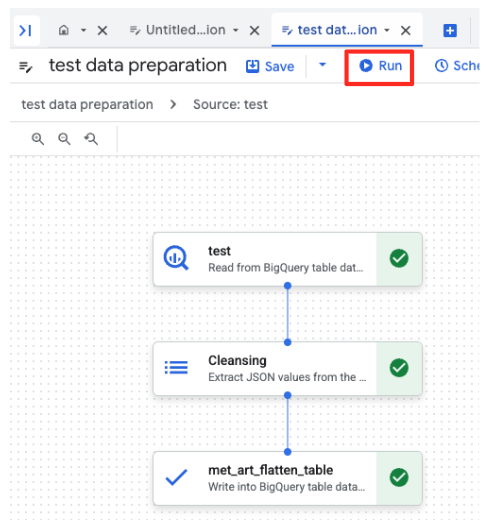
- Bạn có thể theo dõi tiến trình của công việc trong thẻ Thực thi ở cuối trang. Sau vài giây, công việc sẽ hoàn tất.
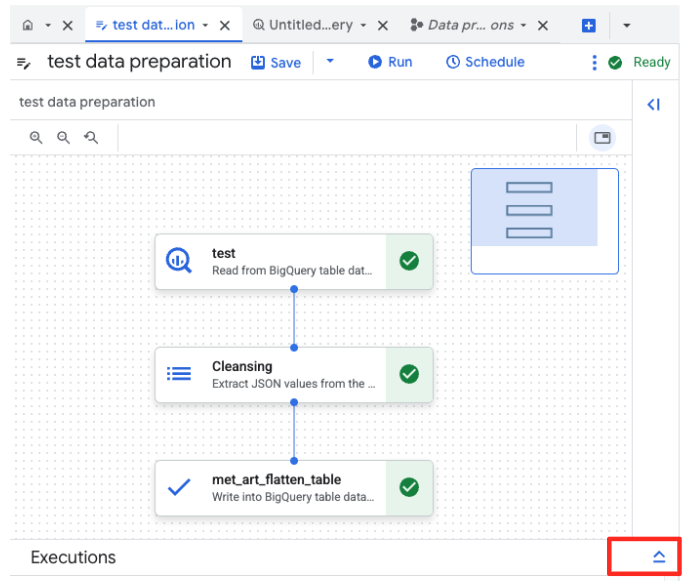
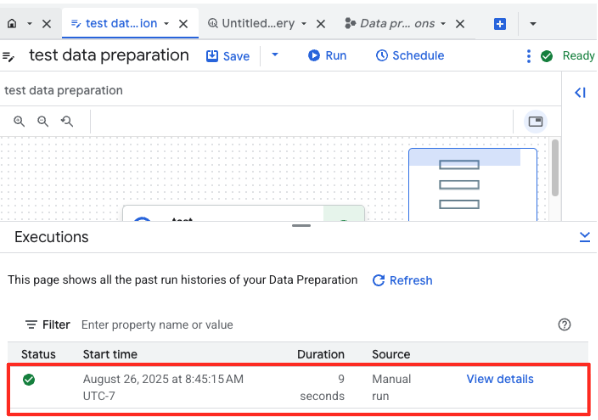
4. Tạo vectơ nhúng bằng BQML
Giờ đây, khi dữ liệu đã được làm sạch và có cấu trúc, chúng ta sẽ sử dụng BigQuery ML cho tác vụ AI cốt lõi: chuyển đổi nội dung mô tả bằng văn bản của tác phẩm nghệ thuật thành các vectơ nhúng dạng số.
Tạo mối kết nối BigQuery
Để cho phép BigQuery giao tiếp với các dịch vụ của Vertex AI, trước tiên, bạn phải tạo một BigQuery Connection.
- Trong bảng điều khiển Trình khám phá của BigQuery Studio, hãy nhấp vào nút "+ Thêm dữ liệu".
