
1. Introduction
BigQuery Graph, BigQuery Conversational Analytics et le SDK BigQuery Agent Analytics sont actuellement disponibles en version preview sur Google Cloud. Le plug-in BigQuery Agent Analytics est en disponibilité générale. Les exemples de cet atelier de programmation utilisent des données synthétiques.
À mesure que les agents d'IA autonomes assument davantage de responsabilités opérationnelles (évaluation des demandes de prêt, gestion des budgets marketing, approbation des demandes d'accès), les organisations doivent être en mesure d'auditer et d'expliquer leurs décisions. La reconstitution du contexte exact, des alternatives envisagées et de la justification finale de la décision d'un agent est essentielle pour la conformité, la gestion des risques et la confiance opérationnelle.
Cet atelier de programmation utilise le SDK BigQuery Agent Analytics pour transformer les journaux d'événements bruts des agents en un graphe de contexte d'agent (un graphe interrogeable dans BigQuery Graph des décisions d'agent) selon une planification, sans base de données de graphes externe ni pipeline ETL.
Termes clés
- Trace de décision d'agent : preuve au niveau de la décision extraite des propres exécutions d'un agent : les options qu'il a pesées, les données qu'il a traitées et le résultat qu'il a validé.
- Graphe de contexte d'agent : graphe typé et interrogeable dans BigQuery Graph dans lequel ces traces sont matérialisées. Il s'agit de l'instance à portée d'agent du concept de graphe de contexte du secteur (la couche durable et liée au temps du contexte de décision que les agents produisent et consomment) ; le qualificatif "Agent" le limite aux exécutions de vos propres agents plutôt qu'à une couche de contexte à l'échelle de l'entreprise.
Dans cet atelier de programmation, bqaa context-graph extrait les traces de décision de l'agent de votre agent_events et les matérialise dans un graphe de contexte d'agent que vous pouvez interroger avec GQL, en suivant le modèle du secteur où les graphes de contexte sont créés à partir de traces de décision.
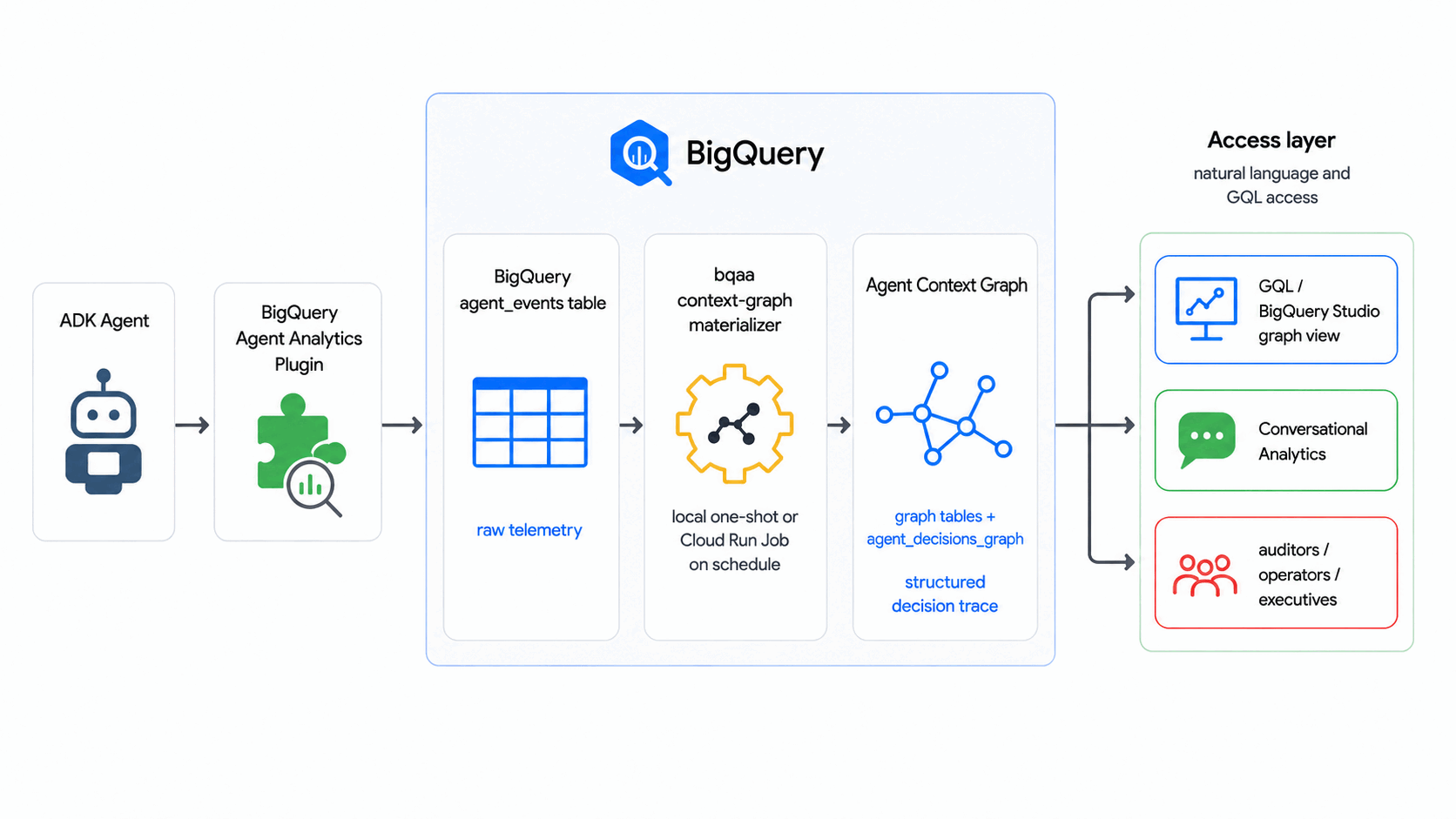
Objectifs de l'atelier
- Un graphe de contexte d'agent (avec BigQuery Graph) qui modélise un flux de décision d'agent générique : une requête arrive, l'agent pèse les options et un résultat est validé.
- Une table
agent_eventsremplie avec un corpus d'événements synthétiques. - Une exécution
bqaa context-graphfonctionnelle qui remplit le graphe à partir de ces événements. - Une requête GQL de type audit qui suit une seule décision de bout en bout.
