
১. ভূমিকা
BigQuery Graph, BigQuery Conversational Analytics, এবং BigQuery Agent Analytics SDK বর্তমানে গুগল ক্লাউডে প্রিভিউ পর্যায়ে রয়েছে। BigQuery Agent Analytics প্লাগইনটি এখন সর্বসাধারণের জন্য উপলব্ধ (GA)। এই কোডল্যাবের উদাহরণগুলিতে সিন্থেটিক ডেটা ব্যবহার করা হয়েছে।
যেহেতু স্বায়ত্তশাসিত এআই এজেন্টরা আরও বেশি পরিচালনগত দায়িত্ব গ্রহণ করছে (যেমন ঋণের আবেদন মূল্যায়ন, বিপণন বাজেট পরিচালনা, প্রবেশের অনুরোধ অনুমোদন), তাই সংস্থাগুলোকে অবশ্যই তাদের সিদ্ধান্তগুলো নিরীক্ষা করতে এবং ব্যাখ্যা করতে সক্ষম হতে হবে। কোনো এজেন্টের সিদ্ধান্তের সঠিক প্রেক্ষাপট, বিবেচিত বিকল্পসমূহ এবং চূড়ান্ত যুক্তি পুনর্গঠন করা নিয়মকানুন প্রতিপালন, ঝুঁকি ব্যবস্থাপনা এবং পরিচালনগত আস্থার জন্য অপরিহার্য।
এই কোডল্যাবটি BigQuery Agent Analytics SDK ব্যবহার করে, কোনো বাহ্যিক গ্রাফ ডেটাবেস বা ETL পাইপলাইন ছাড়াই, একটি নির্দিষ্ট সময়সূচী অনুযায়ী এজেন্টের মূল ইভেন্ট লগগুলোকে একটি Agent Context Graph- এ (যা BigQuery-তে এজেন্টের সিদ্ধান্তগুলোর একটি কোয়েরিযোগ্য গ্রাফ) রূপান্তর করে।
মূল পদগুলি
- এজেন্টের সিদ্ধান্ত ট্রেস — কোনো এজেন্টের নিজস্ব কার্যকলাপ থেকে সংগৃহীত সিদ্ধান্ত-স্তরের প্রমাণ: এটি যে বিকল্পগুলো বিবেচনা করেছে, যে ডেটাগুলো পর্যালোচনা করেছে এবং যে ফলাফলটি গ্রহণ করেছে।
- এজেন্ট কনটেক্সট গ্রাফ — বিগকোয়েরি গ্রাফের সেই টাইপড, কোয়েরিযোগ্য গ্রাফ, যেখানে ঐ ট্রেসগুলো বাস্তবায়িত হয়। এটি ইন্ডাস্ট্রি কনটেক্সট গ্রাফ ধারণার (সিদ্ধান্ত-সংক্রান্ত প্রসঙ্গের সেই টেকসই, সময়-সংযুক্ত স্তর যা এজেন্টরা তৈরি ও গ্রহণ উভয়ই করে) এজেন্ট-স্কোপড ইনস্ট্যান্স; "এজেন্ট" কোয়ালিফায়ারটি এটিকে একটি এন্টারপ্রাইজ-ব্যাপী কনটেক্সট লেয়ারের পরিবর্তে আপনার নিজস্ব এজেন্টদের রানের মধ্যে সীমাবদ্ধ করে।
এই কোডল্যাবে, bqaa context-graph আপনার agent_events থেকে এজেন্টের ডিসিশন ট্রেসগুলো এক্সট্র্যাক্ট করে এবং সেগুলোকে একটি এজেন্ট কনটেক্সট গ্রাফে রূপ দেয়, যা আপনি GQL দিয়ে কোয়েরি করতে পারেন — এটি ইন্ডাস্ট্রির সেই প্যাটার্ন অনুসরণ করে যেখানে ডিসিশন ট্রেস থেকে কনটেক্সট গ্রাফ তৈরি করা হয়।
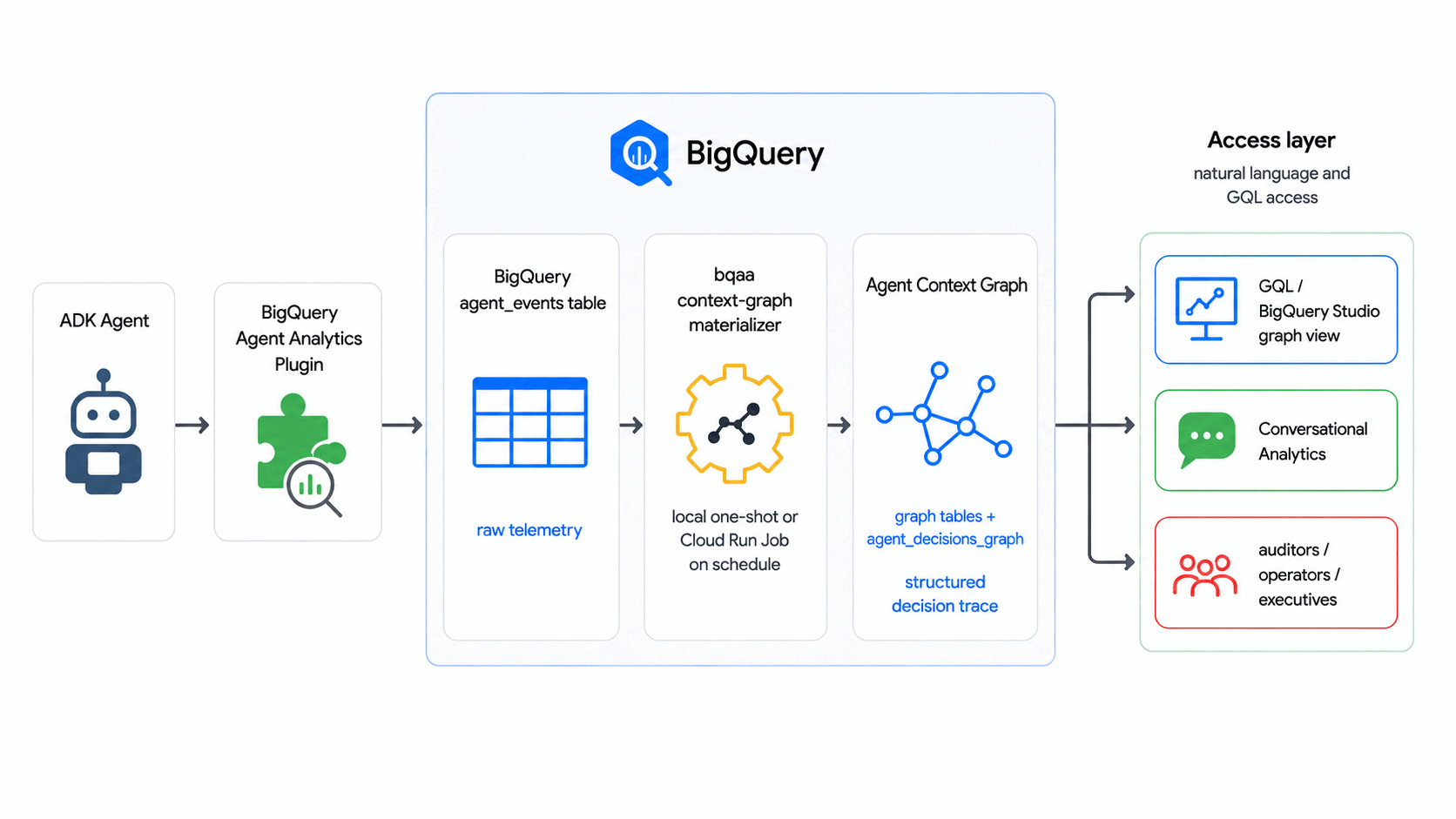
আপনি যা তৈরি করবেন
- একটি এজেন্ট কনটেক্সট গ্রাফ (বিগকোয়েরি গ্রাফ সহ) যা এজেন্টের একটি সাধারণ সিদ্ধান্ত প্রবাহের মডেল তৈরি করে: একটি অনুরোধ আসে, এজেন্ট বিভিন্ন বিকল্প বিবেচনা করে, এবং একটি ফলাফল চূড়ান্ত করা হয়।
- একটি কৃত্রিম ইভেন্ট কর্পাস দ্বারা পূর্ণ
agent_eventsটেবিল। - একটি কার্যকর
bqaa context-graphরান যা ঐ ইভেন্টগুলো থেকে গ্রাফটি পূরণ করে। - একটি অডিট-ধাঁচের GQL কোয়েরি যা একটিমাত্র সিদ্ধান্তকে শুরু থেকে শেষ পর্যন্ত অনুসরণ করে।
