
1. 简介
数据分析师经常会遇到以 JSON 载荷等半结构化格式锁定的宝贵数据。提取和准备这些数据以供分析和机器学习,在过去一直是一项重大的技术障碍,通常需要复杂的 ETL 脚本和数据工程团队的介入。
此 Codelab 为数据分析师提供了一份技术蓝图,帮助他们独立克服这一挑战。它展示了一种“低代码”方法,用于构建端到端 AI 流水线。您将学习如何仅使用 BigQuery Studio 中提供的工具,将 Google Cloud Storage 中的原始 CSV 文件转换为由 AI 驱动的推荐功能。
主要目标是展示一种稳健、快速且便于分析师使用的工作流,该工作流可摆脱复杂且需要大量代码的流程,从数据中创造真正的业务价值。
前提条件
- 对 Google Cloud 控制台有基本的了解
- 具备命令行界面和 Google Cloud Shell 方面的基本技能
学习内容
- 如何使用 BigQuery Data Preparation 直接从 Google Cloud Storage 提取和转换 CSV 文件。
- 如何使用无代码转换来解析和展平数据中的嵌套 JSON 字符串。
- 如何创建连接到 Vertex AI 基础模型以进行文本嵌入的 BigQuery ML 远程模型。
- 如何使用
ML.GENERATE_TEXT_EMBEDDING函数将文本数据转换为数值向量。 - 如何使用
ML.DISTANCE函数计算余弦相似度并查找数据集中的最相似项。
所需条件
- Google Cloud 账号和 Google Cloud 项目
- 网络浏览器,例如 Chrome
主要概念
- BigQuery 数据准备:BigQuery Studio 中的一种工具,可提供用于数据清理和准备的互动式可视化界面。它会建议转换,并允许用户使用最少的代码构建数据流水线。
- BQML 远程模型:一种 BigQuery ML 对象,可充当 Vertex AI(如 Gemini)上托管的模型的代理。借助此功能,您可以使用熟悉的 SQL 语法调用强大的预训练 AI 模型。