Points abordés
- Comment le plug-in BigQuery Agent Analytics écrit dans
agent_events. - Comment un graphe de contexte est défini par seulement deux artefacts déclaratifs : un LDD de table et un schéma
CREATE PROPERTY GRAPH. - Comment exécuter
bqaa context-graphsur un graphe BigQuery. - Comment interroger un graphe à l'aide de GQL.
- Les fonctionnalités de qualité production que le SDK prend en charge pour les déploiements d'entreprise.
Ce dont vous avez besoin
- Un projet Google Cloud avec facturation activée.
- Rôle de propriétaire ou d'éditeur sur ce projet. Vous allez créer un ensemble de données BigQuery et accorder IAM.
- La CLI
gcloudinstallée et authentifiée, ou l'accès à Cloud Shell. - Python 3.10 ou version ultérieure.
- Connaissance de BigQuery SQL. La connaissance de GQL n'est pas requise.
Cet atelier de programmation s'adresse aux développeurs de tous niveaux, y compris à ceux qui débutent avec BigQuery Graph.
Les ressources créées dans cet atelier de programmation coûtent très peu cher, et la dernière étape supprime tout afin que vous ne soyez pas facturé pour un ensemble de données inactif.
Durée estimée : cet atelier de programmation prend environ 35 minutes.
2. Avant de commencer
Sélectionner un projet et une région
Ouvrez Cloud Shell ou un terminal local :
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
La variable unique DATASET contient à la fois la table agent_events brute et les tables de graphes matérialisées. L'utilisation d'un seul ensemble de données simplifie l'atelier de programmation. Les déploiements en production divisent souvent les événements et les graphes en ensembles de données distincts afin que IAM puisse être accordé de manière limitée par ensemble de données.
Activer les API requises
Exécutez la commande suivante pour activer les API utilisées par cet atelier de programmation :
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
L'API aiplatform.googleapis.com est requise, car le chemin d'extraction par défaut du SDK appelle la fonction AI.GENERATE de BigQuery. Si vous passez ultérieurement à l'extraction déterministe avec --extraction-mode=compiled-only, cette API n'est plus nécessaire.
Créer l'ensemble de données BigQuery
Créez l'ensemble de données qui contiendra à la fois la table agent_events brute et les tables de graphes matérialisées :
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
Un message confirmant le succès de l'opération devrait s'afficher :
Dataset 'your-project-id:agent_analytics_demo' successfully created.
