
1. מבוא
BigQuery Graph, BigQuery Conversational Analytics ו-BigQuery Agent Analytics SDK נמצאים כרגע בגרסת Preview ב-Google Cloud. BigQuery Agent Analytics Plugin זמין לכלל המשתמשים (GA). בדוגמאות ב-Codelab הזה נעשה שימוש בנתונים סינתטיים.
ככל שסוכני AI אוטונומיים לוקחים על עצמם יותר אחריות תפעולית (הערכת בקשות להלוואות, ניהול תקציבי שיווק, אישור בקשות גישה), ארגונים צריכים להיות מסוגלים לבדוק ולהסביר את ההחלטות שלהם. שחזור ההקשר המדויק, החלופות שנשקלו וההצדקה הסופית להחלטה של נציג חיוני לצורך תאימות, ניהול סיכונים ואמון תפעולי.
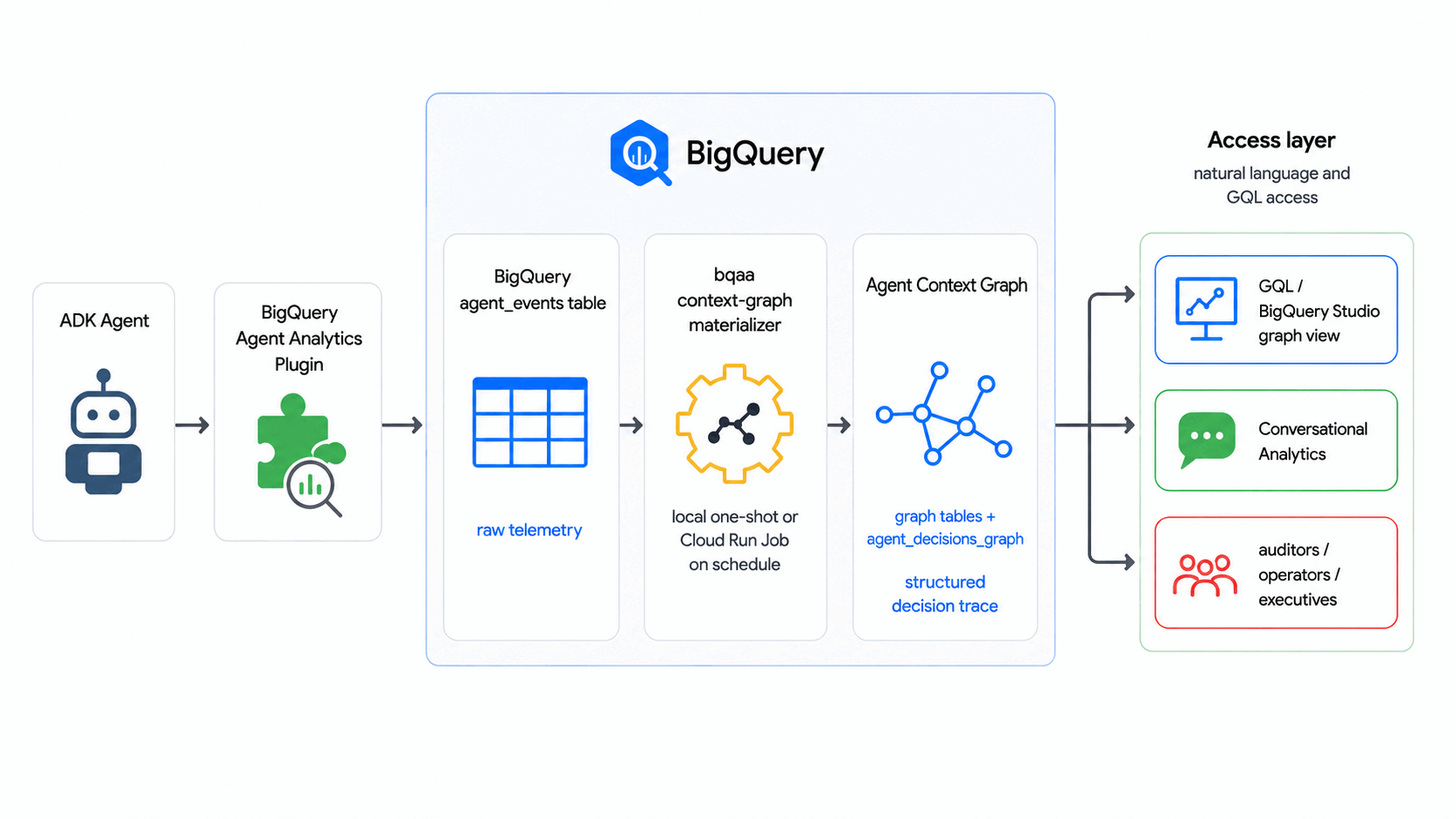
ב-Codelab הזה נעשה שימוש ב-BigQuery Agent Analytics SDK כדי להפוך יומני אירועים גולמיים של סוכנים לגרף הקשר של הסוכן – גרף שאפשר להריץ עליו שאילתות ב-BigQuery Graph של החלטות הסוכן – לפי תזמון, ללא מסד נתונים חיצוני של גרפים או פייפליין ETL.