- 向量嵌入:数据的数值表示形式,例如文本或图片。在此 Codelab 中,我们将把艺术品的文字说明转换为向量,其中相似的说明会生成在多维空间中“更接近”的向量。
- 余弦相似度:一种用于确定两个向量相似程度的数学度量。它是推荐引擎逻辑的核心,供
ML.DISTANCE函数用于查找“最接近”(最相似)的艺术品。
2. 设置和要求
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此 Codelab 中,您将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
在 Google Cloud 控制台 中,点击右上角工具栏中的 Cloud Shell 图标:

预配和连接到环境应该只需要片刻时间。完成后,您应该会看到如下内容:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证功能。您在此 Codelab 中的所有工作都可以在浏览器中完成。您无需安装任何程序。
启用所需的 API 并配置环境
在 Cloud Shell 中,运行以下命令以设置项目 ID、定义环境变量,并为此 Codelab 启用所有必需的 API。
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
创建 BigQuery 数据集和 GCS 存储分区
创建一个新的 BigQuery 数据集来存放我们的表,并创建一个 Google Cloud Storage 存储分区来存储我们的源 CSV 文件。
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
准备并上传示例数据
克隆包含示例 CSV 文件的 GitHub 代码库,然后将其上传到您刚刚创建的 GCS 存储分区。
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. 使用数据准备功能将数据从 GCS 迁移到 BigQuery
在此部分中,我们将使用可视化无代码界面从 GCS 中提取 CSV 文件,对其进行清理,然后将其加载到新的 BigQuery 表中。