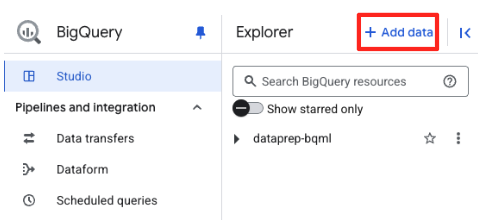
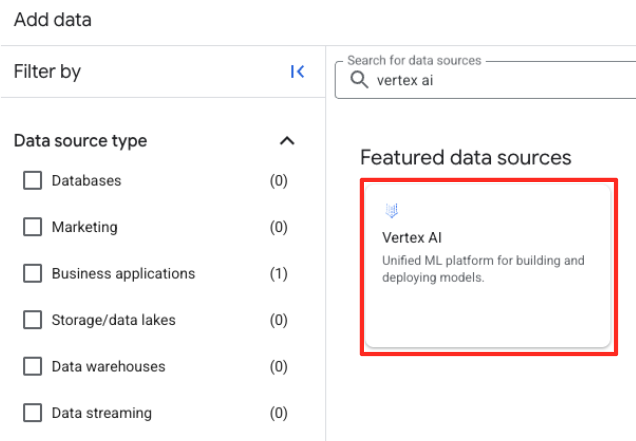
- Trong bảng điều khiển bên phải, hãy dùng thanh tìm kiếm để nhập
Vertex AI. Chọn mục đó rồi chọn liên kết BigQuery trong danh sách được lọc.
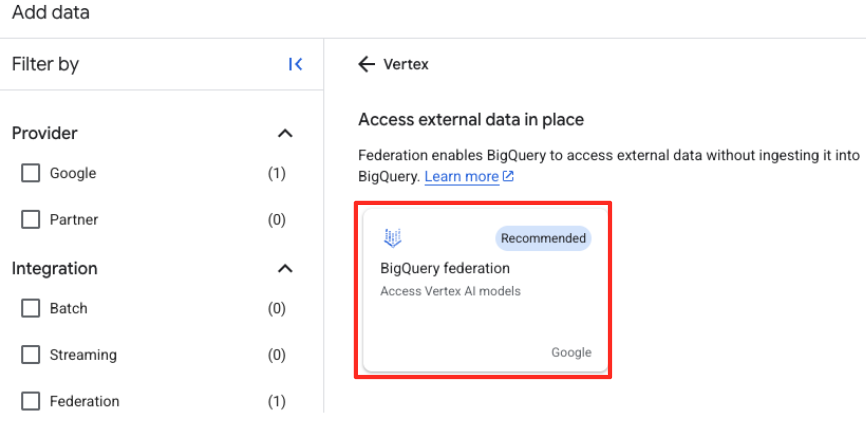
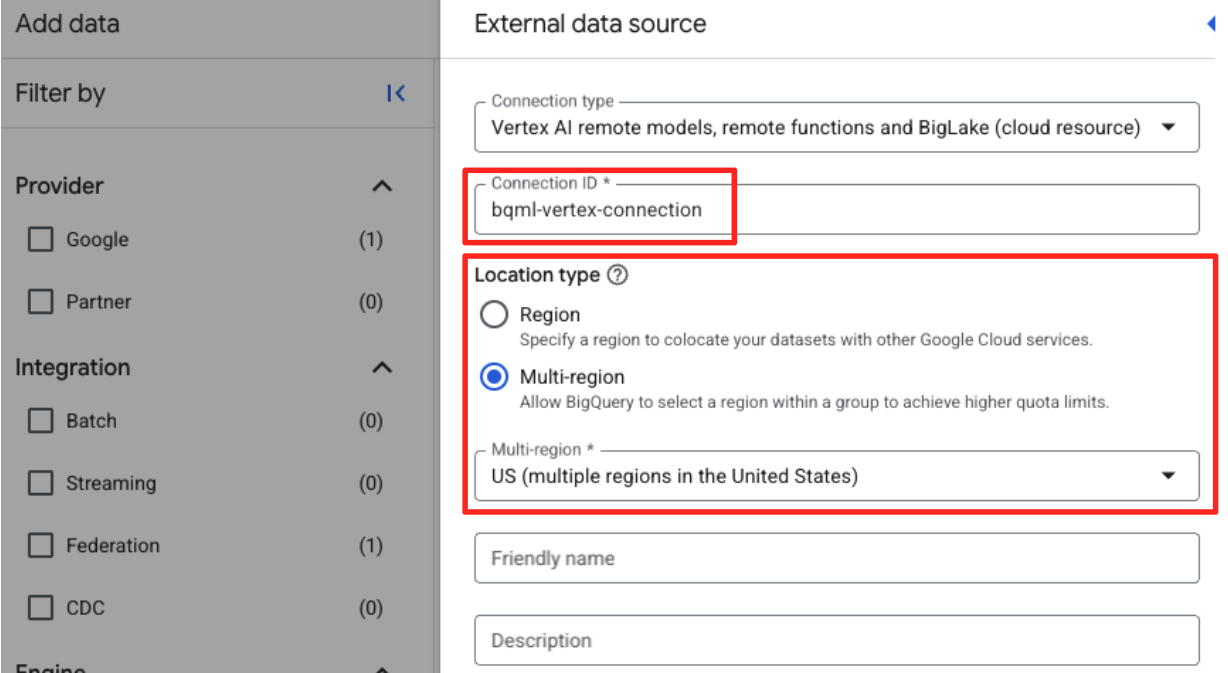
- Thao tác này sẽ mở biểu mẫu Nguồn dữ liệu bên ngoài. Điền các thông tin sau:
- Mã kết nối: Nhập mã kết nối (ví dụ:
bqml-vertex-connection) - Loại vị trí: Đảm bảo bạn đã chọn Nhiều khu vực.
- Vị trí: Chọn vị trí (ví dụ:
US).
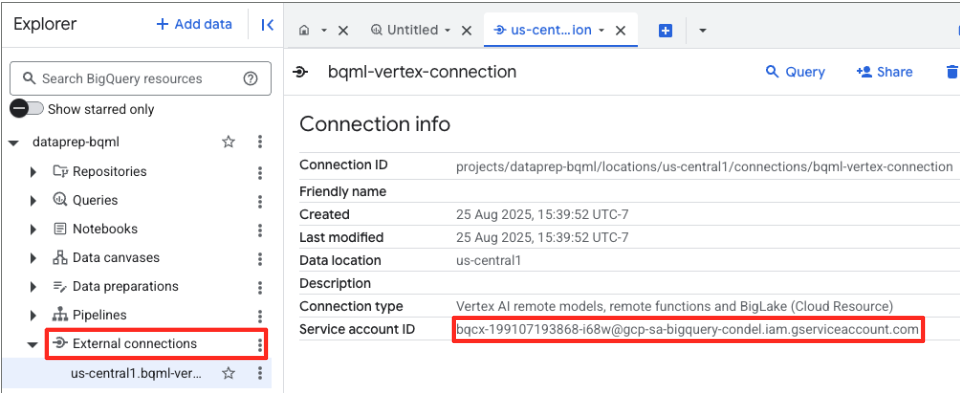
- Sau khi kết nối được tạo, một hộp thoại xác nhận sẽ xuất hiện. Nhấp vào Go to Connection (Chuyển đến phần Kết nối) hoặc External connections (Kết nối bên ngoài) trong thẻ Explorer (Trình khám phá). Trên trang thông tin chi tiết về mối kết nối, hãy sao chép toàn bộ mã nhận dạng vào bảng nhớ tạm. Đây là danh tính tài khoản dịch vụ mà BigQuery sẽ dùng để gọi Vertex AI.
- Trong trình đơn điều hướng của Google Cloud Console, hãy chuyển đến phần IAM & admin (Quản lý danh tính và quyền truy cập) > IAM.
- Nhấp vào nút "Cấp quyền truy cập"
- Dán tài khoản dịch vụ mà bạn đã sao chép ở bước trước vào trường Tài khoản chính mới.
- Chỉ định "Người dùng Vertex AI" trong trình đơn thả xuống Vai trò, rồi nhấp vào "Lưu".