מונחי מפתח
- מעקב אחר החלטות של סוכן – הוכחות ברמת ההחלטה שנשלפות מההרצות של הסוכן: האפשרויות שנשקלו, הנתונים שהסוכן ניגש אליהם והתוצאה שהתקבלה.
- גרף ההקשר של הסוכן – הגרף המוקלד שניתן להריץ עליו שאילתות ב-BigQuery Graph, שבו מתבצעת המימוש של העקבות האלה. זוהי דוגמה למושג תרשים ההקשר של התעשייה (שכבה עמידה של הקשר להחלטות, שמקושרת לזמן, והסוכנים יוצרים ומשתמשים בה), שמוגדרת בהיקף של סוכן. המילה Agent (סוכן) מציינת שההיקף הוא של ההרצות של הסוכנים שלכם, ולא של שכבת הקשר ברמת הארגון.
ב-codelab הזה, bqaa context-graph מחלץ את עקבות ההחלטות של הסוכן מ-agent_events ומממש אותן בגרף הקשר של הסוכן שאפשר לבצע עליו שאילתות באמצעות GQL – בהתאם לדפוס התעשייתי שבו גרפים של הקשר נוצרים מעקבות של החלטות.
מה תפַתחו
- תרשים הקשר של סוכן (עם BigQuery Graph) שמדמה זרימת החלטות כללית של סוכן: מתקבלת בקשה, הסוכן שוקל אפשרויות ומתחייב לתוצאה.
- טבלה מאוכלסת
agent_eventsעם קורפוס של אירועים סינתטיים. bqaa context-graphהפעלה שמתבצעת וממלאת את הגרף על סמך האירועים האלה.- שאילתת GQL בסגנון ביקורת שעוקבת אחרי החלטה יחידה מקצה לקצה.
מה תלמדו
- איך BigQuery Agent Analytics Plugin כותב ל-
agent_events. - איך גרף הקשר מוגדר על ידי שני ארטיפקטים הצהרתיים בלבד – DDL של טבלה וסכימה של
CREATE PROPERTY GRAPH. - איך מריצים
bqaa context-graphמול גרף BigQuery. - איך שולחים שאילתה לגרף באמצעות GQL.
- היכולות ברמת הייצור שנתמכות על ידי ה-SDK לפריסות ארגוניות.
הדרישות
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- תפקיד של בעלים או עורך בפרויקט. תצטרכו ליצור מערך נתונים ב-BigQuery ולהעניק הרשאות IAM.
- ה-CLI של
gcloudמותקן ומאומת, או שיש גישה ל-Cloud Shell. - Python 3.10 ואילך.
- היכרות עם BigQuery SQL. לא נדרש ידע ב-GQL.
ה-codelab הזה מיועד למפתחים בכל הרמות, כולל כאלה שחדשים ב-BigQuery Graph.
המשאבים שנוצרו ב-Codelab הזה עולים מעט מאוד, ובשלב האחרון הכל נמחק כדי שלא תחויבו על מערך נתונים לא פעיל.
משך משוער: השלמת ה-codelab הזה נמשכת כ-35 דקות.
2. לפני שמתחילים
בחירת פרויקט ואזור
פותחים את Cloud Shell או טרמינל מקומי:
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
המשתנה הבודד DATASET מכיל גם את הטבלה הגולמית agent_events וגם את טבלאות הגרף המגובשות. שימוש במערך נתונים אחד שומר על פשטות ה-codelab. בפריסות של סביבת ייצור, לעיתים קרובות האירועים והגרף מחולקים לקבוצות נתונים נפרדות, כדי שאפשר יהיה להעניק הרשאות IAM באופן מצומצם לכל קבוצת נתונים.
הפעלת ממשקי ה-API הנדרשים
מריצים את הפקודה הבאה כדי להפעיל את ממשקי ה-API שבהם נעשה שימוש ב-codelab הזה:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
נדרש aiplatform.googleapis.com API כי נתיב החילוץ שמוגדר כברירת מחדל ב-SDK קורא לפונקציה AI.GENERATE של BigQuery. אם תעברו בהמשך לחילוץ דטרמיניסטי באמצעות --extraction-mode=compiled-only, לא תצטרכו יותר את ה-API הזה.
יצירת מערך נתונים ב-BigQuery
יוצרים את מערך הנתונים שיכיל גם את הטבלה agent_events של הנתונים הגולמיים וגם את הטבלאות של הגרף הממומש:
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
אמורה להופיע הודעה על סיום הפעולה:
Dataset 'your-project-id:agent_analytics_demo' successfully created.
אם מערך הנתונים כבר קיים, הפקודה תיכשל ללא השפעה. להשאיר אותו במקום.