启动“数据准备”并连接到来源
- 在 Google Cloud 控制台中,前往 BigQuery Studio。
- 在欢迎页面中,点击“数据准备”卡片即可开始。
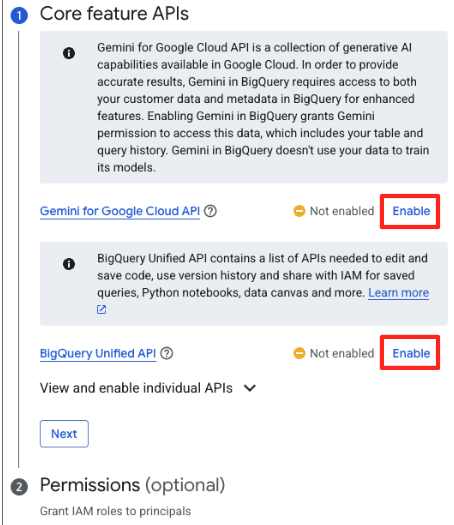
- 如果您是首次使用此功能,可能需要启用必需的 API。点击“Gemini for Google Cloud API”和“BigQuery Unified API”对应的“启用”。启用后,您可以关闭此面板。
- 在主“数据准备”窗口中,点击“选择其他数据源”下的“Google Cloud Storage”。这将在右侧打开“准备数据”面板。
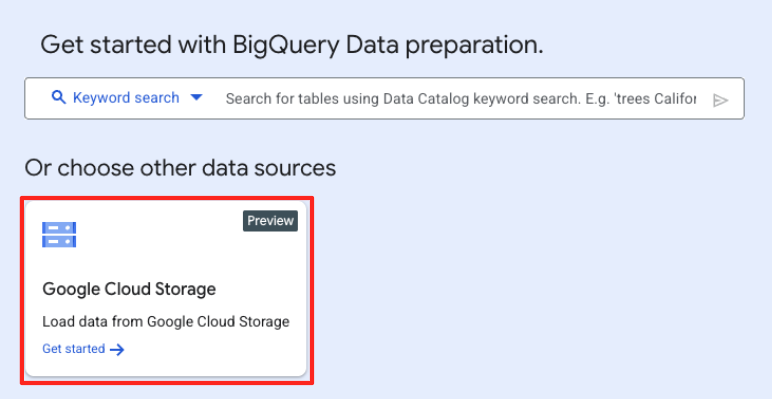
- 点击“浏览”按钮以选择源文件。
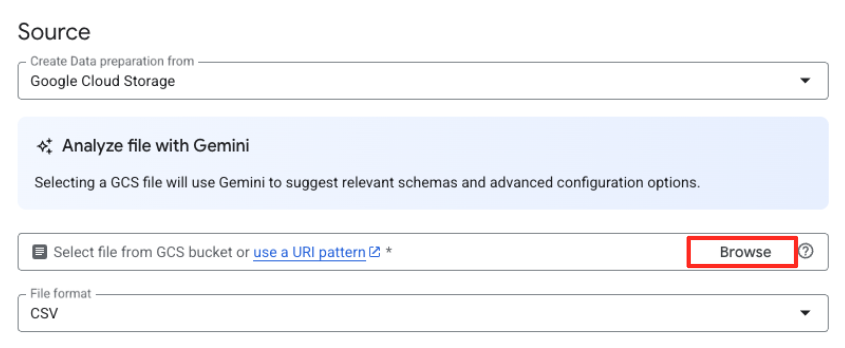
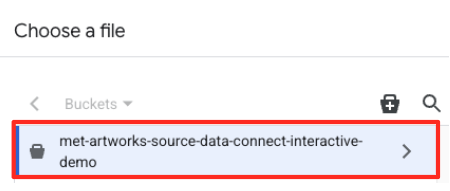
- 前往您之前创建的 GCS 存储分区 (
met-artworks-source-...),然后选择dataprep-met-bqml.csv文件。点击“选择”。
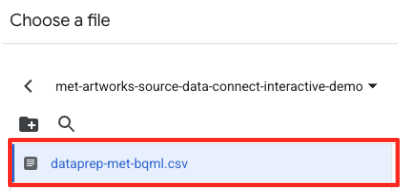
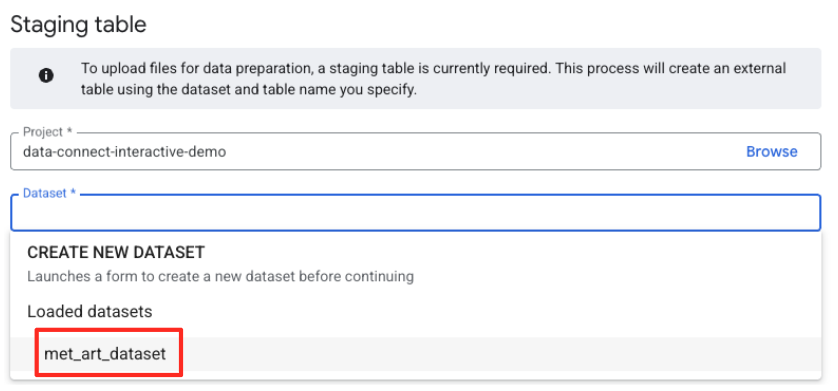
- 接下来,您需要配置一个临时表。
- 对于“数据集”,选择您创建的
met_art_dataset。 - 在“表名称”中,输入一个名称,例如
temp。 - 点击“创建”。
转换和清理数据
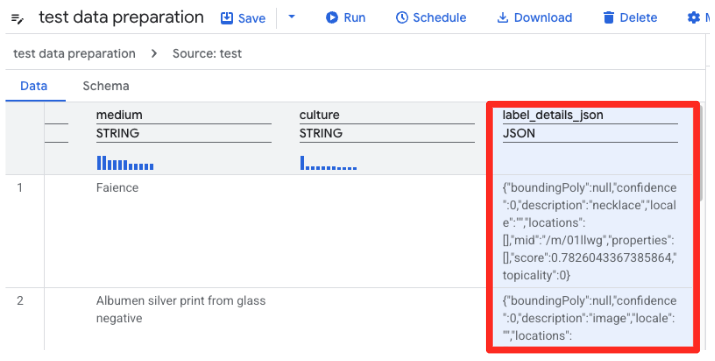
- BigQuery 的数据准备功能现在会加载 CSV 的预览。找到包含长 JSON 字符串的
label_details_json列。点击列标题以将其选中。
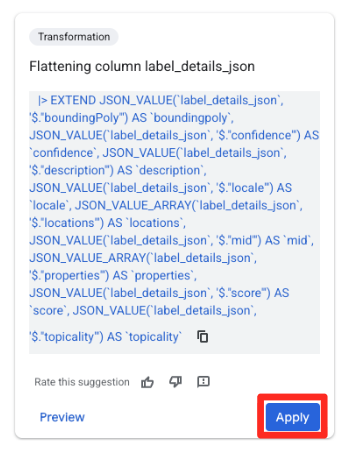
- 在右侧的建议面板中,Gemini in BigQuery 会自动建议相关转换。点击“扁平化列
