
1. Einführung
BigQuery Graph, BigQuery Conversational Analytics und das BigQuery Agent Analytics SDK sind derzeit in der Vorschauversion in Google Cloud verfügbar. Das BigQuery Agent Analytics-Plug-in ist allgemein verfügbar. In den Beispielen in diesem Codelab werden synthetische Daten verwendet.
Da autonome KI-Agents immer mehr operative Aufgaben übernehmen (z. B. die Bewertung von Kreditanträgen, die Verwaltung von Marketingbudgets und die Genehmigung von Zugriffsanfragen), müssen Unternehmen in der Lage sein, ihre Entscheidungen zu prüfen und zu erklären. Die Rekonstruktion des genauen Kontexts, der in Betracht gezogenen Alternativen und der endgültigen Begründung für die Entscheidung eines Agenten ist für Compliance, Risikomanagement und operatives Vertrauen unerlässlich.
In diesem Codelab wird das BigQuery Agent Analytics SDK verwendet, um Rohereignislogs von Agents in einen Agent Context Graph zu transformieren. Das ist ein abfragbarer Graph in BigQuery Graph mit Agent-Entscheidungen, der regelmäßig aktualisiert wird. Dazu sind keine externe Graphdatenbank oder ETL-Pipeline erforderlich.
Wichtige Begriffe
- Agent Decision Trace: Die auf Entscheidungsebene aus den eigenen Ausführungen eines Agenten abgeleiteten Beweise: die Optionen, die er in Betracht gezogen hat, die Daten, auf die er zugegriffen hat, und das Ergebnis, für das er sich entschieden hat.
- Kontextdiagramm für Agenten: Der typisierte, abfragbare Graph in BigQuery Graph, in dem diese Traces materialisiert werden. Es handelt sich um die agentenspezifische Instanz des Konzepts des Kontextdiagramms für die Branche – die dauerhafte, zeitbezogene Ebene des Entscheidungsfindungsprozesses, die von Agents sowohl erstellt als auch genutzt wird. Der Qualifikator „Agent“ bezieht sich auf die Ausführungen Ihrer eigenen Agents und nicht auf eine unternehmensweite Kontextebene.
In diesem Codelab extrahiert bqaa context-graph die Entscheidungs-Traces des Agents aus Ihrem agent_events und materialisiert sie in einem Agent Context Graph, den Sie mit GQL abfragen können. Dies entspricht dem Branchenmuster, bei dem Kontextgraphen aus Entscheidungs-Traces erstellt werden.
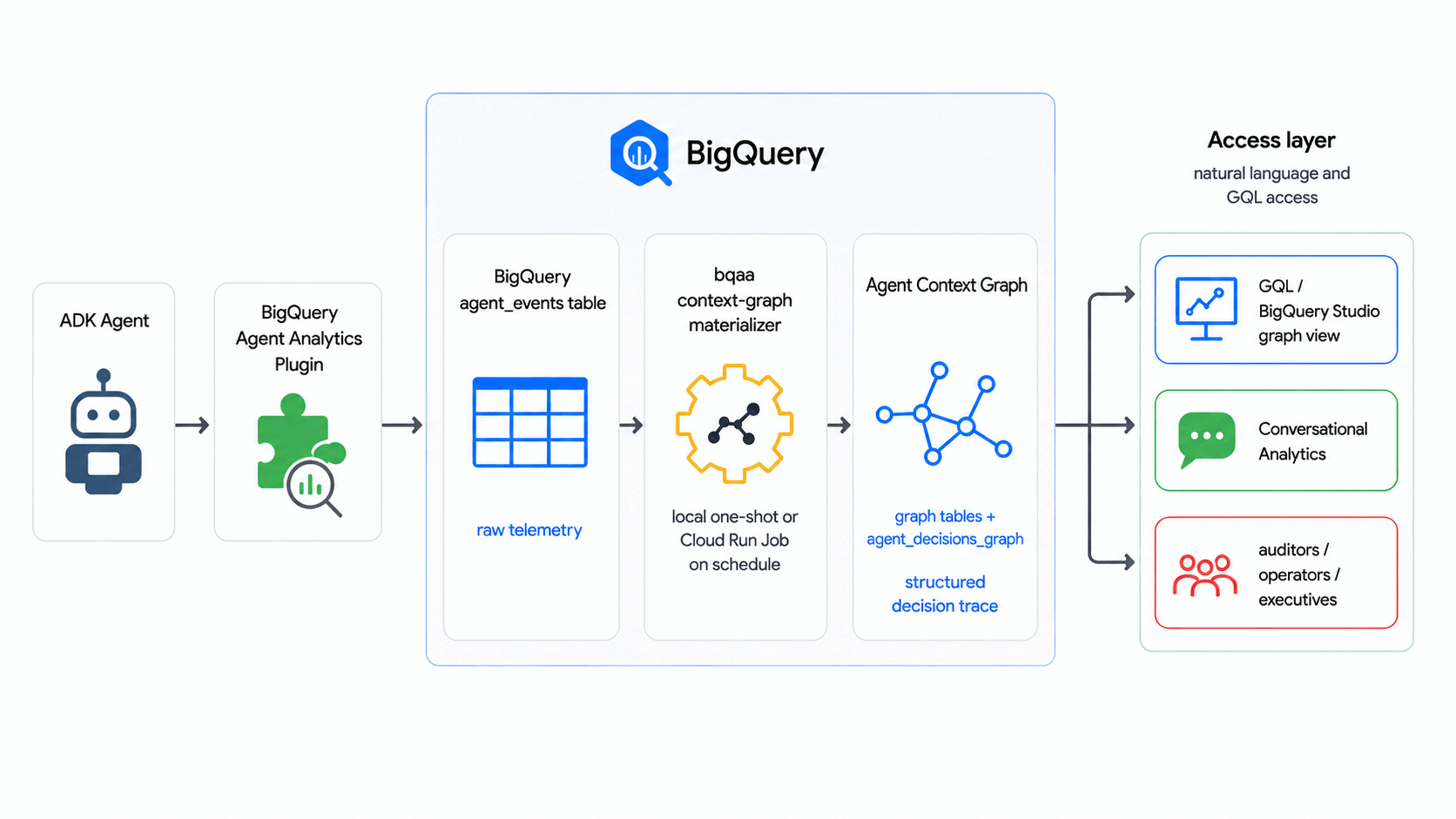
Aufgaben
- Ein Agent Context Graph (mit BigQuery Graph), der einen generischen Entscheidungsablauf für Agenten modelliert: Eine Anfrage geht ein, der Agent wägt Optionen ab und ein Ergebnis wird festgelegt.
- Eine gefüllte
agent_events-Tabelle mit einem synthetischen Ereigniskorpus. - Ein funktionierender
bqaa context-graph-Lauf, der das Diagramm mit diesen Ereignissen füllt. - Eine GQL-Abfrage im Prüfstil, die eine einzelne Entscheidung von Anfang bis Ende nachvollzieht.
Lerninhalte
- So schreibt das BigQuery Agent Analytics-Plug-in in
agent_events. - Wie ein Kontextdiagramm durch nur zwei deklarative Artefakte definiert wird: eine Tabellen-DDL und ein
CREATE PROPERTY GRAPH-Schema. bqaa context-graphfür einen BigQuery-Graphen ausführen- Anleitung zum Abfragen eines Diagramms mit GQL
- Die Funktionen, die das SDK für die Produktion für Unternehmensbereitstellungen unterstützt.
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Rolle „Inhaber“ oder „Bearbeiter“ für dieses Projekt. Sie erstellen ein BigQuery-Dataset und gewähren IAM.
- Die
gcloudCLI ist installiert und authentifiziert oder Sie haben Zugriff auf Cloud Shell. - Python 3.10 oder höher.
- Vertrautheit mit BigQuery SQL. GQL-Kenntnisse sind nicht erforderlich.
Dieses Codelab richtet sich an Entwickler aller Erfahrungsstufen, auch an diejenigen, die noch keine Erfahrung mit BigQuery Graph haben.
Die in diesem Codelab erstellten Ressourcen kosten sehr wenig. Im letzten Schritt wird alles entfernt, sodass Ihnen keine Gebühren für ein inaktives Dataset in Rechnung gestellt werden.
Geschätzte Dauer:Dieses Codelab dauert etwa 35 Minuten.
2. Hinweis
Projekt und Region auswählen
Öffnen Sie Cloud Shell oder ein lokales Terminal:
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
Die einzelne DATASET-Variable enthält sowohl die Rohdaten-agent_events-Tabelle als auch die materialisierten Diagrammtabellen. Durch die Verwendung eines Datasets wird das Codelab einfach gehalten. Bei Produktionsbereitstellungen werden Ereignisse und Grafiken häufig in separate Datasets aufgeteilt, damit IAM-Berechtigungen pro Dataset eingeschränkt werden können.
Erforderliche APIs aktivieren
Führen Sie den folgenden Befehl aus, um die APIs zu aktivieren, die in diesem Codelab verwendet werden:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
Die aiplatform.googleapis.com API ist erforderlich, da im Standardextraktionspfad des SDK die BigQuery-Funktion AI.GENERATE aufgerufen wird. Wenn Sie später zur deterministischen Extraktion mit --extraction-mode=compiled-only wechseln, ist diese API nicht mehr erforderlich.
BigQuery-Dataset erstellen
Erstellen Sie das Dataset, das sowohl die Rohdatentabelle agent_events als auch die materialisierten Diagrammtabellen enthält:
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
Es sollte eine Erfolgsmeldung angezeigt werden:
Dataset 'your-project-id:agent_analytics_demo' successfully created.
Wenn das Dataset bereits vorhanden ist, wird ein harmloser Fehler zurückgegeben. Lassen Sie es an seinem Platz.
3. SDK Installieren
Richten Sie eine virtuelle Python-Umgebung ein und installieren Sie das SDK aus PyPI:
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
Das Paket bigquery-agent-analytics ruft die BigQuery-Clientbibliothek ab. Das ist die einzige Installation, die Sie für das gesamte Codelab benötigen.
Installation überprüfen:
bqaa context-graph --help | head -8
Das CLI-Banner sollte angezeigt werden.
Authentifizieren
Wenn Sie einen Arbeitsplatzcomputer verwenden:
gcloud auth login
gcloud auth application-default login
Cloud Shell-Nutzer können diesen Schritt überspringen, da die Anmeldedaten bereits konfiguriert sind.
4. Codelab-Artefakte abrufen
Für das Codelab sind nur zwei gebrauchsfertige Artefakte erforderlich: die Tabellen-DDL (die physischen Diagrammtabellen) und das Eigenschaftsdiagrammschema (CREATE PROPERTY GRAPH). Sie erstellen keines der beiden selbst. Im Codelab werden sie unverändert verwendet. In der README-Datei im Artefaktordner wird beschrieben, wie Sie sie an Ihre eigene Entscheidungsdomäne anpassen können.
Das Attributgrafikschema ist die einzige Quelle für Informationen darüber, was der Graph enthält. Sie wenden sie einmal auf BigQuery an. Danach ist der bereitgestellte Graph selbst der Vertrag. Beim Materialisieren liest bqaa context-graph die Definition des Diagramms aus INFORMATION_SCHEMA.PROPERTY_GRAPHS von BigQuery (zusammen mit den Schemas der Tabellen, auf die verwiesen wird), um zu ermitteln, welche Einheiten und Beziehungen extrahiert und wohin sie geschrieben werden sollen. Es wird also nie eine SQL-Datei an den Materializer übergeben.
Dieses Codelab ist in sich abgeschlossen, es muss also nichts heruntergeladen werden. Mit dem folgenden Befehl wird die DDL des Kontextdiagramms in ein Arbeitsverzeichnis geschrieben. Der Inhalt ist mit den Artefakten identisch, die in examples/context_graph/codelab/ ausgeliefert werden.
Arbeitsverzeichnis erstellen:
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
DDL für den Kontextgraphen schreiben (context_graph_ddl.sql). Die Markierungen ${PROJECT_ID} / ${DATASET} werden ausgefüllt, wenn Sie die Datei im nächsten Schritt anwenden.
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
Prüfen Sie, ob die Datei vorhanden ist:
ls
Sie sollten eine Datei sehen:
context_graph_ddl.sql
Der beschriebene Entscheidungsablauf hat drei Knotentypen und zwei heterogene Kanten:
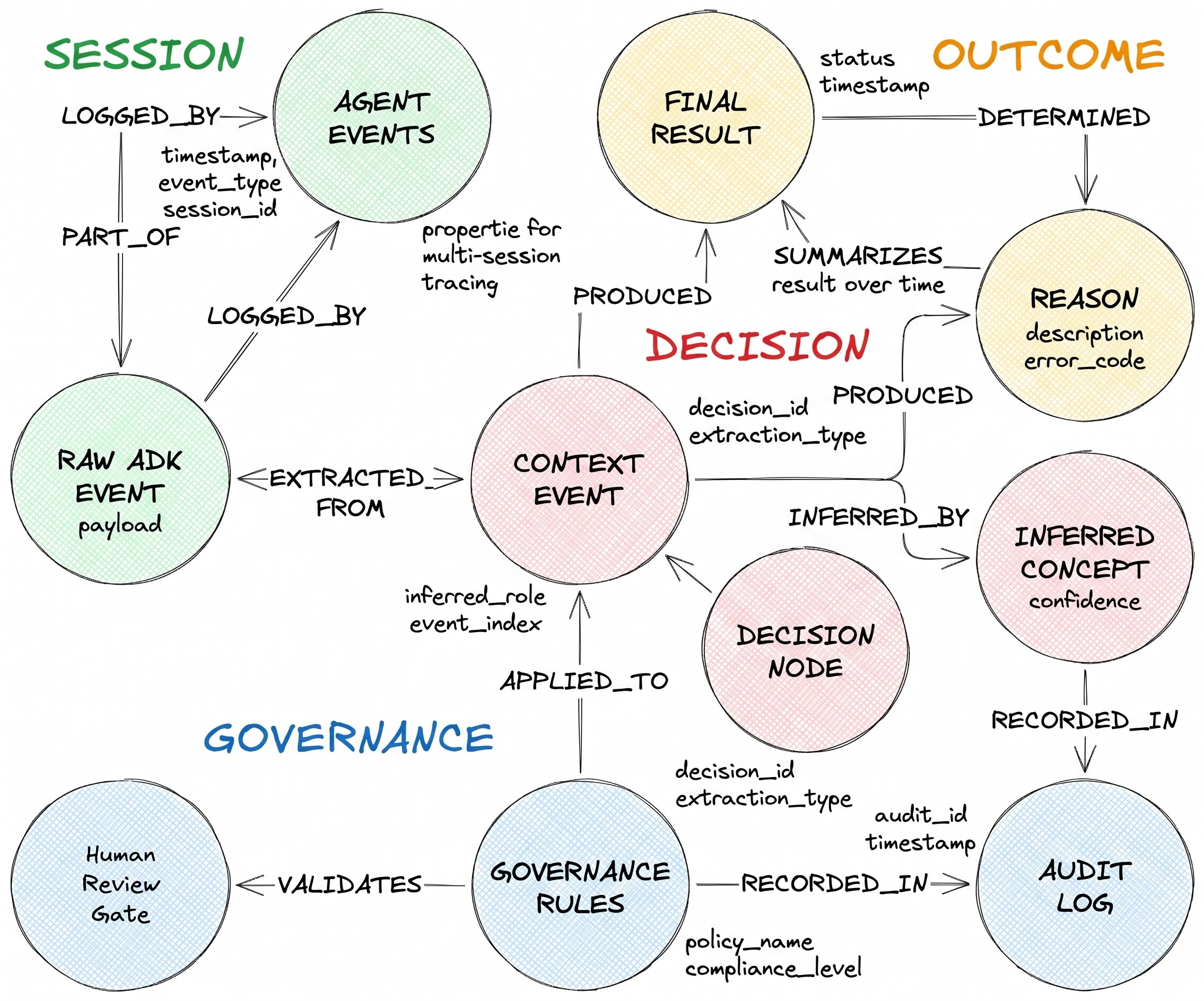
DecisionRequest ist die Frage, die der Agent erhalten hat. DecisionOption ist eine Alternative, die der Agent in Betracht gezogen hat. DecisionOutcome zeichnet die getroffene Entscheidung und die Begründung auf.
5. Attributgrafikschema anwenden
bqaa context-graph schreibt in BigQuery-Tabellen. Diese müssen also vor dem ersten Lauf vorhanden sein. Mit context_graph_ddl.sql werden zuerst die fünf Tabellen und dann der Eigenschaftsgraph erstellt, der auf sie verweist. BigQuery lehnt eine CREATE PROPERTY GRAPH ab, die auf Tabellen verweist, die noch nicht vorhanden sind. Daher wird mit einem einzelnen Apply alles eingerichtet:
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
Sie sollten fünf CREATE TABLE-Ergebnisse und ein CREATE PROPERTY GRAPH-Ergebnis sehen. Die DDL ist idempotent. Sie können sie also problemlos noch einmal ausführen.
Das ist die einzige Schemaarbeit, die Sie durchführen müssen, und die einzige Zeit, in der diese SQL-Dateien verwendet werden. BigQuery speichert jetzt die Definition des Diagramms und bqaa context-graph liest sie anhand des Namens aus INFORMATION_SCHEMA.PROPERTY_GRAPHS. Es gibt keine separate Datei, die an den Materializer übergeben werden muss. Die Abfrage mit GQL und die Materialisierung können sich nie voneinander entfernen, da es sich um denselben bereitgestellten Graphen handelt.
6. Beispielhafte Agentenereignisse generieren
In der Produktion erfasst das BigQuery Agent Analytics-Plug-in Ereignisse automatisch, wenn Ihr ADK-Agent ausgeführt wird. Dieses Snippet dient nur als Referenz. Sie führen es in diesem Codelab nicht aus:
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
In diesem Codelab verwenden Sie einen kleinen synthetischen Ereignisgenerator, der Zeilen mit derselben Form direkt in agent_events schreibt. Führen Sie das Namespace aus:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
Mit dem Befehl wird ein JSON-Bericht ausgegeben. Bei 5 Sitzungen sollten Sie "events_generated": 30, "events_inserted": 30 und "ok": true sehen.
In einer Zeile sehen Sie auf einen Blick eine Vorschau des Korpus – wie viele Sitzungen, wie viele Ereignisse und den Zeitraum, den sie abdecken:
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
Für den Standardlauf mit fünf Sitzungen werden fünf Sitzungen und 30 Ereignisse über einige Minuten hinweg angezeigt. (Seed the realistic scenario below and the same query reports ~100 sessions across roughly three days.)
Prüfen Sie, ob die Ereignisse erfasst wurden:
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
Sie sollten 25 TOOL_COMPLETED-Zeilen und 5 AGENT_COMPLETED-Zeilen sehen. Für jede Sitzung wird ein submit_request, drei evaluate_option, ein commit_outcome und ein schließendes AGENT_COMPLETED ausgegeben – fünf Tool-Ereignisse plus ein Agent-Terminator pro Sitzung. Die AGENT_COMPLETED-Zeilen sind die Sitzungsbeender, die bqaa context-graph für die Erkennung von Terminalereignissen verwendet.
Optional: Daten im realistischen Maßstab
Der oben genannte Korpus mit fünf Sitzungen ist bewusst klein, damit der erste Lauf schnell und kostengünstig ist. Wenn Sie Daten in Produktionsqualität benötigen – mehrere Agenten und Nutzer über mehrere Tage hinweg, mit fehlgeschlagenen, verwaisten und gekürzten Sitzungen –, verwenden Sie das decision-realistic-Szenario. Standardmäßig sind das 100 Sitzungen innerhalb von 72 Stunden. Der oben beschriebene Pfad für die erste Ausführung bleibt unverändert.
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
Im session_outcome_counts des JSON-Berichts wird der Mix angezeigt – ungefähr {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10}.
Bestimmen Sie die Ergebnisverteilung, indem Sie jede Sitzung anhand ihrer Zeilen klassifizieren (verwaist = kein AGENT_COMPLETED; fehlgeschlagen = AGENT_COMPLETED mit status = 'error'; gekürzt = eine beliebige Zeile mit is_truncated = true; ansonsten erfolgreich). Im ersten Durchgang wird jede Sitzung klassifiziert, im zweiten Durchgang werden die Ergebnisse nach Ergebnis aggregiert:
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
Sie sollten etwa 70 erfolgreiche, 10 fehlgeschlagene, 10 verwaiste und 10 gekürzte Sitzungen sehen (plus die 5 erfolgreichen Sitzungen aus dem Corpus des ersten Laufs, wenn Sie diesen zuvor im selben Dataset eingefügt haben).
Für die 10 verwaisten Sitzungen wurde nie AGENT_COMPLETED ausgegeben. Daher werden sie beim Standardlauf von bqaa context-graph übersprungen, da nur Sitzungen mit einem Endereignis materialisiert werden. Damit sie als session_orphaned angezeigt werden, anstatt dass die Anfrage immer wieder im Hintergrund wiederholt wird, fügen Sie --max-session-age-hours hinzu, wenn Sie den Befehl ausführen. Weitere Informationen finden Sie unter --max-session-age-hours im Abschnitt In der Produktionsumgebung verwenden.
7. Kontextdiagramm materialisieren
bqaa context-graph liest die Rohdaten agent_events und leitet dann ab, was direkt aus dem bereitgestellten Diagramm extrahiert werden soll: Die CREATE PROPERTY GRAPH-Definition, die Sie in Eigenschaftsgraf-Schema anwenden angewendet haben, wird aus der INFORMATION_SCHEMA.PROPERTY_GRAPHS von BigQuery gelesen, mit den Schemas der Tabellen zusammengeführt, auf die verwiesen wird, die Entitäten, Beziehungen und Spaltentypen werden ermittelt und die Diagrammtabellen werden gefüllt. Sie verweisen mit --graph agent_decisions_graph über den Namen auf den bereitgestellten Graphen. Es gibt keine SQL-Datei, die übergeben werden muss.
Laufen
bqaa context-graph lokal:
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
Sie sollten einen strukturierten JSON-Bericht sehen:
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true gibt an, dass bqaa context-graph fünf abgeschlossene Sitzungen gefunden, den Entscheidungsablauf aus jeder Sitzung über AI.GENERATE extrahiert und die entsprechenden Zeilen in die Diagrammtabellen geschrieben hat. Bei der deterministischen Extraktion (--extraction-mode=compiled-only, siehe unten) wird die gleiche Berichtsform zurückgegeben – dieselben Felder, dieselbe ok: true –, nur die AI.GENERATE-Aufrufe werden übersprungen.
Fehlerbehebung: Leere Extraktion
Wenn Sie ok: false mit error_code = "empty_extraction" sehen, liegt das in den meisten Fällen daran, dass die aiplatform.googleapis.com API noch nicht weitergegeben wurde oder in Ihrem Konto roles/aiplatform.user fehlt. Warten Sie eine Minute und versuchen Sie es noch einmal oder weisen Sie die Rolle zu:
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
Führen Sie den Befehl bqaa context-graph dann noch einmal aus.
Prüfen Sie, ob die Grafik Zeilen enthält:
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
Es sollten fünf Zeilen angezeigt werden. Das sind insgesamt 25 Knoten in den fünf Sitzungen: 5 DecisionRequest, 15 DecisionOption und 5 DecisionOutcome, verbunden durch 15 evaluatesOption-Kanten und 5 resultedIn-Kanten (ein Entscheidungsbaum pro Sitzung).
Zwei Möglichkeiten, Entscheidungen aus Ereignissen zu extrahieren
bqaa context-graph bietet zwei Extraktionspfade. Wählen Sie die Option aus, die Ihrer Arbeitslast entspricht:
- Standardextraktion: Der einfachste Weg. Verwendet die
AI.GENERATEvon BigQuery, um Ereignisinhalte zu lesen und Entitäten und Beziehungen abzuleiten. Funktioniert für jede Ereignisform ohne zusätzlichen Code. Das wird im Codelab verwendet. - Deterministische Extraktion (
--extraction-mode=compiled-only): Der kostengünstigere, prüffreundliche Weg. Es wird ein kleiner Python-Referenzextractor verwendet, den Sie einmal für Ihre Domain schreiben. Keine Vertex AI-Aufrufe, keine Gebühren pro Token, vollständig reproduzierbare Ausgabe. Bei Produktionsbereitstellungen wird diese Option ausgewählt, wenn Kostenvorhersagbarkeit oder strenge Reproduzierbarkeit wichtig sind.
Der Bereitstellungsleitfaden für den Kontextgraphen ist die Referenz für beide Pfade, einschließlich der IAM-Details und der Erstellung eines Referenzextraktors.
8. Entscheidungsablauf abfragen
Wenn das Diagramm erstellt wurde, können Sie die Prüfungsfrage direkt beantworten. Ein konkretes Beispiel: Welche Optionen hat der Agent für jede Anfrage in Betracht gezogen und wie hat er die Anfrage bearbeitet? In GQL ist das ein einzelner Durchlauf der Anfrage, ihrer Optionen und ihres Ergebnisses.
Schreiben Sie die Abfrage in eine Datei (traversal.sql). Die Markierung ${DATASET} wird ausgefüllt, wenn Sie die Abfrage im nächsten Schritt ausführen:
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
Ausführen:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
Sie sollten 15 Zeilen sehen: drei Optionen pro Anfrage, fünf Anfragen. In jeder Zeile sehen Sie die Anfrage, die vom Kundenservicemitarbeiter in Betracht gezogene Option, den Konfidenzwert, das Endergebnis und die Begründung.
Wenn Sie sich ein vollständiges Bild von einer einzelnen Entscheidung machen möchten, filtern Sie nach request_id, um die Zeilengruppe zu erhalten, die ein Prüfteam benötigt: die eingegangene Frage, die in Betracht gezogenen Optionen (mit Punktzahlen) und die zugrunde liegende Begründung.
Diagramm in BigQuery Studio visualisieren
BigQuery Studio kann den Graphen auch visuell darstellen. Öffnen Sie BigQuery Studio in der BigQuery Console, führen Sie die Pfadabfrage unten aus und wechseln Sie dann im Ergebnisbereich zum Tab Diagramm, um das Entscheidungsnetzwerk zu sehen. Mit dem Korpus im realistischen Maßstab erhalten Sie eine visuelle Karte der Anfragen, Optionen und Ergebnisse:
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
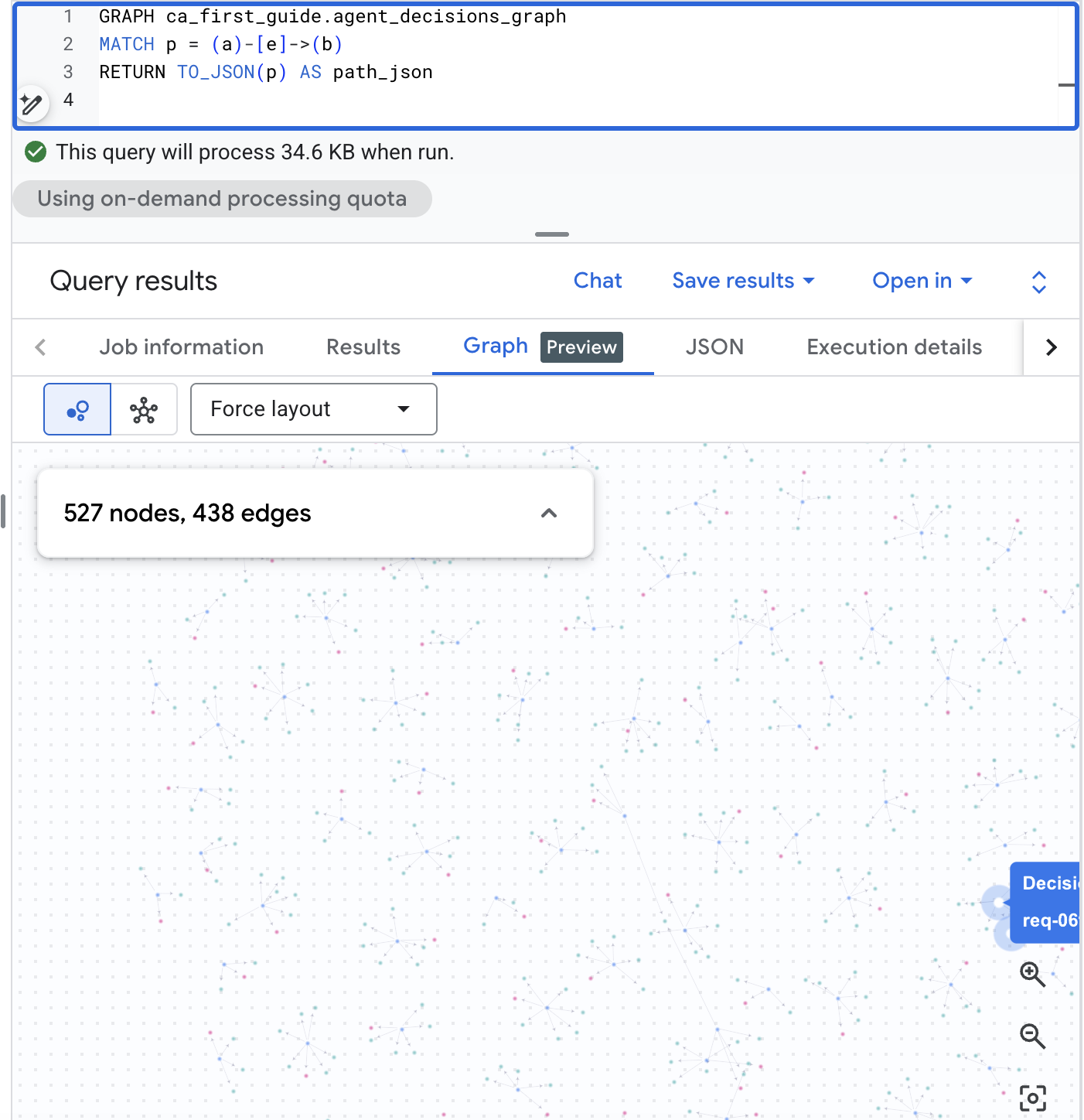
Stellen Sie die gleiche Frage in einfachem Englisch.
Nicht jeder Prüfer schreibt GQL. Mit BigQuery Conversational Analytics (Vorschau) kann Ihr Compliance-Team dieselben Fragen in natürlicher Sprache stellen und erhält eine strukturierte Antwortkarte – ohne Abfragesyntax und ohne Joins.
Registrieren Sie agent_decisions_graph (zusammen mit den agent_events- und Entscheidungstabellen) als Datenquelle für die konversationelle Analyse und stellen Sie dann die Prüffrage direkt:
Prüffrage (in einfachem Deutsch) : „Welche Anfragen haben nie ein zugesichertes Ergebnis erreicht?“
Conversational Analytics analysiert den Graphen, schreibt den SQL-Code für Sie und antwortet in Alltagssprache mit einer unterstützenden Tabelle. Hier wird gezeigt, dass jede aufgezeichnete Anfrage zu einem zugesagten Ergebnis geführt hat:
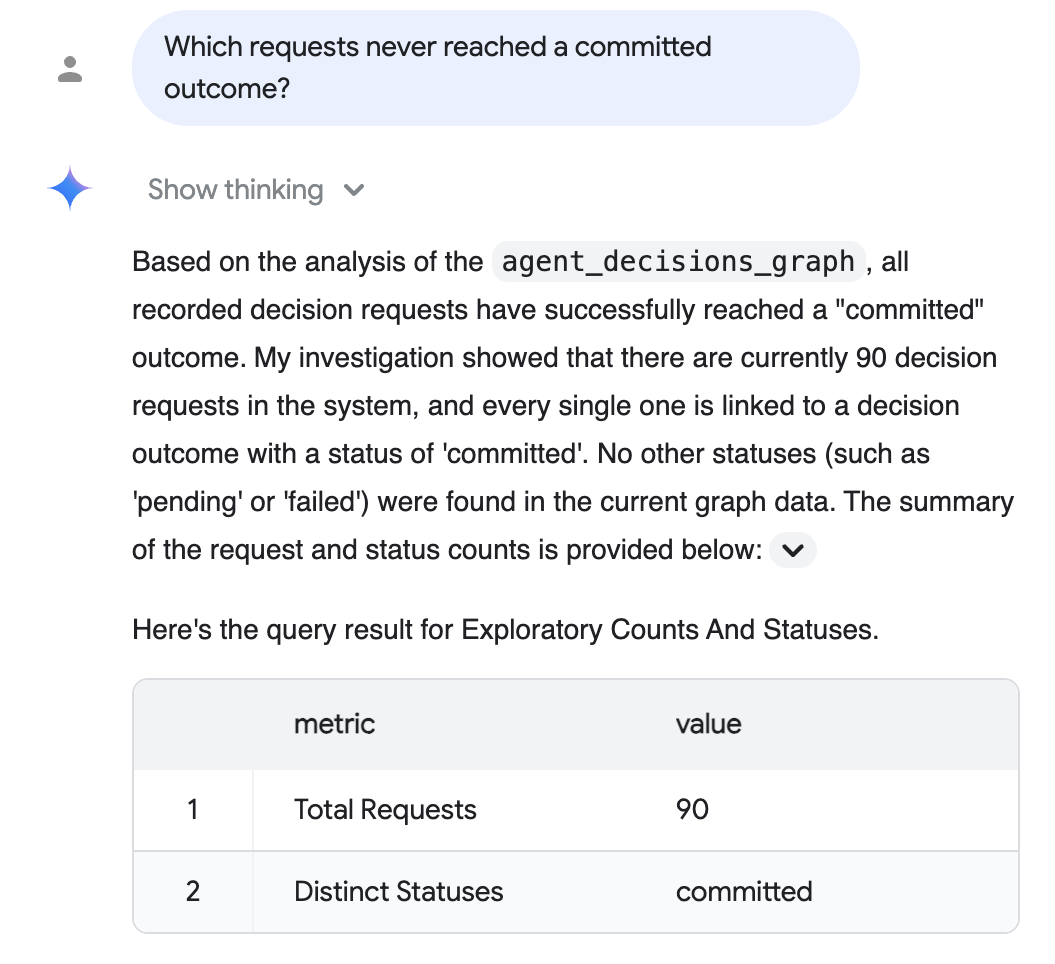
Die Antwort oben spiegelt den Korpus im realistischen Maßstab aus dem optionalen Schritt Daten im realistischen Maßstab wider (90 materialisierte Anfragen, alle übernommen). Ihre genauen Zahlen hängen davon ab, welchen Korpus Sie als Ausgangspunkt verwendet haben. Beim Standardlauf mit fünf Sitzungen werden fünf angezeigt.
Informationen zur Einrichtung finden Sie in der Dokumentation zur konversationellen Analyse.
9. In die Produktion überführen
Für den oben beschriebenen lokalen Lauf wird das Standardverhalten verwendet, das bereits die Grundlagen für echte Bereitstellungen abdeckt: Jeder Lauf hinterlässt einen Audit-Trail (strukturierte Cloud Logging-Einträge sowie eine Zeile pro Lauf in einer Status-Tabelle in Ihrem Dataset), vorübergehende Fehler werden automatisch wiederholt und der Fortschritt wird nur bei vollständig erfolgreichen Sitzungen erhöht, sodass es keine Doppelzählung gibt.
Die Produktionskontrollen – deterministische Extraktion (--extraction-mode=compiled-only), Erkennung von hängenden Sitzungen (--max-session-age-hours), einmalige Wiedergabe eines vergangenen Zeitraums (--backfill --from / --to, wird separat vom regulären Aktualisieren erfasst, damit der Live-Zeitplan nicht beeinträchtigt wird) und Batch-Begrenzung pro Ausführung (--max-sessions) – sind Opt-in-Flags, die Sie bei Bedarf verwenden können. Im Bereitstellungsleitfaden für Kontextdiagramme wird jede Rolle mit der vollständigen IAM-Matrix und den empfohlenen Zeitplänen dokumentiert.
10. Bereinigen
Erstellte Ressourcen entfernen, damit Ihnen keine Kosten für ein inaktives Dataset in Rechnung gestellt werden:
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
Mit diesem einen Befehl werden das Dataset, die Agent-Ereignisse, die Diagrammtabellen und die Status-Tabelle zusammen entfernt.
11. Glückwunsch
Glückwunsch! Sie haben Roh-Agent-Ereignisprotokolle in ein abfragbares Agent Context Graph umgewandelt und eine einzelne Entscheidung von Anfang bis Ende nachvollzogen, ohne eine externe Grafikdatenbank oder ETL-Pipeline zu verwenden.
Dasselbe Muster gilt überall dort, wo ein KI-Agent wichtige Entscheidungen trifft: Kreditprüfung, Vorabgenehmigung, Änderungen am Marketingbudget, Beschaffung, Kundenservice und interne IT. Wenn Sie Ihren eigenen Agent Context Graph erstellen möchten, kopieren Sie die Codelab-Artefakte als Ausgangspunkt, passen Sie die beiden deklarativen Dateien (Tabellen-DDL + CREATE PROPERTY GRAPH-Schema) an Ihre Domain an und wenden Sie sie auf BigQuery an. bqaa context-graph --graph liest den bereitgestellten Graphen aus INFORMATION_SCHEMA und leitet den Rest ab.
Das haben Sie gelernt
- So erstellen Sie ein BigQuery-Dataset und wenden ein Property-Graph-Schema an, das eine Agent-Entscheidungsdomäne beschreibt.
- So füllen Sie
agent_eventsmit einem synthetischen Ereigniskorpus. - So führen Sie
bqaa context-graphaus, um die Entscheidungsspuren des Agenten aus diesen Ereignissen in ein Agent Context Graph zu extrahieren und die Grafikdefinition ausINFORMATION_SCHEMAzu lesen. - So fragen Sie den resultierenden Graphen in GQL ab und lesen die Antwort im Audit-Stil.
Referenzdokumente
- BigQuery Agent Analytics SDK-Repository
- Codelab-Artefakte und Anpassungsleitfaden
- Bereitstellungsleitfaden für Kontextdiagramme: erforderliche APIs, IAM-Matrix, empfohlene Zeitpläne, Cloud Monitoring-Benachrichtigungsabfragen und das Terraform-Modul.
- BigQuery Graph-Dokumentation (Vorschau)
- Dokumentation zu konversationellen Analysen in BigQuery (Vorschau)