3. התקנת ה-SDK
מגדירים סביבה וירטואלית של Python ומתקינים את ה-SDK מ-PyPI:
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
חבילת bigquery-agent-analytics כוללת את ספריית הלקוח של BigQuery, ולכן זו ההתקנה היחידה שצריך לבצע לכל ה-codelab.
אימות ההתקנה:
bqaa context-graph --help | head -8
אמור להופיע באנר ה-CLI.
אמת
בתחנת עבודה:
gcloud auth login
gcloud auth application-default login
משתמשי Cloud Shell יכולים לדלג על השלב הזה, כי פרטי הכניסה כבר מוגדרים.
4. הורדת פריטי Codelab
ב-Codelab נשתמש בשני פריטי מידע שנוצרו בתהליך פיתוח (Artifact) מוכנים לשימוש: table DDL (טבלאות הגרף הפיזי) ו-property-graph schema (CREATE PROPERTY GRAPH). אתם לא צריכים ליצור אותם בעצמכם. ב-Codelab נשתמש בהם כמו שהם, וב-קובץ README בתיקיית הארטיפקטים מוסבר איך להתאים אותם לדומיין ההחלטות שלכם.
סכימת גרף הנכסים היא המקור הקובע למה הגרף מכיל. מחילים את ההסכם על BigQuery פעם אחת, ומאותו רגע הגרף שנפרס הוא ההסכם עצמו. כשמבצעים מירכוז, bqaa context-graph קורא את הגדרת הגרף בחזרה מ-INFORMATION_SCHEMA.PROPERTY_GRAPHS של BigQuery (יחד עם הסכימות של הטבלאות שהוא מפנה אליהן) כדי להבין אילו ישויות ויחסים צריך לחלץ ולאן לכתוב אותם – כך שקובץ SQL אף פעם לא מועבר למרכז.
ה-codelab הזה הוא עצמאי, כך שאין צורך להוריד שום דבר. הפקודה שלמטה כותבת את ה-DDL של תרשים ההקשר לספריית עבודה. התוכן שלו זהה לפריטי המידע שנוצרו בתהליך פיתוח (Artifact) שנשלחים ב-examples/context_graph/codelab/.
יוצרים את ספריית העבודה:
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
כותבים את ה-DDL של גרף ההקשר (context_graph_ddl.sql). הסמנים ${PROJECT_ID} / ${DATASET} ימולאו כשמחילים את הקובץ בשלב הבא.
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
לוודא שהקובץ נמצא במקום:
ls
אמור להופיע קובץ אחד:
context_graph_ddl.sql
זרימת ההחלטות שהם מתארים כוללת שלושה סוגי צמתים ושני קצוות הטרוגניים:
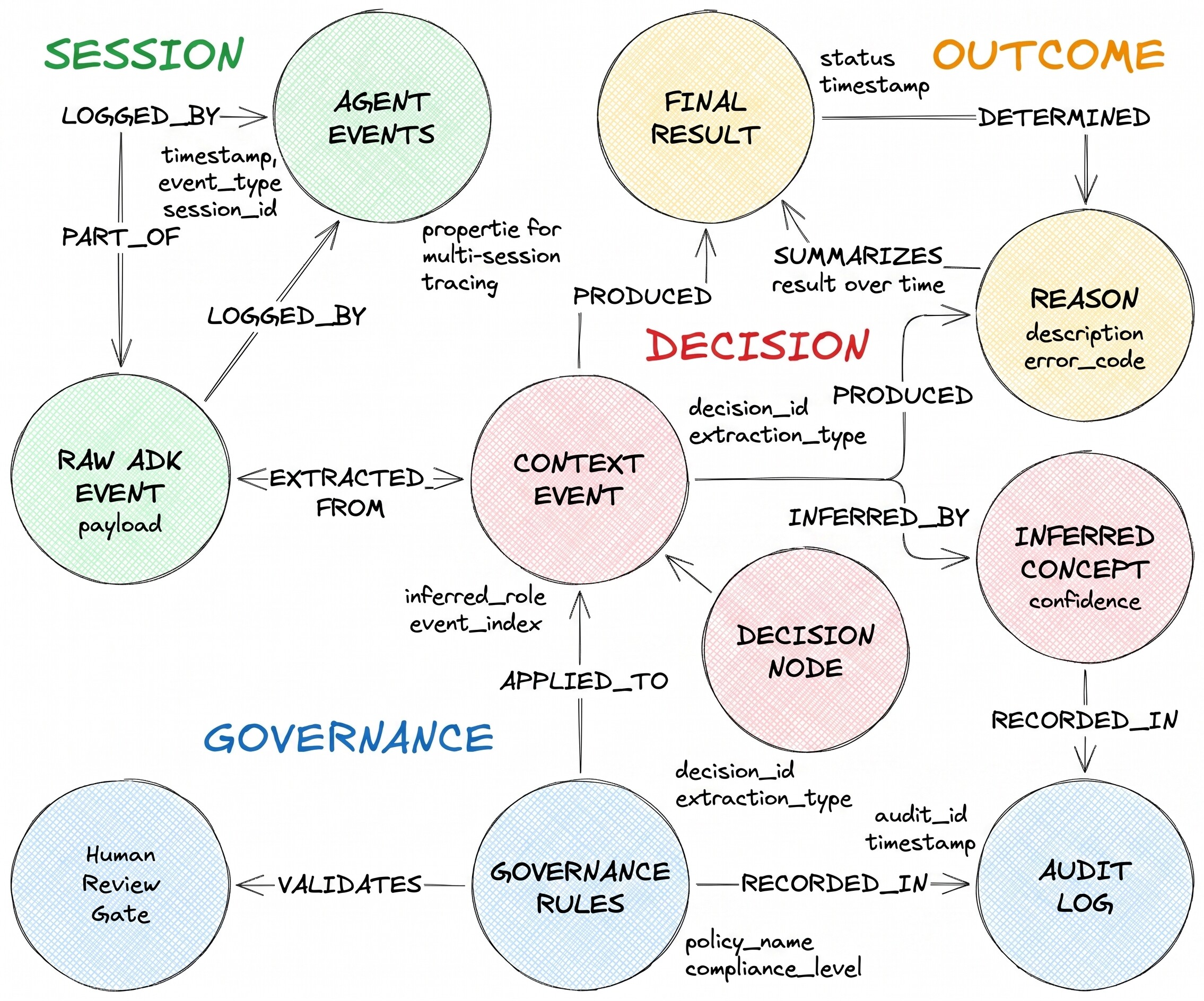
DecisionRequest היא השאלה שהסוכן קיבל. DecisionOption היא אפשרות חלופית שהסוכן שקל. DecisionOutcome מתעד את הבחירה שהתקבלה ואת הנימוקים.
5. החלת סכימת גרף המאפיינים