Si l'ensemble de données existe déjà, la commande génère une erreur sans conséquence. Laissez-le en place.
3. Installer le SDK
Configurez un environnement virtuel Python et installez le SDK à partir de PyPI :
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
Le package bigquery-agent-analytics extrait la bibliothèque cliente BigQuery. Il s'agit donc de la seule installation dont vous avez besoin pour l'ensemble de l'atelier de programmation.
Vérifiez l'installation :
bqaa context-graph --help | head -8
La bannière de la CLI doit s'afficher.
Authentifier
Si vous utilisez un poste de travail :
gcloud auth login
gcloud auth application-default login
Les utilisateurs de Cloud Shell peuvent ignorer cette étape, car les identifiants sont déjà configurés.
4. Obtenir les artefacts de l'atelier de programmation
L'atelier de programmation n'a besoin que de deux artefacts prêts à l'emploi : le LDD de table (les tables de graphes physiques) et le schéma de graphe de propriété (CREATE PROPERTY GRAPH). Vous n'en créez aucun vous-même. L'atelier de programmation les utilise tels quels, et le fichier README du dossier d'artefacts explique comment les adapter à votre propre domaine de décision.
Le schéma de graphe de propriété est la seule source d'informations fiable sur ce que contient le graphe. Vous l'appliquez à BigQuery une seule fois. À partir de ce moment, le graphe déployé lui-même est le contrat. Lorsque vous matérialisez, bqaa context-graph relit la définition du graphe à partir de INFORMATION_SCHEMA.PROPERTY_GRAPHS de BigQuery (ainsi que les schémas des tables auxquelles il fait référence) pour déterminer les entités et les relations à extraire et où les écrire. Aucun fichier SQL n'est donc jamais transmis au matérialiseur.
Cet atelier de programmation est autonome. Vous n'avez donc rien à télécharger. La commande ci-dessous écrit le LDD du graphe de contexte dans un répertoire de travail. Son contenu est identique aux artefacts fournis dans examples/context_graph/codelab/.
Créez le répertoire de travail :
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
Écrivez le LDD du graphe de contexte (context_graph_ddl.sql). Les marqueurs ${PROJECT_ID} / ${DATASET} sont renseignés lorsque vous appliquez le fichier à l'étape suivante.
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
Vérifiez que le fichier est en place :
ls
Un fichier doit s'afficher :
context_graph_ddl.sql