আপনি যা শিখবেন
- BigQuery এজেন্ট অ্যানালিটিক্স প্লাগইনটি যেভাবে
agent_eventsএ লেখে। - কীভাবে মাত্র দুটি ডিক্লারেটিভ আর্টিফ্যাক্ট—একটি টেবিল ডিডিএল এবং একটি
CREATE PROPERTY GRAPHস্কিমা—এর মাধ্যমে একটি কনটেক্সট গ্রাফ সংজ্ঞায়িত করা হয়। - BigQuery Graph-এর বিপরীতে কীভাবে
bqaa context-graphচালানো যায় - GQL ব্যবহার করে কীভাবে একটি গ্রাফ কোয়েরি করতে হয়।
- এন্টারপ্রাইজ ডেপ্লয়মেন্টের জন্য এসডিকে-টি যে প্রোডাকশন-গ্রেড সক্ষমতাগুলো সমর্থন করে।
আপনার যা যা লাগবে
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- ঐ প্রজেক্টে মালিক বা সম্পাদকের ভূমিকা পালন করতে হবে। আপনাকে একটি BigQuery ডেটাসেট তৈরি করতে হবে এবং IAM অনুমোদন দিতে হবে।
-
gcloudCLI ইনস্টল ও প্রমাণীকৃত, অথবা ক্লাউড শেলে প্রবেশাধিকার। - পাইথন ৩.১০ বা তার পরবর্তী সংস্করণ।
- BigQuery SQL সম্পর্কে পরিচিতি থাকতে হবে। GQL জ্ঞানের প্রয়োজন নেই।
এই কোডল্যাবটি সকল স্তরের ডেভেলপারদের জন্য, বিশেষ করে যারা BigQuery Graph-এ নতুন তাদের জন্য।
এই কোডল্যাবে তৈরি রিসোর্সগুলোর খরচ খুবই কম, এবং চূড়ান্ত ধাপে সবকিছু মুছে ফেলা হয়, ফলে কোনো অব্যবহৃত ডেটাসেটের জন্য আপনাকে বিল করা হয় না।
আনুমানিক সময়কাল: এই কোডল্যাবটি সম্পূর্ণ করতে প্রায় ৩৫ মিনিট সময় লাগে।
২. শুরু করার আগে
একটি প্রকল্প এবং অঞ্চল নির্বাচন করুন
ক্লাউড শেল অথবা একটি স্থানীয় টার্মিনাল খুলুন:
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
একটিমাত্র DATASET ভেরিয়েবলে মূল agent_events টেবিল এবং ম্যাটেরিয়ালাইজড গ্রাফ টেবিল উভয়ই থাকে। একটি ডেটাসেট ব্যবহার করলে কোডল্যাবটি সহজ থাকে। প্রোডাকশন ডেপ্লয়মেন্টে প্রায়শই ইভেন্ট এবং গ্রাফকে আলাদা ডেটাসেটে ভাগ করা হয়, যাতে প্রতিটি ডেটাসেটের জন্য সুনির্দিষ্টভাবে IAM অনুমোদন করা যায়।
প্রয়োজনীয় API গুলি সক্রিয় করুন
এই কোডল্যাবে ব্যবহৃত API-গুলো সক্রিয় করতে নিম্নলিখিত কমান্ডটি চালান :
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
aiplatform.googleapis.com API-টি প্রয়োজন, কারণ SDK-এর ডিফল্ট এক্সট্র্যাকশন পাথ BigQuery-এর AI.GENERATE ফাংশনটিকে কল করে। আপনি যদি পরবর্তীতে --extraction-mode=compiled-only ব্যবহার করে ডিটারমিনিস্টিক এক্সট্র্যাকশনে পরিবর্তন করেন, তাহলে এই API-টির আর প্রয়োজন হবে না।
BigQuery ডেটাসেট তৈরি করুন
এমন একটি ডেটাসেট তৈরি করুন যা মূল agent_events টেবিল এবং ম্যাটেরিয়ালাইজড গ্রাফ টেবিল উভয়ই ধারণ করবে:
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
আপনি একটি সফলতার বার্তা দেখতে পাবেন:
Dataset 'your-project-id:agent_analytics_demo' successfully created.