bqaa context-graph כותב לטבלאות BigQuery, ולכן הן צריכות להתקיים לפני ההרצה הראשונה. context_graph_ddl.sql יוצרת קודם את חמש הטבלאות ואז את גרף המאפיינים שמפנה אליהן (BigQuery דוחה CREATE PROPERTY GRAPH שמפנה לטבלאות שעדיין לא קיימות), כך שהפעלה אחת מגדירה את הכול:
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
אמורות להופיע חמש תוצאות של CREATE TABLE ותוצאה אחת של CREATE PROPERTY GRAPH. ה-DDL הוא אידמפוטנטי, כך שאפשר להריץ אותו שוב באופן בטוח.
זהו השלב היחיד שבו עובדים עם סכימה – וזהו גם השלב היחיד שבו משתמשים בקובצי ה-SQL האלה. מערכת BigQuery מתעדת עכשיו את ההגדרה של הגרף, וקוראת אותה בחזרה מ-INFORMATION_SCHEMA.PROPERTY_GRAPHS לפי שם.bqaa context-graph אין קובץ נפרד להעברה אל ה-materializer, והשאילתה שמופעלת באמצעות GQL והגרף שנוצר תמיד זהים: זה אותו גרף שנפרס.
6. יצירת אירועים לדוגמה של סוכנים
בסביבת ייצור, BigQuery Agent Analytics Plugin מתעד אירועים באופן אוטומטי בזמן שהסוכן של ADK פועל. קטע הקוד הזה הוא רק לעיון – לא מפעילים פתרונות חכמים ב-Codelab הזה:
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
בשיעור Codelab הזה משתמשים בגנרטור קטן של אירועים סינתטיים שכותב את אותה צורה של שורות ישירות אל agent_events. מפעילים פתרונות חכמים:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
הפקודה מדפיסה דוח JSON. ב-5 סשנים אמורים להופיע "events_generated": 30, "events_inserted": 30 ו-"ok": true.
בשורת התצוגה המקדימה של הקורפוס אפשר לראות במבט חטוף כמה סשנים וכמה אירועים יש בו, ומה טווח הזמן שלהם:
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
במקרה של ריצה של 5 סשנים כברירת מחדל, מוצגים 5 סשנים ו-30 אירועים שנמשכים כמה דקות. (מזינים את התרחיש הריאליסטי שבהמשך, ואותה שאילתה מדווחת על כ-100 סשנים במשך כשלושה ימים).
בודקים שהאירועים הגיעו:
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
אמורות להופיע 25 שורות של TOOL_COMPLETED ו-5 שורות של AGENT_COMPLETED (בכל סשן מופעלים אירוע submit_request אחד, שלושה אירועים של evaluate_option, אירוע commit_outcome אחד ואירוע סיום AGENT_COMPLETED אחד – חמישה אירועים של כלי ועוד אירוע סיום של סוכן לכל סשן). השורות AGENT_COMPLETED הן סיומי הסשן שbqaa context-graph מזהה כדי לזהות אירועים מסיימים.