Le flux de décision qu'ils décrivent comporte trois types de nœuds et deux arêtes hétérogènes :
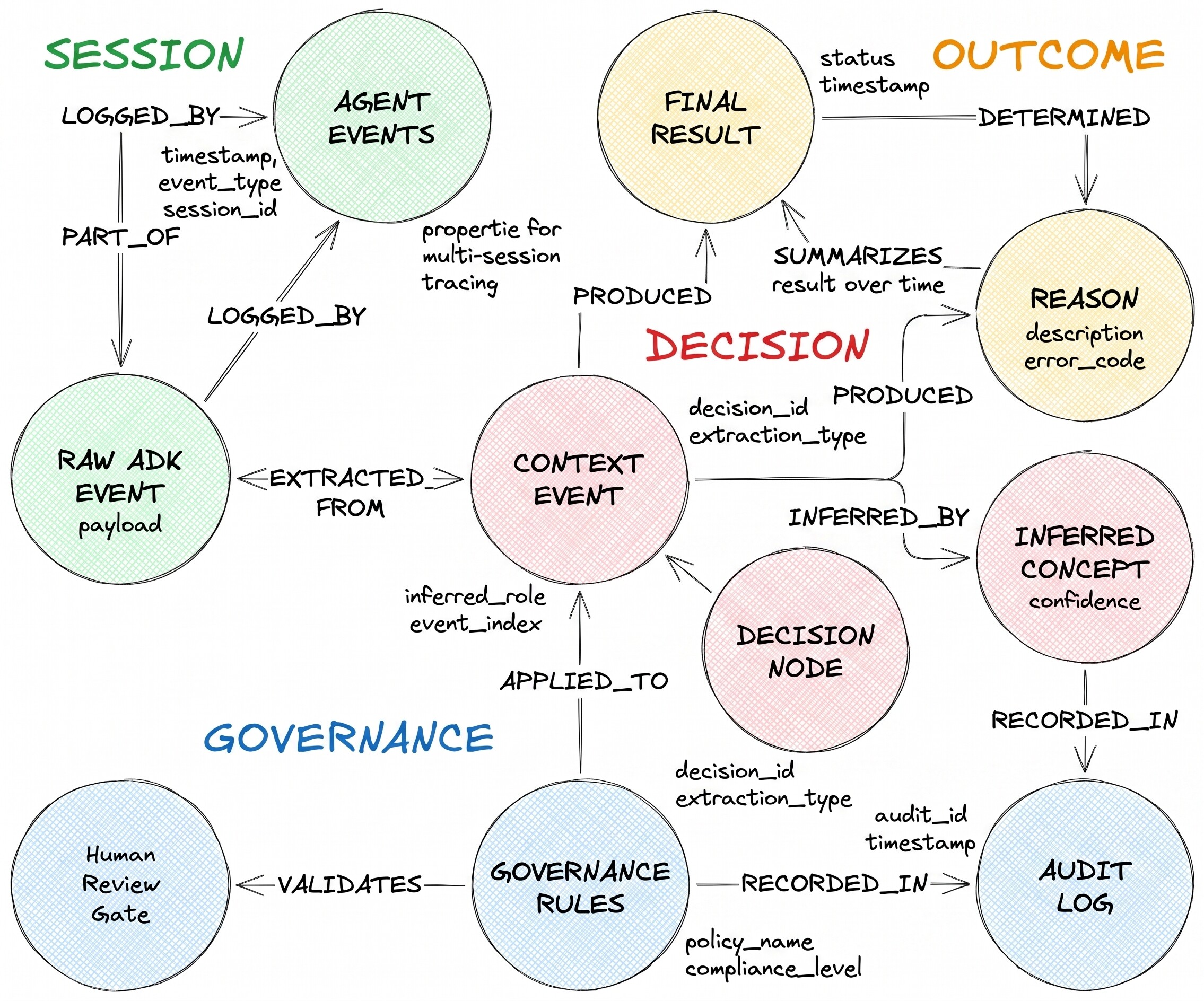
DecisionRequest est la question que l'agent a reçue. DecisionOption est une alternative que l'agent a envisagée. DecisionOutcome enregistre le choix validé et la justification.
5. Appliquer le schéma de graphe de propriété
bqaa context-graph écrit dans les tables BigQuery. Elles doivent donc exister avant la première exécution. context_graph_ddl.sql crée d'abord les cinq tables, puis le graphe de propriété qui les référence (BigQuery rejette un CREATE PROPERTY GRAPH qui pointe vers des tables qui n'existent pas encore). Une seule application configure donc tout :
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
Cinq résultats CREATE TABLE et un résultat CREATE PROPERTY GRAPH doivent s'afficher. Le LDD est idempotent. Vous pouvez le réexécuter en toute sécurité.
Il s'agit du seul travail de schéma que vous effectuez et de la seule fois où ces fichiers SQL sont utilisés. BigQuery enregistre désormais la définition de votre graphe, et bqaa context-graph la relit à partir de INFORMATION_SCHEMA.PROPERTY_GRAPHS par nom. Aucun fichier distinct n'est transmis au matérialiseur, et ce que vous interrogez avec GQL et ce qui est matérialisé ne peuvent jamais diverger : il s'agit du même graphe déployé.
6. Générer des exemples d'événements d'agent
En production, le plug-in BigQuery Agent Analytics capture automatiquement les événements lors de l'exécution de votre agent ADK. Cet extrait est fourni à titre de référence uniquement. Vous ne l'exécutez pas dans cet atelier de programmation :
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
Pour cet atelier de programmation, vous utilisez un petit générateur d'événements synthétiques qui écrit la même forme de lignes directement dans agent_events. Exécutez l'agent :
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
La commande affiche un rapport JSON. Pour cinq sessions, vous devriez voir "events_generated": 30, "events_inserted": 30 et "ok": true.
Aperçu du corpus en un coup d'œil : nombre de sessions, nombre d'événements et plage de temps qu'ils couvrent, sur une seule ligne :
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
Pour l'exécution par défaut de cinq sessions, cela affiche cinq sessions et 30 événements couvrant quelques minutes. (Amorcez le scénario réaliste ci-dessous et la même requête signale environ 100 sessions sur environ trois jours.)
Vérifiez que les événements ont été enregistrés :
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
Vous devriez voir 25 lignes TOOL_COMPLETED et 5 lignes AGENT_COMPLETED (chaque session émet un submit_request, trois evaluate_option, un commit_outcome et un AGENT_COMPLETED de fermeture : cinq événements d'outil plus un terminateur d'agent par session). Les lignes AGENT_COMPLETED sont les terminateurs de session sur lesquels bqaa context-graph s'appuie pour la détection des événements terminaux.
Facultatif : données à l'échelle réaliste
Le corpus de cinq sessions ci-dessus est intentionnellement minuscule afin que la première exécution soit rapide et peu coûteuse. Lorsque vous souhaitez des données de forme production (plusieurs agents et utilisateurs répartis sur plusieurs jours, avec des sessions ayant échoué, orphelines et tronquées), utilisez le scénario decision-realistic. Il est défini par défaut sur 100 sessions sur une période de 72 heures. Le chemin de la première exécution ci-dessus reste inchangé.
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
session_outcome_counts du rapport JSON affiche le mélange : environ {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10}.
Confirmez la distribution des résultats en classifiant chaque session à partir de ses lignes (orpheline = pas de AGENT_COMPLETED ; échec = AGENT_COMPLETED avec status = 'error' ; tronquée = n'importe quelle ligne avec is_truncated = true ; sinon, succès). Une première passe classe chaque session, puis une seconde agrège par résultat :
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
Vous devriez voir environ 70 succès, 10 échecs, 10 orphelins et 10 tronqués (plus les cinq sessions réussies du corpus de la première exécution si vous l'avez amorcé plus tôt dans le même ensemble de données).
Les 10 sessions orphelines n'ont jamais émis AGENT_COMPLETED. L'exécution bqaa context-graph par défaut les ignore donc (elle ne matérialise que les sessions fermées par un événement terminal). Pour les afficher en tant que session_orphaned au lieu de réessayer silencieusement pour toujours, ajoutez --max-session-age-hours lorsque vous l'exécutez. Pour en savoir plus, consultez --max-session-age-hours dans Passer en production.
7. Matérialiser le graphe de contexte
bqaa context-graph lit les agent_events bruts, puis détermine ce qu'il faut extraire directement de votre graphe déployé : il relit la définition CREATE PROPERTY GRAPH que vous avez appliquée dans Appliquer le schéma de graphe de propriété à partir de INFORMATION_SCHEMA.PROPERTY_GRAPHS de BigQuery, la joint aux schémas des tables auxquelles il fait référence, détermine les entités, les relations et les types de colonnes, et remplit les tables de graphes. Vous le pointez vers le graphe déployé par nom avec --graph agent_decisions_graph. Aucun fichier SQL n'est transmis.
Exécuter
bqaa context-graph en local :
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
Un rapport JSON structuré doit s'afficher :
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true indique que bqaa context-graph a trouvé cinq sessions terminées, a extrait le flux de décision de chacune via AI.GENERATE et a écrit les lignes correspondantes dans les tables de graphes. L'extraction déterministe (--extraction-mode=compiled-only, décrite ci-dessous) renvoie la même forme de rapport (mêmes champs, même ok: true) et ignore simplement les appels AI.GENERATE.
Dépannage : extraction vide
Si ok: false s'affiche avec error_code = "empty_extraction", la cause la plus fréquente est que l'API aiplatform.googleapis.com n'a pas encore été propagée ou que votre compte ne dispose pas de roles/aiplatform.user. Patientez une minute et réessayez, ou accordez le rôle :
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
Réexécutez ensuite la commande bqaa context-graph ci-dessus.
Vérifiez que le graphe comporte des lignes :
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
Cinq lignes doivent s'afficher. Sur les cinq sessions, cela représente 25 nœuds de graphes au total : 5 DecisionRequest, 15 DecisionOption et 5 DecisionOutcome, joints par 15 arêtes evaluatesOption et 5 arêtes resultedIn (un réseau de décision par session).
Deux façons d'extraire des décisions à partir d'événements
bqaa context-graph propose deux chemins d'extraction. Choisissez celui qui correspond à votre charge de travail :
- Extraction par défaut. Le chemin le plus simple. Utilise
AI.GENERATEde BigQuery pour lire le contenu des événements et déduire les entités et les relations. Fonctionne avec n'importe quelle forme d'événement sans code supplémentaire. C'est ce qu'utilise l'atelier de programmation. - Extraction déterministe (
--extraction-mode=compiled-only). Le chemin le moins coûteux et adapté à l'audit. Utilise un petit extracteur de référence Python que vous écrivez une seule fois pour votre domaine. Aucun appel Vertex AI, aucun frais par jeton, sortie entièrement reproductible. Les déploiements en production choisissent cette option lorsque la prévisibilité des coûts ou la reproductibilité stricte sont importantes.
Le guide de déploiement du graphe de contexte est la référence pour les deux chemins, y compris les détails IAM et la façon de créer un extracteur de référence.
8. Interroger la trace de décision
Une fois le graphe rempli, vous pouvez répondre directement à la question d'audit. Prenons un exemple concret : "Pour chaque requête, quelles options l'agent a-t-il pesées et comment a-t-il résolu le problème ?" En GQL, il s'agit d'un seul balayage de la requête, de ses options et de son résultat.
Écrivez la requête dans un fichier (traversal.sql). Le marqueur ${DATASET} est renseigné lorsque vous l'exécutez à l'étape suivante :
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
Exécutez l'agent :
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
Quinze lignes doivent s'afficher : trois options par requête, cinq requêtes. Chaque ligne affiche la requête, l'option envisagée par l'agent, son score de confiance, le résultat final et la justification.
Pour obtenir une image complète d'une seule décision, filtrez par request_id pour obtenir l'ensemble de lignes dont une équipe d'audit a besoin : la question posée, les options pesées (avec les scores) et la justification validée.
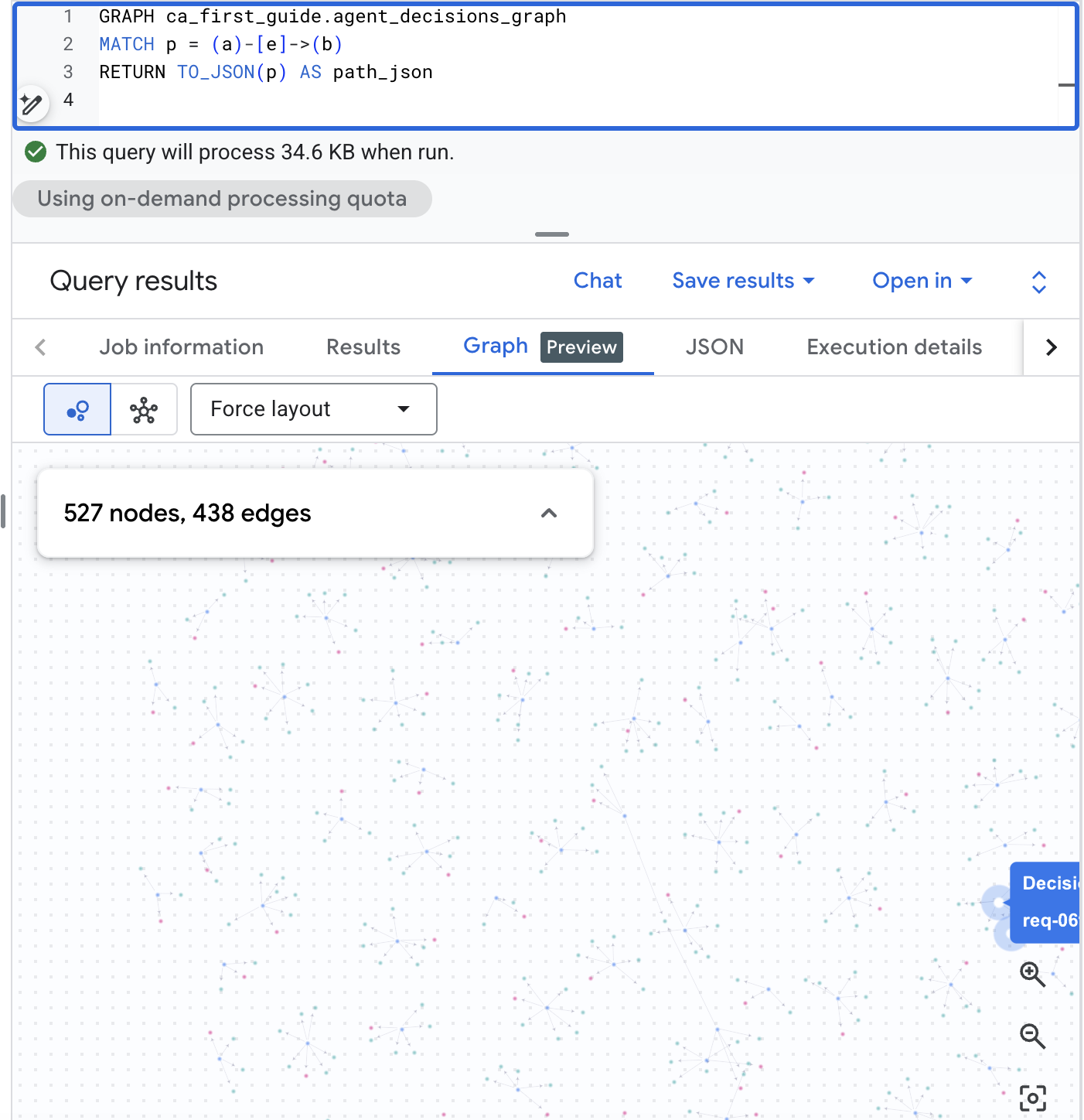
Visualiser le graphe dans BigQuery Studio
BigQuery Studio peut également afficher le graphe visuellement. Ouvrez BigQuery Studio dans la console BigQuery, exécutez la requête de chemin ci-dessous, puis passez le volet de résultats à l'onglet Graphe pour afficher le réseau de décision. Avec le corpus à l'échelle réaliste, vous obtenez une carte visuelle des requêtes, des options et des résultats :
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
Poser la même question en langage naturel
Tous les lecteurs d'audit n'écrivent pas de GQL. Avec BigQuery Conversational Analytics (Preview), votre équipe de conformité peut poser le même type de question en langage naturel et obtenir une fiche de réponse structurée. Aucune syntaxe de requête ni aucune jointure à apprendre.
Enregistrez agent_decisions_graph (ainsi que les tables agent_events et de décision) en tant que source de données Conversational Analytics, puis posez directement la question d'audit :
Question d'audit (langage naturel) "Quelles requêtes n'ont jamais abouti à un résultat validé ?"
Conversational Analytics raisonne sur le graphe, écrit le SQL pour vous et répond en langage naturel avec un tableau d'assistance. Ici, chaque requête enregistrée a abouti à un résultat validé :
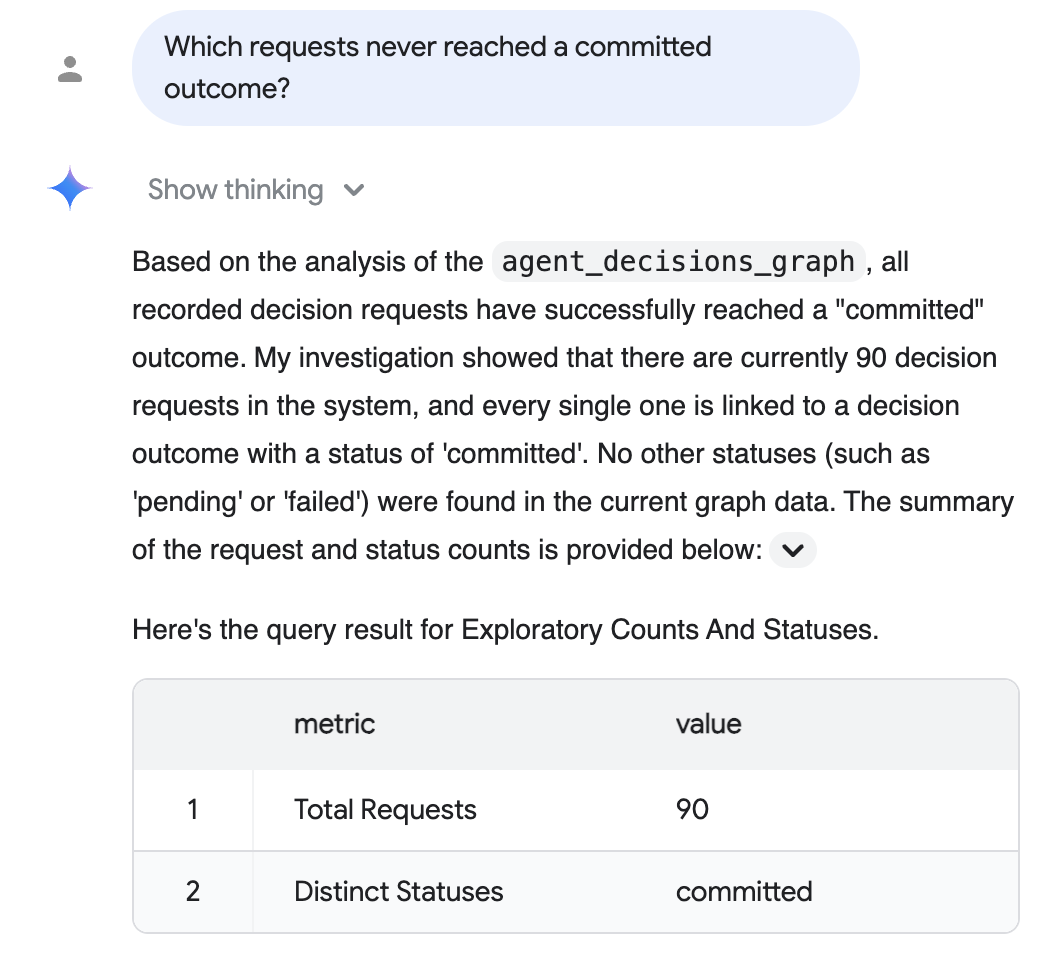
La réponse ci-dessus reflète le corpus à l'échelle réaliste de l'étape facultative Données à l'échelle réaliste (90 requêtes matérialisées, toutes validées). Vos chiffres exacts dépendent du corpus que vous avez amorcé, et l'exécution par défaut de cinq sessions en affiche cinq.
Pour la configuration, consultez la documentation Conversational Analytics.
9. Passer en production
L'exécution locale ci-dessus utilise le comportement par défaut, qui couvre déjà les bases des déploiements réels : chaque exécution laisse une piste d'audit (Cloud Logging structuré plus une ligne par exécution dans une table d'état de votre ensemble de données), les échecs temporaires sont automatiquement réessayés et la progression n'avance que sur les sessions entièrement réussies. Il n'y a donc pas de double comptage.
Les commandes de production (extraction déterministe (--extraction-mode=compiled-only), détection des sessions bloquées (--max-session-age-hours), relecture unique d'une fenêtre passée (--backfill --from / --to, suivie séparément de l'actualisation régulière afin de ne pas perturber la planification en direct) et limitation des lots par exécution (--max-sessions)) sont des indicateurs d'activation que vous utilisez lorsque vous en avez besoin. Le guide de déploiement du graphe de contexte documente chacun d'eux avec la matrice IAM complète et les planifications recommandées.
10. Libérer de l'espace
Supprimez ce que vous avez créé afin de ne pas être facturé pour un ensemble de données inactif :
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
Cette commande unique supprime l'ensemble de données, les événements d'agent, les tables de graphes et la table d'état.
11. Félicitations
Félicitations ! Vous avez transformé les journaux d'événements bruts des agents en un graphe de contexte d'agent interrogeable et suivi une seule décision de bout en bout, sans base de données de graphes externe ni pipeline ETL.
Le même modèle s'applique partout où un agent prend des décisions importantes : souscription de crédit, autorisation préalable, mouvements de budget marketing, approvisionnement, service client et informatique interne. Pour créer votre propre graphe de contexte d'agent, copiez les artefacts de l'atelier de programmation comme point de départ, adaptez les deux fichiers déclaratifs (LDD de table + schéma CREATE PROPERTY GRAPH) à votre domaine et appliquez-les à BigQuery. bqaa context-graph --graph relit le graphe déployé à partir de INFORMATION_SCHEMA et déduit le reste.
Connaissances acquises
- Comment créer un ensemble de données BigQuery et appliquer un schéma de graphe de propriété décrivant un domaine de décision d'agent.
- Comment remplir
agent_eventsavec un corpus d'événements synthétiques. - Comment exécuter
bqaa context-graphpour extraire les traces de décision de l'agent dans un graphe de contexte d'agent à partir de ces événements, en relisant la définition du graphe à partir deINFORMATION_SCHEMA. - Comment interroger le graphe résultant dans GQL et lire la réponse de type audit.
Documents de référence
- Dépôt du SDK BigQuery Agent Analytics
- Artefacts de l'atelier de programmation et guide d'adaptation
- Guide de déploiement du graphe de contexte : API requises, matrice IAM, planifications recommandées, requêtes d'alerte Cloud Monitoring et module Terraform.
- Documentation BigQuery Graph (Preview).
- Documentation BigQuery Conversational Analytics (Preview).