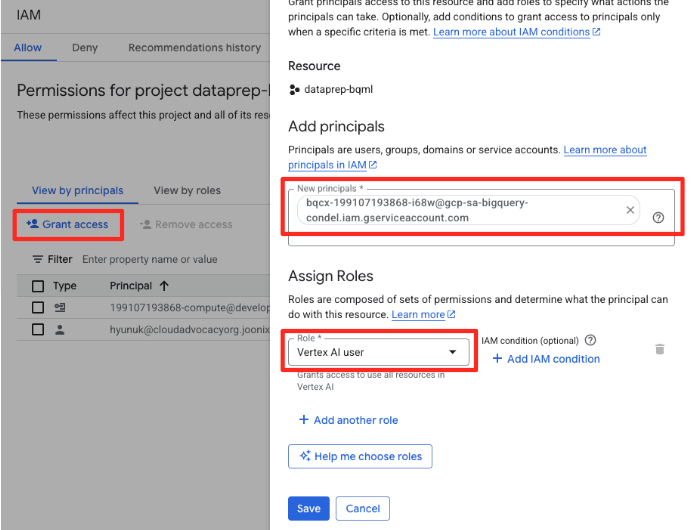
Bước quan trọng này giúp đảm bảo BigQuery có quyền uỷ quyền thích hợp để sử dụng các mô hình Vertex AI thay cho bạn.
Tạo một mô hình Remote
Trong BigQuery Studio, hãy mở một thẻ trình chỉnh sửa SQL mới. Đây là nơi bạn sẽ xác định mô hình BQML kết nối với Gemini.
Câu lệnh này không huấn luyện mô hình mới. Thao tác này chỉ tạo một thông tin tham chiếu trong BigQuery trỏ đến một mô hình gemini-embedding-001 mạnh mẽ, được huấn luyện trước bằng cách sử dụng mối kết nối mà bạn vừa uỷ quyền.
Sao chép toàn bộ tập lệnh SQL bên dưới rồi dán vào trình chỉnh sửa BigQuery.
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
Tạo vectơ nhúng
Giờ đây, chúng ta sẽ sử dụng mô hình BQML để tạo các vectơ nhúng. Thay vì chỉ chuyển đổi một nhãn văn bản cho mỗi hàng, chúng tôi sẽ sử dụng một phương pháp tinh vi hơn để tạo ra "bản tóm tắt ngữ nghĩa" phong phú và có ý nghĩa hơn cho mỗi tác phẩm nghệ thuật. Điều này sẽ giúp bạn có được các mục nhúng chất lượng cao hơn và đề xuất chính xác hơn.
Truy vấn này thực hiện một bước tiền xử lý quan trọng:
- Thao tác này sử dụng một mệnh đề
WITHđể tạo bảng tạm thời trước. - Trong đó, chúng ta
GROUP BYmỗiobject_idđể kết hợp tất cả thông tin về một tác phẩm nghệ thuật vào một hàng. - Chúng ta sử dụng hàm
STRING_AGGđể hợp nhất tất cả nội dung mô tả văn bản riêng biệt (chẳng hạn như "Chân dung", "Phụ nữ", "Sơn dầu trên vải") thành một chuỗi văn bản duy nhất và toàn diện, sắp xếp theo điểm số mức độ liên quan.
Văn bản kết hợp này cung cấp cho AI ngữ cảnh phong phú hơn nhiều về tác phẩm nghệ thuật, dẫn đến các vectơ nhúng chi tiết và mạnh mẽ hơn.
Trong thẻ trình chỉnh sửa SQL mới, hãy dán và chạy truy vấn sau:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
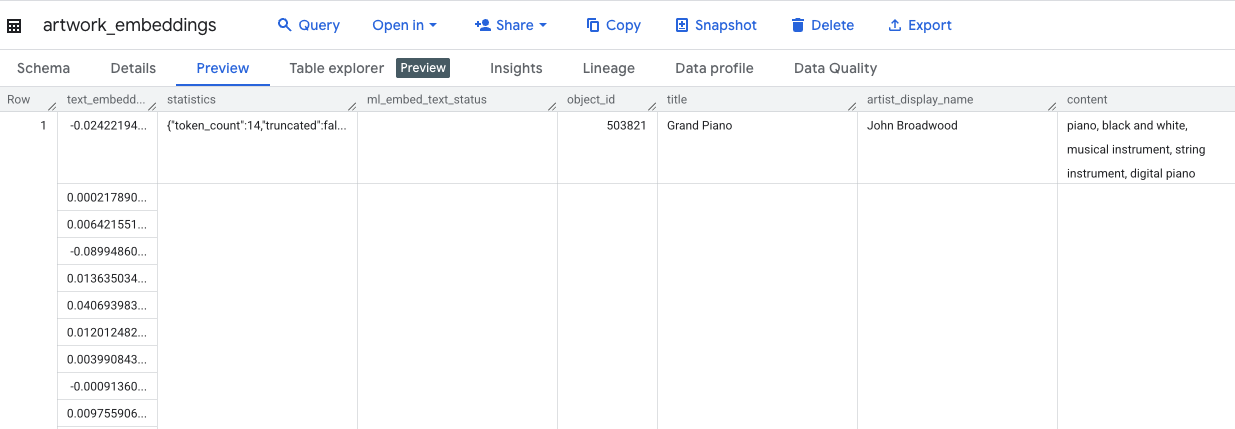
Truy vấn này sẽ mất khoảng 10 phút. Sau khi truy vấn hoàn tất, hãy xác minh kết quả. Trong bảng điều khiển Trình khám phá, hãy tìm bảng artwork_embeddings mới rồi nhấp vào bảng đó. Trong trình xem giản đồ bảng, bạn sẽ thấy object_id, cột ml_generate_text_embedding_result mới chứa các vectơ, cũng như cột aggregated_labels được dùng làm văn bản nguồn.
5. Tìm các tác phẩm nghệ thuật tương tự bằng SQL
Với các vectơ nhúng chất lượng cao và giàu ngữ cảnh mà chúng tôi tạo ra, việc tìm các tác phẩm nghệ thuật tương tự về chủ đề cũng đơn giản như chạy một truy vấn SQL. Chúng ta dùng hàm ML.DISTANCE để tính độ tương đồng về cô-sin giữa các vectơ. Vì các vectơ nhúng của chúng tôi được tạo từ văn bản tổng hợp, nên kết quả về mức độ tương đồng sẽ chính xác và phù hợp hơn.
- Trong thẻ trình chỉnh sửa SQL mới, hãy dán truy vấn sau. Truy vấn này mô phỏng logic cốt lõi của một ứng dụng đề xuất:
- Trước tiên, nó sẽ chọn vectơ cho một tác phẩm nghệ thuật cụ thể (trong trường hợp này là bức "Cây bách" của Van Gogh, có
object_idlà 436535). - Sau đó, hệ thống sẽ tính khoảng cách giữa vectơ đó và tất cả các vectơ khác trong bảng.
- Cuối cùng, hệ thống sẽ sắp xếp kết quả theo khoảng cách (khoảng cách càng nhỏ thì càng giống nhau) để tìm ra 10 kết quả phù hợp nhất.
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- Chạy truy vấn. Kết quả sẽ liệt kê các
object_id, trong đó những kết quả phù hợp nhất sẽ nằm ở trên cùng. Hình minh hoạ nguồn sẽ xuất hiện trước với khoảng cách là 0. Đây là logic cốt lõi hỗ trợ một công cụ đề xuất dựa trên AI và bạn đã xây dựng hoàn toàn logic này trong BigQuery chỉ bằng cách sử dụng SQL.
6. (KHÔNG BẮT BUỘC) Chạy bản minh hoạ trong Cloud Shell
Để minh hoạ các khái niệm trong lớp học lập trình này, kho lưu trữ mà bạn đã sao chép có chứa một ứng dụng web đơn giản. Bản minh hoạ không bắt buộc này sử dụng bảng artwork_embeddings mà bạn đã tạo để hỗ trợ một công cụ tìm kiếm bằng hình ảnh, cho phép bạn xem các đề xuất dựa trên AI đang hoạt động.
Để chạy bản minh hoạ trong Cloud Shell, hãy làm theo các bước sau:
- Đặt biến môi trường: Trước khi chạy ứng dụng, bạn cần đặt các biến môi trường PROJECT_ID và BIGQUERY_DATASET.
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- Cài đặt các phần phụ thuộc và khởi động máy chủ phụ trợ.
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- Bạn sẽ cần một thẻ terminal thứ hai để chạy ứng dụng giao diện người dùng. Nhấp vào biểu tượng "+" để mở một thẻ Cloud Shell mới.

- Bây giờ, trong thẻ mới, hãy thực thi lệnh sau để cài đặt các phần phụ thuộc và chạy máy chủ giao diện người dùng
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
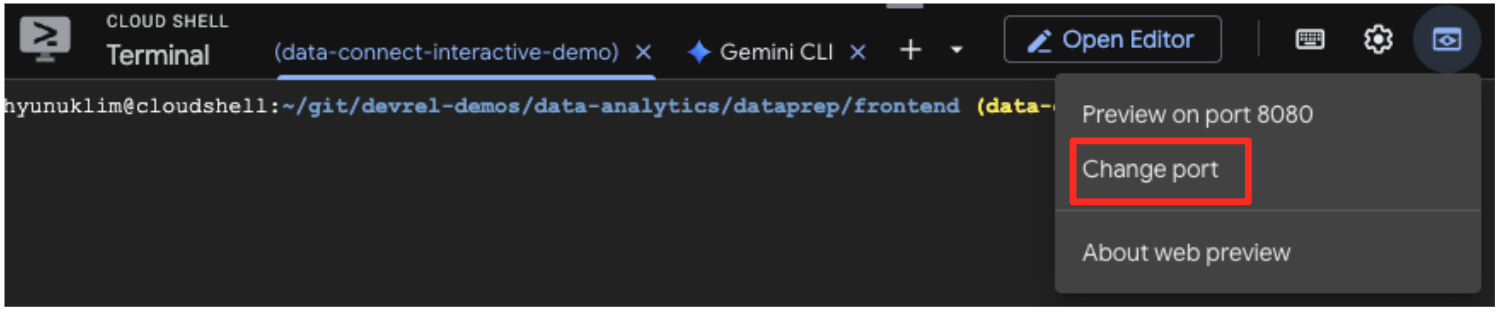
- Xem trước ứng dụng: Trong thanh công cụ Cloud Shell, hãy nhấp vào biểu tượng Xem trước trên web rồi chọn Xem trước trên cổng 5173. Thao tác này sẽ mở một thẻ trình duyệt mới có ứng dụng đang chạy. Giờ đây, bạn có thể dùng ứng dụng này để tìm kiếm tác phẩm nghệ thuật và xem tính năng tìm kiếm tương tự hoạt động.
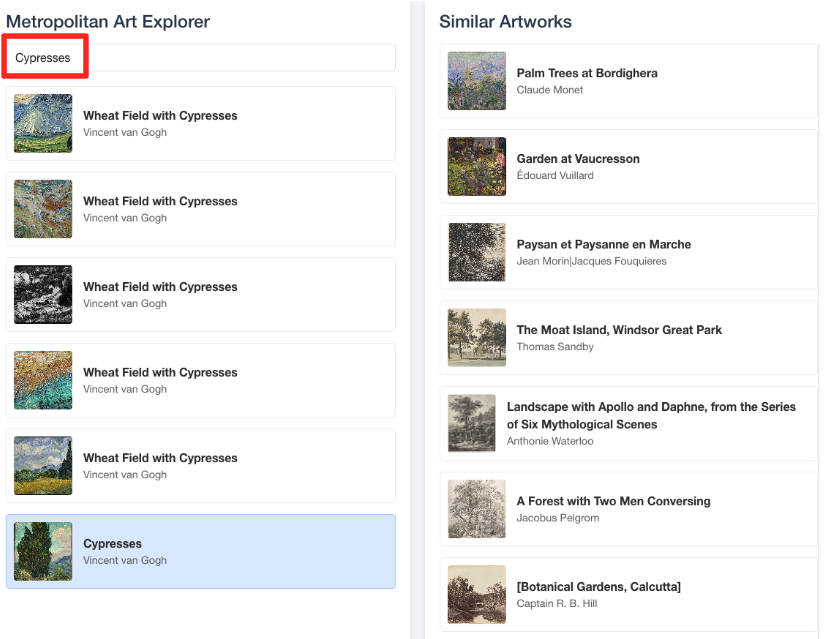
- Để kết nối bản minh hoạ trực quan này với công việc bạn đã thực hiện trong trình chỉnh sửa SQL BigQuery, hãy thử nhập "Cypresses" vào thanh tìm kiếm. Đây là tác phẩm nghệ thuật(
object_id=436535) mà bạn đã dùng trong truy vấnML.DISTANCE. Sau đó, hãy nhấp vào hình ảnh Cypresses khi hình ảnh này xuất hiện trong bảng điều khiển bên trái, bạn sẽ thấy kết quả ở bên phải. Ứng dụng này hiển thị những tác phẩm nghệ thuật tương tự nhất, minh hoạ trực quan sức mạnh của tính năng tìm kiếm tương tự theo vectơ mà bạn đã tạo.