אופציונלי: נתונים בקנה מידה ריאליסטי
מאגר המידע של 5 הסשנים שלמעלה קטן בכוונה, כדי שההפעלה הראשונה תהיה מהירה וזולה. אם רוצים נתונים שדומים לנתוני הייצור – כמה נציגים ומשתמשים שמתפרסים על פני כמה ימים, עם סשנים שנכשלו, סשנים יתומים וסשנים שקוצרו – משתמשים בתרחיש decision-realistic. ברירת המחדל היא 100 סשנים בחלון של 72 שעות, והנתיב של ההפעלה הראשונה לא משתנה.
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
השדה session_outcome_counts בדוח ה-JSON מציג את השילוב – בערך {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10}.
כדי לאשר את חלוקת התוצאות, מסווגים כל סשן מהשורות שלו (יתום = אין AGENT_COMPLETED; נכשל = AGENT_COMPLETED עם status = 'error'; נחתך = כל שורה עם is_truncated = true; אחרת, הצלחה). בשלב הראשון, כל סשן מסווג, ובשלב השני, הסשנים מצורפים לפי התוצאה:
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
אמורים להופיע בערך 70 מקרים של הצלחה, 10 מקרים של כשל, 10 מקרים של נתונים יתומים ו-10 מקרים של נתונים חלקיים (בנוסף ל-5 הסשנים המוצלחים ממאגר הנתונים של ההרצה הראשונה, אם הגדרתם אותו קודם באותו מערך נתונים).
ב-10 הסשנים היתומים לא הופק AGENT_COMPLETED, ולכן ההפעלה של ברירת המחדל bqaa context-graph מדלגת עליהם (היא יוצרת חומר רק לסשנים שנסגרו עם אירוע סיום). כדי שהשגיאות יוצגו כ-session_orphaned במקום לנסות שוב ושוב ללא הפסקה, מוסיפים --max-session-age-hours כשמפעילים פתרונות חכמים – פרטים נוספים על --max-session-age-hours זמינים במאמר העברה לסביבת הייצור.
7. הפיכת גרף ההקשר למוחשי
bqaa context-graph קורא את agent_events הגולמי, ואז מסיק מה צריך לחלץ ישירות מהגרף שנפרס: הוא קורא את ההגדרה של CREATE PROPERTY GRAPH שהחלתם בהחלת סכימת גרף המאפיינים מ-INFORMATION_SCHEMA.PROPERTY_GRAPHS של BigQuery, מצטרף לסכימות של הטבלאות שהוא מפנה אליהן, מזהה את הישויות, הקשרים וסוגי העמודות ומאכלס את טבלאות הגרף. מציינים את הגרף שנפרס לפי שם באמצעות --graph agent_decisions_graph – אין קובץ SQL להעברה.
ריצה
bqaa context-graph באופן מקומי:
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
יוצג לכם דוח JSON מובנה:
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true מציין ש-bqaa context-graph מצא חמש פעילויות באתר שהושלמו, חילץ את תהליך קבלת ההחלטות מכל אחת מהן באמצעות AI.GENERATE, וכתב את השורות המתאימות בטבלאות של הגרף. חילוץ דטרמיניסטי (--extraction-mode=compiled-only, מוסבר בהמשך) מחזיר את אותו מבנה דוח – אותם שדות, אותם ok: true – הוא פשוט מדלג על הקריאות ל-AI.GENERATE.
פתרון בעיות: חילוץ ריק
אם מופיע ok: false עם error_code = "empty_extraction", הסיבה הנפוצה ביותר היא ש-aiplatform.googleapis.com API עדיין לא הופץ, או שחסר בחשבון שלכם roles/aiplatform.user. מחכים דקה ומנסים שוב, או מקצים את התפקיד:
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
ואז מריצים מחדש את הפקודה bqaa context-graph שלמעלה.
מוודאים שיש שורות בתרשים:
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
אמורות להופיע חמש שורות. במהלך חמשת הסשנים האלה נוצרו 25 צמתים של גרף בסך הכול – 5 צמתים של DecisionRequest, 15 צמתים של DecisionOption ו-5 צמתים של DecisionOutcome – שמחוברים באמצעות 15 קשתות של evaluatesOption ו-5 קשתות של resultedIn (רשת החלטות אחת לכל סשן).