ডেটা সেট যদি আগে থেকেই বিদ্যমান থাকে, তাহলে কমান্ডটি কোনো ক্ষতি ছাড়াই ত্রুটি দেখায়। এটিকে যথাস্থানে রেখে দিন।
৩. SDK ইনস্টল করুন
একটি পাইথন ভার্চুয়াল এনভায়রনমেন্ট তৈরি করুন এবং PyPI থেকে SDK ইনস্টল করুন :
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
bigquery-agent-analytics প্যাকেজটি BigQuery ক্লায়েন্ট লাইব্রেরিটি নিয়ে আসে, তাই পুরো কোডল্যাবের জন্য শুধু এটিই ইনস্টল করা প্রয়োজন।
ইনস্টলেশন যাচাই করুন:
bqaa context-graph --help | head -8
আপনি CLI ব্যানারটি দেখতে পাবেন।
প্রমাণীকরণ করুন
আপনি যদি একটি ওয়ার্কস্টেশনে থাকেন:
gcloud auth login
gcloud auth application-default login
ক্লাউড শেল ব্যবহারকারীরা এই ধাপটি এড়িয়ে যেতে পারেন; ক্রেডেনশিয়াল আগে থেকেই কনফিগার করা আছে।
৪. কোডল্যাব আর্টিফ্যাক্টগুলো সংগ্রহ করুন।
কোডল্যাবটির জন্য মাত্র দুটি রেডি-টু-ইউজ আর্টিফ্যাক্ট প্রয়োজন: টেবিল ডিডিএল (ফিজিক্যাল গ্রাফ টেবিলগুলো) এবং প্রপার্টি-গ্রাফ স্কিমা ( CREATE PROPERTY GRAPH )। আপনাকে এগুলোর কোনোটিই নিজে তৈরি করতে হবে না; কোডল্যাবটি এগুলো হুবহু ব্যবহার করে, এবং আর্টিফ্যাক্টস ফোল্ডারের README ফাইলে ব্যাখ্যা করা আছে কীভাবে আপনার নিজের ডিসিশন ডোমেইনের জন্য এগুলোকে মানিয়ে নিতে হবে।
প্রপার্টি-গ্রাফ স্কিমা হলো গ্রাফটিতে কী কী রয়েছে তার একমাত্র নির্ভরযোগ্য উৎস। আপনি এটি BigQuery-তে একবার প্রয়োগ করেন; তারপর থেকে ডেপ্লয় করা গ্রাফটি নিজেই চুক্তি হিসেবে কাজ করে । যখন আপনি ম্যাটেরিয়ালাইজ করেন, তখন bqaa context-graph কমান্ডটি BigQuery-এর INFORMATION_SCHEMA.PROPERTY_GRAPHS থেকে গ্রাফটির ডেফিনিশন (এবং এর সাথে রেফারেন্স করা টেবিলগুলোর স্কিমা) পড়ে নেয়, যাতে কোন এনটিটি ও রিলেশনশিপগুলো এক্সট্র্যাক্ট করতে হবে এবং কোথায় লিখতে হবে তা নির্ধারণ করা যায় — ফলে ম্যাটেরিয়ালাইজারে কোনো SQL ফাইল পাঠানো হয় না।
এই কোডল্যাবটি স্বয়ংসম্পূর্ণ, তাই ডাউনলোড করার মতো কিছু নেই। নিচের কমান্ডটি একটি ওয়ার্কিং ডিরেক্টরিতে কনটেক্সট গ্রাফের DDL লিখে দেয়। এর বিষয়বস্তু examples/context_graph/codelab/ -এ থাকা আর্টিফ্যাক্টগুলোর অনুরূপ।
ওয়ার্কিং ডিরেক্টরি তৈরি করুন:
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
কন্টেক্সট গ্রাফ ডিডিএল ( context_graph_ddl.sql ) লিখুন। পরবর্তী ধাপে ফাইলটি প্রয়োগ করার সময় ${PROJECT_ID} / ${DATASET} মার্কারগুলি পূরণ হয়ে যাবে।
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
ফাইলটি যথাস্থানে আছে কিনা তা নিশ্চিত করুন:
ls
আপনি একটি ফাইল দেখতে পাবেন:
context_graph_ddl.sql
তাদের বর্ণিত সিদ্ধান্ত প্রবাহটিতে তিন ধরনের নোড এবং দুটি ভিন্নধর্মী এজ রয়েছে:
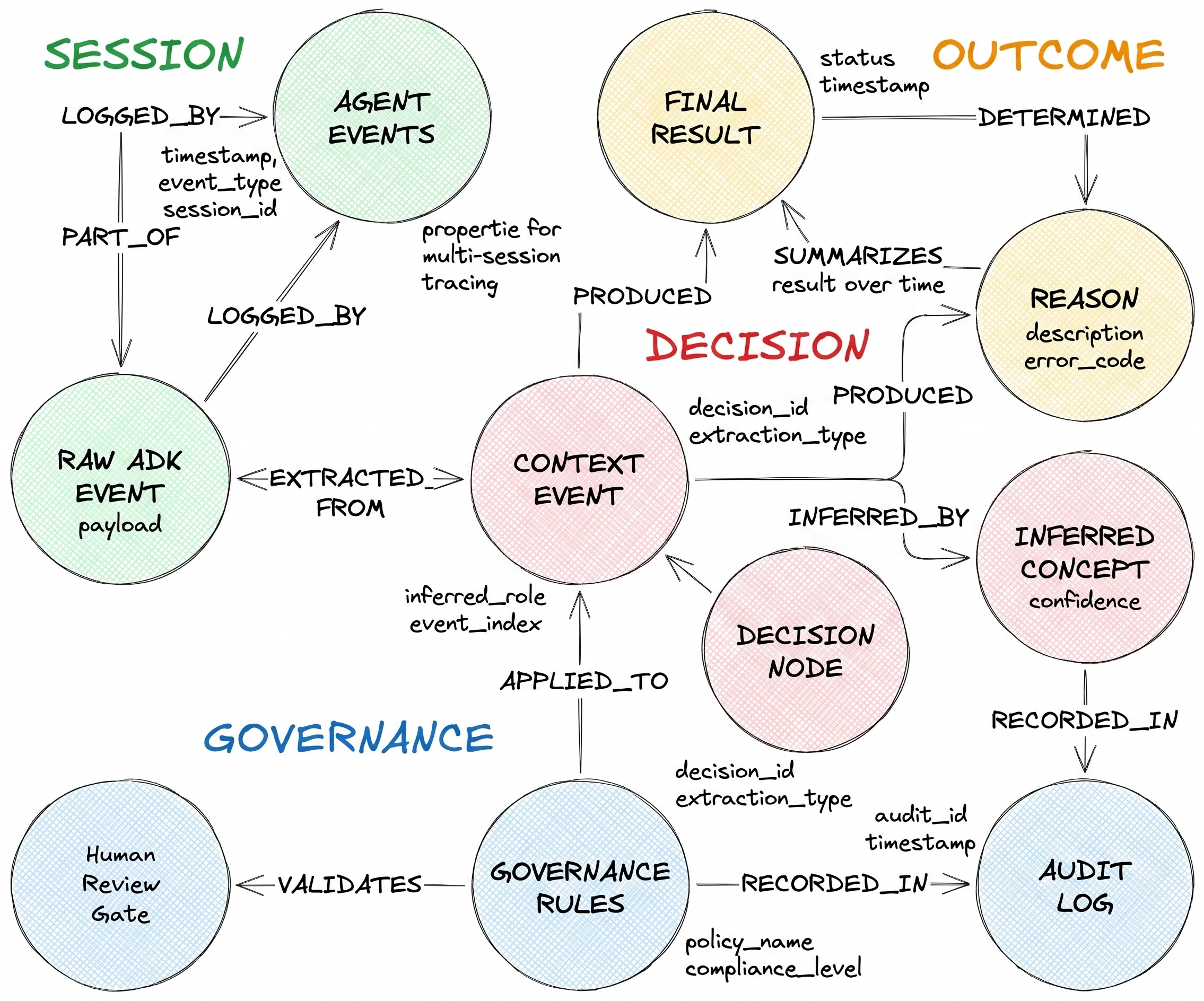
DecisionRequest হলো এজেন্ট কর্তৃক প্রাপ্ত প্রশ্ন। DecisionOption হলো এজেন্ট কর্তৃক বিবেচিত একটি বিকল্প। DecisionOutcome গৃহীত সিদ্ধান্ত এবং তার যুক্তি লিপিবদ্ধ থাকে।
৫. প্রপার্টি গ্রাফ স্কিমা প্রয়োগ করুন
bqaa context-graph BigQuery টেবিলগুলিতে লেখে, তাই প্রথমবার চালানোর আগে টেবিলগুলো অবশ্যই বিদ্যমান থাকতে হবে। context_graph_ddl.sql প্রথমে পাঁচটি টেবিল তৈরি করে এবং তারপর সেগুলোকে রেফারেন্স করে এমন প্রপার্টি গ্রাফ তৈরি করে (BigQuery এমন CREATE PROPERTY GRAPH প্রত্যাখ্যান করে যা এখনও বিদ্যমান নয় এমন টেবিলকে নির্দেশ করে), তাই একটিমাত্র apply-ই সবকিছু সেট আপ করে দেয়:
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
আপনি পাঁচটি CREATE TABLE এবং একটি CREATE PROPERTY GRAPH ফলাফল দেখতে পাবেন। DDL-টি আইডম্পোটেন্ট; আপনি এটি নিরাপদে পুনরায় চালাতে পারেন।
এটাই একমাত্র স্কিমা সংক্রান্ত কাজ যা আপনি করেন — এবং শুধুমাত্র এই সময়েই এই SQL ফাইলগুলো ব্যবহৃত হয়। BigQuery এখন আপনার গ্রাফের সংজ্ঞা রেকর্ড করে, এবং bqaa context-graph INFORMATION_SCHEMA.PROPERTY_GRAPHS থেকে নাম দিয়ে তা পড়ে নেয়। ম্যাটেরিয়ালাইজারে পাঠানোর জন্য কোনো আলাদা ফাইল থাকে না, এবং আপনি GQL দিয়ে যা কোয়েরি করেন ও যা ম্যাটেরিয়ালাইজড হয়, তা কখনোই আলাদা হতে পারে না: এগুলো একই ডেপ্লয়েড গ্রাফ।
৬. নমুনা এজেন্ট ইভেন্ট তৈরি করুন
প্রোডাকশনে, আপনার ADK এজেন্ট চলার সময় BigQuery Agent Analytics Plugin স্বয়ংক্রিয়ভাবে ইভেন্ট ক্যাপচার করে। এই কোড স্নিপেটটি শুধুমাত্র রেফারেন্সের জন্য — এই কোডল্যাবে এটি চালানো হবে না:
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
এই কোডল্যাবের জন্য আপনি একটি ছোট সিন্থেটিক ইভেন্ট জেনারেটর ব্যবহার করবেন যা একই আকারের সারিগুলো সরাসরি agent_events এ লেখে। এটি চালান:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
এই কমান্ডটি একটি JSON রিপোর্ট প্রিন্ট করে। ৫টি সেশনের জন্য আপনি "events_generated": 30 , "events_inserted": 30 , এবং "ok": true দেখতে পাবেন।
এক নজরে কর্পাসটির প্রিভিউ দেখুন — কতগুলো সেশন, কতগুলো ইভেন্ট এবং সেগুলো কোন সময়সীমা জুড়ে রয়েছে — এক সারিতে:
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
ডিফল্ট ৫-সেশনের রানের জন্য এটি কয়েক মিনিটব্যাপী ৫টি সেশন এবং ৩০টি ইভেন্ট দেখায়। (নীচে বাস্তবসম্মত পরিস্থিতিটি দেখুন এবং একই কোয়েরি প্রায় তিন দিন জুড়ে প্রায় ১০০টি সেশন রিপোর্ট করে।)
অবতরণ করা ইভেন্টগুলি যাচাই করুন:
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
আপনি ২৫টি TOOL_COMPLETED সারি এবং ৫টি AGENT_COMPLETED সারি দেখতে পাবেন (প্রতিটি সেশন একটি submit_request , তিনটি evaluate_option , একটি commit_outcome এবং একটি closing AGENT_COMPLETED নির্গত করে — অর্থাৎ প্রতি সেশনে পাঁচটি টুল ইভেন্ট এবং একটি এজেন্ট টার্মিনেটর)। AGENT_COMPLETED সারিগুলো হলো সেই সেশন টার্মিনেটর, যেগুলোকে bqaa context-graph টার্মিনাল-ইভেন্ট শনাক্তকরণের জন্য কী (key) হিসেবে ব্যবহার করে।
ঐচ্ছিক: বাস্তবসম্মত স্কেল ডেটা
উপরের ৫-সেশনের কর্পাসটি ইচ্ছাকৃতভাবে ছোট রাখা হয়েছে, যাতে প্রথমবার চালানো দ্রুত এবং সাশ্রয়ী হয়। যখন আপনি প্রোডাকশন-ধাঁচের ডেটা চাইবেন — অর্থাৎ, বেশ কয়েক দিন ধরে একাধিক এজেন্ট ও ব্যবহারকারীর ডেটা, যেখানে ব্যর্থ, অনাথ এবং অসম্পূর্ণ সেশন থাকবে — তখন decision-realistic সিনারিওটি ব্যবহার করুন। এটি ডিফল্টভাবে ৭২-ঘণ্টার মধ্যে ১০০টি সেশন ব্যবহার করে; এক্ষেত্রে উপরের প্রথমবার চালানোর পাথটি অপরিবর্তিত থাকে।
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
JSON রিপোর্টের session_outcome_counts এ এর মিশ্রণটি দেখা যায় — মোটামুটি {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10} ।
প্রতিটি সেশনকে তার সারিগুলো থেকে শ্রেণীবদ্ধ করে ফলাফলের বণ্টন নিশ্চিত করুন (অনাথ = কোনো AGENT_COMPLETED নেই; ব্যর্থ status = 'error' সহ AGENT_COMPLETED ; খণ্ডিত = is_truncated = true সহ যেকোনো সারি; অন্যথায় সফল)। প্রথম ধাপে প্রতিটি সেশনকে শ্রেণীবদ্ধ করা হয়, তারপর দ্বিতীয় ধাপে প্রতিটি ফলাফলের জন্য সেগুলোকে একত্রিত করা হয়:
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
আপনি মোটামুটি ৭০টি সফল, ১০টি ব্যর্থ, ১০টি অনাথ এবং ১০টি খণ্ডিত সেশন দেখতে পাবেন (এর সাথে প্রথমবার চালানো কর্পাস থেকে ৫টি সফল সেশনও থাকবে, যদি আপনি একই ডেটাসেটে আগে সেটি সিড করে থাকেন)।
১০টি অনাথ সেশন কখনও AGENT_COMPLETED নির্গত করেনি, তাই ডিফল্ট bqaa context-graph রান সেগুলোকে এড়িয়ে যায় (এটি শুধুমাত্র টার্মিনাল-ইভেন্ট-ক্লোজড সেশনগুলোকেই মেটেরিয়ালাইজ করে)। চিরকাল নীরবে পুনরায় চেষ্টা করার পরিবর্তে সেগুলোকে session_orphaned হিসেবে প্রকাশ করতে, এটি চালানোর সময় --max-session-age-hours যোগ করুন — Take it to production-এ --max-session-age-hours দেখুন।
৭. কনটেক্সট গ্রাফটি বাস্তবায়ন করুন
bqaa context-graph প্রথমে agent_events মূল ডেটা পড়ে, তারপর আপনার ডেপ্লয় করা গ্রাফ থেকে সরাসরি কী কী এক্সট্র্যাক্ট করতে হবে তা বের করে নেয় : এটি BigQuery-এর INFORMATION_SCHEMA.PROPERTY_GRAPHS থেকে আপনার প্রয়োগ করা CREATE PROPERTY GRAPH ডেফিনিশনটি আবার পড়ে, এটিকে রেফারেন্স করা টেবিলগুলোর স্কিমার সাথে জয়েন করে, এনটিটি, রিলেশনশিপ এবং কলামের ধরন বের করে, এবং গ্রাফ টেবিলগুলোতে ডেটা পপুলেট করে। আপনি --graph agent_decisions_graph কমান্ডের মাধ্যমে ডেপ্লয় করা গ্রাফটিকে তার নাম দিয়ে নির্দেশ করেন — এখানে পাস করার জন্য কোনো SQL ফাইল নেই।
দৌড়
স্থানীয়ভাবে bqaa context-graph :
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
আপনি একটি কাঠামোগত JSON রিপোর্ট দেখতে পাবেন:
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true নির্দেশ করে যে bqaa context-graph পাঁচটি সম্পূর্ণ সেশন খুঁজে পেয়েছে, AI.GENERATE ব্যবহার করে প্রতিটি থেকে ডিসিশন ফ্লো বের করেছে এবং সংশ্লিষ্ট সারিগুলো গ্রাফ টেবিলে লিখেছে। ডিটারমিনিস্টিক এক্সট্র্যাকশন ( --extraction-mode=compiled-only , যা নিচে আলোচনা করা হয়েছে) একই রিপোর্টের কাঠামো প্রদান করে — একই ফিল্ড, একই ok: true — এটি শুধু AI.GENERATE কলগুলো এড়িয়ে যায়।
সমস্যা সমাধান: খালি নিষ্কাশন
যদি আপনি error_code = "empty_extraction" সহ ok: false দেখতে পান, তাহলে এর সবচেয়ে সাধারণ কারণ হলো aiplatform.googleapis.com API-টি এখনও প্রোপাগেট হয়নি, অথবা আপনার অ্যাকাউন্টে roles/aiplatform.user নেই। এক মিনিট অপেক্ষা করে আবার চেষ্টা করুন, অথবা রোলটি প্রদান করুন:
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
তারপর উপরের bqaa context-graph কমান্ডটি পুনরায় চালান।
গ্রাফটিতে সারি আছে কিনা যাচাই করুন:
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
আপনি পাঁচটি সারি দেখতে পাবেন। পাঁচটি সেশন জুড়ে মোট ২৫টি গ্রাফ নোড রয়েছে — ৫টি DecisionRequest , ১৫টি DecisionOption , এবং ৫টি DecisionOutcome — যেগুলো ১৫টি evaluatesOption এজ এবং ৫টি resultedIn এজ দ্বারা যুক্ত (প্রতিটি সেশনের জন্য একটি করে ডিসিশন ওয়েব)।
ঘটনা থেকে সিদ্ধান্ত বের করার দুটি উপায়
bqaa context-graph দুটি এক্সট্র্যাকশন পাথ অফার করে। আপনার ওয়ার্কলোডের সাথে মেলে এমন একটি বেছে নিন:
- ডিফল্ট এক্সট্র্যাকশন। সবচেয়ে সহজ উপায়। ইভেন্টের বিষয়বস্তু পড়তে এবং এনটিটি ও সম্পর্ক অনুমান করতে BigQuery-এর
AI.GENERATEব্যবহার করে। কোনো অতিরিক্ত কোড ছাড়াই যেকোনো ধরনের ইভেন্টের ক্ষেত্রে কাজ করে। কোডল্যাবে এটিই ব্যবহার করা হয়েছে। - ডিটারমিনিস্টিক এক্সট্র্যাকশন (
--extraction-mode=compiled-only)। এটি কম খরচের এবং নিরীক্ষার জন্য সুবিধাজনক একটি পদ্ধতি। এটি একটি ছোট পাইথন রেফারেন্স এক্সট্র্যাক্টর ব্যবহার করে, যা আপনাকে আপনার ডোমেইনের জন্য একবার লিখতে হয়। এতে কোনো ভার্টেক্স এআই কল নেই, প্রতি-টোকেন চার্জ নেই এবং আউটপুট সম্পূর্ণরূপে পুনরুৎপাদনযোগ্য। যখন খরচের পূর্বাভাসযোগ্যতা বা কঠোর পুনরুৎপাদনযোগ্যতা গুরুত্বপূর্ণ হয়ে ওঠে, তখন প্রোডাকশন ডেপ্লয়মেন্টের জন্য এটিই বেছে নেওয়া হয়।
কন্টেক্সট গ্রাফ ডেপ্লয়মেন্ট গাইডটি উভয় পথের জন্যই একটি রেফারেন্স, যার মধ্যে IAM-এর খুঁটিনাটি এবং কীভাবে একটি রেফারেন্স এক্সট্র্যাক্টর তৈরি করতে হয়, তার বিবরণ অন্তর্ভুক্ত রয়েছে।
৮. সিদ্ধান্তের ট্রেস কোয়েরি করুন
গ্রাফটি ডেটা দিয়ে পূর্ণ হয়ে গেলে, আপনি সরাসরি অডিট প্রশ্নের উত্তর দিতে পারবেন। একটি নির্দিষ্ট প্রশ্নের কথাই ধরুন: "প্রতিটি অনুরোধের জন্য, এজেন্ট কোন বিকল্পগুলো বিবেচনা করেছে এবং এর সমাধান কীভাবে করেছে?" GQL-এ, এটি হলো অনুরোধ, তার বিকল্প এবং তার ফলাফলের উপর দিয়ে একটিমাত্র ট্রাভার্সাল।
কোয়েরিটি একটি ফাইলে ( traversal.sql ) লিখুন। পরবর্তী ধাপে এটি রান করলে ${DATASET} মার্কারটি পূরণ হয়ে যাবে:
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
এটা চালান:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
আপনি পনেরোটি সারি দেখতে পাবেন: প্রতিটি অনুরোধের জন্য তিনটি বিকল্প এবং মোট পাঁচটি অনুরোধ। প্রতিটি সারিতে অনুরোধটি, এজেন্টের বিবেচনা করা বিকল্পটি, তার নির্ভরযোগ্যতার স্কোর, চূড়ান্ত ফলাফল এবং তার কারণ দেখানো হয়।
একটি নির্দিষ্ট সিদ্ধান্তের সম্পূর্ণ চিত্র পেতে, request_id দ্বারা ফিল্টার করে অডিট টিমের প্রয়োজনীয় সারি সেটটি সংগ্রহ করুন: যেমন—আগত প্রশ্ন, বিবেচিত বিকল্পসমূহ (স্কোরসহ), এবং গৃহীত যুক্তি।
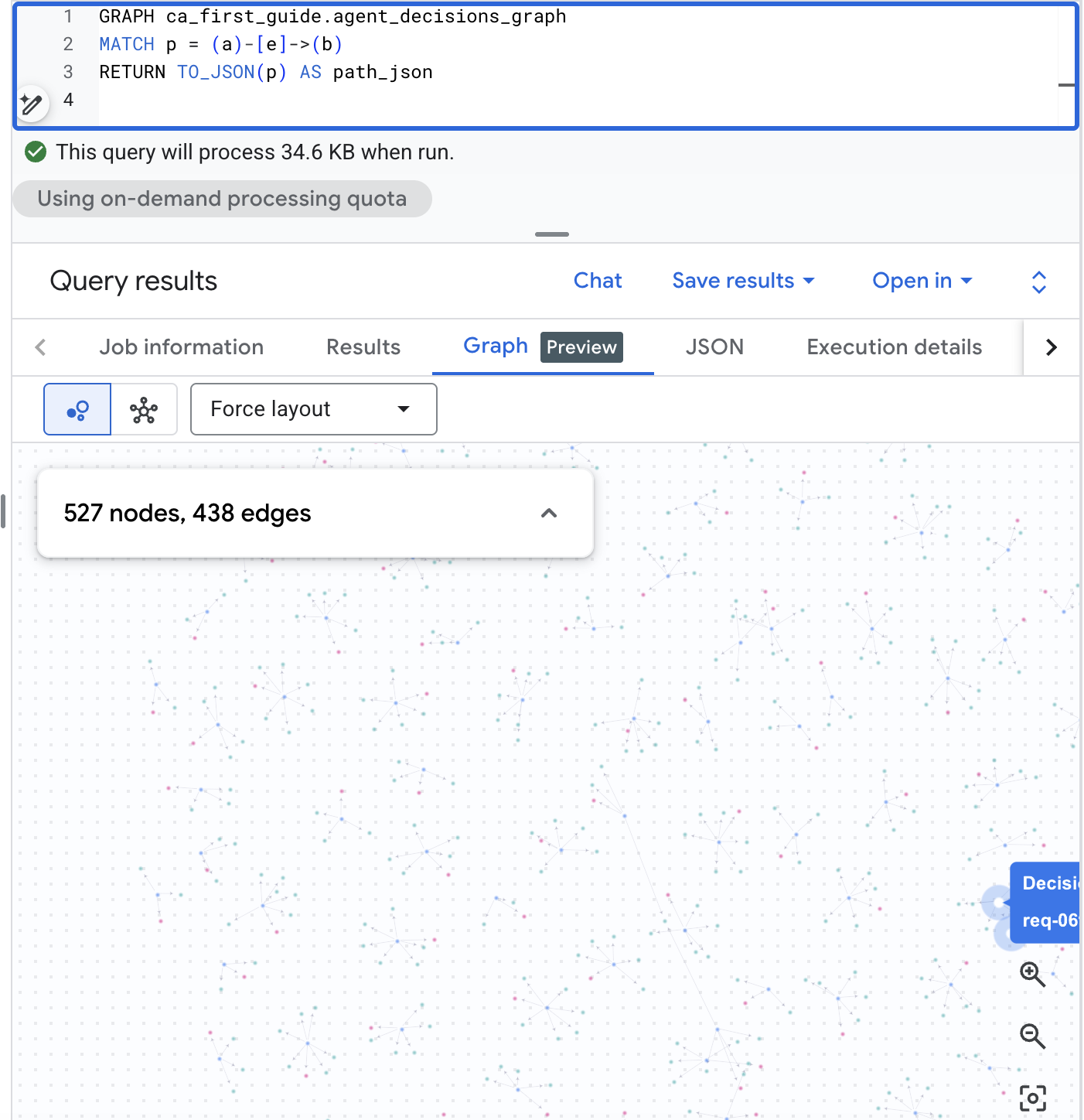
BigQuery Studio-তে গ্রাফটি ভিজ্যুয়ালাইজ করুন।
BigQuery Studio গ্রাফটি দৃশ্যমানভাবেও রেন্ডার করতে পারে। BigQuery কনসোলে BigQuery Studio খুলুন, নিচের পাথ কোয়েরিটি চালান, তারপর ডিসিশন ওয়েবটি দেখতে রেজাল্টস পেইনটি গ্রাফ ট্যাবে নিয়ে যান। বাস্তবসম্মত স্কেলের কর্পাসের সাহায্যে এটি আপনাকে রিকোয়েস্ট, অপশন এবং আউটকামের একটি ভিজ্যুয়াল ম্যাপ প্রদান করে:
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
একই প্রশ্নটি সহজ ইংরেজিতে জিজ্ঞাসা করুন।
সব অডিট রিডার GQL লেখেন না। BigQuery Conversational Analytics (Preview)-এর মাধ্যমে, আপনার কমপ্লায়েন্স টিম স্বাভাবিক ভাষায় একই ধরনের প্রশ্ন জিজ্ঞাসা করতে পারে এবং একটি স্ট্রাকচার্ড উত্তর কার্ড ফেরত পেতে পারে — কোনো কোয়েরি সিনট্যাক্স বা জয়েন শেখার প্রয়োজন নেই।
agent_decisions_graph ( agent_events এবং decision টেবিলগুলোর সাথে) একটি Conversational Analytics ডেটা সোর্স হিসেবে রেজিস্টার করুন, তারপর সরাসরি অডিট প্রশ্নটি জিজ্ঞাসা করুন:
অডিট প্রশ্ন (সহজ ভাষায়): "কোন অনুরোধগুলো কখনও প্রতিশ্রুতিবদ্ধ ফলাফলে পৌঁছায়নি?"
কনভারসেশনাল অ্যানালিটিক্স গ্রাফটি বিশ্লেষণ করে, আপনার জন্য SQL লিখে দেয় এবং একটি সহায়ক টেবিলসহ সহজ ইংরেজিতে উত্তর দেয় — এখানে দেখানো হয় যে, রেকর্ড করা প্রতিটি অনুরোধ একটি প্রতিশ্রুতিবদ্ধ ফলাফলে পৌঁছেছে:
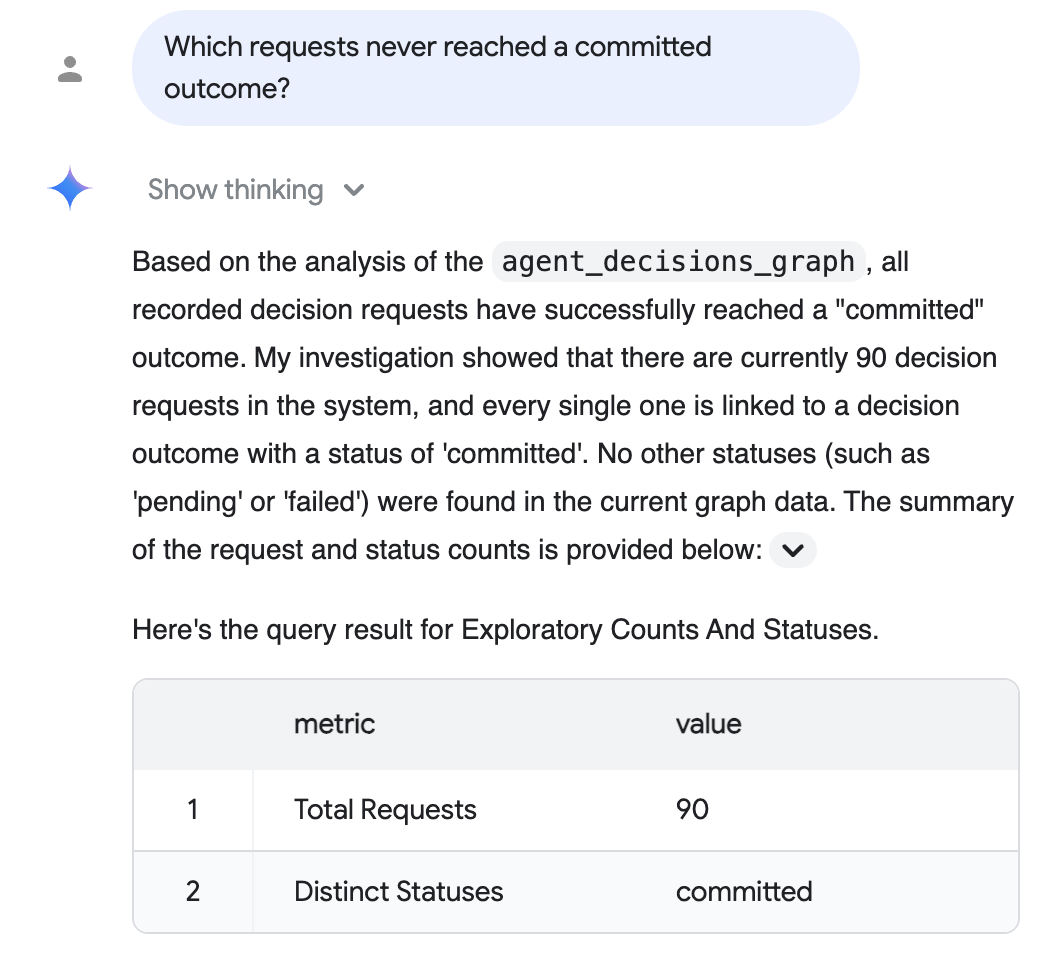
উপরের উত্তরটি ঐচ্ছিক রিয়েলিস্টিক-স্কেল ডেটা স্টেপ থেকে প্রাপ্ত বাস্তব-মাপের কর্পাসকে প্রতিফলিত করে (৯০টি ম্যাটেরিয়ালাইজড রিকোয়েস্ট, সবগুলো কমিট করা); আপনার সঠিক সংখ্যা নির্ভর করে আপনি কোন কর্পাস সিড করেছেন তার উপর, এবং ডিফল্ট ৫-সেশনের রানে পাঁচটি দেখানো হয়।
সেটআপের জন্য কনভারসেশনাল অ্যানালিটিক্স ডকুমেন্টেশন দেখুন।
৯. এটিকে উৎপাদনে নিয়ে যান
উপরের লোকাল রানটি ডিফল্ট আচরণ ব্যবহার করে, যা বাস্তব ডেপ্লয়মেন্টের জন্য প্রয়োজনীয় মৌলিক বিষয়গুলো ইতিমধ্যেই পূরণ করে: প্রতিটি রান একটি অডিট ট্রেইল রেখে যায় (স্ট্রাকচার্ড ক্লাউড লগিং এবং আপনার ডেটাসেটের একটি স্টেট টেবিলে প্রতি-রানের জন্য একটি সারি), সাময়িক ব্যর্থতা স্বয়ংক্রিয়ভাবে পুনরায় চেষ্টা করে, এবং অগ্রগতি কেবল সম্পূর্ণরূপে সফল সেশনগুলোর ক্ষেত্রেই অগ্রসর হয়, ফলে কোনো দ্বৈত গণনা হয় না।
প্রোডাকশন কন্ট্রোল — ডিটারমিনিস্টিক এক্সট্র্যাকশন ( --extraction-mode=compiled-only ), স্টাক-সেশন ডিটেকশন ( --max-session-age-hours ), অতীতের কোনো উইন্ডোর ওয়ান-শট রিপ্লে ( --backfill --from / --to , যা সাধারণ রিফ্রেশ থেকে আলাদাভাবে ট্র্যাক করা হয় যাতে এটি লাইভ শিডিউলে ব্যাঘাত ঘটাতে না পারে), এবং প্রতি-রান ব্যাচ বাউন্ডিং ( --max-sessions ) — হলো ঐচ্ছিক ফ্ল্যাগ যা প্রয়োজনের সময় ব্যবহার করা হয়। কনটেক্সট গ্রাফ ডেপ্লয়মেন্ট গাইডে সম্পূর্ণ IAM ম্যাট্রিক্স এবং প্রস্তাবিত শিডিউলসহ প্রতিটি বিষয় নথিভুক্ত করা আছে।
১০. পরিষ্কার করুন
আপনার তৈরি করা ডেটা সেটটি মুছে ফেলুন , যাতে একটি নিষ্ক্রিয় ডেটা সেটের জন্য আপনাকে বিল করা না হয়:
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
ওই একটিমাত্র কমান্ডই ডেটাসেট, এজেন্ট ইভেন্ট, গ্রাফ টেবিল এবং স্টেট টেবিল একসাথে মুছে ফেলে।
১১. অভিনন্দন
অভিনন্দন! আপনি কোনো বাহ্যিক গ্রাফ ডেটাবেস বা ETL পাইপলাইন ছাড়াই, এজেন্টের সাধারণ ইভেন্ট লগগুলোকে একটি কোয়েরিযোগ্য এজেন্ট কনটেক্সট গ্রাফে রূপান্তরিত করেছেন এবং একটিমাত্র সিদ্ধান্তের শুরু থেকে শেষ পর্যন্ত অনুসরণ করেছেন।
যেখানেই একজন এজেন্ট গুরুত্বপূর্ণ সিদ্ধান্ত গ্রহণ করেন, সেখানেই একই প্যাটার্ন প্রযোজ্য: যেমন ক্রেডিট আন্ডাররাইটিং, পূর্বানুমোদন, মার্কেটিং বাজেট পরিবর্তন, সংগ্রহ, গ্রাহক পরিষেবা এবং অভ্যন্তরীণ আইটি। আপনার নিজস্ব এজেন্ট কনটেক্সট গ্রাফ তৈরি করতে, শুরুর বিন্দু হিসেবে কোডল্যাব আর্টিফ্যাক্টগুলো কপি করুন, দুটি ডিক্লারেটিভ ফাইল (টেবিল ডিডিএল + CREATE PROPERTY GRAPH স্কিমা) আপনার ডোমেইনের সাথে মানিয়ে নিন এবং BigQuery-তে প্রয়োগ করুন — bqaa context-graph --graph INFORMATION_SCHEMA থেকে ডেপ্লয় করা গ্রাফটি পড়ে নেয় এবং বাকি অংশ ডিরাইভ করে।
আপনি যা শিখেছেন
- কিভাবে একটি BigQuery ডেটাসেট তৈরি করতে হয় এবং এজেন্ট ডিসিশন ডোমেন বর্ণনা করে এমন একটি প্রপার্টি-গ্রাফ স্কিমা প্রয়োগ করতে হয়।
- একটি কৃত্রিম ইভেন্ট কর্পাস দিয়ে
agent_eventsকীভাবে পূরণ করা যায়। -
INFORMATION_SCHEMAথেকে গ্রাফের সংজ্ঞাটি রিড করে, সেই ইভেন্টগুলো থেকে এজেন্টের ডিসিশন ট্রেসগুলোকে একটি এজেন্ট কনটেক্সট গ্রাফে এক্সট্র্যাক্ট করার জন্য কীভাবেbqaa context-graphরান করতে হয়। - GQL-এ প্রাপ্ত গ্রাফটি কীভাবে কোয়েরি করবেন এবং অডিট-স্টাইলের উত্তরটি কীভাবে পড়বেন।
রেফারেন্স নথি
- BigQuery এজেন্ট অ্যানালিটিক্স SDK রিপোজিটরি
- কোডল্যাব আর্টিফ্যাক্ট এবং অভিযোজন নির্দেশিকা
- কন্টেক্সট গ্রাফ ডেপ্লয়মেন্ট গাইড : প্রয়োজনীয় এপিআই, আইএএম ম্যাট্রিক্স, প্রস্তাবিত শিডিউল, ক্লাউড মনিটরিং অ্যালার্ট কোয়েরি এবং টেরাফর্ম মডিউল।
- BigQuery গ্রাফ ডকুমেন্টেশন (প্রিভিউ)।
- BigQuery কথোপকথনমূলক বিশ্লেষণ ডকুমেন্টেশন (প্রিভিউ)।