label_details_json”卡片上的“应用”按钮。这会将嵌套字段(description、score等)提取到各自的顶级列中。
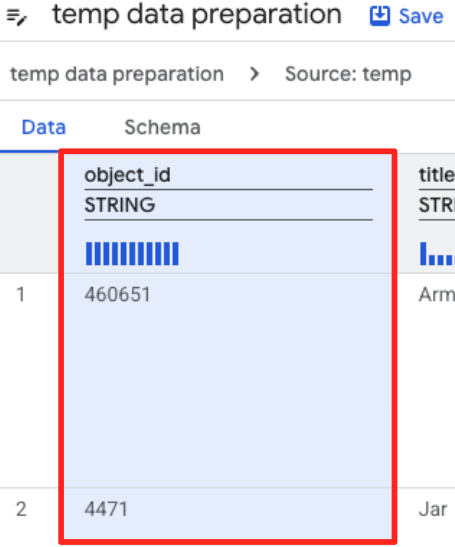
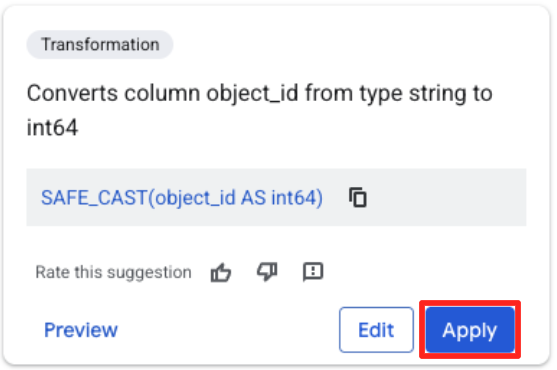
- 点击 object_id 列,然后点击“将列
object_id从类型string转换为int64”上的“应用”按钮。
定义目标并运行作业
- 在右侧面板中,点击“目标”按钮以配置转换的输出。
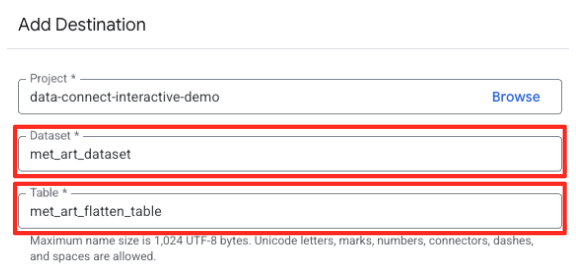
- 设置目标详细信息:
- 数据集应预先填充
met_art_dataset。 - 为输出输入新的表名称:
met_art_flatten_table。 - 点击“保存”。
- 点击“运行”按钮,然后等待数据准备作业完成。
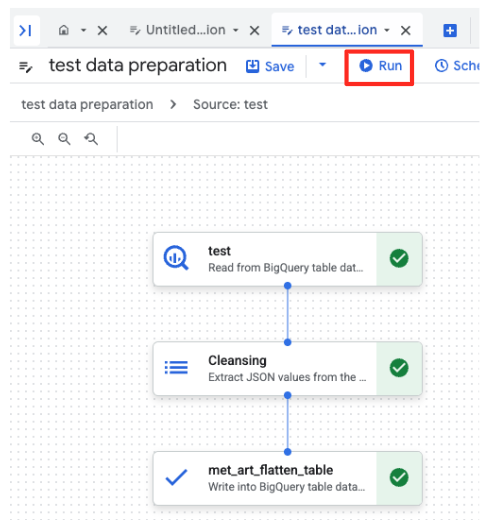
- 您可以在页面底部的“执行”标签页中监控作业的进度。片刻之后,作业就会完成。
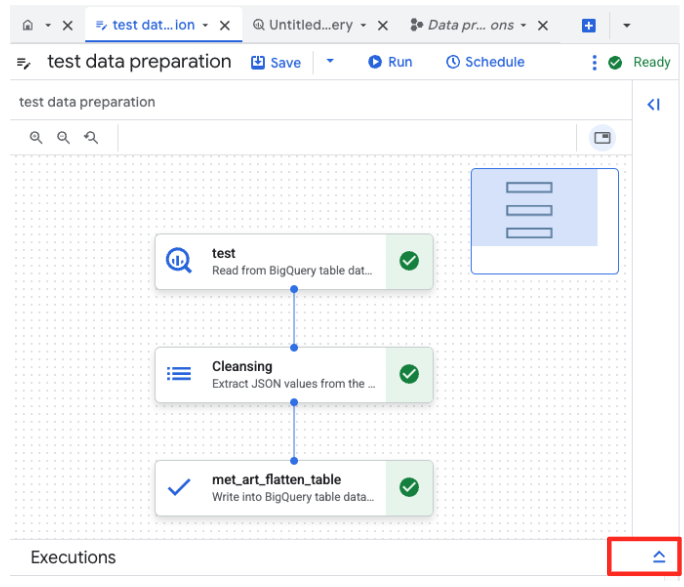
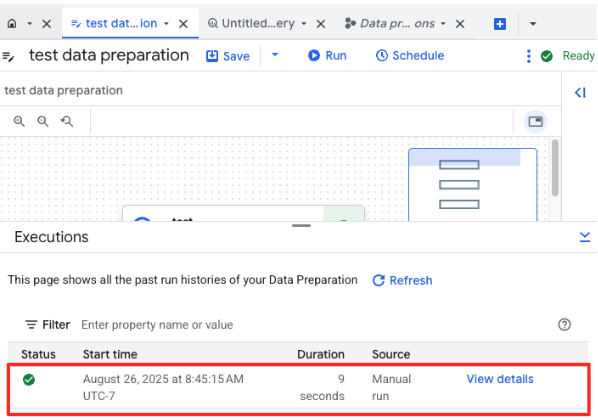
4. 使用 BQML 生成向量嵌入
现在,我们的数据已清理完毕并结构化,接下来我们将使用 BigQuery ML 执行核心 AI 任务:将艺术品的文本描述转换为数值向量嵌入。
创建 BigQuery 连接
如需允许 BigQuery 与 Vertex AI 服务通信,您必须先创建 BigQuery 连接。
- 在 BigQuery Studio 的“探索器”面板中,点击“+ 添加数据”按钮。
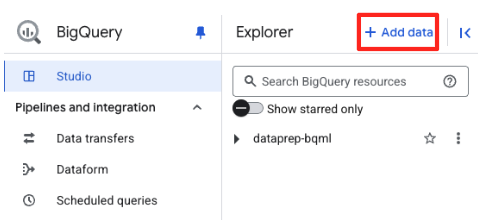
- 在右侧面板中,使用搜索栏输入
Vertex AI。选择该选项,然后从过滤后的列表中选择 BigQuery 联邦。
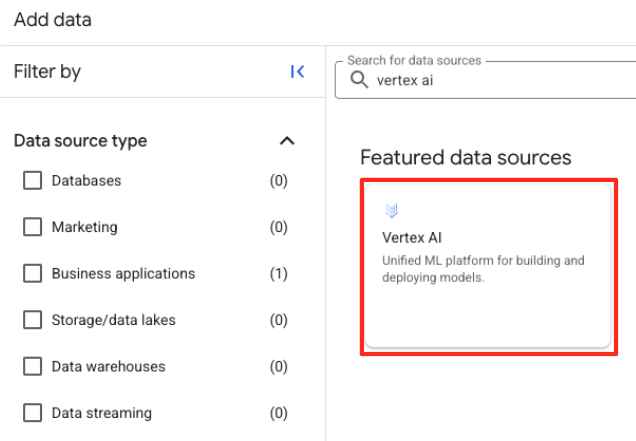
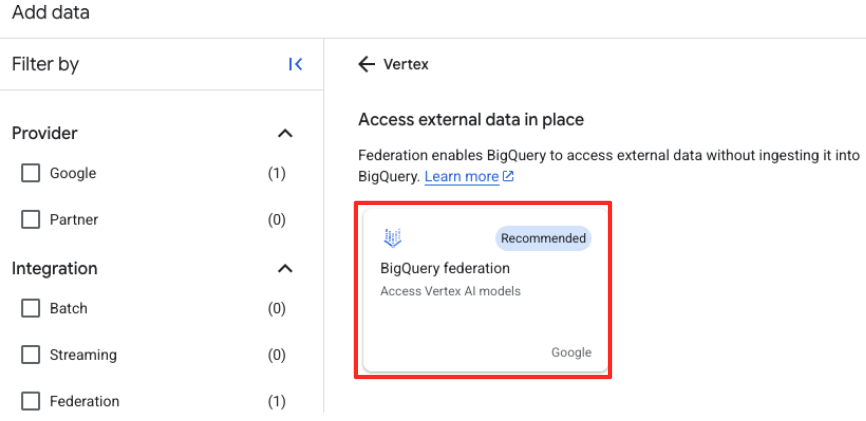