שתי דרכים לחילוץ החלטות מאירועים
bqaa context-graph מציע שתי דרכים לחילוץ. בוחרים את האפשרות שמתאימה לעומס העבודה:
- חילוץ ברירת מחדל. הדרך הקלה ביותר. משתמש ב-
AI.GENERATEשל BigQuery כדי לקרוא את תוכן האירועים ולהסיק מסקנות לגבי ישויות וקשרים. הוא פועל על כל צורת אירוע ללא צורך בקוד נוסף. זה מה שמשמש ב-codelab. - חילוץ דטרמיניסטי (
--extraction-mode=compiled-only). הדרך הזולה יותר והמתאימה לביקורת. הכלי משתמש בכלי קטן לחילוץ הפניות ב-Python שכותבים פעם אחת לדומיין. אין קריאות ל-Vertex AI, אין חיובים לכל טוקן, הפלט ניתן לשחזור מלא. בפריסות בסביבת הייצור, בוחרים באפשרות הזו כשחשוב לחזות את העלויות או לשחזר את התוצאות בצורה מדויקת.
מדריך הפריסה של גרף ההקשר הוא המקור לשתי הדרכים, כולל פרטי IAM והסבר על יצירת כלי לחילוץ הפניות.
8. שאילתת נתוני מעקב של החלטה
אחרי שהתרשים מתמלא, אפשר לענות ישירות על שאלת הביקורת. לדוגמה: "For each request, what options did the agent weigh, and how did it resolve?" ב-GQL, זהו מעבר יחיד על פני הבקשה, האפשרויות שלה והתוצאה שלה.
כותבים את השאילתה לקובץ (traversal.sql). הסמן ${DATASET} מתמלא כשמריצים אותה בשלב הבא:
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
מפעילים פתרונות חכמים:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
אמורות להופיע 15 שורות: שלוש אפשרויות לכל בקשה, חמש בקשות. בכל שורה מוצגת הבקשה, האפשרות שהסוכן שקל, ציון הביטחון, התוצאה הסופית וההסבר.
כדי לקבל את התמונה המלאה של החלטה יחידה, מסננים לפי request_id כדי לקבל את קבוצת השורות שצוות הביקורת צריך: השאלה שהתקבלה, האפשרויות שנשקלו (עם ציונים) וההסבר שנרשם.
המחשה חזותית של הגרף ב-BigQuery Studio
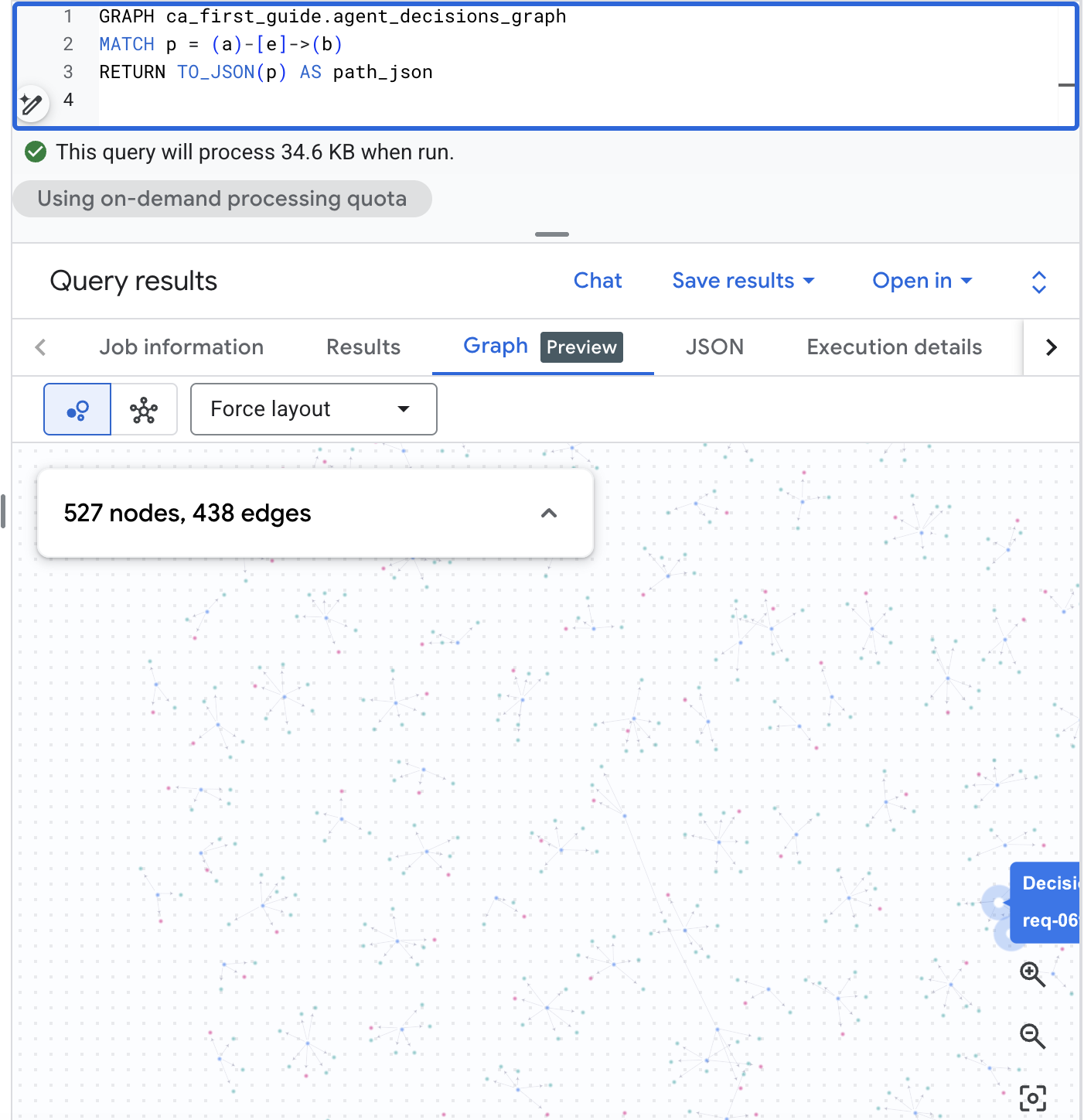
אפשר גם להציג את הגרף באופן חזותי ב-BigQuery Studio. פותחים את BigQuery Studio במסוף BigQuery, מריצים את שאילתת הנתיב שבהמשך, ואז עוברים לחלונית התוצאות בכרטיסייה Graph כדי לראות את רשת ההחלטות. עם מאגר המידע של קנה מידה ריאליסטי, אתם מקבלים מפה ויזואלית של בקשות, אפשרויות ותוצאות:
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
לשאול את אותה שאלה באנגלית פשוטה
לא כל מי שקורא את הביקורת כותב GQL. עם ניתוח נתונים שיחתי ב-BigQuery (גרסת Preview), צוות התאימות יכול לשאול את אותה שאלה בשפה טבעית ולקבל כרטיס תשובה מובנה – בלי תחביר של שאילתות ובלי צורך ללמוד על צירופים.
רושמים את agent_decisions_graph (יחד עם agent_events וטבלאות ההחלטות) כמקור נתונים לניתוח נתונים בשיחה, ואז שואלים את שאלת הביקורת ישירות:
שאלה לביקורת (באנגלית פשוטה): "Which requests never reached a committed outcome?"
התכונה 'ניתוח נתונים שימושי לשיחה' מנתחת את הגרף, כותבת בשבילכם את ה-SQL ומשיבה באנגלית פשוטה עם טבלה תומכת – כאן, כל בקשה שתועדה הגיעה לתוצאה מחייבת:
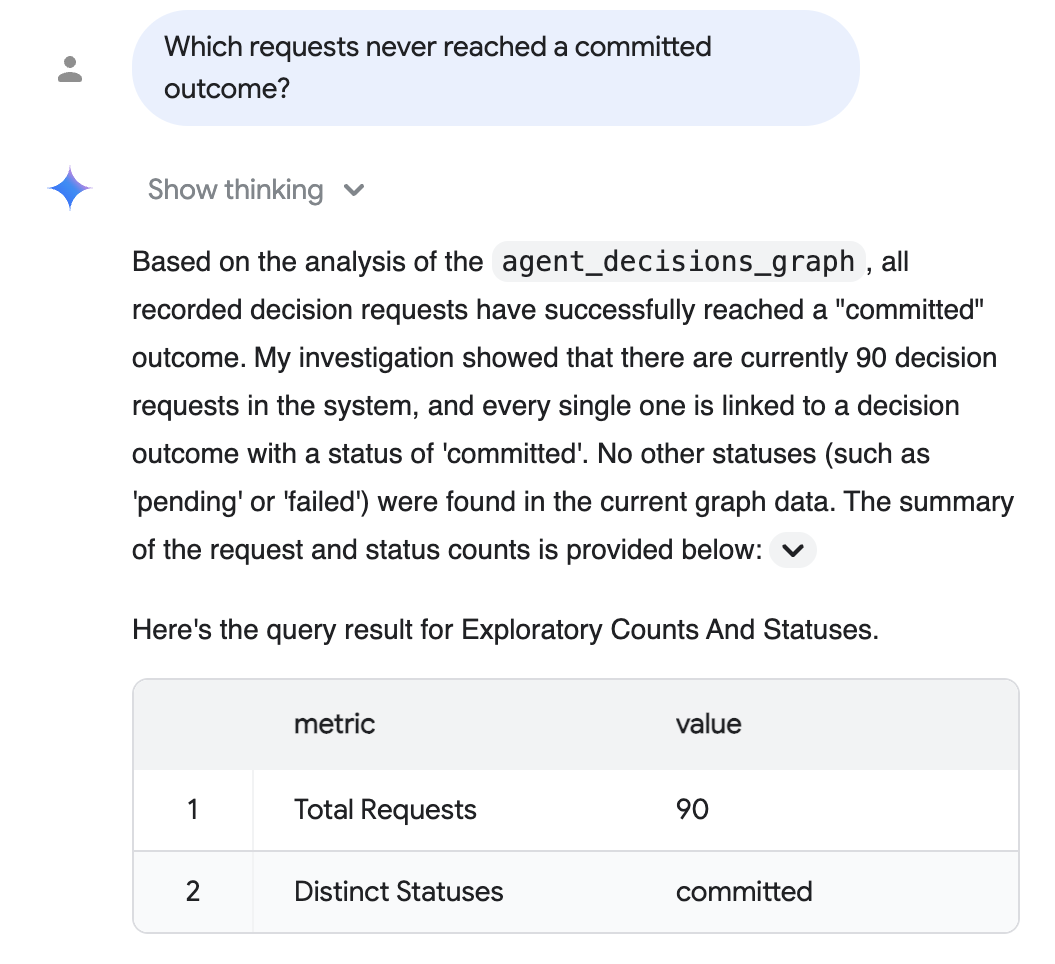
התשובה שלמעלה משקפת את מאגר המידע בקנה מידה ריאליסטי מהשלב האופציונלי נתונים בקנה מידה ריאליסטי (90 בקשות שהתממשו, כולן אושרו). המספרים המדויקים שתקבלו תלויים במאגר המידע שאיתו התחלתם, ובריצת ברירת המחדל של 5 סשנים מוצגים חמישה.
הוראות להגדרה מופיעות במסמכי Conversational Analytics.
9. העברה לסביבת הייצור
ההרצה המקומית שלמעלה משתמשת בהתנהגות ברירת המחדל, שכבר מכסה את היסודות של פריסות אמיתיות: כל הרצה משאירה שביל ביקורת (Cloud Logging מובנה בתוספת שורה לכל הרצה בטבלת מצב במערך הנתונים), ניסיונות חוזרים אוטומטיים במקרה של כשלים זמניים, וההתקדמות מתבצעת רק בסשנים שהסתיימו בהצלחה מלאה, כך שאין ספירה כפולה.
אמצעי הבקרה על ההפקה – חילוץ דטרמיניסטי (--extraction-mode=compiled-only), זיהוי של סשנים תקועים (--max-session-age-hours), הפעלה חד-פעמית של חלון קודם (--backfill --from / --to, במעקב בנפרד מהרענון הרגיל כדי שלא יפריע ללוח הזמנים של השידור החי), ותיחום של אצווה לכל הפעלה (--max-sessions) – הם דגלים אופציונליים שאפשר להשתמש בהם כשצריך. במדריך הפריסה של תרשים ההקשר מפורט כל אחד מהתרחישים עם מטריצת IAM מלאה ולוחות זמנים מומלצים.
10. הסרת המשאבים
מבטלים את מה שיצרתם כדי שלא תחויבו על מערך נתונים לא פעיל:
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
הפקודה הזו מסירה את מערך הנתונים, את אירועי הסוכן, את טבלאות הגרפים ואת טבלת המצב.
11. מזל טוב
מעולה! הפכתם יומני אירועים גולמיים של סוכנים לתרשים הקשר של סוכנים שאפשר להריץ עליו שאילתות, ועקבתם אחרי החלטה יחידה מקצה לקצה, בלי מסד נתונים חיצוני של תרשימים או צינור ETL.
אותו דפוס חל בכל מקום שבו סוכן מקבל החלטות משמעותיות: חיתום אשראי, אישור מראש, העברות בתקציב השיווק, רכש, שירות לקוחות ו-IT פנימי. כדי ליצור גרף הקשר של הסוכן, מעתיקים את הארטיפקטים של ה-codelab כנקודת התחלה, משנים את שני קובצי ההצהרות (DDL של הטבלה + סכמת CREATE PROPERTY GRAPH) בהתאם לדומיין שלכם ומחילים אותם על BigQuery – bqaa context-graph --graph קורא את הגרף שנפרס בחזרה מ-INFORMATION_SCHEMA וגוזר את השאר.
מה למדתם
- איך יוצרים מערך נתונים ב-BigQuery ומחילים סכימת גרף מאפיינים שמתארת תחום של החלטות של סוכן.
- איך מאכלסים את
agent_eventsבקורפוס של אירועים סינתטיים. - איך מריצים את הפקודה
bqaa context-graphכדי לחלץ את עקבות ההחלטות של הסוכן לתרשים הקשר של הסוכן מתוך האירועים האלה, וקוראים את הגדרת התרשים בחזרה מ-INFORMATION_SCHEMA. - איך לשלוח שאילתה לגרף שנוצר ב-GQL ולקרוא את התשובה בסגנון ביקורת.
מסמכים לדוגמה
- מאגר BigQuery Agent Analytics SDK
- ארטיפקטים של Codelab ומדריך להתאמה
- מדריך לפריסת גרף הקשר: ממשקי API נדרשים, מטריצת IAM, לוחות זמנים מומלצים, שאילתות של התראות ב-Cloud Monitoring ומודול Terraform.
- מסמכי BigQuery Graph (גרסת Preview).
- מסמכי BigQuery Conversational Analytics (גרסת Preview).