7. Dọn dẹp môi trường
Để tránh phát sinh các khoản phí trong tương lai cho tài khoản Google Cloud của bạn đối với các tài nguyên được dùng trong lớp học lập trình này, bạn nên xoá các tài nguyên mà mình đã tạo.
Chạy các lệnh sau trong thiết bị đầu cuối Cloud Shell để xoá tài khoản dịch vụ, mối kết nối BigQuery, Nhóm GCS và tập dữ liệu BigQuery.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
Xoá mối kết nối BigQuery và Nhóm lưu trữ trên Google Cloud
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
Xoá tập dữ liệu BigQuery
Cuối cùng, hãy xoá tập dữ liệu BigQuery. Bạn sẽ không thể huỷ lệnh này sau khi thực hiện. Cờ -f (force) sẽ xoá tập dữ liệu và tất cả các bảng của tập dữ liệu đó mà không cần nhắc xác nhận.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. Xin chúc mừng!
Bạn đã xây dựng thành công một quy trình dữ liệu toàn diện dựa trên AI.
Bạn bắt đầu bằng một tệp CSV thô trong một vùng chứa GCS, sử dụng giao diện ít mã nguồn của BigQuery Data Prep để nhập và làm phẳng dữ liệu JSON phức tạp, tạo một mô hình từ xa BQML mạnh mẽ để tạo các embeddings chất lượng cao bằng mô hình Gemini và thực hiện một truy vấn tìm kiếm tương tự để tìm các mục có liên quan.
Giờ đây, bạn đã nắm được mẫu cơ bản để xây dựng quy trình làm việc sử dụng AI trên Google Cloud, chuyển đổi dữ liệu thô thành các ứng dụng thông minh một cách nhanh chóng và đơn giản.
Các bước tiếp theo
- Trực quan hoá kết quả trong Looker Studio: Kết nối trực tiếp bảng
artwork_embeddingsBigQuery với Looker Studio (miễn phí!). Bạn có thể tạo một trang tổng quan tương tác, nơi người dùng có thể chọn một tác phẩm nghệ thuật và xem một thư viện trực quan gồm những tác phẩm tương tự nhất mà không cần viết mã giao diện người dùng. - Tự động hoá bằng truy vấn định kỳ: Bạn không cần một công cụ điều phối phức tạp để cập nhật các mục nhúng. Sử dụng tính năng Truy vấn định kỳ tích hợp sẵn của BigQuery để tự động chạy lại truy vấn
ML.GENERATE_TEXT_EMBEDDINGhằng ngày hoặc hằng tuần. - Tạo một ứng dụng bằng Gemini CLI: Sử dụng Gemini CLI để tạo một ứng dụng hoàn chỉnh chỉ bằng cách mô tả yêu cầu của bạn bằng văn bản thuần tuý. Nhờ đó, bạn có thể nhanh chóng tạo một nguyên mẫu hoạt động cho tính năng tìm kiếm tương tự mà không cần viết mã Python theo cách thủ công.
- Đọc tài liệu: