
۱. مقدمه
BigQuery Graph، BigQuery Conversational Analytics و BigQuery Agent Analytics SDK در حال حاضر در پیشنمایش روی Google Cloud قرار دارند. افزونه BigQuery Agent Analytics به صورت عمومی (GA) در دسترس است. مثالهای موجود در این codelab از دادههای مصنوعی استفاده میکنند.
همچنان که عاملهای هوش مصنوعی خودمختار مسئولیتهای عملیاتی بیشتری (ارزیابی درخواستهای وام، مدیریت بودجههای بازاریابی، تأیید درخواستهای دسترسی) را بر عهده میگیرند، سازمانها باید بتوانند تصمیمات خود را حسابرسی و توضیح دهند. بازسازی دقیق زمینه، گزینههای در نظر گرفته شده و منطق نهایی تصمیم یک عامل برای انطباق، مدیریت ریسک و اعتماد عملیاتی ضروری است.
این آزمایشگاه کد از SDK مربوط به BigQuery Agent Analytics برای تبدیل گزارشهای خام رویدادهای عامل به یک Agent Context Graph - یک گراف قابل پرسوجو در BigQuery Graph از تصمیمات عامل - طبق یک برنامه زمانی، بدون هیچ پایگاه داده گراف خارجی یا خط لوله ETL استفاده میکند.
اصطلاحات کلیدی
- ردیابی تصمیم عامل - شواهد سطح تصمیمگیری که از فعالیتهای خود عامل استخراج شده است: گزینههایی که وزن داده، دادههایی که لمس کرده و نتیجهای که ثبت کرده است.
- نمودار زمینه عامل - نمودار تایپشده و قابل پرسوجو در BigQuery Graph که آن ردپاها در آن تجسم مییابند. این نمونهای از مفهوم نمودار زمینه صنعت است که توسط عامل تعریف شده است (لایه پایدار و مرتبط با زمان از زمینه تصمیمگیری که عاملها هم تولید و هم مصرف میکنند)؛ توصیفکننده "عامل" آن را به فعالیتهای عاملهای خودتان محدود میکند، نه به یک لایه زمینه در سطح سازمان.
در این آزمایشگاه کد، bqaa context-graph ردپاهای تصمیمگیری عامل را از agent_events شما استخراج کرده و آنها را در یک نمودار زمینه عامل که میتوانید با GQL پرسوجو کنید، پیادهسازی میکند - از الگوی صنعتی که در آن نمودارهای زمینه از ردپاهای تصمیمگیری ساخته میشوند، پیروی میکند.
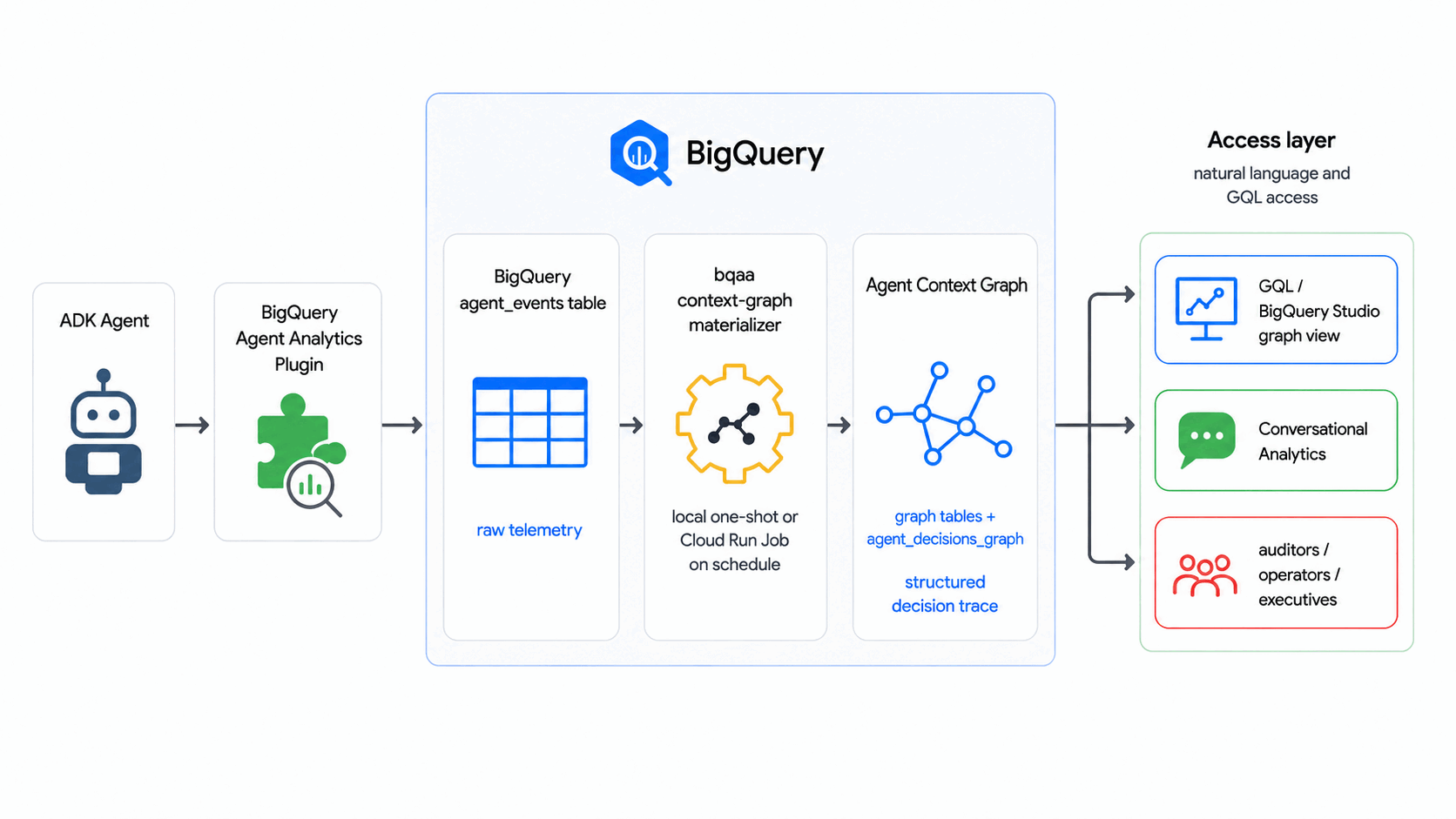
آنچه خواهید ساخت
- یک گراف زمینه عامل (با استفاده از گراف BigQuery) که یک جریان تصمیمگیری عمومی عامل را مدلسازی میکند: یک درخواست دریافت میشود، عامل گزینهها را میسنجد و نتیجهای قطعی میشود.
- یک جدول
agent_eventsپر شده با یک مجموعه رویداد مصنوعی. - یک
bqaa context-graphکارآمد که نمودار را از آن رویدادها پر میکند. - یک پرسوجوی GQL به سبک حسابرسی که یک تصمیم واحد را از ابتدا تا انتها ردیابی میکند.
آنچه یاد خواهید گرفت
- نحوه نوشتن افزونه BigQuery Agent Analytics در
agent_events. - چگونه یک نمودار زمینه تنها توسط دو مصنوع اعلانی تعریف میشود - یک جدول DDL و یک طرحواره
CREATE PROPERTY GRAPH. - نحوه اجرای
bqaa context-graphدر برابر گراف BigQuery. - نحوه پرس و جو کردن یک گراف با استفاده از GQL
- قابلیتهای سطح تولید که SDK برای استقرارهای سازمانی پشتیبانی میکند.
آنچه نیاز دارید
- یک پروژه گوگل کلود با قابلیت پرداخت.
- نقش مالک یا ویرایشگر در آن پروژه. شما یک مجموعه داده BigQuery ایجاد خواهید کرد و به IAM مجوز خواهید داد.
- رابط خط فرمان
gcloudنصب و احراز هویت شده است، یا به Cloud Shell دسترسی دارد. - پایتون ۳.۱۰ یا جدیدتر.
- آشنایی با BigQuery SQL. دانش GQL الزامی نیست.
این آزمایشگاه کد برای توسعهدهندگان در تمام سطوح، از جمله کسانی که در BigQuery Graph تازهکار هستند، مناسب است.
منابع ایجاد شده در این آزمایشگاه کد هزینه بسیار کمی دارند و در مرحله آخر همه چیز از هم جدا میشود تا برای یک مجموعه داده بلااستفاده هزینهای از شما دریافت نشود.
مدت زمان تخمینی: تکمیل این آزمایشگاه کد تقریباً 35 دقیقه طول میکشد.
۲. قبل از شروع
انتخاب پروژه و منطقه
Cloud Shell یا یک ترمینال محلی را باز کنید:
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
متغیر DATASET واحد، هم جدول خام agent_events و هم جداول گراف مادیسازیشده را در خود جای میدهد. استفاده از یک مجموعه داده، آزمایشگاه کد را ساده نگه میدارد. استقرارهای عملیاتی اغلب رویدادها و گرافها را به مجموعه دادههای جداگانه تقسیم میکنند، بنابراین میتوان IAM را به طور محدود برای هر مجموعه داده اعطا کرد.
فعال کردن API های مورد نیاز
برای فعال کردن APIهایی که این codelab استفاده میکند ، دستور زیر را اجرا کنید :
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
API مربوط به aiplatform.googleapis.com مورد نیاز است زیرا مسیر استخراج پیشفرض SDK، تابع AI.GENERATE در BigQuery را فراخوانی میکند. اگر بعداً با --extraction-mode=compiled-only به استخراج قطعی تغییر دهید، دیگر به این API نیازی نیست.
ایجاد مجموعه داده BigQuery
مجموعه دادهای ایجاد کنید که هم جدول خام agent_events و هم جداول گراف مادیسازیشده را در خود جای دهد:
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
شما باید یک پیام موفقیتآمیز ببینید:
Dataset 'your-project-id:agent_analytics_demo' successfully created.
اگر مجموعه داده از قبل وجود داشته باشد، دستور بدون هیچ ضرری خطا میدهد. آن را در جای خود بگذارید.
۳. SDK را نصب کنید
یک محیط مجازی پایتون راهاندازی کنید و SDK را از PyPI نصب کنید :
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
بسته bigquery-agent-analytics کتابخانه کلاینت BigQuery را به سیستم اضافه میکند، بنابراین این تنها نصبی است که برای کل codelab به آن نیاز دارید.
نصب را تأیید کنید:
bqaa context-graph --help | head -8
شما باید بنر CLI را ببینید.
احراز هویت
اگر در یک ایستگاه کاری هستید:
gcloud auth login
gcloud auth application-default login
کاربران Cloud Shell میتوانند از این مرحله صرف نظر کنند؛ اعتبارنامهها از قبل پیکربندی شدهاند.
۴. مصنوعات کدلب را دریافت کنید
آزمایشگاه کد فقط به دو مصنوع آماده برای استفاده نیاز دارد: جدول DDL (جداول نمودار فیزیکی) و طرحواره نمودار ویژگی ( CREATE PROPERTY GRAPH ). شما خودتان هیچکدام را نمینویسید؛ آزمایشگاه کد از آنها به همین صورت استفاده میکند و فایل README موجود در پوشه مصنوعات نحوه تطبیق آنها را برای دامنه تصمیمگیری خود توضیح میدهد.
طرحواره property-graph تنها منبع حقیقت برای محتوای گراف است. شما یک بار آن را در BigQuery اعمال میکنید؛ از آن به بعد ، خود گراف مستقر شده، قرارداد است . وقتی شما materialize میکنید، bqaa context-graph تعریف گراف را از INFORMATION_SCHEMA.PROPERTY_GRAPHS بیگکوئری (همراه با طرحوارههای جداولی که به آنها ارجاع میدهد) میخواند تا مشخص کند کدام موجودیتها و روابط را استخراج کند و آنها را کجا بنویسد - بنابراین هیچ فایل SQL هرگز به materializer منتقل نمیشود.
این codelab مستقل است، بنابراین چیزی برای دانلود وجود ندارد. دستور زیر DDL مربوط به گراف زمینه را در یک دایرکتوری کاری مینویسد. محتویات آن با مصنوعات ارسال شده در examples/context_graph/codelab/ یکسان است.
دایرکتوری کاری را ایجاد کنید:
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
DDL مربوط به گراف زمینه ( context_graph_ddl.sql ) را بنویسید. نشانگرهای ${PROJECT_ID} / ${DATASET} هنگام اعمال فایل در مرحله بعدی پر میشوند.
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
تأیید کنید که فایل در جای خود قرار دارد:
ls
شما باید یک فایل را ببینید:
context_graph_ddl.sql
جریان تصمیمگیری که آنها توصیف میکنند دارای سه نوع گره و دو لبه ناهمگن است:
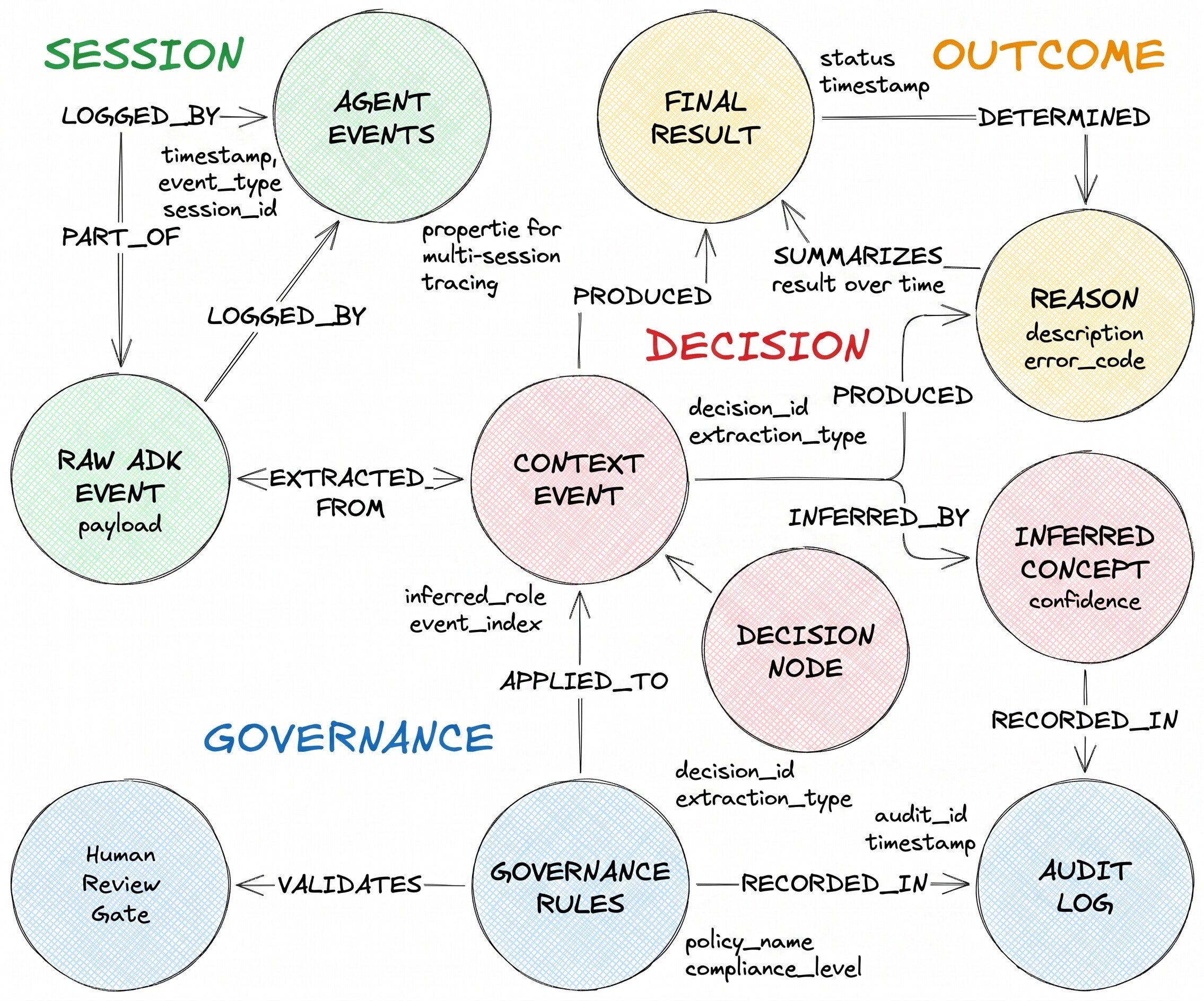
DecisionRequest سوالی است که عامل دریافت کرده است. DecisionOption یکی از گزینههایی است که عامل در نظر گرفته است. DecisionOutcome انتخاب قطعی و منطق آن را ثبت میکند.
۵. طرحواره نمودار ویژگی را اعمال کنید
bqaa context-graph در جداول BigQuery مینویسد، بنابراین آنها باید قبل از اولین اجرا وجود داشته باشند. context_graph_ddl.sql ابتدا پنج جدول و سپس نمودار ویژگی که به آنها ارجاع میدهد را ایجاد میکند (BigQuery نمودار CREATE PROPERTY GRAPH را که به جداولی اشاره میکند که هنوز وجود ندارند، رد میکند)، بنابراین یک apply همه چیز را تنظیم میکند:
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
شما باید پنج نتیجهی CREATE TABLE و یک نتیجهی CREATE PROPERTY GRAPH ببینید. DDL خود-توان است؛ میتوانید با خیال راحت آن را دوباره اجرا کنید.
این تنها کار شما روی طرحواره است که انجام میدهید - و تنها زمانی است که از این فایلهای SQL استفاده میشود. BigQuery اکنون تعریف گراف شما را ثبت میکند و bqaa context-graph آن را از INFORMATION_SCHEMA.PROPERTY_GRAPHS بر اساس نام میخواند. هیچ فایل جداگانهای برای ارسال به materializer وجود ندارد و آنچه شما با GQL پرسوجو میکنید و آنچه materialize میشود هرگز نمیتوانند از هم جدا شوند: آنها همان گراف پیادهسازی شده هستند.
۶. ایجاد رویدادهای نمونه برای عاملها
در محیط عملیاتی، افزونه BigQuery Agent Analytics رویدادها را به طور خودکار همزمان با اجرای ADK agent شما ثبت میکند. این قطعه کد فقط برای مرجع است - شما آن را در این codelab اجرا نمیکنید:
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
برای این کدلب، شما از یک مولد رویداد مصنوعی کوچک استفاده میکنید که شکل یکسانی از ردیفها را مستقیماً در agent_events مینویسد. آن را اجرا کنید:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
این دستور یک گزارش JSON چاپ میکند. برای ۵ جلسه باید "events_generated": 30 ، "events_inserted": 30 و "ok": true ببینید.
پیشنمایش مجموعه دادهها - تعداد جلسات، تعداد رویدادها و محدوده زمانی آنها - در یک ردیف:
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
برای اجرای پیشفرض ۵ جلسهای، این ۵ جلسه و ۳۰ رویداد را در عرض چند دقیقه نشان میدهد. (سناریوی واقعبینانه زیر را در نظر بگیرید و همان پرسوجو حدود ۱۰۰ جلسه را در طول تقریباً سه روز گزارش میدهد.)
تأیید کنید که رویدادها به وقوع پیوستهاند:
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
شما باید ۲۵ ردیف TOOL_COMPLETED و ۵ ردیف AGENT_COMPLETED را ببینید (هر جلسه یک submit_request ، سه evaluate_option ، یک commit_outcome و یک closing AGENT_COMPLETED منتشر میکند - پنج رویداد ابزار به علاوه یک خاتمهدهنده عامل در هر جلسه). ردیفهای AGENT_COMPLETED خاتمهدهندههای جلسه هستند که bqaa context-graph برای تشخیص رویداد ترمینال روی آنها کلید میکند.
اختیاری: دادههای واقعبینانه
مجموعه دادههای ۵ جلسهای بالا عمداً کوچک طراحی شده است، بنابراین اولین اجرا سریع و ارزان است. وقتی میخواهید دادههایی با شکل تولید داشته باشید - چندین عامل و کاربر که در طول چند روز پخش شدهاند، با جلسات ناموفق، یتیم و کوتاهشده - از سناریوی decision-realistic استفاده کنید. این سناریو به طور پیشفرض ۱۰۰ جلسه در یک بازه ۷۲ ساعته است؛ مسیر اولین اجرای بالا بدون تغییر باقی میماند.
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
گزارش JSON مربوط به session_outcome_counts این ترکیب را نشان میدهد - تقریباً {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10} .
توزیع نتیجه را با طبقهبندی هر جلسه از ردیفهای آن تأیید کنید (orphaned = no AGENT_COMPLETED ; failed = AGENT_COMPLETED with status = 'error' ; truncated = any row with is_truncated = true ; در غیر این صورت success). اولین گذر، هر جلسه را طبقهبندی میکند، سپس دومین گذر، هر نتیجه را تجمیع میکند:
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
شما باید تقریباً ۷۰ مورد موفقیتآمیز، ۱۰ مورد شکستخورده، ۱۰ مورد یتیمشده و ۱۰ مورد ناقصشده (بهعلاوه ۵ جلسه موفق از مجموعه دادههای اولیه اگر قبلاً آن را در همان مجموعه داده قرار داده باشید) را ببینید.
۱۰ جلسهی یتیمشده هرگز AGENT_COMPLETED منتشر نکردند، بنابراین اجرای پیشفرض bqaa context-graph از آنها صرفنظر میکند (فقط جلسات بستهشده در ترمینال را اجرا میکند). برای اینکه آنها را به عنوان session_orphaned نمایش دهید، به جای اینکه بیصدا برای همیشه دوباره تلاش کنید، هنگام اجرای آن --max-session-age-hours را اضافه کنید - به --max-session-age-hours در Take it to production مراجعه کنید .
۷. نمودار زمینه را مادیسازی کنید
bqaa context-graph داده خام agent_events را میخواند، سپس آنچه را که باید مستقیماً از گراف مستقر شده شما استخراج شود، استخراج میکند : تعریف CREATE PROPERTY GRAPH را که در Apply the property graph schema اعمال کردهاید، از INFORMATION_SCHEMA.PROPERTY_GRAPHS در BigQuery میخواند، آن را با طرحوارههای جداولی که به آنها ارجاع میدهد، ترکیب میکند، موجودیتها، روابط و انواع ستونها را محاسبه میکند و جداول گراف را پر میکند. شما آن را با نام گراف مستقر شده با --graph agent_decisions_graph نشان میدهید - هیچ فایل SQL برای ارسال وجود ندارد.
اجرا کنید
bqaa context-graph به صورت محلی:
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
شما باید یک گزارش ساختار یافته JSON را ببینید:
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true نشان میدهد که bqaa context-graph پنج جلسه تکمیلشده را پیدا کرده، جریان تصمیمگیری را از هر کدام از طریق AI.GENERATE استخراج کرده و ردیفهای مربوطه را در جداول نمودار نوشته است. استخراج قطعی ( --extraction-mode=compiled-only ، که در زیر توضیح داده شده است) همان شکل گزارش را برمیگرداند - همان فیلدها، همان ok: true - فقط فراخوانیهای AI.GENERATE را رد میکند.
عیب یابی: استخراج خالی
اگر خطای ok: false به همراه error_code = "empty_extraction" مشاهده کردید، شایعترین علت این است که API مربوط به aiplatform.googleapis.com هنوز منتشر نشده است، یا حساب شما roles/aiplatform.user را ندارد. یک دقیقه صبر کنید و دوباره امتحان کنید، یا نقش را اعطا کنید:
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
سپس دستور bqaa context-graph بالا را دوباره اجرا کنید.
تأیید کنید که نمودار دارای سطر است:
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
شما باید پنج ردیف ببینید. در طول پنج جلسه، در مجموع ۲۵ گره گراف وجود دارد - ۵ تا DecisionRequest ، ۱۵ تا DecisionOption و ۵ تا DecisionOutcome - که توسط ۱۵ یال evaluatesOption و ۵ یال resultedIn به هم متصل شدهاند (یک شبکه تصمیمگیری در هر جلسه).
دو روش برای استخراج تصمیمات از رویدادها
bqaa context-graph دو مسیر استخراج ارائه میدهد. مسیری را انتخاب کنید که با حجم کاری شما مطابقت داشته باشد:
- استخراج پیشفرض. سادهترین مسیر. از
AI.GENERATEدر BigQuery برای خواندن محتوای رویداد و استنباط موجودیتها و روابط استفاده میکند. بدون هیچ کد اضافی، روی هر شکل رویدادی کار میکند. این همان چیزی است که codelab از آن استفاده میکند. - استخراج قطعی (
--extraction-mode=compiled-only). مسیر کمهزینهتر و مناسب برای حسابرسی. از یک استخراجکننده مرجع کوچک پایتون که یک بار برای دامنه خود مینویسید استفاده میکند. بدون فراخوانی هوش مصنوعی Vertex، بدون هزینه به ازای هر توکن، خروجی کاملاً قابل تکرار. استقرارهای تولیدی زمانی این را انتخاب میکنند که پیشبینی هزینه یا تکرارپذیری دقیق اهمیت داشته باشد.
راهنمای استقرار گراف زمینه، مرجع هر دو مسیر، شامل جزئیات IAM و نحوهی ایجاد یک استخراجکنندهی مرجع است.
۸. ردیابی تصمیم را پرس و جو کنید
با پر کردن نمودار، میتوانید مستقیماً به سوال حسابرسی پاسخ دهید. یک سوال مشخص را در نظر بگیرید: «برای هر درخواست، عامل چه گزینههایی را ارزیابی کرد و چگونه آن را حل کرد؟» در GQL، این یک پیمایش واحد در سراسر درخواست، گزینههای آن و نتیجه آن است.
کوئری را در یک فایل ( traversal.sql ) بنویسید. علامت ${DATASET} هنگام اجرای آن در مرحله بعدی پر میشود:
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
اجراش کن:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
شما باید پانزده ردیف ببینید: سه گزینه برای هر درخواست، پنج درخواست. هر ردیف درخواست، گزینهای که عامل در نظر گرفته، امتیاز اطمینان آن، نتیجه نهایی و منطق آن را نشان میدهد.
برای دریافت تصویر کامل یک تصمیم، بر اساس request_id فیلتر کنید تا مجموعه ردیفهای مورد نیاز تیم حسابرسی را دریافت کنید: سوالی که مطرح شده، گزینههایی که وزندهی شدهاند (با امتیاز) و منطقی که اتخاذ شده است.
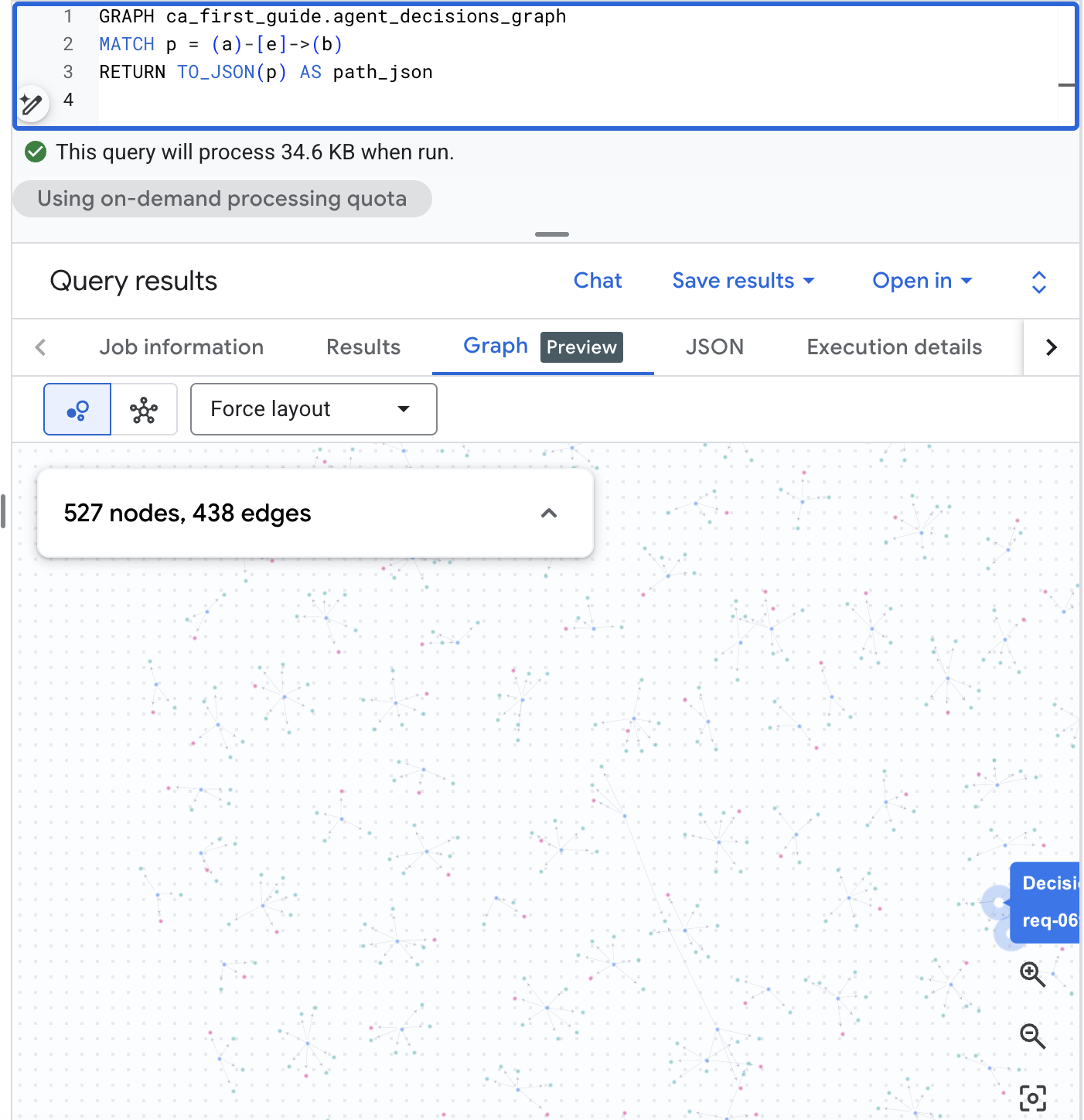
نمودار را در BigQuery Studio تجسم کنید
BigQuery Studio همچنین میتواند نمودار را به صورت بصری نمایش دهد. BigQuery Studio را در کنسول BigQuery باز کنید، کوئری مسیر زیر را اجرا کنید، سپس پنجره نتایج را به تب Graph تغییر دهید تا شبکه تصمیمگیری را ببینید. با استفاده از پیکرهبندی واقعگرایانه، این به شما یک نقشه بصری از درخواستها، گزینهها و نتایج میدهد:
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
همین سوال را به انگلیسی ساده بپرسید
هر خواننده حسابرسی، GQL نمینویسد. با BigQuery Conversational Analytics (Preview)، تیم انطباق شما میتواند همان نوع سؤال را به زبان طبیعی بپرسد و یک کارت پاسخ ساختاریافته دریافت کند - بدون نحو پرسوجو، بدون نیاز به یادگیری پیوندها.
گراف agent_decisions_graph (همراه با جداول agent_events و decision) را به عنوان منبع داده Conversational Analytics ثبت کنید، سپس مستقیماً سوال حسابرسی را بپرسید:
سوال حسابرسی (به زبان ساده): «کدام درخواستها هرگز به نتیجه قطعی نرسیدند؟»
تحلیل مکالمهای روی نمودار استدلال میکند، SQL را برای شما مینویسد و به زبان ساده با یک جدول پشتیبان پاسخ میدهد - در اینجا، هر درخواست ثبتشده به یک نتیجهی قطعی رسیده است:
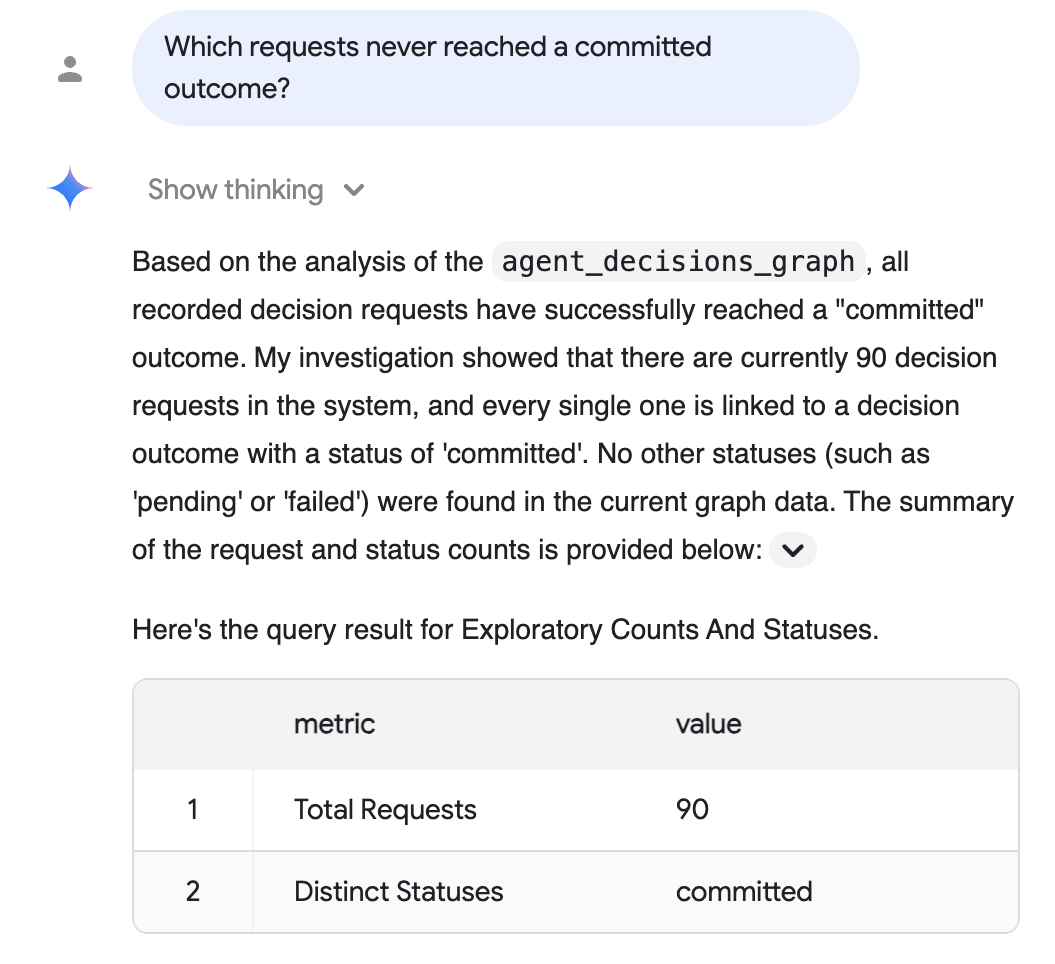
پاسخ بالا، مجموعه دادههای در مقیاس واقعگرایانه را از مرحله اختیاری دادههای در مقیاس واقعگرایانه (۹۰ درخواست محققشده، همگی ثبتشده) منعکس میکند؛ تعداد دقیق شما به مجموعه دادههایی که بارگذاری کردهاید بستگی دارد و اجرای پیشفرض ۵ جلسهای، عدد پنج را نشان میدهد.
برای تنظیمات به مستندات Conversational Analytics مراجعه کنید.
۹. آن را به مرحله تولید برسانید
اجرای محلی فوق از رفتار پیشفرض استفاده میکند که اصول اولیه استقرارهای واقعی را پوشش میدهد: هر اجرا یک رد حسابرسی (ثبت ابری ساختاریافته به علاوه یک ردیف برای هر اجرا در جدول وضعیت در مجموعه دادههای شما) به جا میگذارد، خطاهای گذرا به طور خودکار دوباره امتحان میشوند و پیشرفت فقط در جلسات کاملاً موفق پیش میرود، بنابراین شمارش مضاعف وجود ندارد.
کنترلهای تولید - استخراج قطعی ( --extraction-mode=compiled-only )، تشخیص گیر کردن session ( --max-session-age-hours )، بازپخش یکباره یک پنجره گذشته ( --backfill --from / --to ، که بهطور جداگانه از بهروزرسانی معمولی ردیابی میشود تا نتواند برنامه زنده را مختل کند) و محدود کردن دستهای در هر اجرا ( --max-sessions ) - پرچمهای انتخابی هستند که در صورت نیاز به آنها مراجعه میکنید. راهنمای استقرار گراف زمینه ، هر یک از آنها را با ماتریس کامل IAM و برنامههای پیشنهادی مستند میکند.
۱۰. تمیز کردن
آنچه را که ایجاد کردهاید، از هم بپاشانید تا برای یک مجموعه داده بلااستفاده هزینه دریافت نکنید:
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
آن دستور واحد، مجموعه دادهها، رویدادهای عامل، جداول نمودار و جدول حالت را با هم حذف میکند.
۱۱. تبریک
تبریک! شما لاگهای خام رویداد عامل را به یک گراف زمینه عامل قابل پرسوجو تبدیل کردهاید و یک تصمیم واحد را از ابتدا تا انتها، بدون هیچ پایگاه داده گراف خارجی یا خط لوله ETL، ردیابی کردهاید.
همین الگو در هر جایی که یک عامل تصمیمات مهمی میگیرد، اعمال میشود: پذیرهنویسی اعتبار، مجوز قبلی، جابجایی بودجه بازاریابی، تدارکات، خدمات مشتری و فناوری اطلاعات داخلی. برای ساخت گراف زمینه عامل خود، مصنوعات codelab را به عنوان نقطه شروع کپی کنید، دو فایل اعلانی (جدول DDL + طرحواره CREATE PROPERTY GRAPH ) را با دامنه خود تطبیق دهید و آنها را در BigQuery اعمال کنید - bqaa context-graph --graph گراف مستقر شده را از INFORMATION_SCHEMA میخواند و بقیه را استخراج میکند.
آنچه آموختهاید
- چگونه یک مجموعه داده BigQuery ایجاد کنیم و یک طرحواره نمودار ویژگی را که دامنه تصمیم عامل را توصیف میکند، اعمال کنیم.
- چگونه
agent_eventsبا یک مجموعه رویداد مصنوعی پر کنیم. - چگونه میتوان
bqaa context-graphاجرا کرد تا ردپاهای تصمیمگیری عامل را از آن رویدادها در یک Agent Context Graph استخراج کند و تعریف نمودار را ازINFORMATION_SCHEMAبخواند. - چگونه نمودار حاصل را در GQL جستجو کنیم و پاسخ به سبک حسابرسی را بخوانیم.
اسناد مرجع
- مخزن SDK مربوط به BigQuery Agent Analytics
- راهنمای مصنوعات و سازگاری Codelab
- راهنمای استقرار گراف زمینه : API های مورد نیاز، ماتریس IAM، برنامههای پیشنهادی، کوئریهای هشدار مانیتورینگ ابری و ماژول Terraform.
- مستندات BigQuery Graph (پیشنمایش).
- مستندات BigQuery Conversational Analytics (پیشنمایش).