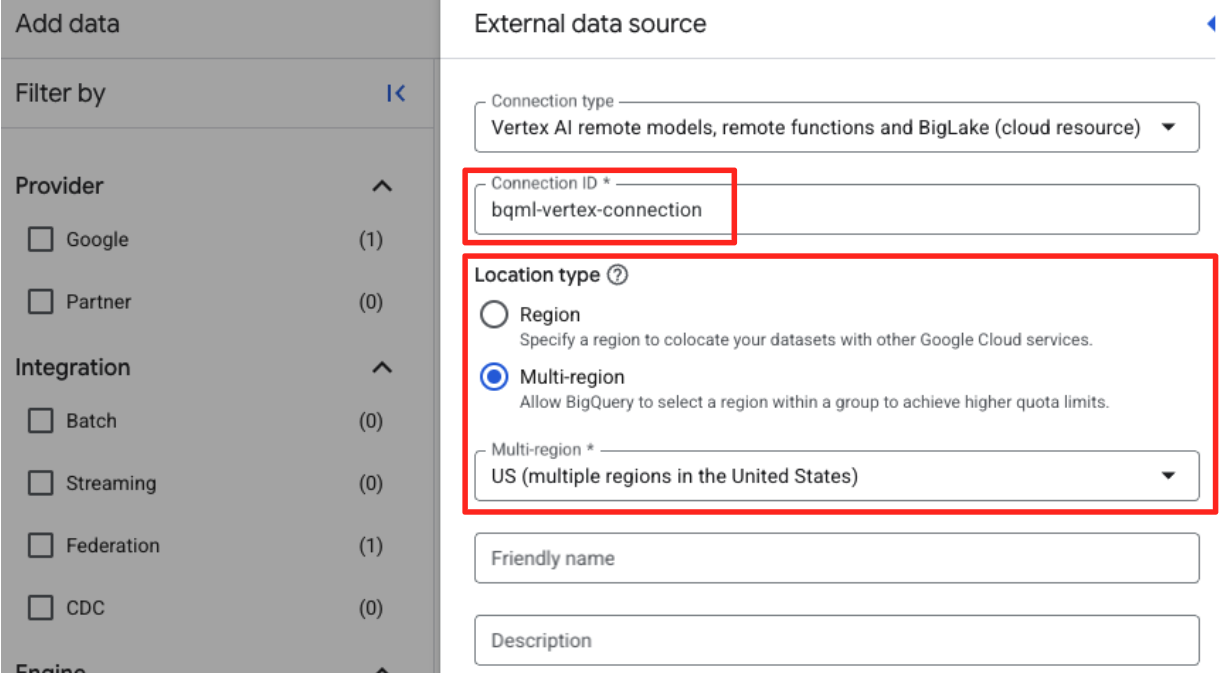
- 系统随即会打开“外部数据源”表单。填写以下详细信息:
- 连接 ID:输入连接 ID(例如
bqml-vertex-connection) - 位置类型:确保已选择“多区域”。
- 位置:选择位置(例如
US)。
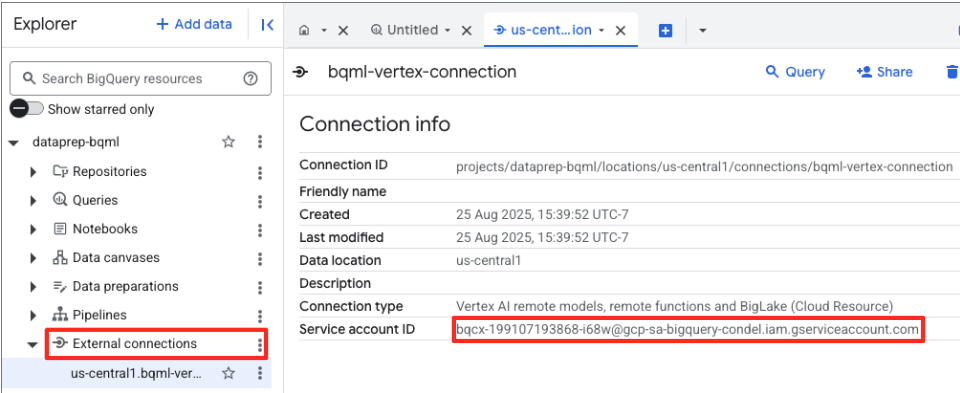
- 连接创建完成后,系统会显示一个确认对话框。在“探索器”标签页中,点击“前往连接”或“外部连接”。在连接详情页面上,将完整 ID 复制到剪贴板。这是 BigQuery 将用于调用 Vertex AI 的服务账号身份。
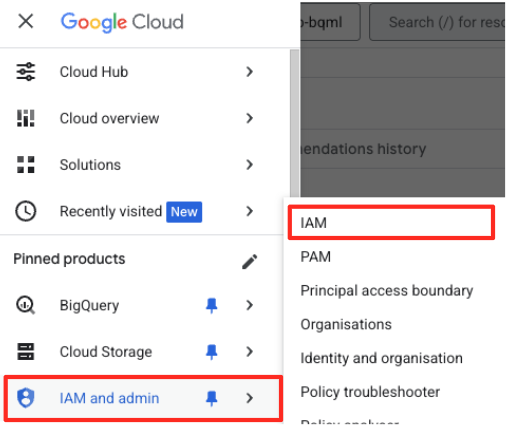
- 在 Google Cloud 控制台导航菜单中,依次前往“IAM 和管理”>“IAM”。
- 点击“授予访问权限”按钮
- 将您在上一步中复制的服务账号粘贴到“新的主账号”字段中。
- 在“角色”下拉菜单中分配“Vertex AI 用户”,然后点击“保存”。
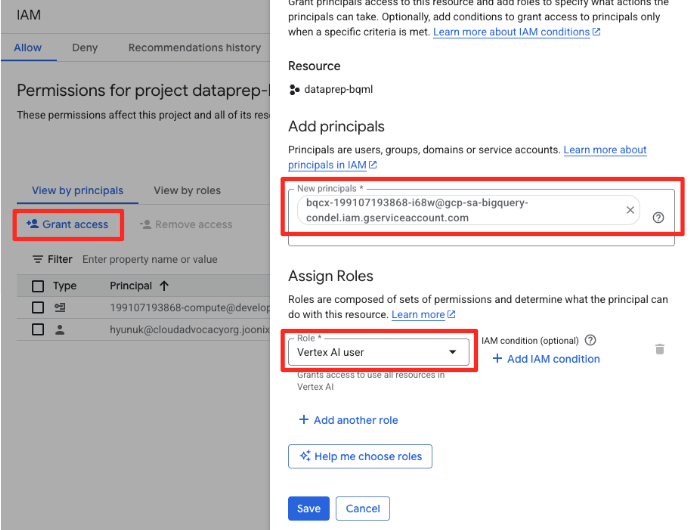
此关键步骤可确保 BigQuery 获得适当的授权,以便代表您使用 Vertex AI 模型。
创建远程模型
在 BigQuery Studio 中,打开新的 SQL 编辑器标签页。您将在此处定义连接到 Gemini 的 BQML 模型。
此语句不会训练新模型。它只是在 BigQuery 中创建一个引用,该引用使用您刚刚授权的连接指向强大的预训练 gemini-embedding-001 模型。
复制下面的整个 SQL 脚本,然后将其粘贴到 BigQuery 编辑器中。
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
生成嵌入
现在,我们将使用 BQML 模型生成向量嵌入。我们不会简单地为每行转换单个文本标签,而是会采用更复杂的方法,为每件艺术品创建更丰富、更有意义的“语义摘要”。这样可以生成更高质量的嵌入内容,并提供更准确的建议。
此查询执行关键的预处理步骤:
- 它使用
WITH子句先创建一个临时表。 - 在其中,我们对每个
object_id进行GROUP BY,以将单个艺术品的所有信息合并到一行中。 - 我们使用
STRING_AGG函数将所有单独的文本描述(例如“人像”“女性”“布面油画”)合并为一个全面的文本字符串,并按相关性得分对它们进行排序。
这种组合文本为 AI 提供了更丰富的艺术品相关背景信息,从而生成更细致、更强大的向量嵌入。
在新的 SQL 编辑器标签页中,粘贴并运行以下查询:
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
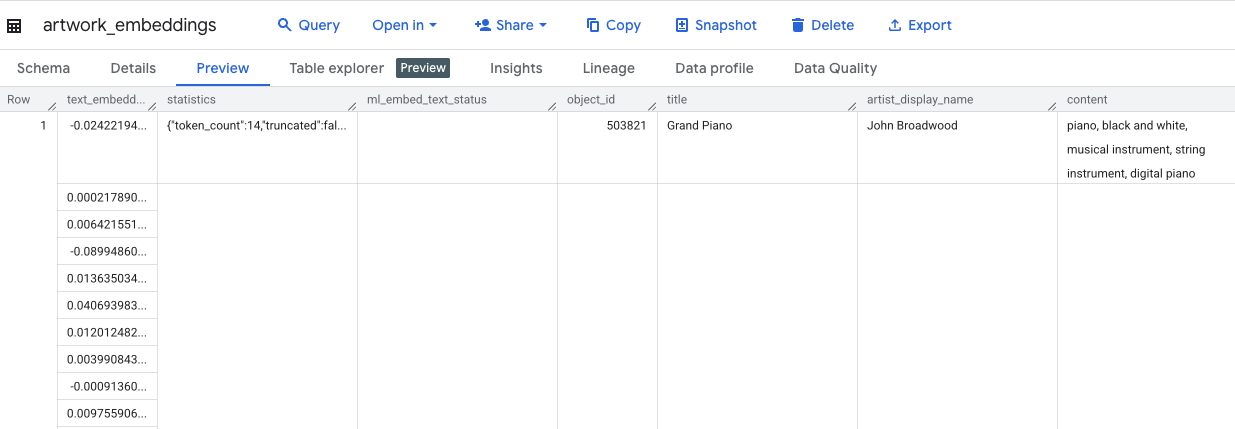
此查询大约需要 10 分钟。查询完成后,验证结果。在“探索器”面板中,找到新的 artwork_embeddings 表,然后点击它。在表架构查看器中,您将看到 object_id、包含向量的新 ml_generate_text_embedding_result 列,以及用作源文本的 aggregated_labels 列。
5. 使用 SQL 查找相似的艺术作品
创建了高质量、富含上下文信息的向量嵌入后,只需运行 SQL 查询即可轻松找到主题相似的艺术品。我们使用 ML.DISTANCE 函数计算向量之间的余弦相似度。由于我们的嵌入是从汇总的文本生成的,因此相似性结果会更准确、更相关。
- 在新的 SQL 编辑器标签页中,粘贴以下查询。此查询模拟了推荐应用的核心逻辑:
- 它首先选择一幅特定艺术品(在本例中为梵高的《柏树》,其
object_id为 436535)的向量。 - 然后,它会计算该单个向量与表中的所有其他向量之间的距离。
- 最后,它会按距离(距离越小表示越相似)对结果进行排序,以找到最接近的前 10 个匹配项。
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- 运行查询。结果将列出
object_id,最接近的匹配项位于顶部。源艺术品将首先显示,距离为 0。这是 AI 推荐引擎的核心逻辑,您仅使用 SQL 便在 BigQuery 中完全构建了该逻辑。
6. (可选)在 Cloud Shell 中运行演示
为了让您更好地理解此 Codelab 中的概念,您克隆的代码库中包含一个简单的 Web 应用。此可选演示使用您创建的 artwork_embeddings 表来支持视觉搜索引擎,让您了解 AI 驱动的建议的实际效果。
如需在 Cloud Shell 中运行演示,请按照以下步骤操作:
- 设置环境变量:在运行应用之前,您需要设置 PROJECT_ID 和 BIGQUERY_DATASET 环境变量。
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- 安装依赖项并启动后端服务器。
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- 您需要打开第二个终端标签页来运行前端应用。点击“+”图标,打开新的 Cloud Shell 标签页。

- 现在,在新标签页中执行以下命令,以安装依赖项并运行前端服务器
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
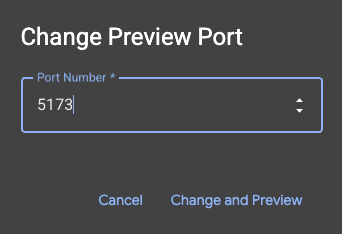
- 预览应用:在 Cloud Shell 工具栏中,点击“网页预览”图标,然后选择“在端口 5173 上预览”。系统会打开一个新的浏览器标签页,其中运行着该应用。现在,您可以使用该应用搜索艺术品,并查看相似度搜索的实际效果。
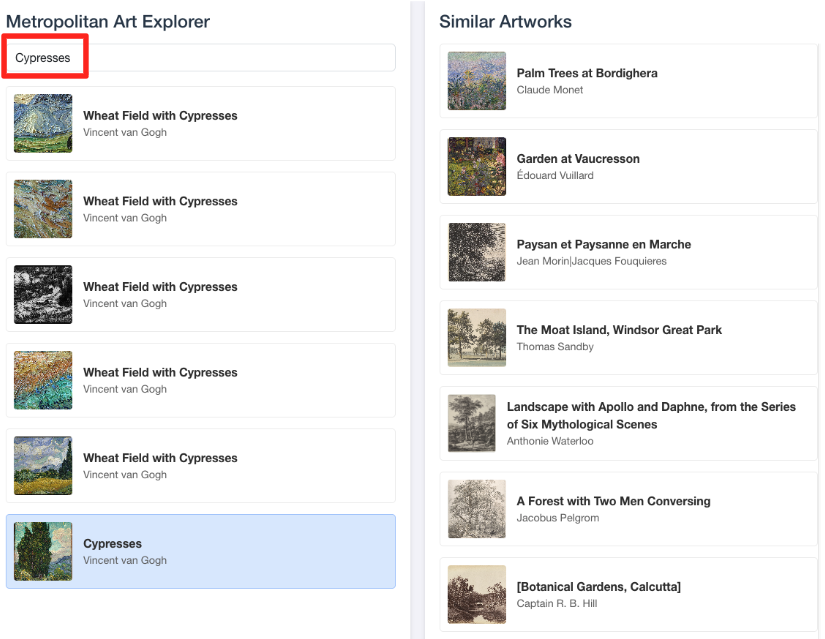
- 如需将此直观演示与您在 BigQuery SQL 编辑器中所做的工作关联起来,请尝试在搜索栏中输入“Cypresses”。这与您在
ML.DISTANCE查询中使用的同一张图片(object_id=436535) 相同。然后,当左侧面板中显示“Cypresses”图片时,点击该图片,您会在右侧看到结果。应用会显示最相似的艺术品,直观地展示您构建的向量相似度搜索的强大功能。
7. 清理环境
为避免系统日后因本 Codelab 中使用的资源向您的 Google Cloud 账号收取费用,您应该删除您创建的资源。
在 Cloud Shell 终端中运行以下命令,以移除服务账号、BigQuery 连接、GCS 存储分区和 BigQuery 数据集。
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
移除 BigQuery 连接和 GCS 存储分区
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
删除 BigQuery 数据集
最后,删除 BigQuery 数据集。此命令不可撤消。-f(强制)标志会移除数据集及其所有表,而不会提示您进行确认。
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. 恭喜!
您已成功构建端到端 AI 赋能的数据流水线。
您首先从 GCS 存储分区中的原始 CSV 文件入手,使用 BigQuery Data Prep 的低代码界面提取并展平复杂的 JSON 数据,创建强大的 BQML 远程模型以使用 Gemini 模型生成高质量的向量嵌入,并执行相似度搜索查询以查找相关商品。
现在,您已经掌握了在 Google Cloud 上构建 AI 辅助工作流的基本模式,可以快速轻松地将原始数据转化为智能应用。
接下来该怎么做?
- 在 Looker Studio 中直观呈现结果:将
artwork_embeddingsBigQuery 表直接连接到 Looker Studio(免费!)。您可以构建一个互动式信息中心,让用户无需编写任何前端代码即可选择一件艺术品,并查看最相似作品的视觉图库。 - 使用预定查询实现自动化:您无需使用复杂的编排工具即可让嵌入内容保持最新状态。使用 BigQuery 的内置“计划查询”功能,每天或每周自动重新运行
ML.GENERATE_TEXT_EMBEDDING查询。 - 使用 Gemini CLI 生成应用:只需以纯文本描述您的要求,即可使用 Gemini CLI 生成完整的应用。这样一来,您无需手动编写 Python 代码,即可快速构建用于相似性搜索的可行原型。
- 阅读文档: